27 sie 2025·7 min
Pule workerów w Go dla zadań w tle: retry, anulowanie, zamykanie
Pule workerów w Go pozwalają małym zespołom obsługiwać zadania w tle z retry, anulowaniem i czystym zamykaniem przy użyciu prostych wzorców, zanim dodasz cięższą infrastrukturę.
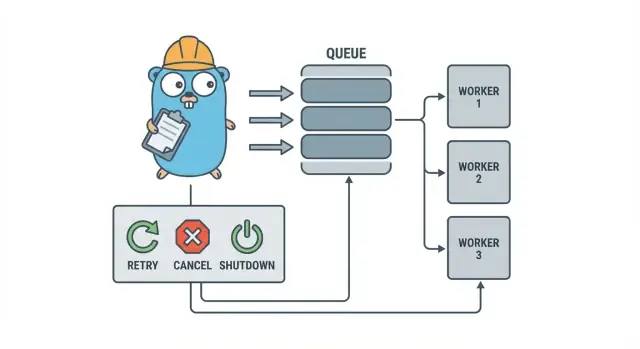
Dlaczego zadania w tle szybko się komplikują
W małej usłudze napisanej w Go praca w tle zwykle zaczyna się od prostego celu: szybko zwrócić odpowiedź HTTP, a wolne zadania wykonać później. To mogą być wysyłki e-maili, zmiana rozmiaru obrazów, synchronizacja z innym API, przebudowa indeksów wyszukiwania czy nocne raporty.
Problem w tym, że te zadania to pełnoprawna praca produkcyjna, tylko bez zabezpieczeń, które naturalnie masz przy obsłudze żądań. Goroutine uruchomiona z handlera HTTP wydaje się w porządku, dopóki nie nastąpi deploy w trakcie pracy, upstreamowe API nie spowolni albo to samo żądanie nie zostanie ponowione i nie uruchomi zadania dwukrotnie.
Pierwsze punkty bólu są przewidywalne:
- Zawieszone zadania: jedno wywołanie wiszące powoduje, że workerzy przestają posuwać się naprzód.
- Duplikacja pracy: retry na warstwie HTTP uruchamia to samo zadanie ponownie.
- Brak planu zamknięcia: proces kończy się i praca jest utracona lub wykonana połowicznie.
- Ciche błędy: błędy są logowane raz (albo wcale) i znikają.
- Burze ponowień: zawodzące zadania retryują natychmiast i obciążają zależności.
Właśnie tutaj pomaga mały, jawny wzorzec, taki jak pula workerów w Go. Pozwala kontrolować konkurencję (N workerów), zmienia „zrób to później” w jasny typ zadania i daje jedno miejsce do obsługi retry, timeoutów i anulowania.
Przykład: SaaS musi wysyłać faktury. Nie chcesz 500 jednoczesnych wysyłek po masowym imporcie i nie chcesz wysyłać tej samej faktury ponownie, bo żądanie zostało ponowione. Pula workerów pozwala ograniczyć przepustowość i traktować „wyślij fakturę #123” jako śledzony element pracy.
Pula workerów nie jest właściwym narzędziem, gdy potrzebujesz trwałych gwarancji międzyprocesowych. Jeśli zadania muszą przetrwać awarie, być harmonogramowane na przyszłość lub obsługiwane przez wiele usług, prawdopodobnie będziesz potrzebować prawdziwej kolejki i trwałego magazynu stanu zadań.
Model puli workerów prostym językiem
Pula workerów w Go jest celowo nudna: włóż pracę do kolejki, stała liczba workerów pobiera ją i upewnij się, że wszystko można zatrzymać w czysty sposób.
Podstawowe pojęcia:
- Zadanie (Job): jedna jednostka pracy, np. „zmień rozmiar tego obrazu” lub „wyślij tego maila z fakturą”.
- Kolejka: miejsce, gdzie zadania czekają.
- Worker: goroutine, która w pętli pobiera zadanie i je wykonuje.
- Dispatcher: komponent przyjmujący zadania i wkładający je do kolejki.
W wielu konstrukcjach in-process rolę kolejki pełni kanał Go. Buforowany kanał może pomieścić ograniczoną liczbę zadań zanim producenci się zablokują. To blokowanie to backpressure i często to właśnie chroni usługę przed akceptowaniem nieograniczonej pracy i wyczerpaniem pamięci przy nagłych skokach ruchu.
Rozmiar bufora zmienia odczucie systemu. Mały bufor szybko ujawnia presję (callerzy czekają wcześniej). Większy bufor wygładza krótkie skoki, ale może ukryć przeciążenie do później. Nie ma idealnej liczby, jest tylko liczba pasująca do tego, ile czekania możesz tolerować.
Możesz też zdecydować, czy rozmiar puli jest stały, czy zmienny. Stałe pule są łatwiejsze do zrozumienia i utrzymują przewidywalne użycie zasobów. Auto-skalowanie workerów pomaga przy nierównym obciążeniu, ale dodaje decyzje do utrzymania (kiedy skalać, o ile, kiedy zmniejszać).
Wreszcie, „ack” w pulach in-process zwykle oznacza po prostu „worker zakończył zadanie i zwrócił brak błędu”. Nie ma zewnętrznego brokera potwierdzającego dostarczenie, więc to twój kod definiuje, co oznacza „zrobione” i co się dzieje, kiedy zadanie zawiedzie lub zostanie anulowane.
Cele projektowe: retry, anulowanie i czyste zamykanie
Mechanicznie pula workerów jest prosta: uruchom stałą liczbę workerów, nakarm ich zadaniami i przetwarzaj. Wartość to kontrola: przewidywalna konkurencja, jasna obsługa błędów i ścieżka zamknięcia, która nie zostawia pracy w połowie wykonania.
Trzy cele, które pomagają małym zespołom zachować spokój:
- Ograniczyć konkurencję, by pojedynczy skok nie stopił bazy danych ani zewnętrznego API.
- Unikać utraty pracy (albo przynajmniej wiedzieć dokładnie, co zostało porzucone i dlaczego).
- Pozostać debugowalnym: każde zadanie powinno być śledzalne w logach i kilku licznikach.
Większość awarii jest nudna, ale chcesz traktować je różnie:
- Błędy przejściowe (network hiccups, rate limits) — warto retryować.
- Błędy trwałe (złe dane wejściowe, brak rekordu) — nie retryować.
- Timeouty (zależność wisi) — trzeba je przerwać, by workerzy się nie zapchali.
Anulowanie to nie to samo co „błąd”. To decyzja: użytkownik anulował, deploy zastąpił proces albo usługa się wyłącza. W Go traktuj anulowanie jako sygnał pierwszej klasy używając context cancellation i upewnij się, że każde zadanie sprawdza go przed rozpoczęciem kosztownych operacji i w kilku bezpiecznych punktach w trakcie wykonania.
Czyste zamknięcie to miejsce, gdzie wiele pul zawodzi. Zdecyduj wcześnie, co dla twoich zadań znaczy „bezpieczne”: dokańczasz zadania w locie, czy zatrzymujesz się szybko i uruchomisz później? Praktyczny przepływ to:
- Przestań przyjmować nowe zadania.
- Powiedz workerom, by skończyli bieżące zadanie (lub zatrzymali się natychmiast).
- Poczekaj do deadline’u, potem wymuś zakończenie.
Jeśli zdefiniujesz te reguły wcześnie, retry, anulowanie i zamykanie pozostaną małe i przewidywalne zamiast rozrastać się w domowej roboty framework.
Krok po kroku: zbuduj podstawową pulę workerów
Pula workerów to grupa goroutines pobierających zadania z kanału i wykonujących je. Ważne jest uczynienie podstaw przewidywalnymi: jak wygląda zadanie, jak workerzy się zatrzymują i jak wiesz, kiedy cała praca jest skończona.
Zacznij od prostego typu Job. Daj mu ID (dla logów), payload (co przetwarzać), licznik prób (przydatny później do retry), znaczniki czasu i miejsce na kontekst per-zadanie.
package jobs
import (
"context"
"sync"
"time"
)
type Job struct {
ID string
Payload any
Attempt int
Enqueued time.Time
Started time.Time
Ctx context.Context
Meta map[string]string
}
type Pool struct {
ctx context.Context
cancel context.CancelFunc
jobs chan Job
wg sync.WaitGroup
}
func New(size, queue int) *Pool {
ctx, cancel := context.WithCancel(context.Background())
p := &Pool{ctx: ctx, cancel: cancel, jobs: make(chan Job, queue)}
for i := 0; i < size; i++ {
go p.worker(i)
}
return p
}
func (p *Pool) worker(_ int) {
for {
select {
case <-p.ctx.Done():
return
case job, ok := <-p.jobs:
if !ok {
return
}
p.wg.Add(1)
job.Started = time.Now()
_ = job // call your handler here
p.wg.Done()
}
}
}
// Submit blocks when the queue is full (backpressure).
func (p *Pool) Submit(job Job) error {
if job.Enqueued.IsZero() {
job.Enqueued = time.Now()
}
select {
case <-p.ctx.Done():
return context.Canceled
case p.jobs <- job:
return nil
}
}
func (p *Pool) Stop() { p.cancel() }
func (p *Pool) Wait() { p.wg.Wait() }
Kilka praktycznych wyborów, które podejmiesz od razu:
- Wybierz rozmiar kolejki na podstawie tego, ile czekania możesz tolerować.
- Zdecyduj, co oznacza backpressure dla callerów: blokować, zwracać błąd czy porzucać zadanie.
- Trzymaj
Stop()iWait()osobno, żeby najpierw zamknąć przyjmowanie, a potem poczekać na zadania w locie.
Dodawanie retry bez tworzenia frameworku
Retry są przydatne, ale też to miejsce, gdzie pule workerów się komplikują. Trzymaj cel wąski: retryuj tylko wtedy, gdy kolejna próba ma realne szanse na powodzenie i szybko przestawiaj się, gdy nie.
Zacznij od zdecydowania, co jest retryowalne. Problemy tymczasowe (network hiccups, timeouty, odpowiedzi „spróbuj później”) zwykle warto retryować. Problemy trwałe (złe dane, brak rekordu, odmowa dostępu) — nie.
Mała polityka retry zwykle wystarcza:
- Oznaczaj błędy jako retryowalne lub nie (np. owijając je helperem
Retryable(err)). - Ustaw maksymalną liczbę prób (zwykle 3–5). Powyżej tego zwykle tylko marnujesz czas.
- Użyj wykładniczego backoffu z jitterem, żeby zadania nie retryowały synchronicznie.
- Ogranicz delay (np. nigdy nie śpij więcej niż 30s).
- Loguj retry z numerem próby, kolejnym opóźnieniem i ID zadania.
Backoff nie musi być skomplikowany. Typowy kształt to: delay = min(base * 2^(attempt-1), max), potem dodaj jitter (losuj +/- 20%). Jitter ma znaczenie, bo w przeciwnym razie wielu workerów zawiedzie razem i retryuje razem.
Gdzie powinien żyć delay? W małych systemach spanie wewnątrz workera jest w porządku, ale zajmuje slot workera. Jeśli retry są rzadkie, to akceptowalne. Jeśli retry są częste lub opóźnienia długie, rozważ ponowne wstawianie zadania z polami „run after”, żeby workerzy byli zajęci inną pracą.
Na ostateczną porażkę bądź jawny. Przechowaj nieudane zadanie (i ostatni błąd) do przeglądu, zaloguj wystarczający kontekst, by je odtworzyć, albo włóż je na listę martwych zadań, którą regularnie sprawdzasz. Unikaj cichych porzuceń. Pula, która ukrywa porażki, jest gorsza niż brak retry.
Anulowanie i timeouty, które rzeczywiście zatrzymują pracę
Wdróż swojego background workera
Wdróż swoją aplikację Go z pomocą hostingu, gdy będziesz gotowy do uruchomienia.
Pule workerów są bezpieczne tylko wtedy, gdy możesz je zatrzymać. Najprostsza zasada: przekaż context.Context przez każdą warstwę, która może się zablokować. To oznacza submisję, wykonanie i sprzątanie.
Praktyczne ustawienie używa dwóch limitów czasu:
- timeout na zadanie tak, żeby pojedyncze zadanie nie zajmowało workera na zawsze.
- timeout zamknięcia tak, żeby proces mógł wyjść, nawet jeśli niektóre zadania nie współpracują.
Używaj context end-to-end
Daj każdemu zadaniu własny kontekst pochodny od kontekstu workera. Wtedy każde wolne wywołanie (DB, HTTP, kolejki, I/O) musi używać tego kontekstu, by mogło wrócić wcześniej.
func worker(ctx context.Context, jobs <-chan Job) {
for {
select {
case <-ctx.Done():
return
case job, ok := <-jobs:
if !ok { return }
jobCtx, cancel := context.WithTimeout(ctx, job.Timeout)
_ = job.Run(jobCtx) // Run must respect jobCtx
cancel()
}
}
}
Jeśli Run wywołuje DB lub API, przekaż kontekst do tych wywołań (np. QueryContext, NewRequestWithContext albo metody klienta akceptujące context). Jeśli to zignorujesz w jednym miejscu, anulowanie stanie się „best effort” i zwykle zawiedzie wtedy, gdy najbardziej tego potrzebujesz.
Częściowa praca i kroki „bezpieczne do retryu”
Anulowanie może nastąpić w połowie zadania, więc zakładaj, że częściowa praca jest normalna. Dąż do idempotentnych kroków, żeby ponowne uruchomienia nie tworzyły duplikatów. Częste podejścia to użycie unikalnych kluczy dla insertów (albo upsertów), zapisywanie markerów postępu (started/done), zapis wyników przed kontynuacją oraz sprawdzanie ctx.Err() między krokami.
Traktuj zamknięcie jak deadline: przestań przyjmować nowe zadania, anuluj konteksty workerów i czekaj tylko do timeoutu zamknięcia, by zadania w locie mogły się zakończyć.
Czyste zamknięcie: co robić, gdy proces musi wyjść
Czyste zamknięcie ma jeden cel: przestać przyjmować nową pracę, powiedzieć pracy w locie, by się zatrzymała, i wyjść bez pozostawiania systemu w dziwnym stanie.
Zacznij od sygnałów. W większości wdrożeń zobaczysz SIGINT lokalnie i SIGTERM od managera procesu lub runtime kontenera. Użyj kontekstu zamknięcia, który jest anulowany po otrzymaniu sygnału i przekaż go do puli oraz handlerów zadań.
Następnie przestań przyjmować nowe zadania. Nie pozwól callerom blokować się na zawsze próbując wstawić zadanie do kanału, z którego nikt już nie czyta. Trzymaj submisję za jedną funkcją, która sprawdza flagę zamknięcia lub wybiera select na shutdown context przed wysłaniem.
Potem zdecyduj, co zrobić z pracą w kolejce:
- Odsącz (Drain): dokończ to, co już jest w kolejce, ale odrzucaj nowe submisje.
- Porzuć (Drop): odrzuć wszystko, co jeszcze nie zostało rozpoczęte.
Draining jest bezpieczniejsze dla rzeczy takich jak płatności i e-maile. Dropping jest w porządku dla zadań „miło mieć” jak przeliczanie cache.
Praktyczna sekwencja zamknięcia:
- Złap SIGINT/SIGTERM i anuluj współdzielony context.
- Przestań przyjmować submisje (zamknij ścieżkę submisji, niekoniecznie kanał pracy).
- Pozwól workerom dokończyć lub przerwać zadania bazując na kontekście.
- Poczekaj na workerów z użyciem WaitGroup.
- Wymuś deadline, potem wyjdź.
Deadline ma znaczenie. Na przykład daj zadaniom w locie 10 sekund na zatrzymanie. Po tym zaloguj, co nadal działa i wyjdź. To utrzymuje deployy przewidywalne i zapobiega zawieszonym procesom.
Logowanie i proste metryki dla pul workerów
Zdobądź kredyty na następny build
Opublikuj krótkie podsumowanie i zdobądź kredyty, które wykorzystasz w Koder.ai.
Kiedy pula workerów przestaje działać, rzadko robi to głośno. Zadania zwalniają, retry się piętrzą i ktoś zgłasza, że „nic się nie dzieje”. Logi i kilka podstawowych liczników zamieniają to w jasną historię.
Nadaj każdemu zadaniu stabilny ID (lub generuj go przy submisji) i dołączaj go do każdej linii logu. Trzymaj logi spójne: jedna linia przy starcie zadania, jedna przy zakończeniu i jedna przy błędzie. Jeśli retry, loguj numer próby i następne opóźnienie.
Prosty kształt logu:
- start: job_id, worker_id, attempt, kind
- finish: job_id, worker_id, attempt, duration_ms
- fail/retry: job_id, worker_id, attempt, err, next_delay_ms
Metryki mogą pozostać minimalne, a i tak się opłaci. Śledź długość kolejki, liczbę zadań w locie, łączne sukcesy i błędy oraz latencję zadań (przynajmniej średnią i maksymalną). Jeśli długość kolejki rośnie, a in-flight jest na poziomie liczby workerów, jesteś nasycony. Jeśli submitterzy blokują się przy wysyłaniu do kanału jobs, backpressure sięga do callerów. To nie zawsze źle, ale powinno być świadome.
Gdy „zadania stoją”, sprawdź, czy proces nadal otrzymuje zadania, czy długość kolejki rośnie, czy workerzy żyją i które zadania działają najdłużej. Długie czasy zwykle wskazują na brak timeoutów, wolne zależności lub pętlę retry, która nigdy się nie kończy.
Realistyczny przykład: mała kolejka background w SaaS
Wyobraź sobie mały SaaS, w którym zamówienie przechodzi na PAID. Bezpośrednio po płatności musisz wygenerować PDF faktury, wysłać e-mail do klienta i powiadomić zespół. Nie chcesz, żeby ta praca blokowała request webowy. To dobry przypadek dla puli workerów, bo praca jest realna, a system wciąż jest mały.
Payload zadania może być minimalny: tylko tyle, by pobrać resztę z bazy. Handler API zapisuje w tej samej transakcji co aktualizacja zamówienia wiersz jobs(status='queued', type='send_invoice', payload, attempts=0), potem pętla w tle sondyje kolejkowane zadania i wrzuca je do kanału workerów.
type SendInvoiceJob struct {
OrderID string
CustomerID string
Email string
}
Gdy worker je pobierze, ścieżka szczęśliwa jest prosta: załaduj zamówienie, wygeneruj fakturę, wywołaj provider e-mailowy, a potem oznacz zadanie jako zakończone.
To retry robią różnicę. Jeśli provider e-mailowy ma tymczasową awarię, nie chcesz, by 1000 zadań padało na zawsze albo by bombardowały provider co sekundę. Praktyczne podejście:
- Traktuj błędy sieciowe i odpowiedzi 5xx jako retryowalne.
- Użyj wykładniczego backoff z maksymalnym opóźnieniem (np. 5s, 15s, 45s, 2m).
- Ogranicz liczbę prób (np. 10) i potem oznacz zadanie jako nieudane.
- Zapisz ostatni błąd, żeby support widział, co się stało.
W czasie awarii zadania przechodzą z queued do in_progress, potem z powrotem do queued z przyszłym czasem uruchomienia. Gdy provider wróci, workerzy naturalnie przepustują zaległości.
Teraz wyobraź sobie deploy. Wysyłasz SIGTERM. Proces powinien przestać przyjmować nową pracę, ale dokończyć to, co już jest w locie. Przestań sondować, przestań wrzucać do kanału workerów i poczekaj na workerów z deadline. Zadania, które się skończą, zostaną oznaczone jako done. Zadania, które nadal działają po upływie deadline, powinny być oznaczone z powrotem jako queued (albo pozostawione jako in_progress z watchdogiem), żeby mogły być odebrane po starcie nowej wersji.
Częste błędy i pułapki
Większość błędów w background processing nie leży w logice zadania. Wynikają z koordynacji, które pojawiają się dopiero pod obciążeniem lub podczas zamykania.
Klasyczna pułapka to zamknięcie kanału z więcej niż jednego miejsca. Rezultatem jest panic trudna do powtórzenia. Wybierz jednego właściciela dla każdego kanału (zwykle producent) i niech tylko on wywołuje close(jobs).
Retry to kolejny obszar, gdzie dobre intencje powodują outage. Jeśli retryujesz wszystko, retryujesz też błędy trwałe. To marnuje czas, zwiększa obciążenie i może zmienić drobny problem w incydent. Klasyfikuj błędy i ogranicz retry jasną polityką.
Duplikaty się zdarzą nawet przy ostrożnym projekcie. Worker może paść w trakcie pracy, timeout może wystrzelić po zakończeniu pracy albo podczas deployu możesz ponownie wstawić zadanie. Jeśli zadanie nie jest idempotentne, duplikaty robią szkody: dwie faktury, dwa e-maile powitalne, dwa zwroty.
Najczęściej pojawiające się błędy:
- Zamknięcie tego samego kanału z więcej niż jednej gorutiny.
- Retryowanie błędów trwałych zamiast ich nagłośnienia.
- Brak klucza idempotencji, co powoduje podwójne skutki uboczne.
- Niezboundedowane kolejki w pamięci rosnące aż do skoku pamięci.
- Ignorowanie
context.Context, więc praca trwa po rozpoczęciu zamknięcia.
Niezboundedowane kolejki są szczególnie podstępne. Skok pracy może cicho narastać w RAM. Preferuj ograniczony bufor kanału i zadecydować, co się dzieje, gdy się zapełni: blokuj, porzuć czy zwróć błąd.
Szybka lista kontrolna przed wypuszczeniem
Zbuduj czyste zamykanie w Go
Utwórz obsługę sygnałów i timeouty context w kilka minut z promptu.
Zanim wypuścisz pulę workerów do produkcji, powinieneś umieć opisać cykl życia zadania na głos. Jeśli ktoś zapyta „gdzie jest teraz to zadanie?”, odpowiedź nie powinna być zgadywanką.
Praktyczna pre-flight lista:
- Potrafisz nazwać każdy stan i przejście: queued, picked up, running, finished, failed (i co je przesuwa między stanami).
- Konkurencja to jeden suwak (np.
workerCount), a zmiana go nie wymaga przepisywania kodu. - Retry są ograniczone: maks liczba prób jasna, backoff rośnie, a błędy trwałe idą tam, gdzie trzeba.
- Zachowanie przy zamknięciu jest przetestowane: przestajesz przyjmować, pozwalasz zadaniom w locie dokończyć i masz twardy timeout.
- Logi odpowiadają na podstawy: job ID, numer próby, czas trwania i powód błędu.
Przeprowadź jeden realistyczny drill przed wydaniem: wstaw 100 zadań „wyślij potwierdzenie”, zmusz 20 do niepowodzenia, potem zrestartuj serwis w trakcie działania. Powinieneś zobaczyć oczekiwane retry, brak podwójnych skutków ubocznych i rzeczywiste zatrzymanie pracy po upływie deadline.
Jeśli którykolwiek punkt jest niejasny, dopracuj go teraz. Małe poprawki tu oszczędzają dni później.
Następne kroki: kiedy dodać cięższą infrastrukturę (a kiedy nie)
Prosta pula in-process często wystarcza, gdy produkt jest młody. Jeśli twoje zadania są „miło mieć” (wysyłki e-mail, odświeżanie cache, generowanie raportów) i możesz je ponownie uruchomić, pula workerów utrzymuje system prostym do zrozumienia.
Znaki, że przerastasz pulę in-process
Obserwuj te punkty krytyczne:
- Uruchamiasz wiele instancji aplikacji i chcesz, żeby tylko jedna z nich pobierała zadania.
- Potrzebujesz trwałości (zadania muszą przetrwać awarie i deployy).
- Potrzebujesz audytu: kto i kiedy wstawił zadanie, kiedy wykonało się i jaki był wynik.
- Potrzebujesz kontroli backpressure między usługami, nie tylko wewnątrz procesu.
- Potrzebujesz ścisłego harmonogramowania albo długich opóźnień (godziny/dni) z niezawodnym budzeniem.
Jeśli żadne z powyższych nie jest prawdą, cięższe narzędzia mogą dodać więcej ruchomych części niż wartości.
Migracja stopniowa bez przepisywania
Najlepsze zabezpieczenie to stabilny interfejs zadania: mały typ payload, ID i handler zwracający jasny wynik. Dzięki temu możesz zmienić backend kolejki później (z kanału in-memory na tabelę w bazie, a dopiero potem na dedykowaną kolejkę) bez zmiany logiki biznesowej.
Praktyczny środek to mała usługa Go czytająca zadania z PostgreSQL, rezerwująca je lockiem i aktualizująca status. Dostajesz trwałość i podstawowy audyt, zachowując tę samą logikę workerów.
Jeśli chcesz szybko prototypować, Koder.ai (koder.ai) może wygenerować starter Go + PostgreSQL z promptu, łącznie z tabelą zadań w tle i pętlą workerów, a jego snapshoty i rollback pomogą podczas strojenia retry i zachowania przy zamknięciu.