27 авг. 2025 г.·7 мин
Пулы воркеров на Go для фоновых задач: повторные попытки, отмена, завершение
Пулы воркеров на Go помогают небольшим командам запускать фоновые задачи с повторами, поддержкой отмены и аккуратным завершением, используя простые паттерны до добавления тяжёлой инфраструктуры.
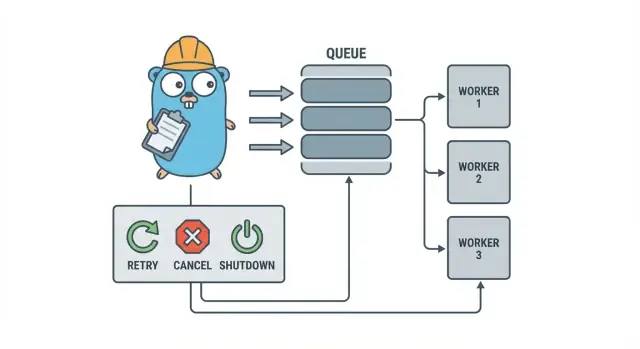
Почему фоновые задачи быстро становятся хаотичными
В небольшом сервисе на Go фоновые задачи обычно появляются с простой целью: быстро вернуть HTTP-ответ, а медленную работу выполнить позже. Это может быть отправка писем, изменение размера картинок, синхронизация с другим API, перестройка поисковых индексов или ночные отчёты.
Проблема в том, что эти задачи — настоящая рабочая нагрузка, просто без тех защит, которые вы естественно получаете при обработке запроса. Горутин, запущенная из HTTP-обработчика, кажется нормальной, пока не произойдёт деплой посередине задачи, внешний API не начнёт тормозить или тот же запрос не будет повторён и не запустит задачу дважды.
Первые болевые точки предсказуемы:
- Зависшие задачи: один вызов застревает, и воркеры перестают прогрессировать.
- Дублирование работы: повторы на уровне HTTP повторно запускают одну и ту же задачу.
- Нет плана завершения: процесс завершается, и работа теряется или остаётся наполовину выполненной.
- Молчанка при ошибках: ошибки логируются один раз (или вообще не логируются) и пропадают.
- Штормы повторов: падающие задачи повторяются мгновенно и перегружают зависимости.
Именно здесь помогает небольшой, явный паттерн вроде пула воркеров на Go. Он превращает конкуррентность в контролируемое значение (N воркеров), делает «сделать позже» понятным типом работы и даёт централизованное место для обработки повторов, таймаутов и отмены.
Пример: SaaS-приложению нужно отправлять счета. Вы не хотите 500 одновременных отправок после пакетного импорта и не хотите повторно отправлять один и тот же счёт, потому что запрос был повторён. Пул воркеров позволяет ограничить пропускную способность и воспринимать «отправить счёт #123» как отслеживаемую единицу работы.
Пул воркеров — не подход, когда вам нужны устойчивые гарантии между процессами. Если задача должна пережить крах, быть запланирована на будущее или обрабатываться несколькими сервисами, вам, вероятно, понадобится полноценная очередь плюс персистентное хранилище состояния задач.
Модель пула воркеров простыми словами
Пул воркеров на Go сознательно скучен: положить работу в очередь, иметь фиксированное количество воркеров, которые её вытягивают, и обеспечить возможность корректно остановить весь механизм.
Базовые термины:
- Задача (Job): одна единица работы, например «изменить размер изображения» или «отправить письмо со счётом».
- Очередь: место, где задачи ждут.
- Воркер: горутина, которая повторно берёт задачу и выполняет её.
- Диспетчер: часть, которая принимает задачи и кладёт их в очередь.
Во многих дизайнах в процессе выполнения очередь — это Go канал. Буферизированный канал может держать ограниченное число задач до блокировки производителей. Такая блокировка — это обратное давление (backpressure), и часто именно оно не даёт сервису принимать бесконечную работу и расходовать всю память при всплесках трафика.
Размер буфера меняет поведение системы. Маленький буфер делает давление заметным быстро (вызыватель ждёт раньше). Большой буфер сглаживает короткие всплески, но может скрывать перегрузку до более позднего момента. Идеального числа нет — есть число, которое соответствует тому, сколько ожидания вы готовы терпеть.
Также вы выбираете, фиксирован ли размер пула или он может изменяться. Фиксированные пулы проще для понимания и держат использование ресурсов предсказуемым. Автоматическое масштабирование воркеров помогает при неравномерной нагрузке, но добавляет решений, которыми придётся управлять (когда масштабировать, на сколько и когда уменьшать).
Наконец, «ack» в ин-процесс пуле обычно просто означает «воркер завершил задачу и вернул отсутствие ошибки». Нет внешнего брокера, который подтверждает доставку, поэтому ваша логика определяет, что значит «сделано» и что происходит при ошибке или отмене.
Цели дизайна: повторы, отмена и корректное завершение
Механика пула воркеров проста: запустить фиксированное число воркеров, подать им задачи и обрабатывать их. Ценность в контроле: предсказуемая конкуррентность, чёткая обработка ошибок и путь завершения, который не оставляет наполовину выполненной работы.
Три цели, которые сохранят разум маленькой команды:
- Ограничить конкуррентность, чтобы один всплеск не расплавил базу данных или внешний API.
- Не терять работу (или по крайней мере точно знать, что и почему было отброшено).
- Оставаться отлаживаемыми: каждая задача должна быть прослеживаема через логи и несколько счётчиков.
Большинство сбоев рутинные, но их всё равно стоит обрабатывать по-разному:
- Временные ошибки (сбои сети, лимиты) — следует пробовать снова.
- Постоянные ошибки (некорректные данные, отсутствующая запись) — не нужно повторять.
- Таймауты (зависимость зависла) — нужно обрезать, чтобы воркеры не забивались.
Отмена — это не то же самое, что «ошибка». Это решение: пользователь отменил, деплой заменил процесс, или сервис завершает работу. В Go относитесь к отмене как к первоклассному сигналу через context cancellation и убедитесь, что каждая задача проверяет контекст перед началом дорогостоящей работы и в нескольких безопасных точках во время выполнения.
Корректное завершение — место, где многие пулы разваливаются. Решите заранее, что значит «безопасно» для ваших задач: закончить текущую работу или остановиться быстро и перезапустить позже? Практичный поток действий:
- Перестать принимать новые задачи.
- Сказать воркерам остановиться после текущей задачи (или остановиться немедленно).
- Подождать до дедлайна, затем принудительно выйти.
Если вы определите эти правила заранее, повторы, отмена и завершение останутся небольшими и предсказуемыми, вместо того чтобы превратиться в самописный фреймворк.
Пошагово: создание базового пула воркеров
Пул воркеров — это просто группа горутин, вытягивающих задачи из канала и выполняющих их. Важная часть — сделать базовые вещи предсказуемыми: как выглядит задача, как воркеры останавливаются и как понять, что вся работа завершена.
Начните с простого типа Job. Дайте ему ID (для логов), полезную нагрузку (что обрабатывать), счётчик попыток (полезно для повторов), временные метки и место для хранения контекста per-job.
package jobs
import (
"context"
"sync"
"time"
)
type Job struct {
ID string
Payload any
Attempt int
Enqueued time.Time
Started time.Time
Ctx context.Context
Meta map[string]string
}
type Pool struct {
ctx context.Context
cancel context.CancelFunc
jobs chan Job
wg sync.WaitGroup
}
func New(size, queue int) *Pool {
ctx, cancel := context.WithCancel(context.Background())
p := \u00026Pool{ctx: ctx, cancel: cancel, jobs: make(chan Job, queue)}
for i := 0; i \u0003c size; i++ {
go p.worker(i)
}
return p
}
func (p *Pool) worker(_ int) {
for {
select {
case \u0003c-p.ctx.Done():
return
case job, ok := \u0003c-p.jobs:
if !ok {
return
}
p.wg.Add(1)
job.Started = time.Now()
_ = job // call your handler here
p.wg.Done()
}
}
}
// Submit blocks when the queue is full (backpressure).
func (p *Pool) Submit(job Job) error {
if job.Enqueued.IsZero() {
job.Enqueued = time.Now()
}
select {
case \u0003c-p.ctx.Done():
return context.Canceled
case p.jobs \u0003c- job:
return nil
}
}
func (p *Pool) Stop() { p.cancel() }
func (p *Pool) Wait() { p.wg.Wait() }
Пару практических выборов, которые вы сделаете сразу:
- Выберите размер очереди в зависимости от того, сколько ожидания вы готовы терпеть.
- Решите, что значит обратное давление для вызывающих: блокировать, вернуть ошибку или отбросить.
- Держите
Stop()иWait()отдельно, чтобы сначала остановить приём, а затем дождаться завершения текущей работы.
Добавление повторов, не превращая это в фреймворк
Повторы полезны, но именно там пулы воркеров становятся грязными. Сузьте цель: повторять только тогда, когда другая попытка действительно имеет шанс на успех, и быстро останавливаться, когда шансов нет.
Начните с решения, что считается повторяемым. Временные проблемы (сбои сети, таймауты, ответы «попробуйте позже») обычно стоит повторить. Постоянные (некорректные данные, отсутствующая запись, отказ в доступе) — не стоит.
Небольшая политика повторов обычно достаточна:
- Отмечайте ошибки как повторяемые или нет (например, оборачивайте их с помощью
Retryable(err)хелпера). - Установите максимум попыток (часто 3–5). Слишком много — пустая трата времени.
- Используйте экспоненциальный backoff с джиттером, чтобы задачи не повторялись синхронно.
- Ограничьте задержку (например, никогда не спать более 30 секунд).
- Логируйте повторы с номером попытки, следующей задержкой и ID задачи.
Backoff не должен быть сложным. Общая формула: delay = min(base * 2^(attempt-1), max), затем добавьте джиттер (рандомизируйте на ±20%). Джиттер важен, потому что иначе многие воркеры упадут одновременно и будут повторяться одновременно.
Где хранить задержку? Для маленьких систем спать внутри воркера нормально, но это занимает слот воркера. Если повторы редки, это приемлемо. Если повторы частые или задержки длинные, подумайте о повторном помещении задачи в очередь с меткой «run after», чтобы воркеры были заняты другой работой.
При окончательном провале будьте явны. Сохраняйте упавшую задачу (и последнюю ошибку) для просмотра, логируйте достаточно контекста для повторного запуска или отправляйте её в dead list, который вы проверяете регулярно. Избегайте тихих падений. Пул, который скрывает ошибки, хуже, чем отсутствие повторов.
Отмена и таймауты, которые действительно останавливают работу
Own the generated source code
Get full Go, React, and database code you can own and extend.
Пулы воркеров кажутся безопасными только тогда, когда вы можете их остановить. Простое правило: передавайте context.Context через все слои, которые могут блокироваться. Это значит — при отправке, при выполнении и при очистке.
Практичная настройка использует два предела времени:
- Таймаут на задачу — чтобы одна задача не занимала воркер вечно.
- Таймаут завершения — чтобы процесс мог выйти, даже если некоторые задачи не хотят сотрудничать.
Используйте контекст от начала до конца
Дайте каждой задаче собственный контекст, производный от контекста воркера. Тогда каждый медленный вызов (БД, HTTP, очереди, файловый ввод/вывод) должен принимать этот контекст, чтобы возвращаться раньше.
func worker(ctx context.Context, jobs \u0003c-chan Job) {
for {
select {
case \u0003c-ctx.Done():
return
case job, ok := \u0003c-jobs:
if !ok { return }
jobCtx, cancel := context.WithTimeout(ctx, job.Timeout)
_ = job.Run(jobCtx) // Run must respect jobCtx
cancel()
}
}
}
Если Run вызывает вашу БД или API, подключайте контекст к этим вызовам (например, QueryContext, NewRequestWithContext или методы клиента, принимающие context). Если вы проигнорируете его в одном месте, отмена станет «best effort» и обычно отказывает в самый нужный момент.
Частичная работа и шаги «безопасные для повтора»
Отмена может произойти в середине задачи, поэтому предполагайте, что частичная работа — нормально. Стремитесь к идемпотентным шагам, чтобы повторные запуски не создавали дубликаты. Часто используют уникальные ключи для вставок (или upsert), пишут маркеры прогресса (started/done), сохраняют результаты до продолжения и проверяют ctx.Err() между шагами.
Рассматривайте shutdown как дедлайн: перестаньте принимать новые задачи, отмените контексты воркеров и ждите только до таймаута завершения для выхода текущих задач.
Корректное завершение: что делать, когда процесс должен выйти
Корректное завершение преследует одну цель: перестать принимать новую работу, сказать выполняющейся работе остановиться и выйти, не оставив систему в странном состоянии.
Начните с сигналов. В большинстве сред вы увидите SIGINT локально и SIGTERM от менеджера процессов или контейнерного рантайма. Используйте shutdown context, который отменяется при приходе сигнала, и передавайте его в пул и обработчики задач.
Дальше перестаньте принимать новые задачи. Не позволяйте вызывающим заблокироваться навсегда, пытаясь отправить в канал, который уже никто не читает. Держите отправку за одной функцией, которая проверяет флаг закрытия или выбирает на shutdown context перед отправкой.
Затем решите, что делать с очередью:
- Дренировать: закончить уже поставленные в очередь задачи, но отклонять новые.
- Отбрасывать: отбросить всё, что ещё не начато.
Дренирование безопаснее для платежей и писем. Отбрасывание подходит для «приятно иметь» задач, например пересчёта кеша.
Практическая последовательность для shutdown:
- Поймать SIGINT/SIGTERM и отменить общий контекст.
- Остановить приём (закрыть путь отправки, но не обязательно канал работы).
- Дать воркерам закончить или прервать по контексту.
- Ждать воркеров с WaitGroup.
- Принудительно выйти по дедлайну.
Дедлайн важен. Например, дайте выполняющимся задачам 10 секунд на остановку. По его истечении залогируйте, что всё ещё работает, и выходите. Это делает деплои предсказуемыми и избегает зависших процессов.
Логирование и простая метрика для пулов воркеров
Generate a worker pool starter
Describe your jobs and get a Go + PostgreSQL scaffold to start fast.
Когда пул воркеров ломается, он редко ломается громко. Задачи замедляются, повторы накапливаются, и кто-то жалуется, что «ничего не происходит». Логи и пара счётчиков превращают это в понятную картину.
Давайте каждой задаче стабильный ID (или генерируйте при отправке) и включайте его в каждую строку лога. Держите логи консистентными: одна строка при старте задачи, одна при завершении и одна при ошибке. Если вы повторяете, логируйте номер попытки и следующую задержку.
Простой шаблон логов:
- start: job_id, worker_id, attempt, kind
- finish: job_id, worker_id, attempt, duration_ms
- fail/retry: job_id, worker_id, attempt, err, next_delay_ms
Метрики можно держать минимальными и всё равно получить эффект. Отслеживайте длину очереди, количество выполняющихся задач, общее число успехов и неудач, а также задержку задач (хотя бы среднюю и максимальную). Если длина очереди растёт, а выполняющихся задач ровно столько, сколько воркеров, значит вы насыщены. Если отправители блокируются при записи в канал задач, обратное давление дошло до вызывающего — это не всегда плохо, но должно быть осознанно.
Когда «задачи зависают», проверьте, получает ли процесс ещё задачи, растёт ли длина очереди, живы ли воркеры и какие задачи выполняются дольше всего. Длительное время выполнения обычно указывает на пропущенные таймауты, медленные зависимости или бесконечный цикл повторов.
Реалистичный пример: небольшая SaaS-очередь для фоновых задач
Представьте небольшую SaaS-систему, где заказ переходит в состояние PAID. Сразу после оплаты нужно сгенерировать PDF счёта, отправить письмо клиенту и уведомить внутреннюю команду. Вы не хотите, чтобы это блокировало веб-запрос. Это хороший кейс для пула воркеров: работа реальная, но система ещё небольшая.
Полезная нагрузка задачи может быть минимальной: столько, чтобы подгрузить остальное из базы. Обработчик API пишет строку вроде jobs(status='queued', type='send_invoice', payload, attempts=0) в той же транзакции, что и обновление заказа, затем фоновый цикл опрашивает таблицу queued jobs и пихает их в канал воркеров.
type SendInvoiceJob struct {
OrderID string
CustomerID string
Email string
}
Когда воркер берёт задачу, счастливый путь прост: загрузить заказ, сгенерировать счёт, вызвать провайдера почты и отметить задачу как выполненную.
Повторы — вот где всё становится серьёзно. Если у провайдера почты временный простой, вы не хотите, чтобы 1000 задач упали навсегда или штурмовали провайдера каждую секунду. Практичный подход:
- Считать сетевые ошибки и 5xx ответы повторяемыми.
- Использовать экспоненциальный backoff с максимальной задержкой (например, 5s, 15s, 45s, 2m).
- Ограничить число попыток (например, 10) и затем пометить задачу как failed.
- Записать последнюю ошибку, чтобы саппорт видел, что случилось.
Во время простоя задачи движутся из queued в in_progress, затем обратно в queued с меткой будущего времени выполнения. Когда провайдер восстановится, воркеры естественно осушат бэклог.
Теперь представьте деплой. Вы отправляете SIGTERM. Процесс должен перестать принимать новую работу, но закончить уже запущенную. Остановите опрос, перестаньте наполнять канал воркеров и подождите воркеров в рамках дедлайна. Задачи, которые завершились, помечаются как done. Те, что всё ещё выполняются к моменту дедлайна, нужно пометить обратно как queued (или оставить как in_progress с watchdog), чтобы они могли быть подобраны после старта новой версии.
Распространённые ошибки и ловушки
Большинство багов в фоновой обработке — не в логике задач. Они происходят из ошибок координации, которые проявляются только при нагрузке или во время завершения.
Классическая ловушка — закрытие канала из более чем одного места. Результат — panic, который тяжело воспроизвести. Назначьте одного владельца для каждого канала (обычно производителя) и сделайте его единственным, кто вызывает close(jobs).
Повторы — другая зона, где благие намерения приводят к авариям. Если повторять всё подряд, вы будете повторять и постоянные ошибки. Это тратит время, увеличивает нагрузку и может превратить мелкую проблему в инцидент. Классифицируйте ошибки и ограничьте повторы чёткой политикой.
Дубликаты будут случаться даже при аккуратном дизайне. Воркеры могут упасть во время задачи, таймаут может сработать после того, как работа уже завершена, или вы можете переочередить задачу во время деплоя. Если задача не идемпотентна, дубликаты наносят реальный ущерб: два счёта, два приветственных письма, два возврата денежных средств.
Частые ошибки:
- Закрытие одного и того же канала из нескольких горутин.
- Повтор попыток постоянных ошибок вместо их поднятия.
- Отсутствие идемпотентного ключа, из‑за чего дубликаты вызывают побочные эффекты.
- Неограниченные in-memory очереди, которые растут до пиков использования памяти.
- Игнорирование
context.Context, из‑за чего работа продолжается после старта завершения.
Неограниченные очереди особенно коварны. Всплеск работы может тихо набраться в RAM. Предпочитайте ограниченный буфер канала и решите заранее, что делать при заполнении: блокировать, отбросить или вернуть ошибку.
Быстрая чек‑листа перед релизом
Deploy your background worker
Deploy your Go app with hosting support when you are ready to run it.
Перед тем как пустить пул воркеров в продакшен, вы должны уметь вслух описать жизненный цикл задачи. Если кто‑то спросит «где сейчас эта задача?», ответ не должен быть предположением.
Практическая предполётная чек‑лист:
- Вы умеете назвать каждое состояние и переход: queued, picked up, running, finished, failed (и что их переводит).
- Конкуррентность — один единственный регулятор (например,
workerCount), и изменение его не требует переписывания кода. - Повторы ограничены: максимум попыток понятен, backoff растёт, а постоянные ошибки уходят в предназначенное место.
- Поведение при завершении проверено: вы останавливаете приём, даёте текущим задачам закончить, и у вас есть жёсткий таймаут.
- Логи отвечают на базовые вопросы: job ID, номер попытки, длительность и причина ошибки.
Проведите одну реалистичную тренировку перед релизом: поставьте в очередь 100 задач «отправить чек», заставьте 20 из них падать, затем перезапустите сервис в середине выполнения. Вы должны увидеть ожидаемое поведение повторов, отсутствие дублирующих побочных эффектов и реальную остановку работы при достижении дедлайна.
Если что‑то неясно — поправьте это сейчас. Небольшие правки здесь сэкономят дни в будущем.
Следующие шаги: когда добавить тяжёлую инфраструктуру (а когда нет)
Простой in‑process пул часто достаточен, пока продукт молод. Если задачи «приятно иметь» (отправка писем, обновление кеша, генерация отчётов) и вы можете их перезапустить, пул воркеров делает систему простой для понимания.
Признаки, что вы перерасли in‑process пул
Наблюдайте за этими признаками:
- У вас несколько инстансов приложения, и нужен только один, который будет подбирать задачу.
- Вам нужна надёжность (jobs должны переживать крахи и деплои).
- Нужен аудиторский след: кто что поставил, когда выполнилось и с каким результатом.
- Нужен контроль обратного давления между сервисами, не только внутри процесса.
- Нужен строгий планировщик или долгие задержки (часы или дни) с гарантией пробуждения.
Если ничего из этого не про вас, тяжёлые инструменты могут добавить больше подвижных частей, чем ценности.
Миграция постепенно, без переписывания
Лучший хедж — стабильный интерфейс задач: маленький тип payload, ID и хендлер, возвращающий понятный результат. Тогда можно поменять бекенд очереди позже (из in‑memory channel → таблица в базе → затем очередь) без изменения бизнес‑логики.
Практический промежуточный шаг — небольшой Go‑сервис, который читает задачи из PostgreSQL, захватывает их блокировкой и обновляет статус. Вы получаете устойчивость и базовую аудитируемость, сохраняя логику воркера.
Если хотите быстро прототипировать, Koder.ai (koder.ai) может сгенерировать стартовый Go + PostgreSQL проект по описанию в чате, включая таблицу фоновых задач и цикл воркера, а его снапшоты и откаты помогут при настройке повторов и поведения завершения.