16 jan. 2026·7 min
Dokumentcentrerade arbetsflöden: datamodell och UI‑mönster
Dokumentcentrerade arbetsflöden förklarade med praktiska datamodeller och UI‑mönster för versioner, förhandsvisningar, metadata och tydliga statusar.
Dokumentcentrerade arbetsflöden förklarade med praktiska datamodeller och UI‑mönster för versioner, förhandsvisningar, metadata och tydliga statusar.
En app är dokumentcentrerad när dokumentet självt är produkten användarna skapar, granskar och förlitar sig på. Upplevelsen byggs kring filer som PDF:er, bilder, skanningar och kvitton, inte kring ett formulär där en fil bara är en bilaga.
I dokumentcentrerade arbetsflöden gör folk verkligt arbete inne i dokumentet: de öppnar det, ser vad som ändrats, lägger till kontext och bestämmer vad som händer härnäst. Om dokumentet inte går att lita på slutar appen vara användbar.
De flesta dokumentcentrerade appar behöver några kärnskärmar tidigt:
Problemen syns snabbt. Användare laddar upp samma kvitto två gånger. Någon redigerar en PDF och laddar upp den igen utan att förklara varför. En skanning saknar datum, säljare och ägare. Veckor senare vet ingen vilken version som godkändes eller vad beslutet baserades på.
En bra dokumentcentrerad app känns snabb och pålitlig. Användare ska kunna svara på dessa frågor på sekunder:
Den tydligheten kommer från definitioner. Innan du bygger skärmar, bestäm vad “version”, “förhandsvisning”, “metadata” och “status” betyder i din app. Om dessa termer är oklara får du dubbletter, förvirrande historik och granskningsflöden som inte matchar verkligt arbete.
UI ser ofta enkel ut (en lista, en visare, några knappar), men datamodellen bär tyngden. Om kärnobjekten är rätt blir revisionshistorik, snabba förhandsvisningar och tillförlitliga godkännanden mycket enklare.
Börja med att separera “dokumentposten” från “filinnehållet”. Posten är det användare pratar om (Faktura från ACME, taxikvittot). Innehållet är bytena (PDF, JPG) som kan ersättas, bearbetas om eller flyttas utan att ändra vad dokumentet betyder i appen.
En praktisk uppsättning objekt att modellera:
Bestäm vad som får ett ID som aldrig ändras. En användbar regel är: Document‑ID lever för alltid, medan Files och Previews kan regenereras. Versions behöver också stabila ID, eftersom människor hänvisar till “hur det såg ut igår” och du behöver ett revisionsspår.
Modellera relationer explicit. Ett Document har många Versions. Varje Version kan ha flera Previews (olika storlekar eller format). Det håller listskärmar snabba eftersom de kan ladda lättviktspreviewdata, medan detaljskärmar laddar full fil först när det behövs.
Exempel: en användare laddar upp ett skrynkligt kvittofoto. Du skapar ett Document, sparar originalfilen, genererar en miniatyr‑Preview och skapar Version 1. Senare laddar användaren upp en tydligare skanning. Det blir Version 2, utan att kommenterar eller godkännanden bryts eller sök kopplat till Document påverkas.
Människor förväntar sig att ett dokument förändras över tid utan att “förvandlas” till en annan post. Det enklaste sättet att leverera det är att separera identitet (Document) från innehåll (Version och Files).
Börja med ett stabilt document_id som aldrig ändras. Även om användaren laddar upp samma PDF igen, ersätter en suddig bild eller laddar upp en korrigerad skanning, bör det fortfarande vara samma dokumentpost. Kommentarer, tilldelningar och revisionsloggar fästs snyggt vid ett durable ID.
Behandla varje meningsfull ändring som en ny version‑rad. Varje version bör fånga vem som skapade den och när, plus lagringspekare (file key, checksum, size, page count) och härledda artefakter (OCR‑text, preview‑bilder) knutna till just den filen. Undvik “redigera på plats.” Det ser enklare ut i början, men bryter spårbarheten och gör buggar svåra att reda ut.
För snabba läsningar, behåll en current_version_id på dokumentet. De flesta skärmar behöver bara “den senaste”, så du slipper sortera versioner vid varje laddning. När du behöver historik, ladda versionerna separat och visa en ren tidslinje.
Rollback är bara en pekarändring. Istället för att radera något, sätt current_version_id tillbaka till en äldre version. Det är snabbt, säkert och håller revisionsspåret intakt.
För att hålla historiken begriplig, spela in varför varje version finns. Ett litet konsekvent reason‑fält (plus en valfri not) förhindrar en tidslinje full av mystiska uppdateringar. Vanliga orsaker är ersatt uppladdning, skanningsrensning, OCR‑korrigering, maskering och redigeringsgodkännande.
Exempel: en ekonomiavdelning laddar upp ett kvittofoto, ersätter det med en tydligare skanning och sedan fixar OCR så totalen blir läsbar. Varje steg är en ny version, men dokumentet förblir en post i inkorgen. Om OCR‑fixen var fel, är rollback ett klick eftersom du bara byter current_version_id.
I dokumentcentrerade arbetsflöden är förhandsvisningen ofta det huvudsakliga användarna interagerar med. Om förhandsvisningar är långsamma eller instabila känns hela appen trasig.
Behandla förhandsvisningsgenerering som ett separat jobb, inte något uppladdningsskärmen väntar på. Spara originalfilen först, återlämna kontroll till användaren och generera sedan förhandsvisningar i bakgrunden. Det håller UI responsivt och gör omförsök säkra.
Spara flera förhandsvisningsstorlekar. En storlek passar aldrig alla skärmar: en liten miniatyr för listor, en medelstor bild för delade vyer och helsidiga bilder för detaljerad granskning (sida för sida för PDF:er).
Spåra förhandsvisningsstatus explicit så UI alltid vet vad som ska visas: pending, ready, failed och needs_retry. Ha användarvänliga etiketter i UI, men håll staterna tydliga i datan.
För snabb rendering, cachea härledda värden tillsammans med preview‑posten i stället för att räkna om dem vid varje vy. Vanliga fält inkluderar page count, preview width och height, rotation (0/90/180/270) och en valfri “bästa sida för miniatyr”.
Designa för långsamma och röriga filer. En 200‑sidig skannad PDF eller ett skrynkligt kvittofoto kan ta tid att bearbeta. Använd progressiv laddning: visa den första färdiga sidan så fort den finns, och fyll i resten efter hand.
Exempel: en användare laddar upp 30 kvittofoton. Listvyn visar miniatyrer som “pending”, och varje kort växlar till “ready” när dess preview är färdig. Om några misslyckas på grund av en korrupt bild, håll dem synliga med en tydlig retry‑åtgärd i stället för att försvinna eller blockera hela batchen.
Metadata förvandlar en hög filer till något du kan söka, sortera, granska och godkänna. Det hjälper folk att svara på enkla frågor snabbt: Vad är detta dokument? Vem är det från? Är det giltigt? Vad ska hända härnäst?
Ett praktiskt sätt att hålla metadata ren är att separera den efter var den kommer från:
Dessa fack förhindrar framtida tvister. Om ett totalbelopp är fel kan du se om det kom från OCR eller en mänsklig ändring.
För kvitton och fakturor lönar sig ett litet set fält om du använder dem konsekvent (samma namn, samma format). Vanliga nyckelfält är vendor, date, total, currency och document_number. Håll dem frivilliga i början. Folk laddar upp ofullständiga skanningar och suddiga foton, och att stoppa flödet för ett saknat fält bromsar hela arbetet.
Behandla okända värden som förstklassiga. Använd explicita tillstånd som null/unknown, plus en anledning när det är hjälpsamt (saknad sida, oläsbar, inte tillämpligt). Det låter dokument gå vidare samtidigt som granskare ser vad som behöver uppmärksamhet.
Spara också proveniens och konfidens för extraherade fält. Källan kan vara user, OCR, import eller API. Konfidens kan vara en 0–1 poäng eller en liten uppsättning som high/medium/low. Om OCR läser “$18.70” med låg konfidens eftersom sista siffran är smutsig, kan UI markera det och be om en snabb bekräftelse.
Flersidsdokument kräver en extra beslutspunkt: vad tillhör hela dokumentet kontra en enskild sida. Totaler och säljare tillhör vanligtvis dokumentet. Sidspecifika anteckningar, maskeringar, rotation och klassificering per sida hör ofta hemma på sidnivå.
Status svarar på en fråga: “Var är detta dokument i processen?” Håll det litet och tråkigt. Om du lägger till en ny status varje gång någon ber om det, får du filter som ingen litar på.
Ett praktiskt set affärstillstånd som mappar till verkliga beslut:
Håll “processing” utanför affärsstatus. OCR‑körning och förhandsvisningsgenerering beskriver vad systemet håller på med, inte vad en person ska göra nästa. Spara dessa som separata bearbetningsstater.
Separera också tilldelning från status (assignee_id, team_id, due_date). Ett dokument kan vara Approved men fortfarande tilldelat för uppföljning, eller Needs review utan ägare än.
Spela in statushistorik, inte bara aktuellt värde. En enkel logg som (from_status, to_status, changed_at, changed_by, reason) betalar sig när någon frågar “Vem avvisade detta kvitto och varför?”
Slutligen, bestäm vilka åtgärder som är tillåtna i varje status. Håll regler enkla: Imported kan flytta till Needs review; Approved är skrivskyddad om inte en ny version skapas; Rejected kan öppnas igen men måste behålla tidigare anledning.
Det mesta av tiden spenderas på att skanna en lista, öppna ett objekt, rätta några fält och gå vidare. Bra UI gör dessa steg snabba och förutsägbara.
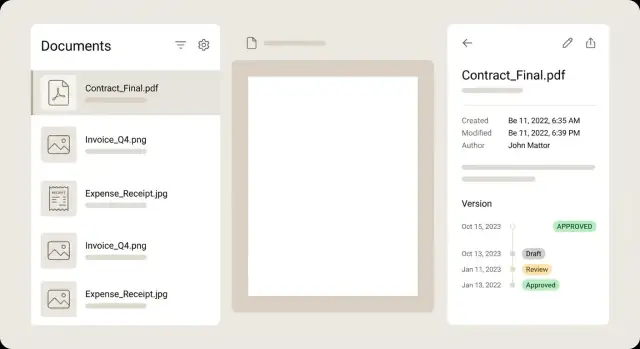
För dokumentlistan, behandla varje rad som en sammanfattning så användare kan besluta utan att öppna varje fil. En stark rad visar en liten miniatyr, en tydlig titel, några nyckelfält (leverantör, datum, total), en status‑badge och en subtil varning när något behöver uppmärksamhet.
Håll detaljvyn lugn och lätt att skumma. En vanlig layout är förhandsvisning till vänster och metadata till höger, med redigeringskontroller intill varje fält. Användare ska kunna zooma, rotera och bläddra sidor utan att tappa plats i formuläret. Om ett fält är extraherat från OCR, visa en liten konfidenshint och lyft gärna fram källområdet i förhandsvisningen när fältet är i fokus.
Versioner fungerar bäst som en tidslinje, inte en dropdown. Visa vem som ändrade vad och när, och låt användare öppna vilken tidigare version som helst i läsläge. Om du erbjuder jämförelse, fokusera på metadata‑skillnader (belopp ändrat, leverantör korrigerad) i stället för pixel‑för‑pixel PDF‑jämförelse.
Granskningsläge ska optimera för snabbhet. Ett tangentbordsfokuserat triage‑flöde räcker ofta: snabba godkänn/avvisa‑åtgärder, snabba rättningar för vanliga fält och en kort kommentarsruta för avvisningar.
Tomma tillstånd är viktiga eftersom dokument ofta är under bearbetning. I stället för en tom ruta, förklara vad som händer: “Förhandsvisning genereras”, “OCR körs” eller “Detta filformat har ingen förhandsvisning än.”
Ett enkelt flöde känns som “ladda upp, kontrollera, godkänn.” Under huven fungerar det bäst när du separerar filen själv (versioner och förhandsvisningar) från affärsbetydelsen (metadata och status).
Användaren laddar upp en PDF, foto eller kvittoskanning och ser den omedelbart i en inkorgslista. Vänta inte på att bearbetning ska bli klar. Visa filnamn, uppladdningstid och en tydlig badge som “Processing.” Om du redan vet källan (e‑postimport, mobilkamera, drag‑and‑drop), visa det också.
Vid uppladdning, skapa en Document‑post (det långlivade objektet) och en Version‑post (denna specifika fil). Sätt current_version_id till den nya versionen. Spara preview_state = pending och extraction_state = pending så UI kan vara ärligt om vad som är klart.
Detaljvyn bör öppnas omedelbart, men visa en platshållarvisare och ett tydligt meddelande “Förbereder förhandsvisning” i stället för en trasig ram.
Ett bakgrundsjobb skapar miniatyrer och en visbar förhandsvisning (sidor som bilder för PDF:er, storleksändrade bilder för foton). Ett annat jobb extraherar metadata (leverantör, datum, total, valuta, dokumenttyp). När varje jobb slutförs, uppdatera bara dess state och tidsstämplar så du kan göra omförsök vid fel utan att röra allt annat.
Håll UI kompakt: visa preview‑state, data‑state och markera fält med låg konfidens.
När förhandsvisningen är klar, rättar granskare fält, lägger till noteringar och flyttar dokumentet genom affärsstatusar som Imported -> Needs review -> Approved (eller Rejected). Logga vem som ändrade vad och när.
Om en granskare laddar upp en korrigerad fil blir det en ny Version och dokumentet går automatiskt tillbaka till Needs review.
Export, redovisningssynk eller interna rapporter bör läsa från current_version_id och den godkända metadata‑snapshoten, inte “senaste extraktionen.” Det förhindrar att en halvbearbetad ominladdning ändrar siffror.
Dokumentcentrerade arbetsflöden misslyckas av tråkiga skäl: tidiga genvägar blir dagligt bekymmer när folk laddar upp dubbletter, rättar misstag eller frågar “Vem ändrade detta och när?”
Att behandla filnamnet som dokumentets identitet är ett klassiskt misstag. Namn ändras, användare laddar upp igen och kameror skapar dubbletter som IMG_0001. Ge varje dokument ett stabilt ID och behandla filnamnet som en etikett.
Att skriva över originalfilen när någon laddar upp en ersättning orsakar också problem. Det känns enklare, men du förlorar revisionsspåret och kan inte svara på grundläggande frågor senare (vad var godkänt, vad redigerades, vad skickades). Håll binärfilen oföränderlig och lägg till en ny versionpost.
Statusförvirring skapar subtila buggar. “OCR körs” är inte samma som “Needs review.” Bearbetningsstater beskriver vad systemet gör; affärsstatus beskriver vad en person bör göra härnäst. När de blandas hamnar dokument i fel hink.
UI‑beslut kan skapa friktion också. Om du blockerar skärmen tills förhandsvisningar genererats upplever folk appen som långsam även när uppladdningen lyckades. Visa dokumentet direkt med en tydlig platshållare och byt sedan in miniatyrer när de är klara.
Slutligen blir metadata opålitlig när du sparar värden utan proveniens. Om totalen kom från OCR, säg det. Behåll tidsstämplar.
En snabb checklista:
Exempel: i en kvittoapp laddar en användare upp ett tydligare foto. Om du versionerar det, behåll den gamla bilden, markera OCR som reprocessas och håll dokumentet i Needs review tills en människa bekräftar beloppet.
Dokumentcentrerade arbetsflöden känns “klara” först när människor kan lita på vad de ser och återhämta sig när något går fel. Innan release, testa med röriga, verkliga dokument (suddiga kvitton, roterade PDF:er, upprepade uppladdningar).
Fem kontroller som fångar de flesta överraskningar:
Ett snabbt verklighetstest: be någon granska tre liknande kvitton och avsiktligt göra en feländring. Om de kan hitta aktuell version, förstå status och rätta felet på under en minut är du nära.
Månatliga kvittoreimbursementer är ett tydligt exempel på dokumentcentrerat arbete. En anställd laddar upp kvitton, sedan granskar två personer dem: en chef och sedan ekonomi. Kvittot är produkten, så din app lever eller dör på versionering, förhandsvisningar, metadata och tydliga statusar.
Jamie laddar upp ett taxikvitto. Ditt system skapar Document #1842 med Version v1 (originalfilen), en miniatyr och förhandsvisning, samt metadata som merchant, date, currency, total och en OCR‑konfidenspoäng. Dokumentet börjar i Imported och går sedan till Needs review när förhandsvisning och extraktion är klara.
Senare laddar Jamie av misstag upp samma kvitto igen. En dubblettkontroll (filhash plus liknande merchant/date/total) kan visa ett enkelt val: “Verkar vara en dubblett av #1842. Bifoga ändå eller kassera.” Om de bifogar, spara det som ytterligare en File länkad till samma Document så du behåller en granskningstråd och ett statusflöde.
Under granskningen ser chefen förhandsvisningen, nyckelfälten och varningarna. OCR gissade totalen till $18.00, men bilden visar tydligt $13.00. Jamie korrigerar totalen. Skriv inte över historiken. Skapa Version v2 med uppdaterade fält, behåll v1 oförändrad och logga “Total korrigerad av Jamie.”
Om du vill bygga detta arbetsflöde snabbt kan Koder.ai (koder.ai) hjälpa dig generera den första versionen av appen från en chattbaserad plan, men samma regel gäller: definiera objekten och staterna först, låt sedan skärmarna följa.
Praktiska nästa steg:
En dokumentcentrerad app behandlar dokumentet som huvudobjektet användarna arbetar med, inte som en bifogad fil. Människor behöver öppna det, lita på vad de ser, förstå vad som ändrats och avgöra vad som händer härnäst baserat på det dokumentet.
Börja med en inkorg/lista, en dokumentdetaljvy med snabb förhandsvisning, ett enkelt granskningsområde (godkänn/avvisa/begär ändring) och ett sätt att exportera eller dela. Dessa fyra skärmar täcker det vanliga flödet hitta → öppna → besluta → överlämna.
Modellera ett stabilt Document‑objekt som aldrig ändras och lagra de faktiska filbitarna som separata File‑objekt. Lägg sedan till Version som en snapshot som binder ett dokument till en specifik fil (och dess härledda artefakter). Denna separation bevarar kommentarer, uppgifter och historik även när filen byts ut.
Gör varje meningsfull ändring till en ny version i stället för att skriva över på plats. Ha en current_version_id på dokumentet för snabba “senaste” läsningar och lagra en tidslinje med äldre versioner för revision och rollback. Detta förhindrar förvirring om vad som blev godkänt och varför.
Generera förhandsvisningar asynkront efter att originalfilen sparats, så att uppladdningar känns omedelbara och retry är säkra. Spåra förhandsvisningsstatus som pending/ready/failed så UI kan vara ärligt, och lagra flera storlekar så listvyer hålls lätta medan detaljvyer förblir skarpa.
Spara metadata i tre fack: system (filstorlek, typ), extraherat (OCR‑fält och konfidens) och användar‑inmatat (korrigeringar). Behåll proveniens så du kan se om ett värde kom från OCR eller en person, och tvinga inte alla fält att vara ifyllda innan arbetet kan fortsätta.
Använd ett litet set affärsstatusar som beskriver vad en människa bör göra härnäst, till exempel Imported, Needs review, Approved, Rejected och Archived. Spåra bearbetning separat (förhandsvisning/OCR körs) så dokument inte blir “fast” i en status som blandar mänskligt och maskinellt arbete.
Spara oföränderliga filchecksummor och jämför dem vid uppladdning, och lägg till en andra kontroll med nyckelfält som leverantör/datum/total när de finns. När du misstänker en dubblett, erbjud valet att fästa den till samma dokumenttråd eller kassera den, så granskningshistoriken inte splittras över kopior.
Ha en statushistoriklogg med vem som ändrade vad, när och varför, och gör versioner läsbara via en tidslinje. Rollback bör vara en enkel pekarändring tillbaka till en äldre version, inte en borttagning, så du kan återställa snabbt utan att förlora revisionsspår.
Definiera objekten och staterna först, och låt UI följa de definitionerna. Om du använder Koder.ai för att generera en app från en chattplan, var tydlig med Document/Version/File, förhandsvisnings‑ och extraktionsstater och statusregler så de genererade skärmarna matcher verkligt arbetsflöde.