Dlaczego zmiany schematu powodują przestoje
Przestoje spowodowane zmianą bazy danych nie zawsze są widocznym, oczywistym outage'em. Dla użytkowników może to wyglądać jak strona, która ładuje się bez końca, płatność, która się nie powiedzie, albo aplikacja nagle pokazująca „coś poszło nie tak”. Dla zespołów objawia się to alertami, rosnącym wskaźnikiem błędów i zaległością nieudanych zapisów do posprzątania.
Zmiany schematu są ryzykowne, bo baza danych jest współdzielona przez wszystkie uruchomione wersje aplikacji. Podczas wydania często mamy równocześnie stare i nowe wersje kodu (rolling deployy, wiele instancji, zadania w tle). Migracja, która wygląda poprawnie, może mimo to złamać jedną z tych wersji.
Typowe tryby awaryjne to:
- Nowy kod zapisuje do kolumny, która jeszcze nie istnieje, co powoduje natychmiastowe błędy.
- Stary kod czyta kolumnę lub tabelę, którą migracja przemianowała lub usunęła, powodując awarie po deployu.
- Backfill lub budowa indeksu skacze użyciem CPU albo blokuje wiersze, spowalniając normalne żądania lub powodując timeouty.
- „Szybka” zmiana ograniczenia (np. NOT NULL) blokuje zapisy podczas sprawdzania tabeli.
Nawet gdy kod jest w porządku, wydania są blokowane, bo prawdziwy problem to timing i zgodność między wersjami. Zmiany schematu bez przestojów sprowadzają się do jednej zasady: każdy stan pośredni musi być bezpieczny dla starego i nowego kodu. Zmieniasz bazę bez łamania odczytów i zapisów, wdrażasz kod, który obsłuży obie struktury, i usuwasz starą ścieżkę dopiero, gdy nic już od niej nie zależy.
Dodatkowy wysiłek opłaca się przy realnym ruchu, ścisłych SLA lub wielu instancjach i workerach. Dla małego narzędzia wewnętrznego z cichą bazą proste okno konserwacyjne może być łatwiejsze.
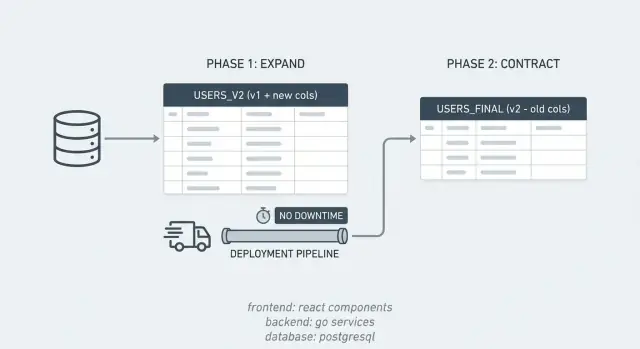
Wzorzec rozszerzanie/zwężanie w prostych słowach
Większość incydentów związanych z pracami na bazie wynika z oczekiwania, że zmiana w bazie nastąpi natychmiast, podczas gdy zmiana ta zajmuje czas. Wzorzec rozszerzanie/zwężanie rozbija ryzykowną operację na mniejsze, bezpieczne kroki.
Przez krótki czas system obsługuje dwie „dialekty” jednocześnie. Najpierw wprowadzasz nową strukturę, utrzymujesz działanie starej, stopniowo przenosisz dane, a potem sprzątasz.
Wzorzec jest prosty:
- Expand (rozszerzanie): dodaj to, czego potrzebujesz (kolumny, tabele, indeksy) bez łamania obecnej aplikacji.
- Run both paths (działaj dwutorowo): wdroż kod, który działa ze starą i nową strukturą, tak aby mieszane wersje zachowywały się poprawnie.
- Contract (zwężanie): gdy wszystko używa nowej struktury, usuń starą część schematu i stary kod.
To dobrze współgra z rolling deployami. Jeśli aktualizujesz 10 serwerów po kolei, przez chwilę będziesz mieć stare i nowe wersje razem. Wzorzec expand/contract pozwala obu pracować z tą samą bazą w tym okresie.
Ułatwia też rollbacky. Jeśli nowe wydanie ma błąd, możesz cofnąć aplikację bez cofania bazy, bo stare struktury istnieją przez okno expand.
Przykład: chcesz rozdzielić kolumnę PostgreSQL full_name na first_name i last_name. Dodajesz nowe kolumny (expand), wysyłasz kod, który potrafi zapisywać i czytać obie wersje, backfillujesz stare wiersze, a potem usuwasz full_name gdy upewnisz się, że nikt już go nie używa (contract).
Co zwykle obejmuje „expand”
Faza expand polega na dodaniu nowych opcji, a nie usuwaniu starych.
Częstym pierwszym krokiem jest dodanie nowej kolumny. W PostgreSQL zwykle najbezpieczniej dodać ją jako nullable i bez domyślnej wartości. Dodanie kolumny NOT NULL z domyślną może wywołać przepisanie tabeli lub cięższe blokady, w zależności od wersji Postgresa i dokładnej zmiany. Bezpieczniejsza sekwencja to: dodać nullable, wdrożyć tolerancyjny kod, backfillować, a dopiero później wymusić NOT NULL.
Indeksy też wymagają uwagi. Tworzenie zwykłego indeksu może blokować zapisy dłużej niż oczekujesz. Tam, gdzie to możliwe, twórz indeksy równolegle (concurrent), żeby odczyty i zapisy działały dalej. Trwa to dłużej, ale unika blokady zatrzymującej wydanie.
Expand może też oznaczać dodanie nowych tabel. Jeśli przechodzisz od pojedynczej kolumny do relacji wiele-do-wielu, możesz dodać tabelę łączącą, zostawiając starą kolumnę. Stara ścieżka nadal działa, podczas gdy nowa zaczyna zbierać dane.
W praktyce expand często obejmuje:
- Dodanie nowych nullable kolumn lub nowych tabel obok istniejących
- Dodawanie indeksów w sposób nieblokujący, gdy to możliwe
- Używanie feature flagów do kontrolowania, kiedy nowe odczyty/zapisy włączają się
- Zapisywanie do obu pól (dual-write) gdy potrzeba
- Zachowanie kompatybilnych odczytów (stare, nowe lub fallback)
Po expand stare i nowe wersje aplikacji powinny móc działać jednocześnie bez niespodzianek.
Wdrażanie kodu, który pozostaje kompatybilny
Większość problemów z wydaniem pojawia się w środku: niektóre serwery mają nowy kod, inne nadal stary kod, podczas gdy baza już się zmienia. Cel jest prosty: każda wersja w rollout powinna działać zarówno ze starym, jak i z rozbudowanym schematem.
Częstym podejściem jest dual-write. Jeżeli dodajesz nową kolumnę, nowa aplikacja zapisuje do obu — starej i nowej kolumny. Stare wersje nadal robią zapisy tylko do starego pola, co jest w porządku, bo ono nadal istnieje. Nową kolumnę trzymaj opcjonalną na początku i odłóż restrykcje na później, aż wszyscy writerzy się zaktualizują.
Odczyty zwykle przełączają się ostrożniej niż zapisy. Przez pewien czas trzymaj odczyty na starym polu (tym, które wiesz, że jest w pełni wypełnione). Po backfillu i weryfikacji przełącz odczyty tak, by preferowały nowe pole, z fallbackiem do starego, jeśli nowe jest puste.
Utrzymuj też stabilny kształt API podczas zmian w bazie. Nawet jeśli wprowadzasz nowe wewnętrzne pole, unikaj zmiany kształtu odpowiedzi, dopóki wszyscy konsumenci (web, mobile, integracje) nie będą gotowi.
Przy rolloutach przyjaznych rollbackowi zwykle stosuje się sekwencję:
- Wydanie 1: dodaj nową kolumnę i wyślij kod, który potrafi czytać stare dane i zapisywać do obu kolumn.
- Wydanie 2: backfilluj istniejące wiersze, potem wyślij kod, który preferuje nowe pole, ale potrafi odwołać się do starego.
- Wydanie 3: przestań zapisywać do starego pola (ale zostaw je w bazie).
- Wydanie 4: usuń stare odczyty, potem usuń starą kolumnę.
Kluczową ideą jest to, że pierwszy nieodwracalny krok to usunięcie starej struktury, więc odkładasz go na koniec.
Backfill danych bez obciążania DB
Zdobywaj kredyty za treści
Podziel się procesem budowy w Koder.ai i zdobądź kredyty na przyszły rozwój.
Backfill to miejsce, gdzie wiele „zmian schematu bez przestojów” się sypie. Chcesz wypełnić nową kolumnę dla istniejących wierszy bez długich blokad, wolnych zapytań czy niespodziewanych skoków obciążenia.
Batchowanie ma znaczenie. Celuj w batchy, które kończą się szybko (sekundy, nie minuty). Jeśli każdy batch jest mały, możesz wstrzymać, wznowić i dostroić pracę bez blokowania wydań.
Do śledzenia postępu używaj stabilnego kursora. W PostgreSQL często jest to klucz główny. Przetwarzaj wiersze po kolei i zapisuj ostatnie id, które ukończyłeś, albo pracuj w zakresach id. Unika to kosztownych skanów całej tabeli przy restarcie joba.
Oto prosty wzorzec:
UPDATE my_table
SET new_col = ...
WHERE new_col IS NULL
AND id > $last_id
ORDER BY id
LIMIT 1000;
Zrób update warunkowy (np. WHERE new_col IS NULL), żeby zadanie było idempotentne. Ponowne uruchomienia dotykają tylko wierszy, które nadal wymagają pracy, co redukuje niepotrzebne zapisy.
Planuj też napływ nowych danych podczas backfillu. Zwykła kolejność to:
- Najpierw zaktualizuj kod aplikacji, żeby nowe zapisy też uzupełniały nowe pole.
- Backfilluj historyczne wiersze w batchach.
- Uruchom krótką pętlę dogrywającą, która ponownie sprawdza ostatnie wiersze.
- W razie potrzeby dodaj zabezpieczenie (np. trigger lub domyślną wartość), żeby zapobiec nowym NULL-om.
Dobry backfill jest nudny: równomierny, mierzalny i łatwy do zatrzymania, jeśli baza zaczyna pracować zbyt ciężko.
Weryfikacja, że migracja naprawdę się zakończyła
Najbardziej ryzykowny moment to nie dodanie nowej kolumny, a decyzja, że możesz już na niej polegać.
Zanim przystąpisz do contract, udowodnij dwie rzeczy: nowe dane są kompletne i produkcja czyta je bezpiecznie.
Zacznij od szybkich, powtarzalnych kontroli kompletności:
- Potwierdź, że w nowej kolumnie nie ma nieoczekiwanych NULL-i.
- Porównaj, ile wierszy kwalifikuje się do uzupełnienia vs ile zostało wypełnionych.
- Przejrzyj ręcznie kilka identyfikatorów i porównaj stare i nowe wartości.
- Przetestuj przypadki brzegowe (puste stringi, zero, bardzo stare rekordy).
- Powtórz te same kontrole później, żeby upewnić się, że nic nie dryfuje.
Jeśli stosujesz dual-write, dodaj kontrolę spójności, żeby wyłapać ciche błędy. Na przykład uruchamiaj zapytanie co godzinę, które znajduje wiersze, gdzie old_value <> new_value i alarmuj, jeśli liczba jest różna od zera. To często najszybszy sposób, by odkryć, że jakiś writer dalej aktualizuje tylko stare pole.
Obserwuj podstawowe sygnały produkcyjne podczas migracji. Jeśli czas zapytań lub oczekiwania na blokady rośnie, nawet twoje „bezpieczne” zapytania weryfikujące mogą dokładać obciążenia. Monitoruj wskaźniki błędów dla ścieżek kodu czytających nowe pole, zwłaszcza tuż po deployach.
Jak długo trzymaj obie ścieżki? Długo wystarczająco, by przetrwać co najmniej jeden pełny cykl wydania i jedno ponowne uruchomienie backfillu. Wiele zespołów używa 1–2 tygodni lub dopóki nie są pewni, że żadna stara wersja aplikacji nie działa.
Faza contract: usuwanie starej ścieżki
Contract to moment, który wywołuje nerwowość, bo wydaje się punktem bez powrotu. Jeśli expand został wykonany poprawnie, contract to w większości sprzątanie i nadal można go wykonać małymi, niskiego ryzyka krokami.
Wybierz moment ostrożnie. Nie usuwaj niczego tuż po zakończeniu backfillu. Odczekaj przynajmniej jeden pełny cykl wydania, żeby zadania opóźnione i przypadki brzegowe miały czas się wykazać.
Bezpieczna sekwencja contract wygląda zwykle tak:
- Przestań robić dual-write i potwierdź, że nowe zapisy lądują tylko w nowych kolumnach.
- Usuń stare odczyty w aplikacji, tak by fallback zniknął.
- Usuń nieużywane ścieżki kodu, flagi funkcji i zadania tła odnoszące się do starego schematu.
- Usuń tymczasowe triggery, zadania synchronizujące lub widoki kompatybilności.
- Usuń stare indeksy i ograniczenia, a potem starą kolumnę.
Jeśli możesz, rozbij contract na dwa wydania: jedno usuwa referencje w kodzie (z dodatkowym logowaniem), a późniejsze usuwa obiekty bazy. To rozdzielenie ułatwia rollback i debugowanie.
Szczegóły PostgreSQL są tu istotne. Usunięcie kolumny to zwykle zmiana metadanych, ale wciąż wymaga krótkiej blokady ACCESS EXCLUSIVE. Zaplanuj spokojny moment i trzymaj migrację krótką. Jeśli stworzyłeś dodatkowe indeksy, preferuj DROP INDEX CONCURRENTLY, żeby nie blokować zapisów (nie można tego wykonać wewnątrz transakcji, więc narzędzia migracyjne muszą to wspierać).
Typowe błędy i pułapki
Ćwicz przyjazne rollouty
Wdróż kolejne wydanie z jasną fazą expand i prostą ścieżką rollback.
Migracje bez przestojów zawodzą, gdy baza i aplikacja przestają się zgadzać co do dozwolonych operacji. Wzorzec działa tylko wtedy, gdy każdy stan pośredni jest bezpieczny dla starego i nowego kodu.
Pułapki, które łamią produkcję
Te błędy występują często:
- Dodanie NOT NULL za wcześnie, gdy starsza wersja aplikacji może nadal zapisywać wiersze bez nowego pola.
- Backfill całej dużej tabeli w jednej transakcji, co może trzymać blokady, powodować bloat i timeouty.
- Zakładanie, że domyślna wartość jest „za darmo”. W PostgreSQL niektóre defaulty wywołują przepisanie tabeli.
- Przełączenie odczytów na nowe pole zanim zapisy niezawodnie je uzupełniają.
- Zapominanie o innych writerach i readerach (cron, workery, eksporty, zapytania raportowe).
Realistyczny scenariusz: zaczynasz zapisywać full_name z API, ale zadanie w tle tworzące użytkowników dalej ustawia tylko first_name i last_name. W nocy dodaje wiersze z full_name = NULL, a późniejszy kod zakłada, że full_name zawsze istnieje.
Jak uniknąć utknięcia w połowie migracji
Traktuj każdy krok jak wydanie, które może trwać dni:
- Trzymaj nową kolumnę nullable w trakcie przejścia i wymuszaj „wymagane” na poziomie kodu najpierw.
- Backfilluj w małych batchach z możliwością pauzy i obserwuj obciążenie DB.
- Spraw kod tolerancyjnym: czytaj obie ścieżki, zapisuj obie gdy trzeba, obsługuj brakujące wartości.
- Audytuj każde miejsce dotykające tabeli, włącznie z workerami i raportami.
Szybka lista kontrolna przed każdym wydaniem
Powtarzalna lista kontrolna chroni przed wysłaniem kodu, który działa tylko w jednym stanie bazy.
Przed wdrożeniem potwierdź, że baza ma już rozszerzone elementy (nowe kolumny/tabele, indeksy utworzone mało blokująco). Następnie upewnij się, że aplikacja jest tolerancyjna: powinna działać ze starym kształtem, z rozszerzonym kształtem i w stanie częściowo backfillowanym.
Zachowaj listę krótką:
- Expansion jest obecne: nowe obiekty schematu istnieją i zostały dodane w sposób nisko blokujący.
- Zgodność jest realna: aplikacja działa ze starym i rozszerzonym schematem, włącznie z workerami i ścieżkami administracyjnymi.
- Backfill jest kontrolowany: małe batchy, możliwe do wstrzymania, z podstawowymi metrykami postępu.
- Przełączenie odczytów jest zaplanowane: wiesz dokładnie, kiedy przenosisz odczyty i jak cofnąć, jeśli wyniki będą niepoprawne.
- Contract jest opóźniony: czekasz co najmniej jeden lub dwa cykle wydania zanim usuniesz stare obiekty.
Migracja jest zakończona dopiero wtedy, gdy odczyty używają nowych danych, zapisy już nie utrzymują starych danych i zweryfikowałeś backfill przynajmniej jednym prostym checkiem (liczby lub próbki).
Realistyczny przykład: wymiana kolumny bez przestojów
Zrób snapshot przed pracami na schemacie
Zrób snapshot przed ryzykownymi zmianami, żeby móc szybko cofnąć.
Załóżmy, że masz tabelę PostgreSQL customers z kolumną phone trzymającą niejednolite wartości (różne formaty, czasem puste). Chcesz ją zastąpić phone_e164, ale nie możesz blokować wydań ani zamykać aplikacji.
Czysta sekwencja expand/contract wygląda tak:
- Expand: dodaj
phone_e164 jako nullable, bez domyślnej wartości i bez surowych constraintów.
- Kompatybilne wdrożenie: zaktualizuj kod, żeby zapisywał i do
phone, i do phone_e164, ale trzymaj odczyty na phone, żeby nic się nie zmieniło dla użytkowników.
- Backfill: konwertuj istniejące wiersze w małych batchach (np. po 1000).
- Przełączenie odczytów: wdroż kod, który czyta
phone_e164 najpierw, a jeśli jest NULL, wraca do phone.
- Contract: kiedy masz pewność, że wszystko używa
phone_e164, usuń fallback, dropnij phone, a potem dodaj ostrzejsze ograniczenia jeśli są potrzebne.
Rollback pozostaje prosty, jeśli każdy krok jest wstecznie zgodny. Jeśli przełączenie odczytów powoduje problemy, cofnij aplikację, a baza nadal ma obie kolumny. Jeśli backfill generuje skoki obciążenia, wstrzymaj job, zmniejsz batch i kontynuuj później.
Jeśli chcesz, żeby zespół się trzymał planu, udokumentuj wszystko w jednym miejscu: dokładny SQL, które wydanie przełącza odczyty, jak mierzysz ukończenie (np. procent non-NULL phone_e164) i kto odpowiada za każdy krok.
Następne kroki: uczynić to powtarzalnym
Wzorzec expand/contract działa najlepiej, gdy staje się rutyną. Napisz krótki runbook, którego zespół będzie używać przy każdej zmianie schematu — najlepiej jedna strona i wystarczająco szczegółowa, żeby nowy członek mógł ją wykonać.
Praktyczny szablon obejmuje:
- Expand (dokładne migracje)
- Zmiany w kodzie (co musi pozostać wstecznie zgodne i gdzie używany jest dual-read lub dual-write)
- Backfill (rozmiar batcha, limity szybkości, pauza/wznowienie)
- Weryfikacja (zapytania i metryki potwierdzające poprawność)
- Contract (co jest usuwane i kiedy)
Ustal właścicieli z góry. „Wszyscy myśleli, że ktoś inny zrobi contract” to powód, dla którego stare kolumny i flagi funkcji żyją miesiącami.
Nawet jeśli backfill działa online, planuj go na niższy ruch — łatwiej trzymać małe batchy, obserwować obciążenie i szybko zatrzymać pracę, jeśli opóźnienia rosną.
Jeśli budujesz i wdrażasz z Koder.ai (koder.ai), Planning Mode może pomóc rozrysować fazy i punkty kontrolne przed dotknięciem produkcji. Te same zasady zgodności nadal obowiązują, ale zapisanie kroków utrudnia pominięcie „nudnych” części, które zapobiegają outage'om.