17 gru 2025·6 min
Poolowanie połączeń PostgreSQL: pool aplikacyjny vs PgBouncer
Poolowanie połączeń PostgreSQL: porównanie puli w aplikacji i PgBouncer dla backendów Go, metryki do monitorowania i błędy konfiguracji wywołujące skoki opóźnień.
Poolowanie połączeń PostgreSQL: porównanie puli w aplikacji i PgBouncer dla backendów Go, metryki do monitorowania i błędy konfiguracji wywołujące skoki opóźnień.
Połączenie do bazy danych to jak linia telefoniczna między aplikacją a Postgresem. Otwarcie go kosztuje czas i zasoby po obu stronach: nawiązanie TCP/TLS, uwierzytelnianie, pamięć i proces backendu po stronie Postgresa. Pula połączeń utrzymuje mały zestaw tych „linii telefonicznych” otwartych, żeby aplikacja mogła je ponownie wykorzystać zamiast wybierać numer za każdym żądaniem.
Gdy poolowanie jest wyłączone lub źle skalibrowane, rzadko najpierw zobaczysz prosty błąd. Pojawiają się losowe spowolnienia. Żądania, które zwykle trwają 20–50 ms, nagle zajmują 500 ms lub 5 sekund, p95 rośnie. Potem pojawiają się timeouty, a później „too many connections” albo kolejka w aplikacji, która czeka na wolne połączenie.
Limity połączeń mają znaczenie nawet dla małych aplikacji, bo ruch jest skokowy. Mail marketingowy, cron lub kilka wolnych endpointów może spowodować, że dziesiątki żądań uderzą w bazę jednocześnie. Jeśli każde żądanie otwiera nowe połączenie, Postgres może zużywać znaczną część swojej mocy na akceptowanie i zarządzanie połączeniami zamiast wykonywać zapytania. Z drugiej strony, jeśli masz pulę, ale jest zbyt duża, możesz przeciążyć Postgresa zbyt wieloma aktywnymi backendami, co prowadzi do przełączeń kontekstu i presji pamięci.
Szukaj wczesnych symptomów, takich jak:
Poolowanie zmniejsza churn połączeń i pomaga Postgresowi obsłużyć skoki. Nie naprawi wolnych zapytań SQL. Jeśli zapytanie robi pełny skan tabeli lub czeka na blokadę, poolowanie głównie zmienia sposób, w jaki system pada (kolejkowanie wcześniej, timeouty później), a nie to, czy będzie szybki.
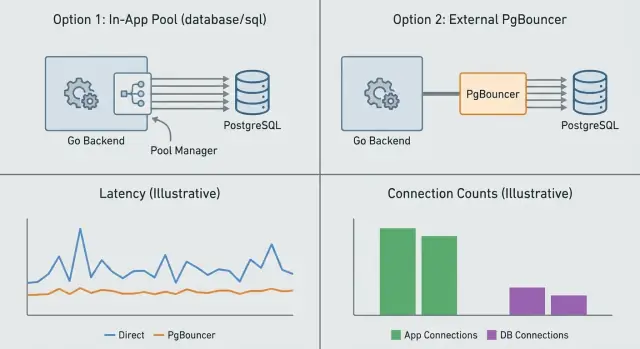
Poolowanie połączeń polega na kontrolowaniu, ile połączeń do bazy istnieje jednocześnie i jak są ponownie używane. Możesz to robić w aplikacji (pool na poziomie aplikacji) lub z osobną usługą przed Postgresem (PgBouncer). Rozwiązują one powiązane, ale różne problemy.
Pool na poziomie aplikacji (w Go zwykle wbudowany database/sql) zarządza połączeniami na proces. Decyduje, kiedy otworzyć nowe połączenie, kiedy je ponownie wykorzystać i kiedy zamknąć nieaktywne. Dzięki temu unikasz kosztu zestawiania połączenia przy każdym żądaniu. Nie potrafi jednak skoordynować się między wieloma instancjami aplikacji. Jeśli uruchomisz 10 replik, masz efektywnie 10 oddzielnych pul.
PgBouncer stoi między aplikacją a Postgresem i pooluje połączenia w imieniu wielu klientów. Jest najbardziej przydatny, gdy masz dużo krótkotrwałych żądań, wiele instancji aplikacji lub skokowy ruch. Ogranicza połączenia po stronie serwera do Postgresa nawet gdy setki połączeń klienckich przychodzą naraz.
Prosty podział odpowiedzialności:
Mogą współpracować razem bez problemów z „podwójnym poolowaniem”, o ile każda warstwa ma jasny cel: rozsądna pula database/sql na proces Go oraz PgBouncer wymuszający globalny budżet połączeń.
Częstym błędnym przekonaniem jest myślenie „więcej pul to więcej pojemności”. Zwykle oznacza odwrotnie. Jeśli każda usługa, worker i replika ma własną dużą pulę, łączna liczba połączeń może eksplodować i spowodować kolejki, przełączanie kontekstu i nagłe skoki opóźnień.
database/sql w Go naprawdę się zachowujeW Go sql.DB to menedżer puli połączeń, a nie pojedyncze połączenie. Gdy wywołujesz db.Query lub db.Exec, database/sql próbuje ponownie użyć nieaktywnego połączenia. Jeśli nie może, może otworzyć nowe (do ustawionego limitu) lub sprawić, że żądanie poczeka.
To oczekiwanie jest źródłem „tajemniczych opóźnień”. Gdy pula jest zapełniona, żądania kolejkują się wewnątrz aplikacji. Z zewnątrz wygląda to jakby Postgres stał się wolny, ale w rzeczywistości czas jest spędzany na czekaniu na wolne połączenie.
Większość strojenia sprowadza się do czterech ustawień:
MaxOpenConns: twardy limit otwartych połączeń (idle + używane). Po jego osiągnięciu wywołujący blokują się.MaxIdleConns: ile połączeń może czekać gotowych do ponownego użycia. Zbyt niska wartość powoduje częste ponowne łączenia.ConnMaxLifetime: wymusza okresowe odnawianie połączeń. Przydaje się przy load balancerach i timeoutach NAT, ale zbyt niska wartość wywołuje churn.ConnMaxIdleTime: zamyka połączenia, które długo stoją nieużywane.Ponowne użycie połączeń zwykle obniża opóźnienia i zużycie CPU w bazie, bo unikasz powtarzanych ustawiań (TCP/TLS, auth, inicjalizacja sesji). Ale przesadnie duża pula może robić odwrotnie: pozwala na więcej jednoczesnych zapytań niż Postgres potrafi sprawnie obsłużyć, co zwiększa contentię i narzut.
Myśl w kategoriach sumarycznych, nie na proces. Jeżeli każda instancja Go dopuszcza 50 otwartych połączeń, a skaluje się do 20 instancji, efektywnie pozwoliłeś na 1 000 połączeń. Porównaj tę liczbę z tym, co twoja instancja Postgresa może obsłużyć komfortowo.
Praktyczny punkt startowy to powiązać MaxOpenConns z oczekiwaną współbieżnością na instancję, a potem weryfikować to metrykami puli (in-use, idle, wait time) zanim podniesiesz limit.
PgBouncer to mały proxy między aplikacją a PostgreSQL. Twoja usługa łączy się z PgBouncerem, a on utrzymuje ograniczoną liczbę prawdziwych połączeń serwera do Postgresa. Podczas szczytów PgBouncer kolejkowuje pracę klientów zamiast natychmiast tworzyć więcej backendów Postgresa. Ta kolejka może decydować o różnicy między kontrolowanym spowolnieniem a przeciążeniem bazy.
PgBouncer ma trzy tryby poolowania:
Session pooling zachowuje się najbardziej podobnie do bezpośrednich połączeń do Postgresa. Jest najmniej zaskakujący, ale oszczędza mniej połączeń serwerowych przy skokowym obciążeniu.
Dla typowych API HTTP w Go, transaction pooling często jest dobrym domyślnym wyborem. Większość żądań wykonuje krótkie zapytanie lub krótką transakcję, po czym kończy. Transaction pooling pozwala wielu klientom dzielić mniejszy budżet połączeń Postgresa.
Wadą jest stan sesji. W trybie transaction wszystko, co zakłada utrzymanie tego samego połączenia serwera, może się zepsuć lub zachowywać dziwnie, w tym:
SET, SET ROLE, search_path)Jeśli aplikacja polega na takim stanie, bezpieczniejszy jest session pooling. Statement pooling jest najbardziej restrykcyjny i rzadko pasuje do aplikacji webowych.
Przydatna zasada: jeśli każde żądanie może ustawić, czego potrzebuje, wewnątrz jednej transakcji, transaction pooling utrzyma opóźnienia bardziej stabilne przy obciążeniu. Jeśli potrzebujesz długotrwałego zachowania sesji, użyj session pooling i skup się na ścisłych limitach w aplikacji.
Jeśli uruchamiasz usługę Go z database/sql, to już masz pool po stronie aplikacji. Dla wielu zespołów to wystarcza: kilka instancji, stabilny ruch i zapytania, które nie są ekstremalnie skokowe. W takim scenariuszu najprostszy i najbezpieczniejszy wybór to dopracować pulę Go, utrzymać realistyczny limit połączeń i na tym poprzestać.
PgBouncer pomaga najbardziej, gdy baza jest uderzana przez zbyt wiele połączeń klienckich naraz. Objawia się to wieloma instancjami aplikacji (lub skalowaniem serverless), skokowym ruchem i dużą liczbą krótkich zapytań.
PgBouncer może też zaszkodzić, jeśli użyjesz go w złym trybie. Jeśli twój kod polega na stanie sesji (tymczasowe tabele, przygotowane zapytania wykorzystywane między żądaniami, advisory locks trzymane między wywołaniami, ustawienia na poziomie sesji), transaction pooling może powodować mylące błędy. Jeśli naprawdę potrzebujesz zachowania sesji, użyj session pooling lub pomiń PgBouncer i starannie dobierz rozmiary pul aplikacyjnych.
Użyj tej reguły:
Limity połączeń to budżet. Jeśli wydasz go wszystko naraz, każde nowe żądanie będzie czekać i ogonowe opóźnienia skoczą. Celem jest ograniczyć współbieżność w kontrolowany sposób, przy zachowaniu stałego przepływu.
Zmierz dzisiejsze szczyty i opóźnienia ogonowe. Zarejestruj maksymalne aktywne połączenia (nie średnie), oraz p50/p95/p99 dla żądań i kluczowych zapytań. Zauważ błędy połączeń i timeouty.
Ustal bezpieczny budżet połączeń Postgresa dla aplikacji. Zacznij od max_connections i odejmij miejsce na dostęp administracyjny, migracje, zadania tła i skoki. Jeśli wiele usług dzieli bazę, celowo podziel budżet.
Mapuj budżet na limity Go na instancję. Podziel budżet aplikacji przez liczbę instancji i ustaw MaxOpenConns na tę wartość (lub nieco niższą). Ustaw MaxIdleConns wystarczająco wysoko, by unikać ciągłych ponownych połączeń, a czasy życia tak, by połączenia były okresowo odnawiane bez churnu.
Dodaj PgBouncer tylko jeśli jest potrzebny i wybierz tryb. Użyj session pooling, jeśli potrzebujesz stanu sesji. Wybierz transaction pooling, gdy chcesz największego zmniejszenia połączeń serwera i gdy aplikacja jest kompatybilna.
Wdrażaj stopniowo i porównuj przed i po. Zmieniaj pojedyncze elementy, stosuj canary i porównuj opóźnienia ogonowe, czas oczekiwania w puli oraz CPU bazy.
Przykład: jeśli Postgres może bezpiecznie przydzielić twojej usłudze 200 połączeń, a masz 10 instancji Go, zacznij od MaxOpenConns=15-18 na instancję. To zostawia zapas na skoki i zmniejsza szansę, że każda instancja jednocześnie osiągnie limit.
Problemy z poolowaniem rzadko zaczynają się od „za dużo połączeń”. Częściej widzisz powolny wzrost czasu oczekiwania, a potem nagły skok p95 i p99.
Zacznij od tego, co raportuje twoja aplikacja Go. W database/sql monitoruj: open connections, in-use, idle, wait count i wait time. Jeśli rośnie wait count przy stałym ruchu, pula jest za mała lub połączenia są trzymane zbyt długo.
Po stronie bazy śledź aktywne połączenia vs max, CPU i aktywność blokad. Jeśli CPU jest niskie, a opóźnienia wysokie, często jest to kolejka lub blokady, a nie surowa moc obliczeniowa.
Jeśli masz PgBouncer, dodaj trzeci widok: połączenia klienta, połączenia serwera do Postgresa i głębokość kolejki. Rosnąca kolejka przy stabilnej liczbie połączeń serwera to jasny sygnał, że budżet jest nasycony.
Dobre sygnały alarmowe:
Problemy z poolowaniem często pojawiają się podczas skoków: żądania gromadzą się czekając na połączenie, potem wszystko znów wygląda dobrze. Przyczyną jest często ustawienie, które jest rozsądne na jednej instancji, ale niebezpieczne przy wielu kopiach usługi.
Typowe przyczyny:
MaxOpenConns ustawione na instancję bez globalnego budżetu. 100 połączeń na instancję * 20 instancji = 2000 potencjalnych połączeń.ConnMaxLifetime / ConnMaxIdleTime ustawione zbyt nisko. To może wywołać burzę ponownych połączeń, gdy wiele połączeń się jednocześnie odnawia.Prosty sposób na zmniejszenie skoków to traktować poolowanie jako limit współdzielony, a nie domyślny lokalny: ogranicz łączne połączenia we wszystkich instancjach, trzymaj umiarkowaną pulę idle i używaj czasów życia dostatecznie długich, by uniknąć zsynchronizowanych reconnectów.
Gdy ruch rośnie, zwykle widzisz jedno z trzech: żądania kolejkują się czekając na wolne połączenie, żądania timeoutują lub wszystko zwalnia tak bardzo, że retry-e się kumulują.
Kolejkowanie jest podstępne. Twój handler nadal działa, ale jest zatrzymany, czekając na połączenie. Ten czas oczekiwania staje się częścią czasu odpowiedzi, więc mała pula może zamienić zapytanie 50 ms w wielosekundowe opóźnienie pod obciążeniem.
Przydatny model mentalny: jeśli pula ma 30 użytecznych połączeń, a nagle masz 300 równoczesnych żądań potrzebujących bazy, 270 z nich musi czekać. Jeśli każde żądanie trzyma połączenie przez 100 ms, opóźnienia ogonowe szybko skoczą do sekund.
Ustal jasny budżet timeoutów i trzymaj się go. Timeout aplikacji powinien być nieco krótszy niż timeout bazy, żebyś szybko porzucał pracę i zmniejszał presję, zamiast pozwalać jej wisieć.
statement_timeout, żeby jedno złe zapytanie nie blokowało połączeńDodaj też mechanizmy backpressure, żeby nie przeciążać puli. Wybierz 1–2 przewidywalne mechanizmy: ograniczenie współbieżności na endpoint, odrzucanie nadmiaru (429) lub wydzielenie zadań tła.
Na koniec: najpierw napraw wolne zapytania. Pod presją poolowania wolne zapytania trzymają połączenia dłużej, co zwiększa czasy oczekiwania, timeouty i retry-e. Ten sprzężony pętli napędza „trochę wolno” w „wszystko wolne”.
Traktuj testy obciążeniowe jako sposób na weryfikację budżetu połączeń, nie tylko przepustowości. Cel to potwierdzić, że poolowanie zachowuje się pod obciążeniem tak jak w staging.
Testuj realistyczny ruch: ten sam miks żądań, wzorce skokowe i taką samą liczbę instancji aplikacji jak w produkcji. Benchmarkowanie jednego endpointu często ukrywa problemy z pulą aż do dnia uruchomienia.
Uwzględnij rozgrzewkę, żeby nie mierzyć cold cache i efektów ramp-up. Pozwól pulom osiągnąć normalny rozmiar, a potem zacznij zapisywać wyniki.
Jeśli porównujesz strategie, trzymaj obciążenie identyczne i uruchom:
database/sql, bez PgBouncer)Po każdym teście zapisz krótką kartę wyników, której będziesz używać po kolejnych wydaniach:
Z czasem to zamienia planowanie pojemności w proces powtarzalny zamiast zgadywania.
Zanim zmienisz rozmiary puli, zapisz jedną liczbę: swój budżet połączeń. To maksymalna bezpieczna liczba aktywnych połączeń Postgresa dla tego środowiska (dev, staging, prod), wliczając zadania tła i dostęp administracyjny. Jeśli nie potrafisz jej podać, zgadujesz.
Krótka lista kontrolna:
MaxOpenConns) mieści się w budżecie (lub w limicie PgBouncer).max_connections i wszelkie zarezerwowane połączenia zgadzają się z twoim planem.Plan wdrożenia z łatwym rollbackem:
Jeśli budujesz i hostujesz aplikację Go + PostgreSQL na Koder.ai (koder.ai), Planning Mode może pomóc wymodelować zmianę i co będziesz mierzyć, a snapshoty i rollback ułatwią wycofanie, jeśli ogonowe opóźnienia się pogorszą.
Następny krok: dodaj jedno pomiar przed kolejnym skokiem ruchu. „Czas spędzony na czekaniu na połączenie” w aplikacji często jest najbardziej przydatny, bo pokazuje presję na pulę zanim użytkownicy ją odczują.
Pula utrzymuje niewielką liczbę połączeń do PostgreSQL i ponownie wykorzystuje je dla kolejnych żądań. Dzięki temu nie trzeba za każdym razem ponosić kosztu nawiązywania połączenia (TCP/TLS, uwierzytelnianie, tworzenie procesu backendu), co pomaga utrzymać stabilne opóźnienia podczas skoków ruchu.
Gdy pula jest pełna, żądania czekają wewnątrz aplikacji na wolne połączenie — ten czas oczekiwania pojawia się jako wolne odpowiedzi. Często wygląda to jak „losowe spowolnienia”, ponieważ średnie wartości mogą wyglądać dobrze, podczas gdy p95/p99 rosną przy skokach ruchu.
Nie. Poolowanie zmienia głównie sposób, w jaki system zachowuje się pod obciążeniem — zmniejsza częstotliwość ponownego łączenia i kontroluje współbieżność. Jeśli zapytanie jest wolne z powodu pełnego skanowania tabeli, blokad lub złych indeksów, poolowanie go nie przyspieszy; jedynie ograniczy liczbę równocześnie uruchamianych wolnych zapytań.
Pool aplikacyjny zarządza połączeniami na poziomie procesu — każda instancja aplikacji ma własną pulę i limity. PgBouncer stoi przed Postgresem i wymusza globalny budżet połączeń, co jest przydatne przy wielu replikach lub skokowym ruchu.
Jeśli masz niewiele instancji i suma otwartych połączeń mieści się z zapasem w limicie bazy, wystarczy dostroić pulę database/sql w Go. Dodaj PgBouncer, kiedy wiele instancji, autoskalowanie lub skoki ruchu mogą przepchnąć łączną liczbę połączeń poza to, co Postgres obsłuży płynnie.
Dobrym punktem startowym jest ustalenie budżetu połączeń dla całej usługi, podzielenie go przez liczbę instancji i ustawienie MaxOpenConns nieco poniżej tej wartości na instancję. Zacznij ostrożnie, obserwuj czas oczekiwania w puli oraz p95/p99 i zwiększaj tylko jeśli baza ma zapas mocy.
Dla typowych API HTTP w Go, transaction pooling jest często dobrym domyślnym wyborem, bo pozwala wielu klientom dzielić mniejszy budżet połączeń do Postgresa i stabilizuje opóźnienia przy skokach. Użyj session pooling, jeśli Twoja aplikacja polega na stanie sesji utrzymywanym między zapytaniami.
Przy transaction poolingu mogą nie działać tak, jak oczekujesz: przygotowane zapytania używane wielokrotnie, tymczasowe tabele, advisory locks oraz ustawienia sesji mogą zachowywać się inaczej, bo klient niekoniecznie dostaje to samo połączenie serwerowe przy kolejnym żądaniu. Jeśli potrzebujesz takich funkcji, trzymaj wszystko w jednej transakcji na żądanie lub wybierz session pooling.
Obserwuj p95/p99 razem z czasem oczekiwania w puli aplikacji, bo czas oczekiwania często rośnie zanim użytkownicy odczują problem. Na bazie monitoruj aktywne połączenia względem max_connections, CPU i aktywność blokad; w PgBouncerze patrz na połączenia klienta, połączenia serwera i głębokość kolejki.
Najpierw zapobiegnij nieograniczonemu czekaniu — ustaw deadliny żądań i statement_timeout, żeby jedno wolne zapytanie nie blokowało puli na zawsze. Dodaj backpressure: ogranicz współbieżność w ciężkich endpointach, odrzucaj nadmiar (np. 429) albo wydziel zadania tła. Unikaj też bardzo krótkich czasów życia połączeń, które wywołują fale ponownych połączeń.