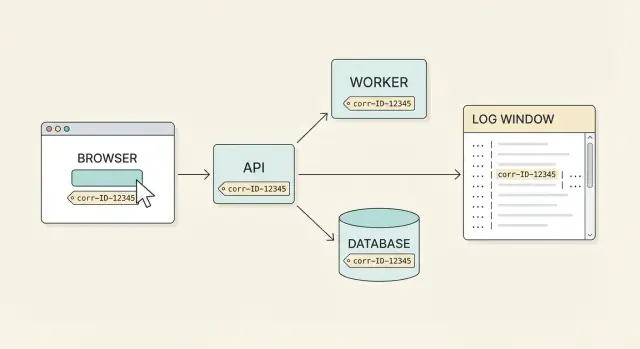
Varför korrelations-ID är viktiga för supporten
Support får nästan aldrig en perfekt buggrapport. En användare säger "Jag klickade på Betala och det misslyckades", men det enkla klicket kan beröra webbläsaren, en API-gateway, en betalningstjänst, en databas och ett bakgrundsjobb. Varje del loggar sin egen del av historien vid olika tidpunkter, på olika maskiner. Utan en gemensam etikett gissar du vilka loggrader som hör ihop.
Ett korrelations-ID är den gemensamma etiketten. Det är ett ID som fästs vid en användaråtgärd (eller ett logiskt arbetsflöde) och följer med genom varje förfrågan, retry och tjänstehopp. Med verklig end-to-end-täckning kan du börja med ett användarklagomål och dra ut hela tidslinjen över systemen.
Folk blandar ofta ihop några liknande ID-typer. Här är en tydlig uppdelning:
- Korrelations-ID: grupperar allt som rör en åtgärd (till exempel "Spara inställningar").
- Request-ID: identifierar en enskild HTTP-förfrågan. Retries får nya request-ID.
- Trace-ID: används av distribuerade tracing-verktyg; liknande syfte, ofta genererat av tracing-bibliotek.
- Sessions-ID: identifierar en användarsession över många åtgärder; för brett för att felsöka en enskild incident.
Hur bra det kan se ut är enkelt: en användare rapporterar ett problem, du ber om korrelations-ID:t som visas i gränssnittet (eller finns i en supportvy), och vem som helst i teamet kan hitta hela historien på några minuter. Du ser frontend-förfrågan, API-svaret, backend-stegen och databasresultatet — alla bundna tillsammans.
Bestäm era konventioner för korrelations-ID
Innan ni börjar generera något, kom överens om några regler. Om varje team väljer ett annat header-namn eller loggfält kommer supporten fortfarande att behöva gissa.
Börja med ett kanoniskt namn och använd det överallt. Ett vanligt val är en HTTP-header som X-Correlation-Id, plus ett strukturerat loggfält som correlation_id. Välj en stavning och en case-stil, dokumentera den och se till att er reverse-proxy eller gateway inte byter namn eller tar bort headern.
Välj ett format som är enkelt att skapa och säkert att dela i tickets och chattar. UUID fungerar bra eftersom det är unikt och trist. Håll ID:t tillräckligt kort för att kopiera, men inte så kort att det finns risk för kollisioner. Konsekvens slår fyndighet.
Bestäm också var ID:t måste synas så människor faktiskt kan använda det. I praktiken betyder det att det finns i förfrågningar, loggar och felutdata, och att det går att söka i det verktyg teamet använder.
Definiera hur länge ett ID ska leva. Ett bra standardval är en användaråtgärd, som "klickade Betala" eller "sparade profil." För längre arbetsflöden som hoppar över tjänster och köer, behåll samma ID tills arbetsflödet är klart, och starta sedan ett nytt för nästa åtgärd. Undvik "ett ID för hela sessionen" eftersom sökningar snabbt blir bullriga.
En hård regel: lägg aldrig personlig data i ID:t. Inga e-postadresser, telefonnummer, användar-id eller ordernummer. Om ni behöver den kontexten, logga den i separata fält med rätt sekretesskontroller.
Generera ID:t i frontend (praktiskt tillvägagångssätt)
Det enklaste stället att starta ett korrelations-ID är när användaren börjar en åtgärd ni bryr er om: klickar "Spara", skickar ett formulär eller triggar ett flöde som startar flera förfrågningar. Om ni väntar på att backend ska skapa det, tappar ni ofta bort den första delen av historien (UI-fel, retries, avbrutna förfrågningar).
Använd ett slumpmässigt, unikt format. UUID v4 är ett vanligt val eftersom det är lätt att generera och osannolikt att kollidera. Håll det opakt (inga användarnamn, e-post eller tidsstämplar) så ni inte läcker persondata i headers och loggar.
Skapa och behåll ID:t för ett arbetsflöde
Behandla ett "arbetsflöde" som en användaråtgärd som kan trigga flera förfrågningar: validera, ladda upp, skapa post, sedan uppdatera listor. Skapa ett ID när arbetsflödet startar och behåll det tills flödet är slut (lyckat, misslyckat eller användaren avbryter). Ett enkelt mönster är att lagra det i komponentens state eller i ett lättviktigt request-context-objekt.
Om användaren startar samma åtgärd två gånger, generera ett nytt korrelations-ID för andra försöket. Det låter support skilja på "samma klick som retades" från "två separata inskickningar."
Bifoga det till varje förfrågan som görs av arbetsflödet
Lägg till ID:t i varje API-anrop som arbetsflödet triggar, vanligtvis via en header som X-Correlation-ID. Om ni använder en delad API-klient (fetch-wrapper, Axios-instans etc.) passa ID:t en gång och låt klienten injicera det i alla anrop.
const correlationId = crypto.randomUUID();
await api.post('/orders', payload, {
headers: { 'X-Correlation-ID': correlationId }
});
await api.get('/orders/summary', {
headers: { 'X-Correlation-ID': correlationId }
});
Om er UI gör bakgrundsförfrågningar som inte hör till åtgärden (polling, analytics, auto-refresh), återanvänd inte arbetsflödes-ID:t för dem. Håll korrelations-ID:n fokuserade så ett ID berättar en historia.
Skicka ID:t genom era API:er pålitligt
När ni väl har genererat ett korrelations-ID i webbläsaren är jobbet enkelt: det måste lämna frontenden med varje förfrågan och anlända oförändrat vid varje API-gräns. Det är där det oftast går sönder när team lägger till nya endpoints, nya klienter eller ny middleware.
Det säkraste standardvalet är en HTTP-header på varje anrop (till exempel X-Correlation-Id). Headers är lätta att lägga till på ett ställe (en fetch-wrapper, en Axios-interceptor, en mobil nätverkslayer) och kräver inga ändringar i payloads.
Om ni har cross-origin-förfrågningar, se till att er API tillåter den headern. Annars kan webbläsaren tyst blockera den och ni tror att ni skickar den när ni inte gör det.
Om ni måste lägga ID:t i querysträngen eller request-body (vissa tredjepartsverktyg eller filuppladdningar kräver det), håll det konsekvent och dokumenterat. Välj ett fältnamn och använd det överallt. Blanda inte correlationId, requestId och cid beroende på endpoint.
Retries är en annan vanlig fälla. Ett retry bör behålla samma korrelations-ID om det fortfarande är samma användaråtgärd. Exempel: en användare klickar "Spara", nätverket bröts, er klient försöker POST igen. Support ska se en sammanhängande bana, inte tre orelaterade. Ett nytt användarklick (eller ett nytt bakgrundsjobb) ska få ett nytt ID.
För WebSockets, inkludera ID:t i meddelandeomslaget, inte bara i initiala handskakningen. En anslutning kan bära många användaråtgärder.
Om ni vill göra en snabb pålitlighetskontroll, håll det enkelt:
- En gemensam klienthelper lägger till headern på varje förfrågan.
- Retries återanvänder samma ID för samma åtgärd.
- Alla body/query-fallbacks använder ett dokumenterat fältnamn.
- WebSocket-meddelanden inkluderar ett explicit
correlationId-fält.
Sätt upp API-entrypointens beteende
Deploy a traceable app faster
Go from plan to a running app without setting up servers yourself.
Er API-edge (gateway, load balancer eller första webbtjänst som tar emot trafik) är där korrelations-ID antingen blir pålitligt eller förvandlas till gissningar. Behandla denna entrypoint som sanningskällan.
Acceptera ett inkommande ID om klienten skickar ett, men anta inte att det alltid finns. Om det saknas, generera ett nytt omedelbart och använd det för resten av förfrågan. Det håller saker fungerande även när vissa klienter är äldre eller felkonfigurerade.
Gör lätt validering så dåliga värden inte förorenar era loggar. Håll det tillåtande: kontrollera längd och tillåtna tecken, men undvik strikta format som kan avvisa riktig trafik. Till exempel, tillåt 16–64 tecken och bokstäver, siffror, bindestreck och understreck. Om värdet misslyckas med validering, ersätt det med ett nytt ID och fortsätt.
Gör ID:t synligt för anroparen. Returnera det alltid i response-headers och inkludera det i felkroppar. Så kan en användare kopiera det från UI, eller en supportagent be om det och hitta exakt loggspår.
En praktisk edge-policy ser ut så här:
- Läs
X-Correlation-ID (eller er valda header) från förfrågan.
- Om den saknas eller är ogiltig, skapa ett nytt ID och fäst det i request-kontexten.
- Lägg till
X-Correlation-ID i varje svar, inklusive fel.
- När ni returnerar JSON-fel, ekontera ID:t i payloaden.
Exempel på felpayload (vad support bör se i tickets och skärmdumpar):
{
"error": {
"code": "PAYMENT_FAILED",
"message": "We could not confirm the payment.",
"correlation_id": "c3a8f2d1-9b24-4c61-8c4a-2a7c1b9c2f61"
}
}
När en förfrågan når er backend, behandla korrelations-ID:t som en del av request-kontexten, inte något ni stoppar i en global variabel. Globals går sönder när ni hanterar två förfrågningar samtidigt, eller när asynkront arbete fortsätter efter svaret.
En skalbar regel: varje funktion som kan logga eller anropa en annan tjänst bör ta emot kontexten som innehåller ID:t. I Go-tjänster betyder det vanligtvis att ni passerar context.Context ner genom handlers, business-logic och klientkod.
När tjänst A anropar tjänst B, kopiera samma ID till den utgående förfrågan. Generera inte ett nytt mitt i flykten om ni inte också behåller det ursprungliga som ett separat fält (till exempel parent_correlation_id). Om ni byter ID, tappar support den enda tråden som knyter ihop historien.
Propagation missas ofta på några förutsägbara ställen: bakgrundsjobb som startas under förfrågan, retries i klientbibliotek, webhooks som triggas senare och fan-out-anrop. Alla asynkrona meddelanden (kö/jobb) bör bära ID:t, och all retry-logik bör bevara det.
Loggar bör vara strukturerade med ett stabilt fältnamn som correlation_id. Välj en stavning och håll den överallt. Undvik att blanda requestId, req_id och traceId om ni inte också definierar en tydlig mappning.
Om möjligt, inkludera ID:t även i databas-synlighet. Ett praktiskt sätt är att lägga det i query-kommentarer eller session-metadata så slow query-loggar kan visa det. När någon rapporterar "Spara-knappen hängde i 10 sekunder" kan support söka correlation_id=abc123 och se API-logg, nedströmsanrop och den långsamma SQL-frågan som orsakade fördröjningen.
Inkludera ID:t i loggar som människor kan använda
Ett korrelations-ID hjälper bara om människor kan hitta och följa det. Gör det till ett förstaklassigt loggfält (inte nedgrävt i ett meddelande) och håll resten av loggposten konsekvent över tjänster.
Loggfält som gör ID:t användbart
Para korrelations-ID med ett litet set fält som svarar på: när, var, vad och vem (på ett användarsäkert sätt). För de flesta team betyder det:
timestamp (med tidszon)service och env (api, worker, prod, staging)route (eller operation-namn) och methodstatus och duration_ms- en användarsäker identifierare (till exempel
account_id eller ett hashat user id, inte en e-post)
Med detta kan support söka efter ID, bekräfta att de tittar på rätt förfrågan och se vilken tjänst som hanterade den.
Vad som bör loggas vid start, lyckat och fel
Sikta på några starka breadcrumbs per förfrågan, inte en fullständig transkription.
- Start: korrelations-ID, route, användarsäker identifierare och nyckelinputs (sammanfattade).
- Lyckat: korrelations-ID, status, duration och ett kort resultat (till exempel
rows=12).
- Fel: korrelations-ID, feltyp, säker kontext och var det hände (handler, dependency).
För att undvika bullriga loggar, håll debug-nivådetaljer avstängt som standard och markera endast händelser som hjälper någon att svara på "Var gick det fel?". Om en loggrad inte hjälper att lokalisera problemet eller mäta påverkan, hör den troligen inte hemma på info-nivå.
Redigering är lika viktig som struktur. Lägg aldrig PII i korrelations-ID eller loggar: inga e-postadresser, namn, telefonnummer, fullständiga adresser eller råa tokens. Om ni behöver identifiera en användare, logga ett internt ID eller en envägs-hash.
Exempel: spåra en användarrapport från UI till databas
Bake correlation IDs into your app
Use Koder.ai Planning Mode to standardize headers and logs from day one.
En användare skriver till support: "Checkout misslyckades när jag klickade Betala." Den bästa följdfrågan är enkel: "Kan du klistra in korrelations-ID:t som visas på felsidan?" De svarar med cid=9f3c2b1f6a7a4c2f.
Support har nu ett handtag som kopplar ihop UI, API och databasarbete. Målet är att varje loggrad för den åtgärden bär samma ID.
Support söker i loggar efter 9f3c2b1f6a7a4c2f och ser flödet:
frontend INFO cid=9f3c2b1f6a7a4c2f event="checkout_submit" cart=3 items
api INFO cid=9f3c2b1f6a7a4c2f method=POST path=/api/checkout user=1842
api ERROR cid=9f3c2b1f6a7a4c2f msg="payment failed" provider=stripe status=502
Därifrån följer en ingenjör samma ID in i nästa hopp. Nyckeln är att backend-anrop (och alla köjobb) också vidarebefordrar ID:t.
payments INFO cid=9f3c2b1f6a7a4c2f action="charge" amount=49.00 currency=USD
payments ERROR cid=9f3c2b1f6a7a4c2f err="timeout" upstream=stripe timeout_ms=3000
db INFO cid=9f3c2b1f6a7a4c2f query="insert into failed_payments" rows=1
Nu är problemet konkret: payments-tjänsten timeoutade efter 3 sekunder och en failure-post skrevs. Ingenjören kan kolla senaste deploys, bekräfta om timeout-inställningar ändrats och se om retries körs.
För att stänga loopen, gör fyra kontroller:
- Åtgärda orsaken (till exempel justera timeout och lägg till en säker retry).
- Se till att användarvända fel inkluderar korrelations-ID.
- Bevaka nya loggar med samma felmönster och olika ID:n.
- Bekräfta att ID:t överlever varje hopp (inklusive workers och kömeddelanden).
Vanliga misstag och hur man undviker dem
Det snabbaste sättet att göra korrelations-ID oanvändbara är att bryta kedjan. De flesta fel kommer från små beslut som känns ofarliga när ni bygger, men som skadar när support behöver svar.
Ett klassiskt misstag är att generera ett nytt ID vid varje hopp. Om webbläsaren skickar ett ID, bör er API-gateway behålla det, inte ersätta det. Om ni verkligen behöver ett internt ID också (för ett kömeddelande eller bakgrundsjobb), behåll det ursprungliga som ett parent-fält så historien fortfarande hänger ihop.
En annan vanlig lucka är partiell loggning. Teamet lägger till ID:t i första API:t, men glömmer det i worker-processer, schemalagda jobb eller databasåtkomstlagret. Resultatet blir en återvändsgränd: ni ser förfrågan in i systemet men inte vart den gick härnäst.
Undvik problemet med "namnkaos"
Även när ID:t finns överallt kan det vara svårt att söka om varje tjänst använder ett annat fältnamn eller format. Välj ett namn och håll er till det över frontend, API:er och loggar (till exempel correlation_id). Välj också ett format (ofta en UUID) och behandla det som case-sensitivt så copy-paste fungerar.
Förlora inte ID:t när saker går fel. Om en API returnerar 500 eller ett valideringsfel, inkludera korrelations-ID:t i felresponser (och helst även i response-headern). Då kan en användare klistra in det i en supportchatt och teamet kan omedelbart spåra hela vägen.
Ett snabbt test: kan en supportperson börja med ett ID och följa det genom varje involverad loggrad, inklusive fel? Om inte, hitta första gapet och fixa det.
Snabb checklista för att verifiera end-to-end-täckning
Set a reliable API entry policy
Generate gateway logic that accepts, validates, and echoes X-Correlation-ID automatically.
Använd detta som en enkel kontroll innan ni säger till support att "bara sök i loggarna." Det här fungerar bara när varje hopp följer samma regler.
Måste-passer kontroller
- Ni har ett ID-format och ett header-namn, använda överallt (frontend, gateway, API:er, workers).
- Frontend skapar (eller tar emot) ID:t i början av en användaråtgärd och håller det stabilt tills åtgärden är klart.
- Er API-entrypoint skapar ett ID om det saknas och returnerar det alltid i response-headers.
- Varje backend-tjänst inkluderar
correlation_id i request-relaterade loggar som ett strukturerat fält.
- On-call kan klistra in ett ID i loggsök och se hela vägen inom några minuter: edge request, auth, service-anrop, databasoperation och retries.
Om någon kontroll misslyckas, fixa så här
Välj den minsta ändringen som håller kedjan obruten.
- Om ID:n ändras mitt i flykten, sluta generera nya ID:n i interna tjänster. Behåll det ursprungliga
correlation_id och lägg till en separat span_id om ni behöver mer detalj.
- Om loggar saknar fältet, lägg till logging-middleware så ingenjörerna inte måste komma ihåg att inkludera det.
- Om support inte får tag på ID:t, se till att UI visar det på felsidor och att gateway ekonterar det i varje svar.
Ett snabbt test som fångar luckor: öppna devtools, trigga en åtgärd, kopiera korrelations-ID:t från första förfrågan, och bekräfta att du ser samma värde i varje relaterad API-förfrågan och varje tillhörande loggrad.
Nästa steg: baka in det i er shipping-process
Korrelations-ID hjälper bara när alla använder dem på samma sätt, varje gång. Behandla korrelations-ID-beteende som en obligatorisk del av att leverera, inte som en trevlig loggförbättring.
Lägg till ett litet spårbarhetssteg i er definition of done för varje ny endpoint eller UI-åtgärd. Täck hur ID:t skapas (eller återanvänds), var det lever under flödet, vilken header som bär det och vad varje tjänst gör när headern saknas.
En lättviktig checklista räcker oftast:
- Frontend: generera eller återanvänd ett ID per användaråtgärd och bifoga det till varje API-anrop för den åtgärden.
- API-entrypoint: acceptera headern, validera eller generera, och ekontera den i svaret.
- Backend: skicka vidare till downstream-tjänster och jobb, och inkludera det i loggar.
- Loggning: håll fältnamnet konsekvent (till exempel
correlation_id) över appar och tjänster.
- Granskningar: avvisa PR:er som lägger till endpoints utan tester som bevisar att ID:t syns i loggar.
Support behöver också ett enkelt skript så felsökning blir snabb och repeterbar. Bestäm var ID:t syns för användare (till exempel en "Kopiera debug-ID"-knapp i felrutor) och skriv ner vad support ska be om och var de ska söka.
Innan ni litar på det i produktion, kör ett stagat flöde som matchar verklig användning: klicka en knapp, trigga ett valideringsfel, och slutför sedan åtgärden. Bekräfta att ni kan följa samma ID från webbläsarförfrågan, genom API-loggar, in i eventuella bakgrundsworkers och upp till databasens loggar om ni spelar in dem.
Om ni bygger appar på Koder.ai hjälper det att skriva era korrelations-ID-header- och loggkonventioner i Planning Mode så genererade React-frontends och Go-tjänster blir konsekventa från början.