Что делает поиск в приложении медленным или бесполезным
Говорят, что поиск должен казаться мгновенным, но редко имеют в виду ноль миллисекунд. Речь о том, чтобы получить понятный отклик достаточно быстро, чтобы не задумываться, услышало ли приложение ввод. Если что‑то заметное происходит примерно в течение секунды (обновление результатов, подсказка загрузки или устойчивый индикатор поиска), большинство пользователей сохраняют уверенность и продолжают печатать.
Поиск кажется медленным, когда интерфейс заставляет ждать в тишине или когда он реагирует шумно. Быстрый бэкенд не поможет, если ввод подвисает, список скачет или результаты постоянно сбрасываются во время набора.
Самые распространённые плохие симптомы поиска
Несколько шаблонов повторяются снова и снова:
- Задержки при вводе: курсор дергается, потому что приложение делает слишком много работы на каждое нажатие клавиши.
- Мигание: список очищается и заполняется заново, пользователь теряет место.
- Устаревшие результаты: интерфейс показывает результаты для старого запроса, потому что ответы приходят вне порядка.
- Неправильные совпадения: верхний результат кажется случайным, и пользователи перестают доверять поиску.
- Тупики: состояние «нет результатов» не даёт подсказок, и пользователю непонятно, что попробовать дальше.
Это важно даже при небольших наборах данных. При нескольких сотнях элементов люди всё равно используют поиск как быстрый способ, а не как последнее средство. Если он кажется ненадёжным, они переходят к прокрутке, фильтрам или бросают попытки. Маленькие наборы часто живут на мобильных устройствах и на устройствах с низкой производительностью, где лишняя работа на каждом нажатии заметнее.
Многое можно исправить до того, как добавлять специализированный поисковый движок. Большая часть скорости и полезности приходит от UX и управления запросами, а не от сложного индексирования.
Сначала сделайте интерфейс предсказуемым: держите ввод отзывчивым, не очищайте результаты слишком рано и показывайте спокойное состояние загрузки только когда нужно. Затем уменьшайте лишнюю работу с помощью debounce и отмены запросов, чтобы не запускать поиск на каждый символ. Добавьте небольшой кеш, чтобы повторяющиеся запросы казались мгновенными (например, при удалении символа). Наконец, используйте простые правила ранжирования (точное совпадение выше частичного, starts‑with выше contains), чтобы верхние результаты имели смысл.
Простой набор целей и границ для версии 1
Исправления скорости не помогают, если поиск пытается делать всё сразу. Версия 1 лучше работает, когда область, критерий качества и ограничения явны.
Выберите область, соответствующую задаче
Решите, для чего нужен поиск. Это быстрый селектор для поиска известного элемента или инструмент для исследования большого объёма контента?
Для большинства приложений достаточно искать по нескольким ожидаемым полям: заголовки, имена и ключевые идентификаторы. В CRM это может быть имя контакта, компания и email. Полнотекстовый поиск по заметкам можно отложить до появления явных доказательств необходимости.
Определите «достаточно хорошую» релевантность
Вам не нужен идеальный ранжир, чтобы выпускать продукт. Но нужны результаты, которые воспринимаются как справедливые.
Используйте правила, которые вы сможете объяснить человеку, если он спросит, почему появился тот или иной результат:
- Сначала точное совпадение ("Alex Kim" лучше, чем "Alexandra")
- Далее starts‑with ("pro" совпадает с "Project")
- Затем contains ("jet" совпадает с "Budget")
- Недавно использованные или закреплённые элементы получают небольшой буст
- Разрывайте равенства по алфавиту или по свежести
Этот базовый набор убирает неожиданности и уменьшает ощущение случайности.
Задайте ограничения заранее (и отразите их в UI)
Границы защищают производительность и предотвращают случаи, когда крайние ситуации ломают опыт.
Решите заранее такие вещи, как максимальное число результатов (обычно 20–50), максимальная длина запроса (например, 50–100 символов) и минимальная длина запроса перед поиском (обычно 2). Если вы ограничиваете результаты 25, укажите это (например, "Топ 25 результатов"), вместо того чтобы подразумевать, что вы искали по всему.
Планирование офлайна и плохого соединения
Если приложение может использоваться в поездах, лифтах или при слабом Wi‑Fi, определите, что будет работать в этих условиях. Практичный выбор для версии 1: недавние элементы и небольшой кеш доступны офлайн, а всё остальное требует соединения.
При плохом соединении избегайте очищения экрана. Сохраняйте последние корректные результаты видимыми и показывайте явное сообщение, что результаты могут быть устаревшими. Это воспринимается спокойнее, чем пустое состояние, которое выглядит как ошибка.
Debounce и управление запросами без ощущения лага
Самый быстрый способ сделать UX поиска медленным — отправлять сетевой запрос на каждый символ. Люди печатают импульсами, и интерфейс начинает мигать между частичными результатами. Debounce решает это, ожидая небольшую паузу после последнего нажатия клавиши перед выполнением поиска.
Хорошая стартовая задержка — 150–300 мс. Меньшая всё ещё может спамить запросы, большая начинает казаться, что приложение игнорирует ввод. Если данные в основном локальные (уже в памяти), можно уменьшить задержку. Если каждый запрос идёт на сервер, придерживайтесь 250–300 мс.
Debounce лучше всего работает с минимальной длиной запроса. Для многих приложений 2 символа достаточно, чтобы избежать бесполезных запросов вроде "a", которые возвращают всё. Если пользователи часто ищут по коротким кодам (например, "HR" или "ID"), разрешите 1–2 символа, но только после паузы.
Управление запросами так же важно, как и debounce. Без него медленные ответы приходят вне порядка и перезаписывают более новые результаты. Если пользователь набрал "car", а затем быстро дописал "d" — "card", ответ для "car" может прийти последним и вернуть интерфейс назад.
Используйте один из следующих паттернов:
- Отменяйте текущие запросы при старте нового.
- Отслеживайте ID запроса и рендерьте только результаты с последнего ID.
- Храните последнюю строку запроса и игнорируйте ответы, которые ей не соответствуют.
Пока ждёте, давайте мгновенную обратную связь, чтобы приложение казалось отзывчивым до прихода результатов. Не блокируйте ввод. Покажите маленький встроенный спиннер в области результатов или короткую подсказку вроде "Поиск...". Если вы оставляете предыдущие результаты на экране, пометьте их мягко (например, "Показаны предыдущие результаты"), чтобы пользователи не путались.
Практический пример: в поиске контактов CRM держите список видимым, debounce 200 мс, ищите только после 2 символов и отменяйте старый запрос, когда пользователь продолжает ввод. Интерфейс остаётся спокойным, результаты не мигают, и пользователи чувствуют контроль.
Основы кеширования, которые безопасно ускоряют
Кеширование — один из простейших способов сделать поиск мгновенным, потому что многие запросы повторяются. Люди печатают, удаляют символы, повторяют запрос или переключаются между несколькими фильтрами.
Кешируйте, используя ключ, который отражает то, что пользователь реально запросил. Частая ошибка — кешировать только по тексту запроса и показывать неверные результаты при изменении фильтров.
Практичный ключ кеша обычно включает нормализованную строку запроса плюс активные фильтры и порядок сортировки. Если вы используете пагинацию — включите страницу или курсор. Если права доступа зависят от пользователя или рабочей области — тоже включите это.
Держите кеш маленьким и кратковременным. Храните только последние 20–50 поисков и удаляйте записи через 30–120 секунд. Этого достаточно для возврата при удалении символа, но недостаточно, чтобы долго выдавать неправильное состояние.
Вы также можете прогреть кеш, предварительно заполнив его тем, что пользователь только что видел: недавние элементы, последний открытый проект или результат пустого запроса (обычно "все элементы" отсортированные по свежести). В небольшой CRM кеширование первой страницы Customers делает первое взаимодействие с поиском мгновенным.
Не кешируйте ошибки так же, как успехи. Временная 500‑я ошибка или таймаут не должны отравлять кеш. Если храните ошибки вообще, делайте для них гораздо меньший TTL.
И наконец, решите, как записи кеша инвалидируются при изменении данных. Минимум — очищайте релевантные ключи при создании, редактировании или удалении объектов, при изменении прав доступа или смене аккаунта/рабочей области.
Основы релевантности с простыми объяснимыми правилами
Если результаты кажутся случайными, люди перестают доверять поиску. Вы можете получить надёжную релевантность без отдельного поискового движка, используя несколько правил, которые можно объяснить.
Простой рецепт подсчёта очков
Начните с приоритета совпадений:
- Точное совпадение (всё поле равно запросу)
- Совпадение префикса (начинается с запроса)
- Совпадение по вхождению (запрос встречается в любом месте)
- Токен‑совпадение (любое слово запроса совпадает с любым словом в поле)
Затем добавляйте небольшие бусты важным полям. Заголовки обычно важнее описаний. ID или теги часто важнее, когда пользователь вставляет их целиком. Держите веса небольшими и последовательными, чтобы можно было рассуждать о результатах.
На этом этапе лёгкая обработка опечаток — в основном нормализация, а не тяжёлый fuzzy matching. Нормализуйте и запрос, и текст, по которому ищете: переводите в нижний регистр, обрезайте пробелы, сводите множественные пробелы в один и убирайте диакритические знаки, если это релевантно аудитории. Это решит многие жалобы «почему не нашёл».
Решите заранее, как вы обращаетесь с символами и цифрами, потому что это меняет ожидания. Простая политика: хештеги оставляйте частью токена, дефисы и подчёркивания считайте пробелами, цифры сохраняйте, а большую часть пунктуации удаляйте (но сохраняйте @ и . при поиске по email или юзернеймам).
Делайте ранжирование объяснимым. Один простой приём — хранить короткую отладочную причину для результата в логах: "prefix в title" лучше, чем "contains в description".
Локальный против серверного поиска: практическое разделение
Быстрый опыт поиска часто сводится к одному выбору: что можно фильтровать на устройстве, а что обязательно нужно спрашивать у сервера.
Локальная фильтрация лучше работает, когда данные небольшие, уже показаны на экране или недавно использованы: последние 50 чатов, недавние проекты, сохранённые контакты или элементы, которые вы уже получили для списка. Если пользователь только что видел элемент, он ожидает, что поиск найдёт его мгновенно.
Серверный поиск нужен для огромных наборов данных, часто меняющейся информации или всего, что вы не хотите скачивать локально. Он также необходим, если результаты зависят от прав доступа и общих рабочих областей.
Практичный паттерн, который остаётся стабильным:
- Сначала показывайте локальные совпадения из того, что уже есть.
- Запускайте серверный запрос в фоне для более широкого охвата.
- Объединяйте результаты по приходу ответа (убирайте дубли по ID).
- Держите высоту контейнера результатов стабильной, чтобы страница не прыгала.
- Сохраняйте фокус в поле поиска.
Пример: CRM может мгновенно отфильтровать недавно просмотренных клиентов по запросу "ann", а затем тихо загрузить полные серверные результаты по всей базе для "Ann".
Чтобы избежать сдвигов в верстке, резервируйте место для результатов и обновляйте строки на месте. Если вы переходите от локальных к серверным результатам, достаточно тонкой подсказки "Обновлены результаты". Поведение клавиатуры должно оставаться консистентным: стрелки перемещаются по списку, Enter выбирает, Escape очищает или закрывает.
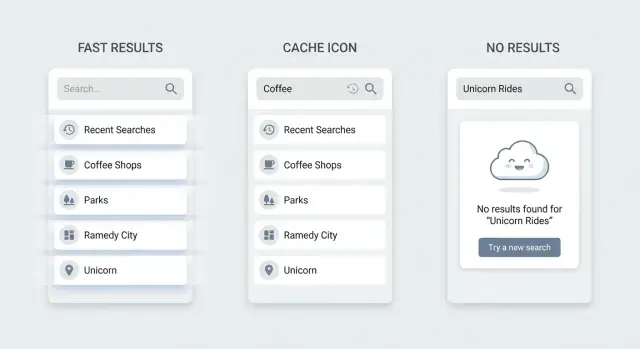
Пустые, загрузочные и no‑results состояния, которые помогают пользователям
Большая часть фрустрации с поиском — не про ранжирование. Она про то, что делает экран, когда пользователь между действиями: до ввода, во время обновления результатов и когда ничего не совпадает.
Когда поле пустое: дайте точку входа
Пустая страница поисковика заставляет пользователей гадать, что работает. Лучшие варианты — недавние поиски (чтобы повторить задачу) и небольшой набор популярных элементов или категорий (чтобы просмотреть без ввода). Держите их небольшими, удобочитаемыми и доступными в один тап.
Во время загрузки: сохраняйте контекст, избегайте мигания
Пользователи воспринимают мигание как медлительность. Очищение списка при каждом нажатии делает интерфейс нестабильным, даже если бэкенд быстрый.
Держите предыдущие результаты на экране и показывайте небольшой индикатор загрузки возле поля ввода. Если ожидание может быть дольше, добавьте несколько skeleton‑строк внизу, сохраняя при этом существующий список.
Если запрос падает, покажите встроенное сообщение и оставьте старые результаты видимыми.
Нет результатов: превращайте тупики в шаги вперёд
Пустая страница с надписью «Нет результатов» — тупик. Подскажите, что попробовать дальше, исходя из возможностей UI. Если фильтры активны — предложите Clear filters в один тап. Если поддерживаются многословные запросы — предложите попробовать меньше слов. Если у вас есть известные синонимы — предложите альтернативу.
Также предоставьте запасной вид, чтобы пользователь мог продолжить (недавние элементы, топ‑элементы или категории), и добавьте действие «Создать новый», если продукт это поддерживает.
Конкретный сценарий: кто‑то ищет "invoice" в CRM и ничего не получает, потому что элементы помечены как "billing". Полезное состояние может предложить "Попробуйте: billing" и показать категорию Billing.
Логируйте запросы без результатов (с активными фильтрами), чтобы добавлять синонимы, улучшать метки или создавать недостающий контент.
Пошагово: соберите ощущение мгновенности за неделю
Ощущение мгновенности создаётся из небольшой, понятной версии 1. Большинство команд застревают, пытаясь поддержать все поля, все фильтры и идеальное ранжирование с первого дня.
Начните с одного сценария. Пример: в небольшой CRM люди в основном ищут клиентов по имени, email и компании, затем сужают по статусу (Active, Trial, Churned). Запишите эти поля и фильтры, чтобы все строили одно и то же.
Практичный недельный план:
- День 1: зафиксировать область. Выберите 3–5 полей для поиска, 0–2 фильтра и одно правило сортировки (например, точное совпадение сначала, затем префикс).
- День 2: сделать ввод безопасным. Добавьте debounce (обычно 150–250 мс) и отмену старых запросов, чтобы поздние ответы не перезаписывали новые.
- День 3: добавить простое ранжирование и подсветку. Используйте объяснимые правила (exact > starts‑with > contains). Подсвечивайте совпадения, чтобы пользователь видел, почему результат появился.
- День 4: добавить небольшой кеш. Кешируйте недавние запросы и результаты на короткое время (30–120 секунд) и переиспользуйте их при удалении символа или повторе запроса.
- День 5: доработать состояния UI. Добавьте лёгкое состояние загрузки и no‑results с действием для следующего шага.
Держите инвалидацию простой. Очищайте кеш при выходе, смене рабочей области и после любого действия, которое меняет основной список (создание, удаление, смена статуса). Если не можете надёжно детектировать изменения, используйте короткий TTL и рассматривайте кеш как подсказку скорости, а не источник истины.
Последний день используйте для измерений. Отслеживайте время до первого результата, долю no‑results и частоту ошибок. Если время до первого результата хорошее, но доля no‑results высокая — нужно пересмотреть поля, фильтры или формулировку.
Частые ошибки, делающие поиск неприятным
Большинство жалоб на медленный поиск на самом деле про обратную связь и корректность. Люди могут подождать секунду, если интерфейс живой и результаты имеют смысл. Они уходят, когда поле застряло, результаты скачут или приложение даёт ощущение, что пользователь что‑то сделал не так.
Распространённая ловушка — слишком большая задержка debounce. Если ждать 500–800 мс перед любым действием, ввод кажется невосприимчивым, особенно для коротких запросов вроде "hr" или "tax". Держите задержку маленькой и показывайте мгновенную обратную связь, чтобы ввод никогда не казался проигнорированным.
Ещё одна фрустрирующая вещь — позволять старым ответам побеждать. Если пользователь набрал "app" и быстро дописал "l", ответ для "app" может прийти последним и перезаписать результаты для "appl". Отменяйте предыдущий запрос или игнорируйте ответы, не соответствующие последнему запросу.
Кеш может навредить, если ключи слишком общие. Если ключ кеша — только текст запроса, а у вас есть фильтры (статус, диапазон дат, категория), вы покажете неверные результаты и пользователи перестанут доверять поиску. Рассматривайте запрос + фильтры + сорт как одну идентичность.
Ошибки ранжирования тонкие, но болезненные. Люди ожидают точных совпадений сверху. Простой и последовательный набор правил часто лучше умного, но непредсказуемого:
- Точное совпадение по имени или ID первым
- Префиксное совпадение следом
- Затем частичное совпадение в любом месте
- Fuzzy только если ничего другого нет
- Недавние или частые элементы могут решать ничьи, но не заменяют точные совпадения
Экраны «нет результатов» часто ничем не помогают. Покажите, что искали, предложите очистить фильтры, предложите более широкий запрос и отобразите несколько популярных или недавних элементов.
Пример: основатель ищет клиентов в простой CRM, вводит "Ana", у него стоит фильтр Active и он ничего не получает. Полезное пустое состояние сказало бы "Нет активных клиентов для 'Ana'" и предложило бы в один тап Показать все статусы.
Быстрый чеклист и следующие шаги
Прежде чем добавлять полноценный поисковый движок, убедитесь, что базовая часть спокойна: ввод остаётся плавным, результаты не скачут, и интерфейс всегда говорит пользователям, что происходит.
Короткий чеклист для версии 1:
- Ввод никогда не подтормаживает. Делайте работу после ввода, а не блокируйте сам ввод.
- Результаты обновляются в порядке. Отменяйте или игнорируйте старые запросы, чтобы не показывать устаревшие данные.
- Загрузка ясна, но ненавязчива. Держите текущий список видимым и показывайте небольшой индикатор обновления.
- Состояние «нет результатов» помогает пользователю восстановиться. Предлагайте очистить фильтры или попробовать более короткий запрос.
- Правила ранжирования записаны и последовательны.
Затем убедитесь, что кеш приносит больше пользы, чем вреда. Держите его небольшим (только недавние запросы), кешируйте окончательный список результатов и инвалидируйте при изменениях данных. Если вы не можете надёжно детектировать изменения, сократите время жизни кеша.
Следующие шаги
Двигайтесь маленькими измеримыми шагами:
- Добавьте крошечный тест‑план: 5 обычных запросов, 2 крайних случая и 1 сценарий no‑results.
- Логируйте только необходимое: длину запроса, время до первого результата и частоту отмен (избегайте личного текста, если можно).
- Раз в неделю добавляйте одно улучшение: лучшее ранжирование, лучшее пустое состояние или лучшее кеширование.
- Подключайте полноценный поисковый бэкенд только после того, как сможете объяснить, чего вам сегодня не хватает.
Если вы строите приложение на Koder.ai (koder.ai), стоит считать поиск важной функцией в ваших prompt и acceptance checks: определите правила, протестируйте состояния и сделайте так, чтобы UI вёл себя спокойно с самого первого дня.