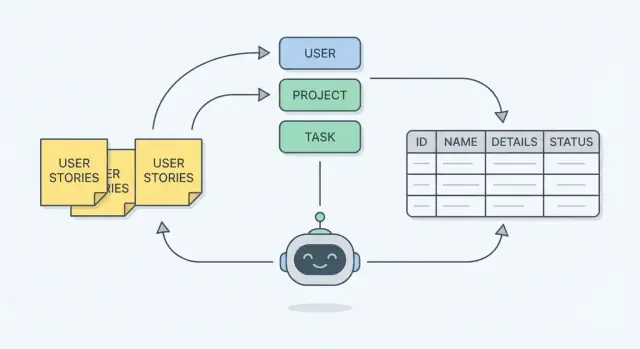
Что вы проектируете: схема, соответствующая реальной работе
Схема базы данных — это план того, как ваше приложение будет запоминать вещи. На практике это:
- Таблицы: «вёдра» информации (Customers, Orders, Tickets)
- Поля (столбцы): детали, которые вы храните о каждом элементе (customer_name, order_date)
- Связи: как вёдра связаны между собой (Order принадлежит одному Customer; Customer может иметь много Orders)
Когда схема соответствует реальной работе, она отражает то, что люди действительно делают — создают, просматривают, утверждают, планируют, назначают, отменяют — а не то, что звучит аккуратно на доске.
Зачем начинать с пользовательских историй?
Пользовательские истории и acceptance criteria описывают реальные нужды простым языком: кто что делает и что значит «готово». Если ориентироваться на них как на исходник, схема с меньшей вероятностью пропустит важные детали (например, «мы должны хранить, кто утвердил возврат» или «бронирование можно перенести несколько раз»).
Начинать со сторий также честно про масштаб: если этого нет в историях (или в workflow), считайте это опциональным, а не тихо строите сложную модель «на всякий случай».
Что ИИ может и чего не может
ИИ может помочь работать быстрее, например:
- выделить кандидатов в сущности (важные «вещи» в историях)
- предложить поля, подразумеваемые acceptance criteria (таймстемпы, статусы, ссылки)
- заметить вероятные связи и пробелы («вы упоминаете утверждения, но не храните approver»)
ИИ не может надёжно:
- знать ваши скрытые бизнес‑правила или крайние случаи, которые вы не записали
- выбрать «правильный» уровень детализации без учёта компромиссов (простота vs гибкость)
- гарантировать, что схема удовлетворяет требованиям отчётности, безопасности или соответствия
Относитесь к ИИ как к мощному ассистенту, а не как к лицу, принимающему окончательное решение.
Если вы хотите превратить этого ассистента в реальное ускорение, платформа vibe-кодинга вроде Koder.ai может помочь быстрее перейти от решений по схеме к рабочему приложению React + Go + PostgreSQL — при этом вы остаётесь в контроле над моделью, ограничениями и миграциями.
Установите ожидания: итеративно, а не в один заход
Проектирование схемы — это цикл: черновик → тест по историям → поиск недостающих данных → правка. Цель не в идеальном первом результате; цель — модель, которую вы можете проследить до каждой пользовательской истории и уверенно сказать: «Да, мы можем сохранить всё, что нужно этому workflow — и объяснить, зачем нужна каждая таблица.»
Входные данные: пользовательские истории, acceptance criteria и реальные примеры
Прежде чем превращать требования в таблицы, проясните, что именно вы моделируете. Хорошая схема редко начинается с пустой страницы — она начинается с конкретной работы людей и доказательств, которые вам понадобятся позже (экраны, выходные данные и крайние случаи).
Типичные входные данные, которые стоит собрать в одном месте
Пользовательские истории — это заголовок, но их недостаточно. Соберите:
- Пользовательские истории + роли (кто что делает и зачем)
- Acceptance criteria (правила «должно быть верно»)
- Формы/экраны (поля, которые вводят или видят пользователи)
- Отчёты/экспорт (что нужно суммировать, группировать, фильтровать)
- Реальные примеры (примерные заказы, счета, тикеты, календари — всё репрезентативное)
Если вы используете ИИ, эти входные данные закрепляют модель в реальности. ИИ может быстро предложить сущности и поля, но ему нужны реальные артефакты, чтобы не выдумать структуру, не соответствующую вашему продукту.
Acceptance criteria: скрытый источник ограничений
Acceptance criteria часто содержат самые важные правила хранения, даже если прямо не упоминают данные. Ищите формулировки вроде:
- «Email должен быть уникальным» (уникальность)
- «Status может быть Draft, Submitted, Approved» (разрешённые значения)
- «Только менеджеры могут утверждать» (права доступа, возможно поля аудита)
- «Нельзя удалить счёт с платежами» (правила ссылочной целостности)
Частые ошибки, которые стоит исправить рано
Расплывчатые истории («Как пользователь, я могу управлять проектами») скрывают множество сущностей и рабочих процессов. Ещё одна частая пустота — отсутствие крайних случаев: отмены, повторы, частичные возвраты или переназначения.
Быстрый чеклист качества истории (перед моделированием)
- Указан актор/роль.
- Объект ясен (не «данные» или «вещи»).
- Есть хотя бы один реальный пример.
- Acceptance criteria включают валидации и границы.
- Обсуждаются ошибки и «что если» (или явно отложены).
Шаг 1 — Выделите сущности из историй (существительные)
Прежде чем думать о таблицах или диаграммах, прочитайте пользовательские истории и выделите существительные. В написании требований сущительные обычно указывают на «вещи», которые система должна запомнить — они часто становятся сущностями в вашей схеме.
Короткая мысль: существительные → сущности, а глаголы → действия или workflows. Если в истории: «Менеджер назначает технику на задание», вероятные сущности — manager, technician, job — а «назначает» подсвечивает связь, которую вы смоделируете позже.
Как понять, что существительное — настоящая сущность
Не каждое существительное должно стать отдельной таблицей. Сильным кандидатом на сущность является существительное, когда оно:
- Имеет свою идентичность: можно указать конкретный экземпляр (Job #1042, Customer A).
- Изменяется со временем: имеет lifecycle (задание меняет статус от planned → completed).
- Используется в нескольких местах: на него ссылаются разные истории или несколько workflows его затрагивают.
Если существительное встречается только один раз или описывает что‑то иное («красная кнопка», «пятница»), то, возможно, это не сущность.
Атрибут или отдельная сущность (тест «Address» и «Tag»)
Обычная ошибка — превращать каждую деталь в таблицу. Правило‑эмпирика:
- Если это одно значение, описывающее вещь, обычно это атрибут (например, Customer.phone_number).
- Если это повторяемо, используется совместно или имеет структуру, это часто отдельная сущность.
Два классических примера:
- Address: если вы храните shipping и billing адреса, ведёте историю или переиспользуете адреса между клиентами/локациями, Address вероятно самостоятельная сущность. Если нужен только один почтовый адрес и он не переиспользуется, можно оставить атрибутом.
- Tag: теги почти всегда отдельная сущность, потому что они повторяемы и отношения M:N (одному Job — много Tags; один Tag — много Jobs).
Как ИИ может помочь с кандидатами в сущности (с оговорками)
ИИ может ускорить обнаружение сущностей, просканировав истории и вернув черновой список существительных, сгруппированных по темам (люди, рабочие элементы, документы, локации). Полезный промпт: «Извлеки существительные, которые представляют данные, которые мы должны хранить, и сгруппируй дубликаты/синонимы.»
Относитесь к выводу как к отправной точке, а не к окончательному ответу. Задавайте уточняющие вопросы:
- «Какие из них имеют lifecycle или требуют собственного ID?»
- «Какие на самом деле статусы, категории или атрибуты?»
- «Есть ли синонимы (например, ‘client’ vs ‘customer’)?»
Цель Шага 1 — короткий, чистый список сущностей, который вы сможете защитить ссылками на реальные истории.
Шаг 2 — Превратите детали в поля (вещи, которые нужно запомнить)
Как только вы назвали сущности (например, Order, Customer, Ticket), следующая задача — зафиксировать детали, которые понадобятся позже. В базе данных эти детали — поля (или атрибуты) — напоминания, которые система не должна забыть.
Как выбирать поля (без домыслов)
Начните с пользовательской истории, затем прочитайте acceptance criteria как чеклист того, что обязано храниться.
Если требование говорит «Пользователи могут фильтровать заказы по дате доставки», то delivery_date не опционален — это поле (или надёжно выводимое значение). Если сказано «Показывать, кто утвердил запрос и когда», скорее всего нужны approved_by и approved_at.
Практический тест: Понадобится ли это для отображения, поиска, сортировки, аудита или вычислений? Если да — вероятно поле.
Простые правила для аккуратных полей
- Держите значения атомарными: храните
First name и Last name отдельно, если будете искать или сортировать по ним. Не упаковывайте несколько значений в одно поле (например, «red, blue»).
- Используйте согласованные типы: даты как даты, деньги как десятичные, булевы как true/false — не смешивайте форматы вроде «$10», «10 USD» и «10».
- Избегайте дублирования текста: не копируйте адрес клиента в каждый элемент заказа. Храните один раз в нужном месте и ссылкуйте.
Контролируемые словари: статусы, типы и категории
Во многих историях встречаются слова вроде «status», «type» или «priority». Рассматривайте их как контролируемые словари — ограниченный набор допустимых значений.
Если набор небольшой и стабильный, подойдёт enum‑поле. Если он может расти, нужен label или права управления (например, админские категории) — используйте отдельную lookup‑таблицу (например, status_codes) и храните ссылку.
Так истории превращаются в поля, которым можно доверять — пригодные для поиска, отчётов и строгого ввода.
Шаг 3 — Свяжите сущности отношениями
Когда вы перечислили сущности (User, Order, Invoice, Comment и т.д.) и набросали их поля, следующий шаг — связать их. Связи отражают «как эти вещи взаимодействуют», что подразумевается в историях.
Три формы отношений (простыми словами)
Один-к-одному (1:1) — «одна вещь имеет ровно одну другую».
- Фраза из истории: «У каждого пользователя есть один профиль.»
- Модель:
User ↔ Profile (часто можно объединить, если нет причин разделять).
Один-ко-многим (1:N) — «одна вещь может иметь много других». Самое распространённое.
- Фраза: «Пользователь может иметь много заказов.»
- Модель:
User → Order (храните user_id в Order).
Многие-ко-многим (M:N) — «много вещей может относиться к многим вещам». Требует дополнительной таблицы.
- Фраза: «Заказ может включать много продуктов, и продукт может быть во многих заказах.»
M:N: трюк со связующей таблицей
Базы данных плохо хранят «список product_id» в колонке Order — это создаёт проблемы при поиске, обновлении и отчётности. Вместо этого создают join table, которая сама представляет отношение.
Пример:
OrderProductOrderItem (join table)
OrderItem обычно включает:
order_idproduct_id- детали из истории, например
quantity, unit_price, discount
Заметьте: детали истории («quantity») часто принадлежат отношению, а не любой из сущностей отдельно.
Обязательно vs. опционально (без жаргона)
Истории также подсказывают, является ли связь обязательной или иногда отсутствует.
- «Заказ должен принадлежать пользователю» → у каждого
Order должен быть user_id (нельзя пустой).
- «У пользователя может быть номер телефона» →
phone может быть пустым.
- «Заказ может иметь адрес доставки (для физических товаров)» →
shipping_address_id может быть пустым для цифровых товаров.
Если из истории понятно, что запись нельзя создать без связи, считайте её обязательной. Если есть «может», «можно» или исключения — опциональной.
Превращайте предложения истории в предложения отношений
Когда вы читаете историю, перепишите её в простое отношение:
- «Пользователь может оставлять много комментариев» →
User 1:N Comment
- «Комментарий принадлежит одному пользователю» →
Comment N:1 User
Сделайте это для каждого взаимодействия из историй. В конце у вас будет связанная модель, отражающая, как работа действительно происходит — ещё до открытия инструмента для ER‑диаграмм.
Шаг 4 — Используйте workflows, чтобы найти состояния, события и пробелы
Устраняйте пробелы на раннем этапе
Находите отсутствующие поля (например, approved_by и approved_at), моделируя процессы в чате.
Пользовательские истории говорят, ЧТО хотят люди. Workflows показывают, КАК работа на самом деле движется, шаг за шагом. Перевод workflow в данные — один из самых быстрых способов поймать «мы забыли это сохранить» проблемы ещё до строительства.
Начните с простого workflow
Запишите workflow как последовательность действий и смены состояний. Пример:
- Create request → Draft
- Submit request → Submitted
- Manager reviews → Approved или Rejected
- If approved, work is scheduled → In progress
- Completed → Done
Эти выделенные слова часто становятся полем status (или небольшой таблицей «state») с явным набором разрешённых значений.
Workflows показывают отсутствующие поля
Пробегая шаги, спрашивайте: «Что нам нужно будет знать позже?» Workflows обычно выявляют поля типа:
- таймстемпы:
submitted_at, approved_at, completed_at
- владение:
created_by, assigned_to, approved_by
- причина/контекст:
rejection_reason, approval_note
- порядок:
sequence для многоступенчатых процессов
Если workflow включает ожидание, эскалацию или передачу, обычно нужен как минимум один таймстемп и поле «кто сейчас отвечает».
Workflows показывают недостающие таблицы
Некоторые шаги workflow — это не просто поля, а отдельные структуры данных:
- Audit log / history для «кто изменил статус когда»
- Approvals для мульти-утверждений или условных правил
- Attachments для файлов, загружаемых в шаге
- Comments если обсуждение — часть процесса
Использование ИИ для перекрёстной проверки пробелов
Дайте ИИ оба набора: (1) пользовательские истории и acceptance criteria, и (2) шаги workflow. Попросите его перечислить каждый шаг и указать требуемые данные для него (состояние, актор, таймстемп, выходы), затем выделить любое требование, которое не поддерживается текущими полями/таблицами.
На платформах типа Koder.ai такая «проверка пробелов» особенно практична: вы быстро меняете допущения схемы, регенерируете каркас и продолжаете без долгих отложений на ручной рутинной работе.
Ключи, уникальность и базовые ограничения (без жаргона)
Когда вы превращаете истории в таблицы, вы не просто перечисляете поля — вы решаете, как данные остаются опознаваемыми и консистентными со временем.
Первичные ключи: стабильный «удостоверяющий» идентификатор строки
Primary key уникально идентифицирует одну запись — это постоянная «карта ID» строки.
Зачем каждой строке нужен такой ID: истории подразумевают обновления, ссылки и историю. Если сказано «Поддержка может просмотреть заказ и оформить возврат», нужен стабильный способ ссылаться на этот заказ — даже если клиент сменил email, адрес отредактировали или статус заказа изменился.
На практике это внутренний id (обычно число или UUID), который не меняется.
Внешние ключи: указатели между таблицами
Foreign key — это способ безопасно ссылаться из одной таблицы на другую. Если orders.customer_id ссылается на customers.id, база гарантирует, что каждый заказ принадлежит реальному клиенту.
Это совпадает с историями вроде «Как пользователь, я могу видеть свои счета». Счёт не плавает отдельно — он прикреплён к клиенту (и часто к заказу или подписке).
Правила уникальности: превращаем «должно быть уникально» в принуждение
Пользовательские истории часто содержат скрытые требования уникальности:
- «Пользователи регистрируются по email» → обеспечить unique email (или уникальность в пределах арендатора)
- «Финансы ищут по номеру счета» → обеспечить unique invoice_number
Эти правила предотвращают путаницу и дубли, которые всплывают позже как «баги данных».
Индексы (высокоуровнево): ускоряем частые запросы
Индексы ускоряют поиски вроде «найти клиента по email» или «список заказов клиента». Начните с индексов, соответствующих вашим частым запросам и правилам уникальности.
Что отложить: тяжёлую индексацию для редких отчётов или спекулятивных фильтров. Зафиксируйте эти потребности в историях, валидируйте схему сначала, затем оптимизируйте по реальным данным и медленным запросам.
Поддерживайте данные консистентными: практический чеклист нормализации
Создайте следующее приложение с Vibe-code
Создавайте веб-, серверные или мобильные приложения из простого чата, затем дорабатывайте модель данных.
Цель нормализации проста: предотвращать конфликтующие дубли. Если один и тот же факт можно сохранить в двух местах, со временем они разойдутся (две орфографии, две цены, два «текущих» адреса). Нормализованная схема хранит факт один раз и ссылается на него.
Быстрый чеклист для черновой схемы
1) Следите за повторяющимися группами
Если видите шаблоны вроде Phone1, Phone2, Phone3 или ItemA, ItemB, ItemC, это сигнал в пользу отдельной таблицы (например, CustomerPhones, OrderItems). Повторяющиеся группы усложняют поиск, валидацию и масштабирование.
2) Не копируйте одно и то же в разные таблицы
Если CustomerName появляется в Orders, Invoices и Shipments, вы получили несколько источников истины. Храните детали клиента в Customers, а в других местах храните customer_id.
3) Избегайте «нескольких колонок для одного и того же»
Колонки вроде billing_address, shipping_address, home_address могут быть оправданы, если это действительно разные концепции. Но если вы моделируете «много адресов разных типов», используйте таблицу Addresses с полем type.
4) Отделяйте lookup‑таблицы от свободного текста
Если пользователь выбирает из известного набора (status, category, role), моделируйте это последовательно: либо ограниченный enum, либо lookup‑таблица. Это избавит от вариаций вроде «Pending» vs «pending» vs «PENDING».
5) Проверьте, зависит ли каждое поле не от чего‑то другого
Полезный тест: в таблице колонка, описывающая не основную сущность таблицы, вероятно должна быть в другом месте. Пример: Orders не должен хранить product_price, если это не «цена на момент заказа» (историческая снимка).
Когда денормализация приемлема (как поздний выбор)
Иногда дублирование — осознанный выбор:
- Отчётность/производительность: предварительно агрегированные итоги или summary‑таблицы.
- Кэширование: вычисленное значение для избегания тяжёлых пересчётов.
- Аудит/история: копирование «имени на момент покупки» для сохранения прошлой реальности.
Ключ — делать это намеренно: документируйте источник истины и способ обновления копий.
Где помогает ИИ — а где решают люди
ИИ может заметить подозрительные дубли (повторные колонки, похожие имена полей, несоответствующие поля статусов) и предложить расколы на таблицы. Люди выбирают компромисс — простота vs гибкость vs производительность — исходя из реального использования продукта.
Хранимые vs вычисляемые значения: что хранить в БД
Полезное правило: сохраняйте факты, которые нельзя надёжно восстановить позже; вычисляйте всё остальное.
Хранимые vs вычисляемые (derived)
Хранимые данные — источник истины: отдельные позиции, таймстемпы, изменения статусов, кто что сделал. Вычисляемые — результаты этих фактов: итоги, счётчики, флаги вроде «просрочен», агрегации уровня «текущее количество на складе».
Если два значения можно получить из одних и тех же фактов, предпочитайте хранить факты и вычислять остальное, иначе появится риск противоречий.
Почему хранение производных значений приводит к рассинхронизации
Производные значения меняются при изменении входных данных. Если вы храните и входы, и результат, вам нужно поддерживать синхронность при каждом сценарии (редакты, возвраты, частичные отгрузки, правки с запозданием). Один промах — и база начнёт рассказывать две разные истории.
Пример: хранение order_total вместе с order_items. Если изменили количество или применили скидку, и итог не обновился — бухгалтерия увидит одно, а корзина — другое.
Используйте workflows, чтобы решить, что хранить (история и снимки)
Workflows показывают, когда вам нужна историческая правда, а не только «текущее состояние». Если пользователи должны знать, какое значение было в момент события — сохраните снимок.
Для заказа вы можете хранить:
- Позиции и цены (факты)
- Захваченный
order_total на момент оформления (snapshot), потому что налоги, скидки и правила ценообразования могут измениться позже
Для инвентаря «уровень запасов» часто вычисляют из движений (приходы, продажи, корректировки). Но если нужен аудит, храните движения и, при необходимости, периодические снимки для скорости отчётов.
Для логина храните last_login_at как факт (таймстемп события). Вопрос «активен ли пользователь за последние 30 дней?» лучше вычислять.
Проработанный пример: от 5 пользовательских историй до ER‑модели
Возьмём знакомое приложение поддержки — support ticket. Пройдём от пяти историй до простой ER‑модели (сущности + поля + связи), затем проверим её по одному workflow.
5 историй → существительные → сущности
- Как клиент, я могу создать тикет поддержки с subject, description и category.
- Как агент, я могу назначить тикет себе или другому агенту.
- Как агент, я могу добавлять внутренние заметки и публичные ответы к тикету.
- Как клиент, я могу видеть, когда мой тикет обновлён и когда он закрыт.
- Как менеджер, я могу отслеживать, как долго тикеты остаются открытыми и кто их закрыл.
От существительных получаем основные сущности:
- User (customers, agents, managers)
- Ticket
- Message (public replies + internal notes)
- Category
- TicketEvent (audit/history)
Поля и связи (компактная ER‑модель)
- User: id, name, email, role
- Category: id, name
- Ticket: id, subject, description, status, created_at, updated_at, closed_at
- связи: Ticket.category_id → Category.id
- связи: Ticket.requester_id → User.id (customer)
- связи: Ticket.assignee_id → User.id (agent, nullable)
- Message: id, ticket_id, author_id, body, is_internal, created_at
- связи: Message.ticket_id → Ticket.id
- связи: Message.author_id → User.id
- TicketEvent: id, ticket_id, actor_id, type, from_status, to_status, created_at
Отображение workflow: create → update → close
- Create: вставить Ticket (status = “open”, created_at), вставить TicketEvent(type = “created”).
- Update (assign, reply): вставить Message или обновить Ticket.assignee_id, и вставить TicketEvent(type = “assigned”/“replied”, updated_at).
- Close: обновить Ticket.status = “closed”, установить closed_at, вставить TicketEvent(type = “closed”, actor_id = closer).
«До и после»: ИИ поймал пропущенное ограничение
До (частая ошибка): Ticket имеет assignee_id, но мы забыли гарантировать, что назначен только агенту.
После: ИИ пометил это, и вы добавляете практическое правило: assignee должен быть User с role = “agent” (реализуется через валидацию в приложении или через ограничение/политику в базе, в зависимости от стека). Это не позволит «назначить клиенту» и сломать отчёты позже.
Валидируйте схему: проследите каждую историю
Превратите примеры в своё приложение
Начните с примера тикетинга или заказов и адаптируйте под свою область по ходу.
Схема «готова», когда на каждую пользовательскую историю можно ответить данными, которые реально можно сохранить и запросить. Простейшая валидация — взять каждую историю и спросить: «Мы можем надёжно ответить на этот запрос из базы данных в каждом случае?» Если ответ «может быть», модель не завершена.
Превратите каждую историю в вопрос к базе
Перепишите историю как один или несколько тестовых вопросов — то, что вы захотите в отчёте, на экране или в API. Примеры:
- Отчёты: «Показать все открытые заказы по клиентам с итогами за последние 30 дней.»
- Права: «Какие пользователи могут утверждать возвраты для этого магазина?»
- Краевые случаи: «Может ли заказ существовать без адреса доставки? А цифровые товары?»
- Удаления: «Если мы удалим клиента, что произойдёт с заказами, счетами и заметками?»
Если вы не можете выразить историю как ясный вопрос — история неясна. Если можете — но не можете ответить на неё схемой, не хватает поля, связи, статуса/события или ограничения.
Используйте примерные данные для быстрой проверки
Создайте маленький набор данных (5–20 строк для ключевых таблиц), включив нормальные и «неудобные» случаи (дубли, отсутствующие значения, отмены). «Пройдитесь» по историям с этими данными — вы быстро найдёте проблемы вроде «мы не можем сказать, какой адрес использовался при покупке» или «некуда сохранить, кто утвердил изменение».
Пусть ИИ поможет найти необработанные случаи
Попросите ИИ сгенерировать проверочные вопросы по каждой истории (включая крайние случаи и сценарии удаления) и перечислить данные, нужные для ответов. Сопоставьте этот список со схемой: любое несоответствие — конкретное действие, а не расплывчатое ощущение, что «что‑то не так».
Безопасное использование ИИ и поддерживаемость схемы
ИИ может ускорить моделирование данных, но также повышает риск утечки чувствительной информации или жёсткой фиксации плохих допущений. Относитесь к нему как к очень быстрому ассистенту: полезен, но с ограждениями.
Что можно давать ИИ (и чего избегать)
Давайте ИИ реалистичные, но санитаризованные данные:
- Санитизированные пользовательские истории (переименуйте клиентов, продукты, локации)
- Acceptance criteria и крайние случаи («refund within 14 days», «одна активная подписка на аккаунт»)
- Примеры полей с фейковыми данными (например,
invoice_total: 129.50, status: "paid")
- Текущие заголовки CSV / существующие таблицы (структура обычно безопасна; содержимое — нет)
Избегайте всего, что может идентифицировать человека или раскрыть конфиденциальные операции:
- реальные имена, емейлы, телефоны, адреса
- реальные истории заказов, тикеты, внутренние заметки
- API‑ключи, креды, скриншоты с приватными данными
Если нужен реализм, генерируйте синтетические образцы в нужных форматах — никогда не копируйте production‑строки.
Оставляйте допущения рядом со схемой
Схемы чаще всего ломаются, потому что «все по‑разному предполагали». Рядом с ER‑моделью (или в том же репозитории) храните короткий журнал решений:
- определения («Что считается ‘активным’ аккаунтом?»)
- ограничения («Пользователь может принадлежать нескольким организациям»)
- компромиссы («Мы храним currency_code на каждом счёте для аудита»)
Это превращает вывод ИИ в командные знания, а не в разовый артефакт.
Планируйте изменения: версионирование и миграции
Схема будет эволюционировать с новыми историями. Защитите изменения так:
- Версионируйте изменения схемы (файлы миграций в Git)
- Пишите обратимые миграции, когда возможно
- Обновляйте seed‑данные и примеры запросов, чтобы изменения можно было протестировать
- Рассматривайте миграции, сгенерированные ИИ, как обычный код в процессе ревью
Если вы используете платформу вроде Koder.ai, используйте механизмы снимков и отката при итерациях по схеме и экспортируйте исходники для глубоких правок и традиционного ревью.
Простая повторяемая процедура
- Санитизируйте истории + создайте 5–10 синтетических примеров.
- Попросите ИИ предложить сущности, поля, связи и ограничения.
- Просмотрите с командой; зафиксируйте допущения.
- Реализуйте миграции; выполните небольшой «trace» по историям (каждая история покрывается моделью).
- Повторяйте при изменении историй; держите схему и заметки в синхронизации.