27 aug. 2025·7 min
Go worker pools för bakgrundsjobb: återförsök, avbryt, shutdown
Go worker pools hjälper små team köra bakgrundsjobb med återförsök, avbokning och rent avslut med enkla mönster innan tung infrastruktur läggs till.
Varför bakgrundsjobb snabbt blir röriga
I en liten Go-tjänst börjar bakgrundsarbete oftast enkelt: returnera HTTP-svaret snabbt och gör det långsamma jobbet efteråt. Det kan vara att skicka mejl, ändra bildstorlekar, synka mot en annan API, bygga om sökindex eller köra nattliga rapporter.
Problemet är att dessa jobb är riktig produktionstrafik, bara utan de skyddsräcken man får i request-hantering. En goroutine som startas från en HTTP-handler känns bra — tills en deploy händer mitt i arbetet, en upstream API saktar ner, eller samma request försöks igen och triggar jobbet två gånger.
De första smärtpunkterna är förutsägbara:
- Fastnade jobb: ett anrop hänger sig och workers slutar göra framsteg.
- Dubbelarbete: retries i HTTP-lagret kör om samma jobb.
- Ingen shutdown-plan: processen avslutas och arbete går förlorat eller blir halvfärdigt.
- Tysta fel: fel loggas en gång (eller inte alls) och försvinner.
- Retry-stormar: misslyckade jobb försöker om direkt och överbelastar beroenden.
Här hjälper ett litet, explicit mönster som en Go worker pool. Det gör samtidigheten till ett val (N workers), förvandlar "gör det här senare" till en tydlig jobtyp och ger en plats att hantera retries, timeouter och avbokning.
Exempel: en SaaS-app behöver skicka fakturor. Du vill inte få 500 samtidiga utskick efter en batchimport, och du vill inte skicka samma faktura igen för att en request retriades. En worker pool låter dig begränsa genomströmningen och behandla "skicka faktura #123" som en spårad arbetsenhet.
En worker pool är inte rätt verktyg när du behöver hållbarhet över processer. Om jobb måste överleva krascher, schemaläggas för framtiden eller bearbetas av flera tjänster behöver du sannolikt en riktig kö och persistens för jobbstatus.
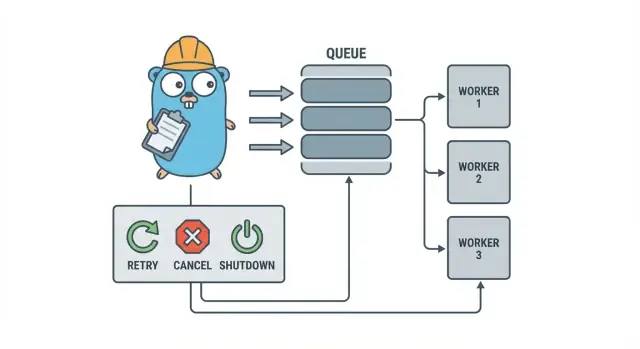
Worker pool-modellen i klarspråk
En Go worker pool är avsiktligt tråkig: lägg jobb i en kö, ha ett fast antal workers som hämtar dem, och se till att allt kan stoppas snyggt.
De grundläggande termerna:
- Job: en enhet arbete, som “ändra storlek på denna bild” eller “skicka denna faktura via mejl”.
- Kö: där jobben väntar.
- Worker: en goroutine som upprepat tar ett jobb och kör det.
- Dispatcher: delen som tar emot jobb och matar dem till kön.
I många in-process-designs är en Go channel kön. En buffrad channel kan hålla ett begränsat antal jobb innan producenter blockeras. Det blocket är backpressure, och det är ofta vad som hindrar din tjänst från att acceptera obegränsat med arbete och få slut på minne vid trafikspikar.
Bufferstorleken ändrar systemkänslan. En liten buffer gör trycket synligt snabbt (anropen väntar tidigare). En större buffer slätar över korta toppar men kan dölja överbelastning tills senare. Det finns inget perfekt nummer, bara ett nummer som matchar hur mycket väntan du tolererar.
Du väljer också om poolstorleken är fast eller kan ändras. Fasta pooler är lättare att resonera om och håller resursanvändningen förutsägbar. Autoskalning av workers hjälper vid ojämn last men lägger till beslut du måste underhålla (när skala upp, hur mycket och när skala ned).
Slutligen betyder "ack" i en in-process-pool vanligtvis bara "workern slutförde jobbet och returnerade inget fel." Det finns ingen extern broker som bekräftar leverans, så din kod definierar vad "klart" betyder och vad som händer när ett jobb misslyckas eller avbryts.
Designmål: återförsök, avbokning och rent avslut
En worker pool är enkel mekaniskt: kör ett fast antal workers, mata dem med jobb och bearbeta dem. Värdet är kontroll: förutsägbar samtidighet, tydlig felhantering och en shutdown-väg som inte lämnar halvfärdigt arbete.
Tre mål håller små team vid sunda vätskor:
- Begränsa samtidighet så att en topp inte smälter databasen eller ett extern API.
- Undvik att tappa arbete (eller åtminstone vet exakt vad som droppas och varför).
- Håll det debuggbart: varje jobb ska vara spårbart i loggar och några räknare.
De flesta fel är tråkiga, men du vill hantera dem olika:
- Transienta fel (nätverkshickups, rate limits) som bör försökas om.
- Permanenta fel (felaktig input, saknad post) som inte bör försökas om.
- Timeouts (ett beroende hänger) som måste kapas så workers inte täpps igen.
Avbokning är inte samma som "fel". Det är ett beslut: en användare avbröt, en deploy ersatte din process, eller tjänsten stängs ned. I Go behandla avbokning som ett förstaklass-tecken med hjälp av context cancellation, och se till att varje jobb kontrollerar det före dyrt arbete och vid några säkra stoppunkter under körningen.
Rent avslut är där många pooler faller isär. Bestäm tidigt vad "säkert" betyder för dina jobb: slutför du redan pågående jobb, eller stoppar du snabbt och kör om senare? Ett praktiskt flöde är:
- Sluta acceptera nya jobb.
- Säg åt workers att sluta efter sitt nuvarande jobb (eller sluta omedelbart).
- Vänta upp till en deadline, sedan tvångsavsluta.
Om du definierar dessa regler tidigt förblir retries, avbokning och shutdown små och förutsägbara istället för att växa till ett egengjort ramverk.
Steg för steg: bygg en grundläggande worker pool
En worker pool är bara en grupp goroutines som drar jobb från en channel och utför arbete. Viktigt är att göra grunderna förutsägbara: hur ett jobb ser ut, hur workers stoppar och hur du vet när allt arbete är klart.
Börja med en enkel Job-typ. Ge den ett ID (för loggar), en payload (vad som ska bearbetas), en försök-räknare (nyttigt för retries), tidsstämplar och en plats för per-job-contextdata.
package jobs
import (
"context"
"sync"
"time"
)
type Job struct {
ID string
Payload any
Attempt int
Enqueued time.Time
Started time.Time
Ctx context.Context
Meta map[string]string
}
type Pool struct {
ctx context.Context
cancel context.CancelFunc
jobs chan Job
wg sync.WaitGroup
}
func New(size, queue int) *Pool {
ctx, cancel := context.WithCancel(context.Background())
p := \u00026Pool{ctx: ctx, cancel: cancel, jobs: make(chan Job, queue)}
for i := 0; i \u0003c size; i++ {
go p.worker(i)
}
return p
}
func (p *Pool) worker(_ int) {
for {
select {
case \u0003c-p.ctx.Done():
return
case job, ok := \u0003c-p.jobs:
if !ok {
return
}
p.wg.Add(1)
job.Started = time.Now()
_ = job // call your handler here
p.wg.Done()
}
}
}
// Submit blocks when the queue is full (backpressure).
func (p *Pool) Submit(job Job) error {
if job.Enqueued.IsZero() {
job.Enqueued = time.Now()
}
select {
case \u0003c-p.ctx.Done():
return context.Canceled
case p.jobs \u0003c- job:
return nil
}
}
func (p *Pool) Stop() { p.cancel() }
func (p *Pool) Wait() { p.wg.Wait() }
Några praktiska val du gör direkt:
- Välj en köstorlek baserat på hur mycket väntan du kan tolerera.
- Bestäm vad backpressure betyder för anropare: blockera, returnera ett fel eller droppa.
- Håll
Stop()ochWait()separata så du kan stoppa intag först och sedan vänta på pågående arbete.
Lägga till återförsök utan att det blir ett ramverk
Återförsök är användbara, men också där worker pools blir röriga. Håll målet smalt: försök om bara när ett nytt försök har verklig chans att lyckas, och sluta snabbt när det inte gör det.
Börja med att bestämma vad som går att försöka om. Temporära problem (nätverkshaverier, timeouter, "försök igen senare") är oftast värda att försöka om. Permanenta (felaktig input, saknad post, permission denied) är inte.
En liten retry-policy räcker ofta:
- Markera fel som retrybara eller ej (t.ex. wrappa dem med en
Retryable(err)-hjälpare). - Sätt en maxantal försök (ofta 3 till 5). Efter det bränner du vanligtvis bara tid.
- Använd exponential backoff med jitter så jobb inte försöker om i takt.
- Begränsa fördröjningen (t.ex. aldrig vänta mer än 30 sekunder).
- Logga retries med försök-nr, nästa fördröjning och job-ID.
Backoff behöver inte vara komplicerat. En vanlig form är: delay = min(base * 2^(attempt-1), max), addera jitter (slumpa +/- 20%). Jitter är viktigt eftersom annars kan många workers misslyckas samtidigt och försöka om samtidigt.
Var ska fördröjningen ligga? För små system är det okej att sova inne i workern, men det blockerar en worker-slot. Om retries är sällsynta är det acceptabelt. Om retries är vanliga eller fördröjningar långa, överväg att köa om jobbet med en "run after"-timestamp så workers kan göra annat under tiden.
Vid slutligt misslyckande: var explicit. Spara det misslyckade jobbet (och sista felet) för granskning, logga tillräcklig kontext för att kunna replaya det eller placera det i en dead-list som du kontrollerar regelbundet. Undvik tysta bortfall. En pool som döljer fel är värre än att inte ha några retries alls.
Avbokning och timeouter som faktiskt stoppar arbete
Bygg snygg shutdown i Go
Skapa signalhantering och context-timeouter på några minuter från en chattprompt.
Worker pools känns bara säkra när du kan stoppa dem. Den enklaste regeln är: skicka en context.Context genom varje lager som kan blockera. Det betyder submission, exekvering och cleanup.
En praktisk uppsättning använder två tidsgränser:
- En per-job timeout så en uppgift inte kan ockupera en worker för alltid.
- En shutdown timeout så processen kan avslutas även om vissa jobb inte samarbetar.
Använd context från början till slut
Ge varje jobb sin egen context härledd från workerns context. Då måste varje långsamt anrop (DB, HTTP, köer, fil I/O) använda den contexten så det kan returnera tidigt.
func worker(ctx context.Context, jobs \u0003c-chan Job) {
for {
select {
case \u0003c-ctx.Done():
return
case job, ok := \u0003c-jobs:
if !ok { return }
jobCtx, cancel := context.WithTimeout(ctx, job.Timeout)
_ = job.Run(jobCtx) // Run must respect jobCtx
cancel()
}
}
}
Om Run anropar din DB eller en API, tråda in context i de anropen (t.ex. QueryContext, NewRequestWithContext eller klientmetoder som accepterar context). Om du ignorerar den på ett ställe blir avbokningen "best effort" och misslyckas vanligtvis när du behöver den som mest.
Partiellt arbete och steg som är "säkra att försöka om"
Avbokning kan hända mitt i ett jobb, så anta att partiellt arbete är normalt. Sikta på idempotenta steg så omkörningar inte skapar dubbletter. Vanliga tillvägagångssätt är att använda unika nycklar för inserts (eller upserts), skriva progressmarkörer (started/done), lagra resultat innan du fortsätter och kontrollera ctx.Err() mellan steg.
Behandla shutdown som en deadline: sluta acceptera nya jobb, cancel:a worker-contexts och vänta bara upp till shutdown-timeouten för att pågående jobb ska avsluta.
Rent avslut: vad göra när processen måste avslutas
Ett rent avslut har ett mål: sluta ta nytt arbete, tala om för pågående arbete att stoppa och avsluta utan att lämna systemet i ett konstigt tillstånd.
Börja med signaler. I de flesta deployment ser du SIGINT lokalt och SIGTERM från processhanteraren eller container-runtime. Använd en shutdown-context som cancel:as när en signal anländer och skicka den till din pool och jobhandlers.
Nästa steg: sluta acceptera nya jobb. Låt inte anropare blockera för evigt när de försöker submit:a till en kanal som ingen längre läser. Håll submission bakom en funktion som kollar en stängd-flagga eller väljer på shutdown-context innan den skickar.
Bestäm sedan vad som händer med köade jobb:
- Dränera: slutför det som redan är i kön, men neka nya submissioner.
- Droppa: kassera allt som inte startat ännu.
Dräning är säkrare för saker som betalningar och mejl. Droppning är okej för "trevligt att ha"-jobb som att räkna om en cache.
En praktisk shutdown-sekvens:
- Fånga SIGINT/SIGTERM och cancel:a en delad context.
- Stoppa submissions (stäng submit-vägen, inte nödvändigtvis work-channlen).
- Låt workers slutföra eller avbryta baserat på context.
- Vänta på workers med en WaitGroup.
- Håll en deadline och lämna därefter.
Deadlinen är viktig. Ge exempelvis pågående jobb 10 sekunder att avsluta. Efter det, logga vad som fortfarande körs och exit. Det gör deploys förutsägbara och undviker fastkörda processer.
Logging och enkla metrics för worker pools
Äg den genererade källkoden
Få full Go-, React- och databaskod som du äger och kan bygga vidare på.
När en worker pool går sönder så sker det sällan högljutt. Jobb går långsamt, retries hopar sig och någon säger att "inget händer." Logging och några grundläggande räknare förvandlar det till en tydlig bild.
Ge varje jobb ett stabilt ID (eller generera ett vid submission) och inkludera det i varje loggrad. Håll loggar konsekventa: en rad när ett jobb startar, en när det slutförs och en när det misslyckas. Om du försöker om, logga försök-nr och nästa fördröjning.
Ett enkelt loggformat:
- start: job_id, worker_id, attempt, kind
- finish: job_id, worker_id, attempt, duration_ms
- fail/retry: job_id, worker_id, attempt, err, next_delay_ms
Metrics kan vara minimala och ändå ge mycket. Spåra kölängd, pågående jobb, totala lyckanden och fel samt jobblatency (minst medel och max). Om kölängden ständigt växer och pågående ligger på workerantalet är du mättad. Om submitters blockerar på att skicka in i jobschannlen når backpressure anroparen — inte alltid dåligt, men det ska vara avsiktligt.
När "jobb sitter fast", kontrollera om processen fortfarande tar emot jobb, om kölängden växer, om workers lever och vilka jobb som kört längst. Långa körtider pekar oftast på saknade timeouter, långsamma beroenden eller en retry-loop som aldrig stoppar.
Ett realistiskt exempel: en liten SaaS bakgrundskö
Föreställ dig en liten SaaS där en order ändras till PAID. Direkt efter betalning behöver du generera en faktura-PDF, mejla kunden och notifiera interna teamet. Du vill inte att det här arbetet blockerar web-requesten. Det är en bra passform för en worker pool eftersom arbetet är verkligt men systemet fortfarande är litet.
Jobpayloaden kan vara minimal: bara nog för att hämta resten från databasen. API-handlaren skriver en rad som jobs(status='queued', type='send_invoice', payload, attempts=0) i samma transaktion som orderuppdateringen, sedan pollar en bakgrundsloop för köade jobb och pushar dem in i workerchannlen.
type SendInvoiceJob struct {
OrderID string
CustomerID string
Email string
}
När en worker plockar upp jobbet är happy path enkel: ladda ordern, generera fakturan, anropa email-providern och markera jobbet som klart.
Återförsök är där det blir verkligt. Om din email-leverantör har ett tillfälligt avbrott vill du inte att 1 000 jobb ska misslyckas för alltid eller slå på leverantören varje sekund. Ett praktiskt tillvägagångssätt är:
- Behandla nätverksfel och 5xx-svar som retrybara.
- Använd exponential backoff med max-delay (t.ex. 5s, 15s, 45s, 2m).
- Begränsa försök (t.ex. 10) och markera sedan jobbet som failed.
- Spara sista felet så support kan se vad som hände.
Under avbrottet flyttas jobb från queued till in_progress och tillbaka till queued med en framtida körtid. När leverantören återhämtar sig töms backloggen naturligt.
Tänk dig nu en deploy. Du skickar SIGTERM. Processen ska sluta ta nytt arbete men färdigställa det som är pågående. Sluta poll:a, sluta mata workerchannlen och vänta på workers med en deadline. Jobb som slutförs markeras done. Jobb som fortfarande kör när deadlinen nås bör markeras tillbaka till queued (eller lämnas i progress med en watchdog) så de kan plockas upp när den nya versionen startar.
Vanliga misstag och fallgropar
De flesta buggar i bakgrundsbehandling är inte i jobblogiken. De kommer från koordineringsmisstag som bara dyker upp under belastning eller vid shutdown.
En klassisk fälla är att stänga en channel från mer än ett ställe. Resultatet är en panic som är svår att reproducera. Välj en ägare för varje channel (vanligtvis producenten) och låt det vara enda stället som kallar close(jobs).
Retries är ett annat område där goda intentioner orsakar outages. Om du försöker om allt så försöker du även om permanenta fel. Det slösar tid, ökar load och kan förvandla ett litet problem till en incident. Klassificera fel och cap:a retries med en tydlig policy.
Dubbletter kommer att hända även med omsorgsfull design. Workers kan krascha mitt i ett jobb, en timeout kan trigga efter att arbetet redan är klart eller du kan requeue:a under deploy. Om jobbet inte är idempotent blir dubbletter verklig skada: två fakturor, två välkomstmejl, två återbetalningar.
De misstag som oftast visar sig:
- Stänga samma channel från flera goroutines.
- Försöka om permanenta fel istället för att synliggöra dem.
- Ingen idempotensnyckel, så dubbletter orsakar sidofekter.
- Obundna in-memory-köer som växer tills minnet spikar.
- Ignorera
context.Context, så arbete fortsätter efter att shutdown börjat.
Obundna köer är särskilt lömska. En trafikspik kan tyst samlas i RAM. Föredra en begränsad channel-buffer och bestäm vad som händer när den fylls: blockera, droppa eller returnera ett fel.
Snabb-checklista innan produktion
Flytta till en PostgreSQL jobbkö
Förvandla in-process jobb till en enkel PostgreSQL-kö utan att skriva om dina handlers.
Innan du skickar en worker pool till produktion bör du kunna beskriva jobblivscykeln högt. Om någon frågar "var är det här jobbet just nu?" ska svaret inte vara en gissning.
En praktisk pre-flight-checklista:
- Du kan namnge varje state och övergång: queued, picked up, running, finished, failed (och vad som flyttar det mellan states).
- Concurrency är en enda ratt (som
workerCount) och att ändra den kräver inte omskrivning av koden. - Retries är begränsade: maxförsök är tydliga, backoff växer och permanent fel går någonstans avsiktligt.
- Shutdown-beteende är bevisat: du stoppar intag, låter pågående jobb slutföra och har ändå en hård timeout.
- Loggar svarar på grunderna: job ID, försök-nr, duration och felorsak.
Gör en verklig drill innan release: köa 100 "skicka kvitto-mejl"-jobb, tvinga 20 att misslyckas och starta om tjänsten mitt i körningen. Du bör se att retries beter sig som förväntat, inga dubbletter, och att avbokning verkligen stoppar arbete när deadlinen nås.
Om något är otydligt, skärp det nu. Små fixar här sparar dagar senare.
Nästa steg: när lägga till tyngre infrastruktur (och när inte)
En enkel in-process pool räcker ofta medan en produkt är ung. Om dina jobb är "trevligt att ha" (skicka mejl, uppdatera caches, generera rapporter) och du kan köra om dem, håller en worker pool systemet lätt att förstå.
Tecken på att du vuxit ur en in-process pool
Håll utkik efter dessa tryckpunkter:
- Du kör flera app-instanser och behöver att bara en av dem plockar ett jobb.
- Du behöver hållbarhet (jobb måste överleva krascher och deploys).
- Du behöver en audit trail: vem köade vad, när det kördes och exakt resultat.
- Du behöver backpressure-kontroller över tjänster, inte bara inom en process.
- Du behöver strikt schemaläggning eller långa fördröjningar (timmar eller dagar) med pålitlig wake-up.
Om inget av det gäller kan tyngre verktyg lägga till fler rörliga delar än värde.
Migrera gradvis utan omskrivning
Den bästa hedgen är ett stabilt jobgränssnitt: en liten payload-typ, ett ID och en handler som returnerar ett tydligt resultat. Då kan du byta kö-backend senare (från en in-memory channel till en databas-tabell, och först därefter till en dedikerad kö) utan att ändra affärslogiken.
Ett praktiskt mellansteg är en liten Go-tjänst som läser jobb från PostgreSQL, låser dem med en claim och uppdaterar status. Du får hållbarhet och enkel auditability samtidigt som du behåller samma workerlogik.
Om du vill prototypa snabbt kan Koder.ai (koder.ai) generera en Go + PostgreSQL-starter från en chattprompt, inklusive en bakgrundsjobs-tabell och en worker-loop, och dess snapshots och rollback kan hjälpa medan du finjusterar retries och shutdown-beteende.