Kiedy baza danych jest przeciążona, co psuje się najpierw
Gdy baza danych jest obciążona, użytkownicy rzadko widzą czysty komunikat "niedostępne". Zamiast tego widzą timeouty, strony ładujące się do połowy, przyciski kręcące się w nieskończoność i akcje, które czasem działają, a czasem zawodzą. Zapis może się powieść raz, a następnym razem wywalić "Coś poszło nie tak." Ta niepewność sprawia, że incydenty wydają się chaotyczne.
Pierwsze do zepsucia są zwykle ścieżki intensywnie zapisujące: edycje rekordów, procesy checkout, wysyłanie formularzy, aktualizacje w tle i wszystko, co wymaga transakcji i blokad. Pod obciążeniem zapisy stają się wolniejsze, blokują się wzajemnie i mogą też spowalniać odczyty przez trzymanie blokad i wymuszanie dodatkowej pracy.
Losowe błędy wydają się gorsze niż kontrolowane ograniczenie, bo użytkownicy nie wiedzą, co robić dalej. Ponawiają próby, odświeżają, klikają i zwiększają obciążenie. Liczba zgłoszeń do supportu rośnie, bo system "trochę działa", ale nikt mu nie ufa.
Celem trybu tylko do odczytu podczas incydentów nie jest perfekcja. Chodzi o to, by utrzymać najważniejsze funkcje użyteczne: przeglądanie kluczowych rekordów, wyszukiwanie, sprawdzanie statusu i pobieranie potrzebnych danych. Celowo zatrzymujesz lub opóźniasz ryzykowne akcje (zapisy), żeby baza mogła się odzyskać, a pozostałe odczyty pozostały responsywne.
Wyraźnie ustaw oczekiwania. To tymczasowe ograniczenie i nie oznacza, że dane są usuwane. W większości przypadków istniejące dane użytkownika są bezpieczne — system tylko wstrzymuje zmiany, aż baza znów będzie zdrowa.
Co właściwie oznacza tryb tylko do odczytu
Tryb tylko do odczytu podczas incydentów to tymczasowy stan, w którym produkt pozostaje użyteczny do przeglądania, ale odrzuca wszystko, co zmienia dane. Cel jest prosty: utrzymać usługę przydatną, chroniąc jednocześnie bazę przed dodatkową pracą.
Mówiąc prosto, ludzie nadal mogą wyszukiwać, ale nie mogą dokonywać zmian wywołujących zapisy. Zwykle oznacza to, że przeglądanie stron, wyszukiwanie, filtrowanie i otwieranie rekordów nadal działa. Zapisywanie formularzy, zmiana ustawień, publikowanie komentarzy, przesyłanie plików czy tworzenie kont są zablokowane.
Praktyczny sposób myślenia: jeśli akcja aktualizuje wiersz, tworzy wiersz, usuwa wiersz lub zapisuje do kolejki — nie jest dozwolona. Wiele zespołów blokuje też „ukryte zapisy” jak zdarzenia analityczne w głównej bazie, logi audytu zapisywane synchronicznie i znaczniki "ostatnio widziany".
Tryb tylko do odczytu to właściwy wybór, gdy odczyty nadal działają w większości, ale opóźnienia zapisów rosną, narasta kontencja blokad lub backlog prac zapisujących spowalnia wszystko.
Przejdź do pełnej niedostępności, gdy nawet podstawowe odczyty timeoutują, cache nie może obsłużyć niezbędnych danych lub system nie potrafi wiarygodnie powiedzieć użytkownikom, co jest bezpieczne do zrobienia.
Dlaczego to pomaga: zapisy często kosztują znacznie więcej niż proste odczyty. Zapis może wywołać indeksy, ograniczenia, blokady i kolejne zapytania. Blokując zapisy, zapobiegasz też efektowi powtórnych prób (retry storm), gdzie klienci ciągle ponawiają nieudane zapisy i mnożą szkody.
Przykład: podczas incydentu w CRM użytkownicy nadal mogą wyszukiwać konta, otwierać dane kontaktowe i przeglądać ostatnie transakcje, ale akcje Edytuj, Utwórz i Import są wyłączone, a każde żądanie zapisu jest natychmiast odrzucane czytelnym komunikatem.
Wybierz, które odczyty zachować, a które zapisy zatrzymać
Gdy przełączasz się w tryb tylko do odczytu podczas incydentów, celem nie jest "wszystko działa". Celem jest, by najważniejsze ekrany nadal się ładowały, podczas gdy wszystko, co generuje dodatkowe obciążenie bazy, zatrzymuje się szybko i bezpiecznie.
Zacznij od nazwania kilku akcji użytkownika, które muszą działać nawet w złe dni. Zwykle są to małe odczyty odblokowujące decyzje: przegląd najnowszego rekordu, sprawdzenie statusu, wyszukanie krótkiej listy lub pobranie już przygotowanego raportu.
Potem zdecyduj, co możesz wstrzymać bez poważnych szkód. Większość ścieżek zapisów to w incydencie „miłe do posiadania”: edycje, masowe aktualizacje, importy, komentarze, załączniki, zdarzenia analityczne i wszystko, co wywołuje dodatkowe zapytania.
Prosty sposób decyzji to podział akcji na trzy koszyki:
- Musi działać: małe, szybkie odczyty odblokowujące użytkowników teraz
- Można wstrzymać: zapisy i ciężkie odczyty, które dodają obciążenie lub blokują wiersze
- Może się pogorszyć: funkcje, które mogą pokazywać dane z cache lub widok częściowy
Ustal też horyzont czasowy. Jeśli spodziewasz się minut, możesz być surowy i zablokować prawie wszystkie zapisy. Jeśli spodziewasz się godzin, rozważ zezwolenie na bardzo ograniczony zestaw bezpiecznych zapisów (np. reset haseł lub krytyczne aktualizacje statusu) i kolejkowanie reszty.
Uzgodnij priorytet z wyprzedzeniem: bezpieczeństwo ponad kompletność. Lepiej pokazać wyraźny komunikat "zmiany są wstrzymane" niż dopuścić zapis, który wykona się częściowo i pozostawi dane niespójne.
Jak zdecydować, kiedy to włączyć
Przełączenie na tryb tylko do odczytu to kompromis: mniej funkcji teraz, ale używalny produkt i zdrowsza baza. Celem jest działanie, zanim użytkownicy wywołają spiralę ponowień, timeoutów i zablokowanych połączeń.
Obserwuj mały zestaw sygnałów, które potrafisz wyjaśnić w jednym zdaniu. Jeśli pojawią się dwa lub więcej jednocześnie, traktuj to jako wczesne ostrzeżenie:
- Żądania timeoutują lub przekraczają wyraźny próg latencji (np. p95 skacze z 300 ms do 3 s)
- CPU bazy danych utrzymuje się wysoko przez kilka minut, nie tylko jako krótki spike
- Wyczerpanie puli połączeń (żądania czekają, bo brak dostępnych połączeń)
- Logi wolnych zapytań nagle wypełnione tymi samymi kilkoma zapytaniami
- Wzrastający współczynnik błędów związanych z oczekiwaniem na blokady, deadlockami lub nieudanymi transakcjami
Same metryki nie powinny być jedynym wyzwalaczem. Dodaj decyzję ludzką: osoba na on-call ogłasza stan incydentu i włącza tryb tylko do odczytu. To zatrzymuje debaty pod presją i sprawia, że działanie jest audytowalne.
Ułatw zapamiętywanie i komunikację progów. „Zapisy są wstrzymane, bo baza jest przeciążona” jest jaśniejsze niż „osiągnęliśmy saturation.” Zdefiniuj też, kto może przełączać i gdzie to się kontroluje.
Unikaj fluktuacji między trybami. Dodaj prosty histerezy: po wejściu w tryb tylko do odczytu zostań w nim przez minimalne okno (np. 10–15 minut) i wróć dopiero gdy kluczowe sygnały będą normalne przez pewien czas. To zapobiega sytuacjom, gdy formularz działa przez minutę, a potem znów przestaje.
Krok po kroku: bezpieczne włączanie trybu tylko do odczytu
Traktuj tryb tylko do odczytu podczas incydentów jak kontrolowaną zmianę, nie panikę. Celem jest ochrona bazy przez zatrzymanie zapisów, przy jednoczesnym utrzymaniu najcenniejszych odczytów.
Bezpieczna sekwencja wdrożenia
Jeśli możesz, przygotuj ścieżkę kodową zanim przełączysz tryb. Wtedy włączenie trybu to tylko toggle, a nie zmiana na żywo.
- Stwórz jeden przełącznik incydentu (feature flag lub ustawienie konfiguracyjne), z którego czyta cały system. Trzymaj go globalnie i nudno:
READ_ONLY=true. Unikaj wielu flag, które mogą się rozjechać.
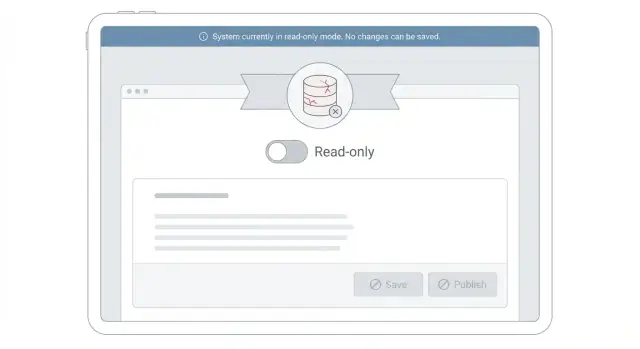
- Zaktualizuj UI, by zapobiegać próbom zapisu. Wyłącz przyciski Zapisz, ukryj formularze edycji i zamień pola wejściowe na zwykły tekst. Wciąż pokazuj dane, żeby ludzie mogli pracować (przeglądać, wyszukiwać, eksportować).
- Egzekwuj to po stronie serwera, nie tylko w UI. Blokuj zapisy w jednym miejscu (middleware, strażnik w kontrolerze lub warstwa serwisowa), tak aby każdy klient był objęty — aplikacje mobilne, użytkownicy API i automatyzacje.
- Zwracaj jasny, spójny błąd dla zablokowanych zapisów. Użyj dedykowanego kodu statusu i komunikatu typu: "Edycja jest tymczasowo wyłączona, gdy stabilizujemy system. Twoje dane są bezpieczne. Spróbuj później." Nie zwracaj ogólnego 500, który wygląda jak utrata danych.
- Loguj każdą próbę zapisu. Zarejestruj użytkownika, endpoint i typ akcji. Trzymaj minimalny ładunek, by nie umieszczać w logach wrażliwych danych. Te logi pomogą naprawić luki UX i odtworzyć krytyczne akcje później, jeśli potrzeba.
Jeden drobny szczegół, który zapobiega powtórnym incydentom
Gdy tryb tylko do odczytu jest aktywny, odrzucaj żądania szybko, zanim dotrą do bazy. Nie uruchamiaj zapytań walidujących, a potem blokuj zapis. Najszybsze zablokowane żądanie to takie, które nigdy nie dotyka przeciążonej bazy.
Komunikacja w UI, która redukuje nieporozumienia i zgłoszenia
Zrób jeden globalny przełącznik
Uruchom aplikację w Go i PostgreSQL i dodaj jeden globalny przełącznik READ_ONLY.
Gdy włączysz tryb tylko do odczytu, UI staje się częścią rozwiązania. Jeśli ludzie ciągle klikają Zapisz i dostają niejasne błędy, będą ponawiać próby, odświeżać i otwierać zgłoszenia. Jasne komunikaty zmniejszają obciążenie i frustrację.
Dobrym wzorcem jest widoczny, trwały baner na górze aplikacji. Krótki i rzeczowy: co się dzieje, czego się spodziewać i co użytkownicy mogą teraz robić. Nie ukrywaj go w znikającym toastrze.
Powiedz, co działa, co jest wstrzymane i co dalej
Użytkownicy głównie chcą wiedzieć, czy mogą pracować. Wytłumacz to prostym językiem. Dla większości produktów oznacza to:
- Działa nadal: przeglądanie rekordów, wyszukiwanie, pobieranie, odczyt dashboardów
- Wstrzymane: tworzenie, edycja, usuwanie, przesyłanie plików, płatności, wysyłanie wiadomości
- Zrób zamiast tego: skopiuj kluczowe informacje, eksportuj widok, spróbuj ponownie później
- Aktualizacje: "Opublikujemy aktualizację tutaj za 15 minut."
Prosty etykietka statusu też pomaga zrozumieć postęp bez zgadywania. "Investigating" (badamy) oznacza, że wciąż szukacie przyczyny. "Stabilizing" (stabilizujemy) oznacza, że redukujecie obciążenie i chronicie dane. "Recovering" (odtwarzanie) oznacza, że zapisy wrócą wkrótce, ale mogą być wolne.
Zachowaj spokojny i konkretny ton
Unikaj oskarżających lub niejasnych tekstów jak "Coś poszło nie tak" albo "Nie masz uprawnień." Jeśli przycisk jest zablokowany, opisz to: "Edycja jest tymczasowo wstrzymana, gdy stabilizujemy system."
Mały przykład: w CRM zachowaj czytelne strony kontaktów i transakcji, ale wyłącz Edytuj, Dodaj notatkę i Nowa transakcja. Jeśli ktoś spróbuje mimo to, pokaż krótki dialog: "Zmiany są teraz wstrzymane. Możesz skopiować ten rekord lub wyeksportować listę, a potem spróbować ponownie."
Zachowaj kluczowe odczyty, nie zwiększając obciążenia
Przełączając się w tryb tylko do odczytu, celem nie jest "wyświetlić wszystko." To „zachować kilka stron, na których ludzie polegają," bez dokładaania kolejnego obciążenia do przeciążonej bazy.
Zacznij od przycięcia najcięższych ekranów. Długie tabele z wieloma filtrami, wyszukiwanie pełnotekstowe po wielu polach i zaawansowane sortowania często wywołują wolne zapytania. W trybie tylko do odczytu uprość te ekrany: mniej opcji filtrowania, bezpieczny domyślny sort i ograniczony zakres dat.
Preferuj cache lub prekomputowane widoki dla najważniejszych stron. Proste "podsumowanie konta" czytające z cache lub tabeli podsumowującej jest zwykle bezpieczniejsze niż ładowanie surowych logów zdarzeń czy łączenie wielu tabel.
Praktyczne sposoby utrzymania odczytów bez pogarszania obciążenia:
- Używaj mniejszych rozmiarów stron i usuń opcję "pokaż wszystko"
- Zastąp złożone sortowania domyślnym porządkiem (np. "najpierw najnowsze")
- Odkładaj nieistotne odczyty jak analityka, rekomendacje i wykresy aktywności
- Preferuj zcache'owane podsumowania zamiast pełnych historii
- Pozwól na lekko nieświeże dane, jeśli to utrzyma responsywność kluczowych stron
Konkret: w incydencie CRM zachowaj widok kontaktu, status transakcji i ostatnią notatkę. Tymczasowo ukryj Zaawansowane wyszukiwanie, wykres przychodów i pełną oś czasu e-maili, oraz poinformuj, że dane mogą być kilka minut opóźnione.
Co robić z zadaniami, webhookami i integracjami
Przećwicz przełącznik na stagingu
Zamień swój plan awaryjny w działający przepływ aplikacji, który możesz testować w dowolnym momencie.
Największym zaskoczeniem przy włączaniu trybu tylko do odczytu bywają niewidoczne zapisy: zadania w tle, zaplanowane synchronizacje, masowe akcje administracyjne i zewnętrzne integracje, które ciągle biją w bazę.
Zacznij od zatrzymania prac tła, które tworzą lub aktualizują rekordy. Typowi sprawcy to importy, synchronizacje nocne, wysyłka maili zapisująca logi doręczeń, rollupy analityczne i pętle ponowień próbujące stale ten sam nieudany update. Wstrzymanie ich szybko redukuje obciążenie i zapobiega drugiej fali.
Domyślnie wstrzymaj lub ogranicz zadania ciężko zapisujące i konsumentów kolejek, którzy persistują wyniki, wyłącz masowe akcje administracyjne (masowe aktualizacje, usuwania, duże reindeksy) i szybko odrzucaj żądania zapisu z jasną tymczasową odpowiedzią zamiast timeoutu.
W przypadku webhooków i integracji jasność jest ważniejsza niż optymizm. Jeśli zaakceptujesz webhook, ale nie możesz go przetworzyć, stworzysz niespójności i mnóstwo zgłoszeń. Gdy zapisy są wstrzymane, zwróć tymczasową porażkę, która każe nadawcy spróbować później, i upewnij się, że komunikat w UI odzwierciedla to, co dzieje się w tle.
Uważaj z „odkładaniem do kolejki na później”. Brzmi pomocnie, ale może stworzyć backlog, który zaleje system, gdy tylko zezwolisz z powrotem na zapisy. Kolejkuj zapisy użytkownika tylko jeśli możesz zagwarantować idempotencję, ograniczyć rozmiar kolejki i pokazać użytkownikowi prawdziwy stan (w toku vs zapisane).
Na koniec, przeaudytuj ukrytych masowych piszących w swoim produkcie. Jeśli automatyzacja może zaktualizować tysiące wierszy, powinna być wymuszona do wyłączenia w trybie tylko do odczytu, nawet jeśli reszta aplikacji nadal się ładuje.
Typowe błędy, które pogarszają incydenty
Najszybszy sposób, by pogorszyć incydent, to traktować tryb tylko do odczytu jako kosmetyczną zmianę. Jeśli tylko wyłączysz przyciski w UI, ludzie nadal zapiszą przez API, stare karty, aplikacje mobilne i zadania w tle. Baza dalej będzie pod presją, a zaufanie spadnie, bo użytkownicy zobaczą "zapisano" tu, a brak zmian tam.
Prawdziwy tryb tylko do odczytu wymaga jednej jasnej zasady: serwer odrzuca zapisy za każdym razem, dla każdego klienta.
Błędy, na które trzeba uważać
Te wzorce często pojawiają się przy przeciążeniu bazy:
- Blokowanie edycji tylko w UI, podczas gdy backend nadal akceptuje POST, PUT, PATCH i DELETE
- Zapominanie o ukrytych ścieżkach: panele admina, narzędzia wewnętrzne, endpointy importu i publiczne API używane przez integracje
- Pozwalanie systemowi na fluktuacje między normalnym a trybem tylko do odczytu co minutę
- Pokazywanie niejasnych komunikatów jak "Coś poszło nie tak"
- Zezwalanie na częściowe zapisy, które pozostawiają dane niespójne
Jak ich unikać
Spraw, by system zachowywał się przewidywalnie. Wymuś jeden przełącznik po stronie serwera, który odrzuca zapisy z jasną odpowiedzią. Dodaj cooldown, żeby po wejściu w tryb tylko do odczytu zostać w nim przez określony czas (np. 10–15 minut), chyba że operator zrobi inaczej.
Bądź rygorystyczny względem integralności danych. Jeśli zapis nie może się w pełni zakończyć, przerwij całą operację i powiedz użytkownikowi, co robić dalej. Prosty komunikat jak "Tryb tylko do odczytu: przegląd działa, zmiany są wstrzymane. Spróbuj później." zmniejsza ponowne próby.
Szybkie kontrole przed i w trakcie incydentu
Tryb tylko do odczytu pomaga tylko wtedy, gdy można go łatwo włączyć i zachowuje się tak samo wszędzie. Przed problemami upewnij się, że istnieje jeden toggle (feature flag, config, przełącznik admina), który on-call może aktywować w kilka sekund, bez wdrożenia.
Gdy podejrzewasz przeciążenie bazy, wykonaj szybką kontrolę, która potwierdzi podstawy:
- Przełącz toggle w bezpiecznym środowisku i potwierdź, że działa natychmiast
- Wywołaj kilka akcji zapisujących (zapisz, usuń, import) i potwierdź, że każdy endpoint zwraca tę samą zablokowaną odpowiedź i kod statusu
- Sprawdź, czy tekst banera jest gotowy, krótki i widoczny na najważniejszych ekranach
- Załaduj swoje top 3 strony (np. logowanie, dashboard, widok rekordu) i potwierdź, że renderują się pod obciążeniem
- Upewnij się, że support ma jednozdaniowy skrypt wyjaśniający, co działa, co jest wstrzymane i gdzie szukać aktualizacji
W trakcie incydentu trzymaj jedną osobę skupioną na weryfikacji doświadczenia użytkownika, nie tylko na dashboardach. Szybkie sprawdzenie w trybie incognito wyłapie problemy jak ukryte banery, zepsute formularze czy nieskończone spinnery, które generują dodatkowy ruch odświeżania.
Zaplanuj wyjście zanim włączysz tryb. Zdecyduj, co oznacza "zdrowe" (latencja, współczynnik błędów, opóźnienie replikacji) i wykonaj krótką weryfikację po przywróceniu: utwórz testowy rekord, edytuj go i potwierdź, że liczniki i ostatnia aktywność wyglądają poprawnie.
Przykład incydentu: utrzymaj CRM używalny, blokując edycje
Posiadaj wdrożenie
Zachowaj pełną kontrolę, eksportując kod źródłowy po wygenerowaniu zabezpieczeń incydentowych.
Jest 10:20. Twój CRM jest wolny, a CPU bazy jest maksymalnie obciążone. Zaczynają przychodzić zgłoszenia: użytkownicy nie mogą zapisać edycji kontaktów i transakcji. Zespół nadal jednak potrzebuje wyszukać numery telefonów, zobaczyć etapy transakcji i przeczytać ostatnie notatki przed rozmowami.
Wybierasz prostą zasadę: zamrozić wszystko, co zapisuje, zachować najcenniejsze odczyty. W praktyce funkcje wyszukiwania kontaktów, szczegóły kontaktu i widok lejka transakcji pozostają aktywne. Edycja kontaktu, tworzenie nowej transakcji, dodawanie notatek i masowe importy są zablokowane.
W UI zmiana powinna być oczywista i spokojna. Na ekranach edycji przycisk Zapisz jest nieaktywny, a formularz pozostaje widoczny, żeby ludzie mogli skopiować wpisane treści. Baner na górze mówi: "Tryb tylko do odczytu jest włączony z powodu dużego obciążenia. Przeglądanie dostępne. Zmiany są wstrzymane. Proszę spróbować później." Jeśli użytkownik mimo to wywoła zapis (np. przez API), zwróć czytelny komunikat i unikaj automatycznych ponowień, które uderzą w bazę.
Operacyjnie zachowaj flow krótkim i powtarzalnym. Włącz tryb tylko do odczytu i zweryfikuj, że wszystkie endpointy zapisujące go respektują. Wstrzymaj zadania tła, które zapisują (synci, importy, logowanie emaili, backfille analityczne). Ogranicz lub wstrzymaj webhooki i integracje, które tworzą aktualizacje. Monitoruj obciążenie bazy, wskaźniki błędów i wolne zapytania. Opublikuj status z informacją, co jest dotknięte (edycje) i co działa (wyszukiwanie i widoki).
Odzyskiwanie to nie tylko powrót przełącznika. Włączaj zapisy stopniowo, sprawdzaj logi błędów dotyczące nieudanych zapisów i obserwuj falę zapisów z kolejek. Następnie jasno zakomunikuj: "Tryb tylko do odczytu wyłączony. Zapisy przywrócone. Jeśli próbowałeś zapisać między 10:20 a 10:55, sprawdź swoje ostatnie zmiany."
Następne kroki: włącz tryb tylko do odczytu do playbooka
Tryb tylko do odczytu podczas incydentów działa najlepiej, gdy jest nudny i powtarzalny. Celem jest wykonywanie krótkiego skryptu z jasnymi właścicielami i kontrolami.
Zbuduj mały, użyteczny playbook
Trzymaj go na jednej stronie. Zawrzyj wyzwalacze (kilka sygnałów uzasadniających przełączenie), dokładny przełącznik, który klikasz i jak potwierdzasz, że zapisy są zablokowane, krótką listę kluczowych odczytów, które muszą działać, jasne role (kto przełącza, kto obserwuje metryki, kto obsługuje support) oraz kryteria wyjścia (co musi być prawdą zanim przywrócisz zapisy i jak opróżnisz backlogi).
Przygotuj teksty do UI zanim będą potrzebne
Napisz i zaakceptuj tekst teraz, żeby nie kłócić się o słowa podczas awarii. Zwykły zestaw obejmuje:
- Baner: "Jesteśmy w trybie tylko do odczytu, przywracamy wydajność. Możesz przeglądać dane, ale zmiany są tymczasowo wyłączone."
- Przy zablokowanych akcjach: "Zapisywanie jest teraz wstrzymane. Twoje zmiany nie zostały zastosowane. Spróbuj ponownie za kilka minut."
- Szczegóły statusu: "Ostatnia aktualizacja o HH:MM. Następna aktualizacja za 10 minut."
Przećwicz przełącznik na stagingu i zmierz czas. Upewnij się, że support i on-call szybko znajdą toggle i że logi wyraźnie pokazują zablokowane zapisy. Po każdym incydencie przejrzyj, które odczyty były naprawdę krytyczne, które były "miłe do posiadania", a które przypadkowo generowały obciążenie, i zaktualizuj checklistę.
Jeśli budujesz produkty na Koder.ai (koder.ai), warto traktować tryb tylko do odczytu jako natywny przełącznik w generowanej aplikacji, tak aby UI i serwerowe straże zapisów były spójne w najważniejszych momentach.