02 okt. 2025·7 min
Skrivskyddat läge vid incidenter: behåll läsning, blockera skrivningar
Lär dig hur skrivskyddat läge under incidenter blockerar skrivningar, behåller viktiga läsningar och kommunicerar tydligt i UI när databasen är stressad.
Lär dig hur skrivskyddat läge under incidenter blockerar skrivningar, behåller viktiga läsningar och kommunicerar tydligt i UI när databasen är stressad.
När din databas är överbelastad ser användare sällan ett rent "nere"-meddelande. De ser timeouter, sidor som laddas halvvägs, knappar som snurrar för evigt och åtgärder som ibland fungerar och ibland misslyckas. En sparning kan lyckas en gång och sedan ge fel nästa gång med "Något gick fel." Den osäkerheten är vad som gör incidenter kaotiska.
Det som vanligtvis går sönder först är skrivtunga vägar: att redigera poster, kassaflöden, formulärinlämningar, bakgrundsuppdateringar och allt som behöver en transaktion och lås. Under stress blir skrivningar långsammare, de blockerar varandra och de kan också sakta ner läsningar genom att hålla lås och orsaka mer arbete.
Slumpmässiga fel upplevs värre än en kontrollerad begränsning eftersom användare inte vet vad de ska göra härnäst. De försöker igen, uppdaterar sidan, klickar igen och skapar ännu mer belastning. Supportärenden ökar eftersom systemet ser ut att "typ fungera", men ingen kan lita på det.
Syftet med skrivskyddat läge under incidenter är inte perfektion. Det är att hålla de viktigaste delarna användbara: visa nyckelposter, söka, kontrollera status och ladda ner vad folk behöver för att fortsätta jobbet. Du stoppar eller fördröjer avsiktligt riskfyllda åtgärder (skrivningar) så att databasen kan återhämta sig och de återstående läsningarna förblir responsiva.
Sätt förväntningarna tydligt. Detta är en tillfällig begränsning och betyder inte att data tas bort. I de flesta fall finns användarens befintliga data kvar och är säker – systemet pausar helt enkelt ändringar tills databasen är frisk igen.
Skrivskyddat läge under incidenter är ett tillfälligt tillstånd där din produkt förblir användbar för visning, men vägrar allt som skulle förändra data. Målet är enkelt: behåll tjänsten hjälpsam samtidigt som du skyddar databasen från extra arbete.
I klarspråk kan folk fortfarande söka upp saker, men de kan inte göra ändringar som triggar skrivningar. Det betyder vanligtvis att bläddring, sökning, filtrering och öppning av poster fortfarande fungerar. Att spara formulär, ändra inställningar, posta kommentarer, ladda upp filer eller skapa nya konton blockeras.
Ett praktiskt sätt att tänka är: om en åtgärd uppdaterar en rad, skapar en rad, tar bort en rad eller skriver till en kö så är den inte tillåten. Många team blockerar också "dolda skrivningar" som analys-händelser lagrade i primärdatabasen, revisionsloggar skrivna synkront och "last seen"-tidsstämplar.
Skrivskyddat läge är rätt val när läsningar fortfarande mestadels fungerar, men skrivlatensen stiger, låskonkurrensen växer eller en kö av skrivtungt arbete saktar ner allt.
Gå helt offline när även grundläggande läsningar timear ut, din cache inte kan leverera det väsentliga, eller systemet inte pålitligt kan berätta för användarna vad som är säkert att göra.
Varför detta hjälper: skrivningar kostar ofta betydligt mer än en enkel läsning. En skrivning kan trigga index, constraints, lås och uppföljande frågor. Att blockera skrivningar förhindrar också retry-stormar, där klienter fortsätter skicka misslyckade sparningar och multiplicerar skadan.
Exempel: under en CRM-incident kan användare fortfarande söka konton, öppna kontaktuppgifter och se senaste affärer, men Redigera, Skapa och Importera är inaktiverade och varje sparförsök avvisas omedelbart med ett tydligt meddelande.
När du växlar till skrivskyddat läge under incidenter är målet inte "allt fungerar". Målet är att de viktigaste skärmarna fortfarande laddas, medan allt som skapar mer databaspress stoppar snabbt och säkert.
Börja med att namnge de få användaråtgärder som måste fungera även en dålig dag. Dessa är vanligtvis små läsningar som möjliggör beslut: visa senaste posten, kontrollera status, söka i en kort lista eller ladda ner en redan cachad rapport.
Bestäm sedan vad du kan pausa utan större skada. De flesta skrivvägar faller under "trevligt att ha" under en incident: redigeringar, massuppdateringar, importer, kommentarer, bilagor, analys-händelser och allt som triggar extra frågor.
Ett enkelt sätt att fatta beslutet är att sortera åtgärder i tre hinkar:
Sätt också en tidshorisont. Om du förväntar dig minuter kan du vara strikt och blockera nästan alla skrivningar. Om du förväntar dig timmar, överväg att tillåta ett mycket begränsat urval av säkra skrivningar (som återställning av lösenord eller kritiska statusuppdateringar) och köa allt annat.
Kom överens om prioriteten tidigt: säkerhet framför fullständighet. Det är bättre att visa en tydlig "ändringar är pausade"-meddelande än att tillåta en skrivning som halvlyckas och lämnar data inkonsekvent.
Att slå på skrivskydd är en avvägning: färre funktioner nu, men en användbar produkt och en friskare databas. Målet är att agera innan användare triggar en spiral av retries, timeouter och fastlåsta anslutningar.
Titta efter en liten uppsättning signaler du kan förklara i en mening. Om två eller fler dyker upp samtidigt, behandla det som en tidig varning:
Metriker bör inte vara den enda triggern. Lägg till ett mänskligt beslut: on-call-personen deklarerar ett incidenttillstånd och slår på skrivskyddet. Det stoppar debatter mitt under press och gör åtgärden auditerbar.
Gör trösklarna lätta att minnas och kommunicera. "Skrivningar är pausade eftersom databasen är överbelastad" är tydligare än "vi nådde saturation." Definiera också vem som kan växla och var det kontrolleras.
Undvik flapping mellan lägen. Lägg in enkel hysteresis: när du går till skrivskydd, stanna där i ett minimifönster (t.ex. 10–15 minuter) och byt tillbaka först efter att nyckelsignaler är normala en stund. Det förhindrar att användare ser formulär som fungerar ena minuten och misslyckas nästa.
Behandla skrivskyddat läge under incidenter som en kontrollerad ändring, inte en rusning. Målet är att skydda databasen genom att stoppa skrivningar samtidigt som de mest värdefulla läsningarna hålls igång.
Om du kan, skicka kodvägen innan du vrider på brytaren. Då är det att slå på skrivskydd bara en toggle, inte en live-ändring.
READ_ONLY=true. Undvik flera flaggor som kan hamna i osynk.När skrivskydd är aktivt, misslyckas snabbt innan du når databasen. Kör inte valideringsfrågor och blockera sedan skrivningen. Den snabbaste blockerade förfrågan är den som aldrig rör din stressade databas.
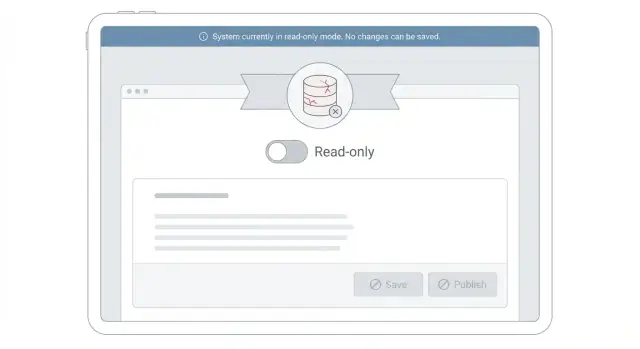
När du aktiverar skrivskyddat läge under incidenter blir UI en del av lösningen. Om folk fortsätter klicka Spara och får vaga fel kommer de försöka igen, uppdatera sidan och öppna ärenden. Tydliga meddelanden minskar belastning och frustration.
Ett bra mönster är en synlig, persistent banner högst upp i appen. Håll den kort och saklig: vad som händer, vad användare kan förvänta sig och vad de kan göra nu. Dölj den inte i en toast som försvinner.
Användare vill främst veta om de kan fortsätta arbeta. Stav ut det i klartext. För de flesta produkter betyder det:
En enkel statusetikett hjälper också folk att förstå framsteg utan att gissa. "Undersöker" betyder att ni fortfarande letar efter orsaken. "Stabiliserar" betyder att ni minskar belastningen och skyddar data. "Återhämtar" betyder att skrivningar snart återkommer, men kan vara långsamma.
Undvik skuldbeläggande eller vaga texter som "Något gick fel" eller "Du hade inte behörighet." Om en knapp är inaktiverad, märk den: "Redigering är tillfälligt pausad medan vi stabiliserar systemet."
Ett litet exempel: i ett CRM, håll kontakt- och affärssidor läsbara, men inaktivera Redigera, Lägg till anteckning och Ny affär. Om någon ändå försöker visa en kort dialog: "Ändringar är pausade just nu. Du kan kopiera denna post eller exportera listan, och försök igen senare."
När du växlar till skrivskydd är målet inte "behåll allt synligt." Det är "behåll de få sidor folk litar på" utan att lägga mer press på en stressad databas.
Börja med att trimma de tyngsta skärmarna. Långa tabeller med många filter, fritextsökningar över flera fält och avancerade sorteringar triggar ofta långsamma frågor. I skrivskyddsläget gör dessa skärmar enklare: färre filterval, en säker standardsortering och ett begränsat datumintervall.
Föredra cachade eller förberäknade vyer för de sidor som betyder mest. En enkel "kontoöversikt" som läser från cache eller en sammanfattningstabell är vanligtvis säkrare än att ladda råa händelseloggar eller göra många joins.
Praktiska sätt att hålla läsningar vid liv utan att öka belastningen:
Ett konkret exempel: i en CRM-incident, behåll Visa kontakt, Visa affärsstatus och Visa senaste anteckning. Dölj tillfälligt Avancerad sökning, Intäktsdiagram och Full e-posthistorik, och visa en notis att data kan vara några minuter gammal.
När du går till skrivskydd är det största överraskningen ofta inte UI. Det är de osynliga skrivarna: bakgrundsjobb, schemalagda synkar, admin-massåtgärder och tredjepartsintegrationer som fortsätter banka på databasen.
Börja med att stoppa bakgrundsarbete som skapar eller uppdaterar poster. Vanliga bovar är importer, nattliga synkroniseringar, e-postutskick som skriver leveransloggar, analys-rollups och retry-loopar som fortsätter försöka samma misslyckade uppdatering. Att pausa dessa minskar snabbt belastningen och undviker en andra våg av tryck.
En säker standard är att pausa eller strypa skrivintensiva jobb och alla kö-konsumenter som persisterar resultat, inaktivera admin-massåtgärder (massuppdateringar, massraderingar, stora re-indexer) och misslyckas snabbt på skrivendpoints med ett tydligt temporärt svar istället för att timea ut.
För webhooks och integrationer vinner tydlighet över optimism. Om du accepterar en webhook men inte kan bearbeta den skapar du mismatchar och supportarbete. När skrivningar är pausade, returnera ett temporärt fel som säger åt avsändaren att försöka igen senare, och se till att ditt UI-meddelande matchar vad som händer bakom kulisserna.
Var försiktig med "köa för senare"-buffring. Det låter vänligt, men kan skapa en backlog som flödar över systemet i samma ögonblick du slår på skrivningar igen. Buffra endast användarskrivningar om du kan garantera idempotens, begränsa köstorleken och visa användaren det verkliga tillståndet (v väntande vs sparad).
Slutligen, audita dolda mass-skrivare i din produkt. Om en automation kan uppdatera tusentals rader ska den tvingas av i skrivskyddsläge även om resten av appen fortfarande laddas.
Det snabbaste sättet att göra en dålig incident värre är att betrakta skrivskyddat läge som en kosmetisk förändring. Om du bara inaktiverar knappar i UI kommer folk fortfarande skriva via API:er, gamla flikar, mobilappar och bakgrundsjobb. Databasen förblir under press, och du tappar också förtroende eftersom användare ser "sparat" på ett ställe och saknade ändringar på ett annat.
Ett verkligt skrivskyddsläge under incidenter behöver en klar regel: servern vägrar skrivningar, varje gång, för varje klient.
Dessa mönster återkommer under databasöverbelastning:
Få systemet att bete sig förutsägbart. Upprätthåll en enda server-side-växel som avvisar skrivningar med ett tydligt svar. Lägg in en cooldown så att när du går in i skrivskydd stannar du där en bestämd tid (t.ex. 10–15 minuter) om inte en operatör ändrar det.
Var strikt med dataintegritet. Om en skrivning inte kan slutföras helt, misslyckas hela operationen och berätta för användaren vad de ska göra härnäst. Ett enkelt meddelande som "Skrivskyddsläge: visning fungerar, ändringar är pausade. Försök igen senare." minskar upprepade retries.
Skrivskyddat läge hjälper bara om det är lätt att slå på och beter sig likadant överallt. Innan problem startar, se till att det finns en enda brytare (feature flag, konfig eller admin-växel) som on-call kan aktivera på sekunder, utan en deployment.
När du misstänker databasöverbelastning, gör en snabb genomgång som bekräftar grunderna:
Under incidenten, håll en person fokuserad på att verifiera användarupplevelsen, inte bara dashboards. En snabb kontroll i ett inkognitofönster fångar problem som dolda banderoller, trasiga formulär eller oändliga spinners som skapar extra refresh-trafik.
Planera utgången innan du slår på funktionen. Bestäm vad "frisk" betyder (latens, felprocent, replikeringsfördröjning) och gör en kort verifiering efter återgång: skapa en testpost, redigera den och bekräfta att räkningar och senaste aktivitet ser korrekt ut.
Klockan 10:20 är ditt CRM långsamt och databas-CPU är maxad. Supportärenden börjar komma in: användare kan inte spara redigeringar av kontakter och affärer. Men teamet behöver fortfarande slå upp telefonnummer, se affärsstadier och läsa senaste anteckningar inför samtal.
Du väljer en enkel regel: frys allt som skriver, behåll de mest värdefulla läsningarna. I praktiken hålls kontaktsökning, kontaktdetaljsidor och pipeline-vyn uppe. Redigering av kontakt, skapa ny affär, lägga till anteckningar och massimporter blockeras.
I UI ska förändringen vara tydlig och lugn. På redigeringsskärmar är Spara-knappen inaktiverad och formuläret syns så folk kan kopiera det de skrev. En banner högst upp säger: "Skrivskyddsläge är på på grund av hög belastning. Visning är tillgänglig. Ändringar är pausade. Försök igen senare." Om en användare ändå triggar en skrivning (t.ex. via en API-anrop) returnera ett tydligt meddelande och undvik automatiska retries som hamrar databasen.
Operativt, håll flödet kort och repeterbart. Aktivera skrivskydd och verifiera att alla skrivendpoints respekterar det. Pausa bakgrundsjobb som skriver (synkroniseringar, importer, e-postloggning, analys-backfills). Stryp eller pausa webhooks och integrationer som skapar uppdateringar. Övervaka databasbelastning, felprocent och långsamma frågor. Publicera en statusuppdatering med vad som påverkas (redigeringar) och vad som fortfarande fungerar (sök och vyer).
Återhämtning är inte bara att vrida tillbaka brytaren. Återaktivera skrivningar gradvis, kontrollera fel-loggar för misslyckade sparningar och bevaka en eventuell skriv-storm från köade jobb. Kommunicera tydligt: "Skrivskyddsläge är av. Sparning återställd. Om du försökte spara mellan 10:20 och 10:55, vänligen kontrollera dina senaste ändringar."
Skrivskyddsläge fungerar bäst när det är tråkigt och upprepbart. Målet är att följa ett kort manus med tydliga ägare och kontroller.
Håll den till en sida. Inkludera era triggers (de få signaler som motiverar att slå på skrivskydd), den exakta brytare ni vrider och hur ni bekräftar att skrivningar blockeras, en kort lista över nyckelläsningar som måste fungera, tydliga roller (vem vrider brytaren, vem följer metrik, vem hanterar support) och exitkriterier (vad måste vara sant innan skrivningar återaktiveras och hur tömmer ni backlogs).
Skriv och godkänn texterna nu så ni inte bråkar om ordalydelsen under ett driftstopp. Ett enkelt set täcker vanligtvis de flesta fall:
Öva bytet i staging och timera det. Se till att support och on-call snabbt hittar brytaren och att loggar tydligt visar blockerade skrivningar. Efter varje incident, granska vilka läsningar som verkligen var kritiska, vilka som var trevliga att ha och vilka som av misstag skapade belastning, och uppdatera checklistan.
Om du bygger produkter på Koder.ai (koder.ai), kan det vara hjälpsamt att behandla skrivskydd som en förstaklass-brytare i din genererade app så UI och server-side skrivskydd förblir konsekventa när du behöver dem som mest.
Vanligtvis försämras dina skrivvägar först: sparningar, redigeringar, utcheckningar, importer och allt som kräver en transaktion. Under belastning gör lås och långsamma commits att skrivningar blockerar varandra, och dessa blockerade skrivningar kan också göra läsningar långsammare.
För att det blir oförutsägbart. Om åtgärder ibland fungerar och ibland misslyckas fortsätter användare att försöka igen, uppdatera sidan och klicka, vilket lägger till mer belastning och skapar ännu fler timeout- och fastlåsningsförfrågningar.
Det är ett tillfälligt läge där produkten förblir användbar för att visa data men vägrar förändringar. Folk kan bläddra, söka och öppna poster, men allt som skulle skapa, uppdatera eller ta bort data blockeras.
Som standard blockera alla åtgärder som skriver till primärdatabasen, inklusive ”dolda skrivningar” som revisionsloggar, last-seen-tidsstämplar och analyshändelser som lagras i samma databas. Om det ändrar en rad eller lägger i köer som senare skrivs, behandla det som en skrivning.
Slå på det när du ser tidiga tecken på att skrivningar håller på att spåra ur: timeouter, stigande p95-latens, lås väntetider, uttömning av anslutningspoolen eller upprepade långsamma frågor. Det är bättre att slå på det innan användares upprepade försök förstärker incidenten.
Använd en global växel och låt servern upprätthålla den, inte bara UI. UI bör inaktivera eller dölja skrivåtgärder, men varje skriv-endpoint ska misslyckas snabbt med samma tydliga svar innan den når databasen.
Visa en persistent banner som säger vad som händer, vad som fortfarande fungerar och vad som är pausat, i enkel svenska. Gör blockerade åtgärder explicita så användare inte fortsätter försöka och du slipper en flod av “Något gick fel”-ärenden.
Håll en liten uppsättning viktiga sidor igång och förenkla allt som triggar tunga frågor. Föredra cachade sammanfattningar, mindre sidstorlekar, säkra standardsorteringar och något föråldrade data framför komplexa filter och dyra joins.
Pausa eller stryp bakgrundsjobb, synkroniseringar, importer och kö-konsumenter som skriver resultat till databasen. För webhooks: acceptera inte arbete du inte kan committa; returnera ett temporärt fel så att avsändaren försöker igen senare i stället för att skapa tysta mismatchar.
Att bara inaktivera knappar i UI är det största misstaget; API:er, mobila klienter och gamla flikar kommer fortfarande att skriva. Ett annat vanligt problem är att systemet vaklar mellan lägen; lägg in en minsta tid i skrivskyddat läge och återgång först när mätvärden är stabila, och verifiera med ett faktiskt skapa/redigera-test.