10 июн. 2025 г.·6 мин
Кэш‑слои сокращают нагрузку — но добавляют скрытую сложность
Кэш‑слои снижают задержки и нагрузку на бэкенд, но добавляют режимы отказа и операционные расходы. Узнайте про типичные слои, риски и способы уменьшить сложность.
Кэш‑слои снижают задержки и нагрузку на бэкенд, но добавляют режимы отказа и операционные расходы. Узнайте про типичные слои, риски и способы уменьшить сложность.
Кеширование сохраняет копию данных рядом с местом, где они нужны, чтобы запросы можно было обслуживать быстрее и с меньшим числом обращений к центральным системам. Выигрыш обычно проявляется в сочетании скорости (меньшая задержка), стоимости (меньше дорогих чтений из БД или внешних вызовов) и стабильности (оригинальные сервисы переживают всплески трафика).
Когда кэш отвечает на запрос, ваш «origin» (серверы приложений, БД, сторонние API) делает меньше. Это сокращение может быть впечатляющим: меньше запросов, меньше CPU‑циклов, меньше сетевых хопов и меньше таймаутов.
Кеширование также сглаживает всплески — помогая системам, рассчитанным на среднюю нагрузку, справляться с пиковыми моментами без немедленного автоскейла (или срывов).
Кеширование не убирает работу; оно перемещает её в дизайн и эксплуатацию. Перед вами появляются новые вопросы:
Каждый слой кэша добавляет конфигурацию, мониторинг и частные случаи. Кэш, ускоряющий 99% запросов, всё ещё может вызвать болезненные инциденты в оставшемся 1%: синхронизированные истечения, несогласованный пользовательский опыт или внезапные потоки на origin.
Один кэш — это одно хранилище (например, in‑memory рядом с приложением). Слой кэша — это отдельная контрольная точка в пути запроса — CDN, кэш браузера, кэш приложения, кэш базы данных — у каждого свои правила и режимы отказа.
В этой статье акцент на практической сложности, которую вносят множественные слои: корректность, инвалидация и эксплуатация (без глубокого обсуждения алгоритмов кэширования или тонкой настройки под конкретного вендора).
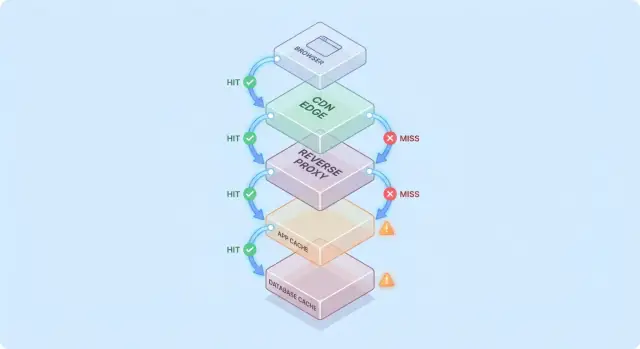
Кеширование становится проще для понимания, если представить запрос, который проходит через стек «может быть, у меня уже есть это» контрольных точек.
Обычно путь выглядит так:
На каждом этапе система либо возвращает кэшированный ответ (hit), либо переводит запрос дальше (miss). Чем раньше происходит попадание (например на edge), тем больше нагрузки вы избегаете в глубине стека.
Попадания красиво выглядят на дашбордах. Промахи показывают сложность: они запускают реальную работу (логика приложения, запросы в БД) и добавляют накладные расходы (поиска в кэше, сериализации, записи в кэш).
Полезная модель: каждый промах платит за кэш дважды — вы всё ещё делаете исходную работу, плюс работу, связанную с кэшированием.
Добавление слоя кэша редко устраняет узкие места; оно часто перемещает их:
Предположим, страница товара кэшируется на CDN на 5 минут, а приложение дополнительно хранит детали товара в Redis на 30 минут.
Если цена меняется, CDN может обновиться быстро, а Redis всё ещё отдаёт старую цену. Теперь «истина» зависит от того, какой слой ответил — раннее объяснение, почему кэш‑слои снижают нагрузку, но повышают сложность системы.
Кеширование — это не одна функция, а стек мест, где данные можно сохранить и повторно использовать. Каждый слой уменьшает нагрузку, но у каждого свои правила свежести, инвалидации и видимости.
Браузеры кешируют изображения, скрипты, CSS и иногда ответы API в зависимости от HTTP‑заголовков (например, Cache-Control и ETag). Это может полностью исключить повторные загрузки — отлично для производительности и уменьшения трафика CDN/origin.
Проблема: как только ответ закеширован на клиенте, вы не полностью контролируете время повторной валидации. Некоторые пользователи могут держать старые активы дольше (или очистить кэш неожиданно), поэтому versioned URLs (например, app.3f2c.js) — распространённая мера предосторожности.
CDN кеширует контент близко к пользователю. Он отлично подходит для статических файлов, публичных страниц и «в основном стабильных» ответов, таких как изображения товаров, документация или ограниченные по частоте API.
CDN также может кешировать полустатический HTML при аккуратной работе с вариациями (куки, заголовки, гео, устройство). Неправильно настроенные правила вариации часто приводят к выдаче неверного контента неверному пользователю.
Реверс‑прокси (NGINX, Varnish) стоят перед приложением и могут кешировать целиком ответы. Это полезно, когда нужно централизованное управление, предсказуемое вытеснение и быстрая защита origin при всплесках трафика.
Обычно они менее распределены глобально, чем CDN, но ими проще тонко управлять по маршрутам и заголовкам приложения.
Этот кэш ориентирован на объекты, вычисленные результаты и дорогие вызовы (например, «профиль пользователя по id» или «правила ценообразования по региону»). Он гибок и может учитывать бизнес‑логику.
Но он вводит новые точки принятия решений: дизайн ключей, выбор TTL, логика инвалидации и эксплуатационные задачи — размер, отказоустойчивость, фэйловеры.
Большинство БД кеширует страницы, индексы и планы запросов автоматически; некоторые поддерживают кеш результатов. Это может ускорить повторяющиеся запросы без изменений в коде приложения.
Лучше рассматривать это как бонус, а не гарантию: кэши БД обычно наиболее непредсказуемы при разнообразных паттернах запросов и не снимают стоимость записи, блокировок или конкуренции так, как внешние кэши.
Кеширование окупается, когда повторяющиеся, дорогие операции превращаются в дешёвый поиск. Важно подобрать кэш к рабочим нагрузкам, где запросы достаточно похожи и стабильны, чтобы их можно было повторно использовать.
Если система отдаёт много больше чтений, чем записей, кэш может убрать значительную долю работы БД и приложений. Страницы товара, публичные профили, справочные статьи и результаты поиска часто запрашивают с одинаковыми параметрами.
Кеширование также помогает с «дорогой» работой, не обязательно связанной с БД: генерация PDF, ресайз изображений, рендеринг шаблонов или вычисление агрегатов. Даже краткосрочный кэш (секунды‑минуты) может сократить повторяющиеся вычисления в пиковые периоды.
Кеширование особенно эффективно при неравномерном трафике. Когда рассылка, упоминание в новостях или соцсетях приводит всплеск пользователей на одни и те же URL, CDN или edge‑кэш может поглотить основную часть этого наплыва.
Это снижает нагрузку не только за счёт «быстрее»: оно предотвращает скачки автоскейлинга, исчерпание подключений к БД и даёт время механизмам ограничения скорости и обратного давления сработать.
Если ваш бэкенд далеко от пользователей — географически или логически (медленная зависимость) — кэширование уменьшает и нагрузку, и воспринимаемую задержку. Отдача с CDN рядом с пользователем исключает повторные долгие поездки к origin.
Внутренние кэши тоже помогают, если узкое место — это высоколатентное хранилище (удалённая БД, сторонний API, общий сервис). Сокращение числа вызовов снижает конкуренцию и улучшает хвостовую латентность.
Кеширование даёт меньше пользы, когда ответы сильно персонализированы (данные по пользователю, конфиденциальные детали) или данные постоянно меняются (живые дашборды, быстро обновляющиеся остатки). В таких сценариях коэффициент попаданий низок, стоимость инвалидации растёт, и сэкономленная работа бекенда может быть незначительной.
Практическое правило: кэш особенно ценен, когда много пользователей просят одно и то же в окне, в котором «одно и то же» остаётся валидным. Если такого пересечения нет, ещё один слой кэша может прибавить сложности без реального сокращения нагрузки.
Кеширование легко, когда данные никогда не меняются. Стоит им измениться, и вы получаете самое трудное: решение, когда кэш перестаёт быть доверенным, и как каждый слой узнаёт об изменении.
Time‑to‑live привлекательна тем, что это одно число и никакой координации. Проблема в том, что «правильный» TTL зависит от сценария использования.
Если вы ставите TTL 5 минут для цены продукта, некоторые пользователи будут видеть старую цену после изменения — возможно, с юридическими или поддержкой последствиями. Если вы ставите 5 секунд — вы вряд ли существенно уменьшите нагрузку. Ещё хуже: разные поля в одном ответе меняются с разной скоростью (инвентарь vs описание), так что единый TTL вынуждает компромисс.
Событийная инвалидация говорит: когда источник правды меняется — опубликуй событие и очисти/обнови все затронутые ключи. Это может быть очень корректно, но создаёт новую работу:
Эта карта — именно то место, где «две тяжёлые вещи: нейминг и инвалидация» становятся практической болью. Если вы кэшируете /users/123 и одновременно кэшируете списки «топ‑контрибьюторов», смена имени пользователя затрагивает более одного ключа. Без трекинга связей вы будете отдавать смешанную реальность.
Cache‑aside (приложение читает/пишет БД, наполняет кэш) — распространён, но инвалидация на вас.
Write‑through (пишем в кэш и БД одновременно) уменьшает риск устаревания, но добавляет задержку и сложность обработки ошибок.
Write‑back (сначала пишем в кэш, потом сбрасываем в БД) повышает скорость, но делает корректность и восстановление намного сложнее.
Stale‑while‑revalidate отдаёт немного устаревшие данные, пока фоновая перестройка обновляет значение. Это сглаживает пики и защищает origin, но это продуктовое решение: вы сознательно выбираете «быстро и в основном актуально» вместо «всегда самое свежее».
Кеширование меняет понятие «корректно». Без кэша пользователи в основном видят последнее зафиксированное значение (с учётом обычного поведения БД). С кэшами пользователи могут видеть данные, слегка отстающие, или несогласованные между экранами — иногда без явной ошибки.
Сильная согласованность стремится к «чтение‑после‑записи»: если пользователь обновил адрес доставки, следующая загрузка страницы должна показывать новый адрес повсюду. Это интуитивно, но дорого, если каждая запись должна немедленно инвалидировать или обновить множество кэшей.
Конечная (eventual) согласованность допускает кратковременную усталость: обновление появится вскоре, но не мгновенно. Пользователи это переносят для некритичного контента (счётчики просмотров), но не для денег, прав доступа или всего, что влияет на действия.
Типичная ошибка: запись происходит одновременно с репопуляцией кэша:
Теперь кэш содержит старые данные на весь TTL, хотя БД корректна.
С множественными слоями разные части системы могут расходиться во мнениях:
Пользователи воспринимают это как «система сломана», а не как «система eventual‑согласована».
Версионирование уменьшает неоднозначность:
user:123:v7) позволяют двигаться вперёд: запись увеличивает версию, и чтения естественно переключаются на новый ключ без идеально синхронных удалений.Ключевой вопрос не «плохи ли устаревшие данные?», а где они неприемлемы.
Задайте явные бюджеты устаревания для каждой фичи (секунды/минуты/часы) и согласуйте их с ожиданиями пользователей. Результаты поиска могут отставать на минуту; балансы счетов и контроль доступа — нет. Это превращает «корректность кэша» в продуктовую метрику, которую можно тестировать и мониторить.
Кеширование часто ломается так, будто «всё работало, а потом всё сразу упало». Эти отказы не означают, что кэш плох — они означают, что кэши концентрируют паттерны трафика, поэтому небольшое изменение может вызвать большой эффект.
После деплоя, масштабирования или очистки кэша вы можете получить в основном пустой кэш. Следующая волна трафика заставляет множество запросов обратиться прямо к БД или внешним API.
Это особенно больно при быстром росте трафика, потому что кэш не успел прогреться с популярными элементами. Если деплой совпадает с пиковым трафиком, вы можете непреднамеренно запустить стресс‑тест на прод.
Штампед случается, когда множество пользователей запрашивает один и тот же объект сразу после его истечения (или если он ещё не был закеширован). Вместо одной перестройки сотни или тысячи клиентов делают одно и то же — перегружая origin.
Меры:
Если требования к корректности позволяют, stale‑while‑revalidate тоже помогает сгладить пики.
Некоторые ключи становятся чрезмерно популярными (домашняя страница, трендовый товар, глобальная конфигурация). Горячие ключи создают неравномерную нагрузку: один узел кэша или один путь к origin получают шквал запросов, пока другие простаивают.
Меры: дробление больших «глобальных» ключей на более мелкие, шардирование/partitioning, или перекладка кэша ближе к пользователям (например, CDN для действительно публичного контента).
Отказы кэша могут быть хуже, чем их отсутствие, потому что приложение может зависеть от него. Решите заранее:
В любом случае rate limits и circuit breakers помогают не дать отказу кэша превратиться в отказ origin.
Кеширование может снизить нагрузку на origin, но увеличивает число сервисов, которыми вы управляете в повседневной работе. Даже «managed» кэши требуют планирования, настройки и реакции на инциденты.
Новый слой кэша — это обычно новый кластер (или хотя бы новый уровень) с собственными лимитами вместимости. Командам нужно решать размеры памяти, политику вытеснения и поведение под давлением. Если кэш недорасчитан, он будет «прыгать»: падает hit rate, растёт латентность, и origin всё равно окажется под ударом.
Кеш редко живёт в одном месте. У вас может быть CDN, кэш приложения и кэш БД — все интерпретируют правила по‑разному.
Небольшие расхождения накапливаются:
Со временем «почему этот запрос закеширован?» превращается в археологию.
Кэши добавляют рутинную работу: прогрев критичных ключей после деплоя, очистка/ревалидция при изменениях данных, ресардирование при добавлении/удалении нод и репетиции поведения после полного флаша.
Когда пользователи жалуются на устаревшие данные или внезапную медлительность, у ответственных теперь больше подозреваемых: CDN, кластер кэша, клиент кэша в приложении и origin. Отладка часто означает проверку hit rate, всплесков вытеснений и таймаутов по слоям — и решение, обходить, чистить или масштабировать.
Кэш снижает нагрузку, отвечая на повторяющиеся запросы без обращения к источнику правды (серверы приложений, БД, сторонние API). Наибольший эффект дают:
Чем раньше в пути запроса происходит попадание (браузер/CDN против приложения), тем больше работы вы экономите у бекенда.
Один кэш — это одно хранилище (например, in-memory рядом с приложением). Кэш-слой — это контрольная точка в пути запроса (кэш браузера, CDN, обратный прокси, кэш приложения, кэш базы данных).
Несколько слоёв охватывают больше путей нагрузки, но также вводят больше правил, больше режимов отказа и больше способов выдавать несогласованные данные, когда слои расходятся во мнениях.
Промахи вызывают реальную работу плюс накладные расходы самого кэширования. При промахе вы обычно платите за:
Поэтому промах может быть даже медленнее, чем отсутствие кэша, если кэш плохо сконструирован и коэффициент попаданий невысок для важнейших эндпоинтов.
TTL прост в том смысле, что не требует координации, но «правильный» TTL зависит от характера данных. Если TTL слишком велик — вы будете выдавать устаревшие данные; если слишком мал — выгода по нагрузке пропадает.
Практика: задавайте TTL по функционалу, исходя из влияния на пользователя (например, минуты для документации, секунды или запрет кэша для балансов/цен) и пересматривайте решения по реальным метрикам hit/miss и инцидентам.
Используйте event-driven инвалидацию, когда устаревание дорого обходится и вы можете надёжно связать запись с зависимыми ключами. Это работает лучше, если:
Если таких гарантий нет, предпочтительнее ограниченная усталость (TTL + повторная проверка), чем «идеальная» инвалидация, которая молча может провалиться.
Множественные слои кэша могут приводить к рассогласованию частей системы. Пример: CDN отдает старую HTML‑страницу, а кэш приложения — новую JSON, и интерфейс становится смешанным.
Чтобы снизить это:
product:v3:...), чтобы чтения плавно переходили на новую версиюШтампед (thundering herd) возникает, когда множество запросов одновременно перестраивают один и тот же ключ (обычно сразу после истечения TTL), перегружая origin.
Распространённые меры:
Решите заранее поведение при медленном или упавшем кэше:
Добавьте таймауты, circuit breakers и rate limits, чтобы отказ кэша не обрушил origin.
Сосредоточьтесь на метриках, которые объясняют результат, а не только на hit ratio:
В трассировке помечайте запросы cache.layer и , чтобы сравнивать путь попадания и путь промаха и быстро выявлять регрессии.
Частая ошибка — кэширование персонализированных или конфиденциальных ответов в общих слоях (CDN/прокси). Это может происходить из‑за широких правил кэширования.
Меры предосторожности:
Vary/заголовки соответствуют фактически меняющимся параметрам ответаcache.resultCache-Control: private или no-store для чувствительных ответовVary (например, Authorization, Accept-Language) если ответы различаютсяSet-Cookie в ответе — сильный сигнал не кэшировать публично