17 dec. 2025·6 min
PostgreSQL-anslutningspoolning: app-pooling vs PgBouncer
PostgreSQL-anslutningspoolning: jämför apppooler och PgBouncer för Go-backends, mätvärden att övervaka och felkonfigurationer som orsakar latensspikar.
PostgreSQL-anslutningspoolning: jämför apppooler och PgBouncer för Go-backends, mätvärden att övervaka och felkonfigurationer som orsakar latensspikar.
En databasanslutning är som en telefonlinje mellan din app och Postgres. Att öppna en kostar tid och resurser på båda sidor: TCP/TLS-uppsättning, autentisering, minne och en backend-process på Postgres-sidan. En anslutningspool håller ett litet antal av dessa “telefonlinjer” öppna så att din app kan återanvända dem istället för att ringa upp för varje förfrågan.
När pooling är avstängd eller felkonfigurerad syns sällan ett snyggt fel först. Du får slumpmässig tröghet. Förfrågningar som vanligtvis tar 20–50 ms kan plötsligt ta 500 ms eller 5 sekunder, och p95 skjuter i höjden. Sedan kommer timeouter, följt av “too many connections”, eller en kö i din app medan den väntar på en ledig anslutning.
Anslutningsgränser spelar roll även för små appar eftersom trafiken är burstig. Ett marknadsföringsmail, ett cron-jobb eller några långsamma endpoints kan få dussintals förfrågningar att nå databasen samtidigt. Om varje förfrågan öppnar en ny anslutning kan Postgres spendera mycket av sin kapacitet på att acceptera och hantera anslutningar istället för att köra frågor. Om du redan har en pool men den är för stor kan du överbelasta Postgres med för många aktiva backends och orsaka context switching och minnestryck.
Var uppmärksam på tidiga symtom som:
Pooling minskar anslutningschurn och hjälper Postgres att hantera burstar. Det fixar inte långsamma SQL-frågor. Om en fråga gör en full tabellskanning eller väntar på lås så ändrar pooling mest hur systemet fallerar (köar tidigare, timeouter senare), inte om det blir snabbt.
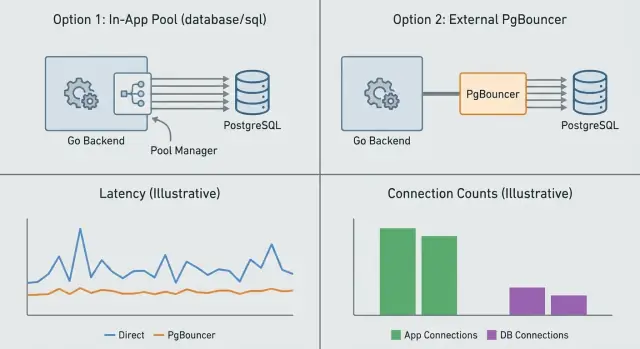
Anslutningspoolning handlar om att kontrollera hur många databasanslutningar som finns samtidigt och hur de återanvänds. Du kan göra detta i din app (app-nivå pooling) eller med en separat tjänst framför Postgres (PgBouncer). De löser närliggande men olika problem.
App-nivå pooling (i Go, vanligtvis inbyggda database/sql-poolen) hanterar anslutningar per process. Den bestämmer när en ny anslutning ska öppnas, när en ska återanvändas och när inaktiva stängs. Detta undviker uppstartskostnaden för varje förfrågan. Det den inte kan göra är att koordinera mellan flera appinstanser. Om du kör 10 repliker har du i praktiken 10 separata pooler.
PgBouncer sitter mellan din app och Postgres och poolar på uppdrag av många klienter. Det är mest användbart när du har många kortlivade förfrågningar, många appinstanser eller spikig trafik. Det begränsar server-sidans anslutningar till Postgres även om hundratals klientanslutningar kommer samtidigt.
En enkel ansvarsfördelning:
De kan samarbeta utan “dubbelpoolnings”-problem så länge varje lager har ett tydligt syfte: en rimlig database/sql-pool per Go-process, plus PgBouncer för att upprätthålla en global anslutningsbudget.
En vanlig missuppfattning är att “fler pooler betyder mer kapacitet.” Oftast betyder det motsatsen. Om varje service, worker och replika har sin egen stora pool kan det totala antalet anslutningar explodera och orsaka köbildning, context switching och plötsliga latensspikar.
database/sql-poolning faktiskt beter sigI Go är sql.DB en manager för en anslutningspool, inte en enda anslutning. När du kallar db.Query eller db.Exec försöker database/sql återanvända en inaktiv anslutning. Om den inte kan det kan den öppna en ny (upp till din gräns) eller få förfrågan att vänta.
Den väntan är där “mystery latency” ofta kommer ifrån. När poolen är mättad köar förfrågningar inne i din app. Utifrån ser det ut som att Postgres blivit långsamt, men tiden spenderas faktiskt på att vänta på en ledig anslutning.
Det mesta av fininställningen handlar om fyra inställningar:
MaxOpenConns: hård gräns för öppna anslutningar (idle + in use). När du når den blockerar anropare.MaxIdleConns: hur många anslutningar som kan ligga redo för återanvändning. För lågt värde orsakar frekventa reconnects.ConnMaxLifetime: tvingar periodisk återcykling av anslutningar. Hjälpsamt för load balancers och NAT-timeouter, men för lågt värde orsakar churn.ConnMaxIdleTime: stänger anslutningar som varit oanvända för länge.Återanvändning av anslutningar sänker vanligtvis latens och databas-CPU eftersom du undviker upprepad uppsättning (TCP/TLS, auth, session-init). Men en överdimensionerad pool kan göra motsatsen: den tillåter fler samtidiga frågor än Postgres klarar av bra, vilket ökar konkurrens och overhead.
Tänk i totaler, inte per process. Om varje Go-instans tillåter 50 öppna anslutningar och du skalar till 20 instanser, har du i praktiken tillåtit 1 000 anslutningar. Jämför det antalet med vad din Postgres-server faktiskt kan hantera smidigt.
Ett praktiskt utgångsvärde är att knyta MaxOpenConns till förväntad samtidighet per instans, och sedan validera med pool-metriker (in-use, idle och wait time) innan du höjer det.
PgBouncer är en liten proxy mellan din app och PostgreSQL. Din service ansluter till PgBouncer, och PgBouncer håller ett begränsat antal riktiga serveranslutningar till Postgres. Under spikar köar PgBouncer klientarbete istället för att omedelbart skapa fler Postgres-backends. Den kön kan vara skillnaden mellan en kontrollerad nedgång i prestanda och en databas som tippar över.
PgBouncer har tre poolningslägen:
Session pooling beter sig mest som direktanslutningar till Postgres. Det är minst överraskande, men sparar färre serveranslutningar under burstig belastning.
För typiska Go HTTP-API:er är transaction pooling ofta ett bra standardval. De flesta förfrågningar gör en liten fråga eller en kort transaktion och är sedan klara. Transaction pooling låter många klientanslutningar dela en mindre Postgres-anslutningsbudget.
Avvägningen gäller sessions-tillstånd. I transaction-läge kan allt som förutsätter en fast serveranslutning misslyckas eller bete sig konstigt, inklusive:
SET, SET ROLE, search_path)Om din app är beroende av den typen av tillstånd är session pooling säkrare. Statement pooling är mest restriktivt och passar sällan webbappar.
En användbar regel: om varje förfrågan kan ställa in vad den behöver inom en transaktion, håller transaction pooling oftast latensen jämnare under belastning. Om du behöver långlivat sessionsbeteende, använd session pooling och fokusera på striktare gränser i appen.
Om du kör en Go-tjänst med database/sql har du redan app-sida pooling. För många team räcker det: några instanser, jämn trafik och frågor som inte är extremt burstiga. I det fallet är det enklaste och säkraste att tunna Go-poolen, hålla databasens anslutningsgräns realistisk och sluta där.
PgBouncer hjälper mest när databasen träffas av för många klientanslutningar samtidigt. Det syns när du har många appinstanser (eller serverless-liknande skalning), burstig trafik och många korta frågor.
PgBouncer kan också skada om det används i fel läge. Om din kod förlitar sig på sessionstillstånd (temporära tabeller, förberedda statements som återanvänds, advisory locks som hålls över anrop eller sessionnivåinställningar) kan transaction pooling orsaka förvirrande fel. Om du verkligen behöver sessionbeteende, använd session pooling eller hoppa över PgBouncer och storleksbestäm app-poolerna noggrant.
Använd denna tumregel:
Anslutningsgränser är en budget. Om du spenderar allt på en gång väntar varje ny förfrågan och tail-latensen skjuter i höjden. Målet är att kapa samtidigheten på ett kontrollerat sätt samtidigt som genomströmningen förblir stabil.
Mät dagens toppar och tail-latens. Notera peak aktiva anslutningar (inte medelvärden), plus p50/p95/p99 för förfrågningar och nyckelfrågor. Notera eventuella anslutningsfel eller timeouter.
Sätt en säker Postgres-anslutningsbudget för appen. Börja från max_connections och dra av marginal för adminåtkomst, migrationer, bakgrundsjobb och burstar. Om flera tjänster delar databasen, dela upp budgeten medvetet.
Mappa budgeten till Go-gränser per instans. Dela app-budgeten med antalet instanser och sätt MaxOpenConns till det (eller något lägre). Sätt MaxIdleConns tillräckligt högt för att undvika konstant reconnects och sätt livstider så att anslutningar återvinns ibland utan att skapa churn.
Lägg till PgBouncer endast om du behöver det, och välj ett läge. Använd session pooling om du behöver sessions-tillstånd. Använd transaction pooling när du vill ha största minskningen av serveranslutningar och din app är kompatibel.
Rulla ut gradvis och jämför före och efter. Ändra en sak i taget, gör en kanarirutroll och jämför tail-latens, pool-wait-tid och databas-CPU.
Exempel: om Postgres säkert kan ge din tjänst 200 anslutningar och du kör 10 Go-instanser, börja med MaxOpenConns=15-18 per instans. Det lämnar utrymme för burstar och minskar sannolikheten att varje instans når taket samtidigt.
Pooling-problem visar sig sällan först som “too many connections.” Oftare ser du en långsam ökning i väntetid och sedan ett plötsligt hopp i p95 och p99.
Börja med vad din Go-app rapporterar. Med database/sql, övervaka öppna anslutningar, in-use, idle, wait count och wait time. Om wait count ökar medan trafiken är stabil är din pool för liten eller anslutningar hålls för länge.
På databassidan, följ aktiva anslutningar vs max, CPU och låsaktivitet. Om CPU är låg men latens hög är det ofta köbildning eller lås, inte rå beräkningskapacitet.
Om du kör PgBouncer, lägg till en tredje vy: klientanslutningar, serveranslutningar till Postgres och ködjup. En växande kö med stabila serveranslutningar är ett klart tecken på att budgeten är mättad.
Bra larmindikatorer:
Pooling-problem syns ofta under burstar: förfrågningar staplas och väntar på en anslutning, sedan ser allt bra ut igen. Rotorsaken är ofta en inställning som verkar rimlig på en instans men farlig när du kör många kopior.
Vanliga orsaker:
MaxOpenConns satt per instans utan en global budget. 100 anslutningar per instans över 20 instanser är 2 000 potentiella anslutningar.ConnMaxLifetime / ConnMaxIdleTime satt för lågt. Det kan utlösa reconnect-stormar när många anslutningar återcirkuleras samtidigt.Ett enkelt sätt att minska spikar är att behandla poolning som en delad gräns, inte en app-lokal standard: kapa totala anslutningar över alla instanser, håll en modest idle-pool och använd livstider som är tillräckligt långa för att undvika synkade reconnects.
När trafiken skjuter i höjden ser du vanligtvis ett av tre utfall: förfrågningar köar och väntar på en ledig anslutning, förfrågningar timear ut, eller allt blir så långsamt att retries staplas.
Köbildning är den listiga. Din handler kör fortfarande, men den sitter parkerad och väntar på en anslutning. Den väntan blir en del av svarstiden, så en liten pool kan göra en 50 ms-fråga till ett endpointsvar på flera sekunder under belastning.
En hjälpsam mental modell: om din pool har 30 användbara anslutningar och du plötsligt har 300 samtidiga förfrågningar som alla behöver databasen, måste 270 av dem vänta. Om varje förfrågan håller en anslutning i 100 ms hoppar tail-latensen snabbt upp i sekunder.
Sätt en tydlig timeout-budget och håll dig till den. Apptimern bör vara något kortare än databastimern så att du misslyckas snabbt och minskar trycket istället för att låta arbete ligga och hänga.
statement_timeout så att en dålig fråga inte kan hålla anslutningar för evigtLägg sedan till backpressure så att du inte överbelastar poolen från början. Välj en eller två förutsägbara mekanismer, som att begränsa samtidighet per endpoint, shed:a load med tydliga fel (t.ex. 429) eller separera bakgrundsjobb från användartrafik.
Slutligen, fixa långsamma frågor först. Under poolningspress håller långsamma frågor anslutningar längre, vilket ökar väntetider, vilket ökar timeouter, vilket triggar retries. Den feedback-loopen är hur “lite långsamt” blir “allt är långsamt.”
Behandla load-testning som ett sätt att validera din anslutningsbudget, inte bara genomströmning. Målet är att bekräfta att pooling beter sig under tryck på samma sätt som i staging.
Testa med realistisk trafik: samma förfrågningsmix, burstmönster och samma antal appinstanser som du kör i produktion. “Ett-endpoint”-benchmarks döljer ofta poolproblem fram till lansering.
Inkludera en uppvärmning så att du inte mäter kalla cache- och ramp-effekter. Låt poolerna nå normal storlek, och börja sedan spela in siffror.
Om du jämför strategier, håll arbetsbelastningen identisk och kör:
database/sql, ingen PgBouncer)Efter varje körning, spela in ett litet scorecard du kan återanvända efter varje release:
Med tiden gör detta kapacitetsplanering upprepbar istället för gissningslek.
Innan du rör poolstorlekar, skriv ner ett nummer: din anslutningsbudget. Det är det maximalt säkra antalet aktiva Postgres-anslutningar för den här miljön (dev, staging, prod), inklusive bakgrundsjobb och adminåtkomst. Om du inte kan ange det talet gissar du.
En snabb checklista:
MaxOpenConns) passar i budgeten (eller PgBouncer-gränsen).max_connections och eventuella reserverade anslutningar stämmer överens med din plan.Utrullningsplan som håller rollback enkel:
Om du bygger och hostar en Go + PostgreSQL-app på Koder.ai (koder.ai), kan Planning Mode hjälpa dig att kartlägga förändringen och vad du kommer att mäta, och snapshots plus rollback gör det enklare att ångra om tail-latensen blir värre.
Nästa steg: lägg till en mätning före nästa trafikökning. “Tid som spenderas väntande på en anslutning” i appen är ofta mest användbar, eftersom den visar pooling-tryck innan användarna känner det.
En pool håller ett litet antal PostgreSQL-anslutningar öppna och återanvänder dem över flera förfrågningar. Det undviker att upprepade gånger betala uppstartskostnaden (TCP/TLS, autentisering, uppsättning av backend-process), vilket hjälper till att hålla tail-latensen stabil under burstar.
När poolen är mättad väntar förfrågningar inne i din app på en ledig anslutning, och den väntetiden syns som långsamma svar. Det ser ofta ut som “slumpmässig långsamhet” eftersom medelvärdet kan vara normalt medan p95/p99 skjuter i höjden vid trafiktoppar.
Nej. Pooling ändrar främst hur systemet beter sig under belastning genom att minska reconnect-churn och styra samtidigheten. Om en fråga är långsam på grund av fullständiga tabellskanningar, lås eller dåliga index kan inte pooling göra den snabbare; den kan bara begränsa hur många långsamma frågor som körs samtidigt.
App-pooling hanterar anslutningar per process, så varje appinstans har sin egen pool och sina egna gränser. PgBouncer ligger framför Postgres och upprätthåller en global anslutningsbudget över många klienter — särskilt användbart om du har många repliker eller burstig trafik.
Om du kör ett litet antal instanser och det totala antalet öppna anslutningar håller sig tryggt under databasgränsen räcker det oftast att ställa in och tunna database/sql i Go. Lägg till PgBouncer när många instanser, autoskalning eller burstig trafik kan pressa totala anslutningar över vad Postgres klarar av smidigt.
Ett bra tillvägagångssätt är att sätta en total anslutningsbudget för tjänsten, dela den med antalet appinstanser och sätta MaxOpenConns något lägre per instans. Börja försiktigt, övervaka väntetid och p95/p99, och öka bara om du är säker på att databasen har marginal.
Transaktionspoolning är ofta ett bra standardval för vanliga HTTP-API:er eftersom många korta förfrågningar kan dela på färre serveranslutningar och hålla latensen jämn under belastning. Använd sessionspoolning om din kod förlitar sig på sessionstillstånd som måste bestå över flera statements.
Förberedda statements, temp-tabeller, advisory locks och sessionnivåinställningar kan bete sig annorlunda eftersom en klient kanske inte får samma serveranslutning nästa gång. Om du behöver dessa funktioner, håll allt inom en enda transaktion per förfrågan eller byt till sessionspoolning för att undvika förvirrande fel.
Övervaka p95/p99 tillsammans med appens pool-väntetid, eftersom väntetid ofta stiger innan användarna märker problem. På Postgres, spåra aktiva anslutningar, CPU och lås; på PgBouncer, spåra klientanslutningar, serveranslutningar och ködjup för att se om anslutningsbudgeten är mättad.
Sätt tydliga tidsgränser och undvik obegränsat väntande: ha en request-deadline och en kortare deadline kring DB-anropet, samt statement_timeout i databasen så att en dålig fråga inte håller anslutningar för evigt. Lägg sedan på backpressure genom att begränsa samtidighet på DB-tunga endpoints eller shed:a load.
Börja med att definiera en anslutningsbudget och säkerställ att (instanser x MaxOpenConns) ryms inom den (eller inom PgBouncer-gränsen). Sätt timeouter så att “vänta för alltid” inte döljer problem. Om du använder PgBouncer, välj ett poolingläge som passar din användning av sessionstillstånd. Undvik mycket korta connection-livslängder som orsakar återanslutningsstormar och bekräfta att max_connections och reserverade anslutningar stämmer med planen.