31 okt. 2025·8 min
Joe Bedas tidiga Kubernetes-beslut som formade plattformar
En tydlig genomgång av Joe Bedas tidiga Kubernetes-val—deklarativa API:er, control loops, Pods, Services och labels—och hur de formade moderna applikationsplattformar.
En tydlig genomgång av Joe Bedas tidiga Kubernetes-val—deklarativa API:er, control loops, Pods, Services och labels—och hur de formade moderna applikationsplattformar.
Joe Beda var en av de viktigaste personerna bakom Kubernetess tidiga design—tillsammans med andra grundare som tog med sig erfarenheter från Googles interna system till en öppen plattform. Hans inflytande handlade inte om att jaga trendiga funktioner; det handlade om att välja enkla primitiva byggstenar som kunde överleva verklig produktionskaos och fortfarande vara begripliga för vanliga team.
Dessa tidiga beslut är anledningen till att Kubernetes blev mer än “ett containerverktyg.” Det förvandlades till en återanvändbar kärna för moderna applikationsplattformar.
“Container orchestration” är mängden regler och automation som håller din app igång när maskiner misslyckas, trafiken ökar eller du deployar en ny version. Istället för att en människa vakar över servrar schemalägger systemet containers på datorer, startar om dem när de kraschar, sprider ut dem för tålighet och kopplar upp nätverk så användare når dem.
Innan Kubernetes blev vanligt sydde team ofta ihop skript och egna verktyg för att svara på grundläggande frågor:
De här DIY-systemen fungerade—tills de inte gjorde det längre. Varje ny app eller team lade till mer engångslogik, och operativ konsekvens blev svår att uppnå.
Denna artikel går igenom tidiga Kubernetes-designval (Kubernetes “form”) och varför de fortfarande påverkar moderna plattformar: den deklarativa modellen, controllers, Pods, labels, Services, ett starkt API, konsekvent kluster-tillstånd, pluggbar schemaläggning och extensibilitet. Även om du inte kör Kubernetes direkt använder du sannolikt en plattform byggd på dessa idéer—eller kämpar med samma problem.
Före Kubernetes innebar “köra containers” oftast att köra några få containers. Team sydde ihop bash-skript, cron-jobb, golden images och ett fåtal ad-hoc-verktyg för att få saker deployade. När något gick sönder levde lösningen ofta i någons huvud—eller i en README som ingen litade på. Drift var en ström av engångsinsatser: starta om processer, peka om load balancers, rensa disk och gissa vilken maskin som var säker att röra.
Containers gjorde paketering enklare, men de tog inte bort de röriga delarna av produktion. I skala fallerar systemet på fler sätt och oftare: noder försvinner, nätverk partitioneras, images rullas ut inkonsekvent och arbetslaster driver bort från vad du tror körs. En “enkel” deploy kan bli en kaskad—vissa instanser uppdaterade, vissa inte, några fastnar, andra friska men otillgängliga.
Det verkliga problemet var inte att starta containers. Det var att hålla de rätta containrarna igång, i rätt form, trots ständig churn.
Team jonglerade också olika miljöer: on‑prem hårdvara, VMer, tidiga molnleverantörer och olika nätverks- och lagringsupplägg. Varje plattform hade sitt eget vokabulär och fellägen. Utan en gemensam modell innebar varje migrering att operativa verktyg behövde skrivas om och folk behövde omskolas.
Kubernetes ville erbjuda ett enda, konsekvent sätt att beskriva applikationer och deras driftbehov, oavsett var maskinerna stod.
Utvecklare ville självbetjäning: deploya utan ticket, skala utan att be om kapacitet och rulla tillbaka utan dramatik. Ops-team ville förutsägbarhet: standardiserade hälsokontroller, repeterbara distributioner och en tydlig sanningskälla för vad som borde köra.
Kubernetes försökte inte vara en fin scheduler. Målet var att vara grunden för en pålitlig applikationsplattform—en som gör rörig verklighet till ett system du kan resonera om.
Ett av de mest inflytelserika tidiga valen var att göra Kubernetes deklarativt: du beskriver vad du vill ha, och systemet arbetar för att få verkligheten att matcha den beskrivningen.
En termostat är ett användbart vardagligt exempel. Du vrider inte värmaren av och på manuellt var femte minut. Du ställer in en önskad temperatur—säg 21°C—och termostaten kontrollerar rummet och justerar värmen för att hålla sig nära målet.
Kubernetes fungerar på samma sätt. Istället för att säga åt klustret steg för steg “starta den här containern på den maskinen, starta om den om den kraschar”, deklarerar du resultatet: “jag vill ha 3 kopior av den här appen körandes.” Kubernetes kontrollerar kontinuerligt vad som faktiskt körs och korrigerar drift.
Deklarativ konfiguration minskar den dolda “ops-checklistan” som ofta lever i någons huvud eller i en halvuppdaterad runbook. Du applicerar konfigurationen och Kubernetes hanterar mekaniken—placering, omstarter och att rekonciliera ändringar.
Det gör också förändringsgranskning enklare. En förändring syns som en diff i konfigurationen, inte som en serie ad-hoc-kommandon.
Eftersom det önskade tillståndet är nedskrivet kan du återanvända samma tillvägagångssätt i dev, staging och production. Miljön kan skilja sig åt, men avsikten förblir konsekvent, vilket gör distributioner mer förutsägbara och lättare att granska.
Deklarativa system har en inlärningskurva: du behöver tänka i “vad ska vara sant” snarare än “vad gör jag härnäst.” De beror också starkt på bra standarder och tydliga konventioner—utan dem kan team producera konfigurationer som tekniskt fungerar men som är svåra att förstå och underhålla.
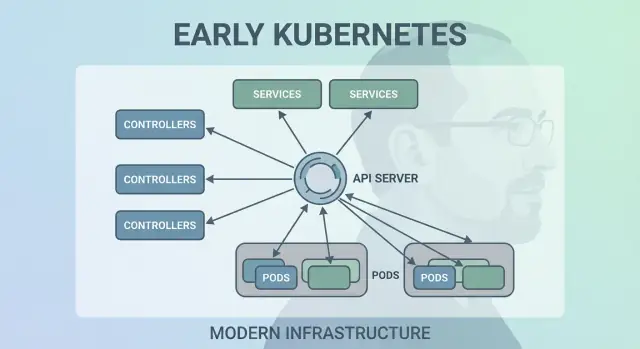
Kubernetes lyckades inte för att det kunde köra containers en gång—det lyckades för att det kunde hålla dem körande korrekt över tid. Det stora designgreppet var att göra “control loops” (controllers) till systemets kärna.
En controller är en enkel loop:
Det är mindre som en engångsuppgift och mer som autopilot. Du behöver inte “vaka” arbetslaster; du deklarerar vad du vill ha och controllers styr klustret tillbaka mot det målet.
Detta mönster är anledningen till att Kubernetes är resilient när verkliga problem uppstår:
Istället för att betrakta fel som specialfall behandlar controllers dem som rutinmässiga “tillståndsskillnader” och fixar dem på samma sätt varje gång.
Traditionella automationsskript antar ofta en stabil miljö: kör steg A, sedan B, sedan C. I distribuerade system bryts de antagandena ständigt. Controllers skalar bättre eftersom de är idempotenta (säkra att köra upprepade gånger) och eventually consistent (de fortsätter försöka tills målet är uppnått).
Om du använt en Deployment har du förlitat dig på control loops. Under huven använder Kubernetes en ReplicaSet-controller för att säkerställa att det begärda antalet pods finns—och en Deployment-controller för att hantera rullande uppdateringar och rollbacks på ett förutsägbart sätt.
Kubernetes hade kunnat schemalägga “bara containers”, men Joe Bedas team introducerade Pods för att representera den minsta deploybara enheten klustret placerar på en maskin. Nyckelidén: många riktiga applikationer är inte en enda process. De är en liten grupp tätt kopplade processer som måste leva tillsammans.
En Pod är ett omslag runt en eller flera containers som delar samma öde: de startar tillsammans, kör på samma nod och skalas tillsammans. Det gör mönster som sidecars naturliga—tänk en logg-skipper, proxy, konfigläsare eller säkerhetsagent som alltid ska följa huvudappen.
Istället för att lära varje app att integrera dessa hjälpare låter Kubernetes dig paketera dem som separata containers som ändå beter sig som en enhet.
Pods gjorde två viktiga antaganden praktiska:
localhost, vilket är enkelt och snabbt.Dessa val minskade behovet av anpassningskod samtidigt som containrar hölls isolerade på processnivå.
Nya användare förväntar sig ofta “en container = en app” och snubblar över Pod-koncept: omstarter, IP:er och skalning. Många plattformar dämpar detta genom att erbjuda opinionsstyrda mallar (till exempel “web service”, “worker” eller “job”) som genererar Pods bakom kulisserna—så teamen får fördelarna med sidecars och delade resurser utan att behöva tänka på Pod-mekanik varje dag.
Ett tyst kraftfullt tidigt val i Kubernetes var att behandla labels som förstaklass-metadat och selectors som huvudsättet att “hitta” saker. Istället för att hårdkoda relationer (till exempel “dessa exakta tre maskiner kör min app”) uppmuntrar Kubernetes dig att beskriva grupper med gemensamma attribut.
En label är ett enkelt nyckel/värde-par du fäster på resurser—Pods, Deployments, Nodes, Namespaces och mer. De fungerar som konsekventa, sökbara “taggar”:
app=checkoutenv=prodtier=frontendEftersom labels är lätta och användardefinierade kan du modellera din organisations verklighet: team, kostnadscentra, efterlevnadszoner, release-kanaler eller vad som än är viktigt för er drift.
Selectors är frågor över labels (till exempel “alla Pods där app=checkout och env=prod”). Detta slår fast hostlistor eftersom systemet kan anpassa sig när Pods rescheduleras, skalas upp/ner eller ersätts under rollout. Din konfiguration förblir stabil även när underliggande instanser ständigt ändras.
Denna design skalar operativt: du hanterar inte tusentals instansidentiteter—du hanterar ett fåtal meningsfulla label-set. Det är kärnan i lös koppling: komponenter kopplar till grupper vars medlemskap säkert kan ändras.
När labels finns blir de ett gemensamt vokabulär över plattformen. De används för trafikstyrning (Services), policygränser (NetworkPolicy), filtrering i observabilitet (metrics/loggar) och till och med kostnadsspårning. En enkel idé—tagga saker konsekvent—öppnar ett helt ekosystem av automation.
Kubernetes behövde ett sätt att få nätverk att kännas förutsägbart även om containers är allt annat än det. Pods ersätts, rescheduleras och skalas upp och ner—så deras IP:er och de specifika maskinerna de körs på ändras. Kärnideen i en Service är enkel: ge en stabil “entré” till en skiftande mängd Pods.
En Service ger dig en konsekvent virtuell IP och DNS-namn (som payments). Bakom det namnet spårar Kubernetes kontinuerligt vilka Pods som matchar Service:ns selector och routar trafiken därefter. Om en Pod dör och en ny dyker upp pekar Service fortfarande till rätt plats utan att du behöver ändra appinställningar.
Detta tog bort mycket manuell koppling. Istället för att baka in IP:er i konfigfiler kan appar lita på namn. Du deployar appen, deployar Service och andra komponenter kan hitta den via DNS—ingen specialbyggd registertjänst behövs, inga hårdkodade endpoints.
Services introducerade också standardbeteende för lastfördelning över hälsosamma endpoints. Det innebar att team inte behövde bygga (eller återskapa) egna lastbalanserare för varje intern mikrotjänst. Att sprida trafiken minskar blast-radien för en enskild Pod-fel och gör rullande uppdateringar mindre riskfyllda.
En Service är utmärkt för L4-trafik (TCP/UDP), men den modellerar inte HTTP-routingregler, TLS-termination eller edge-policyer. Där kommer Ingress och, alltmer, Gateway API in: de bygger på Services för att hantera hostnamn, paths och externa ingångspunkter mer tydligt.
Ett av de tyst radikala tidiga valen var att behandla Kubernetes som ett API man byggde mot—inte ett monolitiskt verktyg du “använder”. Denna API-första hållning gjorde Kubernetes mindre som en produkt man klickar i och mer som en plattform man kan bygga ut, skripta och styra.
När API:et är ytan kan plattformsteam standardisera hur applikationer beskrivs och hanteras, oavsett vilken UI, pipeline eller intern portal som ligger ovanpå. “Att deploya en app” blir att “skicka in och uppdatera API-objekt” (som Deployments, Services och ConfigMaps), vilket är ett mycket renare kontrakt mellan applikationsteam och plattform.
Eftersom allt går genom samma API behöver nya verktyg inga privilegierade bakvägar. Dashboards, GitOps-controllers, policy-motorer och CI/CD-system kan alla agera som vanliga API-klienter med väldefinierade rättigheter.
Denna symmetri spelar roll: samma regler, auth, auditing och admission-kontroller gäller oavsett om begäran kom från en person, ett skript eller en intern plattforms-UI.
API-versionering gjorde det möjligt att utveckla Kubernetes utan att bryta varje kluster eller varje verktyg över en natt. Deprecations kan fasas; kompatibilitet kan testas; uppgraderingar kan planeras. För organisationer som kör kluster i åratal är detta skillnaden mellan “vi kan uppgradera” och “vi sitter fast”.
kubectl egentligen representerarkubectl är inte Kubernetes—det är en klient. Denna mentala modell får team att tänka i API-arbetsflöden: du kan byta ut kubectl mot automation, ett webb-UI eller en egen portal, och systemet förblir konsekvent eftersom kontraktet är API:et självt.
Kubernetes behövde en enda “sanningskälla” för hur klustret borde se ut just nu: vilka Pods som finns, vilka noder som är friska, vad Services pekar på och vilka objekt som uppdateras. Det är vad etcd levererar.
etcd är databasen för kontrollplanet. När du skapar en Deployment, skalar en ReplicaSet eller uppdaterar en Service skrivs den önskade konfigurationen till etcd. Controllers och andra kontrollplanskomponenter bevakar sedan det lagrade tillståndet och arbetar för att få verkligheten att matcha.
Ett Kubernetes-kluster är fullt av rörliga delar: schedulers, controllers, kubelets, autoscalers och admissions-kontroller kan alla reagera samtidigt. Om de läser olika versioner av “sanningen” får du race-conditions—som två komponenter som fattar motstridiga beslut om samma Pod.
etcds starka konsistens säkerställer att när kontrollplanet säger “detta är aktuellt tillstånd” så är alla enade. Denna samordning är vad som gör control loops förutsägbara istället för kaotiska.
Eftersom etcd håller klustrets konfiguration och historia över ändringar är det också det du skyddar under:
Behandla kontrollplanes tillstånd som kritisk data. Ta regelbundna etcd-snapshots, testa återställningar och lagra backups utanför klustret. Om du använder managed Kubernetes, lär dig vad din leverantör backar upp—och vad du fortfarande behöver backa upp själv (t.ex. persistenta volymer och applikationsdata).
Kubernetes behandlade inte “var en arbetslast körs” som en eftertanke. Tidigt var scheduler en separat komponent med ett tydligt jobb: matcha Pods till noder som faktiskt kan köra dem, med hjälp av klustrets aktuella tillstånd och Pod:ens krav.
På en hög nivå är schemaläggning en tvåstegsbeslut:
Denna struktur gjorde det möjligt att utveckla Kubernetes-schemaläggning utan att skriva om allt.
Ett viktigt designval var att hålla ansvar rena:
Eftersom dessa ansvar är separata behöver förbättringar i ett område (säg en ny CNI-plugin) inte tvinga fram en ny schemaläggningsmodell.
Resursmedvetenhet började med requests och limits, vilket gav schedulern meningsfulla signaler istället för gissningar. Därifrån lade Kubernetes till rikare kontroller—node affinity/anti-affinity, pod affinity, priorities and preemption, taints and tolerations och topology-aware spreading—byggt på samma grund.
Detta tillvägagångssätt möjliggör dagens delade kluster: team kan isolera kritiska tjänster med prioriteringar och taints, samtidigt som alla drar nytta av högre utnyttjandegrad. Med bättre bin-packing och topologikontroller kan plattformar placera arbetslaster mer kostnadseffektivt utan att offra pålitlighet.
Kubernetes kunde ha skickats som en full, opinionsstyrd plattformupplevelse—buildpacks, app-routing, bakgrundsjobb, config-konventioner med mera. Istället höll Joe Beda och det tidiga teamet kärnan fokuserad på ett mindre löfte: kör och heala arbetslaster pålitligt, exponera dem och ge ett konsekvent API att automatisera mot.
En “komplett PaaS” skulle ha tvingat ett arbetsflöde och en uppsättning kompromisser på alla. Kubernetes siktade på en bredare grund som kunde stödja många plattformsstilar—Heroku-lik enkelhet, företagsstyrning, batch- och ML-pipelines eller låg nivå-infrastrukturkontroll—utan att låsa in en enda produktfilosofi.
Kubernetes extensibilitetsmekanismer skapade ett kontrollerat sätt att växa funktionalitet:
Certificate eller Database) som känns och ser ut som inbyggda typer.Detta betyder att interna plattformsteam och leverantörer kan leverera funktioner som tillägg, samtidigt som de använder Kubernetes-primitiver som RBAC, namespaces och audit-loggar.
För leverantörer möjliggör det differentierade produkter utan att fork:a Kubernetes. För interna team möjliggörs en “plattform på Kubernetes” anpassad efter organisationens behov.
Trade-offen är spretighet i ekosystemet: för många CRDs, överlappande verktyg och inkonsekventa konventioner. Styrning—standarder, ägarskap, versionering och deprecationsregler—blir en del av plattformsarbetet.
Kubernetes tidiga val skapade inte bara en container-scheduler—de skapade en återanvändbar plattformkärna. Därför är så många moderna interna utvecklarplattformar (IDP) i grunden “Kubernetes plus opinionerade arbetsflöden.” Den deklarativa modellen, controllers och ett konsekvent API gjorde det möjligt att bygga högre nivå-produkter—utan att behöva återuppfinna distribution, rekonciliering och service discovery varje gång.
Eftersom API:et är produktytan kan leverantörer och plattformsteam standardisera på ett kontrollplan och bygga olika upplevelser ovanpå: GitOps, multi-cluster-hantering, policy, service-kataloger och deployments-automation. Det är en stor anledning till att Kubernetes blev gemensam nämnare för cloud native-plattformar: integrationer riktar sig mot API:et, inte mot ett specifikt UI.
Även med rena abstraktioner är det svåraste arbetet fortfarande operationellt:
Ställ frågor som avslöjar operativ mognad:
En bra plattform minskar kognitiv belastning utan att dölja underliggande kontrollplan eller göra nödutgångar smärtsamma.
En praktisk lins: hjälper plattformen team att gå från “idé → körande tjänst” utan att tvinga alla att bli Kubernetes-experter dag ett? Verktyg i “vibe-coding”-kategorin—som Koder.ai—lutande sig in i detta genom att låta team generera riktiga applikationer från chatt (web i React, backend i Go med PostgreSQL, mobil i Flutter) och sedan iterera snabbt med funktioner som planning mode, snapshots och rollback. Oavsett om du antar något sådant eller bygger din egen portal är målet detsamma: bevara Kubernetess starka primitiva byggstenar samtidigt som du minskar arbetsflödesöverhead runt dem.
Kubernetes kan kännas komplext, men det mesta av dess “konstigheter” är avsiktligt: det är en uppsättning små primitiva element designade för att komponera många slags plattformar.
För det första: “Kubernetes är bara Docker-orchestration.” Kubernetes handlar inte främst om att starta containers. Det handlar om att kontinuerligt rekonciliera önskat tillstånd (vad du vill ha igång) med aktuellt tillstånd (vad som verkligen händer), över fel, rollouter och förändrad belastning.
För det andra: “Om vi använder Kubernetes blir allt mikrotjänster.” Kubernetes stödjer mikrotjänster, men stöder också monoliter, batchjobb och interna plattformar. Enheterna (Pods, Services, labels, controllers och API:et) är neutrala; dina arkitekturval dikteras inte av verktyget.
De svåra delarna är vanligtvis inte YAML eller Pods—det är nätverk, säkerhet och multi-team-användning: identitet och åtkomst, secrets-hantering, policyer, ingress, observabilitet, försörjningskedjekontroller och att skapa guardrails så team kan leverera säkert utan att trampa på varandra.
När du planerar, tänk i termer av de ursprungliga designvalen:
Karta dina verkliga krav mot Kubernetes-primitiver och plattforms-lager:
Arbetslaster → Pods/Deployments/Jobs
Anslutning → Services/Ingress
Drift → controllers, policyer och observabilitet
Om du utvärderar eller standardiserar, skriv ner denna mappning och granska den med intressenter—bygg sedan din plattform stegvis kring luckorna, inte kring trender.
Om du också försöker snabba upp “build”-sidan (inte bara “run”-sidan), fundera på hur ditt leveransflöde förvandlar avsikt till deploybara tjänster. För vissa team är det en kurerad uppsättning mallar; för andra är det ett AI-assisterat arbetsflöde som Koder.ai som kan producera en initial fungerande tjänst snabbt och sedan exportera källkod för djupare anpassning—samtidigt som din plattform fortfarande drar nytta av Kubernetess kärnbeslut under ytan.
Container-orchestration är den automation som håller appar igång när maskiner fallerar, trafiken förändras eller när distributioner sker. I praktiken hanterar det:
Kubernetes populariserade en konsekvent modell för att göra detta över olika infrastrukturer.
Huvudproblemet var inte att starta containers—det var att hålla de rätta containrarna igång i rätt form trots ständig förändring. I skala får du rutinmässiga fel och drift:
Kubernetes ville göra driften upprepningsbar och förutsägbar genom att erbjuda ett standardiserat kontrollplan och vokabulär.
I ett deklarativt system beskriver du det resultat du vill ha (till exempel “kör 3 repliker”), och systemet arbetar kontinuerligt för att få verkligheten att matcha.
Praktiskt arbetsflöde:
kubectl apply eller GitOps)Detta minskar “dolda runbooks” och gör ändringar granskningsbara som diffs istället för ad-hoc-kommandon.
Controllers är kontroll-loopar som upprepade gånger:
Den designen gör vanliga fel rutinmässiga istället för specialfall. Till exempel, om en Pod kraschar eller en nod försvinner, märker relevant controller helt enkelt “vi har färre repliker än önskat” och skapar ersättningar.
Kubernetes schemalägger Pods (inte enskilda containers) eftersom många verkliga arbetslaster behöver tätt sammankopplade hjälpprocesser.
Pods möjliggör mönster som:
localhost)Tumregel: håll Pods små och kohesiva—gruppera bara containrar som måste dela livscykel, nätverksidentitet eller lokal data.
Labels är lätta nyckel/värde-taggar (till exempel app=checkout, env=prod). Selectors är frågor över dessa labels för att bilda dynamiska grupper.
Detta är viktigt eftersom instanser är flyktiga: Pods kommer och går under rescheduleringar och rollouter. Med labels/selectors förblir relationer stabila (“alla Pods med dessa labels”) även när medlemmarna ändras.
Operationellt tips: standardisera en liten label-taxonomi (app, team, env, tier) och tvinga den med policy för att undvika kaos senare.
En Service ger en stabil virtuell IP och DNS-namn som routar till en förändrande uppsättning Pods som matchar en selector.
Använd en Service när:
För HTTP-routing, TLS-termination och edge-regler bygger man vanligtvis Ingress eller Gateway API ovanpå Services.
Kubernetes behandlar API:et som den primära produktytan: allt är API-objekt (Deployments, Services, ConfigMaps, osv.). Verktyg—inklusive kubectl, CI/CD, GitOps och dashboards—är bara API-klienter.
Praktiska fördelar:
Om du bygger en intern plattform, designa arbetsflöden kring API-kontrakt, inte kring ett specifikt UI-verktyg.
etcd är kontrollplanets databas och klustrets sanning om önskat och aktuellt tillstånd. Controllers och andra komponenter bevakar etcd och rekoncilierar baserat på det tillståndet.
Praktiska råd:
I managed Kubernetes: lär dig vad din leverantör backar upp—och vad du fortfarande måste skydda själv (t.ex. persistenta volymer och applikationsdata).
Kubernetes håller kärnan liten och låter dig lägga till funktionalitet via extensioner:
Detta möjliggör “plattform på Kubernetes”, men kan leda till verktygsspridning. För att utvärdera en Kubernetes-baserad plattform, fråga: