23 ਅਕਤੂ 2025·6 ਮਿੰਟ
ਸਰਵਰ-ਪਾਸੇ ਵਿਰੁੱਧ ਕਲਾਇੰਟ-ਪਾਸੇ ਫਿਲਟਰਿੰਗ: ਫੈਸਲਾ ਕਰਨ ਲਈ ਚੈੱਕਲਿਸਟ
ਡੇਟਾ ਦੇ ਆਕਾਰ, ਲੇਟੈਂਸੀ, ਅਧਿਕਾਰ ਅਤੇ ਕੈਸ਼ਿੰਗ ਦੇ ਆਧਾਰ 'ਤੇ ਸਰਵਰ-ਵਿਰੁੱਧ ਕਲਾਇੰਟ ਫਿਲਟਰਿੰਗ ਲਈ ਚੈੱਕਲਿਸਟ — ਬਿਨਾਂ UI ਲੀਕ ਜਾਂ ਲੈਗ ਦੇ।
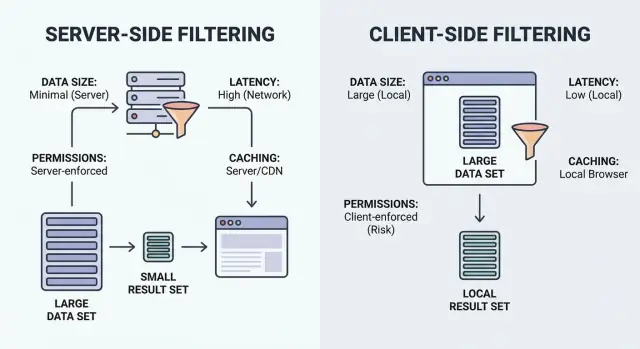
ਡੇਟਾ ਦੇ ਆਕਾਰ, ਲੇਟੈਂਸੀ, ਅਧਿਕਾਰ ਅਤੇ ਕੈਸ਼ਿੰਗ ਦੇ ਆਧਾਰ 'ਤੇ ਸਰਵਰ-ਵਿਰੁੱਧ ਕਲਾਇੰਟ ਫਿਲਟਰਿੰਗ ਲਈ ਚੈੱਕਲਿਸਟ — ਬਿਨਾਂ UI ਲੀਕ ਜਾਂ ਲੈਗ ਦੇ।
UI ਵਿੱਚ ਫਿਲਟਰਿੰਗ ਸਿਰਫ਼ ਇੱਕ ਖੋਜ ਬਾਕਸ ਤੋਂ ਵੱਧ ਹੁੰਦੀ ਹੈ। ਇਹ ਆਮ ਤੌਰ 'ਤੇ ਕੁਝ ਸੰਬੰਧਿਤ ਕਾਰਵਾਈਆਂ ਸ਼ਾਮਲ ਕਰਦੀ ਹੈ ਜੋ ਇਸਦੇ ਨਾਲ ਦਿੱਖ ਨੂੰ ਬਦਲਦੀਆਂ ਹਨ: ਟੈਕਸਟ ਖੋਜ (ਨਾਂ, ਈਮੇਲ, ਆਰਡਰ ID), ਫੇਸੈਟਸ (ਸਥਿਤੀ, ਮਾਲਕ, ਤਾਰੀਖ ਸੀਮਾ, ਟੈਗ), ਅਤੇ ਸੋਰਟਿੰਗ (ਨਵੀਂ, ਵੱਡੀ ਕੀਮਤ, ਆਖਰੀ ਸਰਗਰਮੀ)।
ਮੁੱਖ ਸਵਾਲ ਇਹ ਨਹੀਂ ਕਿ ਕਿਹੜੀ ਤਕਨੀਕ "ਵਧੀਆ" ਹੈ। ਇਹ ਇਸ ਗੱਲ 'ਤੇ ਹੈ ਕਿ ਪੂਰਾ ਡੇਟਾਸੈਟ ਕਿੱਥੇ ਰਹਿੰਦਾ ਹੈ ਅਤੇ ਕੌਣ ਉਸ ਤੱਕ ਪਹੁੰਚ ਕਰ ਸਕਦਾ ਹੈ। ਜੇ ਬ੍ਰਾਉਜ਼ਰ ਨੂੰ ਉਹ ਰਿਕਾਰਡ ਮਿਲਦੇ ਹਨ ਜੋ ਯੂਜ਼ਰ ਨੂੰ ਨਹੀਂ ਦੇਖਣੇ ਚਾਹੀਦੇ, ਤਾਂ UI ਦਿੱਖ ਵਿੱਚ ਲੁਕਾਉਣ ਦੇ ਬਾਵਜੂਦ ਸੰਵੇਦਨਸ਼ੀਲ ਡਾਟਾ ਪ੍ਰਗਟ ਕਰ ਸਕਦਾ ਹੈ।
ਜਿਆਦਾਤਰ ਸਰਵਰ-ਵਿਰੁੱਧ ਕਲਾਇੰਟ-ਪਾਸੇ ਫਿਲਟਰਿੰਗ 'ਤੇ ਚਰਚਾਵਾਂ ਦਰਅਸਲ ਦੋ ਤਰ੍ਹਾਂ ਦੀਆਂ ਨਾਕਾਮੀਆਂ 'ਤੇ ਪ੍ਰਤੀਕਿਰਿਆ ਹੁੰਦੀਆਂ ਹਨ ਜਿਨ੍ਹਾਂ ਨੂੰ ਯੂਜ਼ਰ ਤੁਰੰਤ ਮਹਿਸੂਸ ਕਰਦੇ ਹਨ:
ਇੱਕ ਤੀਜਾ ਮੁੱਦਾ ਜੋ ਬੇਅੰਤ ਬੱਗ ਰਿਪੋਰਟਾਂ ਪੈਦਾ ਕਰਦਾ ਹੈ: ਅਸੰਗਤ ਨਤੀਜੇ। ਜੇ ਕੁਝ ਫਿਲਟਰ ਕਲਾਇੰਟ 'ਤੇ ਚੱਲ ਰਹੇ ਹਨ ਅਤੇ ਹੋਰ ਸਰਵਰ 'ਤੇ, ਤਾਂ ਯੂਜ਼ਰ ਗਿਣਤੀਆਂ, ਪੰਨੇ, ਅਤੇ ਟੋਟਲ ਵੇਖਦੇ ਹਨ ਜੋ ਮੇਲ ਨਹੀਂ ਖਾਂਦੇ। ਇਹ ਖਾਸ ਕਰਕੇ ਪੇਜੀਨੇਟਡ ਲਿਸਟਾਂ 'ਤੇ ਭਰੋਸਾ ਤੋੜ ਦੇਂਦਾ ਹੈ।
ਇੱਕ ਪ੍ਰਯੋਗਿਕ ਡਿਫੌਲਟ ਸਾਦਾ ਹੈ: ਜੇ ਯੂਜ਼ਰ ਨੂੰ ਪੂਰਾ ਡੇਟਾਸੈਟ ਵੇਖਣ ਦੀ ਇਜਾਜ਼ਤ ਨਹੀਂ, ਤਾਂ ਸਰਵਰ 'ਤੇ ਫਿਲਟਰ ਕਰੋ। ਜੇ ਉਹ ਵੇਖ ਸਕਦਾ ਹੈ ਅਤੇ ਡੇਟਾ ਛੋਟਾ ਹੈ ਤਾਂ ਕਲਾਇੰਟ-ਪਾਸੇ ਫਿਲਟਰਿੰਗ ਠੀਕ ਰਹਿ ਸਕਦੀ ਹੈ।
ਫਿਲਟਰਿੰਗ ਸਿਰਫ਼ "ਉਹ ਆਈਟਮ ਦਿਖਾਓ ਜੋ ਮਿਲਦੇ ਹਨ" ਹੈ। ਮੁੱਖ ਸਵਾਲ ਇਹ ਹੈ ਕਿ ਮੈਚ ਕਿੱਥੇ ਹੁੰਦਾ ਹੈ: ਯੂਜ਼ਰ ਦੇ ਬ੍ਰਾਉਜ਼ਰ ਵਿੱਚ (ਕਲਾਇੰਟ) ਜਾਂ ਤੁਹਾਡੇ ਬੈਕਐਂਡ 'ਤੇ (ਸਰਵਰ)।
ਕਲਾਇੰਟ-ਪਾਸੇ ਫਿਲਟਰਿੰਗ ਬ੍ਰਾਉਜ਼ਰ ਵਿੱਚ ਚੱਲਦੀ ਹੈ। ਐਪ ਕੁਝ ਰਿਕਾਰਡ (ਅਕਸਰ JSON) ਡਾਊਨਲੋਡ ਕਰਦਾ ਹੈ, ਫਿਰ ਲੋਕਲ ਤੌਰ 'ਤੇ ਫਿਲਟਰ ਲਗਾਉਂਦਾ ਹੈ। ਡਾਟਾ ਲੋਡ ਹੋਣ ਤੋਂ ਬਾਅਦ ਇਹ ਤੁਰੰਤ ਮਹਿਸੂਸ ਹੋ ਸਕਦੀ ਹੈ, ਪਰ ਇਹ ਸਿਰਫ਼ ਉਦੋਂਕ ਹੀ ਕੰਮ ਕਰਦੀ ਹੈ ਜਦੋਂ ਡੇਟਾਸੈਟ ਛੋਟਾ ਹੋਵੇ ਅਤੇ ਖੁਲਾਸਾ ਕਰਨ ਲਈ ਸੁਰੱਖਿਅਤ ਹੋਵੇ।
ਸਰਵਰ-ਪਾਸੇ ਫਿਲਟਰਿੰਗ ਤੁਹਾਡੇ ਬੈਕਐਂਡ 'ਤੇ ਚੱਲਦੀ ਹੈ। ਬ੍ਰਾਉਜ਼ਰ ਫਿਲਟਰ ਇਨਪੁਟ ਭੇਜਦਾ ਹੈ (ਜਿਵੇਂ status=open, owner=me, createdAfter=Jan 1), ਅਤੇ ਸਰਵਰ ਸਿਰਫ਼ ਉਹੀ ਮੈਚਿੰਗ ਨਤੀਜੇ ਵਾਪਸ ਭੇਝਦਾ ਹੈ। ਅਮਲੀ ਤੌਰ 'ਤੇ ਇਹ ਆਮ ਤੌਰ 'ਤੇ ਇੱਕ API ਐਂਡਪੌਇੰਟ ਹੁੰਦਾ ਹੈ ਜੋ ਫਿਲਟਰ ਲੈਂਦਾ ਹੈ, ਡਾਟਾਬੇਸ ਕੁਐਰੀ ਬਣਾਉਂਦਾ ਹੈ, ਅਤੇ ਪੇਜਿਨੇਟਡ ਲਿਸਟ ਅਤੇ ਟੋਟਲ ਵਾਪਸ ਕਰਦਾ ਹੈ।
ਸਧਾਰਨ ਮਾਨਸਿਕ ਮਾਡਲ:
ਹਾਈਬ੍ਰਿਡ ਸੈਟਅਪ ਆਮ ਹਨ। ਇੱਕ ਵਧੀਆ ਰੀਤੀ ਇਹ ਹੈ ਕਿ ਬੜੇ ਫਿਲਟਰ (ਅਧਿਕਾਰ, ਮਾਲਕੀਅਤ, ਤਾਰੀਖ ਸੀਮਾ, ਖੋਜ) ਸਰਵਰ 'ਤੇ ਲਾਗੂ ਕਰੋ, ਫਿਰ ਛੋਟੇ UI-ਕੇਵਲ ਟੋਗਲ (ਹਾਈਡ ਆਰਕਾਈਵਡ ਆਈਟਮ, ਫਾਸਟ ਟੈਗ ਚਿਪਸ, ਕਾਲਮ ਵਿਸ਼ੀਬਿਲਟੀ) ਲੋਕਲ ਤੌਰ 'ਤੇ ਬਿਨਾਂ ਹੋਰ ਰਿਕਵੇਸਟ ਦੇ ਵਰਤੋ।
ਸੋਰਟਿੰਗ, ਪੇਜਿਨੇਸ਼ਨ, ਅਤੇ ਖੋਜ ਆਮ ਤੌਰ 'ਤੇ ਉਸੇ ਫੈਸਲੇ ਨਾਲ ਜੁੜੇ ਹੁੰਦੇ ਹਨ। ਉਹ ਪੇਲੋਡ ਆਕਾਰ, ਯੂਜ਼ਰ ਅਨੁਭਵ, ਅਤੇ ਤੁਹਾਡੇ ਦੁਆਰਾ ਖੁਲਾਸਾ ਹੋ ਰਹੇ ਡਾਟਾ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰਦੇ ਹਨ।
ਸਭ ਤੋਂ ਪ੍ਰਾਇਕਟਿਕ ਸਵਾਲ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ: ਜੇ ਤੁਸੀਂ ਕਲਾਇੰਟ 'ਤੇ ਫਿਲਟਰ ਕਰੋ ਤਾਂ ਤੁਸੀਂ ਬ੍ਰਾਉਜ਼ਰ ਨੂੰ ਕਿੰਨਾ ਡਾਟਾ ਭੇਜੋਗੇ? ਜੇ ਸਚਾ ਉੱਤਰ "ਕੁਝ ਸਕ੍ਰੀਨਾਂ ਤੋਂ ਵੱਧ" ਹੈ, ਤਾਂ ਤੁਸੀਂ ਡਾਊਨਲੋਡ ਸਮੇਂ, ਮੇਮੋਰੀ ਖਪਤ, ਅਤੇ ਧੀਮੀ ਇੰਟਰੈਕਸ਼ਨ 'ਤੇ ਦੀ ਕੀਮਤ ਭਰੋਂਗੇ।
ਤੁਹਾਨੂੰ ਬਿਲਕੁਲ ਸਹੀ ਅਨੁਮਾਨ ਦੀ ਲੋੜ ਨਹੀਂ। ਸਿਰਫ਼ ਆਕਾਰ ਦਾ ਆੰਦਾਜ਼ ਲਾਓ: ਯੂਜ਼ਰ ਕਿੰਨੀ ਕਤਾਰਾਂ ਦੇਖ ਸਕਦਾ ਹੈ, ਅਤੇ ਪ੍ਰਤੀ ਕਤਾਰ ਦਾ ਆਮ ਆਕਾਰ ਕੀ ਹੈ? 500 ਆਈਟਮਾਂ ਦੀ ਲਿਸਟ ਛੋਟੇ ਖੇਤਰਾਂ ਨਾਲ ਬਹੁਤ ਵੱਖਰੀ ਹੋ ਸਕਦੀ ਹੈ ਉਸ ਤੋਂ 50,000 ਆਈਟਮਾਂ ਦੇ ਜਿਥੇ ਹਰ ਕਤਾਰ ਵਿੱਚ ਲੰਮੇ ਨੋਟਸ, ਰਿਚ ਟੈਕਸਟ, ਜਾਂ ਨੈਸਟਡ ਓਬਜੈਕਟ ਹੋਣ।
ਵਿਆਪਕ ਰਿਕਾਰਡ ਸ਼ਾਂਤ ਪੇਲੋਡ ਕਤਲਹੰਦੇ ਹਨ। ਇੱਕ ਟੇਬਲ ਦਰਸਣ ਵਿੱਚ ਕਤਾਰ ਗਿਣਤੀ ਨਾਲ ਛੋਟੀ ਲੱਗ ਸਕਦੀ ਹੈ ਪਰ ਭਾਰਤੀ ਹੋ ਸਕਦੀ ਹੈ ਜੇ ਹਰ ਕਤਾਰ ਵਿੱਚ ਘਣੇ ਫੀਲਡ, ਲੰਬੇ ਸਤਰ, ਜਾਂ ਜੋੜੀ ਹੋਈ ਡੇਟਾ ਹੋਵੇ (ਸੰਪਰਕ + ਕੰਪਨੀ + ਆਖਰੀ ਸਰਗਰਮੀ + ਪੂਰਾ ਪਤਾ + ਟੈਗ)। ਅਕਸਰ ਦਿਖਾਉਣ ਲਈ ਸਿਰਫ਼ ਤਿੰਨ ਕਾਲਮ ਹੀ ਚਾਹੀਦੇ ਹੋਣ, ਪਰ ਟੀਮ "ਸਭ ਕੁਝ ਭੇਜ ਦਿੰਦੀ ਹੈ, ਸੁਰੱਖਿਆ ਲਈ" ਅਤੇ ਪੇਲੋਡ ਫੂਲ ਹੋ ਜਾਂਦਾ ਹੈ।
ਵੱਧਣ ਬਾਰੇ ਵੀ ਸੋਚੋ। ਅਜਿਹਾ ਡੇਟਾ ਜਿਹੜਾ ਅੱਜ ਠੀਕ ਹੈ, ਕੁਝ ਮਹੀਨਿਆਂ ਵਿੱਚ ਦੁੱਖਦਾਈ ਹੋ ਸਕਦਾ ਹੈ। ਜੇ ਡੇਟਾ ਤੇਜ਼ੀ ਨਾਲ ਵੱਧਦਾ ਹੈ, ਤਾਂ ਕਲਾਇੰਟ-ਪਾਸੇ ਫਿਲਟਰਿੰਗ ਨੂੰ ਅਸਥਾਈ ਛੇਤੀ ਰਾਹ ਸਮਝੋ, ਡਿਫੌਲਟ ਨਹੀਂ।
ਨਿਯਮ-ਹਥਿਆਰ:
ਇਹ ਆਖਰੀ ਗੱਲ ਪ੍ਰਦਰਸ਼ਨ ਤੋਂ ਵੱਧ ਮਹੱਤਵਪੂਰਨ ਹੈ। "ਕੀ ਅਸੀਂ ਪੂਰਾ ਡੇਟਾਸੈਟ ਬ੍ਰਾਉਜ਼ਰ ਨੂੰ ਭੇਜ ਸਕਦੇ ਹਾਂ?" ਇਹ ਵੀ ਇੱਕ ਸੁਰੱਖਿਆ ਸਵਾਲ ਹੈ। ਜੇ ਉੱਤਰ ਪੱਕਾ ਨਹੀਂ ਹੈ, ਤਾਂ ਨਾ ਭੇਜੋ।
ਫਿਲਟਰਿੰਗ ਦੇ ਫੈਸਲੇ ਅਕਸਰ ਸਹੀਤਾ ਦੀ ਨਾ ਕਰਕੇ ਅਨੁਭਵ 'ਤੇ ਫੇਲ ਹੁੰਦੇ ਹਨ। ਯੂਜ਼ਰ ਮਿਲੀਸੈਕਿੰਡਾਂ ਨੂੰ ਨਹੀਂ ਮਾਪਦੇ। ਉਹ ਠਹਿਰਾਅ, ਫਲਿਕਰ, ਅਤੇ ਟਾਈਪ ਕਰਦਿਆਂ ਨਤੀਜਿਆਂ ਦੇ ਦੁਬਾਰਾ-ਉਛਲਦੇ ਦੇਖਦੇ ਹਨ।
ਸਮਾਂ ਵੱਖ-ਵੱਖ ਜਗ੍ਹਾਂ ਖਰਚ ਹੁੰਦਾ ਹੈ:
ਇਸ ਸਕ੍ਰੀਨ ਲਈ "ਤੇਜ਼ ਕਿੰਨਾ ਤੇਜ਼" ਹੈ ਇਹ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ। ਇੱਕ ਲਿਸਟ ਵਿਊ ਨੂੰ ਟਾਈਪਿੰਗ ਦੇ ਦੌਰਾਨ ਜਵਾਬਦੇਹ ਅਤੇ ਸਹਿਜ ਸਕ੍ਰੋਲਿੰਗ ਦੀ ਲੋੜ ਹੋ ਸਕਦੀ ਹੈ, ਜਦਕਿ ਇੱਕ ਰਿਪੋਰਟ ਪੇਜ਼ ਛੋਟੀ ਉਡੀਕ ਬਰਦਾਸ਼ਤ ਕਰ ਸਕਦਾ ਹੈ ਜੇ ਪਹਿਲਾ ਨਤੀਜਾ ਤੁਰੰਤ ਆ ਜਾਵੇ।
ਸਿਰਫ਼ ਦਫ਼ਤਰ Wi-Fi 'ਤੇ ਮਾਪ ਨਾ ਕਰੋ। ਧੀਮਿਆਂ ਕਨੈਕਸ਼ਨਾਂ 'ਤੇ, ਕਲਾਇੰਟ-ਪਾਸੇ ਫਿਲਟਰਿੰਗ ਪਹਿਲੀ ਲੋਡ ਤੋਂ ਬਾਅਦ ਵਧੀਆ ਲੱਗ ਸਕਦੀ ਹੈ, ਪਰ ਉਹ ਪਹਿਲੀ ਲੋਡ ਸਭ ਤੋਂ ਧੀਮਾ ਹਿੱਸਾ ਹੋ ਸਕਦੀ ਹੈ। ਸਰਵਰ-ਪਾਸੇ ਫਿਲਟਰਿੰਗ ਪੇਲੋਡ ਛੋਟੇ ਰੱਖਦੀ ਹੈ, ਪਰ ਜੇ ਤੁਸੀਂ ਹਰ ਕੀਸਟਰੋਕ 'ਤੇ ਰਿਕਵੇਸਟ ਭੇਜੋ ਤਾਂ ਇਹ ਧੀਮੀ ਮਹਿਸੂਸ ਹੋ ਸਕਦੀ ਹੈ।
ਇंसਾਨੀ ਇਨਪੁੱਟ ਦੇ ਆਧਾਰ 'ਤੇ ਡਿਜ਼ਾਇਨ ਕਰੋ। ਟਾਈਪ ਕਰਨ ਦੌਰਾਨ ਡੀਬਾਊਂਸ ਕਰੋ। ਵੱਡੇ ਰਿਜ਼ਲਟ ਸੈੱਟ ਲਈ ਪ੍ਰੋਗਰੇਸਿਵ ਲੋਡਿੰਗ ਵਰਤੋਂ ਤਾਂ ਕਿ ਪੇਜ਼ ਤੁਰੰਤ ਕੁਝ ਦਿਖਾਏ ਅਤੇ ਯੂਜ਼ਰ ਸਕ੍ਰੋਲ ਕਰਦਿਆਂ ਸਾਫ਼ ਰਹੇ।
ਅਧਿਕਾਰਾਂ ਨੂੰ ਤੁਹਾਡੇ ਫਿਲਟਰਿੰਗ ਤਰੀਕੇ ਨੂੰ ਗਤੀਸ਼ੀਲਤਾ ਨਾਲ ਨਹੀਂ, ਬਲਕਿ ਤਰਜੀਹ ਨਾਲ ਨਿਰਧਾਰਤ ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ। ਜੇ ਬ੍ਰਾਉਜ਼ਰ ਨੂੰ ਕਦੇ ਵੀ ਉਹ ਡੇਟਾ ਮਿਲਦਾ ਹੈ ਜਿਸਨੂੰ ਯੂਜ਼ਰ ਵੇਖਣ ਦੀ ਇਜਾਜ਼ਤ ਨਹੀਂ, ਤਾਂ ਤੁਸੀਂ ਪਹਿਲਾਂ ਹੀ ਸਮੱਸਿਆ ਵਿੱਚ ਹੋ, ਭਾਵੇਂ ਤੁਸੀਂ UI ਵਿੱਚ ਉਸਨੂੰ ਲੁਕਾਈ ਵੀ ਦਿਓ।
ਇਸ ਸਕ੍ਰੀਨ 'ਤੇ ਸੰਵੇਦਨਸ਼ੀਲ ਕੀ ਹੈ ਇਹ ਨਾਮ ਦੇ ਕੇ ਸ਼ੁਰੂ ਕਰੋ। ਕੁਝ ਫੀਲਡ ਸਪਸ਼ਟ ਹੁੰਦੇ ਹਨ (ਈਮੇਲ, ਫੋਨ ਨੰਬਰ, ਪਤੇ)। ਹੋਰ ਆਸਾਨੀ ਨਾਲ ਨਜ਼ਰਅੰਦਾਜ਼ ਹੋ ਸਕਦੇ ਹਨ: ਅੰਦਰੂਨੀ ਨੋਟਸ, ਲਾਗਤ ਜਾਂ ਮਾਰਜਿਨ, ਖਾਸ ਕੀਮਤ ਨਿਯਮ, ਰਿਸਕ ਸਕੋਰ, ਮੋਡਰੇਸ਼ਨ ਫਲੈਗ।
ਵੱਡਾ ਫੰਦ ਇਹ ਹੈ: "ਅਸੀਂ ਕਲਾਇੰਟ 'ਤੇ ਫਿਲਟਰ ਕਰਦੇ ਹਾਂ, ਪਰ ਸਿਰਫ਼ ਮਨਜ਼ੂਰ ਕੀਤੀਆਂ ਕਤਾਰਾਂ ਦਿਖਾਈਆਂ ਜਾਵਣਗੀਆਂ." ਇਸ ਦਾ ਮਤਲਬ ਇਹ ਹੈ ਕਿ ਪੂਰਾ ਡੇਟਾ ਡਾਊਨਲੋਡ ਹੋਇਆ। ਕੋਈ ਵੀ ਨੈਟਵਰਕ ਜਵਾਬ ਇੰਸਪੈਕਟ ਕਰ ਸਕਦਾ ਹੈ, ਡਿਵ ਟੂਲ ਖੋਲ ਕੇ ਜਾਂ ਪੇਲੋਡ ਸੇਵ ਕਰਕੇ। UI ਵਿੱਚ ਕਾਲਮ ਲੁਕਾਉਣਾ ਐਕਸੈਸ ਕੰਟਰੋਲ ਨਹੀਂ ਹੈ।
ਜਦੋਂ ਅਧਿਕਾਰ ਯੂਜ਼ਰ ਦੁਆਰਾ ਵੱਖਰੇ-ਵੱਖਰੇ ਹੋ ਸਕਦੇ ਹਨ, ਖਾਸ ਕਰਕੇ ਜਦੋਂ ਵੱਖ-ਵੱਖ ਯੂਜ਼ਰ ਵੱਖ-ਵੱਖ ਕਤਾਰਾਂ ਜਾਂ ਫੀਲਡਾਂ ਵੇਖ ਸਕਦੇ ਹਨ, ਤਦ ਸਰਵਰ-ਪਾਸੇ ਫਿਲਟਰਿੰਗ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ।
ਝਟਪਟ ਜਾਂਚ:
ਜੇ ਕਿਸੇ ਵੀ ਸਵਾਲ ਦਾ ਉੱਤਰ ਹਾਂ ਹੈ, ਤਾਂ ਫਿਲਟਰ ਅਤੇ ਫੀਲਡ ਚੋਣ ਸਰਵਰ-ਪਾਸੇ ਰੱਖੋ। ਜੋ ਕੁਝ ਯੂਜ਼ਰ ਦੇਖ ਸਕਦੇ ਹਨ ਉਹੀ ਭੇਜੋ, ਅਤੇ ਖੋਜ, ਸੋਰਟ, ਪੇਜਿਨੇਸ਼ਨ ਅਤੇ ਨਿਰਯਾਤ 'ਤੇ ਉਹੀ ਨਿਯਮ ਲਾਗੂ ਕਰੋ।
ਉਦਾਹਰਨ: ਇੱਕ CRM ਸੰਪਰਕ ਲਿਸਟ ਵਿੱਚ, ਰੈਪ्स ਆਪਣੀਆਂ ਖਾਤਿਆਂ ਨੂੰ ਦੇਖ ਸਕਦੇ ਹਨ ਜਦਕਿ ਮੈਨੇਜਰ ਸਾਰੀ ਟੀਮ ਦੇਖ ਸਕਦੇ ਹਨ। ਜੇ ਬ੍ਰਾਉਜ਼ਰ ਸਾਰੇ ਸੰਪਰਕ ਡਾਊਨਲੋਡ ਕਰਦਾ ਹੈ ਅਤੇ ਲੋਕਲ ਤੌਰ 'ਤੇ ਫਿਲਟਰ ਕਰਦਾ ਹੈ, ਤਾਂ ਇੱਕ ਰੈਪ ਛੁਪੇ ਹੋਏ ਖਾਤਿਆਂ ਨੂੰ ਜਵਾਬ ਤੋਂ ਬਾਹਰ ਵੀ ਕੱਢ ਸਕਦਾ ਹੈ। ਸਰਵਰ-ਪਾਸੇ ਫਿਲਟਰਿੰਗ ਇਹ ਰੋਕਦੀ ਹੈ ਕਿਉਂਕਿ ਉਹ ਉਹ ਰਿਕਾਰਡ ਕਦੇ ਹੀ ਨਹੀਂ ਭੇਜਦਾ।
ਕੈਸ਼ਿੰਗ ਇੱਕ ਸਕ੍ਰੀਨ ਨੂੰ ਤੁਰੰਤ ਮਹਿਸੂਸ ਕਰਵਾ ਸਕਦੀ ਹੈ। ਇਹ ਗਲਤ ਸੱਚ ਵੀ ਦਿਖਾ ਸਕਦੀ ਹੈ। ਮੁੱਖ ਗੱਲ ਇਹ ਹੈ ਕਿ ਤੁਸੀਂ ਕੀ ਮੁੜ ਵਰਤ ਸਕਦੇ ਹੋ, ਕਿੰਨੀ ਦੇਰ ਲਈ, ਅਤੇ ਕਿਹੜੇ ਘਟਨਾਵਾਂ ਇਸਨੂੰ ਰੀਫ੍ਰੈਸ਼ ਕਰਨ ਲਈ ਮਜਬੂਰ ਕਰਨਗੇ।
ਕੈਸ਼ ਯੂਨਿਟ ਚੁਣ ਕੇ ਸ਼ੁਰੂ ਕਰੋ। ਪੂਰੀ ਲਿਸਟ ਕੈਸ਼ ਕਰਨਾ ਸਾਦਾ ਹੈ ਪਰ ਆਮ ਤੌਰ 'ਤੇ ਫ਼ਜ਼ੂਲ ਬੈਂਡਵਿਡਥ ਖਰਚ ਕਰਦਾ ਹੈ ਅਤੇ ਜਲਦੀ ਸਟੇਲ ਹੋ ਜਾਂਦਾ ਹੈ। ਅਨੰਤ ਸਕ੍ਰੋਲ ਲਈ ਪੇਜ ਕੈਸ਼ ਕਰਨਾ ਚੰਗਾ ਕੰਮ ਕਰਦਾ ਹੈ। ਕਵੈਰੀ ਨਤੀਜੇ (ਫਿਲਟਰ + ਸੋਰਟ + ਖੋਜ) ਕੈਸ਼ ਕਰਨਾ ਸਹੀ ਹੋ ਸਕਦਾ ਹੈ, ਪਰ ਜੇ ਯੂਜ਼ਰ ਬਹੁਤ ਸਾਰੇ ਕੰਬੀਨੇਸ਼ਨ ਟ੍ਰਾਈ ਕਰਨਗੇ ਤਾਂ ਇਹ ਤੇਜ਼ੀ ਨਾਲ ਵੱਧ ਸਕਦਾ ਹੈ।
ਤਾਜਗੀ ਕੁਝ ਡੋਮੇਨਾਂ ਵਿੱਚ ਹੋਰ ਮਹੱਤਵਪੂਰਨ ਹੁੰਦੀ ਹੈ। ਜੇ ਡੇਟਾ ਤੇਜ਼ੀ ਨਾਲ ਬਦਲਦਾ ਹੈ (ਸਟੌਕ ਲੈਵਲ, ਬੈਲੰਸ, ਡਿਲਿਵਰੀ ਸਟੇਟਸ), ਤਾਂ ਇੱਥੇ 30 ਸਕਿੰਟ ਦਾ ਕੈਸ਼ ਵੀ ਯੂਜ਼ਰ ਨੂੰ ਗੁੰਝਲਦਾਰ ਕਰ ਸਕਦਾ ਹੈ। ਜੇ ਡੇਟਾ ਸਲੋ-ਚੇਂਜਿੰਗ ਹੈ (ਆਰਕਾਈਵ ਰਿਕਾਰਡ, ਰੈਫਰੈਂਸ ਡਾਟਾ), ਲੰਬਾ ਕੈਸ਼ ਠੀਕ ਰਹੇਗਾ।
ਕੋਡ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ ਇਨਵੈਲਿਡੇਸ਼ਨ ਦੀ ਯੋਜਨਾ ਬਣਾਓ। ਸਮਾਂ ਬੀਤਣ ਤੋਂ ਇਲਾਵਾ, ਇਹ ਫੈਸਲਾ ਕਰੋ ਕਿ ਕਿਹੜੀਆਂ ਘਟਨਾਵਾਂ ਰੀਫ੍ਰੈਸ਼ ਜ਼ਰੂਰੀ ਬਣਾਉਂਦੀਆਂ ਹਨ: ਬਣਾਉਣਾ/ਸੰਪਾਦਨ/ਮਿਟਾਉਣਾ, ਅਧਿਕਾਰ ਬਦਲਾਅ, ਬਲਕ ਇੰਪੋਰਟ ਜਾਂ ਮਰਜ, ਸਥਿਤੀ ਬਦਲਾਅ, ਅਨਡੂ/ਰੋਲਬੈਕ, ਅਤੇ ਪਿੱਛੇ ਚੱਲ ਰਹੇ ਜੌਬ ਜੋ ਫੀਲਡਾਂ ਨੂੰ ਅੱਪਡੇਟ ਕਰਦੇ ਹਨ।
ਇਹ ਵੀ ਫੈਸਲਾ ਕਰੋ ਕਿ ਕੈਸ਼ ਕਿੱਥੇ ਰਹੇਗਾ। ਬ੍ਰਾਉਜ਼ਰ ਮੇਮੋਰੀ ਬੈਕ/ਫਾਰਵਰ ਨੇਵੀਗੇਸ਼ਨ ਨੂੰ ਤੇਜ਼ ਬਣਾਉਂਦੀ ਹੈ, ਪਰ ਜੇ ਤੁਸੀਂ ਇਹ ਯੂਜ਼ਰ ਅਤੇ ਆਰਗ ਦੁਆਰਾ ਕੀ ਹੀ ਕੀ-ਕਿਵੇਂ ਨਹੀਂ ਕਰਦੇ ਤਾਂ ਇਹ ਖਾਤਿਆਂ ਵਿਚ ਡੇਟਾ ਲੀਕ ਕਰ ਸਕਦੀ ਹੈ। ਬੈਕਐਂਡ ਕੈਸ਼ਿੰਗ ਅਧਿਕਾਰਾਂ ਅਤੇ ਸਥਿਰਤਾ ਲਈ ਸੁਰੱਖਿਅਤ ਹੈ, ਪਰ ਇਹ ਪੂਰੇ ਫਿਲਟਰ ਸਿਗਨੇਚਰ ਅਤੇ ਕਾਲਰ ਪਛਾਣ ਸ਼ਾਮਲ ਕਰਨੀ ਚਾਹੀਦੀ ਹੈ ਤਾਂ ਜੋ ਨਤੀਜੇ ਮਿਲ ਨਾ ਜਾਣ۔
ਲਕੜੀ ਦੇ ਸਾਰੇ ਨਿਰਣਾ ਅਟੱਲ ਹਨ: ਸਕ੍ਰੀਨ ਤੇਜ਼ ਮਹਿਸੂਸ ਹੋਵੇ ਬਿਨਾਂ ਡਾਟਾ ਲੀਕ ਦੇ।
ਅਕਸਰ ਟੀਮਾਂ ਇੱਕੋ ਜਿਹੇ ਪੈਟਰਨਾਂ ਨਾਲ ਡਾਂਟੀਆਂ ਜਾਂਦੀਆਂ ਹਨ: ਇੱਕ UI ਜੋ ਡੈਮੋ ਵਿੱਚ ਵਧੀਆ ਲੱਗਦੀ ਹੈ, ਪਰ ਅਸਲ ਡੇਟਾ, ਅਸਲ ਅਧਿਕਾਰ, ਅਤੇ ਅਸਲ ਨੈਟਵਰਕ ਸਪੀਡ ਨੇ ਉਹਦੇ ਦਰਾਰਾਂ ਨੂੰ ਖੋਲ੍ਹ ਦਿੱਤਾ।
ਸਭ ਤੋਂ ਭਾਰੀ ਨਾਕਾਮੀ ਫਿਲਟਰਿੰਗ ਨੂੰ ਪ੍ਰਸਤੁਤੀ ਸਮਝਣਾ ਹੈ। ਜੇ ਬ੍ਰਾਉਜ਼ਰ ਨੂੰ ਉਹ ਰਿਕਾਰਡ ਮਿਲ ਰਹੇ ਹਨ ਜੋ ਉਹ ਨਹੀਂ ਦੇਖ ਸਕਦੇ, ਤਾਂ ਤੁਸੀਂ ਪਹਿਲਾਂ ਹੀ ਹਾਰ ਗਏ।
ਦੋ ਆਮ ਕਾਰਨ:
ਉਦਾਹਰਨ: ਇੰਟਰਨਸਾਂ ਨੂੰ ਸਿਰਫ਼ ਆਪਣੇ ਖੇਤਰ ਦੇ ਲੀਡ ਵੇਖਣੇ ਚਾਹੀਦੇ ਹਨ। ਜੇ API ਸਾਰੇ ਖੇਤਰ ਵਾਪਸ ਕਰਦਾ ਹੈ ਅਤੇ ਡ੍ਰੌਪਡਾਊਨ React ਵਿੱਚ ਲੋਡ ਹੋ ਕੇ ਫਿਲਟਰ ਕਰਦਾ ਹੈ, ਤਾਂ ਇੰਟਰਨ ਪੂਰਾ ਲਿਸਟ ਕੱਢ ਸਕਦਾ ਹੈ।
ਲੈਗ ਅਕਸਰ ਅਨੁਮਾਨਾਂ ਤੋਂ ਆਉਂਦਾ ਹੈ:
ਇੱਕ ਨਜ਼ਰਅੰਦਾਜ਼ ਪਰ ਦਰਦਨਾਕ ਸਮੱਸਿਆ ਮਿਸਮੇਚਡ ਨਿਯਮ ਹੈ। ਜੇ ਸਰਵਰ 'ਤੇ "starts with" ਨੂੰ ਵੱਖ ਤਰੀਕੇ ਨਾਲ ਟ੍ਰੀਟ ਕਰਦਾ ਹੈ ਇਹ UI ਕਰਕੇ, ਤਾਂ ਯੂਜ਼ਰ ਗਿਣਤੀਆਂ ਦੇਖਦੇ ਹਨ ਜੋ ਮੇਲ ਨਹੀਂ ਖਾਂਦੀਆਂ, ਜਾਂ ਨਤੀਜੇ ਰਿਫ੍ਰੈਸ਼ 'ਤੇ ਗਾਇਬ ਹੋ ਜਾਂਦੇ ਹਨ।
ਇੱਕ ਜਿਗਿਆਸੂ ਯੂਜ਼ਰ ਅਤੇ ਇੱਕ ਖਰਾਬ ਨੈਟਵਰਕ ਦਿਨ ਦੇ ਦੋ ਮਨੋਭਾਵਾਂ ਨਾਲ ਅਖੀਰਲਾ ਪਾਸਾ ਕਰੋ।
ਇਕ ਸਧਾਰਨ ਟੈਸਟ: ਇੱਕ ਸੀਮਤ ਰਿਕਾਰਡ ਬਣਾਓ ਅਤੇ ਯਕੀਨ ਕਰੋ ਕਿ ਇਹ ਕਦੇ ਵੀ ਪੇਲੋਡ, ਗਿਣਤੀ, ਜਾਂ ਕੈਸ਼ ਵਿੱਚ ਨਹੀਂ ਆਉਂਦਾ, ਭਾਵੇਂ ਤੁਸੀਂ ਵਿਸਤਾਰ ਨਾਲ ਫਿਲਟਰ ਕਰੋ ਜਾਂ ਫਿਲਟਰ ਸਾਫ਼ ਕਰ ਦਿਉ।
ਸੋਚੋ ਇੱਕ CRM ਜਿਸ ਵਿੱਚ 200,000 ਸੰਪਰਕ ਹਨ। ਸੇਲਜ਼ ਰੈਪਸ ਸਿਰਫ਼ ਆਪਣੇ ਖਾਤਿਆਂ ਨੂੰ ਵੇਖ ਸਕਦੇ ਹਨ, ਮੈਨੇਜਰ ਆਪਣੀ ਟੀਮ ਦੇਖ ਸਕਦੇ ਹਨ, ਅਤੇ ਐਡਮਿਨ ਸਭ ਨੂੰ ਵੇਖ ਸਕਦੇ ਹਨ। ਸਕ੍ਰੀਨ 'ਤੇ ਖੋਜ, ਫਿਲਟਰ (ਸਥਿਤੀ, ਮਾਲਕ, ਆਖਰੀ ਸਰਗਰਮੀ) ਅਤੇ ਸੋਰਟਿੰਗ ਹੈ।
ਇੱਥੇ ਕਲਾਇੰਟ-ਪਾਸੇ ਫਿਲਟਰਿੰਗ ਜਲਦੀ ਫੇਲ ਹੋ ਜਾਂਦੀ ਹੈ। ਪੇਲੋਡ ਭਾਰੀ ਹੈ, ਪਹਿਲੀ ਲੋਡ ਧੀਮੀ ਹੋ ਜਾਂਦੀ ਹੈ, ਅਤੇ ਡਾਟਾ ਲੀਕ ਦਾ ਖਤਰਾ ਉੱਚਾ ਹੈ। ਭਾਵੇਂ UI ਕਤਾਰਾਂ ਨੂੰ ਛੁਪਾਓ, ਬ੍ਰਾਉਜ਼ਰ ਹਾਲੇ ਵੀ ਡੇਟਾ ਪ੍ਰਾਪਤ ਕਰ ਚੁੱਕਾ ਹੋਵੇਗਾ। ਤੁਸੀਂ ਡਿਵਾਈਸ 'ਤੇ ਦਬਾਅ ਪਾਉਂਦੇ ਹੋ: ਵੱਡੀਆਂ ਐਰੇਜ਼, ਭਾਰੀ ਸੋਰਟਿੰਗ, ਬਾਰ-ਬਾਰ ਫਿਲਟਰ ਚਲਾਉਣਾ, ਬੁਜ਼ੁਰਗ ਫੋਨਾਂ 'ਤੇ ਮੈਮੋਰੀ ਇਸਤਮਾਲ ਅਤੇ ਕ੍ਰੈਸ਼।
ਇੱਕ ਸੁਰੱਖਿਅਤ ਦ੍ਰਿਸ਼ਟੀਕੋਣ ਸਰਵਰ-ਪਾਸੇ ਫਿਲਟਰਿੰਗ ਨਾਲ ਪੇਜਿਨੇਸ਼ਨ ਹੈ। ਕਲਾਇੰਟ ਫਿਲਟਰ ਚੋਣਾਂ ਅਤੇ ਖੋਜ ਟੈੱਕਸਟ ਭੇਜਦਾ ਹੈ, ਅਤੇ ਸਰਵਰ ਸਿਰਫ਼ ਉਹੀ ਰਿਕਾਰਡ ਜੋ ਯੂਜ਼ਰ ਨੂੰ ਦੇਖਣ ਦੀ ਆਗਿਆ ਹੈ ਭੇਜਦਾ ਹੈ, ਪਹਿਲਾਂ ਹੀ ਫਿਲਟਰ ਅਤੇ ਸੋਰਟ ਕੀਤੇ ਹੋਏ।
ਇੱਕ ਪ੍ਰਯੋਗਿਕ ਪੈਟਰਨ:
ਇੱਕ ਛੋਟਾ ਛੁਟਕਾਰਾ ਜਿੱਥੇ ਕਲਾਇੰਟ-ਪਾਸੇ ਫਿਲਟਰਿੰਗ ਠੀਕ ਹੈ: ਨਿੱਕੀ, ਸਥਿਰ ਡੇਟਾ। "Contact status" ਲਈ ਡ੍ਰੌਪਡਾਊਨ ਜਿਸ ਵਿੱਚ 8 ਮੁੱਲ ਹਨ, ਇੱਕ ਵਾਰੀ ਲੋਡ ਕਰਕੇ ਲੋਕਲ ਤੌਰ 'ਤੇ ਫਿਲਟਰ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ ਬਿਨਾਂ ਜ਼ਿਆਦਾ ਖ਼ਤਰੇ ਜਾਂ ਲਾਗਤ ਦੇ।
ਟੀਮਾਂ ਆਮ ਤੌਰ 'ਤੇ ਇੱਕ ਵਾਰੀ ਗਲਤ ਚੋਣ ਕਰਨ ਨਾਲ ਜ਼ਿਆਦਾ ਨਹੀਂ ਜ਼ਖਮੀ ਹੁੰਦੀਆਂ। ਉਹ ਨੇਹਾਂ ਇੱਥੇ ਜ਼ਖਮੀ ਹੁੰਦੀਆਂ ਹਨ ਜਦੋਂ ਹਰ ਸਕ੍ਰੀਨ 'ਤੇ ਵੱਖਰਾ ਫੈਸਲਾ ਕੀਤਾ ਜਾਂਦਾ ਹੈ, ਫਿਰ ਅੰਤ 'ਤੇ ਲੀਕ ਅਤੇ ਧੀਮੇ ਪੇਜ਼ ਠੀਕ ਕਰਨ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰਦੇ ਹਨ।
ਹਰ ਸਕ੍ਰੀਨ ਲਈ ਇੱਕ ਛੋਟਾ ਫੈਸਲਾ ਨੋਟ ਲਿਖੋ: ਫਿਲਟਰ, ਡੇਟਾਸੈਟ ਆਕਾਰ, ਬ੍ਰਾਉਜ਼ਰ 'ਤੇ ਭੇਜਣ ਦੀ ਲਾਗਤ, "ਤੇਜ਼ ਕਿੰਨਾ ਤੇਜ਼" ਮਹਿਸੂਸ ਹੁੰਦਾ ਹੈ, ਕਿਹੜੇ ਫੀਲਡ ਸੰਵੇਦਨਸ਼ੀਲ ਹਨ, ਅਤੇ ਨਤੀਜੇ ਕਿਵੇਂ ਕੈਸ਼ ਹੋਣ (ਯਾ ਨਹੀਂ)। ਸਰਵਰ ਅਤੇ UI ਨੂੰ ਲਾਈਨ ਤੇ ਰੱਖੋ ਤਾਂ ਕਿ ਤੁਸੀਂ ਦੋ ਵੱਖਰੀਆਂ ਸਚਾਈਆਂ ਵਾਲੀ ਫਿਲਟਰਿੰਗ ਨਾਲ ਨਾ ਰਹਿ ਜਾਓ।
ਜੇ ਤੁਸੀਂ Koder.ai (koder.ai) ਵਿੱਚ ਤੇਜ਼ੀ ਨਾਲ ਸਕ੍ਰੀਨ ਬਣਾ ਰਹੇ ਹੋ, ਤਾਂ ਅੱਗੇ ਐਨ ਸਮਝੋ ਕਿ ਕਿਹੜੇ ਫਿਲਟਰ ਬੈਕਐਂਡ 'ਤੇ ਲਾਜ਼ਮੀ ਤੌਰ 'ਤੇ ਲਾਗੂ ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ (ਅਧਿਕਾਰ ਅਤੇ ਰੋ-ਲੈਵਲ ਐਕਸੈਸ) ਅਤੇ ਕਿਹੜੇ ਛੋਟੇ UI-ਕੇਵਲ ਟੌਗਲ React ਲੇਅਰ ਵਿੱਚ ਰਹਿ ਸਕਦੇ ਹਨ। ਇਹ ਇੱਕ ਚੋਣ ਆਮ ਤੌਰ 'ਤੇ ਸਭ ਤੋਂ ਮਹਿੰਗੀ ਰੀ-ਰਾਇਟਜ਼ ਰੋਕਦੀ ਹੈ।
ਜਦੋਂ ਯੂਜ਼ਰਾਂ ਦੇ ਅਧਿਕਾਰ ਵੱਖ-ਵੱਖ ਹੋਣ, ਡੇਟਾਸੈਟ ਵੱਡਾ ਹੋਵੇ, ਜਾਂ ਤੁਸੀਂ ਪੇਜਿਨੇਸ਼ਨ ਅਤੇ ਟੋਟਲਸ ਦੀ ਸਥਿਰਤਾ ਚਾਹੁੰਦੇ ਹੋ ਤਾਂ ਮੂਲ ਰੂਪ ਵਿੱਚ ਸਰਵਰ-ਪਾਸੇ ਫਿਲਟਰਿੰਗ ਕਰੋ। ਸਿਰਫ਼ ਉਹੀ ਸਮਾਂ ਕਲਾਇੰਟ-ਪਾਸੇ ਵਰਤੋ ਜਦੋਂ ਪੂਰਾ ਡੇਟਾਸੈਟ ਛੋਟਾ, ਸੁਰੱਖਿਅਤ ਅਤੇ ਤੇਜ਼ੀ ਨਾਲ ਡਾਊਨਲੋਡ ਹੋ ਸਕੇ।
ਕਿਉਂਕਿ ਬ੍ਰਾਉਜ਼ਰ ਨੂੰ ਜੋ ਕੁਝ ਵੀ ਮਿਲਦਾ ਹੈ ਉਹ ਇੰਸਪੈਕਟ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ। ਭਾਵੇਂ UI ਵਿੱਚ ਕਤਾਰਾਂ ਜਾਂ ਕਾਲਮ ਲੁਕਾਏ ਗਏ ਹੋਣ, ਯੂਜ਼ਰ ਨੈਟਵਰਕ ਜਵਾਬ, ਕੈਸ਼ਡ ਪੇਲੋਡ ਜਾਂ ਮੈਮੋਰੀ ਵਿੱਚ ਉਪਲਬਧ ਆਬਜੈਕਟ ਦੇਖ ਸਕਦਾ ਹੈ।
ਅਕਸਰ ਇਹ ਤਦ੍ਹਾ ਮਹਿਸੂਸ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਬਹੁਤ ਸਾਰਾ ਡਾਟਾ ਭੇਜਦੇ ਹੋ ਅਤੇ ਫਿਰ ਹਰ ਕੀਸਟਰੋਕ 'ਤੇ ਵੱਡੀਆਂ ਐਰੇਜ਼ ਤੇ ਫਿਲਟਰ/ਸੋਰਟ ਚਲਾਉਂਦੇ ਹੋ, ਜਾਂ ਜਦੋਂ ਹਰ ਕੀਸਟਰੋਕ 'ਤੇ ਸਰਵਰ ਰਿਕਵੇਸਟ ਭੇਜੀ ਜਾਵੇ ਬਿਨਾਂ ਡੀਬਾਊਂਸ ਦੇ। ਪੇਲੋਡ ਛੋਟੇ ਰੱਖੋ ਅਤੇ ਹਰ ਇਨਪੁੱਟ ਚੇਂਜ 'ਤੇ ਭਾਰੀ ਕੰਮ ਤੋਂ ਬਚੋ।
ਇੱਕ ਸੱਚਾ ਸਰੋਤ ਰੱਖੋ: ਅਧਿਕਾਰ, ਖੋਜ, ਸੋਰਟਿੰਗ ਅਤੇ ਪੇਜਿਨੇਸ਼ਨ ਨੂੰ ਇਕੱਠੇ ਸਰਵਰ 'ਤੇ ਲਾਗੂ ਕਰੋ। ਫਿਰ ਕਲਾਇੰਟ-ਸਾਈਡ ਲਾਜ਼ਮੀ ਤੌਰ 'ਤੇ ਛੋਟੇ UI-ਟੋਗਲ ਤੱਕ ਸੀਮਿਤ ਰੱਖੋ ਜੋ ਅਧਾਰਭੂਤ ਡੇਟਾਸੈਟ ਨੂੰ ਨਹੀਂ ਬਦਲਦੇ।
ਕਲਾਇੰਟ-ਪਾਸੇ ਕੈਸ਼ਿੰਗ ਸਟੇਲ ਜਾਂ ਗਲਤ ਡੇਟਾ ਦਿਖਾ ਸਕਦੀ ਹੈ ਅਤੇ ਜੇ ਨੀਤੀ ਵਿੱਚ ਕੀ ਹੋਇਆ ਹੈ ਤਾਂ ਖਾਤਿਆਂ ਵਿਚ ਲੀਕ ਕਰ ਸਕਦੀ ਹੈ। ਸਰਵਰ-ਸਾਈਡ ਕੈਸ਼ਿੰਗ ਅਧਿਕਾਰਾਂ ਲਈ ਜ਼ਿਆਦਾ ਸੁਰੱਖਿਅਤ ਹੈ, ਪਰ ਇਹ ਪੂਰੇ ਫਿਲਟਰ ਸਿਗਨੇਚਰ ਅਤੇ ਕਾਲਰ ਦੀ ਪਹਚਾਨ ਸਮੇਤ ਕੀ ਹੋਈ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ ਤਾਂ ਜੋ ਨਤੀਜੇ ਮਿਲ ਨਾ ਜਾਣ।
ਦੋ ਸਵਾਲ ਪੁੱਛੋ: ਯੂਜ਼ਰ ਵਾਸਤਵਿਕਤਾਪੂਰਕ ਕਿੰਨੀ ਕਤਾਰਾਂ ਰੱਖ ਸਕਦਾ ਹੈ, ਅਤੇ ਪ੍ਰਤੀ ਕਤਾਰ ਬਾਈਟ ਵਿੱਚ ਕਿੰਨਾ ਵਜ਼ਨ ਹੈ। ਜੇ ਤੁਸੀਂ ਆਮ ਮੋਬਾਈਲ ਕਨੈਕਸ਼ਨ 'ਤੇ ਆਰਾਮ ਨਾਲ ਲੋਡ ਨਹੀਂ ਕਰ ਸਕਦੇ, ਤਾਂ ਫਿਲਟਰਿੰਗ ਨੂੰ ਸਰਵਰ 'ਤੇ ਧੱਕੋ ਅਤੇ ਪੇਜਿਨੇਟ ਕਰੋ।
ਸਰਵਰ-ਪਾਸੇ. ਜੇ ਭੂਮਿਕਾ, ਟੀਮ, ਖੇਤਰ ਜਾਂ ਮਲਕੀਅਤ ਨਿਯਮ ਇਹ ਤਾਇਨ ਕਰਦੇ ਹਨ ਕਿ ਕਿਸਨੂੰ ਕਿਹੜੀਆਂ ਕਤਾਰਾਂ ਜਾਂ ਫੀਲਡਾਂ ਵੇਖਣ ਦੀ ਆਗਿਆ ਹੈ, ਤਾਂ ਸਰਵਰ ਨੂੰ ਕਤਾਰ ਅਤੇ ਫੀਲਡ ਪਹੁੰਚ ਲਾਗੂ ਕਰਨੀ ਚਾਹੀਦੀ ਹੈ। ਕਲਾਇੰਟ ਨੂੰ ਸਿਰਫ਼ ਉਹੀ ਡੇਟਾ ਭੇਜੋ ਜੋ ਯੂਜ਼ਰ ਦੇਖ ਸਕਦਾ ਹੈ।
ਪਹਿਲਾਂ ਫਿਲਟਰ ਅਤੇ ਸੋਰਟ ਕੰਟਰੈਕਟ ਨੂੰ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ: ਕਿਹੜੇ ਫਿਲਟਰ ਿਖ਼ਾਂ ਮਨਜ਼ੂਰ ਹਨ, ਡਿਫੌਲਟ ਸੋਰਟਿੰਗ, ਪੇਜਿਨੇਸ਼ਨ ਨਿਯਮ ਅਤੇ ਖੋਜ ਕਿਵੇਂ ਮਿਲਦੀ ਹੈ (ਕੇਸ, ਅੱਖਰ ਚਿੰਨ੍ਹ). ਫਿਰ ਇੱਕੋ ਲਾਜਿਕ ਬੈਕਐਂਡ 'ਤੇ ਲਾਗੂ ਕਰੋ ਅਤੇ ਟੈਸਟ ਕਰੋ ਕਿ ਟੋਟਲ ਅਤੇ ਪੇਜ ਮੇਲ ਖਾਂਦੇ ਹਨ।
ਟਾਈਪਿੰਗ ਲਈ ਡੀਬਾਊਂਸ ਕਰੋ ਤਾਂ ਜੋ ਹਰ ਕੀਸਟਰੋਕ 'ਤੇ ਰਿਕਵੇਸਟ ਨਾ ਜਾਵੇ, ਅਤੇ ਨਵੇਂ ਨਤੀਜੇ ਆਉਣ ਤੱਕ ਪੁਰਾਣੇ ਨਤੀਜੇ ਦਿਖਾਓ ਤਾਂ ਕਿ ਫਲਿਕਰ ਘਟੇ। ਪੇਜਿਨੇਸ਼ਨ ਜਾਂ ਪ੍ਰੋਗਰੇਸਿਵ ਲੋਡਿੰਗ ਵਰਤੋਂ ਤਾਂ ਜੋ ਯੂਜ਼ਰ ਨੂੰ ਚੀਜ਼ਾਂ ਤੁਰੰਤ ਦਿੱਸਣ ਲੱਗਣ।
ਪਹਿਲਾਂ ਅਧਿਕਾਰ ਲਗਾਓ, ਫਿਰ ਫਿਲਟਰ ਅਤੇ ਸੋਰਟ. ਇਕ ਪੇਜ ਹੀ ਵਾਪਸ ਭੇਜੋ (ਉਦਾਹਰਨ ਵਜੋਂ 50 ਕਤਾਰਾਂ) ਅਤੇ ਇੱਕ ਟੋਟਲ ਗਿਣਤੀ. "ਜ਼ਰੂਰਤ ਪੈਣ 'ਤੇ ਵਾਧੂ ਫੀਲਡ" ਨਾ ਭੇਜੋ ਅਤੇ ਕੈਸ਼ ਕੀ ਵਿਚ ਯੂਜ਼ਰ/ਆਰਗ/ਭੂਮਿਕਾ ਸ਼ਾਮਲ ਹੋਣ ਦੀ ਯਕੀਨੀ ਬਣਾਓ ਤਾਂ ਕਿ ਰੈਪ ਖਾਤੇ ਲਈ ਮੈਨੇਜਰ ਲਈ ਮੰਤੂਕ ਡਾਟਾ ਕਦੇ ਨਾ ਮਿਲੇ।