29 gru 2025·8 min
Narzędzia admina zapobiegające utracie danych: bezpieczne operacje zbiorcze
Narzędzia admina zapobiegające utracie danych stosują bezpieczniejsze działania zbiorcze, jasne potwierdzenia, miękkie usuwanie, dzienniki audytu i limity ról, aby operatorzy unikali kosztownych błędów.
Gdzie w adminie dochodzi do utraty danych
Wewnętrzne narzędzia administracyjne wydają się bezpieczniejsze, bo „korzystają z nich tylko pracownicy”. Ta ufność właśnie czyni je wysokiego ryzyka. Osoby je obsługujące mają uprawnienia, działają szybko i często robią tę samą operację wiele razy dziennie. Jeden błąd może dotknąć tysiące rekordów.
Większość wypadków nie wynika ze złej woli. To momenty typu oops: filtr za szeroki, fraza wyszukiwania dopasowująca więcej niż myślano, albo lista rozwijalna ustawiona na niewłaściwego klienta. Klasyczny błąd to też niewłaściwe środowisko: ktoś myśli, że jest na stagingu, a patrzy na produkcję, bo UI wygląda prawie identycznie.
Szybkość i powtarzalność pogarszają sprawę. Gdy narzędzie jest zbudowane pod szybkie działanie, użytkownicy uczą się pamięci mięśniowej: klik, potwierdź, następny. Jeśli ekran laguje, klikają dwa razy. Jeśli akcja zbiorcza trwa, otwierają drugą kartę. Te nawyki są normalne, ale tworzą warunki do pomyłek.
„Niszczenie danych” to nie tylko wciśnięcie przycisku usuń. W praktyce może oznaczać:
- Usuwanie rekordów (w tym kaskadowe usunięcia)
- Nadpisywanie pól (np. ustawienie statusu na zamknięty dla niewłaściwego zbioru)
- Odłączanie relacji (odlinkowanie użytkownika od konta, usunięcie uprawnień)
- Czyszczenie historii (kasowanie logów, wiadomości, skracanie tabel)
- Nieodwracalne eksporty lub synchronizacje (wypchnięcie złych danych do innego systemu)
Dla zespołów tworzących narzędzia admina zapobiegające utracie danych „wystarczająco bezpieczne” powinno być jasnym porozumieniem, a nie wrażeniem. Prosta definicja: pospieszny operator powinien móc naprawić typowy błąd bez pomocy inżynierów, a rzadkie, nieodwracalne akcje powinny wymagać dodatkowego tarcia, jasnego dowodu intencji i zapisu, który można później audytować.
Nawet jeśli budujesz aplikacje szybko na platformie takiej jak Koder.ai, te ryzyka są takie same. Różnica jest w tym, czy od pierwszego dnia projektujesz bariery ochronne, czy czekasz na pierwszy incydent, który wszystkiego nauczy.
Zacznij od prostej mapy ryzyka
Zanim zmienisz UI, ustal, co naprawdę może pójść nie tak. Mapa ryzyka to krótka lista operacji, które mogą wyrządzić realną szkodę, oraz zasady, które muszą je otaczać. Ten krok oddziela narzędzia admina, które rzeczywiście zapobiegają utracie danych, od tych, które tylko wyglądają ostrożnie.
Zacznij od spisania najniebezpieczniejszych działań. Zwykle to nie codzienne edycje. To operacje, które zmieniają wiele rekordów szybko lub dotykają wrażliwych danych.
Przydatny pierwszy przegląd:
- Usunięcie, scalanie, zamykanie lub twarde wyłączenie kont
- Zmiana właściciela (klienci, faktury, zgłoszenia, leady)
- Importy i masowe aktualizacje (CSV, zadania API, migracje)
- Operacje rozliczeniowe (zwroty, kredyty, anulowania)
- Zmiany uprawnień (role, dostęp do PII)
Następnie oznacz każdą akcję jako odwracalną lub nieodwracalną. Bądź surowy. Jeśli można cofnąć tylko przez odtworzenie z backupu, traktuj to jako nieodwracalne dla operatora, który wykonuje pracę.
Potem zdecyduj, co musi być chronione polityką, a nie tylko projektem. Zasady prawne i prywatności często dotyczą danych osobowych (imiona, e-maile, adresy), zapisów rozliczeniowych i dzienników audytu. Nawet jeśli narzędzie technicznie może coś usunąć, polityka może wymagać retencji lub przeglądu przez dwie osoby.
Oddziel operacje rutynowe od wyjątkowych. Prace rutynowe powinny być szybkie i bezpieczne (małe zmiany, jasne cofanie). Prace wyjątkowe celowo powinny być wolniejsze (dodatkowe kontrole, zatwierdzenia, ściślejsze limity).
Na koniec uzgodnij proste terminy dla zakresu wpływu, aby wszyscy mówili jednym językiem: jeden rekord, wiele rekordów, wszystkie rekordy. Na przykład „przypisz ponownie jednego klienta” różni się od „przypisz ponownie wszystkich klientów od tego opiekuna”. Ten opis później wpłynie na domyślne ustawienia, potwierdzenia i limity ról.
Przykład: w projekcie vibe-coding na Koder.ai możesz oznaczyć „masowy import użytkowników” jako wiele rekordów, odwracalny tylko jeśli zapiszesz każde utworzone ID, i chroniony polityką, bo dotyka PII.
Wzorce dla bezpieczniejszych działań zbiorczych
Działania zbiorcze to miejsce, gdzie dobre narzędzia admina zamieniają się w ryzykowne. Jeśli chcesz budować narzędzia admina zapobiegające utracie danych, traktuj każdy przycisk „zastosuj do wielu” jak narzędzie elektryczne: przydatny, ale zaprojektowany tak, by unikać potknięć.
Mocny domyślny wzorzec to najpierw podgląd, potem uruchomienie. Zamiast wykonywać od razu, pokaż, co by się zmieniło i pozwól operatorowi potwierdzić dopiero po zobaczeniu zakresu.
Uczyń zakres wyraźnym i trudnym do niezrozumienia. Nie przyjmuj „wszystko” jako pojęcia nieostrego. Zmusić operatora do określenia filtrów jak tenant, status i zakres dat, a potem pokaż dokładną liczbę pasujących rekordów. Mała lista przykładów (nawet 10 elementów) pomaga zauważyć błędy jak „zły region” lub „uwzględnione archiwa”.
Praktyczny wzorzec:
- Zacznij od ekranu suchego uruchomienia, który pokazuje liczbę, filtry i krótki przykład dotkniętych rekordów
- Wymagaj wyraźnego wyboru zakresu (np. tylko aktywni klienci w Tenancie A, utworzeni przed 2024-01-01)
- Ogranicz każdy przebieg (np. 1000 rekordów) i poproś o powtórzenie dla następnej partii
- Dostosuj tempo zmian, aby jedno złe kliknięcie nie zniszczyło bazy danych ani systemów docelowych
- Uruchamiaj jako zadanie w kolejce z postępem, logami i wyraźną opcją anulowania
Zadania w kolejce biją „odpalenie i zapomnij”, bo tworzą papierowy ślad i dają operatorowi szansę zatrzymania akcji, gdy zauważy problem przy 5% postępu.
Przykład: operator chce masowo dezaktywować konta po fali oszustw. Podgląd pokazuje 842 konta, ale próbka zawiera klientów VIP. Taki drobny sygnał często zapobiega prawdziwemu błędowi: brakującemu warunkowi fraud_flag = true.
Jeśli szybko składasz konsolę wewnętrzną (nawet z platformą buduj-przez-czat jak Koder.ai), wprowadź te wzorce od początku. Oszczędzają więcej czasu niż dodają.
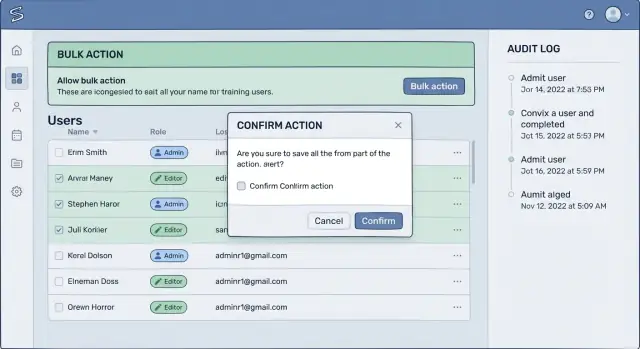
Potwierdzenia, które ludzie rzeczywiście czytają
Większość potwierdzeń zawodzi, bo są zbyt ogólne. Jeśli ekran pyta „Czy na pewno?”, ludzie klikają automatycznie. Potwierdzenie, które działa, używa tych samych słów, których użytkownik użyłby, by wytłumaczyć wynik współpracownikowi.
Zastąp niejasne etykiety jak Usuń lub Zastosuj rzeczywistym skutkiem: Dezaktywuj 38 kont, Usuń dostęp dla tego tenanta, Unieważnij 12 faktur. To jedna z najprostszych zmian, które możesz wprowadzić, bo zamienia odruchowe kliknięcie w moment rozpoznania.
Zmusić użytkownika do potwierdzenia zakresu
Dobry przepływ wymaga krótkiego sprawdzenia: czy to właściwa rzecz, na właściwym zbiorze rekordów? Umieść zakres w potwierdzeniu, nie tylko na stronie za nim. Dołącz nazwę tenanta lub workspace, liczbę rekordów i filtry jak zakres dat czy status.
Na przykład: Zamknij konta dla Tenanta: Acme Retail. Liczba: 38. Filtr: ostatnie logowanie przed 2024-01-01. Jeśli którakolwiek z tych wartości wygląda dziwnie, użytkownik to złapie zanim nastąpi szkoda.
Gdy akcja jest naprawdę destrukcyjna, wymagaj małego, świadomego działania. Potwierdzenia z wpisywaniem tekstu sprawdzają się, gdy koszt błędu jest wysoki.
- Poproś o krótką frazę jak USUŃ 38 KONT
- Lub poproś o dokładne wpisanie nazwy tenanta
- Lub wymagać ponownego wpisania liczby pokazanej na ekranie
Używaj dwóch kroków tylko gdy wpływ jest duży
Potwierdzenia dwukrokowe powinny być rzadkie, inaczej użytkownicy je zignorują. Zarezerwuj je dla akcji trudnych do odzyskania, krzyżujących tenantów lub wpływających na pieniądze. Krok pierwszy potwierdza intencję i zakres. Krok drugi potwierdza czas, np. Uruchom teraz vs Zaplanować, lub wymaga zatwierdzenia o wyższych uprawnieniach.
Na koniec unikaj etykiet OK/Anuluj. Przyciski powinny mówić, co się stanie: Dezaktywuj konta i Wróć. To zmniejsza błędne kliknięcia i sprawia, że decyzja wydaje się realna.
Miękkie usuwanie, przywracanie i zasady retencji
Trenuj przy użyciu rollback
Testuj destrukcyjne przepływy ze snapshotami, aby móc przywrócić po blednym uruchomieniu.
Miękkie usuwanie to najbezpieczniejszy domyślny wybór dla większości rekordów widocznych dla użytkownika: kont, zamówień, zgłoszeń, postów, a nawet wypłat. Zamiast usuwać wiersz, oznacz go jako usunięty i ukryj w normalnych widokach. To jeden z najprostszych wzorców stojących za narzędziami admina zapobiegającymi utracie danych, bo błędy stają się odwracalne.
Polityka miękkiego usuwania potrzebuje jasnego okna retencji i jasnej odpowiedzialności. Zdecyduj, jak długo elementy usunięte będą przywracalne (np. 30 lub 90 dni) i kto może je przywrócić. Powiąż prawa do przywracania z rolami, nie z osobami, i traktuj przywrócenia jako zmiany produkcyjne.
Uczyń przywracanie widocznym (i zalogowanym)
Przywracanie powinno być łatwe do znalezienia, gdy ktoś patrzy na usunięty rekord, a nie ukryte na oddzielnym ekranie. Dodaj widoczny status jak Usunięty, pokaż kiedy to nastąpiło i kto to zrobił. Gdy następuje przywrócenie, zaloguj je jako odrębne zdarzenie, a nie jako edycję pierwotnego usunięcia.
Szybki sposób na określenie zasad retencji to odpowiedź na pytania:
- Jaki jest domyślny okres retencji dla każdego typu obiektu?
- Która rola może przywrócić i czy potrzebuje podać powód?
- Co się dzieje po wygaśnięciu okresu retencji?
- Kto może przedłużyć retencję w sprawach prawnych lub rozliczeniowych?
- Jak obsługujesz żądania "usuń moje dane"?
Przypadki brzegowe, które psują przywracanie
Miękkie usuwanie brzmi prosto, dopóki nie próbujesz przywrócić do świata, który się zmienił. Unikalne ograniczenia mogą kolidować (nazwa użytkownika była ponownie użyta), referencje mogą być brakujące (rekord rodzica został usunięty), a historia rozliczeń musi pozostać spójna, nawet jeśli użytkownik jest "nieobecny". Praktyczne podejście to oddzielenie niemutowalnych ksiąg (faktury, zdarzenia płatności) od danych profilu użytkownika i ostrożne przywracanie relacji z jasnymi ostrzeżeniami, gdy pełne przywrócenie nie jest możliwe.
Twarde usunięcie powinno być rzadkie i jawne. Jeśli je dopuszczasz, niech będzie wyjątkowe, z krótką ścieżką zatwierdzenia:
- Wymagaj roli wyższej niż dla miękkiego usunięcia
- Poproś o wpisanie potwierdzenia i podanie powodu
- Kolejkuj usunięcie z opóźnieniem (np. 24 godziny)
- Powiadom właściciela lub kanał dyżurny
- Zachowaj końcowy zapis audytu nawet po usunięciu
Jeśli budujesz admina na platformie takiej jak Koder.ai, zdefiniuj miękkie usuwanie, przywracanie i retencję jako elementy pierwszorzędne, tak aby były spójne we wszystkich generowanych ekranach i przepływach.
Audytowalność: spraw, by akcje dało się później wyjaśnić
W panelach administracyjnych zdarzają się wypadki, ale prawdziwa szkoda często wychodzi później: nikt nie potrafi powiedzieć, co się zmieniło, kto to zrobił i dlaczego. Jeśli chcesz narzędzi admina, które zapobiegają utracie danych, traktuj dzienniki audytu jako część produktu, nie jako dodatek do debugowania.
Zacznij od logowania akcji w sposób czytelny dla człowieka. "Użytkownik 183 zaktualizował rekord 992" to za mało, gdy klient jest niezadowolony, a on-call próbuje to szybko naprawić. Dobre logi zawierają tożsamość, czas, zakres i intencję oraz wystarczające szczegóły, by cofnąć zmianę lub przynajmniej zrozumieć jej wpływ.
Co zapisywać (by było użyteczne później)
Praktyczny minimalny zestaw:
- Kto to zrobił (użytkownik, rola i informacje o podszywaniu się, jeśli użyte)
- Co i gdzie (nazwa akcji, tenant/konto i typy dotkniętych obiektów)
- Kiedy i skąd (znacznik czasu, strefa czasowa, IP lub ID sesji/urządzenia)
- Co się zmieniło (przed/po dla kluczowych pól, lub diff dla większych obiektów)
- Dlaczego to się stało (wolny tekst z powodem i opcjonalne ID zgłoszenia)
Działania zbiorcze zasługują na specjalne traktowanie. Loguj je jako pojedyncze "zadanie" z jasnym podsumowaniem (ile wybrano, ile zakończono sukcesem, ile niepowodzeń), a także przechowuj wyniki dla każdego elementu. Dzięki temu łatwo odpowiedzieć: "Czy zwróciliśmy 200 zamówień czy tylko 173?" bez przeszukiwania ściany wpisów.
Uczyń logi łatwymi do przeszukania: po użytkowniku administracyjnym, tenancie, typie akcji i przedziale czasu. Dodaj filtry dla "tylko zadania zbiorcze" i "wysokiego ryzyka", by recenzenci mogli wykrywać wzorce.
Nie wymuszaj biurokracji. Krótkie pole powodu z szablonami ("Prośba klienta o zamknięcie", "Śledztwo oszustwa") wypełniane jest częściej niż długi formularz. Jeśli jest ticket wsparcia, pozwól wkleić jego ID.
Na koniec zaplanuj dostęp do odczytu. Wielu wewnętrznych użytkowników potrzebuje widoku logów, ale tylko niewielka grupa powinna widzieć wrażliwe pola (pełne wartości przed/po). Oddziel "może przeglądać podsumowania audytu" od "może przeglądać szczegóły", by zmniejszyć ekspozycję.
Limity i zabezpieczenia oparte na rolach
Większość wypadków zdarza się, bo uprawnienia są zbyt szerokie. Jeśli każdy jest skutecznie adminem, zmęczony operator może jednym kliknięciem wyrządzić trwałą szkodę. Cel jest prosty: spraw, by bezpieczna ścieżka była domyślna, a ryzykowne akcje wymagały dodatkowego zamiaru.
Projektuj role wokół prawdziwych zadań, nie tytułów. Agent wsparcia, który obsługuje zgłoszenia, nie potrzebuje tych samych uprawnień co osoba zarządzająca regułami billingowymi.
Buduj role wokół zadań
Zacznij od oddzielenia tego, co ludzie mogą zobaczyć, od tego, co mogą zmienić. Praktyczny zestaw ról wewnętrznych może wyglądać tak:
- Tylko do odczytu: przegląd użytkowników, zamówień i logów
- Operator: edycja profili i reset haseł
- Operator rozliczeń: wydawanie zwrotów w ramach limitu
- Opiekun danych: scalanie rekordów i uruchamianie zbiorczych poprawek
- Administrator bezpieczeństwa: dezaktywacja kont i zarządzanie rolami
To trzyma funkcję usuń poza codzienną pracą i zmniejsza zasięg szkody, gdy ktoś popełni błąd.
Dla najniebezpieczniejszych akcji dodaj tryb podwyższony. Traktuj go jak klucz czasowy. Wejście do trybu podwyższonego wymaga silniejszego kroku (ponowna autoryzacja, zatwierdzenie menedżera lub druga osoba) i automatycznie wygasa po 10–30 minutach.
Zabezpieczenia środowiska też ratują zespoły. UI powinien utrudniać pomylenie stagingu z produkcją. Użyj głośnych wskazówek wizualnych, pokazuj nazwę środowiska w nagłówku i wyłącz akcje destrukcyjne w nieprodukcyjnym środowisku, chyba że jawnie je włączysz.
Na koniec chroń tenaty przed sobą nawzajem. W systemach multi-tenant zmiany między tenantami powinny być domyślnie zablokowane i dostępne tylko dla konkretnych ról z wyraźnym przełączeniem tenanta i jasnym potwierdzeniem na ekranie.
Jeśli budujesz na platformie Koder.ai, traktuj te zabezpieczenia jako funkcje produktu, a nie dodatek. Narzędzia admina zapobiegające utracie danych to często po prostu dobry projekt uprawnień plus kilka dobrze rozmieszczonych hamulców.
Realistyczny scenariusz: masowe zwroty i zamykanie kont
Dodaj audytowalność
Utwórz przeszukiwalne ślady audytowe, które zapisują kto zmienił co, gdzie i dlaczego.
Agent wsparcia musi obsłużyć przerwę płatności. Plan jest prosty: zwrócić dotknięte zamówienia, potem zamknąć konta, które prosiły o anulowanie. To dokładnie miejsce, gdzie narzędzia admina zapobiegające utracie danych się opłacają, bo agent zaraz uruchomi dwie wpływowe akcje zbiorcze jedna po drugiej.
Ryzyko pojawia się w jednym drobnym szczególe: filtrze. Agent wybiera Zamówienia utworzone w ostatnich 24 godzinach zamiast Zamówień opłaconych w oknie awarii. W ruchliwym dniu może to dodać tysiące normalnych klientów i spowodować zwroty, o które nie prosili. Jeśli następny krok to Zamknij konta dla zwróconych zamówień, szkoda rośnie szybko.
Zanim narzędzie wykona cokolwiek, UI powinien wymusić pauzę z jasnym podglądem, który pasuje do sposobu myślenia ludzi, a nie do tego, jak myśli baza danych. Na przykład powinien pokazać:
- Całkowitą liczbę kont, które zostaną zamknięte (i ile jest już zamkniętych)
- Całkowitą kwotę zwrotów, plus min/max rozmiary zwrotów
- Małą, przewijaną próbkę klientów (imiona, e-maile, ID zamówień)
- Wyjątki i pominięcia (nieudane płatności, już zwrócone, sporne zamówienia)
- Dokładne podsumowanie filtra w prostym języku i oczyczny przycisk Edytuj filtr
Potem dodaj drugie, osobne potwierdzenie dla zamknięcia kont, bo to inny typ szkody. Dobry wzorzec to wymaganie wpisania krótkiej frazy jak CLOSE 127 ACCOUNTS (przetłumaczone: USUŃ 127 KONT), aby agent zauważył, jeśli liczba jest błędna.
Jeśli zamknięcie konta jest miękkim usunięciem, odzyskanie jest realistyczne. Można przywrócić konta, zablokować loginy i ustawić regułę retencji (np. automatyczne oczyszczanie po 30 dniach), by nie stawało się to trwałym śmietnikiem.
Dzienniki audytu to to, co pozwala na sprzątanie i dochodzenie później. Menedżer powinien widzieć kto to uruchomił, dokładny filtr, podgląd liczb pokazany w czasie uruchomienia i listę dotkniętych rekordów. Limity ról mają znaczenie: agenci mogą robić zwroty do dziennego limitu, ale tylko menedżer może zamykać konta lub zatwierdzać zamknięcia powyżej progu.
Jeśli budujesz taką konsolę w Koder.ai, funkcje jak snapshoty i rollback są przydatnymi dodatkowymi zabezpieczeniami, ale pierwsza linia obrony to nadal podgląd, potwierdzenia i role.
Krok po kroku: wprowadź bezpieczeństwo do istniejącego admina
Retrofitting bezpieczeństwa działa najlepiej, gdy traktujesz admina jak produkt, a nie zbiór wewnętrznych stron. Wybierz jeden wysokiego ryzyka workflow najpierw (np. masowa dezaktywacja użytkowników), a potem idź krok po kroku.
Praktyczny plan retrofit
Zacznij od wypisania ekranów i endpointów, które mogą usuwać, nadpisywać lub wywoływać przepływ pieniędzy. Uwzględnij ukryte ryzyka jak importy CSV, masowe edycje i skrypty, które operatorzy uruchamiają z UI.
Następnie zabezpiecz akcje zbiorcze, wymuszając zakres i podgląd. Pokaż dokładnie, które rekordy pasują do filtrów, ile ich będzie zmienionych i małą próbkę ID przed uruchomieniem.
Potem zastąp twarde usunięcia miękkim, gdzie to możliwe. Przechowuj flagę usunięcia, kto to zrobił i kiedy. Dodaj ścieżkę przywracania równie łatwą w użyciu jak usunięcie, plus jasne zasady retencji (np. „przywracalne przez 30 dni”).
Po tym dodaj dziennik audytu i usiądź z operatorami, by przejrzeć rzeczywiste wpisy. Jeśli linia logu nie odpowiada na pytanie "co się zmieniło, z czego na co i dlaczego", to nie pomoże podczas incydentów.
Na koniec zaostrz role i dodaj zatwierdzenia dla akcji o dużym wpływie. Na przykład pozwól wsparciu wydawać zwroty do małego limitu, ale wymagaj drugiej osoby dla dużych kwot lub zamknięć kont. W ten sposób narzędzia admina zapobiegające utracie danych pozostają użyteczne bez bycia przerażającymi.
Szybki przykład
Operator musi zamknąć 200 nieaktywnych kont. Przed zmianą klika Usun i liczy, że filtry są poprawne. Po retroficie musi potwierdzić dokładne zapytanie (status=inactive, last_login>365d), przejrzeć liczbę i próbkę, wybrać Zamknij (przywracalne) zamiast Usuń i wpisać powód.
Dobry standard "zrobione" to:
- Możesz podejrzeć i wyeksportować zbiór przed wykonaniem.
- Możesz cofnąć (przywrócić lub rollback) w zdefiniowanym oknie.
- Każda akcja przypisywana jest do osoby i powodu.
- Akcje o dużym wpływie są limitowane przez role lub wymagają zatwierdzenia.
Jeśli tworzysz wewnętrzne narzędzia na platformie prowadzonej przez chat jak Koder.ai, dodaj te zabezpieczenia jako komponenty wielokrotnego użytku, aby nowe strony admina dziedziczyły bezpieczne domyślne ustawienia.
Typowe błędy, które wciąż prowadzą do wypadków
Wdróż panel administracyjny
Zamień mapę ryzyka w strony do audytów, przywróceń i kolejek zadań w jednym miejscu.
Wiele zespołów projektuje narzędzia admina zapobiegające utracie danych w teorii, a potem traci dane w praktyce, bo funkcje bezpieczeństwa są łatwe do zignorowania lub trudne w użyciu.
Najczęstszą pułapką jest potwierdzenie typu jeden-rozmiar-dla-wszystkich. Jeśli każda akcja pokazuje to samo Czy na pewno?, ludzie przestają to czytać. Co gorsza, zespoły często dodają więcej potwierdzeń, by "naprawić" błędy, co ćwiczy operatorów do szybszego klikania.
Innym problemem jest brak kontekstu w momencie, gdy się liczy. Akcja destrukcyjna powinna jasno pokazywać, w którym tenantie lub workspace jesteś, czy to produkcja czy test, i ile rekordów zostanie dotkniętych. Gdy ta informacja jest ukryta na innym ekranie, narzędzie cicho prosi o zły dzień.
Działania zbiorcze stają się niebezpieczne też wtedy, gdy uruchamiają się natychmiast bez śledzenia. Operatorzy potrzebują jasnego rekordu zadania: co uruchomiono, na jakim filtrze, kto to zaczął i co system zrobił przy błędzie. Bez tego nie można wstrzymać, cofnąć ani nawet wyjaśnić, co się stało.
Oto błędy, które powtarzają się najczęściej:
- Używanie tego samego tekstu potwierdzenia dla usunięć, zwrotów i zmian uprawnień
- Dodawanie potwierdzeń tak często, że ludzie klikają je automatycznie
- Niepokazywanie liczby rekordów, tenanta i środowiska na ekranie potwierdzenia
- Uruchamianie działań zbiorczych natychmiast bez podglądu, strony zadania i możliwości zatrzymania
- Trzymanie dzienników audytu, ale brak możliwości przeszukiwania po użytkowniku, rekordzie czy czasie
Szybki przykład: operator zamierza dezaktywować 12 kont w sandboxie, ale narzędzie domyślnie używa ostatnio używanego tenanta i ukrywa go w nagłówku. Uruchamia akcję, wykonuje się natychmiast, a jedyny "log" to ogólny wpis "bulk update completed". Gdy ktoś to zauważa, trudno ustalić, co się zmieniło lub to przywrócić.
Dobra ochrona to nie więcej popupów. To jasny kontekst, znaczące potwierdzenia i akcje, które można śledzić i odwrócić.
Szybka lista kontrolna i kolejne kroki
Zanim wypuścisz akcję destrukcyjną, zrób ostatnie spojrzenie świeżymi oczami. Większość incydentów adminów dzieje się, gdy narzędzie pozwala komuś działać na złym zakresie, ukrywa prawdziwy wpływ lub nie daje jasnej drogi powrotu.
Oto szybka lista przed startem dla narzędzi admina zapobiegających utracie danych:
- Zakres + podgląd: pokaż dokładnie, co się zmieni (kto, co, gdzie). Zawieraj czytelny podgląd i próbkę dotkniętych rekordów.
- Liczby + limity: pokaż całkowitą liczbę elementów i egzekwuj rozsądne limity (i rate limiting), by jedno kliknięcie nie mogło dotknąć "wszystkiego".
- Kontrole kontekstu: zmusz operatora do potwierdzenia tenanta/konta, środowiska (prod vs test) i dodania krótkiego powodu, który pojawi się w logach.
- Ścieżka odzyskiwania: preferuj miękkie usuwanie tam, gdzie możesz, potwierdź, że przywracanie działa, i zdefiniuj retencję (jak długo możliwe jest odzyskanie).
- Odpowiedzialność: loguj kto co zrobił, kiedy, skąd i z jakimi filtrami. Uczyń logi przeszukiwalnymi i dopasuj role do rzeczywistych obowiązków.
Jeśli jesteś operatorem, zatrzymaj się na dziesięć sekund i przeczytaj narzędzie na głos: "Działam na tenant X, zmieniam N rekordów, na produkcji, z powodu Y." Jeśli cokolwiek jest niejasne, zatrzymaj się i poproś o bezpieczniejszy UI przed uruchomieniem akcji.
Kolejne kroki: szybko prototypuj bezpieczne przepływy w Koder.ai używając Planning Mode do szkicowania ekranów i zabezpieczeń najpierw. Podczas testów używaj snapshotów i rollback, aby sprawdzać rzeczywiste przypadki brzegowe bez obaw. Gdy przepływ będzie stabilny, wyeksportuj kod źródłowy i wdroż, gdy będziesz gotowy.