Настоящая проблема: утечки, задержки и несогласованные результаты
Фильтрация в интерфейсе — это не просто одно поле поиска. Обычно это набор связанных действий, которые меняют то, что видит пользователь: текстовый поиск (имя, email, номер заказа), фасеты (статус, владелец, диапазон дат, теги) и сортировка (новые, по ценности, по активности).
Ключевой вопрос не в том, какая техника «лучше». Важно, где находится полный набор данных и кто имеет к нему доступ. Если браузер получает записи, которые пользователь не должен видеть, интерфейс может раскрыть чувствительные данные, даже если вы визуально их скрываете.
Большинство дебатов про серверную и клиентскую фильтрацию на самом деле — реакция на два явных провала, которые пользователи замечают сразу:
- Утечки: данные появляются в сетевых полезных нагрузках, закешированных ответах или через неожиданные фильтры, раскрывающие скрытые строки.
- Задержки: экран кажется медленным, потому что вы отправили слишком много данных и заставляете устройство выполнять тяжёлую работу на каждом нажатии клавиши.
Есть и третья проблема, которая порождает бесконечные баг-репорты: несогласованные результаты. Если некоторые фильтры выполняются на клиенте, а другие — на сервере, пользователи видят несоответствия в подсчётах, страницах и итогах. Это быстро подрывает доверие, особенно в пагинированных списках.
Практический дефолт прост: если пользователь не должен иметь доступ к полному набору данных — фильтруйте на сервере. Если может и набор достаточно мал, чтобы быстро загрузиться, клиентская фильтрация допустима.
Короткие определения простым языком
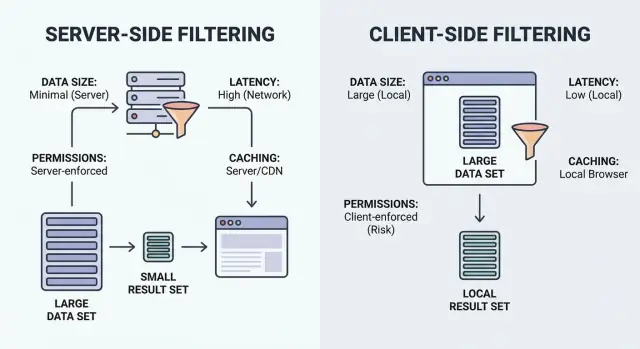
Фильтрация — это просто «покажи элементы, которые соответствуют». Вопрос в том, где происходит соответствие: в браузере пользователя (клиент) или на вашем бэкенде (сервер).
Клиентская фильтрация выполняется в браузере. Приложение скачивает набор записей (обычно JSON) и применяет фильтры локально. После загрузки это может казаться моментальным, но работает только если набор данных достаточно маленький и безопасно его раскрывать.
Серверная фильтрация выполняется на бэкенде. Браузер отправляет параметры фильтра (например status=open, owner=me, createdAfter=Jan 1), а сервер возвращает только подходящие результаты. На практике это обычно API-эндпойнт, который принимает фильтры, строит запрос к базе данных и возвращает пагинированный список плюс итоги.
Простая модель:
- Клиент: скачиваешь много — фильтруешь здесь.
- Сервер: запрашиваешь ровно то, что нужно.
Гибридные подходы распространены. Хороший паттерн — применять «тяжёлые» фильтры на сервере (права, владение, диапазон дат, поиск), а мелкие UI-переключатели делать локально (скрыть архивные, быстрые теги, видимость колонок) без дополнительного запроса.
Сортировка, пагинация и поиск обычно связаны с тем же решением: они влияют на размер полезной нагрузки, ощущение пользователя и какие данные вы раскрываете.
Фактор решения 1: размер данных и стоимость полезной нагрузки
Начните с практичного вопроса: сколько данных вы отправите в браузер, если будете фильтровать на клиенте? Если честный ответ — «больше, чем несколько экранов», вы заплатите за это временем загрузки, использованием памяти и замедленными взаимодействиями.
Вам не нужны точные оценки. Получите порядок величины: сколько строк может увидеть пользователь и какой средний размер строки. Список из 500 элементов с несколькими короткими полями сильно отличается от 50 000 элементов, где каждая запись содержит длинные заметки, rich text или вложенные объекты.
Широкие записи — тихий убийца полезной нагрузки. Таблица может казаться маленькой по числу строк, но тяжёлой, если каждая строка содержит много полей, большие строки или объединённые данные (контакт + компания + последняя активность + полный адрес + теги). Даже если вы показываете только три колонки, команды часто «шлют всё про запас», и полезная нагрузка раздувается.
Также подумайте о росте. Набор данных, который сегодня приемлем, через несколько месяцев может стать проблемой. Если данные быстро растут, рассматривайте клиентскую фильтрацию как временное упрощение, а не как дефолт.
Правила на практике:
- Если вы не можете с комфортом отправить весь набор данных по типичному мобильному соединению — фильтруйте на сервере.
- Если пользователи работают только с небольшой частью данных одновременно — запрашивайте эту часть и фильтруйте на сервере.
- Если набор данных мал, стабильный и действительно безопасен для раскрытия — клиентская фильтрация может дать отличное ощущение.
Последний пункт важен не только для производительности. Вопрос «можем ли мы отправить весь набор в браузер?» — ещё и вопрос безопасности. Если ответ не уверенное «да», не отправляйте данные.
Фактор решения 2: задержка и ощущение пользователя
Выбор фильтрации часто терпит не из-за корректности, а из-за ощущения. Пользователи не меряют миллисекунды. Они замечают паузы, мерцание и прыжки результатов во время ввода.
Время уходит в разных местах:
- Сеть: время запроса/ответа и размер полезной нагрузки
- Сервер: запросы к базе данных, join'ы, сортировка, проверки прав
- Браузер: парсинг JSON, рендер строк, фильтрация больших массивов
Определите, что значит «достаточно быстро» для этого экрана. Вид списка может требовать отзывчивого ввода и плавного скролла, а страница отчёта может терпеть небольшую задержку, если первый результат появляется быстро.
Не оценивайте только по офисному Wi‑Fi. На медленных соединениях клиентская фильтрация может казаться быстрой после первой загрузки, но сама первая загрузка может быть долгой. Серверная фильтрация держит полезную нагрузку маленькой, но может казаться медленной, если вы выполняете запрос на каждый нажатый символ.
Проектируйте под поведение человека. Дебаунсьте запросы при вводе. Для больших наборов используйте постепенную загрузку, чтобы страница показывала что-то быстро и оставалась плавной по мере прокрутки.
Фактор решения 3: права доступа и раскрытие данных
Права доступа должны решать подход к фильтрации скорее, чем скорость. Если браузер хоть раз получает данные, которые пользователь не должен видеть, вы уже в проблеме, даже если вы скрываете их за неактивной кнопкой или свернутой колонкой.
Начните с перечисления того, что чувствительно на этом экране. Некоторые поля очевидны (email, телефоны, адреса). Другие легко пропустить: внутренние заметки, стоимость или маржа, особые правила ценообразования, оценки риска, флаги модерации.
Большая ловушка — «мы фильтруем на клиенте, но показываем только разрешённые строки». Это всё равно значит, что полный набор был скачан. Любой может просмотреть сетевой ответ, открыть dev tools или сохранить полезную нагрузку. Скрытие колонок в UI — не контроль доступа.
Когда серверная фильтрация — безопасный дефолт
Серверная фильтрация безопаснее по умолчанию, когда авторизация варьируется по пользователям, особенно если разные пользователи видят разные строки или поля.
Быстрая проверка:
- Видят ли разные роли разные строки (только команда, только регион, «только мои»)?
- Видят ли разные роли разные поля (заметки, цены, PII)?
- Есть ли правила на уровне строки (владелец аккаунта, стадия сделки, флаг «приватно»)?
- Могут ли экспорт, сортировка или итоги раскрыть ограниченную информацию?
- Создёт ли утечка полезной нагрузки проблему соответствия?
Если хоть один ответ «да», держите фильтрацию и выбор полей на сервере. Отправляйте только то, что пользователь может видеть, и применяйте те же правила к поиску, сортировке, пагинации и экспорту.
Пример: в списке контактов CRM представители видят только свои аккаунты, менеджеры — всю команду. Если браузер скачивает все контакты и фильтрует локально, представитель всё равно сможет восстановить скрытые аккаунты из ответа. Серверная фильтрация предотвращает это, просто не отправляя эти строки.
Фактор решения 4: кеширование и актуальность данных
Кеширование может сделать экран мгновенным. Но оно также может показать неправильную правду. Важно решить, что можно переиспользовать, как долго и какие события должны сбрасывать кеш.
Начните с выбора единицы кеша. Кешировать весь список просто, но обычно расточительно и быстро устаревает. Кеширование страниц хорошо для бесконечной прокрутки. Кеширование результатов запросов (фильтр + сортировка + поиск) точно, но может разрастаться, если пользователи пробуют много комбинаций.
Актуальность важнее в некоторых доменах. Если данные меняются быстро (остатки на складе, балансы, статус доставки), даже 30‑секундный кеш может запутать пользователей. Если данные меняются редко (архивные записи, справочные данные), более долгий кеш обычно приемлем.
Планируйте инвалидацию заранее. Кроме простого истечения по времени, решите, что должно принудительно обновлять: создание/редактирование/удаление, смена прав, массовый импорт или слияние, переход статуса, откат/undo и фоновые джобы, которые обновляют поля, по которым фильтруют.
Также решите, где хранится кеш. Память браузера делает быструю навигацию назад/вперёд, но может протекать между аккаунтами, если вы не учитываете ключ по пользователю и организации. Бэкенд‑кеш безопаснее для прав доступа и согласованности, но должен включать полную подпись фильтра и идентичность вызывающего, чтобы результаты не смешивались.
Пошагово: как выбрать для нового экрана
Цель негибкая: экран должен казаться быстрым и не допускать утечек данных.
Практичный поток принятия решения
- Начните с самого жёсткого ограничения. Если доступ варьируется по роли, команде, региону или подписке — права побеждают. Если набор данных большой или может быстро расти — размер побеждает.
- По умолчанию используйте серверную фильтрацию, когда данные большие или чувствительные. Если вы не были бы комфортны логировать весь набор в консоли браузера, не отправляйте его.
- Клиентскую фильтрацию используйте только для небольших, безопасных, часто переиспользуемых списков. Выпадающие списки статусов, небольшие списки тегов, одна страница уже одобренных результатов.
- Определите форму API до UI. Запишите фильтры, сортировку, пагинацию и значения по умолчанию, чтобы сервер и интерфейс не расходились во взглядах.
- Добавьте страховочные ограждения. Ограничьте максимальный размер страницы, задайте тайм‑ауты и решите, как интерфейс ведёт себя при медленной фильтрации (показывать спиннер, оставлять старые результаты, предлагать повторить).
Частые ошибки, приводящие к утечкам или задержкам
Большинство команд наступает на одни и те же грабли: интерфейс отлично выглядит на демо, но реальные данные, реальные права и реальные сети выявляют трещины.
Ошибки, которые ведут к утечкам данных
Самая серьёзная ошибка — рассматривать фильтрацию как презентацию. Если браузер получил записи, которые не должен был, вы уже проиграли.
Две распространённые причины:
- Отправка полного набора данных в браузер и локальная фильтрация «ради скорости». Любой может просмотреть ответ или запросить данные из памяти.
- Кеширование отфильтрованных ответов без привязки ключа кеша к идентичности пользователя, организации, роли или версии политики. Из‑за изменения прав можно незаметно раскрыть старые данные.
Пример: стажёры должны видеть лиды только из своего региона. Если API возвращает все регионы, а фильтр в React прячет лишние, стажёр всё равно может получить полный список.
Ошибки, которые делают экран медленным
Задержки часто возникают из неверных предположений:
- Предположение, что клиентская фильтрация всегда быстрее. При 50 000 строк загрузка и парсинг могут занять больше времени, чем точечный запрос.
- Забвение о пагинации и состояниях загрузки. Экран, который блокируется при рендере огромного списка, кажется сломанным даже при корректном запросе.
Тонкая, но болезненная проблема — несовпадение правил. Если сервер и UI по‑разному понимают «начинается с» или регистр, пользователи увидят несоответствия в подсчётах или элементы, которые исчезают после обновления.
Быстрый чек‑лист перед релизом
Пройдитесь по финальной проверке с двумя настройками мышления: любопытный пользователь и плохой сетевой день.
- Адекватность полезной нагрузки: убедитесь, что ответы никогда не содержат строк или полей, которые пользователь не должен видеть, даже если интерфейс их скрывает. Следите за итогами, группировками или ID, которые позволяют выводить ограниченные данные.
- Безопасный лог: фильтры часто содержат email, имена или ID. Не логируйте чувствительные значения фильтров, полный SQL или полные тела запросов в местах, где доступ много у кого.
- Согласованность между устройствами: применяйте одинаковые фильтры на десктопе и мобайле. Различия часто появляются из‑за клиентской сортировки, правил локали (регистр, акценты) или значений по умолчанию.
- Чёткие состояния: состояния загрузки, пустоты и ошибок должны быть очевидны. Тестируйте быстрые изменения (ввод, backspace, переключатели), чтобы UI не мерцал и не показывал устаревшие результаты.
- Страховочные правила: максимальный размер страницы, максимальный диапазон дат и тайм‑ауты. Защитите систему от дорогих запросов (wildcard'ы, слишком много OR, нефильтрованные поля без индексов).
Простой тест: создайте ограниченную запись и подтвердите, что она никогда не появляется в полезной нагрузке, итогах или кеше, даже при широком или очищенном фильтре.
Пример: список контактов CRM
Представьте CRM с 200 000 контактами. Менеджеры продаж видят только свои аккаунты, руководители видят всю команду, админы — всё. Экран содержит поиск, фильтры (статус, владелец, последняя активность) и сортировку.
Клиентская фильтрация быстро терпит неудачу. Полезная нагрузка тяжёлая, первая загрузка медленная, а риск утечки данных велик. Даже если интерфейс прячет строки, браузер всё равно получил данные. Вы также нагружаете устройство: большие массивы, тяжёлая сортировка, многократные фильтрации, высокий расход памяти и падения на старых телефонах.
Более безопасный подход — серверная фильтрация с пагинацией. Клиент отправляет выбор фильтров и текст поиска, сервер возвращает только строки, которые пользователь может видеть, уже отфильтрованные и отсортированные.
Практический паттерн:
- Применяйте права сначала, затем фильтры и сортировку.
- Возвращайте по странице (например, 50 строк) плюс общий счёт.
- Кешируйте аккуратно (по пользователю или роли), чтобы не смешивать результаты между правами доступа.
Небольшое исключение, где клиентская фильтрация приемлема: крошечные статичные данные. Выпадающий список «Статус контакта» с 8 значениями можно загрузить раз и фильтровать локально без риска или затрат.
Следующие шаги: документируйте решения и сокращайте переработки
Команды обычно не проваливаются из‑за единственного «неправильного» выбора. Они проваливаются, когда принимают разные решения на каждом экране и потом пытаются исправлять утечки и медленные страницы в условиях стресса.
Напишите короткую заметку по каждому экрану с фильтрами: размер набора, стоимость отправки, что значит «достаточно быстро», какие поля чувствительны и как результаты кешируются (или не кешируются). Держите сервер и UI согласованными, чтобы не было «двух истин» фильтрации.
Если вы быстро собираете экраны в Koder.ai (koder.ai), стоит заранее решить, какие фильтры обязательно должны применяться на бэкенде (права и доступ на уровне строки), а какие мелкие UI‑переключатели можно оставить в React. Это одно решение предотвращает большинство дорогостоящих переработок позже.