29 wrz 2025·7 min
Plan śledzenia zdarzeń dla SaaS: nazwy, właściwości, 10 dashboardów
Użyj tego planu śledzenia zdarzeń dla SaaS, aby spójnie nazywać eventy i właściwości oraz przygotować 10 wczesnych dashboardów dla aktywacji i retencji.
Co warto zrozumieć wcześnie (i dlaczego to jest trudne)
Wczesna analityka w pierwszej aplikacji SaaS często wydaje się myląca, bo masz dwa problemy naraz: niewielu użytkowników i mało kontekstu. Kilku aktywnych użytkowników może zniekształcić wykresy, a kilku „turystów” (osoby, które rejestrują się i odchodzą) może sprawić, że wszystko będzie wyglądać źle.
Najtrudniejsze jest oddzielenie szumu użycia od prawdziwych sygnałów. Szum to aktywność, która wygląda na ruch, ale nie oznacza postępu — np. klikanie ustawień, odświeżanie stron czy tworzenie testowych kont. Sygnały to akcje przewidujące wartość, takie jak ukończenie onboardingu, zaproszenie współpracownika czy wykonanie pierwszego udanego zadania.
Dobry plan śledzenia zdarzeń dla SaaS powinien pomóc odpowiedzieć na kilka podstawowych pytań w pierwszych 30 dniach, bez potrzeby zespołu danych.
Co powinieneś móc szybko odpowiedzieć
Jeśli twoje śledzenie potrafi odpowiedzieć na te pytania, jesteś w dobrym miejscu:
- Gdzie nowi użytkownicy odpadają przed osiągnięciem pierwszej wartości?
- Ilu użytkowników osiąga „pierwszą wartość” w ciągu 24 godzin i w ciągu 7 dni?
- Które funkcje używane są przez osoby, które wracają w następnym tygodniu?
- Jaka jest najczęstsza ścieżka do sukcesu (i najczęstszy martwy punkt)?
- Czy powracający użytkownicy wracają, żeby wykonać tę samą pracę, czy tylko „dotykają” produktu?
Prosto: aktywacja to moment, w którym użytkownik osiąga swoje pierwsze realne zwycięstwo. Retencja to to, czy wraca po tę wartość ponownie. Nie potrzebujesz idealnych definicji pierwszego dnia, ale potrzebujesz jasnego przypuszczenia i sposobu pomiaru.
Jeśli szybko budujesz (np. wdrażając nowe przepływy codziennie w platformie takiej jak Koder.ai), ryzyko polega na instrumentowaniu wszystkiego. Więcej zdarzeń może oznaczać większe zamieszanie. Zacznij od niewielkiego zestawu akcji odpowiadających „pierwszemu zwycięstwu” i „powtórnemu zwycięstwu”, a potem rozszerzaj tylko wtedy, gdy decyzja tego wymaga.
Zdefiniuj aktywację i retencję prostymi słowami
Aktywacja to moment, kiedy nowy użytkownik po raz pierwszy otrzymuje realną wartość. Retencja to czy wraca i nadal otrzymuje wartość w czasie. Jeśli nie potrafisz obu tych rzeczy opisać prostymi słowami, twoje śledzenie zamieni się w stos zdarzeń, które nic nie wyjaśniają.
Zacznij od nazwania dwóch „osób” w produkcie:
- Core user: osoba wykonująca pracę (ta, która klika, przesyła, wysyła, buduje).
- Account: klient, który płaci i ma rozliczenia (osoba lub firma).
Wiele aplikacji SaaS działa w zespołach, więc jedno konto może mieć wielu użytkowników. Dlatego plan śledzenia zdarzeń dla SaaS powinien zawsze jasno określać, czy mierzysz zachowanie użytkownika, zdrowie konta, czy obie rzeczy.
Jedno zdanie dla aktywacji
Napisz aktywację jako jedno zdanie zawierające wyraźną akcję i wyraźny rezultat. Dobre momenty aktywacji brzmią jak: „Zrobiłem X i dostałem Y.”
Przykład: „Użytkownik tworzy swój pierwszy projekt i pomyślnie go publikuje.” (Jeśli budujesz z narzędziem takim jak Koder.ai, to może być „pierwsze udane wdrożenie” lub „pierwszy eksport kodu źródłowego”, w zależności od obietnicy produktu.)
Aby to zdanie uczynić mierzalnym, wypisz kilka kroków, które zazwyczaj poprzedzają pierwszą wartość. Trzymaj to krótko i skup się na tym, co możesz zaobserwować:
- Sign up
- Create the first workspace/project
- Add the key input (data, content, integration, or settings)
- Run the core action (send, publish, generate, invite)
- Reach a success state (completed, delivered, deployed)
Co oznacza retencja dla ciebie
Retencja to „czy wrócili” według harmonogramu pasującego do twojego produktu.
Jeśli produkt jest używany codziennie — patrz na retencję dzienną. Jeśli to narzędzie do pracy używane kilka razy w tygodniu — użyj retencji tygodniowej. Jeśli to miesięczny przepływ (fakturowanie, raportowanie) — użyj retencji miesięcznej. Najlepszy wybór to ten, w którym „powrót” realistycznie sygnalizuje ciągłą wartość, a nie logowania z poczucia obowiązku.
Krok po kroku: zbuduj swój pierwszy plan śledzenia zdarzeń
Zacznij od ścieżki do pierwszej wartości
Plan śledzenia zdarzeń dla SaaS działa najlepiej, gdy opowiada jedną prostą historię: jak nowa osoba przechodzi od rejestracji do pierwszego realnego zwycięstwa.
Zapisz najkrótszą ścieżkę onboardingu, która tworzy wartość. Przykład: Signup -> verify email -> create workspace -> invite teammate (opcjonalnie) -> connect data (lub skonfiguruj projekt) -> complete first key action -> zobaczyć rezultat.
Oznacz momenty, w których ktoś może odpaść lub utknąć. Te momenty stają się pierwszymi zdarzeniami, które śledzisz.
Zdefiniuj i przetestuj minimalny zestaw
Trzymaj pierwszą wersję małą. Zwykle potrzebujesz 8–15 zdarzeń, nie 80. Celuj w zdarzenia, które odpowiadają: Czy zaczęli? Czy osiągnęli pierwszą wartość? Czy wrócili?
Praktyczna kolejność budowy:
- Zmapuj onboarding i ścieżkę pierwszej wartości (jedna strona, bez debaty)
- Wybierz krótłą listę zdarzeń obejmującą każdy krok tej ścieżki
- Zdefiniuj każde zdarzenie w małej specyfikacji (nazwa, kiedy wywołuje się, kluczowe właściwości)
- Dodaj jeden stabilny identyfikator użytkownika i jeden identyfikator konta/workspace do każdego zdarzenia
- Przetestuj zdarzenia, wykonując prawdziwe przepływy przed wydaniem
Dla specyfikacji zdarzenia wystarczy mała tabela w dokumencie. Uwzględnij: nazwę zdarzenia, trigger (co musi się zdarzyć w produkcie), kto może je uruchomić i właściwości, które zawsze wyślesz.
Dwa ID zapobiegają większości wczesnych nieporozumień: unikalny user ID (osoba) i account lub workspace ID (miejsce pracy). Dzięki temu oddzielisz osobiste użycie od adopcji zespołowej i późniejszych uaktualnień.
Przed wydaniem wykonaj test „świeżego użytkownika”: załóż nowe konto, przejdź onboarding, a potem sprawdź, czy każde zdarzenie odpala się raz (nie zero, nie pięć razy), z właściwymi ID i znacznikami czasu. Jeśli budujesz na platformie takiej jak Koder.ai, włącz ten test do standardowej procedury przed wydaniem, żeby śledzenie pozostało poprawne przy zmianach aplikacji.
Prosta konwencja nazewnictwa zdarzeń
Konwencja nazewnictwa nie polega na byciu „poprawnym”. Chodzi o konsekwencję, żeby wykresy nie rozsypywały się przy zmianach produktu.
Prosta zasada działająca w większości aplikacji SaaS to verb_noun w snake_case. Utrzymuj czasownik jasny, a rzeczownik konkretny.
Przykłady, które możesz skopiować:
created_project,invited_teammate,uploaded_file,scheduled_demosubmitted_form(czas przeszły czytelnie oznacza ukończoną akcję)connected_integration,enabled_feature,exported_report
Wol preferuj czas przeszły dla zdarzeń oznaczających „to się wydarzyło”. To redukuje niejednoznaczność. Na przykład started_checkout może być użyteczne, ale completed_checkout to to, czego chcesz do danych przychodów i pracy nad retencją.
Unikaj nazw specyficznych dla UI, jak clicked_blue_button czy pressed_save_icon. Przyciski i układy się zmieniają, a śledzenie staje się historią starych ekranów. Nazwij zamiar: saved_settings lub updated_profile.
Utrzymuj nazwy stabilne nawet jeśli UI się zmieni. Jeśli zmienisz created_workspace na created_team, wykres aktywacji może pęknąć na dwie linie i stracisz ciągłość. Jeśli musisz zmienić nazwę, potraktuj to jak migrację: mapuj stare nazwy na nowe i udokumentuj decyzję.
Zarezerwowane prefiksy (krótkie i praktyczne)
Krótki zestaw prefiksów pomaga utrzymać listę zdarzeń czytelną. Wybierz kilka i trzymaj się ich.
Na przykład:
auth_(signup, login, logout)onboarding_(kroki prowadzące do pierwszej wartości)billing_(trial, checkout, invoices)admin_(role, uprawnienia, ustawienia organizacji)
Jeśli budujesz SaaS w narzędziu chat-driven jak Koder.ai, ta konwencja nadal ma sens. Funkcja zbudowana dziś może być przeprojektowana jutro, ale created_project pozostaje znaczące przez kolejne wersje UI.
Właściwości do uwzględnienia (i jak zachować ich spójność)
Zbuduj podstawowy workflow teraz
Zamień przepływ „pierwszej wartości” w działającą aplikację z prostego czatu.
Dobre nazwy zdarzeń mówią, co się stało. Właściwości mówią, kto to zrobił, gdzie się stało i jaki był rezultat. Jeśli utrzymasz mały, przewidywalny zestaw, plan śledzenia zdarzeń dla SaaS pozostanie czytelny w miarę dodawania funkcji.
Zacznij od małego „zawsze włączonego” rdzenia
Wybierz parę właściwości, które pojawiają się w prawie każdym zdarzeniu. Pozwolą ci kroić wykresy po typie klienta bez przebudowywania dashboardów później.
Praktyczny zestaw rdzeniowy:
- user_id i account_id (kto to zrobił i do którego workspace należy)
- plan_tier (free, pro, business, enterprise)
- timestamp (kiedy to się zdarzyło, najlepiej z serwera)
- app_version (żeby zauważyć zmiany po release)
- signup_source (skąd przyszedł użytkownik: ads, referral, organic)
Dodawaj kontekst tylko wtedy, gdy zmienia on sens zdarzenia. Na przykład „Project Created” jest dużo bardziej użyteczne z project_type lub template_id, a „Invite Sent” zyskuje dzięki seats_count.
Śledź rezultaty, nie tylko akcje
Gdy akcja może nie powieść się, dołącz jawny wynik. Prosty success: true/false często wystarcza. Jeśli nie powiodło się, dodaj krótki error_code (np. billing_declined lub invalid_domain), żeby grupować problemy bez czytania surowych logów.
Realistyczny przykład: na Koder.ai „Deploy Started” bez danych o wyniku jest mylące. Dodaj success plus error_code i szybko zobaczysz, czy nowi użytkownicy przegrywają z powodu brakującej konfiguracji domeny, limitów płatności czy ustawień regionu.
Zasady spójności, które ratują dashboardy
Zdecyduj nazwę, typ i znaczenie raz, a potem się tego trzymaj. Jeśli plan_tier jest stringiem w jednym zdarzeniu, nie wysyłaj go jako liczby w innym. Unikaj synonimów (account_id vs workspace_id) i nigdy nie zmieniaj znaczenia właściwości w czasie.
Jeśli potrzebujesz lepszej wersji, stwórz nową nazwę właściwości i zachowaj starą aż do migracji dashboardów.
Higiena danych i podstawy prywatności
Czyste dane śledzenia to w dużej mierze dwie nawyki: wysyłaj tylko to, co potrzebne, i ułatw naprawianie błędów.
Traktuj analitykę jako dziennik akcji, nie miejsce do przechowywania danych osobowych. Unikaj wysyłania surowych adresów e-mail, pełnych imion i nazwisk, numerów telefonów czy czegokolwiek, co użytkownik wpisuje w polu tekstowym (notatki wsparcia, pola opinii, wiadomości czatu). Tekst wolny często zawiera wrażliwe dane, których nie planowałeś.
Używaj wewnętrznych ID zamiast PII. Śledź user_id, account_id i workspace_id, a mapowanie do danych osobowych trzymaj w swojej bazie lub CRM. Jeśli ktoś musi powiązać zdarzenie z osobą, rób to przez wewnętrzne narzędzia, nie kopiując PII do analityki.
Adresy IP i dane lokalizacyjne wymagają decyzji z góry. Wiele narzędzi zbiera IP domyślnie, a „miasto/kraj” może wydawać się nieszkodliwe, ale nadal może być danymi osobowymi. Wybierz podejście i dokumentuj je: nic nie przechowywać, przechowywać tylko zgrubną lokalizację (kraj/region) lub przechowywać IP tymczasowo dla bezpieczeństwa, a potem usuwać.
Oto prosta lista higieny do wdrożenia z pierwszymi dashboardami:
- Zdefiniuj allow-listę właściwości zdarzeń, które będziesz wysyłać (wszystko inne blokowane)
- Dodaj sposób usuwania danych użytkownika na żądanie (po
user_idiaccount_id) - Ogranicz dostęp: kto może przeglądać surowe zdarzenia, kto może eksportować i kto może zmieniać śledzenie
- Prowadź krótki dokument śledzenia z przykładami „bezpieczne” vs „niebezpieczne” właściwości
Jeśli budujesz SaaS na platformie takiej jak Koder.ai, stosuj te same zasady do logów systemowych i snapshotów: utrzymuj identyfikatory spójne, trzymaj PII poza payloadami zdarzeń i zapisz, kto co widzi i dlaczego.
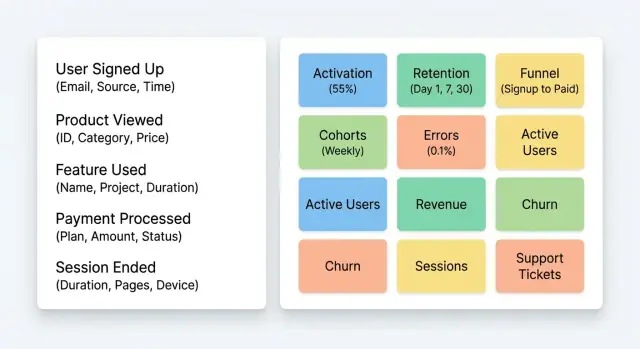
10 niezbędnych dashboardów na wczesne fazy aktywacji i retencji
Dobry plan śledzenia zdarzeń dla SaaS zamienia surowe kliknięcia w odpowiedzi, na których można działać. Te dashboardy koncentrują się na dwóch rzeczach: jak ludzie osiągają pierwszą wartość i czy do niej wracają.
Dashboardy wyjaśniające aktywację
- 1) Trend nowych użytkowników (dziennie/tygodniowo) + signup_source: Licz nowe konta i podziel je według kanału pozyskania (ads, organic, referral, invite). Obserwuj skoki, które później nie aktywują się.
- 2) Lejek aktywacji z miejscami odpadu: Prosty lejek: Signup -> Email verified -> Project created -> First value action. Wyróżnij największy krok, gdzie odpadają użytkownicy i sprawdź sesje.
- 3) Czas do pierwszej wartości (mediana, p75): Mierz, ile czasu użytkownicy potrzebują, by trafić na zdarzenie pierwszej wartości. Mediana pokazuje typową ścieżkę; p75 pokazuje, kto ma trudności.
- 4) Adopcja funkcji (top 5 akcji wartościowych): Śledź kilka akcji, które oznaczają realne użycie (nie kliknięcia ustawień). Trzymaj się top 5, żeby było czytelne.
- 5) Wskaźnik aktywacji wg signup_source: Ta sama definicja aktywacji, podzielona według źródła. Jeden kanał może przyciągać ciekawskich, inny kupujących.
Jeśli zbudowałeś pierwszą wersję na platformie takiej jak Koder.ai, nadal możesz korzystać z tych dashboardów — kluczem są spójne zdarzenia.
Dashboardy wyjaśniające retencję
- 6) Kohorty retencji (tydzień 1, tydzień 4): Kohorty według tygodnia rejestracji, retencja mierzona przez wykonanie kluczowej akcji. Pokaże, czy produkt staje się bardziej „klejący”.
- 7) Trend powracających użytkowników (WAU): Weekly active users (bazowane na kluczowej akcji) oddziela „logowania” od realnego użycia.
- 8) Częstotliwość powtarzania wartości: Ile dni w tygodniu użytkownicy wykonują podstawową akcję. To pokazuje, czy masz workflow budujący nawyk.
- 9) Lejek reaktywacji: Inactive -> Returned -> Did key action. Pomaga zobaczyć, czy przypomnienia i nowe funkcje faktycznie ściągają ludzi z powrotem.
- 10) Dashboard friction (błędy i nieudane akcje): Śledź
error_shown,payment_failedlubintegration_failed. Skoki tutaj cicho zabijają aktywację i retencję.
Przykładowy scenariusz: śledzenie nowego SaaS od signup do pierwszej wartości
Miej pełną kontrolę nad kodem
Eksportuj kod źródłowy w dowolnym momencie i dodaj analitykę tak, jak chcesz.
Wyobraź sobie prosty B2B SaaS z 14-dniowym trialem. Jedna osoba rejestruje się, tworzy workspace dla zespołu, testuje produkt i (idealnie) zaprasza współpracownika. Cel to szybko dowiedzieć się, gdzie ludzie utkną.
Zdefiniuj „pierwszą wartość” jako: użytkownik tworzy workspace i wykonuje jedno kluczowe zadanie potwierdzające, że produkt działa dla niego (np. „zaimportuj CSV i wygeneruj pierwszy raport”). Wszystko we wczesnym śledzeniu powinno odnosić się do tego momentu.
Oto lekki zestaw zdarzeń, który możesz wypuścić pierwszego dnia (nazwy to proste czasowniki w czasie przeszłym, z jasnymi obiektami):
created_workspacecompleted_core_taskinvited_teammate
Dla każdego zdarzenia dołącz tylko tyle właściwości, żeby wyjaśnić dlaczego to się stało (lub nie). Dobre wczesne właściwości to:
- signup_source (google_ads, referral, founder_linkedin, itd.)
- template_id (które ustawienie początkowe wybrali)
- seats_count (szczególnie przy zaproszeniach zespołowych)
- success (true/false) plus krótki error_code gdy success=false
Wyobraź sobie dashboardy: lejek aktywacji pokazuje: signed_up -> created_workspace -> completed_core_task. Jeśli widzisz duży odpływ między utworzeniem workspace a kluczowym zadaniem, segmentuj po template_id i success. Możesz odkryć, że jeden szablon prowadzi do wielu nieudanych prób (success=false), albo że użytkownicy z jednego signup_source wybierają zły szablon i wcale nie osiągają wartości.
Widok „rozszerzanie zespołu” (completed_core_task -> invited_teammate) mówi, czy ludzie zapraszają innych dopiero po sukcesie, czy zapraszają wcześniej, a zaproszeni nigdy nie kończą kluczowego zadania.
Na tym polega plan śledzenia zdarzeń dla SaaS: nie zbierać wszystkiego, lecz znaleźć największe wąskie gardło, które możesz naprawić w następnym tygodniu.
Częste błędy, które niszczą wczesne insighty
Większość porażek śledzenia to nie problem narzędzi. Dzieją się, gdy śledzenie mówi, co ktoś kliknął, ale nie mówi, co osiągnął. Jeśli dane nie potrafią odpowiedzieć „czy użytkownik osiągnął wartość?”, twój plan śledzenia zdarzeń dla SaaS będzie wyglądał na zajęty i wciąż pozostawi cię ze zgadywankami.
Błąd 1: Mierzenie kliknięć zamiast rezultatów
Kliknięcia są łatwe do śledzenia i łatwe do błędnej interpretacji. Użytkownik może kliknąć „Create project” trzy razy i i tak nie skończyć. Wol preferuj zdarzenia opisujące postęp: created a workspace, invited a teammate, connected data, published, sent first invoice, completed first run.
Błąd 2: Zmienianie nazw zdarzeń co sprint
Jeśli zmieniasz nazwy, by pasowały do najnowszego tekstu UI, trendy się rozpadają i tracisz kontekst tydzień do tygodnia. Wybierz stabilną nazwę zdarzenia, a potem rozwijaj znaczenie przez właściwości (np. zachowaj project_created, dodaj creation_source jeśli dodasz nowe wejście).
Błąd 3: Zapominanie identyfikatorów B2B
Jeśli wysyłasz tylko user_id, nie odpowiesz na pytania o konta: które zespoły się aktywowały, które konta churnują, kto jest power userem w koncie. Zawsze dołącz account_id (a najlepiej też role lub seat_type), żeby móc oglądać retencję zarówno użytkownika, jak i konta.
Błąd 4: Wysyłanie zbyt wielu właściwości
Więcej nie znaczy lepiej. Olbrzymi, niespójny zestaw właściwości tworzy puste wartości, dziwne warianty pisowni i dashboardy, którym nikt nie ufa. Trzymaj mały „zawsze obecny” zestaw i dodawaj dodatkowe właściwości tylko wtedy, gdy odpowiadają na konkretne pytanie.
Błąd 5: Brak testów end-to-end
Przed wydaniem zweryfikuj:
- Zdarzenia odpala się raz (nie dwa razy) i w odpowiednim momencie
- Wysyłane są wymagane ID (
user_id,account_idgdzie trzeba) - Wartości właściwości odpowiadają ustalonej liście (brak niespodzianych stringów)
- Dashboardy aktualizują się z prawdziwych przepływów, nie tylko z danych testowych
- Możesz odtworzyć ścieżkę użytkownika w kolejności
Jeśli budujesz SaaS w chat-driven narzędziu jak Koder.ai, traktuj śledzenie jak każdą inną funkcję: zdefiniuj oczekiwane zdarzenia, przejdź pełną ścieżkę użytkownika i dopiero potem wypuść.
Szybka lista kontrolna przed wysłaniem śledzenia
Zaplanuj aktywację w kilka minut
Szkicuj kroki onboardingowe i kluczowe zdarzenia przed napisaniem kodu.
Zanim dodasz więcej zdarzeń, upewnij się, że twoje śledzenie odpowie na pytania, które naprawdę masz w tygodniu 1: czy ludzie osiągają pierwszą wartość i czy do niej wracają.
Zacznij od kluczowych przepływów (signup, onboarding, pierwsza wartość, powracające użycie). Dla każdego przepływu wybierz 1–3 zdarzenia rezultatu, które dowodzą postępu. Jeśli śledzisz każde kliknięcie, utoniesz w szumie i nadal przegapisz to, co ważne.
Stosuj jedną konwencję nazewnictwa wszędzie i zapisz ją w prostym dokumencie. Cel: żeby dwie osoby niezależnie nazwały to samo zdarzenie i otrzymały tę samą nazwę.
Oto szybki pre-release check, który łapie większość wczesnych błędów:
- Outcome first: każdy kluczowy przepływ ma mały zestaw zdarzeń rezultatu, nie dziesiątki kliknięć UI.
- Nazwy są spójne: zdarzenia mają styl verb+noun i znaczenie każdego zdarzenia jest udokumentowane w jednym miejscu.
- Właściwości mają typy: krytyczne właściwości zachowują ten sam typ w każdym zdarzeniu (np. plan zawsze string, seat_count zawsze number).
- Dashboardy pasują do definicji: dashboard aktywacji używa twojego eventu aktywacji, a dashboard retencji — eventu retencji (nie przypadkowego proxy).
- QA jak użytkownik: przejdź aplikację i potwierdź, że zdarzenia odpala się raz, we właściwym momencie i z właściwymi właściwościami.
Prosty trik QA: przejdź pełną ścieżkę dwa razy. Pierwszy przebieg sprawdza aktywację. Drugi (po wylogowaniu i ponownym zalogowaniu lub powrocie następnego dnia) sprawdza sygnały retencji i zapobiega błędom podwójnego wysyłania.
Jeśli budujesz z Koder.ai, wykonaj tę samą QA po snapshot/rollback albo eksporcie kodu, żeby śledzenie zostało aktualne przy zmianach aplikacji.
Następne kroki: trzymaj to lekkie i iterujuj
Twoje pierwsze ustawienie śledzenia powinno być małe. Jeśli wdrożenie zajmuje tygodnie, będziesz unikać zmian, a dane zostaną w tyle za produktem.
Przyjmij prostą rutynę tygodniową: patrz na te same dashboardy, zapisz, co cię zaskoczyło, i zmieniaj śledzenie tylko wtedy, gdy masz jasny powód. Cel to nie „więcej zdarzeń”, tylko jaśniejsze odpowiedzi.
Dobra zasada: dodawaj 1–2 zdarzenia naraz, każde powiązane z jednym pytaniem, na które dziś nie potrafisz odpowiedzieć. Na przykład: „Czy użytkownicy, którzy zapraszają współpracownika, częściej się aktywują?” Jeśli już śledzisz invite_sent, ale nie invite_accepted, dodaj tylko brakujące zdarzenie i jedną właściwość do segmentacji (np. plan tier). Wdróż, obserwuj dashboard przez tydzień i potem decyduj o kolejnej zmianie.
Prosty rytm dla wczesnych zespołów:
- Przeglądaj dashboardy aktywacji i retencji raz w tygodniu, tego samego dnia i godziny
- Zapisz 3 wnioski i 1 pytanie follow-up
- Dodawaj lub dostosowuj śledzenie tylko jeśli to odblokowuje to pytanie
- Trzymaj nazwy zdarzeń stabilne; dodawaj właściwości zanim dodasz nowe zdarzenia
- Nic nie usuwaj, dopóki nie jesteś pewien, że jest nieużywane (usuwanie łamie trendy)
Prowadź mały changelog dla aktualizacji śledzenia, żeby wszyscy ufali liczbom później. Może to być dokument lub notka w repozytorium. Zawieraj:
- Data i właściciel
- Co się zmieniło (nazwa eventu/właściwości)
- Dlaczego to zmieniono (pytanie)
- Oczekiwany wpływ (które dashboardy dotyczy)
Jeśli budujesz pierwszą aplikację, zaplanuj przepływ przed implementacją czegokolwiek. W Koder.ai, Planning Mode to praktyczny sposób na opisanie kroków onboardingu i listy potrzebnych zdarzeń na każdym kroku, zanim powstanie kod.
Gdy iterujesz onboarding, chroń spójność śledzenia. Jeśli używasz snapshotów i rollbacków w Koder.ai, możesz zmieniać ekrany i kroki, zachowując jasny zapis, kiedy przepływ się zmienił — wtedy nagłe przesunięcia w aktywacji łatwiej wyjaśnić.