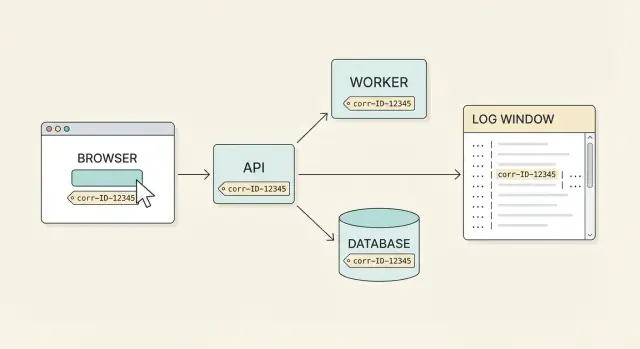
Dlaczego identyfikatory korelacyjne są ważne dla wsparcia
Support rzadko dostaje czyste zgłoszenie błędu. Użytkownik mówi: "Kliknąłem Zapłać i to się nie powiodło", ale to jedno kliknięcie może przejść przez przeglądarkę, gateway API, serwis płatności, bazę danych i zadanie w tle. Każdy element loguje swoją część historii w różnych momentach, na różnych maszynach. Bez wspólnej etykiety trudno ustalić, które linie logów należą do tej samej akcji.
Identyfikator korelacyjny to właśnie ta wspólna etykieta. To jeden ID przypisany do jednej akcji użytkownika (albo jednego logicznego workflowu) i przenoszony przez każde żądanie, retry i przeskok między serwisami. Przy prawdziwym pokryciu end-to-end możesz zacząć od zgłoszenia użytkownika i wyciągnąć pełny przebieg we wszystkich systemach.
Ludzie często mylą kilka podobnych ID. Oto klarowne rozróżnienie:
- Correlation ID: grupuje wszystko związane z jedną akcją (np. "Zapisz ustawienia").
- Request ID: identyfikuje jedno żądanie HTTP. Przy retry powstają nowe request ID.
- Trace ID: używany przez narzędzia do śledzenia rozproszonego; ma podobny cel, często generowany przez biblioteki śledzenia.
- Session ID: identyfikuje sesję użytkownika obejmującą wiele akcji; za szerokie do debugowania jednego incydentu.
Dobry przykład zastosowania jest prosty: użytkownik zgłasza problem, prosisz go o identyfikator korelacyjny pokazany w UI (lub znaleziony w ekranie wsparcia), i każdy w zespole może znaleźć pełną historię w kilka minut. Widzisz żądanie frontendu, odpowiedź API, kroki backendu i wynik bazy danych — wszystko powiązane jednym ID.
Ustal konwencje dla identyfikatorów korelacyjnych
Zanim zaczniesz generować ID, uzgodnij kilka zasad. Jeśli każdy zespół wybierze inny nagłówek lub pole w logu, support nadal będzie zgadywał.
Zacznij od jednej kanonicznej nazwy i używaj jej wszędzie. Częstym wyborem jest nagłówek HTTP, np. X-Correlation-Id, oraz strukturalne pole logu jak correlation_id. Wybierz jedno pisownię i jedną wielkość liter, udokumentuj to i upewnij się, że reverse proxy lub gateway nie zmieni ani nie usunie tego nagłówka.
Wybierz format, który łatwo wygenerować i bezpiecznie udostępnić w ticketach i czatach. UUIDy sprawdzają się dobrze, bo są unikalne i „nudne”. Trzymaj ID na tyle krótkie, by dało się je skopiować, ale nie tak krótkie, by ryzykować kolizje. Konsekwencja jest ważniejsza niż pomysłowość.
Zdecyduj także, gdzie ID musi się pojawiać, żeby ludzie mogli go używać. W praktyce oznacza to jego obecność w żądaniach, logach i komunikatach o błędach oraz możliwość wyszukiwania w narzędziu, z którego korzysta zespół.
Określ też, jak długo ma żyć jedno ID. Dobry domyślny czas to jedna akcja użytkownika, np. "kliknięto Zapłać" lub "zapisano profil". W dłuższych workflowach, które przechodzą przez serwisy i kolejki, trzymaj ten sam ID aż do zakończenia workflowu, a potem rozpocznij nowy dla następnej akcji. Unikaj "jednego ID dla całej sesji", bo wyszukiwania szybko staną się hałaśliwe.
Twarda zasada: nigdy nie umieszczaj w ID danych osobowych. Żadne e-maile, numery telefonów, identyfikatory użytkowników czy numery zamówień. Jeśli potrzebujesz kontekstu, loguj go w oddzielnych polach z odpowiednimi zasadami prywatności.
Generowanie ID we frontendzie (praktyczne podejście)
Najłatwiejsze miejsce na rozpoczęcie identyfikatora korelacyjnego to moment, gdy użytkownik zaczyna akcję, którą chcesz śledzić: kliknięcie "Zapisz", wysłanie formularza lub uruchomienie przepływu, który powoduje wiele żądań. Jeśli poczekasz, aż backend wygeneruje ID, często utracisz pierwszą część historii (błędy UI, retry, anulowane żądania).
Użyj losowego, unikalnego formatu. UUID v4 to częsty wybór, bo łatwo go wygenerować i ma niskie ryzyko kolizji. Trzymaj go jako wartość nieczytelną (opaque) — bez nazw użytkowników, e-maili czy znaczników czasu — żeby nie wyciekały dane osobowe w nagłówkach i logach.
Utwórz i zachowaj ID dla jednego workflowu
Traktuj "workflow" jako jedną akcję użytkownika, która może wywołać wiele żądań: walidacja, upload, utworzenie rekordu, odświeżenie list. Utwórz jedno ID na początku workflowu i zachowaj je do momentu zakończenia (sukces, porażka lub anulowanie przez użytkownika). Prosty wzorzec to przechowywanie go w stanie komponentu lub lekkim kontekście żądania.
Jeśli użytkownik uruchomi tę samą akcję dwa razy, wygeneruj nowy identyfikator korelacyjny dla drugiej próby. Dzięki temu support odróżni "ten sam klik z retrypem" od "dwóch niezależnych zgłoszeń".
Dołącz go do każdego żądania wywołanego przez workflow
Dodaj ID do każdego wywołania API uruchomionego przez workflow, zwykle przez nagłówek taki jak X-Correlation-ID. Jeśli używasz wspólnego klienta API (wrapper fetch, instancja Axios itp.), przekaż ID raz, a klient niech wstrzykuje go do wszystkich wywołań.
const correlationId = crypto.randomUUID();
await api.post('/orders', payload, {
headers: { 'X-Correlation-ID': correlationId }
});
await api.get('/orders/summary', {
headers: { 'X-Correlation-ID': correlationId }
});
Jeśli UI wykonuje zapytania w tle niezwiązane z akcją (polling, analytics, auto-refresh), nie używaj dla nich ID workflowu. Trzymaj identyfikatory korelacyjne skupione, żeby jedno ID opowiadało jedną historię.
Przekazywanie ID przez API w niezawodny sposób
Gdy już wygenerujesz identyfikator korelacyjny w przeglądarce, zadanie jest proste: musi on opuścić frontend w każdym żądaniu i dotrzeć niezmieniony na każde API boundary. To jest miejsce, w którym najczęściej coś się psuje, gdy zespoły dodają nowe endpointy, nowe klienty lub nowe middleware.
Najbezpieczniejszym domyślnym rozwiązaniem jest nagłówek HTTP w każdym wywołaniu (np. X-Correlation-Id). Nagłówki łatwo dodać w jednym miejscu (wrapper fetch, interceptor Axios, warstwa sieciowa w mobilnej aplikacji) i nie wymagają zmiany payloadów.
Jeśli masz żądania cross-origin, upewnij się, że API pozwala na ten nagłówek. W przeciwnym razie przeglądarka może go cicho zablokować i będziesz myślał, że go wysyłasz, a tak naprawdę nie.
Jeśli musisz umieścić ID w query stringu lub ciele żądania (niektóre narzędzia zewnętrzne lub uploady plików tego wymagają), trzymaj to spójne i udokumentowane. Wybierz jedno pole i używaj go wszędzie. Nie mieszaj correlationId, requestId i cid zależnie od endpointu.
Retry to kolejna pułapka. Retry powinien zachować ten sam identyfikator korelacyjny, jeżeli to wciąż ta sama akcja użytkownika. Przykład: użytkownik klika "Zapisz", sieć siada, klient retryuje POST. Support powinien zobaczyć jedną powiązaną ścieżkę, a nie trzy niezależne. Nowy klik (albo nowe zadanie background) powinno dostać nowy ID.
Dla WebSocketów dołączaj ID w kopercie wiadomości, a nie tylko w początkowym handshake. Jedne połączenie może przenosić wiele akcji użytkowników.
Jeśli chcesz szybkiego testu niezawodności, trzymaj to proste:
- Jeden wspólny helper klienta dodaje nagłówek do każdego żądania.
- Retry używają tego samego ID dla tej samej akcji.
- Każde body/query jako fallback używa jednego udokumentowanego pola.
- Wiadomości WebSocket zawierają wyraźne pole
correlationId.
Zachowanie punktu wejścia API
Śledź workflowy przez serwisy
Zaprojektuj propagację dla API, workerów i kolejek bez łamania łańcucha korelacji.
Edge API (gateway, load balancer lub pierwszy serwis otrzymujący ruch) to miejsce, gdzie identyfikatory korelacyjne albo stają się wiarygodne, albo zamieniają się w zgadywanie. Traktuj ten punkt wejścia jako źródło prawdy.
Akceptuj przychodzący ID, jeśli klient go wysłał, ale nie zakładaj, że zawsze będzie obecny. Jeśli go brakuje, wygeneruj nowy od razu i używaj go przez resztę obsługi żądania. Dzięki temu system działa nawet wtedy, gdy niektóre klienty są starsze lub źle skonfigurowane.
Wykonuj lekką walidację, żeby złe wartości nie zanieczyszczały logów. Bądź przy tym permissywny: sprawdź długość i dozwolone znaki, ale unikaj ścisłych formatów, które odrzucą rzeczywisty ruch. Na przykład pozwól na 16–64 znaków oraz litery, cyfry, myślnik i podkreślenie. Jeśli wartość nie przejdzie walidacji, zastąp ją nowym ID i kontynuuj.
Uczyń ID widocznym dla klienta. Zawsze zwracaj go w nagłówkach odpowiedzi i dołączaj go do ciał błędów. W ten sposób użytkownik może go skopiować z UI, a agent wsparcia może poprosić o niego i znaleźć dokładny ślad w logach.
Praktyczna polityka edge wygląda tak:
- Odczytaj
X-Correlation-ID (lub wybrany nagłówek) z żądania.
- Jeśli brakuje lub jest nieprawidłowy — stwórz nowy ID i dołącz do kontekstu żądania.
- Dodaj
X-Correlation-ID do każdej odpowiedzi, włącznie z błędami.
- Przy zwracaniu JSON-owych błędów, echo ID również w payloadzie.
Przykład payloadu błędu (co support powinien widzieć w ticketach i zrzutach ekranu):
{
"error": {
"code": "PAYMENT_FAILED",
"message": "We could not confirm the payment.",
"correlation_id": "c3a8f2d1-9b24-4c61-8c4a-2a7c1b9c2f61"
}
}
Propagacja ID przez serwisy backendowe
Gdy żądanie trafi do backendu, traktuj identyfikator korelacyjny jako część kontekstu żądania, a nie coś, co trzymasz w zmiennej globalnej. Globalne stają się problemem, gdy obsługujesz dwa żądania na raz albo gdy asynchroniczna praca trwa po wysłaniu odpowiedzi.
Zasada skalująca się: każda funkcja, która może logować lub wywołać inny serwis, powinna otrzymać kontekst zawierający ID. W serwisach Go zwykle oznacza to przekazywanie context.Context przez handlery, logikę biznesową i kod klienta.
Gdy Serwis A wywołuje Serwis B, skopiuj ten sam ID do wychodzącego żądania. Nie generuj nowego w trakcie przepływu, chyba że zachowasz oryginał jako oddzielne pole (np. parent_correlation_id). Jeśli zmienisz ID, support straci pojedynczą nić łączącą historię.
Propagacja często jest pomijana w kilku przewidywalnych miejscach: zadania background wyzwalane podczas żądania, retry wewnątrz bibliotek klientów, webhooki wyzwalane później i wywołania fan-out. Każda wiadomość asynchroniczna (kolejka/zadanie) powinna nieść ID, a każdy mechanizm retry powinien go zachować.
Logi powinny być strukturalne z ustalonym polem jak correlation_id. Wybierz jedną pisownię i trzymaj ją wszędzie. Unikaj mieszania requestId, req_id i traceId, chyba że masz jasne mapowanie.
Jeśli to możliwe, dołącz ID także do widoczności bazy danych. Praktyczne podejście to dodanie go do komentarzy zapytań lub metadanych sesji, żeby slow query logi mogły go pokazywać. Gdy ktoś zgłasza "Przycisk zapis zawiesił się przez 10 sekund", support może wyszukać correlation_id=abc123 i zobaczyć log API, wywołanie serwisu downstream i jedno wolne zapytanie SQL, które spowodowało opóźnienie.
Dołącz ID do logów, z których ludzie rzeczywiście skorzystają
Identyfikator korelacyjny pomaga tylko wtedy, gdy ludzie mogą go znaleźć i śledzić. Uczyń go polem pierwszej klasy w logu (nie ukrywaj wewnątrz tekstu wiadomości) i zachowaj spójność reszty wpisu logu między serwisami.
Pola logu, które czynią ID użytecznym
Sparuj identyfikator korelacyjny z małym zbiorem pól, które odpowiadają na: kiedy, gdzie, co i kto (bez ujawniania danych osobowych). Dla większości zespołów to znaczy:
timestamp (ze strefą czasową)service i env (api, worker, prod, staging)route (lub nazwa operacji) i methodstatus i duration_ms- bezpieczny identyfikator użytkownika (np.
account_id lub zahashowane ID, nie e-mail)
Dzięki temu support może wyszukać po ID, potwierdzić, że patrzy na właściwe żądanie i zobaczyć, który serwis je obsłużył.
Co logować na starcie, przy sukcesie i przy błędzie
Celuj w kilka silnych breadcrumbów na żądanie, nie w pełen transkrypt.
- Start: correlation ID, trasa, bezpieczny identyfikator użytkownika i kluczowe wejścia (zwięźle).
- Sukces: correlation ID, status, czas trwania i krótki wynik (np.
rows=12).
- Błąd: correlation ID, typ błędu, bezpieczny kontekst i miejsce wystąpienia (handler, zależność).
Aby unikać głośnych logów, trzymaj szczegóły debugowe domyślnie wyłączone i promuj tylko wpisy, które pomagają odpowiedzieć "gdzie się zepsuło?". Jeśli linia nie pomaga zlokalizować problemu lub zmierzyć wpływu, prawdopodobnie nie należy jej trzymać na poziomie info.
Redakcja ma taką samą wagę jak struktura. Nigdy nie umieszczaj PII w identyfikatorze korelacyjnym ani w logach: żadnych e-maili, imion, numerów telefonów, pełnych adresów czy surowych tokenów. Jeśli musisz zidentyfikować użytkownika, loguj wewnętrzne ID lub hashowaną wartość jednostronną.
Przykład: śledzenie jednego zgłoszenia użytkownika od UI do bazy
Prototypuj bezpieczny przepływ checkoutu
Zaprojektuj retry i timeouty w bezpieczny sposób, zachowując jeden identyfikator na akcję użytkownika.
Użytkownik pisze do supportu: "Checkout nie powiódł się, gdy kliknąłem Zapłać." Najlepsze pytanie follow-up to proste: "Czy możesz wkleić identyfikator korelacyjny pokazany na ekranie błędu?" Odpowiada cid=9f3c2b1f6a7a4c2f.
Support ma teraz uchwyt łączący UI, API i pracę w bazie. Celem jest, aby każda linia logu dla tej akcji miała ten sam ID.
Support wyszukuje w logach 9f3c2b1f6a7a4c2f i widzi przebieg:
frontend INFO cid=9f3c2b1f6a7a4c2f event="checkout_submit" cart=3 items
api INFO cid=9f3c2b1f6a7a4c2f method=POST path=/api/checkout user=1842
api ERROR cid=9f3c2b1f6a7a4c2f msg="payment failed" provider=stripe status=502
Stąd inżynier śledzi ten sam ID do następnego hopu. Kluczem jest to, że backendowe wywołania (i wszelkie zadania w kolejkach) też przekazują ID.
payments INFO cid=9f3c2b1f6a7a4c2f action="charge" amount=49.00 currency=USD
payments ERROR cid=9f3c2b1f6a7a4c2f err="timeout" upstream=stripe timeout_ms=3000
db INFO cid=9f3c2b1f6a7a4c2f query="insert into failed_payments" rows=1
Teraz problem jest konkretny: serwis płatności przekroczył czas po 3 sekundach i zapisano rekord błędu. Inżynier może sprawdzić ostatnie deploye, potwierdzić, czy ustawienia timeoutu się zmieniły, i zobaczyć, czy retry są wywoływane.
Aby domknąć pętlę, wykonaj cztery kroki sprawdzające:
- Napraw przyczynę (np. dostosuj timeout i dodaj bezpieczny retry).
- Upewnij się, że komunikaty widoczne dla użytkownika zawierają identyfikator korelacyjny.
- Monitoruj nowe logi z tym samym wzorcem błędu i różnymi ID.
- Potwierdź, że ID przeżywa każdy hop (włącznie z workerami i wiadomościami w kolejkach).
Typowe błędy i jak ich unikać
Najszybszy sposób, by uczynić identyfikatory korelacyjne bezużytecznymi, to przerwać łańcuch. Większość awarii wynika z małych decyzji, które wydają się nieszkodliwe podczas budowy, ale przeszkadzają, gdy support potrzebuje odpowiedzi.
Klasyczny błąd to generowanie nowego ID na każdym hopie. Jeśli przeglądarka wysyła ID, gateway API powinien go zachować, a nie zastępować. Jeśli naprawdę potrzebujesz wewnętrznego ID (np. dla wiadomości w kolejce), zachowaj oryginał jako pole parent, żeby historia nadal się łączyła.
Inna luka to częściowe logowanie. Zespoły dodają ID do pierwszego API, ale zapominają o workerach, zadaniach cyklicznych czy warstwie dostępu do bazy. Efekt to martwy koniec: widzisz żądanie wchodzące do systemu, ale nie wiesz, gdzie poszło dalej.
Unikaj problemu "naming chaos"
Nawet gdy ID jest wszędzie, może być trudno je wyszukać, jeśli każdy serwis używa innej nazwy pola lub formatu. Wybierz jedną nazwę i trzymaj się jej we frontendzie, API i logach (np. correlation_id). Wybierz też jeden format (często UUID) i traktuj go jako rozróżniający wielkość liter, aby kopiuj-wklej działało bez niespodzianek.
Nie trać ID, gdy coś pójdzie źle. Jeśli API zwraca 500 lub błąd walidacji, dołącz identyfikator korelacyjny w odpowiedzi (i najlepiej także w nagłówku). Dzięki temu użytkownik może wkleić go do czatu z supportem, a zespół od razu znajdzie pełną ścieżkę.
Szybki test: czy osoba z supportu może zacząć od jednego ID i śledzić każdą linię logu związaną z żądaniem, włącznie z błędami?
Szybka lista kontrolna, by zweryfikować pokrycie end-to-end
Dostarczaj ekrany błędów gotowe dla supportu
Twórz komunikaty błędów w UI, które pokazują kopiowalny identyfikator korelacyjny, aby przyspieszyć zgłoszenia.
Użyj tego jako sanity checka, zanim powiesz supportowi „po prostu przeszukaj logi”. To działa tylko, gdy każdy hop stosuje te same zasady.
Warunki konieczne
- Masz jeden format ID i jedną nazwę nagłówka, używaną wszędzie (frontend, gateway, API, workery).
- Frontend tworzy (lub otrzymuje) ID na początku akcji i utrzymuje je stabilnie do końca tej akcji.
- Punkt wejścia API tworzy ID, jeśli go brakuje, i zawsze zwraca je w nagłówkach odpowiedzi.
- Każdy backendowy serwis zawiera
correlation_id w logach związanych z żądaniami jako pole strukturalne.
- Osoba na służbie może wkleić jedno ID w wyszukiwarce logów i zobaczyć całą ścieżkę w kilka minut: żądanie edge, auth, wywołania serwisów, operację bazy danych i retry.
Jeśli jakiś punkt zawiedzie, napraw to tak:
Wybierz najmniejszą zmianę, która sprawi, że łańcuch nie będzie przerwany.
- Jeśli ID zmieniają się w trakcie przepływu, przestań generować nowe ID wewnątrz serwisów. Zachowaj oryginalne
correlation_id i dodaj osobne span_id, jeśli potrzebujesz więcej szczegółów.
- Jeśli w logach brakuje pola, dodaj middleware logujący, żeby inżynierowie nie musieli pamiętać o jego dołączaniu.
- Jeśli support nie może uzyskać ID, upewnij się, że UI je pokazuje na ekranach błędów i że gateway odzwierciedla je we wszystkich odpowiedziach.
Szybki test, który wykrywa braki: otwórz devtools, wywołaj akcję, skopiuj identyfikator korelacyjny z pierwszego żądania, a następnie potwierdź, że widzisz tę samą wartość we wszystkich powiązanych nagłówkach API i w każdym odpowiadającym wpisie w logach.
Kolejne kroki: wpisz to w proces wydawniczy
Identyfikatory korelacyjne pomagają tylko wtedy, gdy wszyscy używają ich w ten sam sposób, za każdym razem. Traktuj zachowanie związane z correlation ID jako wymagany element definicji ukończenia zadania (definition of done), a nie jako miły dodatek do logowania.
Dodaj mały krok śledzalności do definicji gotowości dla każdego nowego endpointu lub akcji UI. Opisz, jak ID jest tworzone (lub ponownie używane), gdzie przechowuje się podczas przepływu, który nagłówek go niesie i co robi każdy serwis, gdy nagłówek jest nieobecny.
Lekka lista kontrolna wystarczy:
- Frontend: wygeneruj lub użyj jednego ID na akcję użytkownika i dołącz go do każdego wywołania API tej akcji.
- Punkt wejścia API: akceptuj nagłówek, waliduj lub generuj, a następnie echo w odpowiedzi.
- Backend: przekazuj go do serwisów downstream i zadań, i dołączaj do logów.
- Logowanie: trzymaj spójną nazwę pola (np.
correlation_id) we wszystkich aplikacjach i serwisach.
- Przeglądy: odrzucaj PR-y, które dodają endpointy bez testów potwierdzających, że ID pojawia się w logach.
Support potrzebuje też prostego skryptu, aby debugowanie było szybkie i powtarzalne. Zdecyduj, gdzie ID pokazuje się użytkownikom (np. przycisk "Kopiuj debug ID" w dialogach błędów) i zapisz, o co support ma pytać i gdzie szukać.
Zanim polegasz na tym w produkcji, przeprowadź etapowany przepływ, który odpowiada rzeczywistemu użyciu: kliknij przycisk, wywołaj błąd walidacji, potem dokończ akcję. Potwierdź, że możesz śledzić ten sam ID od żądania w przeglądarce, przez logi API, do jakiegokolwiek workera i aż do logów wywołań bazy danych, jeśli je rejestrujesz.
Jeśli budujesz aplikacje na Koder.ai, warto wpisać konwencje nagłówka i logowania identyfikatorów korelacyjnych do Planning Mode, żeby generowane frontendy React i serwisy Go były zgodne domyślnie.