23 дек. 2025 г.·6 мин
Ограничение запросов в SaaS API: по пользователю, организации и IP
Шаблоны ограничения скорости для SaaS API: лимиты по пользователю, организации и IP, с понятными заголовками, телами ошибок и советами по развёртыванию.
Шаблоны ограничения скорости для SaaS API: лимиты по пользователю, организации и IP, с понятными заголовками, телами ошибок и советами по развёртыванию.
Лимиты скорости и квоты звучат похоже, поэтому люди часто считают их тем же самым. Лимит скорости определяет, как быстро можно вызывать API (запросы в секунду или в минуту). Квота — это сколько вы можете использовать за более длинный период (в день, в месяц или в биллинговый цикл). Оба механизма нормальны, но кажутся случайными, когда правила не видны.
Классическая жалоба: «вчера работало». Использование редко бывает равномерным. Короткий всплеск может вывести кого-то за предел даже если их суточный объём в порядке. Представьте клиента, который запускает отчёт раз в день, но сегодня задача повторяется после таймаута и делает в 10 раз больше вызовов за 2 минуты. API блокирует его, и он видит лишь внезапную ошибку.
Путаница усиливается, когда ошибки расплывчаты. Если API возвращает 500 или общее сообщение, клиенты думают, что сервис упал, а не что они превысили лимит. Они открывают срочные тикеты, придумывают обходы или меняют поставщика. Даже 429 Too Many Requests раздражает, если не указывает, что делать дальше.
Большинство SaaS API ограничивают трафик по двум причинам:
Смешение этих целей приводит к плохим решениям. Контроль злоупотреблений часто делается по IP или по токену и может быть строгим. Формирование нормального использования обычно идёт по пользователю или по организации и должно сопровождаться понятными инструкциями: какой лимит превышен, когда он сбросится и как избежать повторного превышения.
Когда клиенты могут предсказать лимиты, они планируют с учётом ограничений. Когда нет — каждый всплеск кажется сломанным API.
Лимиты — это не просто дроссель. Это система безопасности. Прежде чем выбирать числа, ясно определите, что вы пытаетесь защитить, потому что каждая цель ведёт к разным лимитам и ожиданиям.
Доступность обычно на первом месте. Если несколько клиентов могут вызвать всплески и загнать API в таймауты, страдают все. Лимиты в этом случае должны сохранять отзывчивость серверов при пиках и быстро давать отказ, а не позволять запросам накапливаться.
Стоимость — тихий драйвер многих API. Некоторые запросы дешёвые, другие — дорогие (вызовы LLM, обработка файлов, запись в хранилище, платные сторонние запросы). Например, на платформе Koder.ai один пользователь может запустить много вызовов моделей через чат-генерацию приложений. Лимиты, отслеживающие дорогостоящие действия, предотвращают внезапные счета.
Злоупотребления выглядят иначе, чем высокий легитимный трафик. Подбор учётных данных, угадывание токенов и скрейпинг часто проявляются как множество мелких запросов с узкого набора IP или аккаунтов. Здесь нужны строгие лимиты и быстрое блокирование.
Справедливость важна в мультиарендных системах. Один шумный клиент не должен ухудшать работу всех остальных. На практике это часто означает многослойный контроль: защита от всплесков, чтобы API был здоров каждую минуту; бюджет для дорогих эндпоинтов; защита от злоупотреблений для auth и подозрительных паттернов; и защита «справедливости», чтобы одна организация не вытеснила остальных.
Простой тест помогает: выберите один эндпоинт и спросите: «Если трафик на этот запрос вырастет в 10×, что сначала сломается?» Ответ подскажет, какую цель защиты приоритизировать и в каком измерении (пользователь, организация, IP) ставить лимит.
Большинство команд начинают с одного лимита и затем обнаруживают, что он бьёт по не тем людям. Цель — подобрать измерения, которые соответствуют реальному использованию: кто вызывает, кто платит и что выглядит как злоупотребление.
Распространённые измерения в SaaS:
Лимиты по пользователю обеспечивают справедливость внутри арендатора. Если кто-то запускает большой экспорт, он должен почувствовать замедление сильнее, чем остальная команда.
Лимиты по организации — про бюджет и ёмкость. Даже если десять пользователей одновременно запускают задачи, организация не должна создавать пиковую нагрузку, которая ломает сервис или ваши ценовые предположения.
Лимиты по IP лучше рассматривать как страховку, а не инструмент биллинга. IP могут быть общими (офисный NAT, мобильные сети), поэтому эти лимиты делайте щедрыми и используйте их в основном для остановки очевидного злоупотребления.
Когда вы комбинируете измерения, решите, какое правило «побеждает», если применимо несколько лимитов. Практическое правило: отклонять запрос, если любой релевантный лимит превышен, и возвращать наиболее полезную причину. Если воркспейс превысил квоту организации, не вините отдельного пользователя или IP.
Пример: рабочее пространство Koder.ai на тарифе Pro может допускать устойчивый поток сборок по организации, одновременно ограничивая одного пользователя от сотен запросов в минуту. Если интеграция партнёра использует общий токен, лимит по токену может помешать ей заглушить интерактивных пользователей.
Большинство проблем с лимитами — не про математику, а про поведение, соответствующее тому, как клиенты вызывают API, и про предсказуемость под нагрузкой.
Token bucket — распространённый выбор, потому что он позволяет короткие всплески при соблюдении среднего в долгосрочной перспективе. Пользователь, который обновляет дашборд, может сгенерировать 10 быстрых запросов; token bucket это позволяет, если накоплены токены, а затем замедляет поток.
Leaky bucket жёстче. Он сглаживает трафик в постоянный поток, что полезно, когда бекенд не выдерживает пиков (например, дорогая генерация отчётов). Минус в том, что пользователи почувствуют это раньше — всплески превращаются в очередь или отказы.
Окна с подсчётом просты, но детали важны. Фиксированные окна создают резкие границы (пользователь может сделать всплеск в 12:00:59 и снова в 12:01:00). Скользящие окна кажутся справедливее и уменьшают пиковые эффекты на границе, но требуют больше состояния или эффективных структур данных.
Отдельный класс лимитов — конкурентность (одновременные запросы). Это защищает от медленных соединений клиентов и долгих эндпоинтов. Клиент может умещаться в 60 запросов в минуту, но при этом держать 200 открытых запросов, перегружая систему.
В реальных системах команды часто комбинируют несколько контролей: token bucket для общего темпа запросов, ограничение конкурентности для медленных или тяжёлых эндпоинтов и отдельные бюджеты для групп эндпоинтов (дешёвые чтения vs дорогие экспорты). Если вы ограничиваете только по числу запросов, один дорогой эндпоинт может вытеснить всё остальное и сделать API кажущимся случайно сломанным.
Хорошие квоты кажутся справедливыми и предсказуемыми. Клиенты не должны узнавать правила только после блокировки.
Держите разделение ясным:
Многие команды используют оба типа: краткосрочный лимит для спирания всплесков и месячную квоту, привязанную к тарифу.
Жёсткие vs мягкие лимиты — в основном вопрос поддержки. Жёсткий лимит блокирует сразу. Мягкий сначала предупреждает, затем блокирует позже. Мягкие лимиты уменьшают число рассерженных тикетов, давая шанс исправить баг или апгрейднуть до того, как интеграция перестанет работать.
Когда кто-то превышает лимит, поведение должно соответствовать тому, что вы защищаете. Блокирование подходит, когда перерасход может навредить другим арендаторам или вздуть расходы. Деградация (медленнее обработка или более низкий приоритет) подходит, когда вы хотите, чтобы работа продолжалась. «Сначала выставить счёт» работает, когда использование предсказуемо и у вас уже есть биллинговый поток.
Ограничения по уровням работают лучше, когда у каждого тарифа есть понятная «форма использования». Бесплатный тариф может иметь маленькие месячные квоты и низкие скоростные пределы, а бизнес/enterprise — большие квоты и высокие burst-пределы, чтобы фоновые задачи успевали завершиться. Это похоже на то, как тарифы Free, Pro, Business и Enterprise у Koder.ai задают ожидания по объёму действий до перехода на следующий план.
Поддержка кастомных лимитов важна ещё на раннем этапе, особенно для enterprise. Чистый подход — «по умолчанию по плану, переопределения по заказчику». Храните override, установленный администратором для организации (и иногда для эндпоинта), и убедитесь, что он переживёт смену тарифа. Решите, кто может запрашивать изменения и как быстро они вступают в силу.
Пример: клиент импортирует 50 000 записей в последний день месяца. Если месячная квота почти использована, мягкое предупреждение на 80–90% даст время приостановить импорт. Краткосрочный лимит в запросах в секунду предотвратит поток запросов, а одобренное переопределение для организации (временное или постоянное) позволит бизнесу двигаться дальше.
Сначала опишите, что вы будете считать и кому это принадлежит. Большинство команд используют три идентичности: вошедший пользователь, организация (рабочее пространство) и клиентский IP.
Практический план:
При настройке лимитов думайте о тарифах и группах эндпоинтов, а не об одном глобальном числе. Частая ошибка — полагаться на in-memory счётчики на нескольких серверах. Счётчики расходятся, и пользователи видят «рандомные» 429. Общий стор вроде Redis делает лимиты стабильными между инстансами, а TTL держит данные маленькими.
Важно и корректное развертывание. Начните в режиме «только отчётность» (логируйте, что было бы заблокировано), затем включайте enforcement для одной группы эндпоинтов, затем расширяйте. Так вы избежите шквала тикетов в поддержку.
Когда клиент попадает под лимит, худший результат — путаница: «Упала ли ваша API или я что-то сделал не так?» Чёткие и последовательные ответы сокращают тикеты в поддержку и помогают людям исправить поведение клиента.
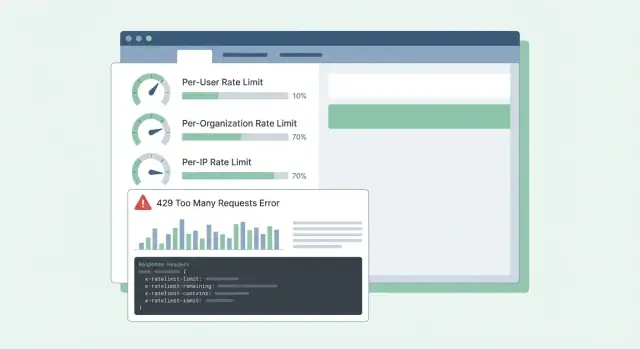
Используйте HTTP 429 Too Many Requests, когда вы блокируете вызовы. Держите тело ответа предсказуемым, чтобы SDK и дашборды могли его читать.
Вот простой JSON-шаблон, который хорошо работает для per-user, per-org и per-IP лимитов:
{
\"error\": {
\"code\": \"rate_limit_exceeded\",\n \"message\": \"Rate limit exceeded for org. Try again later.\",\n \"limit_scope\": \"org\",\n \"reset_at\": \"2026-01-17T12:34:56Z\",\n \"request_id\": \"req_01H...\"\n }
}
Заголовки должны объяснять текущее окно и что клиент может сделать дальше. Если добавить всего несколько, начните с: RateLimit-Limit, RateLimit-Remaining, RateLimit-Reset, Retry-After и X-Request-Id.
Пример: cron-задача клиента запускается каждую минуту и вдруг начинает падать. С 429 плюс RateLimit-Remaining: 0 и Retry-After: 20 они сразу поймут, что это лимит, а не простои, и смогут отложить повторы на 20 секунд. Если они сообщат X-Request-Id в поддержку, вы быстро найдёте событие.
Ещё одно важное: возвращайте те же заголовки и при успешных ответах. Клиенты увидят, что приближаются к краю до блокировки.
Хорошие клиенты делают лимиты незаметными. Плохие клиенты превращают временный лимит в простой, усиленно добивая систему.
При получении 429 рассматривайте это как сигнал замедлиться. Если ответ содержит рекомендованное время повтора (например, через Retry-After), ждите не меньше этого времени. Если его нет, используйте экспоненциальный бэкофф с джиттером, чтобы тысячи клиентов не повторяли одновременно.
Ограничивайте ретраи: ставьте верхнюю границу на задержку между попытками (например, 30–60 секунд) и на общее время попыток (например, прекращать после 2 минут и показывать ошибку). Также логируйте событие с деталями лимита, чтобы разработчики могли настроить поведение позже.
Не повторяйте всё подряд. Многие ошибки не пройдут без изменения или действий пользователя: 400 — валидация, 401/403 — аутентификация, 404 — не найдено, 409 — конфликт бизнес-правила.
Ретрай опасен для операций записи (create, charge, send email). При таймауте повтор может привести к дублированию. Используйте idempotency keys: клиент посылает уникальный ключ для логической операции, а сервер возвращает тот же результат для повторов с тем же ключом.
Хорошие SDK упрощают жизнь: они показывают статус (429), сколько ждать, можно ли безопасно повторить запрос, и сообщение вроде «Rate limit exceeded for org. Retry after 8s or reduce concurrency.»
Большинство тикетов про лимиты — не про сам лимит, а про сюрпризы. Если пользователи не понимают, что будет дальше, они думают, что API сломано или несправедливо.
Использовать только IP-лимиты — частая ошибка. Многие команды находятся за одним публичным IP (офис, мобильные сети, cloud NAT). Если ограничивать по IP, один активный клиент может заблокировать всех на той же сети. Предпочитайте лимиты по пользователю и по организации, а по IP используйте как запасной механизм.
Ещё одна проблема — все эндпоинты равны. Дешёвый GET и тяжёлый экспорт не должны делить один бюджет. Иначе клиенты потратят квоту на обычный просмотр, а при реальной задаче их заблокирует. Разделяйте бакеты по группам эндпоинтов или взвешивайте запросы по стоимости.
Время сброса тоже должно быть явным. «Сбрасывается ежедневно» — мало. В каком часовом поясе? Скользящее окно или сброс в полночь? Если календарный сброс — укажите временную зону. Если скользящее окно — укажите длину окна.
Наконец, расплывчатые ошибки создают хаос. Возврат 500 или общей JSON-ошибки заставляет людей повторять чаще. Используйте 429 и включайте заголовки RateLimit, чтобы клиенты могли корректно отступить.
Пример: если команда делает интеграцию Koder.ai с корпоративной сети, IP-only кап может заблокировать всю организацию и выглядеть как случайные сбои. Чёткие измерения и 429 ответы предотвращают это.
Перед включением лимитов для всех, пройдитесь по пунктам, фокусируясь на предсказуемости:
Проверка интуитивно: если у продукта есть тарифы Free, Pro, Business и Enterprise (как у Koder.ai), вы должны уметь простыми словами объяснить, что нормальный клиент может делать в минуту и в день, и какие эндпоинты обрабатываются иначе.
Если вы не можете ясно объяснить 429, клиенты сочтут API сломанным, а не защищающим сервис.
Представьте B2B SaaS, где люди работают внутри рабочего пространства (org). Несколько power-пользователей запускают тяжёлые экспорты, а многие сотрудники сидят за одним общим офисным IP. Если вы ограничиваете только по IP — блокируете целые компании. Если только по пользователю — скрипт всё равно может навредить воркспейсу.
Практичная смесь:
Когда кто-то попадает под лимит, ваше сообщение должно сказать, что произошло, что делать дальше и когда пробовать снова. Поддержка должна опираться на формулировки типа:
"Request rate exceeded for workspace ACME. You can retry after 23 seconds. If you are running an export, reduce concurrency to 2 or schedule it off-peak. If this blocks normal use, reply with your workspace ID and timestamp and we can review your quota."
Сопроводите сообщение заголовком Retry-After и последовательными RateLimit-заголовками, чтобы клиентам не приходилось гадать.
План развёртывания без сюрпризов: сначала наблюдение, затем предупреждение (заголовки и мягкие оповещения), затем принудительное применение (429 с явным временем повтора), затем настройка порогов по тарифам и ревью после крупных запусков и онбордингов.
Если вы хотите быстро превратить эти идеи в работающий код, платформа типа Koder.ai (koder.ai) может помочь с черновой спецификацией лимитов и генерацией Go-middleware, которое будет это последовательно исполнять.
Ограничение скорости определяет, как быстро вы можете делать запросы (например, запросы в секунду или в минуту). Квота определяет, сколько вы можете использовать за более длинный период (день, месяц или биллинговый цикл).
Чтобы снизить сюрпризы типа «вчера работало», показывайте оба правила явно и указывайте точное время сброса, чтобы клиенты могли предсказать поведение.
Начинайте с того, какую ошибку вы предотвращаете. Если всплески вызывают таймауты — нужен контроль кратковременных пиков; если определённые эндпоинты сильно тратят ресурсы — нужен бюджет, основанный на стоимости; при переборе учётных данных или скрейпинге — нужны строгие меры против злоупотреблений.
Простой способ решить: спросите себя, что сломается первым, если трафик на этот эндпоинт вырастет в 10× — задержка, стоимость или безопасность? Проектируйте лимит вокруг ответа.
Используйте лимиты по пользователю, чтобы один человек не замедлял коллег; лимиты по организации, чтобы рабочее пространство укладывалось в предсказуемый потолок, соответствующий ценовой и ёмкостной политике. Добавляйте лимиты по токену для интеграций с общим ключом, чтобы они не заглушали интерактивных пользователей.
Ограничения по IP рассматривайте как запасной механизм для очевидных злоупотреблений: у сетей часто общий публичный IP, поэтому IP-лимиты не годятся для точного биллинга.
Token bucket — хороший выбор по умолчанию: он позволяет кратковременные всплески, сохраняя средний предел за время. Это подходит для UX-случаев, когда дашборд делает несколько быстрых запросов.
Если бекенд не выдерживает всплесков вовсе, подойдёт leaky bucket или явная очередность: они сглаживают поток, но менее терпимы к пикам.
Добавляйте ограничения по конкурентности, когда вред наносит не количество запросов, а большое число одновременных открытых соединений. Это важно для медленных эндпоинтов, стриминга, долгих экспортов или плохих сетевых условий.
Ограничение конкурентности не позволит клиенту «вписаться» в 60 запросов в минуту, но держать 200 открытых соединений.
Возвращайте HTTP 429, когда вы активно ограничиваете запросы, и включайте понятное тело ошибки, где указано, какой скоуп был превышен (user, org, IP или token) и когда можно попробовать снова. Самый полезный заголовок — Retry-After, потому что он говорит клиентам, сколько ждать.
Также возвращайте заголовки лимита и при успешных ответах, чтобы клиенты видели, что приближаются к пределу.
Если в ответе есть Retry-After, подождите как минимум это время. Если его нет — используйте экспоненциальный бэкофф с небольшим джиттером, чтобы тысячи клиентов не попытались повторить одновременно.
Ограничивайте ретраи: верхний предел задержки (например, 30–60 с) и общее время попыток (например, прекращать после 2 минут). Не повторяйте ошибки, которые не исправятся повтором (400, 401/403, 404, 409).
Жёсткие лимиты нужны, когда превышение может навредить другим клиентам или вызвать немедленные расходы, которые вы не можете поглотить. Мягкие лимиты полезны, когда вы хотите сначала предупредить и дать время исправить баг или сделать апгрейд.
Практика: предупреждать на 80–90% использования, а затем применять блокировку — это снижает количество срочных обращений в поддержку.
Ограничения по IP должны быть щедрыми и использоваться в основном для защиты от злоупотреблений, потому что многие организации выходят в интернет через один публичный IP (NAT, офисный Wi‑Fi, мобильные операторы). Строгие IP-лимиты могут случайно заблокировать целую компанию.
Для формирующих нагрузку правил лучше использовать лимиты по пользователю и по организации, а IP оставить как страховку.
Внедряйте поэтапно. Сначала «только отчётность» — логируйте, что было бы заблокировано. Потом включайте предупреждения (заголовки и мягкие оповещения), затем — жёсткое ограничение (429 с явным временем повтора). Наблюдайте за всплесками 429, изменением задержек и наиболее часто блокируемыми ключами; эти сигналы покажут, где нужны корректировки, прежде чем пользователи начнут жаловаться.