Когда база данных нагружена, что ломается первым
Когда ваша база данных перегружена, пользователи редко видят чистое сообщение «сервис недоступен». Они видят таймауты, страницы, которые грузятся наполовину, крутящиеся кнопки и действия, которые иногда проходят, а иногда — падают. Сохранение может сработать один раз, а в следующий раз вернуть ошибку «Что‑то пошло не так». Такая неопределённость делает инциденты хаотичными.
Первое, что обычно ломается — это операции, нагружающие запись: редактирование записей, процессы оформления заказа, отправка форм, фоновые обновления и всё, что требует транзакции и блокировок. Под нагрузкой записи замедляются, блокируют друг друга и могут замедлять чтения, удерживая блокировки и вызывая дополнительную работу.
Случайные ошибки кажутся хуже контролируемого ограничения, потому что пользователи не понимают, что делать дальше. Они повторяют попытки, обновляют страницу, кликают снова — и создают ещё большую нагрузку. Количество обращений в поддержку растёт, потому что система «как‑бы работает», но ей нельзя доверять.
Цель режима только для чтения при инцидентах — не идеальная работа. Цель — сохранить самые важные части полезными: просмотр ключевых записей, поиск, проверка статуса и скачивание того, что нужно пользователям для продолжения работы. Вы преднамеренно останавливаете или откладываете рискованные операции (записи), чтобы база данных успела восстановиться, а оставшиеся чтения оставались отзывчивыми.
Чётко обозначайте ожидания. Это временное ограничение и не означает удаление данных. В большинстве случаев данные пользователя остаются на месте и в безопасности — система просто приостанавливает изменения, пока база данных снова не придёт в норму.
Что на самом деле значит режим только для чтения
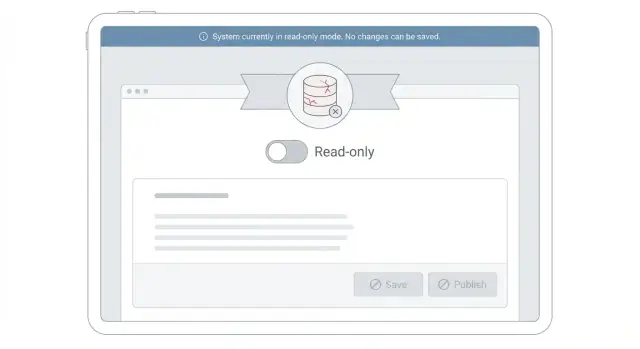
Режим только для чтения во время инцидента — это временное состояние, при котором продукт остаётся пригодным для просмотра, но отказывает во всём, что меняет данные. Цель проста: сохранить полезность сервиса и защитить базу данных от лишней работы.
Проще говоря: люди всё ещё могут смотреть данные, но не могут совершать действия, которые вызвали бы записи. Обычно это означает, что работают просмотр страниц, поиск, фильтры и открытие записей. Сохранение форм, изменение настроек, публикация комментариев, загрузка файлов или создание новых аккаунтов блокируются.
Практическое правило: если действие обновляет строку, создаёт строку, удаляет строку или пишет в очередь — оно недоступно. Многие команды также блокируют «скрытые записи», такие как аналитические события, сохраняемые в основной базе, синхронно пишущиеся логи аудита и метки «последний визит».
Режим только для чтения — правильный выбор, когда чтения ещё в основном работают, но латентность записей растёт, растёт конкуренция за блокировки или очередь операций записи замедляет всё.
Включайте полный офлайн, когда даже базовые чтения начинают таймаутить, кэш не может отдавать необходимое или система не может надёжно сказать пользователям, что безопасно делать.
Почему это помогает: запись часто стоит гораздо дороже, чем простое чтение. Запись может задействовать индексы, проверки ограничений, блокировки и последующие запросы. Блокировка записей также предотвращает штормы повторных попыток, когда клиенты продолжают повторно отправлять неудачные сохранения и умножают ущерб.
Пример: во время инцидента CRM пользователи всё ещё могут искать аккаунты, открывать контакты и просматривать недавние сделки, но действия Редактировать, Создать и Импорт отключены, а любые запросы на сохранение немедленно отклоняются с понятным сообщением.
Выберите, какие чтения важны, а какие записи приостановить
Когда вы переключаетесь в режим только для чтения, цель не в том, чтобы «всё работало». Цель — чтобы самые важные экраны по‑прежнему загружались, а всё, что создаёт дополнительное давление на базу, останавливалось быстро и безопасно.
Начните с перечисления немногих действий пользователя, которые должны продолжать работать даже в плохой день. Обычно это небольшие чтения, которые разблокируют решения: просмотр последней записи, проверка статуса, поиск по короткому списку или загрузка отчёта из кэша.
Затем решите, что можно приостановить без серьёзного вреда. Большинство путей записи относятся к «приятно иметь» во время инцидента: правки, массовые обновления, импорты, комментарии, вложения, аналитика и всё, что запускает дополнительные запросы.
Простой способ принять решение — разделить действия на три корзины:
- Must keep: небольшие, быстрые чтения, которые прямо сейчас разблокируют пользователей
- Can pause: записи и тяжёлые чтения, которые добавляют нагрузку или блокируют строки
- Can degrade: функции, которые могут показывать кэшированные данные или частичный вид
Также задайте временной горизонт. Если вы ожидаете минуточного восстановления, можно быть жёстким и заблокировать почти все записи. Если вы ожидаете часов — рассмотрите возможность разрешить очень ограниченный набор безопасных записей (например, сбросы пароля или критические обновления статуса) и поставить в очередь всё остальное.
Согласуйте приоритет заранее: безопасность важнее полноты. Лучше показать чёткое сообщение «изменения приостановлены», чем позволить записи, которые наполовину выполняются и оставляют данные неконсистентными.
Как решить, когда включать режим
Переход в режим только для чтения — это компромисс: меньше функционала сейчас, но работающее приложение и здоровая база. Цель — действовать до того, как пользователи спровоцируют спираль повторных попыток, таймаутов и зависших соединений.
Следите за небольшим набором сигналов, которые можно объяснить в одном предложении. Если два и более сигнала появляются одновременно, воспринимайте это как раннее предупреждение:
- Таймауты запросов или резкий рост латентности (например, p95 с 300 мс до 3 с)
- CPU базы данных, загруженный на 100% в течение нескольких минут, а не только кратковременный всплеск
- Истощение пула подключений (запросы в очереди, потому что нет свободных подключений)
- Лог медленных запросов заполняется одними и теми же тяжёлыми запросами
- Рост ошибок из‑за ожиданий блокировок, дедлоков или провалившихся транзакций
Метрики не должны быть единственным триггером. Добавьте человеческое решение: on‑call объявляет состояние инцидента и включает режим только для чтения. Это прекращает споры под давлением и делает действие аудируемым.
Сделайте пороги запоминающимися и простыми для общения. «Записи приостановлены из‑за перегрузки базы» понятнее, чем «мы достигли насыщения». Также определите, кто может переключать режим и где это контролируется.
Избегайте флаппинга между режимами. Добавьте простую гистерезис‑логику: после перехода в read‑only оставайтесь в нём минимум заданное время (например, 10–15 минут) и возвращайтесь только после того, как ключевые сигналы нормализуются. Это предотвращает ситуацию, когда формы работают одну минуту, а в следующую — падают.
Пошагово: как безопасно включать режим только для чтения
Рассматривайте режим только для чтения как контролируемое изменение, а не как панику. Цель — защитить базу, остановив записи, и при этом сохранить самые ценные чтения.
Безопасная последовательность развёртывания
Если можно, подготовьте путь в коде до переключения. Тогда включение read‑only — это просто тумблер, а не правка в проде.
- Создайте один переключатель инцидента (флаг фичи или настройку конфигурации), который читает вся система. Держите его глобальным и простым:
READ_ONLY=true. Избегайте множества флагов, которые могут рассинхронизироваться.
- Обновите UI, чтобы предотвращать попытки записи. Отключите кнопки Сохранить, спрячьте формы редактирования и переключите поля на обычный текст. Всё равно показывайте данные, чтобы люди могли продолжать работать (просмотр, поиск, экспорт).
- Принудительно применяйте это на сервере, а не только в UI. Блокируйте записи в одном месте (middleware, guard в контроллере или сервис‑слой), чтобы все клиенты были покрыты: мобильные приложения, API‑пользователи и автоматизация.
- Возвращайте понятную, согласованную ошибку для заблокированных записей. Используйте отдельный статус и сообщение типа: «Редактирование временно отключено, пока мы стабилизируем систему. Ваши данные в безопасности. Попробуйте позже.» Не возвращайте общий 500, который похож на потерю данных.
- Логируйте каждую заблокированную попытку записи. Фиксируйте пользователя, endpoint и тип действия. Минимизируйте полезную нагрузку логов, чтобы не сохранять чувствительные данные. Эти логи помогут найти проблемы UX и при необходимости воспроизвести критичные действия позже.
Мелочь, которая предотвращает повторные инциденты
Когда режим только для чтения активен, быстро отказывайте до обращения к базе. Не запускайте проверки валидации, а потом блокируйте запись. Самый быстрый отклонённый запрос — это тот, который не коснулся вашей перегруженной базы.
Сообщения в UI, которые снижают путаницу и количество тикетов
Deploy with Confidence
Deploy and host your app so the read-only switch is always available to on call.
Когда вы включаете режим только для чтения, UI становится частью решения. Если люди продолжают нажимать Сохранить и получать расплывчатые ошибки, они будут повторять попытки, обновлять страницы и создавать тикеты. Чёткие сообщения снижают нагрузку и раздражение.
Хорошая практика — видимый постоянный баннер в верхней части приложения. Коротко и по делу: что происходит, чего ожидать и что можно сделать сейчас. Не прячьте это в исчезающем уведомлении.
Говорите, что работает, что приостановлено и что далее
Пользователи в основном хотят понимать, могут ли они продолжать работу. Пишите простым языком. Для большинства продуктов это значит:
- Работает: просмотр записей, поиск, скачивание, чтение дашбордов
- Приостановлено: создание, редактирование, удаление, загрузки, платежи, отправка сообщений
- Делайте вместо этого: скопируйте ключевую информацию, экспортируйте вид, повторите позже
- Обновления: «Мы опубликуем обновление здесь через 15 минут.»
Простой статус‑лейбл тоже помогает понять прогресс без домыслов. «Investigating» означает, что вы ещё выясняете причину. «Stabilizing» — вы снижаете нагрузку и защищаете данные. «Recovering» — записи вернутся скоро, но могут быть медленными.
Держите тон спокойным и конкретным
Избегайте обвиняющего или расплывчатого текста вроде «Что‑то пошло не так» или «У вас нет прав». Если кнопка отключена, подпишите её: «Редактирование временно приостановлено, пока мы стабилизируем систему.»
Небольшой пример: в CRM оставляйте страницы контактов и сделок читаемыми, но отключайте Редактировать, Добавить заметку и Новая сделка. Если пользователь всё же пытается, покажите короткий диалог: «Изменения сейчас приостановлены. Можете скопировать запись или экспортировать список, затем попробуйте позже.»
Сохраняйте ключевые чтения, не увеличивая нагрузку
Цель не в том, чтобы всё было видно, а в том, чтобы сохранять несколько страниц, на которые люди полагаются, без дополнительного давления на базу.
Начните с урезания самых тяжёлых экранов. Длинные таблицы с множеством фильтров, полнотекстовый поиск по множеству полей и сложные сортировки часто запускают медленные запросы. В режиме только для чтения упростите такие экраны: меньше опций фильтра, безопасная сортировка по умолчанию и ограниченный диапазон дат.
Отдавайте предпочтение кэшированным или предвычисленным представлениям для важных страниц. Простая «обзорная» страница аккаунта из кэша или сводной таблицы безопаснее, чем загрузка сырых логов событий или множественных соединений таблиц.
Практические приёмы, чтобы чтения оставались живыми, но не давили:
- Используйте меньшие размеры страниц и убирайте «показать всё»
- Замените сложные сортировки на сортировку по умолчанию (например, «сначала последние»)
- Отложите несущественные чтения: аналитику, рекомендации, графики активности
- Отдавайте предпочтение кэшированным сводкам вместо полного исторического лога
- Допускайте слегка устаревшие данные, если это сохраняет отзывчивость ключевых страниц
Конкретный пример: в CRM оставляйте работающими Просмотр контакта, Просмотр статуса сделки и Просмотр последней заметки. Временно скрывайте Расширенный поиск, Диаграмму доходов и Полную историю писем, указывая, что данные могут отставать на несколько минут.
Что делать с заданиями, вебхуками и интеграциями
Test the CRM Scenario
Prototype a CRM style workflow and test what stays usable when writes are paused.
Самый большой сюрприз при включении read‑only часто не в UI, а в невидимых писателях: фоновые задания, плановые синхронизации, админ‑массовые операции и сторонние интеграции, которые продолжают долбить базу.
Начните с остановки фоновой работы, которая создаёт или обновляет записи. Частые виновники: импорты, ночные синки, отправка почты с записью логов доставки, аналитические сводки и циклы повторных попыток тех же неудачных обновлений. Приостановка этого быстро снижает нагрузку и предотвращает вторую волну.
Безопасный дефолт — приостановить или замедлить задачі с интенсивной записью и любых потребителей очередей, которые сохраняют результаты, отключить админ‑массовые действия (массовые обновления, массовые удаления, большие переиндексации) и быстро отдавать отказ для endpoint’ов записи, чтобы не приводить к таймаутам.
Для вебхуков и интеграций ясность лучше надежды. Если вы принимаете вебхук, но не можете его обработать, это создаст рассинхронизации и обращения в поддержку. Когда записи приостановлены, возвращайте временный отказ с указанием повторить позже и убедитесь, что UI отражает, что происходит на бэкенде.
Будьте осторожны с буферизацией «поставить в очередь на потом». Звучит дружелюбно, но может создать бэклог, который зальёт систему при включении записи. Буферизуйте действия пользователя только если вы гарантируете идемпотентность, ограничите размер очереди и показывайте пользователю реальное состояние (ожидает vs сохранено).
Наконец, проверьте скрытых массовых писателей в продукте. Если автоматизация может обновить тысячи строк, её нужно отключать в read‑only даже если остальная часть приложения грузится.
Частые ошибки, которые усугубляют инциденты
Самый быстрый способ ухудшить инцидент — считать режим только для чтения косметической мерой. Если вы только отключаете кнопки в UI, люди всё ещё будут писать через API, старые вкладки, мобильные приложения и фоновые задачи. База останется под давлением, и вы потеряете доверие, потому что в одном месте видны «сохранено», а в другом изменения отсутствуют.
Реальный режим только для чтения требует одного правила: сервер отказывает в записях всегда и для всех клиентов.
Ошибки, за которыми стоит следить
Эти паттерны часто повторяются при перегрузке базы:
- Блокировка правок только в UI, в то время как backend всё ещё принимает POST, PUT, PATCH и DELETE
- Забытые пути: админ‑панели, внутренние инструменты, эндпоинты импорта и публичные API, используемые интеграциями
- Флаппинг между нормальным режимом и read‑only каждую минуту
- Расплывчатые сообщения типа «Что‑то пошло не так»
- Частичные записи, оставляющие данные неконсистентными
Как этого избежать
Заставьте систему вести себя предсказуемо. Применяйте один серверный переключатель, который отказывает в записях с понятным ответом. Добавьте кулдаун: после перехода в read‑only оставайтесь в нём заданное время (например, 10–15 минут), если только оператор явно не изменит состояние.
Будьте строги в вопросах целостности данных. Если запись не может завершиться полностью, откатывайте всю операцию и объясняйте пользователю, что делать дальше. Простое сообщение «Read‑only mode: просмотр работает, изменения приостановлены. Попробуйте позже.» снизит число повторных попыток.
Быстрая проверка до и во время инцидента
Режим только для чтения полезен лишь тогда, когда его легко включить и он ведёт себя одинаково везде. До инцидента убедитесь, что есть один тумблер (флаг фичи, конфиг, админ‑переключатель), который on‑call может включить за секунды без деплоя.
Когда вы подозреваете перегрузку, выполните быструю проверку базовых вещей:
- Включите тумблер в безопасной среде и подтвердите, что он действует немедленно
- Попытайтесь выполнить несколько записей (сохранение, удаление, импорт) и убедитесь, что все эндпоинты записи возвращают одинаковый блокирующий ответ и статус
- Проверьте, что текст баннера готов, короток и виден на наиболее используемых экранах
- Загрузите ваши топ‑3 страницы (например: вход, дашборд, просмотр записи) и убедитесь, что они всё ещё рендерятся под нагрузкой
- Убедитесь, что поддержка знает одно‑параграфный скрипт: что работает, что приостановлено и где смотреть обновления
Во время инцидента держите одного человека, который фокусируется на проверке пользовательского опыта, а не только на дашбордах. Быстрая проверка в приватном окне ловит проблемы вроде скрытых баннеров, сломанных форм или вечных спиннеров, которые приводят к дополнительному трафику обновлений.
План выхода подготовьте заранее. Решите, что значит «здорово» (латентность, уровень ошибок, отставание репликации) и выполните короткую верификацию после возвращения: создайте тестовую запись, отредактируйте её и проверьте счётчики и недавнюю активность.
Пример инцидента: сохранить CRM рабочей, блокируя правки
Practice the Switch in Staging
Turn your incident playbook into a working app flow you can test anytime.
10:20 утра. CRM тормозит, CPU базы загружен. В поддержку начали приходить обращения: пользователи не могут сохранить изменения контактов и сделок. Но команде всё ещё нужно смотреть номера телефонов, этапы сделок и последние заметки перед звонками.
Вы выбираете простое правило: заморозить всё, что пишет, и сохранить самые ценные чтения. На практике поиск контактов, страницы деталей контакта и вид воронки сделок остаются доступными. Редактирование контактов, создание новых сделок, добавление заметок и массовые импорты блокируются.
В UI изменение должно быть заметным и спокойным. На экранах редактирования кнопка Сохранить отключена, форма остаётся видимой, чтобы люди могли скопировать введённый текст. Вверху баннер: «Read‑only mode включён из‑за высокой нагрузки. Доступен просмотр. Изменения приостановлены. Пожалуйста, попробуйте позже.» Если пользователь всё же инициирует запись (например через API), возвращайте понятное сообщение и избегайте автоповторов, которые бьют по базе.
Операционно держите поток коротким и повторяемым. Включите read‑only и проверьте, что все эндпоинты записи его соблюдают. Приостановите фоновые задачи, которые пишут (синки, импорты, логирование почты, аналитические бэкапы). Ограничьте или приостановите вебхуки и интеграции, создающие обновления. Мониторьте нагрузку базы, уровень ошибок и медленные запросы. Опубликуйте статус с тем, что затронуто (редактирование) и что доступно (поиск и просмотры).
Восстановление — это не просто отключение тумблера. Включайте записи поэтапно, проверяйте логи ошибок по неудачным сохранениям и следите за возможным «штормом» записей из очередей. Затем сообщите ясно: «Read‑only mode выключен. Сохранение восстановлено. Если вы пытались сохранить изменения между 10:20 и 10:55, пожалуйста, проверьте свои последние изменения.»
Следующие шаги: сделайте режим только для чтения частью вашей инструкции
Режим только для чтения эффективнее, когда он скучен и повторяем. Цель — следовать короткому сценарию с понятными владельцами и проверками.
Составьте небольшую рабочую инструкцию
Держите её на одной странице. Включите триггеры (несколько сигналов, которые оправдывают переход в read‑only), точный переключатель и как подтверждать блокировку записей, короткий список ключевых чтений, чёткие роли (кто включает переключатель, кто наблюдает метрики, кто работает с поддержкой) и критерии выхода (что должно быть правдой перед включением записей и как вы будете сливать накопления).
Подготовьте тексты UI заранее
Напишите и утвердите тексты сейчас, чтобы не спорить об формулировках во время простоя. Набор обычно покрывает большинство случаев:
- Баннер: «Мы в режиме только для чтения, пока восстанавливаем производительность. Вы можете просматривать данные, но изменения временно отключены.»
- При блокировке действий: «Сохранение приостановлено. Ваши изменения не применены. Пожалуйста, попробуйте через несколько минут.»
- Статус деталей: «Последнее обновление в HH:MM. Следующее обновление через 10 минут.»
Отрепетируйте переключение в staging и засеките время. Убедитесь, что поддержка и on‑call быстро находят тумблер, а логи чётко фиксируют заблокированные записи. После каждого инцидента анализируйте, какие чтения действительно были критичны, какие были приятными дополнениями, а какие случайно создали нагрузку, и обновляйте чеклист.
Если вы строите продукты на Koder.ai (koder.ai), полезно сделать read‑only первоклассным тумблером в сгенерированном приложении, чтобы UI и серверные защиты оставались синхронизированы в самый нужный момент.