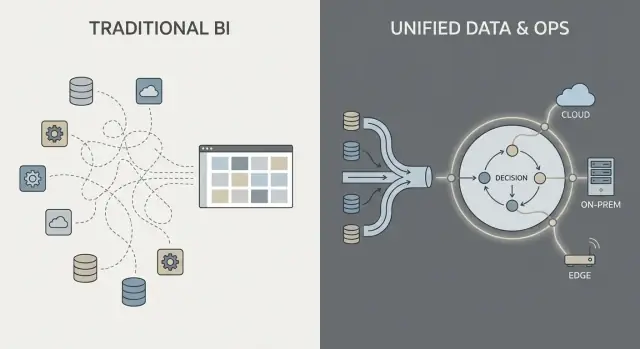
Что здесь подразумевается под «Palantir» и «традиционным корпоративным ПО"\n\nЛюди часто употребляют «Palantir» как сокращение для нескольких связанных продуктов и общего подхода к построению управляемых данными операций. Чтобы сравнение было понятным, полезно уточнить, о чём именно идёт речь — и о чём нет.\n\n### Что в этой статье называется «Palantir»\n\nВ корпоративном контексте «Palantir» обычно означает один (или несколько) из следующих элементов:\n\n- Foundry: коммерческая платформа Palantir, сосредоточенная на интеграции данных, их моделировании и поддержке операционного принятия решений.\n- Gotham: часто ассоциируется с обороной и госсектором, схожие идеи, но другая история и позиционирование.\n- Apollo: система доставки и управления, используемая для доставки и поддержки ПО в различных средах (включая изолированные).\n\nВ этой статье под «Palantir‑подобным» подходом понимается сочетание (1) мощной интеграции данных, (2) семантического/онтологического слоя, который выравнивает команды по смыслу, и (3) паттернов развертывания, охватывающих облако, on‑prem и отключённые среды.\n\n### Что здесь называется «традиционным корпоративным ПО»\n\n«Традиционное корпоративное ПО» — это не один продукт, а типичный стек, который многие организации собирают со временем, например:\n\n- ERP и CRM (системы учёта для финансов, цепочки поставок, продаж)\n- Хранилище данных или дата‑озеро плюс BI‑дашборды (средства отчётности и аналитики)\n- Интеграционная прослойка (ETL/ELT‑инструменты, iPaaS, очереди сообщений, API)\n\nВ таком подходе интеграция, аналитика и операции часто обрабатываются разными инструментами и командами, связанные через проекты и процессы управления.\n\n### Что это сравнение такое — и чего оно не делает\n\nЭто сравнение подходов, а не реклама вендора. Многие организации успешно работают с традиционными стеками; другим выгодна более единая платформа.\n\nПрактический вопрос: какие компромиссы вы делаете в скорости, контроле и в том, насколько напрямую аналитика связана с повседневной работой?\n\nЧтобы текст оставался предметным, мы сосредоточимся на трёх областях:\n\n1. Интеграция данных: как данные подключаются, поддерживаются и кем владеют ими\n2. Операционная аналитика: как аналитика выходит за рамки дашбордов и переходит в принятие решений\n3. Модели развертывания: облако, on‑prem и реальности с отключённой связью\n\n## Интеграция данных: конвейеры и ответственность\n\nБольшая часть работы с данными в «традиционном корпоративном ПО» следует знакомой цепочке: вытянуть данные из систем (ERP, CRM, логи), трансформировать их, загрузить в хранилище или озеро, а затем построить BI‑дашборды и несколько downstream‑приложений.\n\nЭтот паттерн может работать, но часто превращает интеграцию в серию хрупких передач: одна команда владеет скриптами выгрузки, другая — моделями в хранилище, третья — определениями дашбордов, а бизнес‑команды поддерживают таблицы в электронных таблицах, которые тайно переопределяют «реальные» числа.\n\n### Традиционный паттерн: ETL/ELT как эстафета\n\nС ETL/ELT изменения обычно расходятся волнами. Новое поле в системе источника может сломать конвейер. «Быстрая починка» порождает второй конвейер. Вскоре метрик становится несколько («выручка» в трёх местах), и непонятно, кто отвечает, если числа не совпадают.\n\nЗдесь часто используют пакетную обработку: данные приходят ночью, дашборды обновляются утром. Почти реальное время возможно, но обычно это отдельный стриминговый стек с собственными инструментами и владельцами.\n\n### Palantir‑подобный паттерн: интегрировать, стандартизировать смысл и затем переиспользовать\n\nПодход в духе Palantir стремится объединять источники и применять единые семантические определения (определения, связи и правила) на раннем этапе, а затем открывать те же куратированные данные для аналитики и операционных рабочих процессов.\n\nПроще говоря: вместо того чтобы каждое приложение или дашборд «выясняли», что такое клиент, актив, случай или отгрузка, это значение определяется один раз и переиспользуется. Это снижает дублирование логики и делает ответственность яснее — когда определение меняется, вы знаете, где оно живёт и кто его утверждает.\n\n### Частые болевые точки, на которые стоит обратить внимание\n\nИнтеграция обычно рушится не из‑за коннекторов, а из‑за ответственности:\n\n- Хрупкие конвейеры, которые ломаются при незначительных изменениях в источнике\n- Дублированные метрики, определённые по‑разному в разных командах\n- Неясная собственность на качество данных, определения и исправления\n\nКлючевой вопрос: не просто «можем ли мы подключиться к системе X?», а «кто владеет конвейером, определениями метрик и бизнес‑смыслом со временем?"\n\n## Семантический слой и онтология: другая точка притяжения\n\nТрадиционное корпоративное ПО часто рассматривает «смысл» как вторичный элемент: данные хранятся в множестве схем, определения метрик живут внутри отдельных дашбордов, а команды тихо поддерживают свои версии «что такое заказ» или «когда кейс считается решённым». Результат знаком: разные числа в разных местах, долгие встречи по сверке и неясная ответственность при рассогласовании.\n\n### Онтология, простыми словами\n\nВ Palantir‑подобном подходе семантический слой — это не просто удобство для отчётов. Онтология выступает как общий бизнес‑модель, которая определяет:\n\n- Сущности (вещи, важные для бизнеса): Заказ, Клиент, Актив, Отгрузка, Кейс\n- Связи (как эти вещи связаны): Заказ принадлежит Клиенту; Отгрузка выполняет Заказ; Актив установлен в Локации\n- Действия (что с ними делают люди): утвердить, отправить, эскалировать, списать, вернуть\n\nЭто становится «центром тяжести» для аналитики и операций: источники могут оставаться разными, но они маппятся на общий набор бизнес‑объектов с единообразными определениями.\n\n### Почему семантика важнее, чем ожидают многие\n\nОбщая модель уменьшает несоответствия чисел, потому что команды не придумывают определения заново в каждом отчёте или приложении. Она также повышает ответственность: если «доставка вовремя» считается по событиям Отгрузки в онтологии, становится понятнее, кто отвечает за базовые данные и бизнес‑логику.\n\n### Практические примеры\n\n- Заказы: отделы продаж, финансов и поддержки видят один и тот же объект Заказ с состоянием, стоимостью, утверждениями и исключениями — никаких отдельных «таблиц заказов» для каждого департамента.\n- Актывы: техобслуживание, операции и комплаенс работают с одним Записью Активов с местоположением, историей проверок и флагами риска.\n- Кейсы: обращения поддержки связаны с клиентами, заказами и отгрузками, поэтому правила эскалации и метрики сервиса не расходятся по командам.\n\nХорошо реализованная онтология не только делает дашборды чище — она ускоряет и упрощает принятие ежедневных решений.\n\n## Операционная аналитика против BI‑дашбордов\n\nBI‑дашборды и традиционная отчётность прежде всего про ретроспективу и мониторинг. Они отвечают на вопросы «Что произошло на прошлой неделе?» или «Мы в рамках KPI?». Продвинутые отчёты полезны, но часто останавливаются на уровне видимости.\n\nОперационная аналитика иная: это аналитика, встроенная в повседневные решения и исполнение. Анализ появляется внутри рабочего процесса и приводит к конкретному следующему шагу.\n\n### BI: наблюдать и объяснять\n\nBI и отчётность обычно фокусируются на:\n\n- стандартизованных метриках и определениях KPI\n- запланированных обновлениях и еженедельных/ежемесячных обзорах\n- агрегированных представлениях (команды, регионы, периоды)\n- исследовании корней проблемы после наступления результата\n\nЭто отлично для управления, оценки эффективности и ответственности.\n\n### Операционная аналитика: решать и делать\n\nОперационная аналитика делает упор на:\n\n- сигналы в реальном или близком к реальному времени\n- поддержку решения в момент действия\n- рекомендации, приоритезацию и обработку исключений\n- петли обратной связи (сработало ли действие, и что изменилось?)\n\nКонкретные примеры больше похожи не на «график», а на очередь задач с контекстом:\n\n- Диспетчеризация: выбор задания для бригады с учётом местоположения, навыков, SLA и наличия запчастей\n- Распределение запасов: решение, куда направить ограниченный запас, чтобы снизить бэклаты и пропущенные поставки\n- Триаж мошенничества: ранжирование кейсов по риску и маршрутизация к следователям с нужными доказательствами\n- Планирование техобслуживания: прогнозирование отказов и планирование простоев с учётом производственных ограничений\n\n### Ключевой сдвиг: от «видеть» к «действовать»\n\nГлавное изменение в том, что анализ привязан к конкретному шагу рабочего процесса. BI‑дашборд может показать «увеличение просрочек по доставкам». Операционная аналитика превращает это в «вот 37 отгрузок под риском сегодня, вероятные причины и рекомендованные вмешательства» с возможностью немедленно выполнить или назначить следующее действие.\n\n## От инсайтов к действиям: дизайн, ориентированный на рабочие процессы\n\nТрадиционная корпоративная аналитика часто заканчивается видом дашборда: кто‑то замечает проблему, экспортирует CSV, отправляет по почте, и отдельная команда «что‑то делает» позже. Palantir‑подобный подход стремится сократить этот разрыв, встраивая аналитику прямо в рабочий процесс, где принимают решения.\n\n### Человеко‑в‑цепочке решения (не автопилот)\n\nСистемы, ориентированные на рабочие процессы, обычно генерируют рекомендации (напр., «приоритизируйте эти 12 отправок», «пометьте этих 3 поставщиков», «запланируйте техобслуживание в течение 72 часов»), но всё ещё требуют явных утверждений. Этап утверждения важен, потому что он создаёт:\n\n- Ответственность за решение: кто утвердил, когда и на основании каких данных\n- Аудит‑трейсы: зафиксированная цепочка от входных данных → логики/модели → рекомендации → действия\n- Контролируемые исключения: операторы могут переопределить с указанием причины, а не обходить инструмент\n\nЭто особенно актуально в регулируемых или критичных операциях, где «модель так сказала» — неприменимое оправдание.\n\n### Рабочие процессы заменяют «передачу отчёта»\n\nВместо того чтобы считать аналитику отдельной целью, интерфейс может направлять инсайты в задачи: назначить в очередь, запросить подпись, отправить уведомление, открыть кейс или создать наряд. Важно, что результаты отслеживаются внутри той же системы — так вы можете измерить, действительно ли действия уменьшили риск, стоимость или задержки.\n\n### Ролевые интерфейсы и права принятия решений\n\nДизайн, ориентированный на рабочие процессы, обычно разделяет интерфейсы по ролям:\n\n- Фронтлайн‑операторы: быстрые очереди, понятный следующий шаг, минимальный необходимый контекст\n- Аналитики: детальные возможности исследования, тестирования сценариев и мониторинга качества данных/моделей\n- Руководство: KPI, привязанные к пропускной способности операций и узким местам, а не только к графикам\n\nОбщий фактор успеха — выравнивание продукта с правами принятия решений и регламентами: кто может действовать, какие утверждения требуются и что означает «выполнено» операционно.\n\n## Управление, безопасность и доверие к данным\n\nУправление — это то место, где многие программы аналитики либо добиваются успеха, либо останавливаются. Это не просто «настройки безопасности» — это практический набор правил и доказательств, позволяющих людям доверять цифрам, безопасно делиться ими и использовать их для реальных решений.\n\n### Что должно покрывать управление (кроме входа в систему)\n\nБольшинству предприятий нужны одни и те же основные контролы, независимо от вендора:\n\n- Контроль доступа: кто может видеть, редактировать или утверждать данные, модели и операционные выходные данные\n- Прослеживаемость данных: откуда пошла метрика, какие источники её сформировали и какие трансформации применялись\n- Журналы аудита: надёжная запись того, кто что и когда изменял\n- Утверждения и управление изменениями: особенно для «официальных» метрик, общих наборов данных и рабочих процессов в продакшене\n\nЭто не бюрократия ради бюрократии. Это способ предотвратить проблему «двух версий истины» и снизить риск, когда аналитика приближается к операциям.\n\n### «Безопасность на уровне дашборда» vs безопасность по всей цепочке\n\nТрадиционные BI‑реализации часто фокусируют безопасность главным образом на слое отчётов: пользователи видят определённые дашборды, администраторы управляют правами там. Такой подход работает, когда аналитика в основном описательная.\n\nPalantir‑подобный подход распространяет безопасность и управление на всю цепочку: от сырых данных при приёме, через семантический слой (объекты, связи, определения), до моделей и даже до действий, запускаемых по результатам инсайтов. Цель — чтобы операционное решение (диспетчеризация, выпуск запаса, приоритезация кейса) наследовало те же контролы, что и данные, на которых оно основано.\n\n### Принцип наименьших привилегий и разделение обязанностей\n\nДва принципа важны для безопасности и подотчётности:\n\n- Наименьшие привилегии: людям даётся только тот доступ, который им необходим для работы\n- Разделение обязанностей: тот, кто создаёт или меняет логику, не тот, кто её утверждает для продакшена\n\nНапример, аналитик может предложить определение метрики, data‑стюард утверждает его, а операционный персонал использует — при этом сохраняется прозрачный журнал действий.\n\n### Почему управление стимулирует принятие\n\nХорошее управление нужно не только для команд комплаенса. Когда бизнес‑пользователи могут кликнуть и увидеть происхождение данных, определения и правила доступа, они перестают спорить из‑за таблиц и начинают действовать. Это уверенность, которая превращает аналитику из «интересных отчётов» в реальное операционное поведение.\n\n## Модели развертывания: облако, on‑prem и отключённые среды\n\nГде запускается корпоративное ПО — это уже не мелочь IT: это определяет, что можно делать с данными, как быстро вы можете менять систему и какие риски вы готовы принять. Покупатели обычно оценивают четыре модели развертывания.\n\n### Публичное облако\n\nПубличное облако (AWS/Azure/GCP) оптимизировано для скорости: быстрое выделение ресурсов, управляемые сервисы уменьшают работу с инфраструктурой, а масштабирование — простая операция. Главные вопросы покупателя — резидентность данных (регион, бэкапы, доступ поддержки), интеграция с on‑prem системами и выдержит ли ваша модель безопасности облачную сетевую доступность.\n\n### Частное облако\n\nЧастное облако (single‑tenant или управляемые клиентом Kubernetes/VM) выбирают, когда нужна облачная автоматизация, но более жёсткий контроль сетевых границ и требований аудита. Это снижает часть трений соответствия, но требует дисциплины в операциях — патчи, мониторинг, ревью доступа.\n\n### On‑prem\n\nOn‑prem всё ещё широко используется в производстве, энергетике и сильно регулируемых секторах, где ядро систем и данные не могут покидать объект. Компромисс — операционные издержки: жизненный цикл железа, планирование ёмкости и больше работы по поддержанию согласованности сред dev/test/prod. Если организация плохо справляется с управлением платформами, on‑prem может замедлить время до ценности.\n\n### Отключённые / air‑gapped\n\nОтключённые (air‑gapped) среды — особый случай: оборона, критическая инфраструктура или площадки с ограничённой связью. Здесь модель развертывания должна поддерживать строгий контроль обновлений — подписанные артефакты, контролируемое продвижение релизов и повторяемую установку в изолированных сетях.\n\nСетевые ограничения также влияют на перемещение данных: вместо непрерывного синка вы можете полагаться на поэтапные перенесения и «экспорт/импорт» рабочих процессов.\n\n### Ключевые компромиссы\n\nНа практике это треугольник: гибкость (облако), контроль (on‑prem/air‑gapped) и скорость изменений (автоматизация + обновления). Правильный выбор зависит от правил резидентности, сетевых реалий и того, сколько операций платформы вы готовы держать на себе.\n\n## Операционализация обновлений: что меняет delivery в духе Apollo\n\n«Доставка в духе Apollo» — это по сути непрерывная доставка для сред с повышенными требованиями: вы можете поставлять улучшения часто (еженедельно, ежедневно, даже несколько раз в день), сохраняя при этом стабильность операций.\n\nЦель не в «бежать быстро и всё ломать». Цель — «часто доставлять и ничего не ломать».\n\n### Непрерывная доставка простыми словами\n\nВместо свёртывания изменений в большой квартальный релиз, команды поставляют маленькие, обратимые обновления. Каждое обновление проще тестировать, объяснять и откатить при необходимости.\n\nДля операционной аналитики это важно, потому что ваше «ПО» — это не только UI, а данные, конвейеры, бизнес‑логика и рабочие процессы, от которых люди зависят. Надёжный процесс обновлений становится частью повседневных операций.\n\n### Чем это отличается от традиционных циклов обновлений\n\nТрадиционные обновления корпоративного ПО чаще выглядят как проекты: длительное планирование, координация простоев, проблемы совместимости, переобучение и жёсткая дата переключения. Даже при наличии патчей многие организации откладывают обновления, потому что риски и усилия непредсказуемы.\n\nИнструменты в духе Apollo стремятся сделать обновления рутинными, а не исключительными — больше похоже на обслуживание инфраструктуры, чем на крупную миграцию.\n\n### Разделение «разработки» и «доставки»\n\nСовременные инструменты развертывания позволяют командам разрабатывать и тестировать в изолированных средах, а затем «продвигать» ту же сборку через стадии (dev → test → staging → production) с едиными контролями. Такое разделение помогает уменьшить сюрпризы, связанные с различиями между средами.\n\n### Вопросы к вендору\n\n- Как вы откатываете изменения — одним кликом, частичным откатом или сложным восстановлением?\n- Что с версионированием конвейеров, моделей и изменений онтологии (не только UI)?\n- Как работает продвижение среды и кто может его утверждать?\n- Поддерживаете ли вы канареечные релизы или feature‑флаги?\n- Какой журнал показывает, кто что и когда доставлял и почему?\n- Какое ожидаемое время простоя — идеалом является нулевой — при типичных обновлениях?\n\n## Внедрение и время до ценности: где действительно требуется усилие\n\nВремя до ценности — это не столько про скорость установки, сколько про то, как быстро команды согласятся на определения, подключат грязные данные и превратят инсайты в повседневные решения.\n\n### Стилы внедрения: конфигурировать, собирать или разрабатывать\n\nТрадиционное корпоративное ПО часто делает ставку на конфигурацию: вы принимаете предопределённую модель данных и рабочие процессы, затем маппите ваш бизнес под них.\n\nPalantir‑подобные платформы обычно смешивают три режима:\n\n- Конфигурация для контроля доступа, подключений данных и стандартных компонентов\n- Переиспользуемые блоки (шаблоны, компоненты, паттерны), которые можно собирать в новые кейсы\n- Кастомная разработка приложений, когда рабочий процесс уникален (напр., утверждения, обработка исключений, операционные передачи)
Обещание — гибкость, но это также значит, что нужно понимать, что вы строите, а что стандартизируете.\n\nПрактический вариант на ранней стадии — быстро прототипировать рабочие приложения до масштабного развёртывания. Например, команды иногда используют (платформа vibe‑coding), чтобы превратить описание рабочего процесса в рабочее веб‑приложение через чат, а затем итеративно согласовывать с заинтересованными сторонами, используя , и . Поскольку Koder.ai поддерживает и типичные production‑стэки (React для фронтенда; Go + PostgreSQL для бэкенда; Flutter для мобильных клиентов), это может быть низкопороговым способом валидировать UX «инсайт → задача → журнал аудита» и требования интеграции в ходе proof‑of‑value.\n\n### Где команды на самом деле тратят время\n\nБольшая часть усилий обычно уходит на четыре области:\n\n1. получение доступа от владельцев источников, документирование полей, обработка разрывов качества и установка ожиданий по обновлениям\n2. согласование бизнес‑определений (что считается «активным», «просроченным», «доступным») и их поддержание\n3. кто реагирует на оповещения, какие решения разрешены и что означает «выполнено»\n4. превращение инструмента в привычку — особенно для фронтлайн‑пользователей, которые не потерпят сложности\n\n### Красные флаги, которые тормозят или убивают ценность\n\nСледите за (нет владельца данных/продукта), (каждая команда придумывает свои метрики) и (демо, которое нельзя ввести в эксплуатацию, поддерживать или обеспечить управление).\n\n### Как строить пилот, который масштабируется\n\nХороший пилот целенаправленно узок: выберите , определите и зафиксируйте (например, сократить время обработки на 15%, уменьшить запас исключений на 30%). Спроектируйте пилот так, чтобы те же данные, семантика и контролы могли быть расширены на следующий кейс, а не начинались с нуля.\n\n## Стоимость и закупки: платформа vs точечные решения\n\nРазговоры о цене легко запутать, потому что «платформа» объединяет возможности, которые обычно покупают отдельными инструментами. Главное — соотносить ценообразование с результатами, которые вам нужны (интеграция + моделирование + управление + операционные приложения), а не только с позицией «лицензия ПО».\n\n### Общие драйверы стоимости для Palantir‑подобной платформы\n\nБольшинство сделок платформ формируются несколькими переменными:\n\n- разработчики (инженеры, моделеры) vs потребители (операторы, аналитики)\n- тяжёлые рабочие нагрузки (поточные данные, симуляции, большие джоины) увеличивают инфраструктурные расходы\n- dev/test/prod и отдельные регулируемые или отключённые среды — каждая добавляет накладные расходы\n- круглосуточная поддержка, SLA инцидентов и выделенные команды успеха меняют цену\n- начальный онбординг данных, дизайн онтологии и разработка рабочих процессов часто — реальные ранние драйверы стоимости\n\n### Что скрывают затраты традиционного стека\n\nТочечный подход может выглядеть дешевле сначала, но суммарная стоимость распределяется по:
- множеству лицензий (ETL/ELT, BI, каталог, управление, workflow, feature store и т.д.)
- интеграционной работе между инструментами (коннекторы, идентичность, синхронизация метаданных)
- постоянному обслуживанию (обновления версий, сломавшиеся конвейеры, дублирование определений метрик)
Платформы часто сокращают «спред инструментов», но вы платите за более крупный и стратегический контракт.\n\n### Закупки: покупка платформы vs приложения\n\nПри покупке платформы относитесь к ней как к общей инфраструктуре: определите , , и . Попросите явное разделение между , и , чтобы можно было сравнивать предложения по‑существу.\n\n### Простой чек‑лист для бюджетирования\n\n- Какие команды будут активно разрабатывать, а какие — только просматривать?\n- Какие рабочие процессы должны работать в проде (а не только отчёты)?\n- Сколько сред и регионов требуется?\n- Есть ли изолированные или офлайн‑сайты?\n- Ожидаемый рост объёма данных/частоты обновлений?\n- Какие услуги нужны на первые 90 дней?\n\nЕсли нужен быстрый способ структурировать допущения, см. /pricing.\n\n## Когда Palantir‑подобные подходы подходят (и когда нет)\n\nPalantir‑подобные платформы обычно блистательны, когда проблема (люди должны принимать решения и действовать через системы), а не просто (нужен отчёт). Компромисс в том, что вы принимаете более платформенный подход — мощный, но он требует от организации больше, чем простой BI‑проект.\n\n### Сценарии хорошей совместимости\n\nТакой подход хорош, когда работа пересекает несколько систем и команд, и вы не можете терпеть хрупкие передачи.\n\nПримеры: координация цепочки поставок, операции по борьбе с мошенничеством и рисками, планирование миссий, управление случаями, флот и техобслуживание — там, где одни и те же данные должны иметь единое толкование разными ролями.\n\nОн также полезен, когда права сложны (доступ на уровне строк/столбцов, многоарендность, правила необходимости знать) и когда нужен прозрачный журнал использования данных. Наконец, он хорошо подходит для регулируемых или ограниченных сред: on‑prem, air‑gapped/отключённые развертывания или строгая аккредитация безопасности.\n\n### Менее подходящие сценарии\n\nЕсли цель — простая отчётность (еженедельные KPI, несколько дашбордов, сводки по финансам), традиционный BI поверх хорошо управляемого хранилища может быть быстрее и дешевле.\n\nОн также избыточен для небольших наборов данных, стабильных схем или аналитики в пределах одного департамента, где одна команда контролирует источники и определения, а основное действие происходит вне инструмента.\n\n### Критерии принятия решения (соответствие задаче)\n\nЗадайте три практических вопроса:
\n- нужны ли рабочие процессы в течение недель, или это долгосрочная программа модернизации?\n- заблокированы ли ключевые решения несогласованными определениями и фрагментированными источниками?\n- есть ли у вас продуктовая собственность, эксперты предметной области и ресурсы управления, чтобы принять платформу и поддерживать её в актуальном состоянии?\n\nЛучшие результаты приходят от подхода «подходит задаче», а не «один инструмент заменит всё». Многие организации сохраняют существующий BI для общей отчётности и применяют Palantir‑подобный подход для самых критичных операционных доменов.\n\n## Чек‑лист покупателя и дальнейшие шаги\n\nПокупка Palantir‑подобной платформы vs традиционного корпоративного ПО — это меньше про чек‑боксы функций и больше про то, куда ложится реальная работа: интеграция, единый смысл (семантика) и повседневное операционное использование. Используйте чек‑лист ниже, чтобы заранее добиться ясности, прежде чем вас запрут в долгую реализацию или узкое точечное решение.\n\n### Практический чек‑лист сравнения вендоров\n\nПопросите каждого вендора чётко рассказать , и .\n\n- какие источники типичны (ERP, логи, таблицы, фиды партнёров)? Что преднастроено, а что кастомно? Кто поддерживает конвейеры после запуска — IT, data engineering или вендор?\n- как они предотвращают ситуацию, когда пять команд по‑разному определяют «клиента», «актив» или «готовность к миссии»? Могут ли показать управляемый бизнес‑слой (онтология/семантика) и как изменения распространяются?\n- могут ли фронтлайн‑команды завершить задачу (триаж, утверждение, диспетчеризация, расследование) внутри продукта или это «проанализируй здесь, действуй где‑то ещё»? Как обрабатываются исключения?\n- гранулярные права, журналы аудита и управление политиками — могут ли владельцы данных контролировать, кто что видит, с каким уровнем детализации и почему?\n- можно ли запустить в требуемой среде (облако, on‑prem, отключённое)? Что ломается при ограниченной связности? Какой путь обновлений?\n\n### Вопросы для демонстраций (не принимайте слайды)\n\n1. выберите критический KPI и проследите его от источника до финальной метрики. Где он может быть неверен и как это обнаружить?\n2. от сырых данных до оповещения → решение → действие → журнал аудита. Включите утверждения и «кто что изменил».\n3. что происходит, если конвейер падает или релиз вызывает регрессию? Могут ли быстро и чисто откатиться?\n\n### Кто должен быть в комнате\n\nПривлеките заинтересованных лиц, которые будут жить с компромиссами:
\n- (владение интеграцией, надёжностью, стоимостью)\n- (контроли, аудит, одобрения развёртывания)\n- (определения, правила доступа, ответственность)\n- (влияние на процессы, внедрение)\n- (действительно ли это помогает сделать работу быстрее?)\n\n### Следующие шаги\n\nЗапустите time‑boxed proof‑of‑value, сфокусированный на одном высоко‑рисковом операционном рабочем процессе (а не на общем дашборде). Зафиксируйте критерии успеха заранее: время до решения, снижение ошибок, аудитируемость и владение постоянной работой с данными.\n\nЕсли нужна помощь с паттернами оценки, см. /blog. Для помощи в подготовке объёма proof‑of‑value или шорт‑листе вендоров свяжитесь по /contact.