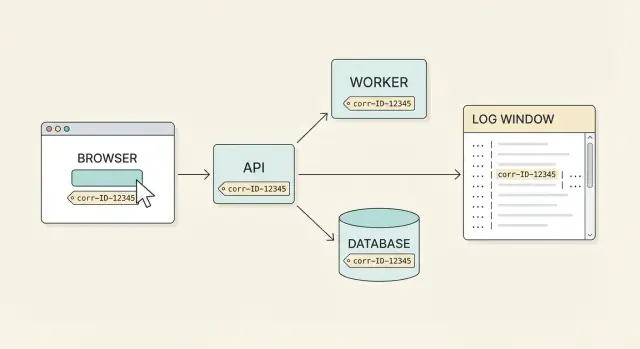
Почему корреляционные ID важны для поддержки
Поддержка почти никогда не получает идеальный баг-репорт. Пользователь может сказать «я нажал(а) Pay и всё упало», но один клик затрагивает браузер, API-шлюз, сервисы платежей, базу данных и фоновые задания. Каждая часть пишет свою часть истории в разное время на разных машинах. Без одного общего ярлыка приходится угадывать, какие строки логов относятся к одному событию.
Корреляционный ID — это такой общий ярлык. Это один идентификатор, прикреплённый к одному действию пользователя (или логическому workflow), который переносится через каждый запрос, повтор и переход между сервисами. При действительно end-to-end покрытии можно начать с жалобы пользователя и вытянуть полную временную шкалу по всем системам.
Люди часто путают несколько похожих идентификаторов. Вот чистое разделение:
- Correlation ID: группирует всё, что связано с одним действием (например, «Сохранение настроек»).
- Request ID: идентифицирует один HTTP-запрос. Повторы создают новые request ID.
- Trace ID: используется инструментами распределённого трейсинга; цель похожа, часто генерируется библиотеками трассировки.
- Session ID: идентифицирует пользовательскую сессию через множество действий; слишком широк для отладки одного инцидента.
Хороший результат прост: пользователь сообщает проблему, вы просите у него корреляционный ID, который показан в UI (или в экране поддержки), и любой в команде может найти полную историю за считанные минуты. Видны фронтенд-запрос, ответ API, шаги бэкенда и результат базы данных — всё связано одним идентификатором.
Решите конвенции для корреляционного ID
Прежде чем что-то генерировать, договоритесь о нескольких правилах. Если каждая команда выберет своё имя заголовка или поле лога, поддержка всё равно будет гадать.
Начните с одного канонического имени и используйте его везде. Частый выбор — HTTP-заголовок вроде X-Correlation-Id и структурное поле в логах вроде correlation_id. Выберите одно написание и одну регистрозависимость, задокументируйте это и убедитесь, что ваш обратный прокси или шлюз не переименует и не удалит заголовок.
Выберите формат, который легко создать и безопасно передавать в тикетах и чатах. UUID хорошо подходит: уникален и прост. Держите ID достаточно коротким, чтобы его можно было скопировать, но не настолько коротким, чтобы были коллизии. Последовательность важнее хитростей.
Также решите, где ID обязательно должен появляться, чтобы люди могли им пользоваться. На практике это значит: он должен присутствовать в запросах, логах и выводах ошибок, и быть доступным для поиска в том инструменте, которым пользуется команда.
Определите, как долго живёт один ID. Хороший дефолт — одно пользовательское действие, например «нажал(а) Pay» или «сохранил профиль». Для более длинных рабочих процессов, перескакивающих между сервисами и очередями, сохраняйте тот же ID до завершения workflow, затем для следующего действия создавайте новый. Избегайте «один ID на всю сессию», потому что поиск быстро станет шумным.
Жёсткое правило: никогда не включайте персональные данные в ID. Никаких email, телефонов, пользовательских идентификаторов или номеров заказов. Если нужен такой контекст — логируйте его отдельными полями с корректной приватностью.
Генерация ID на фронтенде (практический подход)
Проще всего начать корреляционный ID в момент, когда пользователь начинает важное действие: клик «Сохранить», отправка формы или запуск потока, который порождает несколько запросов. Если ждать, пока бэкенд создаст ID, вы часто потеряете первую часть истории (ошибки UI, повторы, отмены запросов).
Используйте случайный уникальный формат. UUID v4 — частый выбор: его легко сгенерировать и вероятность коллизии мала. Держите ID непрозрачным (без имён пользователей, email или временных меток), чтобы не утекали персональные данные в заголовках и логах.
Создайте и храните ID для одного workflow
Рассматривайте «workflow» как одно действие пользователя, которое может порождать несколько запросов: валидация, загрузка, создание записи, обновление списков. Создайте один ID при старте workflow и храните его до конца (успех, ошибка или отмена пользователем). Простая схема — хранить его в состоянии компонента или в лёгком контексте запроса.
Если пользователь запускает то же действие дважды, создавайте новый корреляционный ID для второй попытки. Это позволит поддержке отличить «повтор одного клика» от «двух отдельных отправок».
Прикрепляйте его ко всем запросам этого workflow
Добавляйте ID ко всем API-вызовам, инициируемым workflow, обычно через заголовок вроде X-Correlation-ID. Если у вас есть общий клиент API (обёртка fetch, экземпляр Axios и т.п.), передавайте ID один раз и пусть клиент вставляет его во все вызовы.
const correlationId = crypto.randomUUID();
await api.post('/orders', payload, {
headers: { 'X-Correlation-ID': correlationId }
});
await api.get('/orders/summary', {
headers: { 'X-Correlation-ID': correlationId }
});
Если UI делает фоновые запросы, не связанные с действием (polling, аналитика, автообновление), не переиспользуйте workflow ID для них. Держите корреляционные ID сфокусированными, чтобы один ID рассказывал одну историю.
Надёжная передача ID через ваши API
После генерации корреляционного ID в браузере задача простая: он должен уходить с фронтенда в каждом запросе и доходить неизменным до каждой границы API. Именно тут чаще всего всё ломается, когда команды добавляют новые эндпоинты, новые клиенты или новое middleware.
Самый безопасный дефолт — HTTP-заголовок в каждом вызове (например, X-Correlation-Id). Заголовки легко добавить в одном месте (в обёртке fetch, интерсепторе Axios, сетевом слое мобильного приложения) и не требуют изменения тела запроса.
Если у вас кросс-доменные запросы, убедитесь, что API разрешает этот заголовок. Иначе браузер может тихо блокировать его, и вы будете думать, что он отправляется, хотя это не так.
Если придётся передавать ID в query-string или теле запроса (некоторые сторонние инструменты или загрузки файлов требуют этого), держите это консистентно и задокументируйте. Выберите одно имя поля и используйте его везде. Не мешайте correlationId, requestId и cid в зависимости от эндпоинта.
Ещё одна ловушка — ретраи. Ретрай должен сохранять тот же корреляционный ID, если это всё ещё одно и то же действие пользователя. Пример: пользователь нажал «Сохранить», сеть упала, клиент повторно отправляет POST. Поддержка должна видеть одну связанную цепочку, а не три несвязанных. Новая попытка пользователя (или новое фоновое задание) должна получить новый ID.
Для WebSocket включайте ID в тело сообщений, а не только в начальном рукопожатии. Одно соединение может нести множество действий.
Для быстрой проверки надёжности держите всё просто:
- Один общий helper клиента добавляет заголовок ко всем запросам.
- Ретраи переиспользуют тот же ID для одного действия.
- Любой fallback в теле/строке запроса использует одно задокументированное имя поля.
- Сообщения WebSocket включают явное поле
correlationId.
Поведение на точке входа API
Быстрее развернуть отслеживаемое приложение
От плана до работающего приложения без настройки серверов вручную.
Ваш API edge (gateway, load balancer или первый веб-сервис, принимающий трафик) — это место, где корреляционные ID либо становятся надёжными, либо превращаются в догадки. Рассматривайте эту точку входа как источник правды.
Принимайте входящий ID, если клиент его прислал, но не предполагаете, что он всегда есть. Если он отсутствует — сгенерируйте новый и используйте его для остальной части обработки запроса. Это сохраняет работоспособность даже когда клиенты старые или неверно настроены.
Делайте лёгкую валидацию, чтобы плохие значения не загрязняли логи. Будьте терпимы: проверьте длину и допустимые символы, но избегайте строгих форматов, отбрасывающих реальный трафик. Например, разрешите 16–64 символа и буквы, цифры, дефис и подчёркивание. Если значение не проходит валидацию — замените его на свежий ID и продолжайте.
Делайте ID видимым для вызывающего. Всегда возвращайте его в заголовках ответа и включайте в тела ошибок. Тогда пользователь сможет скопировать его из UI, а агент поддержки попросит его и найдёт точную цепочку в логах.
Практическая политика на edge выглядит так:
- Считать
X-Correlation-ID (или выбранный заголовок) из запроса.
- Если он отсутствует или недействителен — создать новый и прикрепить к контексту запроса.
- Добавлять
X-Correlation-ID ко всем ответам, включая ошибки.
- При возвращении JSON-ошибок отражать ID в полезной нагрузке.
Пример полезной нагрузки ошибки (что поддержка должна видеть в тикетах и скриншотах):
{
"error": {
"code": "PAYMENT_FAILED",
"message": "We could not confirm the payment.",
"correlation_id": "c3a8f2d1-9b24-4c61-8c4a-2a7c1b9c2f61"
}
}
Пропагирование ID между бэкенд-сервисами
После того как запрос достигает бэкенда, рассматривайте корреляционный ID как часть контекста запроса, а не как глобальную переменную. Глобальные переменные ломаются, когда обрабатываются параллельные запросы или когда асинхронная работа продолжается после ответа.
Правило, которое масштабируется: каждая функция, которая может логировать или вызывать другой сервис, должна получать контекст с ID. В Go-сервисах это обычно означает передачу context.Context вниз через обработчики, бизнес-логику и клиентский код.
Когда Сервис A вызывает Сервис B, копируйте тот же ID в исходящий запрос. Не генерируйте новый mid-flight, если не сохраняете оригинал как отдельное поле (например, parent_correlation_id). Если вы меняете ID, поддержка теряет единую нить, связывающую историю.
Пропагация часто упускается в нескольких предсказуемых местах: фоновые задания, инициированные во время запроса, ретраи внутри клиентских библиотек, вебхуки, триггерящиеся позже, и фан-аут вызовы. Любое асинхронное сообщение (очередь/задание) должно нести ID, и любая логика повторных попыток должна его сохранять.
Логи должны быть структурированными с постоянным именем поля вроде correlation_id. Выберите одно написание и держитесь его везде. Избегайте смешения requestId, req_id и traceId, если только вы явно не определили соответствие между ними.
Если возможно, включите ID и в видимость базы данных. Практичный подход — добавлять его в комментарии к запросу или в метаданные сессии, чтобы slow query логи могли его показывать. Тогда при жалобе «Сохранение висело 10 секунд» поддержка сможет найти correlation_id=abc123 и увидеть API-лог, downstream-вызов и один медленный SQL-запрос, вызвавший задержку.
Включайте ID в логи, удобные людям
Корреляционный ID полезен только если люди могут его найти и проследить. Сделайте его первоклассным полем лога (не прячьте внутри текстовой строки) и держите остальные поля записи логов согласованными между сервисами.
Поля логов, которые делают ID полезным
Сопоставьте корреляционный ID с небольшим набором полей, отвечающих на вопросы: когда, где, что и кто (без персональных данных). Для большинства команд это означает:
timestamp (с часовым поясом)service и env (api, worker, prod, staging)route (или имя операции) и methodstatus и duration_ms- безопасный идентификатор пользователя (например,
account_id или захешированный user id, но не email)
С этим поддержка может искать по ID, убедиться, что смотрит на нужный запрос, и увидеть, какой сервис его обработал.
Что логировать на старте, при успехе и при ошибке
Стремитесь к нескольким важным «хлебным крошкам» на запрос, а не к расшифровке всего процесса.
- Start: correlation ID, route, безопасный идентификатор пользователя и ключевые входные данные (в сокращённом виде).
- Success: correlation ID, статус, длительность и краткий результат (например
rows=12).
- Failure: correlation ID, тип ошибки, безопасный контекст и где это произошло (handler, dependency).
Чтобы не получить шумные логи, держите подробности уровня debug выключенными по умолчанию и включайте только события, которые помогают ответить на вопрос «Где случился сбой?». Если строка не помогает локализовать проблему или измерить её влияние, вероятно, ей не место в info-логах.
Редакция данных важна так же, как и структура. Никогда не помещайте PII в корреляционный ID или логи: ни email, ни имена, ни телефоны, ни полные адреса или сырые токены. Если нужно идентифицировать пользователя, логируйте внутренний ID или однонаправленный хеш.
Пример: от UI до базы — отслеживаем жалобу пользователя
Отслеживать рабочие процессы между сервисами
Проектируйте распространение для API, workers и очередей, не нарушая цепочку корреляции.
Пользователь пишет в поддержку: "Checkout failed when I clicked Pay." Лучший вопрос в ответ прост: "Можете вставить корреляционный ID с экрана ошибки?" Он отвечает cid=9f3c2b1f6a7a4c2f.
У поддержки теперь есть ручка, связывающая UI, API и базу. Цель — чтобы каждая запись лога для этого действия несла одинаковый ID.
Поддержка ищет логи по 9f3c2b1f6a7a4c2f и видит поток:
frontend INFO cid=9f3c2b1f6a7a4c2f event="checkout_submit" cart=3 items
api INFO cid=9f3c2b1f6a7a4c2f method=POST path=/api/checkout user=1842
api ERROR cid=9f3c2b1f6a7a4c2f msg="payment failed" provider=stripe status=502
Далее инженер идёт по тому же ID в следующий сервис. Главное — backend-вызовы (и задания в очередях) тоже передают ID.
payments INFO cid=9f3c2b1f6a7a4c2f action="charge" amount=49.00 currency=USD
payments ERROR cid=9f3c2b1f6a7a4c2f err="timeout" upstream=stripe timeout_ms=3000
db INFO cid=9f3c2b1f6a7a4c2f query="insert into failed_payments" rows=1
Теперь проблема конкретна: платежный сервис истёк по таймауту через 3 секунды и записал запись о неудаче. Инженер может проверить последние деплои, посмотреть, не изменялись ли таймауты, и увидеть, происходят ли повторы.
Чтобы закрыть цикл, выполните четыре шага:
- Исправьте причину (например, отрегулируйте таймаут и добавьте безопасный retry).
- Убедитесь, что ошибки, видимые пользователю, включают корреляционный ID.
- Следите за новыми логами с тем же паттерном ошибки и разными ID.
- Подтвердите, что ID проходит через все переходы (включая workers и сообщения в очередях).
Частые ошибки и как их избегать
Самый быстрый способ сделать корреляционные ID бесполезными — разорвать цепочку. Большинство сбоев возникают из мелких решений, которые кажутся безвредными в процессе разработки, но мешают, когда поддержке нужны ответы.
Классическая ошибка — генерировать новый ID на каждом шаге. Если браузер прислал ID, ваш API-шлюз должен его сохранить, а не заменить. Если действительно нужен внутренний ID (для очереди или фоновой задачи), держите оригинал как parent поле, чтобы история оставалась связной.
Ещё одна привычная пробоина — частичное логирование. Команды добавляют ID в первый API, но забывают про worker-процессы, планировщики или слой доступа к базе. В итоге получается тупик: видно вход в систему, но не видно, куда запрос ушёл дальше.
Избегайте проблемы «хаоса имён»
Даже при наличии ID повсюду, поиск может быть тяжёлым, если каждый сервис использует своё имя поля или формат. Выберите одно имя и придерживайтесь его на фронтенде, в API и в логах (например, correlation_id). Также выберите один формат (часто UUID) и относитесь к нему как к чувствительному к регистру, чтобы copy-paste работал надёжно.
Не теряйте ID в момент ошибки. Если API возвращает 500 или валидационную ошибку, включайте корреляционный ID в ответ (и желательно в заголовок ответа). Тогда пользователь сможет вставить его в чат поддержки, и команда сразу проследит путь.
Быстрый тест: может ли сотрудник поддержки начать с одного ID и проследовать по всем строкам логов, включая ошибки?
Быстрый чеклист для верификации end-to-end покрытия
Сделать экраны ошибок удобными для поддержки
Делайте UI-ошибки с копируемым корреляционным ID для ускорения обработки тикетов.
Используйте это как здравый осмотр перед тем, как сказать поддержке «ищите в логах». Всё работает только если каждый шаг следует одинаковым правилам.
Обязательные проверки
- У вас один формат ID и одно имя заголовка, используемые везде (фронтенд, шлюз, API, workers).
- Фронтенд создаёт (или принимает) ID в начале действия и сохраняет его, пока действие не завершится.
- Точка входа API создаёт ID при отсутствии и всегда возвращает его в заголовках ответа.
- Каждый бэкенд-сервис включает
correlation_id в логи, связанные с запросом, как структурное поле.
- Дежурный может вставить один ID в поиск логов и увидеть весь путь за пару минут: запрос на edge, auth, вызовы сервисов, операция в базе и повторы.
Если какая-то проверка не проходит — исправляйте так
Выберите минимальное изменение, которое сохраняет непрерывность цепочки.
- Если ID меняются mid-flight, перестаньте генерировать новые ID внутри внутренних сервисов. Сохраняйте оригинальный
correlation_id и добавляйте отдельный span_id, если нужна детализация.
- Если в логах отсутствует поле, добавьте middleware для логирования, чтобы инженерам не приходилось вспоминать о нём вручную.
- Если поддержка не может получить ID, убедитесь, что UI показывает его на экранах ошибок, а шлюз отражает его в каждом ответе.
Быстрый тест, который ловит большинство пробелов: откройте devtools, выполните действие, скопируйте корреляционный ID из первого запроса, затем подтвердите, что видите то же значение в каждом связанном API-заголовке и в каждой соответствующей строке лога.
Следующие шаги: включите это в процесс релизов
Корреляционные ID помогают только когда ими пользовались всегда и одинаково. Рассматривайте поведение с ID как обязательный элемент релиза, а не как приятную опцию логирования.
Добавьте небольшой шаг traceability в определение готовности (definition of done) для любого нового эндпоинта или UI-действия. Покройте: как ID создаётся (или переиспользуется), где он хранится в ходе потока, какой заголовок его несёт и что делает каждый сервис, если заголовок отсутствует.
Лёгкий чеклист обычно достаточен:
- Фронтенд: генерирует или переиспользует один ID на действие пользователя и прикрепляет его ко всем API-вызовам для этого действия.
- Точка входа API: принимает заголовок, проверяет или генерирует, затем возвращает его в ответе.
- Бэкенд: передаёт ID вниз по цепочке до downstream-сервисов и задач, и включает его в логи.
- Логирование: сохраняйте единое имя поля (например,
correlation_id) во всех приложениях и сервисах.
- Ревью: отклоняйте PR, которые добавляют эндпоинты без теста, доказывающего, что ID появляется в логах.
Поддержке также нужен простой скрипт, чтобы отладка была быстрой и воспроизводимой. Решите, где ID виден пользователям (например, кнопка "Copy debug ID" на диалогах ошибок), и опишите, что поддержка должна запрашивать и где искать.
Перед тем как полагаться на это в продакшене, прогоните staged flow, близкий к реальному использованию: нажмите кнопку, вызовите валидационную ошибку, затем доведите действие до конца. Подтвердите, что вы можете проследовать по одному ID от запроса браузера через логи API, в фоновые worker’ы и, при наличии, до логов базы данных.
Если вы строите приложения на Koder.ai, полезно задать заголовок корреляционного ID и соглашения по логированию в Planning Mode, чтобы сгенерированные React-фронтенды и Go-сервисы сразу были согласованными по умолчанию.