22 wrz 2025·6 min
Jak utrzymać generowany kod: zasada nudnej architektury
Dowiedz się, jak utrzymać generowany kod w stanie łatwym do modyfikacji stosując zasadę nudnej architektury: jasne granice folderów, spójne nazwy i proste domyślne ustawienia zmniejszające przyszłą pracę.
Dlaczego utrzymanie generowanego kodu jest trudniejsze
Generowany kod zmienia codzienną pracę. Nie tylko budujesz funkcje — prowadzisz system, który może szybko tworzyć mnóstwo plików. Ta prędkość jest realna, ale małe niespójności mnożą się szybko.
Wygenerowany kod często wygląda dobrze w izolacji. Koszty pojawiają się przy drugiej i trzeciej zmianie: nie wiadomo, gdzie dana część powinna być, poprawiasz to samo zachowanie w dwóch miejscach albo unikasz modyfikowania pliku, bo nie wiesz, co to jeszcze dotyka.
„Sprytna” struktura staje się droga, bo jest trudna do przewidzenia. Niestandardowe wzorce, ukryta magia i mocna abstrakcja mają sens pierwszego dnia. W szóstym tygodniu kolejna zmiana spowalnia, bo trzeba się znowu nauczyć tego triku, zanim będzie można jej bezpiecznie dokonać. Przy generowaniu wspieranym przez AI ta sprytność może też zmylić przyszłe generacje i prowadzić do zdublowanej logiki lub kolejnych warstw nałożonych jedna na drugą.
Nudna architektura to przeciwieństwo: proste granice, proste nazwy i oczywiste domyślne ustawienia. Nie chodzi o perfekcję. Chodzi o wybór układu, który zmęczony współpracownik (albo przyszłe ja) zrozumie w 30 sekund.
Prosty cel: ułatwić następną zmianę, nie zaimponować. To zwykle oznacza jedno jasne miejsce dla każdego rodzaju kodu (UI, API, dane, wspólne narzędzia), przewidywalne nazwy pasujące do roli pliku oraz minimalną „magia” jak auto-wiązanie, ukryte globalne zmienne czy metaprogramowanie.
Przykład: jeśli poprosisz Koder.ai o dodanie „zaproszeń do zespołu”, chcesz, by umieścił UI w obszarze UI, dodał jedną trasę API w obszarze API i zapisał dane zaproszeń w warstwie danych, bez wymyślania nowego folderu lub wzorca tylko dla tej funkcji. To nudna spójność utrzymuje przyszłe edycje tanie.
Zasada nudnej architektury
Generowany kod staje się drogi, gdy daje wiele sposobów na to samo zadanie. Zasada nudnej architektury jest prosta: spraw, by następna zmiana była przewidywalna, nawet jeśli pierwsze rozwiązanie wydaje się mniej sprytne.
Powinieneś być w stanie szybko odpowiedzieć na te pytania:
- Gdzie żyje ta funkcja?
- Gdzie dodać nowy plik?
- Jak go nazwać?
- Jaka jest najprostsza ścieżka od UI do danych?
Reguła
Wybierz jedną prostą strukturę i trzymaj się jej wszędzie. Gdy narzędzie (lub współpracownik) zasugeruje wyszukany wzorzec, domyślną odpowiedzią jest „nie”, chyba że naprawdę rozwiązuje istotny problem.
Praktyczne domyślne ustawienia, które się obronią w czasie:
- Jedna odpowiedzialność na folder i na plik. Jeśli plik ma dwa powody do zmiany, rozdziel go.
- Przewidywalność jest ważniejsza niż elastyczność. Ten sam typ rzeczy trafia w to samo miejsce, za każdym razem.
- Preferuj standardowe podejście stosu technologicznego zamiast mini-frameworków na zamówienie.
- Uczyń ścieżkę szczęścia oczywistą. Nowi współpracownicy powinni zgadywać właściwe miejsce bez pytania.
- Odrzucaj „magiczne” rozwiązania. Unikaj ukrytego zachowania, refleksji i zbyt wyszukanych abstrakcji.
Krótki test mentalny
Wyobraź sobie, że nowy deweloper otwiera repozytorium i musi dodać przycisk „Anuluj subskrypcję”. Nie powinien musieć najpierw poznawać niestandardowej architektury. Powinien znaleźć jasny obszar funkcji, komponent UI, jedno miejsce klienta API i jedną ścieżkę dostępu do danych.
Ta zasada dobrze działa z narzędziami typu vibe-coding, jak Koder.ai: możesz generować szybko, ale wciąż kierujesz wynik do tych samych nudnych granic za każdym razem.
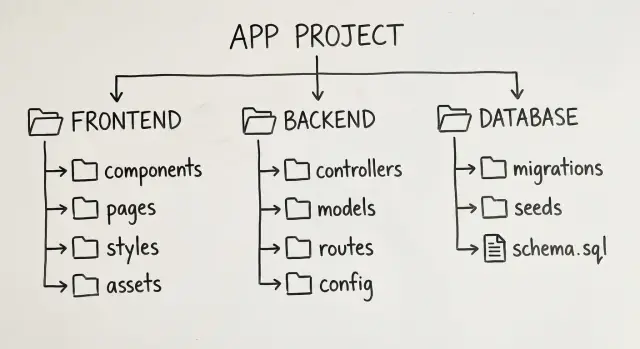
Proste granice folderów, które skalują
Generowany kod ma tendencję do szybkiego przyrostu. Najbezpieczniejszym sposobem utrzymania go jest nudna mapa folderów, w której każdy zgadnie, gdzie należy wprowadzić zmianę.
Mały, top-level układ pasujący do wielu aplikacji webowych:
app/– ekrany, routing i stan na poziomie stroncomponents/– wielokrotnego użytku części UIfeatures/– jeden folder na funkcję (billing, projects, settings)api/– kod klienta API i helpery żądańserver/– handlery backendu, serwisy i reguły biznesowe
To czyni granice oczywistymi: UI znajduje się w app/ i components/, wywołania API w api/, a logika backendu w server/.
Dostęp do danych też powinien być nudny. Trzymaj zapytania SQL i kod repozytoriów blisko backendu, a nie rozrzucone po plikach UI. W konfiguracji Go + PostgreSQL prosta zasada to: handlery HTTP wywołują serwisy, serwisy wywołują repozytoria, repozytoria rozmawiają z bazą danych.
Wspólne typy i narzędzia zasługują na jasne miejsce, ale trzymaj je małe. Umieść typy przekrojowe w types/ (DTO, enumy, wspólne interfejsy), a małe pomocniki w utils/ (formatowanie dat, proste walidatory). Jeśli utils/ zaczyna wyglądać jak drugie aplikacja, kod prawdopodobnie należy do konkretnej funkcji.
Generowany vs ręcznie pisany kod
Traktuj foldery z generowanym kodem jako wymienne.
- Umieść wygenerowane pliki w
generated/(lubgen/) i unikaj ich bezpośredniej edycji. - Trzymaj niestandardową logikę w
features/lubserver/, żeby regeneracja jej nie nadpisała. - Jeśli musisz poprawić zachowanie wygenerowane, opakuj je (plik adaptera) zamiast modyfikować źródło.
Przykład: jeśli Koder.ai generuje klienta API, umieść go w generated/api/, a następnie napisz cienkie wrappery w api/, gdzie dodasz retry, logowanie lub czytelniejsze komunikaty o błędach bez dotykania wygenerowanych plików.
Konwencje nazewnictwa, które zapobiegają chaosowi
Generowany kod łatwo tworzyć i łatwo zapełnić. Nazewnictwo sprawia, że pozostaje czytelny za miesiąc.
Wybierz jeden styl nazewnictwa i nie mieszaj go:
- Foldery i pliki:
kebab-case(user-profile-card.tsx,billing-settings) - Komponenty React:
PascalCase(UserProfileCard) - Funkcje i zmienne:
camelCase(getUserProfile) - Stałe:
SCREAMING_SNAKE_CASE(MAX_RETRY_COUNT)
Nazwij elementy według roli, nie według tego, jak działają teraz. user-repository.ts to rola. postgres-user-repository.ts to szczegół implementacji, który może się zmienić. Używaj sufiksów implementacji tylko gdy naprawdę masz wiele implementacji.
Unikaj szufladek takich jak misc, helpers czy gigantycznego utils. Jeśli funkcja jest używana tylko przez jedną funkcję, trzymaj ją blisko tej funkcji. Jeśli jest współdzielona, niech nazwa opisuje zdolność (date-format.ts, money-format.ts, id-generator.ts) i trzymaj moduł mały.
Konwencje, które przyspieszają nawigację
Gdy trasy, handlery i komponenty podążają za wzorcem, znajdziesz pliki bez szukania:
- Trasy:
routes/users.tsz ścieżkami jak/users/:userId - Handlery (HTTP):
handlers/users.get.ts,handlers/users.update.ts - Serwisy (reguły biznesowe):
services/user-profile-service.ts - Dostęp do danych:
repositories/user-repository.ts - Komponenty UI:
components/user/UserProfileCard.tsx
Jeśli używasz Koder.ai (lub dowolnego generatora), umieść te reguły w promptcie i utrzymuj je podczas edycji. Chodzi o przewidywalność: jeśli możesz zgadnąć nazwę pliku, przyszłe zmiany pozostaną tańsze.
Domyślne bez sprytu (zasady kciuka)
Ship a clean vertical slice
Wygeneruj jedną wąską funkcję end-to-end, a potem używaj tej samej struktury przy każdej zmianie.
Generowany kod może imponować pierwszego dnia i boleć trzydziestego. Wybierz domyślne ustawienia, które czynią kod oczywistym, nawet jeśli trochę powtarzalnym.
Zacznij od usunięcia magii. Pomiń dynamiczne ładowanie, refleksyjne sztuczki i auto-wiązanie, chyba że są mierzalne korzyści. Te funkcje ukrywają skąd się bierze kod, co spowalnia debugowanie i refaktoring.
Preferuj jawne importy i czytelne zależności. Jeśli plik czegoś potrzebuje, zaimportuj to bezpośrednio. Jeśli moduły wymagają połączenia, zrób to w jednym widocznym miejscu (np. pojedynczy plik kompozycji). Czytelnik nie powinien zgadywać, co uruchamia się jako pierwsze.
Trzymaj konfigurację nudną i scentralizowaną. Umieść zmienne środowiskowe, feature flagi i ustawienia aplikacji w jednym module ze spójnym nazewnictwem. Nie rozrzucaj konfiguracji po losowych plikach, bo było wygodniej.
Zasady, które utrzymują zespół spójnym:
- Wybierz jawne zamiast ukrytego (importy, routing, DI, efekty uboczne).
- Jeśli coś oszczędza 10 linii, ale wprowadza nową koncepcję, odpuść to.
- Miej jeden sposób robienia rzeczy (jeden logger, jeden moduł konfiguracji).
- Preferuj prosty przepływ danych zamiast ukrytych obserwatorów czy łańcuchów zdarzeń.
- Przy debugowaniu usuń najpierw sprytne rozwiązania.
Obsługa błędów to miejsce, gdzie spryt najbardziej szkodzi. Wybierz jeden wzorzec i używaj go wszędzie: zwracaj ustrukturyzowane błędy z warstwy danych, mapuj je na odpowiedzi HTTP w jednym miejscu i tłumacz na komunikaty dla użytkownika na granicy UI. Nie rzucaj trzech różnych typów błędów w zależności od pliku.
Jeśli generujesz aplikację z Koder.ai, poproś o te domyślne ustawienia od początku: jawne wiązanie modułów, scentralizowana konfiguracja i jeden wzorzec obsługi błędów.
Granice między UI, API i danymi
Jasne linie między UI, API i danymi utrzymują zmiany lokalnymi. Większość tajemniczych błędów zdarza się, gdy jedna warstwa zaczyna robić zadania innej warstwy.
UI: pokazywać stan, zbierać dane wejściowe
Traktuj UI (często React) jako miejsce do renderowania ekranów i zarządzania stanem tylko UI: która zakładka jest otwarta, błędy formularza, spinnery ładowania i podstawowa obsługa wejścia.
Trzymaj stan serwera osobno: pobrane listy, cache profili i wszystko, co musi zgadzać się z backendem. Kiedy komponenty UI zaczynają liczyć sumy, walidować skomplikowane reguły lub decydować o uprawnieniach, logika rozprasza się po ekranach i staje się kosztowna w zmianach.
API: cienkie, stabilne kształty
Utrzymuj warstwę API przewidywalną. Powinna tłumaczyć żądania HTTP na wywołania kodu biznesowego, a wyniki na stabilne kształty request/response. Unikaj wysyłania modeli bazy bezpośrednio przez sieć. Stabilne odpowiedzi pozwalają refaktoryzować wnętrze bez łamania UI.
Prosta ścieżka, która dobrze działa:
- UI wywołuje klienta API z typowanymi obiektami request/response.
- Handlery API walidują wejście i wywołują metodę serwisu.
- Serwisy zawierają reguły biznesowe i workflowy.
- Repozytoria ukrywają zapytania do bazy za małymi metodami.
Dane: ukryj zapytania za repozytoriami
Umieść SQL (lub logikę ORM) za granicą repozytorium, tak by reszta aplikacji „nie wiedziała”, jak dane są przechowywane. W Go + PostgreSQL zwykle oznacza to repozytoria jak UserRepo lub InvoiceRepo z małymi, jasnymi metodami (GetByID, ListByAccount, Save).
Konkretna ilustracja: dodanie kodów rabatowych. UI renderuje pole i pokazuje zaktualizowaną cenę. API przyjmuje code i zwraca {total, discount}. Serwis decyduje, czy kod jest ważny i jak się łączą zniżki. Repozytorium pobiera i zapisuje wymagane wiersze.
Krok po kroku: ustaw utrzymywalny generowany kod
Wygenerowane aplikacje mogą szybko wyglądać na „skończone”, ale to struktura sprawia, że zmiany są tanie później. Najpierw zdecyduj o nudnych regułach, potem wygeneruj tylko tyle kodu, by je zweryfikować.
Praktyczny przebieg ustawień
Zacznij od krótkiego planowania. Jeśli używasz Koder.ai, Planning Mode to dobre miejsce, by opisać mapę folderów i kilka reguł nazewnictwa przed generacją czegokolwiek.
Następnie wykonaj tę sekwencję:
- Zdefiniuj mapę i reguły na piśmie. Wybierz granice (np.:
ui/,api/,data/,features/) i garść reguł nazewnictwa. - Wygeneruj jedną cienką pionową ścieżkę. Wybierz małą funkcję, która dotyka UI, API i storage, np. „utwórz kontakt”. Celem jest ścieżka end-to-end, nie kompletność.
- Natychmiast zrefaktoruj, by dopasować granice. Przenieś kod do zaplanowanych folderów, zmień nazwy niejasnych plików i usuń duplikaty. Podziel funkcje, które „robią wszystko” na UI, handler i dostęp do danych.
- Dodaj drugą funkcję, by przetestować kształt. Wybierz coś podobnego, np. „lista kontaktów”. Jeśli czujesz, że musisz złamać reguły, granice prawdopodobnie są złe.
- Zablokuj konwencje wcześnie. Dodaj krótki
CONVENTIONS.mdi traktuj go jak kontrakt. Gdy repo rośnie, zmiana nazw i wzorców staje się droga.
Sprawdzenie rzeczywistości: jeśli nowa osoba nie potrafi zgadnąć, gdzie dodać „edytuj kontakt” bez pytania, architektura wciąż nie jest dostatecznie nudna.
Scenariusz przykład: dodawanie funkcji bez bałaganu
Get rewarded for teaching
Zarabiaj kredyty, dzieląc się tym, co zbudowałeś z Koder.ai i konwencjami, których użyłeś.
Wyobraź sobie prosty CRM: lista kontaktów i formularz edycji kontaktu. Pierwszą wersję budujesz szybko, a tydzień później trzeba dodać „tagi” do kontaktów.
Traktuj aplikację jak trzy nudne pudełka: UI, API i dane. Każde pudełko ma jasne granice i literalne nazwy, więc zmiana „tagów” pozostaje mała.
Czysty układ może wyglądać tak:
web/src/pages/ContactsPage.tsxiweb/src/components/ContactForm.tsxserver/internal/http/contacts_handlers.goserver/internal/service/contacts_service.goserver/internal/repo/contacts_repo.goserver/migrations/
Teraz „tagi” stają się przewidywalne. Zaktualizuj schemat (nowa tabela contact_tags lub kolumna tags), potem dotknij każdej warstwy po kolei: repo zapisuje/odczytuje tagi, serwis je waliduje, handler udostępnia pole, UI renderuje i edytuje je. Nie wpychaj SQL do handlerów ani reguł biznesowych do komponentów React.
Jeśli produkt potem poprosi o „filtrowanie po tagu”, większość pracy będzie w ContactsPage.tsx (stan UI i query params) i handlerze HTTP (parsowanie żądania), a repozytorium obsłuży zapytanie.
Dla testów i fixture'ów trzymaj rzeczy małe i blisko kodu:
server/internal/service/contacts_service_test.godla reguł typu „nazwy tagów muszą być unikalne per kontakt”server/internal/repo/testdata/dla minimalnych fixture'ówweb/src/components/__tests__/ContactForm.test.tsxdla zachowania formularza
Jeśli generujesz to z Koder.ai, ta sama zasada obowiązuje po eksporcie: trzymaj foldery nudne, nazwy literalne, a edycje przestaną przypominać archeologię.
Typowe błędy, które drożeją w przyszłości
Generowany kod może wyglądać schludnie pierwszego dnia, a mimo to być kosztowny później. Zwykłym winowajcą nie jest „zły kod”, tylko niespójność.
Jednym drogim nawykiem jest pozwalanie generatorowi na wymyślanie struktury za każdym razem. Funkcja ląduje z własnymi folderami, stylem nazewnictwa i pomocnikami, i kończysz z trzema sposobami robienia tej samej rzeczy. Wybierz jeden wzorzec, zapisz go i traktuj każdy nowy wzorzec jako świadomą zmianę, nie domyślną.
Inną pułapką jest mieszanie warstw. Gdy komponent UI rozmawia z bazą danych, albo handler API buduje SQL, małe zmiany przekształcają się w ryzykowne edycje obejmujące cały projekt. Trzymaj granicę: UI wywołuje API, API wywołuje serwis, serwis wywołuje dostęp do danych.
Nadmierne używanie ogólnych abstrakcji zbyt wcześnie też dodaje kosztów. Uniwersalny „BaseService” czy „Repository” wygląda ładnie, ale wczesne abstrakcje to zgadywanie. Gdy rzeczywistość się zmienia, walczysz z własnym frameworkiem zamiast wysyłać funkcję.
Ciągłe zmienianie nazw i reorganizacja to cicha forma długu. Jeśli pliki przenoszą się co tydzień, ludzie przestają ufać układowi i szybkie poprawki lądują w losowych miejscach. Ustabilizuj mapę folderów najpierw, potem refaktoruj planowo.
Na koniec, uważaj na „kod platformowy”, który nie ma realnego użytkownika. Wspólne biblioteki i domorosłe narzędzia się zwracają tylko przy powtarzalnych, udowodnionych potrzebach. Do tego momentu trzymaj domyślne rozwiązania bezpośrednie.
Krótka lista kontrolna przed wydaniem
Plan your boring architecture
Zdefiniuj foldery, nazewnictwo i granice UI-API-danych w Koder.ai przed pierwszą generacją.
Jeśli ktoś nowy otworzy repo, powinien szybko odpowiedzieć na jedno pytanie: „Gdzie to dodać?”
2-minutowy test nawigacji
Podaj projekt współpracownikowi (albo przyszłemu sobie) i poproś, by dodał małą funkcję, np. „dodaj pole do formularza rejestracji”. Jeśli nie znajdzie właściwego miejsca szybko, struktura nie spełnia swojej roli.
Sprawdź trzy jasne domy:
- Zmiany UI living w jednym oczywistym miejscu.
- Trasy/handlery API łatwe do znalezienia z poziomu UI.
- Model danych i zmiany bazy mają jasne miejsce.
Zasady warte egzekwowania w code review
- UI, API i dane mają swoje domy, wyjątki są rzadkie.
- Nazwy czyta się jak etykiety, nie zagadki.
- Łamanie warstw jest wychwytywane (np. UI sięga do bazy).
- Sprytne skróty domyślnie się odrzuca.
Jeśli platforma to wspiera, trzymaj ścieżkę rollbacku. Snapshoty i rollback są szczególnie przydatne, gdy eksperymentujesz ze strukturą i chcesz mieć bezpieczny powrót.
Następne kroki: pozostań nudny, utrzymaj niski koszt
Utrzymywalność rośnie najszybciej, gdy przestaniesz debatować o stylu i zaczniesz podejmować kilka decyzji, które się utrzymają.
Zapisz krótki zestaw konwencji, który usuwa codzienne wahania: gdzie trafiają pliki, jak się nazywają oraz jak obsługiwane są błędy i konfiguracja. Trzymaj to na tyle krótkie, by przeczytać w minutę.
Następnie zrób jedno przejście porządkujące, by dopasować kod do tych reguł i przestań co tydzień przestawiać wszystko. Częste reorganizacje spowalniają kolejną zmianę, nawet jeśli kod wygląda ładniej.
Jeśli budujesz z Koder.ai (koder.ai), warto zapisać te konwencje jako startowy prompt, aby każda nowa generacja trafiała w ten sam układ. Narzędzie może działać szybko, ale to nudne granice sprawiają, że kod łatwo się zmienia.