18 sie 2025·7 min
Usuwanie miękkie vs twarde: kompromisy ważne w realnych aplikacjach
Usuwanie miękkie a twarde: poznaj rzeczywiste kompromisy dla analiz, wsparcia, żądań usunięcia w stylu RODO i złożoności zapytań oraz bezpieczne wzorce przywracania.
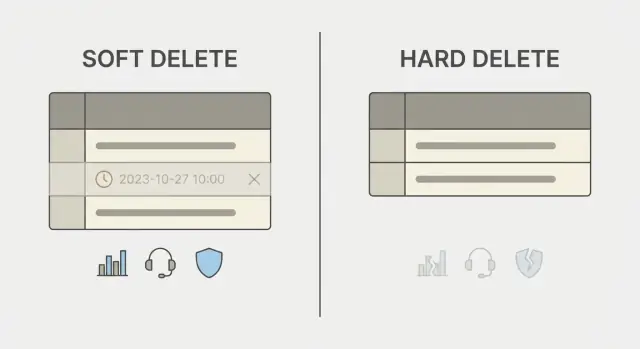
Co naprawdę oznaczają soft delete i hard delete
Przycisk „usuń” może oznaczać w bazie danych dwie bardzo różne rzeczy.
Hard delete usuwa wiersz. Po tym rekord znika, chyba że masz kopie zapasowe, logi lub repliki, które go nadal przechowują. To proste do zrozumienia, ale ostateczne.
Soft delete zostawia wiersz, ale oznacza go jako usunięty, zwykle przez pole takie jak deleted_at lub is_deleted. Aplikacja traktuje oznaczone wiersze jako niewidoczne. Zachowujesz powiązane dane, historię i czasem możliwość przywrócenia rekordu.
Ten wybór pojawia się w codziennej pracy częściej, niż się wydaje. Wpływa na odpowiedzi na pytania typu: „Dlaczego przychód spadł w zeszłym miesiącu?”, „Możecie przywrócić mój usunięty projekt?” albo „Dostaliśmy wniosek RODO — czy rzeczywiście usuwamy dane osobowe?” Kształtuje też, co UI pokazuje użytkownikom. Użytkownicy często zakładają, że mogą cofnąć akcję, dopóki nie okaże się, że nie mogą.
Praktyczna zasada:
- Używaj soft delete, gdy użytkownicy oczekują cofnięcia, gdy support musi przywracać pomyłki lub gdy potrzebujesz śladu audytowego.
- Używaj hard delete, gdy przechowywanie danych stwarza ryzyko prawne, bezpieczeństwa lub oczywiste koszty magazynowania bez realnej wartości.
- Użyj obu, gdy chcesz mieć okres „kosza”: najpierw soft delete, potem trwałe oczyszczenie.
Przykład: klient usuwa workspace, a potem zdaje sobie sprawę, że były tam faktury potrzebne do księgowości. Przy soft delete support może go przywrócić (jeśli aplikacja poprawnie obsługuje przywracanie). Przy hard delete zwykle pozostaje tłumaczenie o kopiach zapasowych, opóźnieniach lub „to niemożliwe”.
Żadne podejście nie jest uniwersalnie „najlepsze”. Najmniej bolesna opcja zależy od tego, co chcesz chronić: zaufanie użytkownika, dokładność raportów czy zgodność z prywatnością.
Trade-offy w analizach: dokładność vs zachowanie historii
Wybór sposobu usuwania szybko wpływa na analitykę. W dniu, kiedy zaczynasz śledzić aktywnych użytkowników, konwersję czy przychód, „usunięty” przestaje być prostym stanem i staje się decyzją raportową.
Jeśli stosujesz hard delete, wiele metryk wygląda czysto, bo usunięte rekordy znikają z zapytań. Tracisz jednak kontekst: stare subskrypcje, wcześniejszy rozmiar zespołu czy jak wyglądał lejek miesiąc temu. Usunięty klient może przesunąć historyczne wykresy przy ponownym uruchomieniu raportów, co niepokoi finansów i growth.
Jeżeli stosujesz soft delete, zachowujesz historię, ale możesz przypadkowo zawyżać liczby. Proste „COUNT users” może liczyć osoby, które odeszły. Wykres churnu może się dublować, jeśli w jednym raporcie traktujesz deleted_at jako churn, a w innym go ignorujesz. Nawet przychody mogą się komplikować, jeśli faktury pozostają, a konto jest oznaczone jako usunięte.
Dobrze działa wybranie spójnego wzorca raportowania i trzymanie się go:
- Filtruj rekordy oznaczone jako usunięte w metrykach „stan bieżący” (aktywni użytkownicy, bieżące MRR).
- Używaj tabel snapshotowych dla dashboardów czasowych, żeby historia nie zmieniała się, gdy encje zostaną usunięte później.
- Oddziel fakty od encji: przechowuj niezmienne wiersze zdarzeń (płatności, logowania) nawet jeśli ukrywasz rekord użytkownika.
- Traktuj „usunięcie” jako stan cyklu życia z własną datą i raportuj go jawnie (utworzony, aktywowany, usunięty).
- Zdefiniuj okna retencji: kiedy soft-deleted dane zostają faktycznie usunięte.
Klucz to dokumentacja, żeby analitycy nie zgadywali. Zapisz, co oznacza „aktywny”, czy soft-deleted użytkownicy są wliczani i jak przypisywany jest przychód, jeśli konto później zostanie usunięte.
Konkret: workspace został omyłkowo usunięty, potem przywrócony. Jeśli dashboard liczy workspaces bez filtrów, zobaczysz nagły spadek i odbicie, którego realnie nie było. Dzięki snapshotom wykres historyczny pozostaje stabilny, podczas gdy widoki produktowe mogą ukrywać usunięte workspace'y.
Support i ślad audytu: co da się później odzyskać
Większość zgłoszeń supportu związanych z usuwaniem brzmi podobnie: „Usunąłem to przez pomyłkę” albo „Gdzie jest mój rekord?” Strategia usuwania decyduje, czy support odpowie w minutę, czy jedyną uczciwą odpowiedzią będzie „to zniknęło”.
Przy soft delete zwykle możesz zweryfikować, co się stało, i cofnąć. Przy hard delete support często musi polegać na backupach (o ile są), a to może być wolne, niekompletne lub niemożliwe dla pojedynczego elementu. Dlatego wybór to nie tylko sprawa bazy danych — wpływa na to, jak „pomocny” jest produkt po błędzie.
Prosty ślad audytu (co przechowywać)
Jeśli spodziewasz się realnego wsparcia, dodaj kilka pól, które wyjaśnią zdarzenia usuwania:
deleted_at(znacznik czasu)deleted_by(id użytkownika lub systemu)delete_reason(opcjonalnie, krótki tekst)deleted_from_iplubdeleted_from_device(opcjonalnie)restored_atirestored_by(jeśli obsługujesz przywracanie)
Nawet bez pełnego logu aktywności te dane pozwalają supportowi odpowiedzieć: kto to usunął, kiedy i czy był to przypadek czy automatyczne oczyszczanie.
Co oznaczają hard delete dla supportu
Hard delete może być w porządku dla danych tymczasowych, ale dla rekordów widocznych dla użytkownika zmienia możliwości supportu.
Support nie może przywrócić pojedynczego rekordu, chyba że zbudowałeś osobny kosz. Może być potrzebne pełne odtworzenie z backupu, co wpływa na inne dane. Trudniej też udowodnić, co się stało, co prowadzi do długich wymian komunikatów.
Funkcje przywracania zmieniają też obciążenie pracą. Jeśli użytkownicy mogą sami przywrócić w oknie czasowym, liczba ticketów spada. Jeśli przywracanie wymaga ręcznej interwencji supportu, ticketów może być więcej, ale stają się szybkie i powtarzalne zamiast jednostkowych dochodzeń.
Usuwanie w stylu RODO: soft delete to nie pełne wymazanie
„Prawo do bycia zapomnianym” zwykle oznacza, że musisz zaprzestać przetwarzania danych osoby i usunąć je z miejsc, gdzie są nadal użyteczne. Nie zawsze znaczy to natychmiastowe wyrzucenie wszystkich historycznych agregatów, ale oznacza, że nie powinieneś trzymać identyfikowalnych danych „na wszelki wypadek”, jeśli nie masz podstawy prawnej.
Tu soft delete kontra hard delete staje się czymś więcej niż wyborem produktowym. Soft delete (np. ustawienie deleted_at) często tylko ukrywa rekord w aplikacji. Dane nadal są w bazie, nadal dostępne dla adminów i często obecne w eksportach, indeksach wyszukiwania i tabelach analitycznych. Dla wielu wniosków RODO to nie jest wymazanie.
Wciąż potrzebujesz purge, gdy:
- Użytkownik żąda usunięcia i nie masz ważnego powodu retencyjnego (np. wymogi wystawiania faktur).
- Przechowywałeś dane szczególnej kategorii i polityka mówi, że muszą zostać usunięte.
- Rekord pojawia się w eksportach widocznych dla użytkownika lub może być odzyskany przez support.
- Zewnętrzny procesor (e-mail, analityka, narzędzia supportowe) nadal je przechowuje.
Backupy i logi to elementy, o których zespoły zapominają. Możesz nie być w stanie usunąć pojedynczego wiersza z zaszyfrowanego backupu, ale możesz ustalić zasady: backupy wygasają szybko, a przy odtwarzaniu należy ponownie zastosować zdarzenia usunięcia przed uruchomieniem systemu. Logi powinny unikać przechowywania surowych danych osobowych i mieć jasne limity retencji.
Praktyczna polityka dwustopniowa:
- Soft delete natychmiast (produkt zachowuje się poprawnie, konta są dezaktywowane, “przywróć usunięte” może działać dla pomyłek).
- Uruchom timer retencyjny (np. 7–30 dni) i zaplanuj zadanie purge, które hard-delete'uje lub anonimizuje pola osobowe.
- Zapisz, co się stało w śladzie audytu używając nieidentyfikujących markerów (znaczniki czasu, kody przyczyn), by support mógł wyjaśnić działania bez przechowywania danych.
Jeśli platforma wspiera eksport źródeł lub eksport danych, traktuj eksporty jako repozytoria danych: zdefiniuj, gdzie leżą, kto ma do nich dostęp i kiedy są usuwane.
Złożoność zapytań i zachowanie produktu: ukryty koszt
Szybko dodaj soft delete
Generuj tabele i API z polami deleted_at i deleted_by w kilka minut.
Soft delete brzmi prosto: dodaj deleted_at (albo is_deleted) i ukryj wiersz. Ukryty koszt polega na tym, że każde miejsce, w którym czytasz dane, musi teraz pamiętać o tej fladze. Pomyśl o tym raz, a pojawią się dziwne błędy: sumy obejmują usunięte elementy, wyszukiwanie pokazuje „duchy”, albo użytkownik widzi coś, co myślał, że zniknęło.
Edge case'y UI/UX pojawiają się szybko. Wyobraź sobie, że zespół usuwa projekt „Roadmap” i potem ktoś próbuje stworzyć nowy projekt o tej samej nazwie. Jeśli masz ograniczenie unikalności nazwy, tworzenie może się nie powieść, bo usunięty wiersz nadal istnieje. Wyszukiwanie też może mylić: jeśli ukrywasz usunięte elementy list, ale nie w globalnym wyszukiwaniu, użytkownicy pomyślą, że aplikacja jest zepsuta.
Filtry soft delete są często pomijane w:
- Panelach admina i narzędziach supportu
- Zadaniach backgroundowych (e-maile, przypomnienia, oczyszczanie)
- Zapytaniach analitycznych i eksportach
- Sprawdzeniach uprawnień („czy ten rekord istnieje?”)
- Autouzupełnianiu i wyszukiwaniu
Wydajność zwykle jest w porządku na początku, ale dodatkowy warunek dodaje pracy. Jeśli większość wierszy jest aktywna, filtrowanie deleted_at IS NULL jest tanie. Jeśli wiele wierszy jest usuniętych, baza musi pominąć więcej wierszy, chyba że dodasz odpowiedni indeks. W prostych słowach: to jak szukanie aktualnych dokumentów w szufladzie, która też zawiera wiele starych.
Oddzielna strefa „Archiwum” może zmniejszyć zamieszanie. Domyślny widok pokaż tylko aktywne rekordy, a usunięte trzymaj w jednym miejscu z jasnymi oznaczeniami i oknem czasowym. W narzędziach tworzonych szybko (np. aplikacje wewnętrzne zbudowane na Koder.ai) ta decyzja produktowa często zapobiega więcej ticketom niż jakikolwiek sprytny trick zapytaniowy.
Typowe modele danych dla soft delete
Soft delete to nie jedna funkcja. To wybór modelu danych, a model, który wybierzesz, ukształtuje wszystko: reguły zapytań, zachowanie przy przywracaniu i co „usunięte” znaczy dla twojego produktu.
Model 1: deleted_at plus deleted_by
Najczęstszy wzorzec to nullable timestamp. Gdy rekord jest usuwany, ustaw deleted_at (i często deleted_by na id użytkownika). „Aktywne” rekordy to te, gdzie deleted_at jest null.
Dobrze działa, gdy potrzebujesz prostego przywracania: przywrócenie to czyszczenie deleted_at i deleted_by. Daje też prosty sygnał audytowy dla supportu.
Model 2: jawne stany statusu
Zamiast znacznika czasu, niektóre zespoły używają pola status z jasno nazwanymi stanami jak active, archived i deleted. Przydatne, gdy „archived” to rzeczywisty stan produktu (ukryty na większości ekranów, ale nadal liczony w billing, np.).
Kosztem są reguły. Musisz zdefiniować, co każdy stan oznacza wszędzie: wyszukiwanie, powiadomienia, eksporty i analityka.
Model 3: oddzielne przechowywanie dla rekordów wysokiej wartości
Dla wrażliwych lub wartościowych obiektów możesz przenieść usunięte wiersze do osobnej tabeli albo zapisać zdarzenie w append-only logu.
- Soft delete z timestampem:
deleted_at,deleted_by - Maszyna stanów:
statusz nazwanymi stanami - Osobna tabela dla usuniętych: tabela „active” pozostaje mała
- Log zdarzeń: przechowuj „kto co zrobił” bez trzymania pełnych wierszy na zawsze
To często stosuje się, gdy przywracanie musi być ściśle kontrolowane lub gdy chcesz mieć ślad audytu bez mieszania usuniętych danych z codziennymi zapytaniami.
Rekordy potomne też potrzebują przemyślanej reguły. Jeśli workspace jest usunięty, co się dzieje z projektami, plikami i członkostwami?
- Cascade: oznacz dzieci jako usunięte również
- Restrict: zablokuj usunięcie dopóki dzieci nie zostaną obsłużone
- Archive: przekonwertuj dzieci na
archived(nieusunięte) - Detach: usuń relacje, ale zachowaj dziecko
Wybierz jedną regułę na relację, zapisz ją i trzymaj konsekwentnie. Większość bugów „przywracanie poszło źle” wynika z różnych interpretacji usunięcia dla rodzica i dzieci.
Jak zaimplementować bezpieczne przywracanie (krok po kroku)
Przycisk przywróć brzmi prosto, ale może cicho popsuć uprawnienia, przywrócić stare dane w niewłaściwe miejsce albo zdezorientować użytkowników, jeśli „przywrócone” nie znaczy tego, czego oczekują. Zacznij od zapisania dokładnej obietnicy produktu.
Praktyczny flow przywracania
Użyj krótkiej, ścisłej sekwencji, aby przywracanie było przewidywalne i audytowalne.
- Zdefiniuj, co oznacza „przywróć”. Czy rekord zachowa to samo ID? Czy wróci do tego samego rodzica (workspace, projekt) i zachowa relacje? Zdecyduj, co się stanie z członkostwami, rolami i widocznością.
- Wymagaj potwierdzenia i zbierz powód. Pokaż, co zostanie przywrócone (nazwa, właściciel, data ostatniej modyfikacji) i żądaj jasnego potwierdzenia. Dla supportu pole na krótki powód („usunąłem omyłkowo”, „zamykanie ticketa”) zwykle wystarcza.
- Sprawdź konflikty zanim cokolwiek zmienisz. Typowe problemy: stara nazwa została użyta ponownie, użytkownik nie ma już uprawnień albo powiązane rekordy zostały hard-deleted. Wybierz regułę: zablokuj przywrócenie z jasnym komunikatem albo przywróć do stanu „wymaga przeglądu”.
- Zaloguj akcję przywrócenia. Zapisz kto przywrócił, kiedy, skąd (UI, API) i co się zmieniło. To pomaga w audytach i support, i jest niezbędne, gdy ktoś zapyta: „Dlaczego to wróciło?”.
- Dodaj limit czasowy, jeśli to pasuje. Wiele aplikacji pozwala na przywrócenie przez 30 lub 90 dni, potem wymaga innego procesu odzyskiwania lub traktuje to jako trwałe.
Jeśli budujesz szybko w narzędziu chat-driven jak Koder.ai, zachowaj te sprawdzenia jako część wygenerowanego workflow, aby każdy ekran i endpoint stosował te same reguły.
Typowe błędy i pułapki, których unikać
Testuj przypadki brzegowe usuwania
Przetestuj okna cofania i kolizje pól unikalnych zanim zatwierdzisz schemat.
Największy ból przy soft delete to nie samo usunięcie, lecz miejsca, które zapominają, że rekord „zniknął”. Wiele zespołów wybiera soft delete dla bezpieczeństwa, a potem przypadkowo pokazuje usunięte elementy w wynikach wyszukiwania, odznakach czy sumach. Użytkownicy szybko zauważają, gdy dashboard mówi „12 projektów”, ale na liście jest 11.
Tuż za tym jest kontrola dostępu. Jeśli użytkownik, zespół lub workspace jest soft-deleted, nie powinien się logować, wywoływać API ani otrzymywać powiadomień. To często umyka, gdy check logowania znajduje wiersz po adresie e-mail i nigdy nie sprawdza flagi deleted.
Pułapki tworzące ticketów:
- Brak filtra deleted w jednej ścieżce odczytu (widoki admina, eksporty, wyszukiwanie, background jobs).
- Przywracanie rekordów kolidujących z polami unikalnymi (email, username, slug, numer faktury).
- Usunięcie rodzica i pozostawienie dzieci „aktywnych” (lub usunięcie dzieci, gdy rodzic nadal wygląda na żywy).
- Wliczanie usuniętych w analizach, limitach lub kalkulacjach billingowych.
- Wysyłanie usuniętych danych do stron trzecich, bo integracje i joby sync nie rozumieją „deleted”.
Kolizje unikalności są szczególnie uciążliwe przy przywracaniu. Jeśli ktoś założy nowe konto z tym samym emailem, podczas gdy stare jest soft-deleted, przywrócenie albo się nie uda, albo nadpisze niewłaściwą tożsamość. Ustal regułę wcześniej: blokuj ponowne użycie do purge, pozwól na ponowne użycie ale zablokuj przywrócenie, albo przywróć pod nowym identyfikatorem.
Scenariusz: agent supportu przywraca soft-deleted workspace. Workspace wraca, ale jego członkowie pozostają usunięci, a integracja zaczyna synchronizować stare rekordy do narzędzia partnera. Z perspektywy użytkownika przywrócenie „zadziałało połowicznie” i spowodowało bałagan.
Zanim wypuścisz przywracanie, wyraźnie określ te zachowania:
- Co oznacza „usunięty” dla logowania, dostępu API i powiadomień
- Jak przywracanie traktuje pola unikalne i własność
- Jak rekordy powiązane zachowują się z rodzicem (wszystko albo nic to lepsze niż niespodzianki)
- Jak eksporty i integracje traktują usunięte dane (wyklucz, oznacz lub wysyłaj tombstony)
Realistyczny przykład: workspace usunięty przez pomyłkę
Zespół B2B SaaS ma przycisk „Usuń workspace”. Pewnego piątku administrator robi porządki i usuwa 40 workspace'ów, które wyglądały na nieaktywne. W poniedziałek trzech klientów skarży się, że ich projekty zniknęły i prosi o natychmiastowe przywrócenie.
Zespół myślał, że decyzja będzie prosta. Nie była.
Pierwszy problem: support nie może przywrócić tego, co zostało naprawdę usunięte. Jeśli wiersz workspace został hard-deleted i kaskadowo usunięto projekty, pliki i członkostwa, jedyną opcją są backupy. To oznacza czas, ryzyko i niezręczną odpowiedź dla klienta.
Drugi problem: analityka wygląda na zepsutą. Dashboard liczy „aktywne workspace'y” zapytaniem deleted_at IS NULL. Omyłkowe usunięcie powoduje nagły spadek adopcji na wykresach. Gorzej, cotygodniowy raport porównuje do zeszłego tygodnia i generuje fałszywy spike churnu. Dane nie zniknęły, ale zostały wykluczone w niewłaściwych miejscach.
Trzeci problem: pojawia się prośba o prywatność od jednego z użytkowników. Żąda usunięcia danych osobowych. Sam soft delete tego nie spełnia. Zespół musi zaplanować purge pól osobowych (imię, e-mail, logi IP), zachowując agregaty nieosobowe jak sumy billingowe i numery faktur.
Czwarty problem: wszyscy pytają „Kto kliknął usuń?” Jeśli nie ma śladu, support nie może wyjaśnić, co się stało.
Bezpieczniejszy wzorzec to traktowanie usunięcia jako zdarzenia z metadanymi:
- Oznacz workspace jako usunięty (i ukryj go w produkcie)
- Zapisz
deleted_by,deleted_ati powód lub id ticketa - Zaloguj, co zostanie dotknięte (liczba projektów, miejsca, przestrzeń dyskowa)
- Pozwól na przywrócenie w oknie czasowym, potem purge wybranych pól osobowych gdy to wymagane
To workflow, który zespoły często budują szybko w platformach jak Koder.ai, a potem zdają sobie sprawę, że polityka usuwania potrzebuje tyle samo projektowania, co funkcje wokół niej.
Szybka lista kontrolna do wyboru strategii usuwania
Unikaj widmowych rekordów
Buduj widoki list, wyszukiwania i eksportów, które konsekwentnie filtrują usunięte dane.
Wybór między soft deletes a hard deletes to mniej kwestia preferencji, a bardziej tego, co twoja aplikacja musi gwarantować po „usunięciu” rekordu. Zadaj sobie te pytania zanim napiszesz choćby jedno zapytanie.
- Czy kiedykolwiek potrzebujesz rzeczywistego wymazania? Jeśli musisz sprostać żądaniom prywatności lub prawnym, zaplanuj prawdziwe usunięcie (i backupy, eksporty oraz cache). Sama flaga soft delete nie wystarczy.
- Czy potrzebujesz przycisku przywróć i na jak długo? Jeśli cofnięcie ma znaczenie, ustal okno przywracania (7 dni, 30 dni, na zawsze) i co się dzieje po jego wygaśnięciu.
- Czy raportowanie potrzebuje starych danych po usunięciu? Niektóre zespoły chcą, żeby wykresy odzwierciedlały widok użytkownika dziś; inne potrzebują historycznych liczb dla finansów. Wybór zmienia znaczenie „aktywni użytkownicy” i „całkowity przychód”.
- Czy support może wyjaśnić, co się stało bez detektywistycznej pracy? Jeśli spodziewasz się zgłoszeń typu „mój projekt zniknął”, potrzebujesz śladu: kto usunął, kiedy i skąd, plus wystarczające dane do zbadania sprawy.
- Czy zespół potrafi utrzymać spójne zachowanie wszędzie? Soft delete wprowadza ukryte reguły: każde zapytanie musi filtrować usunięte rekordy, każdy join musi się zachowywać, a każdy ekran musi zgadzać się, co znaczy „usunięty”.
Prosty sanity-check: wybierz jedno realistyczne zdarzenie i przejdź je krok po kroku. Na przykład: ktoś omyłkowo usuwa workspace w piątek wieczorem. W poniedziałek support musi zobaczyć zdarzenie usunięcia, bezpiecznie je przywrócić i uniknąć przywracania powiązanych danych, które powinny pozostać usunięte. Jeśli budujesz aplikację na platformie takiej jak Koder.ai, zdefiniuj te reguły wczesnie, żeby wygenerowany backend i UI stosowały jedną politykę zamiast rozsypywać wyjątki w kodzie.
Następne kroki: wybierz politykę i zbuduj ją bezpiecznie
Wybierz podejście, zapisując prostą politykę, którą możesz udostępnić zespołowi i supportowi. Jeśli nie jest spisana, będzie dryfować, a użytkownicy poczują niespójność.
Zacznij od prostego zestawu reguł:
- Co jest soft-deleted (i jak długo pozostaje możliwe do przywrócenia)
- Co jest hard-deleted od razu (i dlaczego)
- Kiedy soft-deleted dane są purge'owane (np. po X dniach)
- Kto może przywracać i jaka dowód/proces zatwierdzenia jest wymagany
- Jak obsługiwane są żądania usunięcia z powodów prywatności end-to-end
Potem zbuduj dwie oddzielne ścieżki, które się nie mieszają: ścieżkę „admin restore” dla pomyłek i ścieżkę „privacy purge” dla prawdziwego usunięcia. Ścieżka przywracania powinna być odwracalna i logowana. Ścieżka purge powinna być ostateczna i usuwać lub anonimizować wszystkie powiązane dane identyfikujące osobę, łącznie z backupami lub eksportami, jeśli polityka tego wymaga.
Dodaj zabezpieczenia, by usunięte dane nie wróciły do produktu. Najprościej traktować „usunięte” jako pierwszy klasowy stan w testach. Dodaj checkpointy przeglądowe dla każdego nowego zapytania, strony listy, wyszukiwania, eksportu i pracy analitycznej. Dobra zasada: jeśli ekran pokazuje dane widoczne dla użytkownika, musi mieć explicite decyzję dotyczącą usuniętych rekordów (ukryj, pokaż z etykietą albo admin-only).
Jeśli jesteś na wczesnym etapie, prototypuj oba flowy zanim zamkniesz schemat. W Koder.ai możesz naszkicować politykę usuwania w trybie planowania, wygenerować podstawowe CRUD i szybko przetestować scenariusze przywracania i purge, a potem dopracować model danych zanim go zatwierdzisz.