16 янв. 2026 г.·7 мин
Документно-ориентированные рабочие процессы: модель данных и шаблоны интерфейса
Документно-ориентированные рабочие процессы: практические модели данных и шаблоны UI для версий, превью, метаданных и ясных состояний статуса.
Документно-ориентированные рабочие процессы: практические модели данных и шаблоны UI для версий, превью, метаданных и ясных состояний статуса.
Приложение считается документно-ориентированным, когда сам документ — это продукт, который пользователи создают, просматривают и на который полагаются. Опыт строится вокруг файлов — PDF, изображений, сканов и квитанций — а не вокруг формы, где файл просто приложен.
В таких рабочих процессах люди выполняют реальную работу внутри документа: открывают его, проверяют изменения, добавляют контекст и решают, что делать дальше. Если документам нельзя доверять, приложение перестаёт быть полезным.
Большинству документно-ориентированных приложений нужны несколько ключевых экранов на старте:
Проблемы проявляются быстро. Пользователь загружает одну и ту же квитанцию дважды. Кто-то редактирует PDF и перезагружает его без объяснения. В скане нет даты, поставщика и владельца. Через недели никто не понимает, какая версия была утверждена и на чём основывалось решение.
Хорошее документно-ориентированное приложение должно казаться быстрым и надёжным. Пользователь должен уметь ответить на эти вопросы за секунды:
Эта очевидность приходит из определений. Прежде чем строить экраны, решите, что в вашем приложении означает «версия», «предпросмотр», «метаданные» и «статус». Если эти термины размыты, вы получите дубликаты, запутанную историю и потоки проверки, не соответствующие реальной работе.
Интерфейс часто выглядит просто (список, просмотр, несколько кнопок), но груз держит модель данных. Если базовые объекты определены правильно, аудит, быстрые превью и надёжные утверждения становятся значительно проще.
Начните с разделения «запись документа» и «содержимого файла». Запись — это то, о чём говорят пользователи (счёт от ACME, такси-квитанция). Содержимое — это байты (PDF, JPG), которые можно заменить, переработать или переместить, не меняя смысла документа внутри приложения.
Практический набор объектов для моделирования:
Решите, что получает неизменяемый ID. Полезное правило: Document ID живёт вечно, в то время как Files и Previews можно регенерировать. Версии тоже должны иметь стабильные ID, потому что люди ссылаются на «как это выглядело вчера», и вам нужен след аудита.
Моделируйте связи явно. У Document много Versions. У каждой Version может быть несколько Previews (разные размеры или форматы). Это держит списковые экраны быстрыми, потому что они загружают лёгкие данные превью, а детальные экраны подгружают сам файл только по необходимости.
Пример: пользователь загружает помятую фотографию квитанции. Вы создаёте Document, сохраняете оригинальный File, генерируете миниатюру Preview и создаёте Version 1. Позже пользователь загружает более чёткий скан. Это становится Version 2, не нарушая комментарии, утверждения и поиск, привязанные к Document.
Люди ожидают, что документ со временем будет меняться, не превращаясь в другой объект. Самый простой способ этого добиться — отделить идентичность (Document) от содержимого (Version и Files).
Начните со стабильного document_id, который никогда не меняется. Даже если пользователь перезагружает тот же PDF, заменяет размытое фото или загружает исправленный скан, это должна быть та же запись документа. Комментарии, назначения и журналы аудита аккуратно привязываются к одному устойчивому ID.
Рассматривайте каждое значимое изменение как новую запись version. Каждая версия должна фиксировать, кто её создал и когда, а также указатели на хранение (ключ файла, контрольная сумма, размер, число страниц) и производные артефакты (OCR-текст, изображения предпросмотра), привязанные к этому конкретному файлу. Избегайте «правок на месте». Сначала это кажется проще, но ломает трассируемость и делает баги труднее исправимыми.
Для быстрых чтений держите current_version_id в документе. Большинству экранов нужна «последняя» версия, чтобы не сортировать версии при каждой загрузке. Когда нужна история, загружайте версии отдельно и показывайте чистую шкалу времени.
Откаты — это просто смена указателя. Вместо удаления чего-либо установите current_version_id на более старую версию. Это быстро, безопасно и сохраняет след аудита.
Чтобы история была понятной, записывайте, зачем каждая версия существует. Небольшое единообразное поле reason (с опциональной заметкой) предотвращает таймлайн, полный загадочных обновлений. Обычные причины: замена при перезагрузке, очистка скана, коррекция OCR, редактирование для удаления данных и правка после утверждения.
Пример: команда финансов загружает фото квитанции, заменяет его более чётким сканом, затем правит OCR, чтобы сумма читалась. Каждый шаг — новая версия, но документ остаётся одним элементом в входящих. Если исправление OCR было ошибочным, откат — один клик, потому что вы меняете только current_version_id.
В документно-ориентированных рабочих процессах превью часто — главный объект взаимодействия. Если превью медленное или ненадёжное, всё приложение кажется сломанным.
Рассматривайте генерацию превью как отдельную задачу, а не что-то, ради чего ждёт экран загрузки. Сначала сохраните оригинал, верните управление пользователю, а затем генерируйте превью в фоне. Это держит UI отзывчивым и делает повторные попытки безопасными.
Храните несколько размеров превью. Один размер не подходит для всех экранов: крошечная миниатюра для списков, среднее изображение для разделённого вида и полноразмерная страница для детального просмотра (по-странично для PDF).
Отслеживайте состояние превью явно, чтобы UI всегда знал, что показать: pending, ready, failed и needs_retry. Держите метки удобными для пользователя в интерфейсе, но сохраняйте состояния ясными в данных.
Для быстрого рендеринга кэшируйте производные значения вместе с записью превью вместо перерасчёта при каждом просмотре. Частые поля: количество страниц, ширина и высота превью, поворот (0/90/180/270) и опционально «лучшая страница для миниатюры».
Проектируйте систему для медленных и проблемных файлов. 200-страничный скан или смятый снимок квитанции могут обрабатываться долго. Используйте прогрессивную загрузку: показывайте первую готовую страницу сразу, затем подгружайте остальные.
Пример: пользователь загружает 30 фотографий квитанций. В списке видно миниатюры со статусом «pending», затем каждая карточка переключается на «ready» по мере завершения обработки. Если несколько файлов упали из-за повреждения, они остаются видимыми с ясным действием «повторить», вместо того чтобы исчезнуть или заблокировать всю партию.
Метаданные превращают груду файлов в то, что можно искать, сортировать, проверять и утверждать. Они помогают людям быстро ответить на простые вопросы: Что это за документ? От кого он? Валиден ли он? Что с ним дальше делать?
Практичный способ держать метаданные в порядке — разделить их по источнику:
Такие корзины предотвращают будущие споры. Если сумма неверна, видно, пришла ли она из OCR или её ввёл человек.
Для квитанций и счетов небольшой набор полей окупается, если вы используете их последовательно (те же названия, те же форматы). Частые якорные поля: vendor, date, total, currency, document_number. Сначала делайте их необязательными. Люди загружают частичные сканы и размытые фото, и блокировка процесса из‑за одного отсутствующего поля тормозит рабочий процесс.
Обращайтесь с неизвестными значениями как с полноценными: используйте явные состояния null/unknown и при необходимости указывайте причину (страница отсутствует, нечитабельно, не применимо). Это позволяет документу двигаться дальше, показывая рецензентам, что требует внимания.
Также сохраняйте происхождение и уверенность для извлечённых полей. Источник может быть user, OCR, import или API. Уровень доверия — число от 0 до 1 или набор high/medium/low. Если OCR прочитал «$18.70» с низкой уверенностью из‑за размытого последнего символа, UI может подсветить это поле и попросить быстро подтвердить.
Многостраничные документы требуют дополнительного решения: что относится ко всему документу, а что — к отдельной странице. Суммы и мерчанты обычно принадлежат документу. Заметки уровня страницы, редактирование для удаления данных, поворот и классификация по странице — часто хранятся на уровне страницы.
Статус отвечает на вопрос: «Где сейчас этот документ в процессе?» Держите набор статусов небольшим и тривиальным. Если вы добавляете новый статус при каждом запросе, в итоге получите фильтры, которым никто не доверяет.
Практичный набор бизнес-состояний, соответствующих реальным решениям:
Держите «processing» вне бизнес-статусов. OCR и генерация превью описывают, что делает система, а не то, что должен сделать человек дальше. Храните их как отдельные состояния обработки.
Также разделяйте назначение от статуса (assignee_id, team_id, due_date). Документ может быть Approved, но всё ещё назначен для последующих задач, или Needs review без назначенного ответственного.
Записывайте историю статусов, а не только текущее значение. Простой лог (from_status, to_status, changed_at, changed_by, reason) окупается, когда спрашивают: «Кто отклонил эту квитанцию и почему?»
Наконец, определите, какие действия разрешены в каждом статусе. Держите правила простыми: Imported → Needs review; Approved — только для чтения, если не создана новая версия; Rejected можно открыть повторно, но предыдущая причина должна сохраняться.
Большая часть времени уходит на просмотр списка, открытие одного элемента, исправление пары полей и переход дальше. Хороший UI делает эти шаги быстрыми и предсказуемыми.
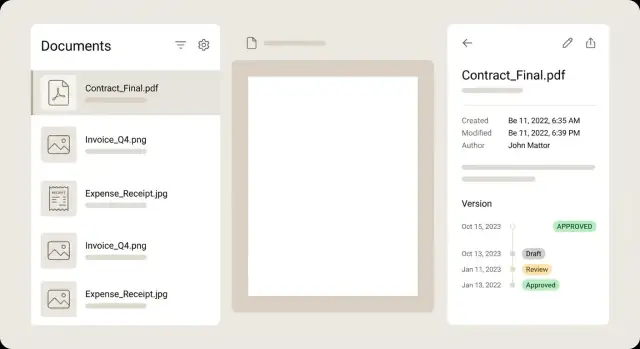
Для списка документов обрабатывайте каждую строку как резюме, чтобы пользователь мог принять решение, не открывая каждый файл. Сильная строка показывает маленькую миниатюру, понятный заголовок, несколько ключевых полей (мерчант, дата, сумма), бейдж статуса и тонкое предупреждение, если что-то требует внимания.
Детальный просмотр держите спокойным и удобочитаемым. Обычная схема — предпросмотр слева и метаданные справа, с контролами редактирования рядом с каждым полем. Пользователь должен масштабировать, вращать и перелистывать страницы, не теряя место в форме. Если поле извлечено OCR, показывайте подсказку с уровнем уверенности и, по возможности, подсвечивайте область на превью при фокусе на поле.
Версии лучше показывать в виде таймлайна, а не выпадающего списка. Показывайте, кто что и когда изменил, и давайте открыть любую прошлую версию в режиме только для чтения. Если предлагаете сравнение — фокусируйтесь на различиях в метаданных (сумма изменилась, мерчант исправлен), а не на пиксельном сравнении PDF.
Режим проверки должен быть оптимизирован для скорости. Часто достаточно клавиатурного потока триажа: быстрые действия утвердить/отклонить, быстрые правки для распространённых полей и короткое поле для комментария при отклонении.
Пустые состояния важны, потому что документы часто в процессе обработки. Вместо пустого окна объясните, что происходит: «Генерируется превью», «Запущен OCR» или «Для этого типа файла предпросмотра нет».
Простой поток ощущается как «загрузил — проверил — утвердил». Под капотом он работает лучше, когда вы разделяете файл как такой (версии и превью) и бизнес‑смысл (метаданные и статус).
Пользователь загружает PDF, фото или скан квитанции и сразу видит его в списке входящих. Не ждите завершения обработки. Покажите имя файла, время загрузки и ясный бейдж вроде «Processing». Если источник известен (импорт по почте, мобильная камера, drag-and-drop), тоже показывайте это.
При загрузке создайте запись Document (долговечную сущность) и запись Version (этот конкретный файл). Установите current_version_id в новую версию. Сохраните preview_state = pending и extraction_state = pending, чтобы UI честно показывал, что готово.
Детальный просмотр должен открываться сразу, но показывать плейсхолдер и явное сообщение «Подготавливается превью», а не битый фрейм.
Фоновая задача создаёт миниатюры и просматриваемое представление (изображения страниц для PDF, изменённые по размеру фото для картинок). Другая задача извлекает метаданные (мерчант, дата, сумма, валюта, тип документа). Когда каждая задача завершаются, обновляйте только её состояние и метки времени, чтобы можно было повторить неудачные попытки без касания всего остального.
Держите UI компактным: показывайте состояние превью, состояние данных и подчёркивайте поля с низкой уверенностью.
Когда превью готово, рецензенты исправляют поля, добавляют заметки и переводят документ по бизнес-статусам: Imported → Needs review → Approved (или Rejected). Логируйте, кто и что изменил и когда.
Если рецензент загружает исправленный файл, он становится новой Version, и документ автоматически возвращается в Needs review.
Экспорт, синхронизация с бухгалтерией или внутренние отчёты должны читать current_version_id и снимок утверждённых метаданных, а не «последнее извлечение». Это предотвращает ситуацию, когда полуобработанная перезагрузка меняет числа.
Документно-ориентированные рабочие процессы рушатся по скучным причинам: ранние упрощения превращаются в ежедневные боли, когда люди загружают дубликаты, исправляют ошибки или спрашивают: «Кто и когда это изменил?»
Классическая ошибка — считать имя файла идентичностью документа. Имёна меняются, пользователи перезагружают, камеры генерируют дубликаты вроде IMG_0001. Дайте каждому документу стабильный ID, а имя файла используйте как метку.
Перезапись оригинального файла при загрузке замены тоже создаёт проблемы. Кажется проще, но вы теряете след аудита и не сможете ответить на базовые вопросы позже (что было утверждено, что редактировали, что отправляли). Держите бинарный файл неизменяемым и добавляйте новую запись версии.
Путаница со статусами вызывает тонкие ошибки. «Запущен OCR» — не то же самое, что «Нужна проверка». Состояния обработки описывают, что делает система; бизнес-статус описывает, что должен сделать человек. Если их смешать, документы окажутся в неправильных корзинах.
Решения UI тоже могут создавать трения. Если вы блокируете экран до генерации превью, пользователи будут ощущать работу приложения как медленную, даже если загрузка прошла успешно. Покажите документ сразу с плейсхолдером, затем подменяйте миниатюру по готовности.
Наконец, метаданные становятся недоверительными, если хранить значения без происхождения. Если сумма пришла из OCR, укажите это. Храните метки времени.
Короткий чеклист:
Пример: в приложении для квитанций пользователь перезагружает более чёткое фото. Если вы сделали версионирование, сохраните старое изображение, пометьте OCR как в процессе повторной обработки и оставьте статус Needs review, пока человек не подтвердит сумму.
Документно-ориентированные рабочие процессы кажутся «готовыми» только тогда, когда людям можно доверять то, что они видят, и когда восстановление после ошибок встроено. Перед запуском тестируйте на реальных, грязных документах (размытые квитанции, повернутые PDF, повторные загрузки).
Пять проверок, которые ловят большинство сюрпризов:
Быстрый тест: попросите кого‑то проверить три похожие квитанции и намеренно сделать одну неправильную правку. Если они смогут найти текущую версию, понять статус и исправить ошибку меньше чем за минуту — вы близки к хорошему решению.
Ежемесячные возмещения квитанций — очевидный пример документно-ориентированной работы. Сотрудник загружает квитанции, затем два рецензента проверяют их: менеджер, потом бухгалтерия. Квитанция — это продукт, поэтому ваше приложение живёт или умирает благодаря версионированию, превью, метаданным и ясным статусам.
Джейми загружает фото такси. Система создаёт Document #1842 с Version v1 (оригинал), миниатюрой и превью, а также метаданными: merchant, date, currency, total и скором уверенности OCR. Документ стартует в Imported, затем переходит в Needs review, когда превью и извлечение готовы.
Позже Джейми случайно загружает ту же квитанцию снова. Проверка на дубликат (хеш файла плюс похожие merchant/date/total) может предложить выбор: «Похоже на дубликат #1842. Привязать или отбросить?» Если привязывают, сохраните её как ещё один File, связанный с тем же Document, чтобы не дробить поток проверки и статусы.
Во время проверки менеджер видит превью, ключевые поля и предупреждения. OCR угадал сумму как $18.00, но на картинке видно $13.00. Джейми исправляет сумму. Не перезаписывайте историю. Создайте Version v2 с обновлёнными файлами, держите v1 нетронутой и залогируйте «Сумма исправлена Джейми».
Если вы хотите быстро собрать такой рабочий процесс, Koder.ai (koder.ai) может помочь сгенерировать первый вариант приложения по чат-плану, но всё та же идея остаётся: сначала определите объекты и состояния, а затем позвольте экранам следовать за ними.
Практические следующие шаги:
Документно-ориентированное приложение рассматривает сам документ как главный объект работы пользователей, а не как дополнительный вложенный файл. Людям нужно открывать документ, доверять увиденному, понимать, что изменилось, и принимать решения, опираясь на этот документ.
Начните с входящей/списка, детального просмотра документа с быстрым предпросмотром, простой области для действий проверки (утвердить/отклонить/запросить изменения) и возможности экспорта или передачи. Эти четыре экрана покрывают цикл «найти — открыть — решить — передать».
Разделите стабильную запись — Document — которая никогда не меняет идентичность, и реальные байты файла — File. Добавьте Version как снимок, связывающий документ с конкретным файлом и его производными. Такая структура сохраняет комментарии, назначения и историю, даже если файл заменяют.
Каждое заметное изменение делайте новой версией, а не правьте файл на месте. Держите current_version_id в Document для быстрых обращений к «последней» версии и сохраняйте хронологию старых версий для аудита и отката. Это предотвращает путаницу с тем, что было утверждено и почему.
Генерируйте превью асинхронно после сохранения оригинала, чтобы загрузки казались мгновенными и повторы были безопасными. Отслеживайте состояние превью — pending/ready/failed — чтобы UI мог честно показывать прогресс, и храните несколько размеров, чтобы список оставался лёгким, а детальный просмотр — качественным.
Храните метаданные в трёх категориях: системные (имя файла, размер, тип), извлечённые (OCR-поля и доверие) и введённые пользователем (правки, теги, заметки). Фиксируйте происхождение каждого значения, чтобы было понятно, откуда взялась та или иная цифра, и не заставляйте завершать процесс, если какое-то поле отсутствует.
Используйте небольшой набор бизнес-статусов, отражающих, что должен сделать человек: Imported, Needs review, Approved, Rejected, Archived. Состояния обработки (OCR, генерация превью) храните отдельно, чтобы документы не зависали в «неправильном» статусе, который смешивает машинную и человеческую работу.
Сохраняйте неизменяемые контрольные суммы файлов и сравнивайте их при загрузке; затем при наличии ключевых полей (мерчант/дата/сумма) используйте дополнительную проверку похожести. Если система подозревает дубликат, предложите пользователю привязать загрузку к существующему документу или отменить её — так история отзывов останется в одном потоке.
Ведите журнал истории статусов с полями who/when/why, храните версии в таймлайне и делайте откат простым — изменение указателя на старую версию. Не удаляйте старые файлы: так вы быстро восстановите состояние без потери аудита.
Сначала определите объекты и состояния, потом пусть UI следует за ними. Если вы используете Koder.ai для генерации приложения по чат-плану, будьте точны в описании Document/Version/File, состояний превью и правил статусов, чтобы сгенерированные экраны соответствовали реальной рабочей логике.