10 nov. 2025·8 min
Hur du bygger en webbplats för din produkt‑experimentlogg
Lär dig planera, designa och lansera en webbplats som dokumenterar produktexperiment med konsekventa poster, taggning, sök och tydliga resultat.
Lär dig planera, designa och lansera en webbplats som dokumenterar produktexperiment med konsekventa poster, taggning, sök och tydliga resultat.
En produkt-experimentlogg är en gemensam plats för att dokumentera varje experiment ert team kör—A/B-tester, prismodeller, justeringar av onboarding, feature-flaggor, e-posttester och till och med ”misslyckade” idéer som ändå gav insikter. Tänk på den som ett experimentarkiv och en produktlärande-logg i ett: en redogörelse för vad ni provade, varför ni gjorde det, vad som hände och vad ni beslutade efteråt.
De flesta team har redan fragmenterad experimentspårning utspridd i dokument, dashboards och chattrådar. En dedikerad spårningssajt samlar dessa artefakter i en enda, navigerbar historik.
De praktiska effekterna är:
Denna guide fokuserar på hur du bygger en webbplats som gör experimentdokumentation enkel att skapa och lätt att använda. Vi går igenom hur du planerar struktur och navigation, definierar ett datamodell för experimentposter (så poster förblir konsekventa), skapar läsbara sidmallar, sätter upp taggning och sökning för snabb upptäckt, och väljer rätt implementeringsstrategi (CMS vs anpassad app).
I slutändan har du en tydlig plan för en dokumentationssajt för A/B-tester som stödjer det dagliga produktarbetet—fångar hypoteser, mätvärden och resultatrapportering, samt beslut på ett sätt som är sökbart, trovärdigt och användbart över tid.
Innan du väljer verktyg eller designar experimentmallar, var tydlig med varför den här experimentlogg-webbplatsen finns och vem den tjänar. En produkt-experimentlogg är bara användbar om den matchar hur era team faktiskt fattar beslut.
Skriv ner 2–4 mätbara utfall för experimentarkivet. Vanliga definitioner av framgång inkluderar:
Dessa mål bör påverka allt senare: vilka fält du kräver i varje post, hur strikt ditt arbetsflöde är och hur avancerad din taggning och sökning behöver vara.
Lista era primära målgrupper och vad de behöver göra i produktlärande-loggen:
Ett enkelt sätt att validera detta: fråga varje grupp, “Vilken fråga vill du få besvarad på 30 sekunder?” och se till att era mallar och sidlayout stödjer det.
Bestäm tidigt om er CMS för experimentloggar ska vara:
Om ni väljer blandat, definiera vad som är tillåtet i publika poster (t.ex. inga råa mätvärden, anonymiserade segment, inga unreleasade funktionsnamn) och vem som godkänner publicering. Det förhindrar omarbete senare när teamet vill dela lärdomar externt.
En produkt-experimentlogg fungerar bara om folk kan hitta rätt experiment på under en minut. Innan du väljer verktyg eller designar skärmar, bestäm hur någon kommer att bläddra i er experimentlogg när de inte vet vad de söker efter.
Håll huvudnavigeringen begränsad och förutsägbar. Ett praktiskt startförslag är:
Om “Metrics” känns tungt kan du länka till det från Experiments i början och utöka senare.
Bestäm den huvudsakliga “formen” för bläddring. De flesta produktlärande-loggar fungerar bäst med en primär vy och resten hanteras av filter:
Välj den som era intressenter redan använder i samtal. Allt annat kan vara taggar (t.ex. plattform, hypotes-tema, segment, experimenttyp).
Gör URL:er läsbara och stabila så folk kan dela dem i Slack och tickets:
/experiments/2025-12-checkout-free-shipping-thresholdLägg till breadcrumbs som Experiments → Checkout → Free shipping threshold för att undvika döda ändar och göra det lätt att skumma.
Lista vad ni publicerar dag ett kontra senare: senaste experiment, topp-playbooks, en kärn-metrics-glossar och team-sidor. Prioritera poster som kommer att refereras ofta (högpåverkande tester, kanoniska experimentmallar och mätdefinitionsposter som används i resultatrapportering).
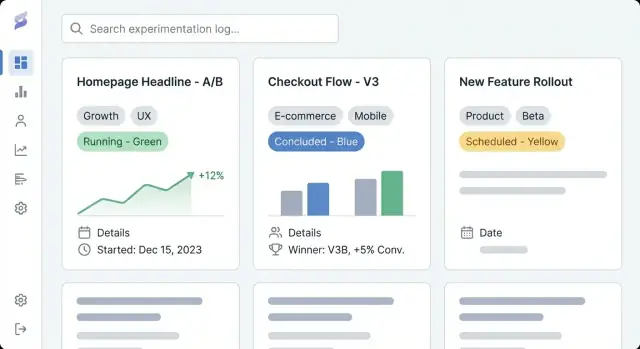
En användbar experimentlogg är inte bara en lista med länkar—det är en databas av lärdomar. Datamodellen är ”formen” på den databasen: vad ni lagrar, hur poster relaterar, och vilka fält som måste finnas så experiment blir jämförbara över tid.
Börja med ett litet set innehållstyper som matchar hur team faktiskt arbetar:
Att hålla dessa separata förhindrar att varje experiment uppfinner nya mätvärdesnamn eller gömmer beslut i fri text.
Gör den “minimala livskraftiga posten” enkel att fylla i. Minst krävs:
Valfria—men ofta värdefulla—fält inkluderar målgrupp, trafikallokering, testtyp (A/B, multivariat) och länkar till tickets eller design.
Resultat är där loggar oftast fallerar, så standardisera dem:
Om ni tillåter bilagor, ha en konsekvent plats för skärmdumpar så läsare vet var de ska titta.
Modellera relationer explicit så upptäckt och rapportering fungerar senare:
Standardisera statusar så sortering och dashboards förblir meningsfulla: proposed, running, concluded, shipped, archived. Detta förhindrar att “done”, “complete” och “finished” blir tre olika tillstånd.
Bra mallar förvandlar ”någon anteckning” till en delad post som hela företaget kan skumma, lita på och återanvända. Målet är konsekvens utan att författare känner att de fyller i byråkrati.
Börja med den information en läsare behöver för att avgöra om de ska läsa vidare.
/docs/...) och primärt mätvärde.Indexsidan bör fungera som en dashboard. Inkludera filter för status, team, tagg, datumintervall och plattform; sortering efter nyligen uppdaterat, startdatum, och (om möjligt att kvantifiera) påverkan; samt snabbläsfält som status, ägare, start/slutdatum och en enradig resultat.
Skapa en standardmall plus valfria varianter (t.ex. “A/B-test”, “Pris-test”, “Onboarding-experiment”). Fyll i rubriker, exempeltext och obligatoriska fält så författare slipper börja från ett tomt papper.
Använd en enkelspralt layout, generös radavstånd och tydlig typografi. Behåll nyckelfakta i en sticky sammanfattningsruta där det är lämpligt, och gör tabeller horisontellt rullbara så resultat förblir läsbara på telefoner.
En produkt-experimentlogg är bara användbar om folk snabbt kan hitta relevanta lärdomar. Taggning och taxonomi förvandlar en hög av experiment-sidor till något du kan bläddra i, filtrera och återanvända.
Definiera ett fåtal taggrupper som matchar hur teamet naturligt söker. Ett praktiskt baseline är:
Håll antalet grupper begränsat. För många dimensioner gör filtrering förvirrande och uppmuntrar inkonsekvent taggning.
Okontrollerade taggar blir snabbt “signup”, “sign-up” och “registration” samtidigt. Skapa ett kontrollerat vokabulär:
Ett enkelt tillvägagångssätt är en “taggregister”-sida som teamet underhåller (t.ex. /experiment-tags) plus lättviktig granskning under experiment-skrivandet.
Taggar är bra för upptäckt, men vissa attribut bör vara strukturerade fält för att hålla konsekvens:
Strukturerade fält driver tillförlitliga filter och dashboards, medan taggar fångar nyans.
Hjälp läsare hoppa mellan kopplat arbete. Lägg till sektioner som Relaterade experiment (samma funktion eller mätvärde) och Liknande hypoteser (samma antagande testat annorstädes). Detta kan göras med manuella länkar först och senare automatiseras med regler för “delade taggar” för att föreslå grannar.
Detta beslut sätter taket för vad din experimentlogg kan bli. Ett CMS får dig publiceringsklart snabbt, medan en anpassad app kan göra loggen till ett tätt integrerat system för beslutsfattande.
Ett CMS passar när ditt huvudbehov är konsekvent, läsbart A/B-testdokumentation med lätt struktur.
Använd ett CMS om du vill ha:
Ett vanligt mönster: ett headless CMS (innehåll lagras i CMS:et, presenteras av din sajt) ihop med en statisk site-generator. Det håller experimentarkivet snabbt, enkelt att hosta och vänligt för icke-tekniska bidragsgivare.
En anpassad experimentspårningssajt är rätt när loggen måste kopplas direkt till produktdata och interna verktyg.
Överväg en anpassad app om du behöver:
Om du vill prototypa snabbt kan en vibe-coding-plattform som Koder.ai vara ett praktiskt genväg: du kan beskriva datamodellen (experiments, metrics, decisions), sidmallar och arbetsflöden i chatten, och sedan iterera på en fungerande React + Go + PostgreSQL-app, med distribution/hosting, export av källkod och snapshots/rollback för säkra ändringar.
Var tydlig med var experimentdata bor.
Skriv ner detta tidigt—annars får ni dubbletter över dokument, kalkylblad och verktyg, och produktlärande-loggen slutar vara betrodd.
Din experimentlogg behöver inte exotisk teknik. Den bästa stacken är den ert team kan drifta tryggt, hålla säker och utveckla utan friktion.
En statisk site (förbyggda sidor) är ofta det enklaste valet: snabb, billig att hosta och låg driftkostnad. Den fungerar bra om experiment mestadels är läsorienterade och uppdateringar sker via ett CMS eller pull requests.
En server-renderad app (sidor genereras vid förfrågan) passar när ni behöver starkare åtkomstkontroll, dynamiska filter eller per-team-vyer utan komplex klientlogik. Det är också enklare att upprätthålla permissions på serversidan.
En single-page app (SPA) kan kännas mycket responsiv för filtrering och dashboards, men ökar komplexiteten kring SEO, autentisering och initial laddning. Välj den bara om ni verkligen behöver applikationslika interaktioner.
Om ni bygger en anpassad app, bestäm också om ni vill ha en konventionell build-pipeline eller ett accelererat tillvägagångssätt. Till exempel kan Koder.ai generera grundskalet (React-UI, Go-API, PostgreSQL-schema) från en skriven specifikation, vilket är användbart när ni itererar på mallar och arbetsflöden med flera intressenter.
Prioritera tillförlitlighet (uptime, övervakning, larm) och backups (automatiserade, testade återställningar). Håll miljöseparation: minst en staging-miljö för att testa taxonomiändringar, malluppdateringar och behörighetsregler innan produktion.
De flesta team behöver förr eller senare SSO (Okta, Google Workspace, Azure AD), plus roller (viewer, editor, admin) och privata områden för känsliga lärdomar (intäkt, användardata, juridiska anteckningar). Planera detta tidigt så ni slipper göra om arkitekturen senare.
Använd caching (CDN och browsercaching), håll sidor lätta och optimera media (komprimerade bilder, lazy loading där lämpligt). Snabb sidladdning är viktigt—folk använder inte en logg som känns långsam, särskilt när de letar efter ett tidigare test under ett möte.
En produkt-experimentlogg blir verkligt användbar när folk kan hitta “det där testet” på sekunder—utan att känna till exakt titel.
On-site-sök (byggt i CMS eller appdatabas) räcker oftast när ni har några hundra experiment, ett litet team och enkla behov som att söka i titlar, sammanfattningar och taggar. Det är lättare att underhålla och undviker extra leverantörsinställning.
En extern söktjänst (som Algolia/Elastic/OpenSearch) är motiverad när ni har tusentals poster, behöver blixtsnabba resultat, stavningskorrigering och synonymer (t.ex. “checkout” = “purchase”), eller avancerad rankning så mest relevanta experiment visas först. Extern sök är också bra om ert innehåll spretar över flera källor (dokument + logg + wiki).
Sök ensam räcker inte. Lägg till filter som speglar verkliga beslutsprocesser:
Gör filtren kombinerbara (t.ex. “Concluded + Senaste 90 dagar + Growth-team + Aktiveringsmätvärde”).
Sparade vyer gör återkommande frågor till ett klick:
Låt team fästa delade vyer i navigationen och låt individer spara personliga vyer.
I sökresultat, visa ett kort utdrag: hypotes, variant, målgrupp och huvudresultat. Markera matchade nyckelord i titel och sammanfattning, och visa några nyckelfält (status, ägare, primärt mätvärde) så användare kan avgöra vad som är värt att öppna utan att klicka på fem sidor.
En bra experimentlogg är inte bara sidor och taggar—det är en delad process. Tydligt ägarskap och ett lättviktigt arbetsflöde förhindrar halvfärdiga poster, saknade resultat och “mystery decisions” månader senare.
Börja med att bestämma vem som kan skapa, redigera, granska och publicera experimentposter. En enkel modell räcker för de flesta team:
Håll behörigheter konsistenta med era åtkomstbeslut (intern vs publik vs begränsad). Om ni stödjer privata experiment, kräva en explicit ägare för varje post.
Definiera en kort checklista som varje experiment måste uppfylla innan publicering:
Denna checklista kan vara ett obligatoriskt formuläravsnitt i era experimentmallar.
Behandla poster som levande dokument. Aktivera versionshistorik och kräva korta ändringsanteckningar för materiella uppdateringar (mätvärdesfix, analyskorrigering, beslutsgenering). Det håller förtroendet högt och gör revision enklare.
Bestäm i förväg hur ni lagrar känslig info:
Styrning behöver inte vara tung—bara explicit.
En experimentlogg är bara användbar om folk hittar, litar på och återanvänder innehållet. Lättviktig analys hjälper dig se varloggen fungerar—och var den tyst misslyckas—utan att förvandla sajten till ett övervakningsverktyg.
Börja med några praktiska signaler:
Om ert analysverktyg tillåter det, undvik IP-loggning och använd inte användarnivåidentifierare. Föredra aggregerad, sidnivårapportering.
Användningsstatistik säger inte om poster är kompletta. Lägg till “innehållshälsokontroller” som rapporterar om arkivet självt:
Detta kan vara en enkel veckorapport från ert CMS/databas eller ett litet skript som flaggar poster. Målet är att göra luckor synliga så ägare kan åtgärda dem.
Experiment-texter bör nästan aldrig innehålla personlig användardata. Håll poster fria från:
Länka till aggregerade dashboards istället för att bädda in råa dataset, och lagra känslig analys i godkända system.
A/B-testresultat är lätta att misstolka ur kontext. Lägg in en kort friskrivning i er experimentmall (och/eller sidfoten) som noterar att:
Detta håller loggen ärlig och minskar oreflekterad återanvändning av tidigare resultat.
En bra experimentlogg är inte “färdig” när sajten går live. Det verkliga värdet syns när team litar på den, håller den aktuell och hittar lärdomar sex månader senare.
De flesta team börjar från kalkylblad, presentationsmaterial eller utspridda dokument. Välj en liten pilotgrupp (t.ex. senaste kvartalets experiment) och mappa varje källfält till er nya mall.
Om möjligt, importera i bulk: exportera kalkylblad till CSV och använd skript eller en CMS-importör för att skapa poster i det nya formatet. För dokument, migrera nyckelsammanfattningarna först (mål, förändring, resultat, beslut) och länka till originalfilen för stödjande detaljer.
Gör en genomgång fokuserad på konsekvens, inte perfektion. Vanliga problem att fånga:
Detta är också ett bra tillfälle att enas om obligatoriska fält för allt som markeras som slutfört.
Innan ni tillkännager, verifiera:
Sätt en lätt rutin: månadsvis städning (stagnanta utkast, saknade resultat) och kvartalsvis taxonomigranskning (slå ihop taggar, lägg till nya kategorier med eftertanke).
När grunderna sitter kan ni överväga integrationer: auto-länka experiment till issue-trackers eller plocka in analyskontext så varje post pekar mot exakt dashboard som användes för resultatanalys.
Om ni utvecklar mot en anpassad app kan ni också iterera i “planeringsläge” först—skriv ner arbetsflöden, obligatoriska fält och godkännanderegler—och sedan implementera dem. Plattformar som Koder.ai stödjer sådana iterativa bygg-och-förfina-cykler (med deploys, snapshots och rollback) så er logg kan växa utan tung omläggning.
En produkt-experimentlogg är ett delat, sökbart arkiv för att dokumentera experiment (A/B-tester, prismodeller, ändringar i onboarding, feature-flag-rullouter, e-posttester). Varje post fångar vad ni testade, varför, vad som hände och vilket beslut som togs därefter — så lärdomar inte går förlorade i dokument, dashboards eller chattrådar.
Börja med att definiera 2–4 mätbara utfall, till exempel:
Dessa mål bör styra vilka fält som krävs, hur strikt ert arbetsflöde behöver vara och hur avancerad taxonomi/sök måste bli.
Lista era primära målgrupper och den “30-sekundersfråga” varje grupp behöver svar på. Vanliga behov är:
Designa sedan mallar och sidlayout för att omedelbart lyfta fram dessa svar.
Välj en av tre modeller:
Om ni väljer blandat, definiera vad som är tillåtet offentligt (t.ex. inga råa mätvärden, anonymiserade segment) och vem som godkänner publicering för att undvika omarbete senare.
Håll toppnavigeringen enkel och förutsägbar, till exempel:
Välj en primär bläddringsdimension (produktområde, funnel-steg eller team) och använd filter/taggar för allt annat.
Gör varje experimentpost konsekvent med ett minimikrav:
För resultat, standardisera:
En praktisk ordning är:
Använd ett litet antal tagggrupper som speglar hur folk söker, till exempel:
Förebygg taggsprawl med en kontrollerad vokabulär (namngivningsregler, vem som får skapa nya taggar och korta taggbeskrivningar). Håll kärnegenskaper som , och som strukturerade fält — inte fria taggar.
Använd ett CMS om ni främst behöver konsekvent dokumentation, behörigheter och grundläggande taggning med en lättanvänd editor.
Välj en anpassad app om ni behöver djupa integrationer (feature flags, analytics, datalager, ticketing), avancerad sökning/sparade vyer, arbetsflödesregler (obligatoriska fält/godkännanden) eller automatiska resultatuppdateringar.
Dokumentera alltid var ”sanningskällan” ligger (CMS vs databas/app) för att undvika dubbletter och motstridiga poster.
Börja med praktiska sökverktyg:
I listresultat, visa en kort resultatsammanfattning plus nyckelfält (status, ägare, primärt mätvärde) så användare slipper öppna flera sidor för att hitta rätt experiment.
Detta gör ”anteckningar” jämförbara över tid.
Det här gör sidor lätta att skumma men behåller djup vid behov.