16 sty 2026·7 min
Przepływy pracy skoncentrowane na dokumencie: model danych i wzorce UI
Przepływy pracy skoncentrowane na dokumencie — praktyczne modele danych i wzorce UI dla wersji, podglądów, metadanych i jasnych stanów statusu.
Przepływy pracy skoncentrowane na dokumencie — praktyczne modele danych i wzorce UI dla wersji, podglądów, metadanych i jasnych stanów statusu.
Aplikacja jest skoncentrowana na dokumencie, gdy sam dokument jest produktem, który użytkownicy tworzą, przeglądają i na którym polegają. Doświadczenie jest zbudowane wokół plików takich jak PDF-y, obrazy, skany i paragony, a nie formularza, gdzie plik jest tylko załącznikiem.
W przepływach zorientowanych na dokument ludzie wykonują faktyczną pracę wewnątrz dokumentu: otwierają go, sprawdzają, co się zmieniło, dodają kontekst i decydują, co dalej. Jeśli dokumentowi nie można zaufać, aplikacja przestaje być użyteczna.
Większość aplikacji skoncentrowanych na dokumencie potrzebuje kilku podstawowych ekranów na start:
Problemy pojawiają się szybko. Użytkownicy przesyłają ten sam paragon dwa razy. Ktoś edytuje PDF i ponownie go wrzuca bez wyjaśnienia. Skany nie mają daty, sprzedawcy ani właściciela. Po tygodniach nikt nie wie, która wersja została zatwierdzona ani na jakiej podstawie podjęto decyzję.
Dobra aplikacja dokumentowa wydaje się szybka i niezawodna. Użytkownicy powinni móc odpowiedzieć na te pytania w kilka sekund:
Ta jasność pochodzi z definicji. Zanim zbudujesz ekrany, ustal, co w twojej aplikacji oznacza „wersja”, „podgląd”, „metadane” i „status”. Jeśli te terminy będą nieostre, pojawią się duplikaty, myląca historia i przepływy przeglądu nieodzwierciedlające rzeczywistej pracy.
UI często wygląda prosto (lista, viewer, kilka przycisków), ale to model danych unosi ciężar. Jeśli podstawowe obiekty będą poprawne, historia audytu, szybkie podglądy i niezawodne zatwierdzenia staną się dużo prostsze.
Zacznij od oddzielenia „rekordu dokumentu” od „zawartości pliku”. Rekord to to, o czym mówią użytkownicy (Faktura od ACME, paragon taxi). Zawartość to bajty (PDF, JPG), które można wymienić, ponownie przetworzyć lub przenieść bez zmiany znaczenia dokumentu w aplikacji.
Praktyczny zestaw obiektów do wymodelowania:
Zdecyduj, co dostaje identyfikator, który nigdy się nie zmienia. Użyteczna zasada: Document ID żyje wiecznie, podczas gdy Files i Previews można regenerować. Wersje także potrzebują stabilnych ID, bo ludzie będą odwoływać się do „jak to wyglądało wczoraj” i potrzebujesz śladu audytu.
Modeluj relacje explicite. Document ma wiele Versions. Każda Version może mieć wiele Previews (różne rozmiary lub formaty). To utrzymuje ekrany list szybkie, bo ładują lekkie dane podglądu, a ekrany ze szczegółami ładują pełny plik tylko gdy potrzeba.
Przykład: użytkownik przesyła pogniecioną fotografię paragonu. Tworzysz Document, zapisujesz oryginalny File, generujesz miniaturę Preview i tworzysz Wersję 1. Później użytkownik przesyła czytelniejszy skan. To staje się Wersją 2, bez łamania komentarzy, zatwierdzeń czy wyszukiwania powiązanego z Document.
Ludzie oczekują, że dokument będzie się zmieniał w czasie, ale nie „zamieni się” w inny element. Najprostszy sposób, by to osiągnąć, to oddzielić tożsamość (Document) od zawartości (Version i Files).
Zacznij od stabilnego document_id, który nigdy się nie zmienia. Nawet jeśli użytkownik ponownie wrzuci ten sam PDF, zastąpi rozmazane zdjęcie lub prześle poprawiony skan, powinien to nadal być ten sam rekord dokumentu. Komentarze, przypisania i logi audytu dołączają się czysto do jednego trwałego ID.
Traktuj każdą znaczącą zmianę jako nowy wiersz version. Każda wersja powinna zawierać kto ją stworzył i kiedy, plus wskaźniki przechowywania (klucz pliku, suma kontrolna, rozmiar, liczba stron) oraz pochodne artefakty (tekst OCR, obrazy podglądu) przypisane do dokładnie tego pliku. Unikaj „edytowania w miejscu”. Wygląda to prostszo na początku, ale psuje śledzenie zmian i utrudnia naprawę błędów.
Dla szybkich odczytów trzymaj current_version_id na dokumencie. Większość ekranów potrzebuje tylko „najświeższej”, więc nie musisz sortować wersji przy każdym ładowaniu. Gdy potrzebna jest historia, ładuj wersje osobno i pokazuj przejrzystą oś czasu.
Rollbacky to po prostu zmiana wskaźnika. Zamiast cokolwiek usuwać, ustaw current_version_id z powrotem na starszą wersję. To szybkie, bezpieczne i zachowuje ślad audytu.
Aby historia była zrozumiała, zapisuj powód istnienia każdej wersji. Małe, spójne pole reason (plus opcjonalna notatka) zapobiega osi czasu pełnej tajemniczych aktualizacji. Typowe powody to zastąpienie uploadem, oczyszczenie skanu, korekta OCR, redakcja i edycja po zatwierdzeniu.
Przykład: zespół finansowy przesyła zdjęcie paragonu, zastępuje je czyściejszym skanem, a potem poprawia OCR, by kwota była czytelna. Każdy krok to nowa wersja, ale dokument pozostaje jednym elementem w skrzynce. Jeśli poprawka OCR była błędna, rollback to jeden klik, bo zmieniasz tylko current_version_id.
W przepływach zorientowanych na dokument podgląd to często główna rzecz, z którą użytkownicy wchodzą w interakcję. Jeśli podglądy są powolne lub zawodzą, cała aplikacja wydaje się zepsuta.
Traktuj generowanie podglądów jako osobne zadanie, a nie coś, co ekran uploadu powinien czekać. Najpierw zapisz oryginalny plik, oddaj kontrolę użytkownikowi, a potem generuj podglądy w tle. To utrzymuje responsywność UI i pozwala na bezpieczne ponawianie prób.
Przechowuj kilka rozmiarów podglądu. Jeden rozmiar nigdy nie pasuje do wszystkich ekranów: miniatura do list, średni obraz do widoków dzielonych i pełnostronicowe obrazy do szczegółowego przeglądu (strona po stronie dla PDF-ów).
Śledź stan podglądu explicite, żeby UI zawsze wiedział, co pokazać: pending, ready, failed, needs_retry. Etykiety w UI powinny być przyjazne, ale stany w danych muszą być jednoznaczne.
Aby utrzymać szybkie renderowanie, cachuj wartości pochodne razem z rekordem podglądu zamiast przeliczać je przy każdym widoku. Typowe pola to liczba stron, szerokość i wysokość podglądu, rotacja (0/90/180/270) i opcjonalne „najlepsza strona do miniatury”.
Projektuj z myślą o wolnych i problematycznych plikach. 200-stronicowy zeskanowany PDF czy pognieciony paragon może zająć czas. Używaj ładowania progresywnego: pokaż pierwszą gotową stronę jak tylko powstanie, a potem dopełniaj resztę.
Przykład: użytkownik przesyła 30 zdjęć paragonów. Widok listy pokazuje miniatury jako „pending”, a potem każda karta przełącza się na „ready” gdy jej podgląd się skończy. Jeśli kilka się nie uda z powodu uszkodzonego obrazu, pozostają widoczne z jasną akcją retry zamiast znikać czy blokować cały batch.
Metadane zamieniają stertę plików w coś, co można przeszukiwać, sortować, przeglądać i zatwierdzać. Pomagają ludziom szybko odpowiedzieć na proste pytania: Co to jest? Od kogo to pochodzi? Czy to jest ważne? Co powinno się dalej stać?
Praktyczny sposób utrzymania porządku w metadanych to podział według źródła:
Te koszyki zapobiegają późniejszym sporom. Jeśli kwota jest błędna, widać czy pochodziła z OCR czy z ręcznej poprawki.
Dla paragonów i faktur mały zestaw pól daje dużo korzyści, jeśli stosujesz je konsekwentnie (te same nazwy, te same formaty). Typowe pola kotwiczące to sprzedawca, data, suma, waluta i numer_dokumentu. Trzymaj je opcjonalne na start — ludzie przesyłają częściowe skany i rozmazane zdjęcia, a blokowanie pracy z powodu brakującego pola spowalnia cały workflow.
Traktuj nieznane wartości jako pierwszorzędne. Używaj stanów explicite jak null/unknown oraz powodu (brakująca strona, nieczytelne, nie dotyczy). To pozwala dokumentowi iść dalej, a przeglądającym pokazywać, co wymaga uwagi.
Również przechowuj prowieniencję i pewność dla wyodrębnionych pól. Źródło może być user, OCR, import lub API. Pewność może być wartością 0–1 lub zbiorem jak high/medium/low. Jeśli OCR odczytuje „$18.70” z niską pewnością, bo ostatnia cyfra jest rozmazana, UI może to podświetlić i poprosić o szybką weryfikację.
Dokumenty wielostronicowe wymagają dodatkowej decyzji: co należy do całego dokumentu, a co do pojedynczej strony. Sumy i sprzedawca zwykle należą do dokumentu. Notatki na stronie, redakcje, rotacja i klasyfikacja per-strona należą do poziomu strony.
Status odpowiada na jedno pytanie: „Gdzie jest ten dokument w procesie?” Trzymaj go małego i nudnego. Jeśli dodasz nowy status za każdym razem, gdy ktoś poprosi, dostaniesz filtry, którym nikt nie ufa.
Praktyczny zestaw statusów biznesowych, które mapują rzeczywiste decyzje:
Trzymaj „processing” poza biznesowym statusem. OCR i generowanie podglądu opisują, co system robi, a nie co człowiek powinien zrobić dalej. Przechowuj je jako oddzielne stany przetwarzania.
Oddziel też przypisanie od statusu (assignee_id, team_id, due_date). Dokument może być Approved, a mimo to przypisany do follow-upu, albo Needs review bez przypisanego właściciela.
Zapisuj historię statusów, nie tylko bieżącą wartość. Prosty log (from_status, to_status, changed_at, changed_by, reason) zwróci się, gdy ktoś zapyta: „Kto odrzucił ten paragon i dlaczego?”
Na koniec, zdecyduj, jakie akcje są dozwolone w każdym statusie. Trzymaj reguły proste: Imported może przejść do Needs review; Approved jest tylko do odczytu chyba że utworzysz nową wersję; Rejected można ponownie otworzyć, ale musi zachować wcześniejszy powód.
Większość czasu użytkownicy skanują listę, otwierają jeden element, poprawiają kilka pól i idą dalej. Dobre UI sprawia, że te kroki są szybkie i przewidywalne.
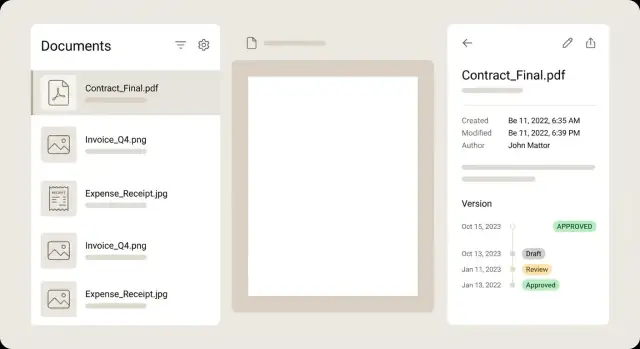
Dla listy dokumentów traktuj każdy wiersz jak podsumowanie, by użytkownicy mogli zdecydować bez otwierania każdego pliku. Silny wiersz pokazuje małą miniaturę, jasny tytuł, kilka kluczowych pól (sprzedawca, data, suma), odznakę statusu i subtelne ostrzeżenie, gdy coś wymaga uwagi.
Trzymaj widok szczegółów spokojny i łatwy do przeskanowania. Popularny układ to podgląd po lewej i metadane po prawej, z kontrolkami edycji obok każdego pola. Użytkownicy powinni móc przybliżać, obracać i przewijać strony bez utraty miejsca w formularzu. Jeśli pole pochodzi z OCR, pokaż małą wskazówkę o pewności i najlepiej podświetl obszar źródłowy na podglądzie, gdy pole jest skupione.
Wersje najlepiej prezentować jako oś czasu, nie dropdown. Pokaż kto co zmienił i kiedy, i pozwól otworzyć każdą przeszłą wersję w trybie tylko do odczytu. Jeśli oferujesz porównanie, skup się na różnicach metadanych (kwota zmieniona, sprzedawca poprawiony) zamiast wymuszać piksel-po-piksel porównanie PDF.
Tryb przeglądu powinien optymalizować szybkość. Najczęściej wystarcza klawiaturowy przepływ triage: szybkie akcje zatwierdź/odrzuć, szybkie poprawki dla typowych pól i krótkie pole na komentarz przy odrzuceniu.
Stany puste mają znaczenie, bo dokumenty często są w trakcie przetwarzania. Zamiast pustego pola wyjaśnij, co się dzieje: „Generowany podgląd”, „OCR w toku” lub „Ten typ pliku nie ma jeszcze podglądu”.
Prosty przepływ musi brzmieć jak „wrzuć, sprawdź, zatwierdź”. Pod spodem najlepiej działa, gdy oddzielisz plik (wersje i podglądy) od znaczenia biznesowego (metadane i status).
Użytkownik przesyła PDF, zdjęcie lub skan paragonu i natychmiast widzi go na liście w skrzynce. Nie czekaj na zakończenie przetwarzania. Pokaż nazwę pliku, czas uploadu i wyraźną odznakę jak „Processing”. Jeśli już znasz źródło (import e‑mail, aparat mobilny, drag-and-drop), pokaż to również.
Przy uploadzie utwórz rekord Document (obiekt długowieczny) i rekord Version (konkretny plik). Ustaw current_version_id na nową wersję. Zapisz preview_state = pending i extraction_state = pending, by UI mógł uczciwie pokazać, co jest gotowe.
Widok szczegółów powinien otworzyć się od razu, ale pokazywać zastępczy viewer i jasny komunikat „Przygotowywanie podglądu” zamiast zepsutej ramki.
Zadanie w tle tworzy miniatury i podgląd (obrazy stron dla PDF-ów, zmniejszone obrazy dla zdjęć). Inne zadanie wyodrębnia metadane (sprzedawca, data, suma, waluta, typ dokumentu). Gdy każde zadanie się zakończy, aktualizuj tylko jego stan i znaczniki czasu, aby można było powtarzać nieudane próby bez ruszania reszty.
Trzymaj UI kompaktowy: pokaż stan podglądu, stan danych i podświetl pola o niskiej pewności.
Gdy podgląd jest gotowy, recenzenci poprawiają pola, dodają notatki i przesuwają dokument przez statusy biznesowe jak Imported -> Needs review -> Approved (lub Rejected). Loguj kto co i kiedy zmienił.
Jeśli recenzent wrzuca poprawiony plik, staje się on nową Version i dokument automatycznie wraca do Needs review.
Eksporty, synchronizacja księgowa lub raporty wewnętrzne powinny odczytywać z current_version_id i zatwierdzonego snapshotu metadanych, a nie „najnowszej ekstrakcji”. To zapobiega sytuacji, w której półprzetworzony re-upload zmienia liczby.
Przepływy pracy skoncentrowane na dokumentach zawodzą z nudnych powodów: wczesne skróty zamieniają się w codzienne problemy, gdy ludzie przesyłają duplikaty, poprawiają błędy lub pytają „kto to zmienił i kiedy?”.
Traktowanie nazwy pliku jako tożsamości dokumentu to klasyczny błąd. Nazwy się zmieniają, użytkownicy przesyłają ponownie, a aparaty generują duplikaty typu IMG_0001. Nadaj każdemu dokumentowi stabilne ID i traktuj nazwę pliku jako etykietę.
Nadpisywanie oryginalnego pliku przy przesłaniu zamiennika też powoduje problemy. Wygląda prościej, ale tracisz ślad audytu i nie możesz odpowiedzieć na podstawowe pytania później (co było zatwierdzone, co edytowano, co wysłano). Trzymaj binarny plik niemutowalny i dodaj nowy rekord wersji.
Zamieszanie statusów tworzy subtelne błędy. „OCR w toku” to nie to samo co „Needs review”. Stany przetwarzania opisują, co system robi; status biznesowy opisuje, co powinien zrobić człowiek. Gdy je pomieszasz, dokumenty utkną w złej kategorii.
Decyzje UI też mogą tworzyć tarcie. Jeśli blokujesz ekran aż do wygenerowania podglądów, użytkownicy odczują aplikację jako wolną nawet gdy upload się powiódł. Pokaż dokument od razu z jasnym zastępczym widokiem, potem podmieniaj miniatury gdy będą gotowe.
Na końcu, metadane tracą zaufanie, gdy zapisujesz wartości bez informacji o pochodzeniu. Jeśli suma pochodzi z OCR, powiedz to. Trzymaj znaczniki czasu.
Krótka lista kontrolna:
Przykład: w aplikacji do paragonów użytkownik przesyła czytelniejsze zdjęcie. Jeśli wersjonujesz, zachowaj stary obraz, oznacz OCR do ponownego przetworzenia i utrzymaj Needs review aż człowiek potwierdzi kwotę.
Przepływy zorientowane na dokumenty wydają się „dokończone” dopiero wtedy, gdy ludzie mogą zaufać temu, co widzą, i odzyskać stan gdy coś pójdzie nie tak. Przed uruchomieniem testuj z bałaganiarskimi, realnymi dokumentami (rozmazane paragony, obrócone PDF-y, powtórne uploady).
Pięć kontroli, które łapią większość niespodzianek:
Szybki test rzeczywistości: poproś kogoś, aby przejrzał trzy podobne paragony i celowo zrobił jedną złą zmianę. Jeśli potrafi rozpoznać bieżącą wersję, zrozumieć status i naprawić błąd w mniej niż minutę, jesteś blisko.
Miesięczne zwroty kosztów na podstawie paragonów to jasny przykład pracy skoncentrowanej na dokumencie. Pracownik przesyła paragony, potem dwóch recenzentów sprawdza: menedżer, potem dział księgowości. Paragon jest produktem, więc twoja aplikacja zależy od wersjonowania, podglądów, metadanych i jasnych statusów.
Jamie przesyła zdjęcie paragonu taxi. System tworzy Document #1842 z Version v1 (oryginalny plik), miniaturą i podglądem oraz metadanymi jak merchant, date, currency, total i score pewności OCR. Dokument zaczyna w Imported, potem przechodzi do Needs review gdy podgląd i ekstrakcja są gotowe.
Później Jamie przypadkowo przesyła ten sam paragon jeszcze raz. Sprawdzenie duplikatów (hash pliku plus podobny merchant/date/total) może podpowiedzieć prosty wybór: „Wygląda jak duplikat #1842. Dołączyć mimo to czy odrzucić?” Jeśli dołączy, zapisz to jako kolejny File powiązany z tym samym Document, żeby zachować jeden wątek przeglądu i jeden status.
Podczas przeglądu menedżer widzi podgląd, kluczowe pola i ostrzeżenia. OCR odgadł sumę jako $18.00, ale obraz wyraźnie pokazuje $13.00. Jamie poprawia kwotę. Nie nadpisuj historii. Stwórz Version v2 z poprawionymi polami, zachowaj v1 bez zmian i zapisz „Total corrected by Jamie.”
Jeśli chcesz szybko zbudować taki przepływ, Koder.ai (koder.ai) może pomóc wygenerować pierwszą wersję aplikacji z planu w czacie, ale ta sama zasada: najpierw zdefiniuj obiekty i stany, potem pozwól ekranom podążać za nimi.
Praktyczne następne kroki:
Aplikacja skoncentrowana na dokumencie traktuje dokument jako główny obiekt pracy, a nie jako dodatek. Użytkownicy muszą móc go otworzyć, zaufać temu, co widzą, zrozumieć, co się zmieniło, i na tej podstawie zdecydować, co dalej.
Zacznij od skrzynki odbiorczej/listy, widoku szczegółów dokumentu z szybkim podglądem, prostej sekcji akcji przeglądu (zatwierdź/odrzuć/zaproś do zmian) oraz sposobu eksportu lub udostępnienia. Te cztery ekrany obsługują najczęstsze czynności: znajdź, otwórz, zdecyduj i przekaż dalej.
Modeluj trwały rekord Document, który nigdy się nie zmienia, a rzeczywiste bajty pliku trzymaj jako osobne obiekty File. Dodaj Version jako migawkę łączącą dokument z konkretnym plikiem i jego pochodnymi. To rozdzielenie pozwala zachować komentarze, przypisania i historię nawet gdy plik zostanie wymieniony.
Każdą istotną zmianę traktuj jako nową wersję zamiast edytować w miejscu. Trzymaj current_version_id w rekordzie Document dla szybkiego odczytu „najbardziej aktualnej” wersji i zapisuj linię czasu poprzednich wersji do audytu i rollbacku. Dzięki temu nikt nie będzie się zastanawiał, co zostało zatwierdzone i dlaczego.
Generuj podglądy asynchronicznie po zapisaniu oryginalnego pliku, żeby upload był odczuwalnie natychmiastowy i by retry był bezpieczny. Śledź stan podglądu jak pending/ready/failed, aby UI mógł być uczciwy, i przechowuj różne rozmiary miniatur, żeby widoki listowe były lekkie, a widoki szczegółowe wyraźne.
Przechowuj metadane w trzech warstwach: systemowe (rozmiar pliku, typ), wyodrębnione (pola OCR i ich pewność) oraz wprowadzone przez użytkownika (poprawki). Zachowaj informację o pochodzeniu, żeby wiedzieć, czy wartość pochodzi z OCR czy od człowieka, i nie wymuszaj wypełniania każdego pola zanim praca może postępować.
Użyj małego zestawu statusów biznesowych opisujących, co powinna zrobić osoba: Imported, Needs review, Approved, Rejected, Archived. Przetwarzanie (OCR, generowanie podglądu) trzymaj oddzielnie jako stany systemowe, żeby dokumenty nie utknęły w mieszanym statusie.
Przechowuj niezmienne sumy kontrolne plików i porównuj je przy uploadzie, a gdy to możliwe dodaj drugą kontrolę na podstawie kluczowych pól jak sprzedawca/data/kwota. Przy podejrzeniu duplikatu zaoferuj wybór: dołączyć do tego samego wątku dokumentu lub odrzucić, aby nie rozdzielać historii przeglądu.
Prowadź log statusów z informacją kto i kiedy zmienił status oraz dlaczego, i trzymaj wersje możliwe do odczytu na osi czasu. Rollback powinien być zmianą wskaźnika do starszej wersji, a nie usuwaniem, żeby szybko odzyskać poprzedni stan bez utraty audytu.
Najpierw zdefiniuj obiekty i stany, potem pozwól interfejsowi podążać za tymi definicjami. Jeśli używasz Koder.ai do generowania aplikacji z planu w rozmowie, bądź precyzyjny w opisie Document/Version/File, stanów podglądu i reguł statusów, aby wygenerowane ekrany odpowiadały rzeczywistym potrzebom workflow.