01 ਸਤੰ 2025·8 ਮਿੰਟ
ਇੱਕ AI-ਸਹਾਇਤ workflow ਵਿੱਚ ਵਿਚਾਰ ਤੋਂ ਡਿਪਲੋਇਡ ਐਪ ਤੱਕ
ਇਕ ਪ੍ਰਯੋਗਕਰਤਾ, end-to-end ਕਹਾਣੀ ਜੋ ਦਿਖਾਉਂਦੀ ਹੈ ਕਿ ਇੱਕ AI-ਸਹਾਇਤ workflow ਨਾਲ ਇਕ ਐਪ ਵਿਚਾਰ ਤੋਂ ਲੈ ਕੇ ਡਿਪਲੋਇਡ ਉਤਪਾਦ ਤੱਕ ਕਿਵੇਂ ਲਿਆਂਦਾ ਜਾ ਸਕਦਾ ਹੈ—ਕਦਮ, ਪ੍ਰਾਪਟ, ਅਤੇ ਚੈਕਸ।
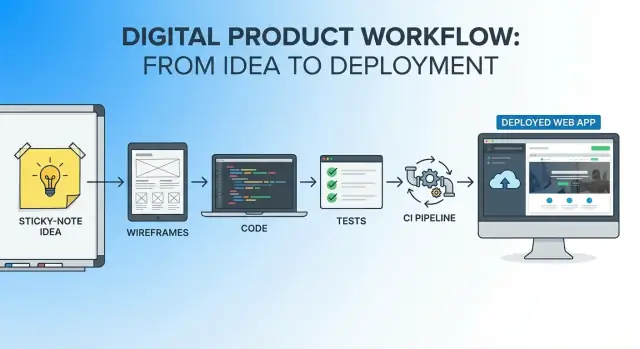
ਇਕ ਪ੍ਰਯੋਗਕਰਤਾ, end-to-end ਕਹਾਣੀ ਜੋ ਦਿਖਾਉਂਦੀ ਹੈ ਕਿ ਇੱਕ AI-ਸਹਾਇਤ workflow ਨਾਲ ਇਕ ਐਪ ਵਿਚਾਰ ਤੋਂ ਲੈ ਕੇ ਡਿਪਲੋਇਡ ਉਤਪਾਦ ਤੱਕ ਕਿਵੇਂ ਲਿਆਂਦਾ ਜਾ ਸਕਦਾ ਹੈ—ਕਦਮ, ਪ੍ਰਾਪਟ, ਅਤੇ ਚੈਕਸ।
ਛੋਟੀ, ਮਦਦਗਾਰ ਐਪ ਦੀ ਇੱਕ ਤਸਵੀਰ ਸੋਚੋ: “Queue Buddy” ਜੋ ਕੈਫੇ ਦਾ ਕਰਮਚਾਰੀ ਇਕ ਬਟਨ ਨਾਲ ਗਾਹਕ ਨੂੰ ਵੈਟਿੰਗ ਲਿਸਟ ਵਿੱਚ ਜੋੜ ਸਕਦਾ ਹੈ ਅਤੇ ਆਟੋਮੈਟਿਕ ਟੈਕਸਟ ਕਰਕੇ ਦੱਸਦਾ ਹੈ ਕਿ ਉਹਨਾਂ ਦੀ ਮੇਜ਼ ਤਿਆਰ ਹੈ। ਸਫਲਤਾ ਮੈਟਰਿਕ ਸਧਾਰਨ ਅਤੇ ਮਾਪਯੋਗ ਹੈ: ਦੋ ਹਫ਼ਤਿਆਂ ਵਿੱਚ ਔਸਤ ਵੈਟ-ਟਾਈਮ ਸਬੰਧੀ ਕੌਲਾਂ ਨੂੰ 50% ਘਟਾਉਣਾ, ਅਤੇ ਕਰਮਚਾਰੀ ਲਈ ਓਨਬੋਰਡਿੰਗ 10 ਮਿੰਟ ਤੋਂ ਘੱਟ ਰੱਖਣਾ।
ਇਸ ਲੇਖ ਦੀ ਰੂਹ ਇਹੁ ਹੈ: ਇੱਕ ਸਪਸ਼ਟ, ਸੀਮਿਤ ਵਿਚਾਰ ਚੁਣੋ, “ਅਚਛਾ” ਕੀ ਹੈ ਪਹਚਾਣੋ, ਅਤੇ ਫਿਰ ਬਿਨਾ ਮੁੜ-ਮੁੜ ਟੂਲ, ਡੌਕਸ ਅਤੇ ਮਾਨਸਿਕ ਮਾਡਲ ਬਦਲੇ ਵichਾਰ ਤੋਂ ਲਾਈਵ ਡਿਪਲੋਇਮੈਂਟ ਤੱਕ ਜਾਓ।
ਇਕ single workflow ਉਹ ਹੈ ਜੋ ਪਹਿਲੀ ਪଙਕਤੀ ਵਿਚਾਰ ਤੋਂ ਪਹਿਲੀ ਪ੍ਰੋਡਕਸ਼ਨ ਰਿਲੀਜ਼ ਤੱਕ ਇੱਕ ਲਗਾਤਾਰ Dhara ਦਿੰਦਾ ਹੈ:
ਤੁਸੀਂ ਅਜੇ ਵੀ ਕਈ ਟੂਲ ਪ੍ਰਯੋਗ ਕਰੋਗੇ (ਐਡੀਟਰ, ਰੀਪੋ, CI, ਹੋਸਟਿੰਗ), ਪਰ ਹਰ ਪੜਾਅ 'ਤੇ ਪ੍ਰੋਜੈਕਟ ਨੂੰ “ਰਿਸਟਾਰਟ” ਨਹੀਂ ਕਰਨਾ ਪਵੇਗਾ। ਉਹੀ ਕਹਾਣੀ ਅਤੇ ਸੀਮਾਵਾਂ ਅੱਗੇ ਚੱਲਣਗੀਆਂ।
AI ਸਭ ਤੋਂ ਜ਼ਿਆਦਾ ਕਦਰਦਾਨ ਹੈ ਜਦੋਂ ਇਹ:
ਪਰ ਇਹ ਉਤਪਾਦ ਫ਼ੈਸਲੇ ਦਾ ਮਾਲਿਕ ਨਹੀਂ ਬਣਦਾ। ਤੁਹਾਡੇ ਕੋਲ ਅਸਲ ਫ਼ੈਸਲੇ ਹਨ। workflow ਇਸ ਤਰ੍ਹਾਂ ਬਣਾਇਆ ਗਿਆ ਹੈ ਕਿ ਤੁਸੀਂ ਹਮੇਸ਼ਾ ਜਾਂਚ ਕਰਦੇ ਹੋ: ਕੀ ਇਹ ਬਦਲਾਅ ਮੈਟਰਿਕ ਨੂੰ ਅੱਗੇ ਵਧਾਉਂਦਾ ਹੈ? ਕੀ ਇਹ ਸੁਰੱਖਿਅਤ ਤੌਰ 'ਤੇ ਸ਼ਿਪ ਕਰਨ ਯੋਗ ਹੈ?
ਅਗਲੇ ਹਿੱਸਿਆਂ ਵਿੱਚ, ਤੁਸੀਂ ਕਦਮ-ਦਰ-ਕਦਮ ਜਾਵੋਗੇ:
ਅੰਤ ਤਕ, ਤੁਹਾਡੇ ਕੋਲ ਇੱਕ ਦੁਹਰਾਯੋਗ ਤਰੀਕਾ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ ਜੋ “ਵਿਚਾਰ” ਤੋਂ “ਲਾਈਵ ਐਪ” ਤੱਕ ਜਾਂਦਾ ਹੈ, ਜਿੱਥੇ ਸਕੋਪ, ਗੁਣਵੱਤਾ ਅਤੇ ਸਿੱਖਣ ਨੇੜੇ-ਨੇੜੇ ਜੁੜੇ ਰਹਿੰਦੇ ਹਨ।
AI ਨੂੰ ਸਕ੍ਰੀਨ, API ਜਾਂ ਡੇਟਾਬੇਸ ਟੇਬਲ ਡਰਾਫਟ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ ਤੁਹਾਨੂੰ ਇੱਕ ਸਪਸ਼ਟ ਟੀਚਾ ਚਾਹੀਦਾ ਹੈ। ਇੱਥੇ ਕੱਚੀ ਸਪਸ਼ਟਤਾ ਬਚਤ ਕਰਦੀ ਹੈ—ਬਾਅਦ ਦੇ ਘੰਟੇ “ਕਿਰੀਬ-ਕਿਰੀਬ ਠੀਕ” ਨਤਜਿਆਂ ਤੋਂ ਬਚਾਉਂਦੇ ਹਨ।
ਤੁਸੀਂ ਐਪ ਇਸ ਲਈ ਬਣਾ ਰਹੇ ਹੋ ਕਿਉਂਕਿ ਇੱਕ ਵਿਸ਼ੇਸ਼ ਗਰੁੱਪ ਲੋਕਾਂ ਨੂੰ ਇਕੋ ਹੀ ਰੁਕਾਵਟ بار-ਬਾਰ ਆ ਰਹੀ ਹੈ: ਉਹ ਉਹ ਕੰਮ ਤੇਜ਼ੀ ਨਾਲ, ਭਰੋਸੇਯੋਗੀ ਤਰੀਕੇ ਨਾਲ ਜਾਂ ਵਿਸ਼ਵਾਸ ਨਾਲ ਨਹੀਂ ਕਰ ਸਕਦੇ ਜੋ ਉਹਨਾਂ ਕੋਲ ਮੌਜੂਦ ਟੂਲਾਂ ਨਾਲ ਕਰਨਾ ਚਾਹੀਦਾ। v1 ਦਾ ਲਕਸ਼ ਇਕ workflow ਵਿੱਚ ਇਕ ਦਰਦਨਾਕ ਕਦਮ ਹਟਾਉਣਾ ਹੈ—ਸਭ ਕੁਝ ਆਟੋਮੇਟ ਨਹੀਂ ਕਰਨ ਦੀ ਕੋਸ਼ਿਸ਼—ਤਾਂ ਜੋ ਯੂਜ਼ਰ ਮਿੰਟਾਂ ਵਿੱਚ “ਮੈਨੂੰ X ਕਰਨ ਦੀ ਲੋੜ ਸੀ” ਤੋਂ “X ਹੋ ਗਿਆ” ਤੱਕ ਜਾ ਸਕਣ, ਅਤੇ ਕੀ ਹੋਇਆ ਦਾ ਇੱਕ ਸਪਸ਼ਟ ਰਿਕਾਰਡ ਹੋਵੇ।
ਇੱਕ ਪ੍ਰਾਇਮਰੀ ਯੂਜ਼ਰ ਚੁਣੋ। ਸਕੈਂਡਰੀ ਯੂਜ਼ਰ ਬਾਅਦ ਵਿੱਚ ਆ ਸਕਦੇ ਹਨ।
ਅਨੁਮਾਨ ਉਹ ਜਗ੍ਹਾ ਹਨ ਜਿੱਥੇ ਚੰਗੀਆਂ ਸੋਚਾਂ ਚੁਪਚਾਪ ਫੇਲ ਹੁੰਦੀ ਹਨ—ਉਹਨੂੰ ਦਰਸਾਓ।
Version 1 ਇੱਕ ਛੋਟੀ ਜਿੱਤ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ ਜੋ ਤੁਸੀਂ ਸ਼ਿਪ ਕਰ ਸਕੋ।
ਇੱਕ ਹਲਕਾ requirements doc (ਸੋਚੋ: ਇੱਕ ਪੇਜ) “ਕੂਲ ਆਈਡੀਆ” ਅਤੇ “ਬਿਲਡ ਕਰਨ ਯੋਗ ਯੋਜਨਾ” ਦੇ ਵਿਚਕਾਰ ਪੁਲ ਹੈ। ਇਹ ਤੁਹਾਨੂੰ ਕੇਂਦਰਿਤ ਰੱਖਦਾ ਹੈ, ਤੁਹਾਡੇ AI ਸਹਾਇਕ ਨੂੰ ਸਹੀ ਪ੍ਰਸੰਗ ਦਿੰਦਾ ਹੈ, ਅਤੇ ਪਹਿਲੀ ਵਰਜ਼ਨ ਨੂੰ ਮਹੀਨਿਆਂ ਦੇ ਪ੍ਰੋਜੈਕਟ ਵਿੱਚ ਨਹੀਂ ਫੈਲਣ ਦਿੰਦਾ।
ਇਹਨੂੰ ਕਸਕੇ ਅਤੇ ਸਕਿੰਮੇਬਲ ਰੱਖੋ। ਸਰਲ ਟੈਮਪਲੇਟ:
5–10 ਫੀਚਰ ਵੱਧ ਤੋਂ ਵੱਧ ਲਿਖੋ, ਨਤੀਜੇ ਵਜੋਂ ਫਰੇਜ਼ ਕਰੋ। ਫਿਰ ਉਹਨਾਂ ਨੂੰ ਰੈਂਕ ਕਰੋ:
ਇਹ ਰੈਂਕਿੰਗ AI-ਜਨਰੇਟ ਕੀਤੇ ਯੋਜਨਾਵਾਂ ਅਤੇ ਕੋਡ ਨੂੰ ਮਾਰਗਦਰਸ਼ਨ ਦਿੰਦੀ ਹੈ: “ਸਿਰਫ Must-haves ਪਹਿਲਾਂ ਲਾਗੂ ਕਰੋ।”
ਟਾਪ 3–5 ਫੀਚਰਾਂ ਲਈ 2–4 acceptance criteria ਜੋੜੋ। ਸਧਾਰਨ ਭਾਸ਼ਾ ਅਤੇ ਟੈਸਟੇਬਲ ਬਿਆਨ ਵਰਤੋ।
ਉਦਾਹਰਣ:
ਅੰਤ ਵਿੱਚ ਇੱਕ ਛੋਟੀ “Open Questions” ਸੂਚੀ ਰੱਖੋ—ਉਹ ਚੀਜ਼ਾਂ ਜਿਨ੍ਹਾਂ ਦਾ ਜਵਾਬ ਤੁਸੀਂ ਇੱਕ ਚੈਟ, ਇੱਕ ਗ੍ਰਾਹਕ ਕਾਲ ਜਾਂ ਇੱਕ ਤੇਜ਼ ਖੋਜ ਨਾਲ ਪ੍ਰਾਪਤ ਕਰ ਸਕਦੇ ਹੋ।
ਉਦਾਹਰਣ: “ਕੀ ਯੂਜ਼ਰਾਂ ਨੂੰ Google login ਦੀ ਲੋੜ ਹੈ?” “ਸਾਨੂੰ ਘੱਟੋ-ਘੱਟ ਕਿਹੜਾ ਡੇਟਾ ਸਟੋਰ ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ?” “ਕੀ ਸਾਨੂੰ admin ਮਨਜ਼ੂਰੀ ਦੀ ਲੋੜ ਹੈ?”
ਇਹ ਡੌਕ ਪੇਪਰਵਰਕ ਨਹੀਂ ਹੈ; ਇਹ ਇੱਕ ਸਾਂਝਾ ਸੱਚਾਈ ਦਾ ਸਰੋਤ ਹੈ ਜੋ ਤੁਸੀਂ ਬਿਲਡ ਦੌਰਾਨ ਅਪਡੇਟ ਕਰਦੇ ਰਹੋਗੇ।
AI ਨੂੰ ਸਕ੍ਰੀਨ ਜਾਂ ਕੋਡ ਬਣਾਉਣ ਲਈ ਕਹਿਣ ਤੋਂ ਪਹਿਲਾਂ, ਪ੍ਰੋਡਕਟ ਦੀ ਕਹਾਣੀ ਸਿੱਧੀ ਕਰੋ। ਇੱਕ ਤੇਜ਼ ਯਾਤਰਾ ਖਾਕਾ ਸਭ ਨੂੰ ਸੰਰਖਿਤ ਰੱਖਦਾ ਹੈ: ਯੂਜ਼ਰ ਕੀ ਕਰਨ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰ ਰਿਹਾ ਹੈ, “ਸਫਲਤਾ” ਕੀ ਦਿਖਦੀ ਹੈ, ਅਤੇ ਕਿੱਥੇ ਗਲਤ ਹੋ ਸਕਦਾ ਹੈ।
ਸਭ ਤੋਂ ਪਹਿਲਾਂ happy path ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ: ਸਭ ਤੋਂ ਸਰਲ ਲੜੀ ਜੋ ਮੁੱਖ ਮੁੱਲ ਪਹੁੰਚਾਉਂਦੀ ਹੈ।
ਉਦਾਹਰਣ ਫਲੋ (ਜਨਰਲ):
ਫਿਰ ਕੁਝ ਏਡਜ ਕੇਸ ਜੋ ਸੰਭਾਵਨਾ ਵਾਲੇ ਅਤੇ ਮਹਿੰਗੇ ਹੋ ਸਕਦੇ ਹਨ ਸ਼ਾਮਿਲ ਕਰੋ:
ਤੁਹਾਨੂੰ ਵੱਡਾ ਡਾਇਗ੍ਰਾਮ ਦੀ ਲੋੜ ਨਹੀਂ; ਇੱਕ ਨੰਬਰਵਾਰ ਸੂਚੀ ਅਤੇ ਨੋਟਸ ਪ੍ਰੋਟੋਟਾਈਪਿੰਗ ਅਤੇ ਕੋਡ ਜਨਰੇਸ਼ਨ ਲਈ ਕਾਫੀ ਹੈ।
ਹਰੇਕ ਸਕ੍ਰੀਨ ਲਈ ਛੋਟਾ “ਕਰਣ ਦਾ ਕੰਮ” ਲਿਖੋ। ਨਤੀਜੇ-ਕੇਂਦਰਤ ਰੱਖੋ, UI-ਕੇਂਦਰਤ ਨਹੀਂ।
ਜੇ ਤੁਸੀਂ AI ਨਾਲ ਕੰਮ ਕਰ ਰਹੇ ਹੋ, ਤਾਂ ਇਹ ਸੂਚੀ ਸ਼ਾਨਦਾਰ prompt ਸਮੱਗਰੀ ਬਣ ਜਾਂਦੀ ਹੈ: “Dashboard ਜਨਰੇਟ ਕਰੋ ਜੋ X, Y, Z ਸਮਰਥਨ ਕਰਦਾ ਹੈ ਅਤੇ empty/loading/error states ਸ਼ਾਮਿਲ ਕਰਦਾ ਹੈ।”
ਇਹ "napkin schema" ਲੈਵਲ 'ਤੇ ਰੱਖੋ—ਸਕ੍ਰੀਨ ਅਤੇ ਫਲੋ ਲਈ ਕਾਫੀ।
ਰਿਸ਼ਤਿਆਂ (User → Projects → Tasks) ਅਤੇ ਜੋ ਕੁਝ permissions 'ਤੇ ਪ੍ਰਭਾਵ ਪਾਂਦਾ ਹੈ ਉਹ ਦਰਸਾਓ।
ਉਹ ਜਗ੍ਹਾ ਚਿਨ੍ਹੋ ਜਿੱਥੇ ਗਲਤੀਆਂ ਵਿਸ਼ਵਾਸ ਤੋੜਦੀਆਂ ਹਨ:
ਇਹ over-engineer ਕਰਨ ਬਾਰੇ ਨਹੀਂ—ਇਹ ਉਨ੍ਹਾਂ ਅਚਾਨਕੀ ਚੀਜ਼ਾਂ ਨੂੰ ਰੋਕਣ ਬਾਰੇ ਹੈ ਜੋ "ਚਲਦੀ ਡੈਮੋ" ਨੂੰ ਲਾਂਚ ਤੋਂ ਬਾਅਦ ਸਪੋਰਟ ਸਿਰਦਰਦ ਵਿੱਚ ਬਦਲ ਦਿਤਾ ਜਾਂਦਾ ਹੈ।
Version 1 ਆਰਕੀਟੈਕਚਰ ਨੂੰ ਇਕ ਹੀ ਗੱਲ ਚੰਗੀ ਤਰ੍ਹਾਂ ਕਰਨੀ ਚਾਹੀਦੀ ਹੈ: ਤੁਹਾਨੂੰ ਸਭ ਤੋਂ ਛੋਟਾ ਉਪਯੋਗੀ ਉਤਪਾਦ ਸ਼ਿਪ ਕਰਨ ਦੇ ਯੋਗ ਬਣਾਉਣਾ ਬਿਨਾ ਆਪ ਨੂੰ ਕੋਨੇਚੱਕਣ ਦੇ। ਇੱਕ ਚੰਗਾ ਨਿਯਮ ਹੈ "ਇੱਕ רੀਪੋ, ਇੱਕ deployable backend, ਇੱਕ deployable frontend, ਇੱਕ ਡੇਟਾਬੇਸ"—ਅਤੇ ਵੱਡੀਆਂ ਚੀਜ਼ਾਂ ਤਦ ਹੀ ਜੋੜੋ ਜਦੋਂ ਸਪਸ਼ਟ ਲੋੜ ਆਵੇ।
ਜੇ ਤੁਸੀਂ ਇੱਕ ਆਮ ਵੈੱਬ ਐਪ ਬਣਾ ਰਹੇ ਹੋ, ਇੱਕ sensible ਡਿਫ਼ੌਲਟ ਇਹ ਹੈ:
v1 ਲਈ ਸਰਵਿਸਿਜ਼ ਦੀ ਗਿਣਤੀ ਘੱਟ ਰੱਖੋ। ਇੱਕ “modular monolith” (ਚੰਗੀ ਢੰਗ ਨਾਲ ਸੰਗਠਿਤ ਕੋਡਬੇਸ, ਪਰ ਇੱਕ ਬੈਕਐਂਡ ਸਰਵਿਸ) ਆਮ ਤੌਰ 'ਤੇ microservices ਨਾਲੋਂ ਆਸਾਨ ਹੁੰਦਾ ਹੈ।
ਜੇ ਤੁਸੀਂ ਇੱਕ AI-ਫਰਸਟ ਵਾਤਾਵਰਨ ਪਸੰਦ ਕਰਦੇ ਹੋ ਜਿੱਥੇ ਆਰਕੀਟੈਕਚਰ, ਟਾਸਕ, ਅਤੇ ਜਨਰੇਟ ਕੀਤਾ ਗਿਆ ਕੋਡ ਕੜੇ ਤੌਰ 'ਤੇ ਜੁੜੇ ਰਹਿਣ, ਤਾਂ Koder.ai ਵਰਗੇ ਪਲੇਟਫਾਰਮ ਇਕ ਵਧੀਆ ਚੋਣ ਹੋ ਸਕਦੇ ਹਨ: ਤੁਸੀਂ v1 ਸਕੋਪ ਨੂੰ ਚੈਟ ਵਿੱਚ ਦਰਸਾ ਸਕਦੇ ਹੋ, “planning mode” ਵਿੱਚ ਦੁਹਰਾਓ, ਅਤੇ ਫਿਰ React ਫਰੰਟਐਂਡ ਦੇ ਨਾਲ Go + PostgreSQL ਬੈਕਐਂਡ ਜਨਰੇਟ ਕਰ ਸਕਦੇ ਹੋ—ਫਿਰ ਵੀ ਸਮੀਖਿਆ ਅਤੇ ਨਿਯੰਤਰਣ ਤੁਹਾਡੇ ਹੱਥ ਵਿੱਚ ਰਹਿੰਦੇ ਹਨ।
ਕੋਡ ਜਨਰੇਸ਼ਨ ਤੋਂ ਪਹਿਲਾਂ, ਇਕ ਨਾਨਾ API ਟੇਬਲ ਲਿਖੋ ਤਾਂ ਜੋ ਤੁਸੀਂ ਅਤੇ AI ਇੱਕੋ ਨਿਸ਼ਾਨਾ ਨੂੰ ਸਾਂਝਾ ਕਰੋ। ਉਦਾਹਰਣ ਆਕਾਰ:
GET /api/projects → { items: Project[] }\n- POST /api/projects → { project: Project }\n- GET /api/projects/:id → { project: Project, tasks: Task[] }\n- POST /api/projects/:id/tasks → { task: Task }ਸਟੇਟਸ ਕੋਡ, ਗਲਤੀ ਫਾਰਮੈਟ (ਉਦਾਹਰਣ: { error: { code, message } }), ਅਤੇ pagination ਲਈ ਨੋਟਸ ਜੋੜੋ।
ਜੇ v1 ਪਬਲਿਕ ਜਾਂ ਸਿੰਗਲ-ਯੂਜ਼ਰ ਹੋ ਸਕਦਾ ਹੈ ਤਾਂ auth ਛੱਡ ਦਿਓ ਅਤੇ ਤੇਜ਼ੀ ਨਾਲ ਸ਼ਿਪ ਕਰੋ। ਜੇ ਤੁਹਾਨੂੰ ਅਕਾਉਂਟਾਂ ਦੀ ਲੋੜ ਹੈ, ਤਾਂ ਮੈਨੇਜਡ ਪ੍ਰਦਾਤਾ ਵਰਤੋ (ਈਮੇਲ magic link ਜਾਂ OAuth) ਅਤੇ permissions ਨੂੰ ਸਧਾਰਨ ਰੱਖੋ: “user owns their records.” ਜਦ ਤਕ ਵਾਸਤਵਿਕ ਉਪਯੋਗ ਚਾਹੀਦਾ ਨਹੀਂ ਹੁੰਦਾ, ਕਠੋਰ roles ਤੋਂ ਬਚੋ।
ਕੁਝ ਅਮਲ ਲਿਖੋ:\n\n- ਅਨੁਮਾਨਤ ਟ੍ਰੈਫਿਕ (ਭਲਕੇ ਇੱਕ ਅਨੁਮਾਨ)\n- ਬੁਨਿਆਦੀ response-time ਲਕਸ਼ (ਉਦਾਹਰਣ: “ਅਧਿਕਤਰ ਬੇਨਤੀ 300ms ਤੋਂ ਘੱਟ”)\n- ਮੁੱਢਲਾ logging (ਬੇਨਤੀਆਂ, ਗਲਤੀਆਂ, ਅਤੇ ਮੁੱਖ ਬਿਜਨੈਸ ਇਵੇਂਟ)\n- ਬੈਕਅਪ ਅਤੇ rollback ਯੋਜਨਾ
ਇਹ ਨੋਟਸ AI-ਸਹਾਇਤ ਕੋਡ ਜਨਰੇਸ਼ਨ ਨੂੰ ਕੁਝ deployable ਬਣਾਉਣ ਲਈ ਮਾਰਗਦਰਸ਼ਨ ਦਿੰਦੀਆਂ ਹਨ, ਸਿਰਫ਼ ਫੰਕਸ਼ਨਲ ਨਾਂ।
Momentum ਮਾਰਨ ਦਾ ਸਭ ਤੋਂ ਤੇਜ਼ ਤਰੀਕਾ ਟੂਲਾਂ 'ਤੇ ਇਕ ਹਫ਼ਤਾ ਵਾਦ-ਵਿਵਾਦ ਕਰਨਾ ਹੈ ਪਰ ਰਨਏਬਲ ਕੋਡ ਨਾ ਹੋਣਾ। ਤੁਹਾਡਾ ਲਕਸ਼ ਸਧਾਰਨ ਹੈ: “hello app” ਤੇ ਪਹੁੰਚ ਕਰੋ ਜੋ ਲੋਕਲ ਚੱਲੇ, ਇੱਕ ਦਿੱਖਵੀਂ ਸਕ੍ਰੀਨ ਹੋਵੇ, ਅਤੇ ਇੱਕ ਸਰਵਿਸ ਲਈ ਬੇਨਤੀ ਸਵੀਕਾਰ ਕਰ ਸਕੇ—ਪਰ ਛੋਟਾ enough ਕਿ ਹਰ ਬਦਲਾਅ ਆਸਾਨੀ ਨਾਲ ਸਮੀਖਿਆ ਯੋਗ ਹੋਵੇ।
AI ਨੂੰ ਇੱਕ ਸੰਕੁਚਿਤ prompt ਦਿਓ: ਫਰੇਮਵਰਕ ਚੋਣ, ਬੇਸਿਕ ਪੇਜ, ਇੱਕ.stub API, ਅਤੇ ਫਾਇਲਾਂ ਜੋ ਤੁਸੀਂ ਉਮੀਦ ਕਰਦੇ ਹੋ। ਤੁਸੀਂ predictable conventions ਚਾਹੁੰਦੇ ਹੋ, ਨਾ ਕਿ cleverness।
ਇੱਕ ਚੰਗੀ ਪਹਿਲੀ ਪਾਸ ਹੈ ਇੱਕ ਧਾਂਚਾ ਜਿਵੇਂ:
\n/README.md\n/.env.example\n/apps/web/\n/apps/api/\n/package.json\n
ਜੇ ਤੁਸੀਂ ਇਕੱਲੇ ਰੀਪੋ ਵਰਤ ਰਹੇ ਹੋ, ਤਾਂ ਬੇਸਿਕ ਰਾਊਟਸ (ਜਿਵੇਂ / ਅਤੇ /settings) ਅਤੇ ਇੱਕ API endpoint (ਜਿਵੇਂ GET /health ਜਾਂ GET /api/status) ਮੰਗੋ। ਇਹ plumbing ਕੰਮ ਕਰਦੀ ਹੋਵੇ ਇਹ ਸਾਬਿਤ ਕਰਨ ਲਈ ਕਾਫ਼ੀ ਹੈ।
ਜੇ ਤੁਸੀਂ Koder.ai ਵਰਤ ਰਹੇ ਹੋ, ਤਾਂ ਇਹ ਵੀ ਇੱਕ ਕੁਦਰਤੀ ਸ਼ੁਰੂਆਤ ਹੈ: ਇਕ ਨਿਊਨਤਮ “web + api + database-ready” ਸਕੈਲੈਟਨ ਮੰਗੋ, ਫਿਰ ਜਦੋੜ ਤੁਹਾਨੂੰ structure ਤੇ conventions ਪਸੰਦ ਆਉਣ, ਤਾਂ ਸੋਰਸ ਐਕਸਪੋਰਟ ਕਰੋ।
UI ਨੂੰ ਜਾਣ-ਬੁਝ ਕੇ ਸਧਾਰਨ ਰੱਖੋ: ਇੱਕ ਪੇਜ, ਇੱਕ ਬਟਨ, ਇੱਕ ਕਾਲ।
ਉਦਾਹਰਣ ਵਿਹਾਰ:
ਇਸ ਨਾਲ ਤੁਹਾਨੂੰ ਤੁਰੰਤ ਫੀਡਬੈਕ ਲੂਪ ਮਿਲਦਾ ਹੈ: ਜੇ UI ਲੋਡ ਹੁੰਦਾ ਹੈ ਪਰ ਕਾਲ ਫੇਲ ਹੁੰਦੀ ਹੈ ਤਾਂ ਤੁਹਾਨੂੰ ਪਤਾ ਹੈ ਕਿ ਕਿੱਥੇ ਵੇਖਣਾ ਹੈ (CORS, ਪੋਰਟ, ਰਾਊਟਿੰਗ, ਨੈੱਟਵਰਕ ਐਰਰ)। ਇਸ ਰੇਤ auth, ਡੇਟਾਬੇਸ, ਜਾਂ ਜਟਿਲ ਰਾਜ ਨੂੰ ਸ਼ਾਮਿਲ ਨਾ ਕਰੋ—ਉਹ ਬਾਅਦ ਵਿੱਚ ਆਉਣਗੇ।
ਦਿਨ ਇੱਕ .env.example ਬਣਾਓ। ਇਹ “ਮੇਰੇ ਮਸ਼ੀਨ 'ਤੇ ਚੱਲਦਾ ਹੈ” ਮੁੱਦਿਆਂ ਨੂੰ ਰੋਕਦਾ ਹੈ ਅਤੇ onboarding ਆਸਾਨ ਬਣਾਉਂਦਾ ਹੈ।
ਉਦਾਹਰਣ:
\nWEB_PORT=3000\nAPI_PORT=4000\nAPI_URL=http://localhost:4000\n
ਫਿਰ README ਨੂੰ ਇਕ ਮਿੰਟ ਤੋਂ ਘੱਟ ਵਿੱਚ runnable ਬਣਾਓ:
.env.example ਨੂੰ .env ਵਿੱਚ ਕਾਪੀ ਕਰੋ\n- web + api ਸ਼ੁਰੂ ਕਰੋ\n- ਬਰਾਊਜ਼ਰ URL ਖੋਲ੍ਹੋਇਸ ਪੜਾਅ ਨੂੰ ਸਾਫ਼ ਬੁਨਿਆਦ ਰੱਖੋ। ਹਰ ਛੋਟੀ ਜਿੱਤ ਤੋਂ ਬਾਅਦ commit ਕਰੋ: “init repo,” “add web shell,” “add api health endpoint,” “wire web to api.” ਛੋਟੇ commits AI-ਸਹਾਇਤ iteration ਨੂੰ ਸੁਰੱਖਿਅਤ ਬਣਾਉਂਦੇ ਹਨ: ਜੇ ਕੋਈ generated ਬਦਲਾਅ ਠੀਕ ਨਾ ਹੋਏ, ਤਾਂ ਤੁਸੀਂ ਰਿਵਰਟ ਕਰ ਸਕਦੇ ਹੋ ਬਿਨਾ ਇੱਕ ਦਿਨ ਖੋਏ।
ਜਦੋਂ ਸਕੈਲੈਟਨ end-to-end ਚੱਲਦਾ ਹੈ, ਤਾਂ “ਸਭ ਕੁਝ ਖਤਮ ਕਰਨ” ਦੀ ਲਾਲਚ ਨਾਲ ਰੋਕੋ। ਇਸਦੀ ਬਜਾਏ, ਡੇਟਾਬੇਸ, API, ਅਤੇ UI ਨੂੰ ਛੂਹਣ ਵਾਲਾ ਇੱਕ ਸੰਕੋਚਿਤ vertical slice ਬਣਾਓ, ਫਿਰ ਦੁਹਰਾਓ। ਪਤਲੇ slices ਸਮੀਖਿਆ ਤੇਜ਼ ਰੱਖਦੇ ਹਨ, ਬੱਗ ਛੋਟੇ ਹੁੰਦੇ ਹਨ, ਅਤੇ AI ਸਹਾਇਤਾ ਦੀ ਜਾਂਚ ਆਸਾਨ ਹੁੰਦੀ ਹੈ।
ਉਹ ਇੱਕ ਮਾਡਲ ਚੁਣੋ ਜਿਸ ਬਿਨਾ ਤੁਹਾਡੀ ਐਪ ਕੰਮ ਨਹੀਂ ਕਰ ਸਕਦੀ—ਅਕਸਰ ਉਹ "ਚੀਜ਼" ਜੋ ਯੂਜ਼ਰ ਬਣਾਉਂਦਾ/ਸੰਭਾਲਦਾ ਹੈ। ਇਸ ਨੂੰ ਸਪੱਸ਼ਟ ਰੂਪ ਵਿੱਚ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ (ਫੀਲਡ, ਲਾਜ਼ਮੀ ਬਨਾਮ ਵ ਸ਼ੈਆਰ), ਫਿਰ migrations ਜੁੜੋ ਜੇ ਤੁਸੀਂ ਰਿਲੇਸ਼ਨਲ ਡੇਟਾਬੇਸ ਵਰਤ ਰਹੇ ਹੋ। ਪਹਿਲੀ ਵਰਜ਼ਨ ਨੂੰ ਸਧਾਰਨ ਰੱਖੋ: clever normalization ਜਾਂ ਪਹਿਲਾਂ ਦਾ ਲਚਕੀਲਾਪਨ ਤੋਂ ਬਚੋ।
ਜੇ ਤੁਸੀਂ AI ਨੂੰ ਮਾਡਲ ਡਰਾਫਟ ਕਰਨ ਲਈ ਕਹਿੰਦੇ ਹੋ, ਤਾਂ ਪੁੱਛੋ ਕਿ ਹਰ ਫੀਲਡ ਅਤੇ ਡਿਫਾਲਟ ਦੀ ਇੱਕ ਵਾਕੀ ਵਜ੍ਹਾ ਦੱਸੇ। ਜੋ ਕੁਝ ਵੀ ਇਹ ਇੱਕ ਵਾਕ ਵਿੱਚ ਸਮਝਾ ਨਾ ਸਕੇ, ਸੰਭਵਤ: v1 'ਚ ਨਹੀਂ ਹੋਣਾ ਚਾਹੀਦਾ।
ਸਿਰਫ ਉਨ੍ਹਾਂ ਐਂਡਪੋਇੰਟਸ ਨੂੰ ਬਣਾਓ ਜੋ ਪਹਿਲੀ ਯੂਜ਼ਰ ਯਾਤਰਾ ਲਈ ਲਾਜ਼ਮੀ ਹਨ: ਆਮ ਤੌਰ 'ਤੇ create, read, ਅਤੇ ਇੱਕ ਨਿਮਨਤਮ update। ਵੈਲਿਡੇਸ਼ਨ ਸੀਮਾ ਦੇ ਨੇੜੇ ਰੱਖੋ (request DTO/schema), ਅਤੇ ਨਿਯਮ ਸਪੱਸ਼ਟ ਰੱਖੋ:\n\n- ਲਾਜ਼ਮੀ ਫੀਲਡ, ਫਾਰਮੈਟ, ਅਤੇ ਮਨਜ਼ੂਰ ਕੀਤੀਆਂ ਸੀਮਾਵਾਂ\n- ਮਾਲਕੀ/ਪਰਮਿਸ਼ਨ ਚੈੱਕ (“ਕੀ ਇਹ ਯੂਜ਼ਰ ਇਸ ਰਿਕਾਰਡ ਤੱਕ ਪਹੁੰਚ ਸਕਦਾ ਹੈ?”)\n- ਲਗਾਤਾਰ ਰਿਸਪਾਂਸ ਸ਼ੇਪ (ਸਫਲਤਾ ਅਤੇ ਅਸਫਲਤਾ ਦੋਹਾਂ)
ਵੈਲਿਡੇਸ਼ਨ ਫੀਚਰ ਦਾ ਹਿੱਸਾ ਹੈ, ਨਾ ਕਿ ਸਿਰਫ਼ ਪਾਲਿਸ਼—ਇਹ messy ਡੇਟਾ ਰੋਕਦਾ ਹੈ ਜੋ ਬਾਅਦ ਵਿੱਚ ਤੁਹਾਨੂੰ ਠਹਿਰਾਉਂਦਾ ਹੈ।
ਐਰਰ ਸੁਨੇਹੇ ਨੂੰ debugging ਅਤੇ support ਲਈ UX ਵਜੋਂ ਚTreat ਕਰੋ। ਕੈਲੀਅਰ-ਕਲਿਸ਼ਨ ਸੁਨੇਹੇ ਵਾਪਸ ਕਰੋ (ਕੀ ਫੇਲ ਹੋਇਆ ਅਤੇ ਇਸਨੂੰ ਕਿਵੇਂ ਠੀਕ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ) ਪਰ client ਨੂੰ حساس ਵੇਰਵੇ ਨਾ ਦਿਓ। server-side ਤੇ technical context ਨੂੰ request ID ਨਾਲ ਲੌਗ ਕਰੋ ਤਾਂ ਕਿ ਤੁਸੀਂ incidents ਨੂੰ ਗੁੱਸੇ ਬਿਨਾ ਟ੍ਰੇਸ ਕਰ ਸکو।
AI ਨੂੰ incremental PR-ਸਾਈਜ਼ ਬਦਲਾਅ ਮੰਗੋ: ਇੱਕ migration + ਇੱਕ endpoint + ਇੱਕ test ਇਕ ਸਮੇਂ ਵਿੱਚ। ਸਮੀਖਿਆ ਪ੍ਰੋਟੀਨ ਨੂੰ ਉਸੇ ਤਰ੍ਹਾਂ ਕਰੋ ਜਿਵੇਂ ਤੁਸੀਂ ਟੀਮਮੇਟ ਦੇ ਕੰਮ ਦੀ ਸਮੀਖਿਆ ਕਰੋਗੇ: naming, edge cases, security assumptions, ਅਤੇ ਕੀ ਇਹ ਬਦਲਾਅ ਯੂਜ਼ਰ ਦੀ ਛੋਟੀ ਜਿੱਤ ਨੂੰ ਸਹਾਰਦਾ ਹੈ। ਜੇ ਇਹ ਵਾਧੂ ਫੀਚਰ ਜੋੜਦਾ ਹੈ, ਉਨ੍ਹਾਂ ਨੂੰ ਹਟਾਓ ਅਤੇ ਅੱਗੇ ਵਧੋ।
Version 1 ਨੂੰ enterprise-ਗਰੇਡ ਸੁਰੱਖਿਆ ਦੀ ਲੋੜ ਨਹੀਂ, ਪਰ ਇਹ ਉਹ predictable ਫੇਲ੍ਹ ਰੋਕਣੀ ਚਾਹੀਦੀ ਹੈ ਜੋ ਇੱਕ ਉਮੀਦਵਾਰ ਐਪ ਨੂੰ ਲਾਂਚ ਤੋਂ ਬਾਅਦ ਸਪੋਰਟ ਹੇਡੇਕ ਵਿੱਚ ਬਦਲ ਦਿੰਦਾ ਹੈ। ਲਕਸ਼ "ਕਾਫੀ ਸੁਰੱਖਿਅਤ": ਬੁਰਾ ਇਨਪੁੱਟ ਰੋਕੋ, ਦਫ਼ਾਇਤ ਦੇਹੀਂ ਅਧਿਕਾਰ ਰੱਖੋ, ਅਤੇ ਜਦੋਂ ਕੁਝ ਗਲਤ ਹੋਵੇ ਤਾਂ ਇਕ ਲਾਹਣੀ ਨਿਸ਼ਾਨ ਛੱਡੋ।
ਹਰ ਸਿਮਾ ਨੂੰ ਅਣ-ਟ੍ਰੱਸਟਡ ਸਮਝੋ: ਫਾਰਮ ਖੇਤਰ, API ਪੇਲੋਡ, query ਪੈਰਾਮ, ਅਤੇ ਅੰਦਰੂਨੀ webhook। ਟਾਈਪ, ਲੰਬਾਈ, ਅਤੇ ਮਨਜ਼ੂਰ ਕੀਤੇ ਮੁੱਲਾਂ ਦੀ ਜਾਂਚ ਕਰੋ, ਅਤੇ ਸਟੋਰ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ ਡੇਟਾ ਨੂੰ ਨਾਰਮਲਾਈਜ਼ ਕਰੋ (strings trim ਕਰੋ, casing ਬਦਲੋ)।
ਕੁਝ ਪ੍ਰਯੋਗਕਰਤਾ ਡਿਫ਼ੌਲਟ:
ਜੇ ਤੁਸੀਂ AI ਨਾਲ ਹੈਂਡਲਰ ਜਨਰੇਟ ਕਰਵਾ ਰਹੇ ਹੋ, ਤਾਂ ਉਸ ਤੋਂ ਵੈਲਿਡੇਸ਼ਨ ਨਿਯਮ ਸਪਸ਼ਟ ਰੂਪ ਵਿੱਚ ਸ਼ਾਮਿਲ ਕਰਨ ਲਈ ਕਹੋ (ਜਿਵੇਂ “max 140 chars” ਜਾਂ “ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ ਇੱਕ ਵਿੱਚੋਂ: …”) ਬਜਾਏ ਕਿ ਸਿਰਫ਼ “ਇਨਪੁੱਟ ਵੈਲਿਡੇਟ ਕਰੋ” ਕਹਿਣ ਦੇ।
v1 ਲਈ ਇੱਕ ਸਧਾਰਨ permission ਮਾਡਲ ਆਮ ਤੌਰ 'ਤੇ ਕਾਫ਼ੀ ਹੁੰਦਾ ਹੈ:
ਮਾਲਕੀ ਸਰੋਤਾਂ ਦੀ ਜਾਂਚ middleware/policy functions ਵਿੱਚ ਕੇਂਦਰੀ ਬਣਾਓ, ਤਾਂ ਜੋ ਤੁਸੀਂ ਕੋਡ ਵਿੱਚ "if userId == …" ਹਰ ਥਾਂ ਨਾ ਫੈਲਾਓ।
ਚੰਗੇ ਲੌਗ ਇਹ ਜਵਾਬ ਦਿੰਦੇ ਹਨ: ਕੀ ਹੋਇਆ, ਕਿਸ ਨਾਲ, ਅਤੇ ਕਿੱਥੇ? ਸ਼ਾਮਿਲ ਕਰੋ:
update_project, project_id)\n- Timing (ਧੀਮੀ ਬੇਨਤੀਆਂ ਲਈ ਅਵਧੀ)ਇਵੈਂਟ ਲੌਗ ਕਰੋ, ਰਾਜ (secrets) ਨਹੀਂ: ਕਦੇ ਵੀ passwords, tokens, ਜਾਂ ਪੂਰੇ payment ਵੇਰਵੇ ਲਿਖੋ ਨਾ।
ਐਪ ਨੂੰ “ਕਾਫੀ ਸੁਰੱਖਿਅਤ” ਕਹਿੰਣ ਤੋਂ ਪਹਿਲਾਂ, ਚੈੱਕ ਕਰੋ:
ਟੈਸਟ ਇੱਕ perfect ਸਕੋਰ ਦੇ ਪਿੱਛੇ ਦੌੜ ਨਹੀਂ ਹਨ—ਉਹ ਉਹ failures ਰੋਕਣ ਲਈ ਹਨ ਜੋ ਯੂਜ਼ਰਾਂ ਨੂੰ ਨੁਕਸਾਨ ਪਹੁੰਚਾਉਂਦੇ ਹਨ, ਭਰੋਸਾ ਤੋੜਦੇ ਹਨ, ਜਾਂ ਮਹਿੰਗੇ emergency ਕਰਦੇ ਹਨ। AI-ਸਹਾਇਤ workflow ਵਿੱਚ, ਟੈਸਟ GENERATED ਕੋਡ ਨੂੰ ਉਸ “contract” ਵਜੋਂ ਵੀ ਕੰਟਰੋਲ ਕਰਦੇ ਹਨ ਜੋ ਤੁਹਾਡੀ ਇਰਾਦਾ ਨਾਲ ਮੇਲ ਰੱਖਦੇ ਹਨ।
ਬਹੁਤ ਜ਼ਿਆਦਾ ਕਵਰੇਜ ਤਿਆਰ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ, ਉਹ ਥਾਂਆਂ ਪਛਾਣੋ ਜਿੱਥੇ ਗਲਤੀਆਂ ਮਹਿੰਗੀਆਂ ਹੋਣਗੀਆਂ। ਆਮ ਹਾਈ-ਰਿਸਕ ਖੇਤਰ ਹਨ: ਪੈਸਾ/ਕਰੇਡਿਟ, permissions, data transformations, ਅਤੇ ਏਡਜ ਕੇਸ validation।
ਇਨ੍ਹਾਂ ਹਿੱਸਿਆਂ ਲਈ ਯੂਨਿਟ ਟੈਸਟ ਪਹਿਲਾਂ ਲਿਖੋ। ਉਨ੍ਹਾਂ ਨੂੰ ਛੋਟੇ ਅਤੇ ਨਿਰਧਾਰਤ ਰੱਖੋ: ਦਿੱਤਾ ਗਿਆ ਇਨਪੁੱਟ X, ਤੁਸੀਂ ਉਮੀਦ Y ਦੇਖਦੇ ਹੋ (ਜਾਂ ERROR)। ਜੇ ਕੋਈ ਫੰਕਸ਼ਨ ਬਹੁਤ ਸਾਰੀਆਂ ਸ਼ਾਖਾਂ ਰੱਖਦਾ ਹੈ ਤਾਂ ਟੈਸਟ ਕਰਨਾ ਮੁਸ਼ਕਲ ਹੋ ਸਕਦਾ ਹੈ—ਇਹ ਇੱਕ ਸੰਕੇਤ ਹੈ ਕਿ ਉਸ ਨੂੰ ਸਧਾਰਾ ਬਣਾਉਣਾ ਚਾਹੀਦਾ ਹੈ।
ਯੂਨਿਟ ਟੈਸਟ ਲਾਜ਼ਮੀ ਦੋਸ਼ਾਂ ਨੂੰ ਫੜਦੇ ਹਨ; ਇੰਟੀਗ੍ਰੇਸ਼ਨ ਟੈਸਟ “ਵਾਇਰਿੰਗ” ਦੀਆਂ ਗਲਤੀਆਂ ਫੜਦੇ ਹਨ—ਰਾਊਟਸ, ਡੇਟਾਬੇਸ ਕਾਲ, auth checks, ਅਤੇ UI ਫਲੋ ਇਕੱਠੇ ਕੰਮ ਕਰਨਾ।
ਮੁੱਖ ਯਾਤਰਾ ਚੁਣੋ ਅਤੇ ਉਨ੍ਹਾਂ ਦਾ end-to-end automation ਕਰੋ:\n\n- ਖਾਤਾ ਬਣਾਓ / ਸਾਈਨ ਇਨ\n- ਉਹ ਪ੍ਰാഥਮਿਕ ਕਾਰਵਾਈ ਪੂਰੀ ਕਰੋ ਜਿਸ ਲਈ ਐਪ ਬਣਾਈ ਗਈ ਹੈ\n- ਨਤੀਜਾ ਉਸ ਥਾਂ ਤੇ ਆਉਂਦਾ ਹੈ ਜਿੱਥੇ ਯੂਜ਼ਰ ਉਮੀਦ ਕਰਦਾ ਹੈ (ਸਕ੍ਰੀਨ, ਇਮੇਲ, ਡੈਸ਼ਬੋਰਡ)
ਦੋ-ਤਿੰਨ ਮਜ਼ਬੂਤ ਇੰਟੀਗ੍ਰੇਸ਼ਨ ਟੈਸਟ ਅਕਸਰ ਡੈਜਨਾਂ ਦੇ ਬਦਲੇ ਬਹੁਤ ਸਾਰੇ ਘਟਨਾਵਾਂ ਤੋਂ ਰੋਕਦੇ ਹਨ।
AI ਟੈਸਟ scaffold ਅਤੇ ਉਹਨਾਂ ਏਡਜ ਕੇਸਾਂ ਦੀ ਗਿਣਤੀ ਕਰਨ ਵਿੱਚ ਸ਼ਾਨਦਾਰ ਹੈ ਜੋ ਤੁਸੀਂ ਛੱਡ ਸਕਦੇ ਹੋ। ਇਸ ਲਈ ਉਨ੍ਹਾਂ ਤੋਂ ਮੰਗੋ:
ਫਿਰ ਹਰ generated assertion ਦੀ ਸਮੀਖਿਆ ਕਰੋ। ਟੈਸਟ ਵਰਤਾਰ ਨੂੰ verify ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ, implementation ਵੇਰਵੇ ਨਹੀਂ। ਜੇ ਇੱਕ ਟੈਸਟ ਬਗ ਹੋਣ 'ਤੇ ਵੀ ਪਾਸ ਹੋ ਜਾਂਦਾ ਹੈ, ਤਾਂ ਇਹ ਟੈਸਟ ਆਪਣਾ ਕੰਮ ਨਹੀਂ ਕਰ ਰਿਹਾ।
ਇੱਕ ਨਿਮਿਣ ਲਕਸ਼ ਚੁਣੋ (ਉਦਾਹਰਣ ਲਈ core modules 'ਤੇ 60–70%) ਅਤੇ ਇਸਨੂੰ ਇੱਕ guardrail ਵੱਜੋਂ ਵਰਤੋ, trophy ਵੱਜੋਂ ਨਹੀਂ। ਤੇਜ਼, ਦਿਲਚਸਪ ਟੈਸਟਾਂ 'ਤੇ ਧਿਆਨ ਦਿਉ ਜੋ CI ਵਿੱਚ ਤੇਜ਼ ਦੌੜਨ ਅਤੇ ਸਹੀ ਕਾਰਨਾਂ ਕਰਕੇ fail ਕਰਨ। flaky tests ਭਰੋਸਾ ਘਟਾਉਂਦੇ ਹਨ—ਅਤੇ ਜਦੋਂ ਲੋਕ suite 'ਤੇ ਭਰੋਸਾ ਕਰਨਾ ਬੰਦ ਕਰ ਦਿੰਦੇ ਨੇ, ਤਾਂ ਇਹ ਤੁਹਾਡੀ ਰੱਖਿਆ ਰੁਕ ਜਾਂਦੀ ਹੈ।
Automation ਓਸ ਜਗ੍ਹਾ ਹੈ ਜਿੱਥੇ AI-ਸਹਾਇਤ workflow “ਮੇਰੇ ਮਸ਼ੀਨ 'ਤੇ ਚੱਲਦੀ ਪ੍ਰੋਜੈਕਟ” ਤੋਂ ਇੱਕ ਅਜਿਹੇ ਪ੍ਰਕਿਰਿਆ ਵਿੱਚ ਬਦਲਦੀ ਹੈ ਜਿਸ ਨੂੰ ਤੁਸੀਂ ਭਰੋਸੇ ਨਾਲ ਸ਼ਿਪ ਕਰ ਸਕਦੇ ਹੋ। ਲਕਸ਼ fancy tooling ਨਹੀਂ—ਦੋਹਰਾਯੋਗਤਾ ਹੈ।
ਇੱਕ single command ਚੁਣੋ ਜੋ ਲੋਕਲ ਅਤੇ CI ਵਿੱਚ ਇੱਕੋ ਨਤੀਜਾ ਦੇਵੇ। Node ਲਈ ਇਹ npm run build ਹੋ ਸਕਦਾ ਹੈ; Python ਲਈ make build; ਮੋਬਾਈਲ ਲਈ ਇੱਕ ਵਿਸ਼ੇਸ਼ Gradle/Xcode build step।
ਅਤੇ dev ਅਤੇ production config ਨੂੰ ਪਹਿਲੇ ਤੋਂ ਅਲੱਗ ਰੱਖੋ। ਅਕਸਰ ਨਿਯਮ: dev defaults ਆਸਾਨ; production defaults ਸੁਰੱਖਿਅਤ।
{
"scripts": {
"lint": "eslint .",
"format": "prettier -w .",
"test": "vitest run",
"build": "vite build"
}
}
ਲਿਨਟਰ ਖਤਰਨਾਕ ਪੈਟਰਨ (unused variables, unsafe async calls) ਫੜਦਾ ਹੈ। ਫਾਰਮੈਟਰ noisy diffs ਨੂੰ ਰੋਕਦਾ ਹੈ। v1 ਲਈ ਨਿਯਮ ਮਿਆਰੀ ਰੱਖੋ, ਪਰ ਅਨੁਸ਼ਾਸਨ ਸਥਿਰ ਰੱਖੋ।
ਓਸ ਗੇਟ ਆਰਡਰ ਲਈ ਇੱਕ ਪ੍ਰੈਕਟਿਕਲ ਢੰਗ:
ਪਹਿਲਾ CI workflow ਛੋਟਾ ਹੋ ਸਕਦਾ ਹੈ: dependencies ਇੰਸਟਾਲ ਕਰੋ, gates ਚਲਾਓ, ਅਤੇ ਜਲਦੀ fail ਕਰੋ। ਇਹ ਹੀ ਟੁੱਟੇ ਕੋਡ ਨੂੰ ਖ਼ਾਮੋਸ਼ੀ ਨਾਲ ਲੈਂਡ ਹੋਣ ਤੋਂ ਰੋਕਦਾ ਹੈ।
name: ci
on: [push, pull_request]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: 20
- run: npm ci
- run: npm run format -- --check
- run: npm run lint
- run: npm test
- run: npm run build
ਫੈਸਲਾ ਕਰੋ ਕਿ ਸੀਕ੍ਰੇਟ ਕਿੱਥੇ ਰਹਿਣਗੇ: CI secret store, password manager, ਜਾਂ deployment platform ਦੇ environment settings। ਉਨ੍ਹਾਂ ਨੂੰ ਕਦੇ ਵੀ git ਵਿੱਚ commit ਨਾ ਕਰੋ—.env ਨੂੰ .gitignore ਵਿੱਚ ਜੋੜੋ, ਅਤੇ .env.example ਵਿਚ ਸੁਰੱਖਿਅਤ placeholders ਰੱਖੋ।
ਜੇ ਤੁਸੀਂ ਚਾਹੁੰਦੇ ਹੋ ਕਿ ਅਗਲਾ ਕਦਮ ਸਾਫ਼ ਹੋਵੇ, ਤਾਂ ਇਹ gates deployment ਪ੍ਰਕਿਰਿਆ ਨਾਲ ਜੁੜੋ ਤਾਂ ਕਿ “green CI” ਹੀ ਪ੍ਰੋਡਕਸ਼ਨ ਦਾ ਇੱਕ ਹੋਣਾ ਰਸਤਾ ਹੋਵੇ।
ਸ਼ਿਪ ਕਰਨਾ ਇਕ single button ਨਹੀਂ—ਇਹ ਇੱਕ ਦੋਹਰਾਯੋਗ ਰੁਟੀਨ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ। v1 ਲਈ ਲਕਸ਼ ਸਧਾਰਨ ਹੈ: ਆਪਣੀ ਸਟੈਕ ਨੂੰ ਮਿਲਣ ਵਾਲਾ deployment ਟਾਰਗੇਟ ਚੁਣੋ, ਛੋਟੇ increments ਵਿੱਚ ਡਿਪਲੋਈ ਕਰੋ, ਅਤੇ ਹਮੇਸ਼ਾ ਵਾਪਸੀ ਦਾ ਰਸਤਾ ਰੱਖੋ।
ਉਹ ਪਲੇਟਫਾਰਮ ਚੁਣੋ ਜੋ ਤੁਹਾਡੀ ਐਪ ਦੇ ਤਰੀਕੇ ਨਾਲ ਮਿਲੇ:
ਜੇ ਤੁਹਾਡੀ ਤਰਜੀਹ ਟੂਲ-ਸਵਿੱਚ ਘਟਾਉਣਾ ਹੈ, ਤਾਂ ਉਹ ਪਲੇਟਫਾਰਮ ਚੁਣੋ ਜੋ build + hosting + rollback ਪ੍ਰਿਮਿਟਿਵਜ਼ ਨੂੰ bundle ਕਰਦੇ ਹਨ। ਉਦਾਹਰਣ ਦੇ ਤੌਰ 'ਤੇ, Koder.ai deployment ਅਤੇ hosting ਨੂੰ snapshots ਅਤੇ rollback ਸਮੇਤ ਸਹਾਇਤਾ ਦਿੰਦਾ ਹੈ, ਤਾਂ ਜੋ ਤੁਸੀਂ ਰਿਲੀਜ਼ ਨੂੰ ਵਾਪਸੀਯੋਗ ਕਦਮ ਵਜੋਂ ਸTreat ਕਰੋ ਨਾ ਕਿ ਇਕ-ਤਰਫ਼ਾ ਦਰਵਾਜ਼ਾ।
ਇਕ ਵਾਰੀ ਚੈੱਕਲਿਸਟ ਲਿਖੋ ਅਤੇ ਹਰ ਰਿਲੀਜ਼ ਲਈ ਦੁਹਰਾਓ। ਇਸਨੂੰ ਛੋਟਾ ਰੱਖੋ ਤਾਂ ਕਿ ਲੋਕ ਵਾਕਈ ਅਪਣਾਉਂ:
ਜੇ ਤੁਸੀਂ ਇਸਨੂੰ ਰੀਪੋ ਵਿੱਚ ਰੱਖਦੇ ਹੋ (ਉਦਾਹਰਣ ਲਈ /docs/deploy.md), ਤਾਂ ਇਹ ਕੁਦਰਤੀ ਤੌਰ 'ਤੇ ਕੋਡ ਦੇ ਨੇੜੇ ਰਹਿੰਦਾ ਹੈ।
ਇੱਕ ਹਲਕੀ endpoint ਬਣਾਓ ਜੋ ਇਹ ਉੱਤਰ ਦੇ: "ਐਪ ਠੀਕ ਹੈ ਅਤੇ ਆਪਣੀਆਂ dependencies ਤੱਕ ਪਹੁੰਚ ਸਕਦਾ ਹੈ?" ਆਮ ਪੈਟਰਨ ਹਨ:
GET /health load balancers ਅਤੇ uptime monitors ਲਈ\n- GET /status ਜੋ ਮੁੱਢਲਾ app version + dependency checks ਵਾਪਸ ਕਰਦਾ ਹੈਜਵਾਬ ਤੇਜ਼, cache-free, ਅਤੇ ਸੁਰੱਖਿਅਤ ਰੱਖੋ (ਕੋਈ secrets ਜਾਂ ਅੰਦਰੂਨੀ ਵੇਰਵਾ ਨਾ ਦਿਖਾਓ)।
ਰੋਲਬੈਕ ਯੋਜਨਾ ਸਪਸ਼ਟ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ:\n\n- ਪਿਛਲੇ ਵਰਜ਼ਨ ਨੂੰ ਫਿਰ ਤੋਂ deploy ਕਰਨ ਦਾ ਤਰੀਕਾ (tag, release, ਜਾਂ image)\n- migrations ਬਾਰੇ ਕੀ ਕਰਨਾ (ਪਹਿਲਾਂ backward-compatible; reversible ਸਿਰਫ਼ ਜਦੋਂ ਜਰੂਰੀ ਹੋ)\n- ਰੋਲਬੈਕ ਕੌਣ ਫੈਸਲਾ ਕਰੇਗਾ, ਅਤੇ ਕਿਹੜੇ ਸੰਕੇਤ ਇਸਨੂੰ trigger ਕਰਨਗੇ (error rate, failed health checks)
ਜਦੋਂ deployment reversible ਹੋਵੇ, ਰਿਲੀਜ਼ ਰੁਟੀਨ ਬਣ ਜਾਂਦੀ ਹੈ—ਅਤੇ ਤੁਸੀਂ ਬਿਨਾ tension ਦੇ ਜ਼ਿਆਦਾ ਅਕਸਰ ਸ਼ਿਪ ਕਰ ਸਕਦੇ ਹੋ।
ਲਾਂਚ ਸਭ ਤੋਂ ਵਰਤੋਂਯੋਗ ਪੜਾਅ ਦੀ ਸ਼ੁਰੂਆਤ ਹੈ: ਜਿਸ ਵਿੱਚ ਅਸਲੀ ਯੂਜ਼ਰ ਕੀ ਕਰਦੇ ਹਨ, ਐਪ ਕਿੱਥੇ ਟੁੱਟਦੀ ਹੈ, ਅਤੇ ਕਿਹੜੇ ਛੋਟੇ ਬਦਲਾਅ ਤੁਹਾਡੇ ਸਫਲਤਾ ਮੈਟਰਿਕ ਨੂੰ ਹਿਲਾਉਂਦੇ ਹਨ, ਇਹ ਸਿੱਖਣਾ ਸ਼ੁਰੂ ਹੁੰਦਾ ਹੈ। ਉਦੇਸ਼ ਇਹ ਹੈ ਕਿ ਉਸੇ AI-ਸਹਾਇਤ workflow ਨੂੰ ਜਾਰੀ ਰੱਖੋ ਜੋ ਤੁਸੀਂ ਬਨਾਉਣ ਲਈ ਵਰਤੇ—ਹੁਣ ਸਬੂਤਾਂ ਦੀ ਦਿਸ਼ਾ ਵਿੱਚ।
ਸ਼ੁਰੂਆਤ ਇੱਕ ਘੱਟੋ-ਘੱਟ мਾਨੀਟਰਿੰਗ ਸਟੈਕ ਨਾਲ ਕਰੋ ਜੋ ਤਿੰਨ ਪ੍ਰਸ਼ਨਾਂ ਦਾ ਜਵਾਬ ਦਿੰਦਾ ਹੈ: ਕੀ ਇਹ ਚੱਲ ਰਿਹਾ ਹੈ? ਕੀ ਇਹ ਫੇਲ ਹੋ ਰਿਹਾ ਹੈ? ਕੀ ਇਹ ਧੀਮਾ ਹੈ?
Uptime checks ਸਾਦੇ ਹੋ ਸਕਦੇ ਹਨ (health endpoint ਨੂੰ ਸਮੇਂ-ਸਮੇਂ 'ਤੇ ਹਿੱਟ). Error tracking stack traces ਅਤੇ request context ਕੈਪਚਰ ਕਰੇ (ਸੰਵੇਦਨਸ਼ੀਲ ਡੇਟਾ ਨਾ ਇਕੱਤਰ ਕਰਦੇ ਹੋਏ). Performance ਮਾਨੀਟਰਿੰਗ ਮੁੱਖ endpoints ਅਤੇ front-end page load ਮੈਟ੍ਰਿਕਸ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ।
AI ਦੀ ਮਦਦ ਨਾਲ ਜਨਰੇਟ ਕਰੋ:\n\n- ਇੱਕ logging ਫਾਰਮੈਟ ਅਤੇ correlation IDs ਤਾਂ ਜੋ ਇੱਕ ਯੂਜ਼ਰ ਐਕਸ਼ਨ end-to-end ਟਰੇਸ ਹੋ ਸਕੇ\n- alert thresholds (ਸੁਰੂਆਤੀ ਭਿਆਨਕ) ਅਤੇ ਇੱਕ “on-call” ਚੈਕਲਿਸਟ ਜੋ ਸਭ ਤੋਂ ਪਹਿਲਾ ਕਾਉਣ ਕਰੇ
ਹਰ ਚੀਜ਼ ਨੂੰ ਟ੍ਰੈਕ ਨਾ ਕਰੋ—ਉਹ ਚੀਜ਼ਾਂ ਟਰੈਕ ਕਰੋ ਜੋ ਇਹ ਸਾਬਤ ਕਰਦੀਆਂ ਹਨ ਕਿ ਐਪ ਕੰਮ ਕਰ ਰਹੀ ਹੈ। ਇੱਕ ਪ੍ਰਾਈਮਰੀ success metric ਤਹਿ ਕਰੋ (ਉਦਾਹਰਣ: “completed checkout,” “created first project,” ਜਾਂ “invited a teammate”)। ਫਿਰ ਇੱਕ ਛੋਟਾ ਫਨਲ ਇੰਸਟ੍ਰੂਮੈਂਟ ਕਰੋ: entry → key action → success।
AI ਤੋਂ ਮੰਗੋ ਕਿ ਉਹ event names ਅਤੇ properties ਸੁਝਾਓ, ਫਿਰ ਉਨ੍ਹਾਂ ਦੀ privacy ਅਤੇ ਸਪಷ್ಟਤਾ ਲਈ ਸਮੀਖਿਆ ਕਰੋ। events ਨੂੰ ਸਥਿਰ ਰੱਖੋ; ਹਰ ਹਫ਼ਤੇ ਨਾਂ ਬਦਲਣ ਨਾਲ ਰੁਝਾਨ ਮੈਟਰਿਕਸ ਬੇਮਾਨੀ ਹੋ ਜਾਂਦੇ ਹਨ।
ਇੱਕ ਸੌਖਾ intake ਬਣਾਓ: In-app feedback ਬਟਨ, ਇੱਕ ਛੋਟੀ ਈਮੇਲ ਐਲਿਆਸ, ਅਤੇ ਇੱਕ ਹਲਕੀ bug ਟੈਂਪਲੇਟ। ਹਫ਼ਤਾਵਾਰੀ triage ਕਰੋ: ਫੀਡਬੈਕ ਨੂੰ ਥੀਮਾਂ ਵਿੱਚ ਗਰੁੱਪ ਕਰੋ, ਥੀਮਾਂ ਨੂੰ analytics ਨਾਲ ਜੋੜੋ, ਅਤੇ ਅਗਲੇ 1–2 ਸੁਧਾਰਾਂ ਦਾ ਫੈਸਲਾ ਕਰੋ।
ਮਾਨੀਟਰਿੰਗ alerts, analytics ਘਟਾਓ, ਅਤੇ ਫੀਡਬੈਕ ਥੀਮਾਂ ਨੂੰ ਨਵੇਂ “requirements” ਵਜੋਂ ਟਰੀਟ ਕਰੋ। ਉਹਨਾਂ ਨੂੰ ਉਸੇ ਪ੍ਰਕਿਰਿਆ ਵਿੱਚ ਫੀਡ ਕਰੋ: doc ਨੂੰ ਅਪਡੇਟ ਕਰੋ, ਇੱਕ ਛੋਟਾ change proposal ਜਨਰੇਟ ਕਰੋ, ਪਤਲਾ slice implement ਕਰੋ, ਇੱਕ ਨਿਸ਼ਾਨ ਟੈਸਟ ਜੋੜੋ, ਅਤੇ ਉਸੇ reversible release ਪ੍ਰਕਿਰਿਆ ਰਾਹੀਂ ਡਿਪਲੋਈ ਕਰੋ। ਟੀਮਾਂ ਲਈ, ਇੱਕ ਸਾਂਝਾ “Learning Log” ਪੇਜ (repo ਵਿੱਚ /docs ਜਾਂ ਅੰਦਰੂਨੀ ਡੌਕ) ਫੈਸਲਿਆਂ ਨੂੰ ਦਿੱਖਯੋਗ ਅਤੇ ਦੁਹਰਾਯੋਗ ਰੱਖਦਾ ਹੈ।
“Single workflow” ਇਕ ਲਗਾਤਾਰ ਧਾਰ ਹੈ ਜਿੱਥੇ ਇੱਕ ਵਿਚਾਰ ਤੋਂ ਪ੍ਰੋਡਕਸ਼ਨ ਤੱਕ ਸਭ ਕੁਝ ਇੱਕ ਥਾਂ ਤੇ ਜੋੜਿਆ ਜਾਂਦਾ ਹੈ:
ਤੁਸੀਂ ਹਾਲੇ ਵੀ ਅਨੇਕ ਟੂਲ ਵਰਤੋਂਗੇ, ਪਰ ਹਰ ਫੇਜ਼ 'ਤੇ ਪ੍ਰੋਜੈਕਟ ਨੂੰ “ਸ਼ੁਰੂ ਤੋਂ ਦੁਬਾਰਾ” ਨਹੀਂ ਕਰਨਾ ਪਏਗਾ।
AI ਨੂੰ ਵਿਕਾਸ ਵਿੱਚ ਇਸ ਤਰ੍ਹਾਂ ਵਰਤੋ ਕਿ ਉਹ ਛਾਂਟੀਆਂ ਤੇ ਡਰਾਫਟ ਪੇਸ਼ ਕਰੇ, ਪਰ ਫ਼ੈਸਲੇ ਤੁਹਾਡੇ ਹੋਣ:
ਫੈਸਲਾ ਕਰਨ ਦੀ ਨੀਤੀ ਸਪਸ਼ਟ ਰੱਖੋ: “ਕੀ ਇਹ ਮੈਟਰਿਕ ਨੂੰ ਅੱਗੇ ਵਧਾਉਂਦਾ ਹੈ, ਅਤੇ ਕੀ ਇਹ ਸੁਰੱਖਿਅਤ ਤੌਰ 'ਤੇ ਸ਼ਿਪ ਕਰਨ ਯੋਗ ਹੈ?”
ਮੇਟਰਿਕ ਨੂੰ ਨਾਪਣਯੋਗ ਬਣਾਉ ਅਤੇ v1 ਲਈ ਇੱਕ ਤੰਗ “definition of done” ਤਹਿ ਕਰੋ। ਉਦਾਹਰਣ ਲਈ:
ਜੇ ਕੋਈ ਫੀਚਰ ਇਹਨਾਂ ਨਤੀਜਿਆਂ ਨੂੰ ਸਹਾਇਕ ਨਹੀਂ ਹੈ ਤਾਂ ਉਹ v1 ਲਈ ਨਾਂ-ਮਕਸਦ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ।
ਛੋਟੀ, ਸਕਿਮੇਬਲ ਇਕ-ਪੇਜ PRD ਵਿੱਚ ਸ਼ਾਮِل ਕਰੋ:
ਫਿਰ 5–10 ਕੋਰ ਫੀਚਰ ਲਿਖੋ, Must/Should/Nice ਵੱਜੋਂ ਰੈਂਕ ਕਰੋ। ਇਹ ਰੈਂਕਿੰਗ AI ਨੂੰ ਸੀਮਿਤ ਰਾਜਾਂ ਅਤੇ ਕੋਡ ਲਈ ਰਾਹ ਦਿੰਦੀਆਂ ਹਨ।
ਟਾਪ 3–5 ਫੀਚਰਾਂ ਲਈ 2–4 ਟੈਸਟੇਬਲ ਬਿਆਨ ਬਣਾਓ। ਚੰਗੇ acceptance criteria ਹਨ:
ਉਦਾਹਰਣ: ਵੈਲੀਡੇਸ਼ਨ ਨਿਯਮ, ਉਮੀਦ ਕੀਤੀ ਰੀਡਾਇਰੈਕਟ, ਐਰਰ ਸੁਨੇਹੇ, ਅਤੇ ਅਧਿਕਾਰਨ ਵਰਤੋਂ (ਜਿਵੇਂ “Unauthorized ਯੂਜ਼ਰ ਨੂੰ ਸਪਸ਼ਟ ਐਰਰ ਮਿੱਲੇ ਅਤੇ ਕੋਈ ਡੇਟਾ ਲੀਕ ਨਾ ਹੋਵੇ”)।
ਸਭ ਤੋਂ ਪਹਿਲਾਂ ਸਧਾਰਨ “happy path” ਨੰਬਰਵਾਰ ਲਿਖੋ, ਫਿਰ ਕੁਝ ਉੱਚ-ਸੰਭਾਵਨਾ/ਉੱਚ-ਲਾਗਤ ਫੇਲ੍ਹ-ਸਥਿਤੀਆਂ ਜੋੜੋ:
ਇੱਕ ਸادہ ਸੂਚੀ ਹੀ ਕਾਫ਼ੀ ਹੈ; ਉਦੇਸ਼ UI ਸਥਿਤੀਆਂ, API ਜਵਾਬਾਂ ਅਤੇ ਟੈਸਟਾਂ ਲਈ ਮਾਰਗਦਰਸ਼ਨ ਦੇਣਾ ਹੈ।
v1 ਲਈ “ਮੋਡੀਅਲ ਮੋਨੋਲਿਥ” ਨੂੰ ਡਿਫ਼ੌਲਟ ਮੰਨੋ:
ਕੇਵਲ ਉਦੋਂ ਹੋਰ ਸਰਵਿਸਿਜ਼ ਜੋੜੋ ਜਦੋਂ ਕੋਈ ਸਪੱਸ਼ਟ ਲੋੜ ਬਣੇ। ਇਹ coordination ਬੋਝ ਘਟਾਉਂਦਾ ਹੈ ਅਤੇ AI-ਸਹਾਇਤ iteration ਨੂੰ ਆਸਾਨ ਬਣਾਉਂਦਾ ਹੈ।
ਸਟਾਰਟ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ ਇੱਕ ਸੂਖਮ “API contract” ਟੇਬਲ ਲਿਖੋ:
{ error: { code, message } })ਇਸ ਨਾਲ UI ਅਤੇ ਬੈਕਐਂਡ ਵਿਚ গোলমাল ਨਹੀਂ ਹੁੰਦੀ ਅਤੇ ਟੈਸਟਾਂ ਨੂੰ ਇਕ ਥਿਰ ਟਾਰਗੇਟ ਮਿਲਦਾ ਹੈ।
ਸਕੈਲੈਟਨ ਲਈ ਟੀਕ-ਟੌਕ ‘hello app’ ਲਕਸ਼ ਐਸਾ ਰੱਖੋ:
/health) ਨੂੰ ਕਾਲ ਕਰਦਾ ਹੋਵੇ.env.example ਅਤੇ ਇੱਕ README ਜੋ ਇਕ ਮਿੰਟ ਤੋਂ ਘੱਟ ਵਿੱਚ ਚੱਲਾਏ ਜਾ ਸਕੇਛੋਟੀ-ਛੋਟੀ ਮਾਈਲਸਟੋਨ ਕਮੇਟ ਕਰੋ ਤਾਂ ਕਿ ਜੇ ਕੋਈ generated ਬਦਲਾਅ ਗਲਤ ਹੋਵੇ ਤਾਂ ਅਸਾਨੀ ਨਾਲ ਰਿਵਰਟ ਕੀਤਾ ਜਾ ਸਕੇ।
ਉਹ ਟੈਸਟਾਂ ਅਤੇ CI ਗੇਟਾਂ ਅਹਿਮ ਹਨ ਜੋ ਮਹਿੰਗੀਆਂ ਗਲਤੀਆਂ ਰੋਕਦੇ ਹਨ:
CI ਵਿੱਚ ਸਿੰਪਲ ਗੇਟ ਅਨੁਕ੍ਰਮ ਨੂੰ ਲਾਗੂ ਕਰੋ:
ਟੈਸਟਾਂ ਨੂੰ ਸਥਿਰ ਅਤੇ ਤੇਜ਼ ਰੱਖੋ; flaky suite ਵਿਸ਼ਵਾਸ ਖਤਮ ਕਰ ਦਿੰਦਾ ਹੈ।