29 dec. 2025·8 min
Administrationsverktyg som förhindrar dataförlust: säkrare massåtgärder
Administrationsverktyg som förhindrar dataförlust använder säkrare massåtgärder, tydliga bekräftelser, mjuk borttagning, revisionsloggar och rollbegränsningar så operatörer undviker kostsamma misstag.
Var dataförlust sker i administrationsverktyg
Interna administrationsverktyg känns ofta säkrare eftersom "bara personal" kan använda dem. Den tilliten är just varför de är högrisk. De som använder dem har makt, jobbar snabbt och gör ofta samma sak många gånger om dagen. Ett misstag kan påverka tusentals poster.
De flesta olyckor orsakas inte av illvilja. De kommer från "ups"-ögonblick: ett filter som var för brett, ett sökord som matchade fler än väntat, eller en dropdown som stod kvar på fel tenant. En annan klassiker är fel miljö: någon tror att de är i staging men tittar på produktion eftersom UI ser nästan likadant ut.
Hastighet och repetition gör det värre. När ett verktyg är byggt för att gå snabbt lär sig användarna muskelminne: klick, bekräfta, nästa. Om skärmen laggar klickar de två gånger. Om en massåtgärd tar tid öppnar de en andra flik. Dessa vanor är normala, men skapar förutsättningar för misstag.
"Förstöra data" är inte bara att trycka på en radera-knapp. I praktiken kan det betyda:
- Att ta bort poster (inklusive kaskadborttagningar)
- Att skriva över fält (t.ex. sätta status till "closed" för fel uppsättning)
- Att ta bort relationer (avlänka en användare från ett konto, ta bort behörigheter)
- Att rensa historik (tömma loggar, radera meddelanden, truncate:a tabeller)
- Irreversibla exporter eller synkroniseringar (skjuta fel data till ett annat system)
För team som bygger administrationsverktyg som förhindrar dataförlust bör "tillräckligt säkert" vara en tydlig överenskommelse, inte en magkänsla. En enkel definition: en stressad operatör ska kunna återställa från ett vanligt misstag utan ingenjörshjälp, och en sällsynt irreversibel åtgärd ska kräva extra friktion, tydligt bevis på avsikt och en post att granska senare.
Även om du snabbt bygger appar med en plattform som Koder.ai kvarstår dessa risker. Skillnaden är om du designar skyddsräcken från dag ett eller väntar på den första incidenten som lär dig läxan.
Börja med en enkel riskkarta
Innan du ändrar någon UI, bli klar över vad som faktiskt kan gå fel. En riskkarta är en kort lista över åtgärder som kan orsaka verklig skada, plus reglerna som måste omge dem. Det här steget skiljer administrationsverktyg som verkligen förhindrar dataförlust från sådana som bara ser omsorgsfulla ut.
Börja med att skriva ner dina farligaste åtgärder. Dessa är oftast inte vardagsredigeringarna. De är operationer som förändrar många poster snabbt eller rör känslig data.
En användbar första genomgång är:
- Radera, slå ihop, stänga eller hård-disable:a konton
- Omsätta ägarskap (kunder, fakturor, ärenden, leads)
- Importer och massuppdateringar (CSV, API-jobb, migrationer)
- Fakturahantering (återbetalningar, krediter, avbokningar)
- Behörighetsändringar (roller, åtkomst till PII)
Markera sedan varje åtgärd som återställbar eller icke-återställbar. Var strikt. Om du bara kan återställa genom att återställa från backup, behandla det som icke-återställbart för operatören som utför jobbet.
Bestäm sedan vad som måste skyddas av policy, inte bara design. Juridik och integritetsregler gäller ofta för PII (namn, mejl, adresser), fakturaregister och revisionsloggar. Även om ett verktyg tekniskt kan ta bort något kan er policy kräva retention eller två-personersgranskning.
Separera rutinmässiga operationer från undantagsoperationer. Rutinjobb ska vara snabba och säkra (små ändringar, tydlig ångra). Undantagsjobb ska vara långsammare medvetet (extra kontroller, godkännanden, snävare begränsningar).
Slutligen, enas om enkla termer för "blast radius" så alla pratar samma språk: en post, många poster, alla poster. Till exempel är "återassigna den här kunden" annorlunda än "återassigna alla kunder från denna säljare." Den etiketten styr senare era standarder, bekräftelser och rollgränser.
Exempel: i ett vibe-coding-projekt på Koder.ai kan du märka "bulk import users" som många-poster, återställbar endast om du loggar varje skapat ID, och policy-skyddad eftersom den rör PII.
Mönster för säkrare massåtgärder
Massåtgärder är där bra adminverktyg blir riskfyllda. Om du bygger administrationsverktyg som förhindrar dataförlust, behandla varje "apply to many"-knapp som ett kraftverktyg: användbart, men utformat för att undvika snedsteg.
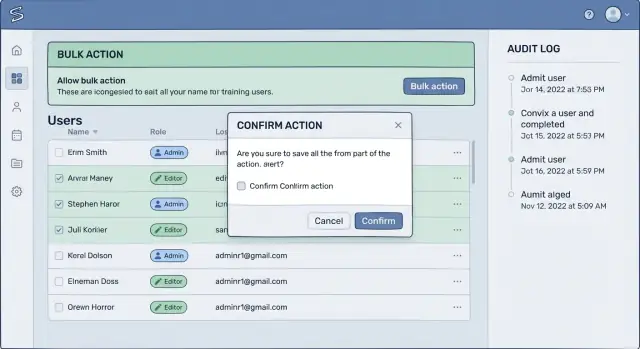
Ett starkt standardval är en förhandsgranskning först, sedan körning. Istället för att köra direkt, visa vad som skulle förändras och låt operatören bekräfta först när de ser omfånget.
Gör scope explicit och svårt att missförstå. Acceptera inte "alla" som en vag idé. Tvinga operatören att definiera filter som tenant, status och datumintervall, och visa sedan exakt antal poster som matchar. En liten provlista (även 10 objekt) hjälper människor att upptäcka misstag som "fel region" eller "arkiverat inkluderat."
Ett praktiskt mönster som fungerar väl:
- Börja med en torrkörningsskärm som visar antal, filter och ett kort prov av påverkade poster
- Kräv ett explicit scope-val (t.ex.: "Endast Aktiva kunder i Tenant A, skapade före 2024-01-01")
- Begränsa varje körning (t.ex. 1 000 poster) och erbjud att köra igen för nästa batch
- Tvinga igenom rate-limiting så ett dåligt klick inte hamrar databasen eller downstream-system
- Kör som ett köat jobb med progress, loggar och en tydlig avbryt-knapp
Köade jobb slår "skjut-och-glöm" eftersom de skapar ett pappersspår och ger operatören en chans att stoppa åtgärden när de märker något fel vid 5 %.
Exempel: en operatör vill mass-inaktivera användarkonton efter en bedrägerivåg. Förhandsgranskningen visar 842 konton, men provet innehåller VIP-kunder. Den lilla ledtråden förhindrar ofta det verkliga felet: ett filter utan "fraud_flag = true."
Om du snabbt sätter ihop en intern konsol (även med en build-by-chat-plattform som Koder.ai), implementera dessa mönster tidigt. De sparar mer tid än de kostar.
Bekräftelseflöden som folk faktiskt läser
De flesta bekräftelser misslyckas eftersom de är för generiska. Om skärmen säger "Är du säker?" klickar folk bara igenom på autopilot. En bekräftelse som fungerar använder samma ord som användaren skulle använda för att förklara resultatet för en kollega.
Byt ut vaga etiketter som "Radera" eller "Verkställ" mot den verkliga konsekvensen: "Inaktivera 38 konton", "Ta bort åtkomst för denna tenant" eller "Makulera 12 fakturor". Det är en av de enklaste förbättringarna för administrationsverktyg som förhindrar dataförlust, eftersom det förvandlar ett reflexklick till en ögonblicklig igenkänning.
Få användaren att bekräfta scope
Ett bra flöde tvingar igenom en snabb mental kontroll: "Är det här rätt sak, på rätt uppsättning poster?" Sätt scope i bekräftelsen, inte bara på sidan bakom. Inkludera tenant- eller arbetsytans namn, postantalet och eventuella filter som datumintervall eller status.
Till exempel: "Stäng konton för Tenant: Acme Retail. Antal: 38. Filter: sista inloggning före 2024-01-01." Om någon av dessa värden ser fel ut fångar användaren det innan skada uppstår.
När åtgärden är verkligt destruktiv, krävs en liten, avsiktlig handling. Typade bekräftelser fungerar bra när kostnaden för ett misstag är hög.
- Be om en kort fras som RADERA 38 KONTO
- Eller be dem skriva tenant-namnet exakt
- Eller kräva att de återfyller det nummer som visas på skärmen
Använd två steg bara när påverkan är hög
Tvåstegsbekräftelser bör vara sällsynta, annars ignorerar användarna dem. Spara dem för åtgärder som är svåra att återställa, korsar tenants eller påverkar pengar. Steg ett bekräftar avsikt och scope. Steg två bekräftar tidpunkt, som "Kör nu" vs "Schemalägg", eller kräver ett högre behörighetsgodkännande.
Undvik slutligen "OK/Avbryt". Knapptexter ska säga vad som händer: "Inaktivera konton" och "Gå tillbaka". Det minskar felklick och gör beslutet verkligt.
Mjuk borttagning, återställningar och retention-regler
Planera skydden först
Skissa roller, bekräftelser och retention-regler innan du genererar den första skärmen.
Mjuk borttagning är standarden för de flesta användarrelaterade objekt: konton, order, ärenden, inlägg och även utbetalningar. Istället för att ta bort raden, markera den som raderad och göm den i normala vyer. Detta är ett av de enklaste mönstren bakom administrationsverktyg som förhindrar dataförlust, eftersom misstag blir återställbara.
En policy för mjuk borttagning behöver ett tydligt retention-fönster och tydligt ägarskap. Bestäm hur länge raderade objekt är återställbara (t.ex. 30 eller 90 dagar) och vem som får återställa dem. Koppla återställningsrätten till roller, inte individer, och behandla återställningar som produktionsändringar.
Gör återställning synlig (och loggad)
Återställningar ska vara lätta att hitta när någon tittar på en raderad post, inte begravd i en separat skärm. Lägg till en synlig status som "Raderad", visa när det hände och vem som gjorde det. När en återställning sker, logga den som sin egen händelse, inte som en redigering av den ursprungliga raderingen.
Ett snabbt sätt att definiera era retention-regler är att svara på dessa frågor:
- Vad är standard retention-period per objekttyp?
- Vilken roll kan återställa, och måste de ange en anledning?
- Vad händer efter att retention-perioden löper ut?
- Vem kan förlänga retention för juridiska eller faktureringsfall?
- Hur hanterar ni "ta bort mina data"-förfrågningar?
Kantfall som bryter återställningar
Mjuk borttagning låter enkelt tills du återställer in en värld som gått vidare. Unika begränsningar kan kollidera (ett användarnamn återanvändes), referenser kan saknas (en föräldrapost raderades) och fakturahistorik måste förbli konsekvent även om användaren "försvann." Ett praktiskt angreppssätt är att hålla immutabla loggar (fakturor, betalningshändelser) separata från användarprofildata, och att återställa relationer försiktigt med tydliga varningar när en full återställning inte är möjlig.
Hård borttagning bör vara sällsynt och explicit. Om ni tillåter det, låt det kännas som ett undantag med en kort godkännandebana:
- Kräver en högre roll än för mjuk borttagning
- Be om en typad bekräftelse och en anledning
- Köa raderingen med en fördröjning (t.ex. 24 timmar)
- Notifiera en ägare eller on-call-kanal
- Behåll en slutgiltig revisionspost även efter borttagning
Om ni bygger er admin på en plattform som Koder.ai, definiera mjuk borttagning, återställning och retention som förstklassiga åtgärder tidigt så de blir konsekventa över varje genererad skärm och arbetsflöde.
Revisibilitet: gör åtgärder förklarbara i efterhand
Olyckor händer i adminpaneler, men den verkliga skadan uppstår ofta senare: ingen kan svara vad som ändrades, vem som gjorde det och varför. Om du vill ha administrationsverktyg som förhindrar dataförlust, behandla revisionsloggar som en del av produkten, inte ett felsökningseftertanke.
Börja med att logga åtgärder på ett sätt en människa kan läsa. "User 183 updated record 992" räcker inte när en kund är upprörd och on-call-personen försöker åtgärda snabbt. Bra loggar fångar identitet, tidpunkt, scope och avsikt, plus tillräcklig detalj för att rulla tillbaka eller åtminstone förstå påverkan.
Vad som bör sparas (så det är användbart senare)
En praktisk miniminivå är:
- Vem gjorde det (användare, roll och impersonationsinfo om det användes)
- Vad och var (åtgärdsnamn, tenant/konto och påverkade objekttyper)
- När och varifrån (tidsstämpel, tidszon, IP eller device/session-ID)
- Vad som ändrades (före/efter för nyckelfält, eller en diff för större objekt)
- Varför det hände (fri-text anledning och ett valfritt ärende-/referens-ID)
Massåtgärder förtjänar särskild behandling. Logga dem som ett enda "jobb" med en tydlig sammanfattning (hur många valda, hur många lyckades, hur många misslyckades), och spara också per-post-resultat. Då blir det enkelt att svara "Återbetalade vi 200 order eller bara 173?" utan att gräva i en vägg av poster.
Gör loggar lätta att söka: efter admin-användare, tenant, åtgärdstyp och tidsintervall. Inkludera filter för "endast bulkjobb" och "hög-risk-åtgärder" så granskare kan upptäcka mönster.
Tvinga inte fram byråkrati. Ett kort "orsak"-fält som stödjer mallar ("Kund begärde stängning", "Bedrägerigranskning") fylls i oftare än en lång blankett. Om det finns ett supportärende, låt folk klistra in ID:t.
Planera slutligen åtkomst för läsning. Många interna behöver se loggar, men bara en liten grupp bör se känsliga fält (som fulla före/efter-värden). Separera "kan se revisionssammanfattningar" från "kan se detaljer" för att minska exponering.
Rollbaserade begränsningar och skyddsräcken
De flesta olyckor händer eftersom behörigheter är för breda. Om alla i praktiken är admin kan en trött operatör göra permanent skada med ett klick. Målet är enkelt: gör den säkra vägen till standard, och kräva extra avsikt för riskfyllda åtgärder.
Designa roller kring verkliga jobb, inte titlar. En supportagent som svarar på ärenden behöver inte samma åtkomst som någon som hanterar fakturaregler.
Bygg roller kring uppgifter
Börja med att separera vad folk kan se från vad de kan ändra. Ett praktiskt sett interna roller kan se ut så här:
- Read-only: visa användare, order och loggar
- Operator: redigera profiler och återställa lösenord
- Billing operator: utfärda återbetalningar inom en gräns
- Data steward: slå ihop poster och köra massrättelser
- Security admin: inaktivera konton och hantera roller
Detta håller "radera" utanför vardagsarbete och minskar blast-radien när någon gör ett misstag.
För de farligaste åtgärderna, lägg till ett upphöjt läge. Tänk det som en tidsbegränsad nyckel. För att gå in i upphöjt läge krävs ett starkare steg (omautentisering, chefsgodkännande eller en andra person) och systemet lämnar det automatiskt efter 10–30 minuter.
Miljösäkerhet räddar också team. UI bör göra det svårt att blanda ihop staging med produktion. Använd tydliga visuella markörer, visa miljönamnet i varje header och inaktivera destruktiva åtgärder i icke-produktion om inte en explicit toggle är på.
Skydda slutligen tenants från varandra. I multitenant-system bör kors-tenant-ändringar blockeras som standard och bara aktiveras för specifika roller med en tydlig tenant-switch och klar på-skärm-bekräftelse.
Om du bygger på en plattform som Koder.ai, behandla dessa skydd som produktfunktioner, inte eftertankar. Administrationsverktyg som förhindrar dataförlust är ofta bara bra behörighetsdesign plus några välplacerade hastighetsdämpare.
Ett realistiskt scenario: massåterbetalningar och kontostängningar
Förhandsgranska innan körning
Lägg till ett torrkörningssteg som visar filter, posträkningar och ett prov innan körning.
En supportagent behöver hantera ett betalningsavbrott. Planen är enkel: återbetala berörda order, sedan stänga konton som begärt avbokning. Här tjänar administrationsverktyg som förhindrar dataförlust in sig, eftersom agenten är på väg att köra två högpåverkande massåtgärder i följd.
Risken visar sig i en liten detalj: filtret. Agenten väljer "Orders skapade senaste 24 timmarna" istället för "Orders betalda under avbrottsfönstret." På en hektisk dag kan det dra in tusentals normala kunder och trigga återbetalningar de aldrig bad om. Om nästa steg är "stäng konto för återbetalade order" sprids skadan snabbt.
Innan verktyget kör något bör UI tvinga en paus med en tydlig förhandsgranskning som matchar hur människor tänker, inte hur databasen tänker. Till exempel bör det visa:
- Totalt antal konton som kommer att stängas (och hur många som redan är stängda)
- Total återbetalningssumma, plus min/max belopp
- Ett litet, rullbart prov av berörda kunder (namn, mejl, order-ID)
- Undantag och hoppningar (misslyckade betalningar, redan återbetalda, bestridda order)
- Den exakta filter-sammanfattningen i vanlig text, med en tydlig "Redigera filter"-knapp
Lägg sedan till en andra, separat bekräftelse för kontostängning, eftersom det är en annan typ av skada. Ett bra mönster är att kräva att agenten skriver en kort fras som "STÄNG 127 KONTON" så agenten märker om siffran ser fel ut.
Om "stäng konto" är en mjuk borttagning är återställning realistisk. Du kan återställa kontona, hålla inloggningar blockerade och sätta en retention-regel (t.ex. auto-purge efter 30 dagar) så det inte blir permanent skräp.
Revisionsloggar gör städning och utredning möjlig senare. Chefen ska se vem som körde, exakt filter, förhandsgranskningssummor som visades då och en lista över påverkade poster. Rollgränser spelar också roll: agenter kan köra återbetalningar upp till en daglig gräns, men endast en chef kan stänga konton eller godkänna stängningar över en tröskel.
Om du bygger den här typen av konsol i Koder.ai är funktioner som snapshots och rollback användbara extra skydd, men den första försvarslinjen är fortfarande förhandsgranskningen, bekräftelserna och rollerna.
Steg för steg: retrofit för säkerhet i en befintlig admin
Att retrofit:a säkerhet fungerar bäst när du behandlar din admin som en produkt, inte en hög med interna sidor. Välj ett hög-risk-flöde först (t.ex. massinaktivering av användare), och ta det steg för steg.
En praktisk retrofit-plan
Börja med att lista skärmar och endpoints som kan radera, skriva över eller trigga penningrörelser. Inkludera "dolda" risker som CSV-importer, massredigeringar och skript som operatörer kör från UI.
Gör sedan massåtgärder säkrare genom att tvinga scope och förhandsgranskning. Visa exakt vilka poster som matchar filtren, hur många som kommer att förändras och ett litet prov med ID:n innan åtgärden körs.
Ersätt hårda raderingar med mjuk borttagning där ni kan. Spara en raderad-flagga, vem som gjorde det och när. Lägg till en återställningsväg som är lika enkel att använda som radering, plus tydliga retention-regler (t.ex. "återställbart i 30 dagar").
Efter det, lägg till en revisionslogg och sitta med operatörer för att granska verkliga poster. Om en loggrad inte kan svara "vad ändrades, från vad till vad, och varför" hjälper den inte vid incidenter.
Till sist, skärp rollerna och lägg till godkännanden för högpåverkande åtgärder. Till exempel: tillåt support att ge återbetalningar upp till en liten gräns, men kräva en andra person för stora belopp eller kontostängningar. Så håller administrationsverktyg som förhindrar dataförlust sig användbara utan att bli skrämmande.
Snabbt exempel
En operatör behöver stänga 200 inaktiva konton. Före ändringen klickar de på "Radera" och hoppas att filtren är rätt. Efter retrofit måste de bekräfta den exakta frågan ("status=inactive, last_login>365d"), granska antalet och provlistan, välja "Stäng (återställbart)" istället för radera och ange en anledning.
En bra "färdig"-standard är:
- Du kan förhandsgranska och exportera den påverkade mängden innan du kör.
- Du kan ångra (återställa eller rollback) inom ett definierat fönster.
- Varje åtgärd är spårbar till en person och en anledning.
- Högpåverkande åtgärder är begränsade av roll eller kräver godkännande.
Om du bygger interna verktyg i en chattstyrd plattform som Koder.ai, lägg in dessa skydd som återanvändbara komponenter så nya admin-sidor är säkra från början.
Vanliga misstag som fortfarande leder till olyckor
Skala din byggprocess
Gå från gratis till Pro eller Business när du behöver mer kapacitet för interna verktyg.
Många team bygger administrationsverktyg som i teorin förhindrar dataförlust, men förlorar ändå data i praktiken eftersom säkerhetsfunktionerna är lätta att ignorera eller svåra att använda.
Den vanligaste fällan är en universell bekräftelse. Om varje åtgärd visar samma "Är du säker?"-meddelande slutar folk läsa det. Ännu värre: team lägger ofta till fler bekräftelser för att "lösa" misstag, vilket lär operatörer att klicka snabbare.
Ett annat problem är saknad kontext i rätt ögonblick. En destruktiv åtgärd bör tydligt visa vilken tenant eller workspace du är i, om det är produktion eller test och hur många poster som påverkas. När den informationen är gömd på en annan skärm ber verktyget om en dålig dag.
Massåtgärder kan också vara farliga när de körs omedelbart utan spårning. Operatörer behöver en tydlig jobbpost: vad körde, på vilket filter, vem startade det och vad systemet gjorde när det träffade ett fel. Utan det kan du varken pausa, ångra eller förklara vad som hände.
Här är misstag som återkommer:
- Använda samma bekräftelsetext för raderingar, återbetalningar och behörighetsändringar
- Lägga till bekräftelser så ofta att folk klickar igenom på autopilot
- Inte visa postantal, tenant och miljö på bekräftelseskärmen
- Köra massåtgärder direkt utan förhandsgranskning, jobb-sida eller möjlighet att stoppa
- Ha revisionsloggar men inte göra dem sökbara per användare, post eller tid
Ett snabbt exempel: en operatör tänker inaktivera 12 konton i en sandbox-tenant, men verktyget använder det sist använda tenant som standard och gömmer det i headern. De kör en massåtgärd, den exekverar direkt och den enda "loggen" är en vag rad som "bulk update completed." När någon märker det går det inte att enkelt se vad som ändrades eller återställa det.
Bra säkerhet är inte fler popups. Det är tydlig kontext, meningsfulla bekräftelser och åtgärder du kan spåra och reversera.
Snabbchecklista och nästa steg
Innan du släpper en destruktiv åtgärd, gör en sista genomgång med fräscha ögon. De flesta admin-incidenter händer när ett verktyg låter någon agera på fel scope, döljer verklig påverkan eller inte erbjuder en tydlig väg tillbaka.
Här är en snabb pre-flight-checklista för administrationsverktyg som förhindrar dataförlust:
- Scope + förhandsgranskning: visa exakt vad som kommer att förändras (vem, vad, var). Inkludera en läsbar förhandsvisning och ett prov av berörda poster.
- Antal + begränsningar: visa totalt antal objekt och sätt vettiga tak (och rate limits) så ett klick inte når "allt".
- Kontextkontroller: få operatören att bekräfta tenant/konto, miljö (prod vs test) och lägga in en kort anledning som visas i loggar.
- Återställningsväg: prioritera mjuk borttagning där det går, kontrollera att återställningsflödet fungerar och definiera retention (hur länge återställning är möjlig).
- Ansvarsskyldighet: logga vem gjorde vad, när, varifrån och med vilka filter. Gör loggar sökbara och se till att roller matchar verkliga ansvar.
Om du är operatör: pausa i tio sekunder och läs upp verktyget för dig själv: "Jag agerar på tenant X, ändrar N poster, i produktion, av anledning Y." Om någon del känns otydlig, stoppa och be om ett säkrare UI innan du kör åtgärden.
Nästa steg: prototypa säkrare flöden snabbt i Koder.ai med Planning Mode för att skissa skärmar och skydd innan ni bygger. Under test, använd snapshots och rollback så ni kan prova verkliga kantfall utan rädsla. När flödet känns stabilt, exportera källkoden och deploya när ni är redo.