17 ਦਸੰ 2025·8 ਮਿੰਟ
PostgreSQL ਕਨੈਕਸ਼ਨ ਪੁਲਿੰਗ: app ਪੂਲਿੰਗ vs PgBouncer
PostgreSQL ਕਨੈਕਸ਼ਨ ਪੁਲਿੰਗ: Go ਬੈਕਐਂਡ ਲਈ app ਪੂਲ ਅਤੇ PgBouncer ਦੀ ਤੁਲਨਾ, ਮਾਪਣ ਯੋਗ ਮੈਟ੍ਰਿਕਸ, ਅਤੇ ਗਲਤ ਕਨਫ਼ਿਗਰੇਸ਼ਨ ਜੋ ਲੈਟੈਂਸੀ ਸਪਾਈਕ ਪੈਦਾ ਕਰਦੇ ਹਨ।
PostgreSQL ਕਨੈਕਸ਼ਨ ਪੁਲਿੰਗ: Go ਬੈਕਐਂਡ ਲਈ app ਪੂਲ ਅਤੇ PgBouncer ਦੀ ਤੁਲਨਾ, ਮਾਪਣ ਯੋਗ ਮੈਟ੍ਰਿਕਸ, ਅਤੇ ਗਲਤ ਕਨਫ਼ਿਗਰੇਸ਼ਨ ਜੋ ਲੈਟੈਂਸੀ ਸਪਾਈਕ ਪੈਦਾ ਕਰਦੇ ਹਨ।
ਡੇਟਾਬੇਜ਼ ਕਨੈਕਸ਼ਨ ਤੁਹਾਡੇ ਐਪ ਅਤੇ Postgres ਦਰਮਿਆਨ ਇੱਕ ਫ਼ੋਨ ਲਾਈਨ ਵਾਂਗ ਹੈ। ਇੱਕ ਨਵਾਂ ਕਨੈਕਸ਼ਨ ਖੋਲ੍ਹਣ ਵਿੱਚ ਦੋਹਾਂ ਪਾਸਿਆਂ 'ਤੇ ਸਮਾਂ ਤੇ ਕੰਮ ਲੱਗਦਾ ਹੈ: TCP/TLS ਸੈਟਅੱਪ, ਪ੍ਰਮਾਣਿਕਤਾ, ਮੈਮੋਰੀ, ਅਤੇ Postgres ਪੱਖ ਤੇ ਇੱਕ ਬੈਕਐਂਡ ਪ੍ਰਕਿਰਿਆ। ਇੱਕ ਪੂਲ ਇਹਨਾਂ "ਫ਼ੋਨ ਲਾਈਨਾਂ" ਦਾ ਛੋਟਾ ਸੈੱਟ ਖੁਲਾ ਰੱਖਦਾ ਹੈ ਤਾਂ ਜੋ ਤੁਹਾਡੀ ਐਪ ਹਰ ਰਿਕਵੈਸਟ ਲਈ ਵਾਰ-ਵਾਰ ਨਵਾਂ ਨੰਬਰ ਨਾ ਡਾਇਲ ਕਰੇ।
ਜਦੋਂ ਪੂਲਿੰਗ ਬੰਦ ਹੁੰਦੀ ਹੈ ਜਾਂ ਗਲਤ ਤਰ੍ਹਾਂ ਸਾਈਜ਼ ਕੀਤੀ ਜਾਂਦੀ ਹੈ, ਤੁਹਾਨੂੰ ਆਮ ਤੌਰ 'ਤੇ ਐਰਰ ਪਹਿਲਾਂ ਨਹੀਂ ਮਿਲਦਾ। ਤੁਹਾਨੂੰ ਬੇ-ਤਰਤੀਬੀ ਧੀਮੀ ਚੀਜ਼ਾਂ ਮਿਲਦੀਆਂ ਹਨ। ਜੋ ਰਿਕਵੈਸਟ ਆਮ ਤੌਰ 'ਤੇ 20-50 ms ਲੈਂਦੇ ਹਨ ਉਹ ਅਚਾਨਕ 500 ms ਜਾਂ 5 ਸਕਿੰਟ ਲੈ ਸਕਦੇ ਹਨ, ਤੇ p95 ਉੱਪਰ ਚਲ ਜਾਂਦਾ ਹੈ। ਫਿਰ ਟਾਈਮਆਉਟ ਆਉਂਦੇ ਹਨ, ਬਾਅਦ ਵਿੱਚ “too many connections” ਆ ਸਕਦਾ ਹੈ, ਜਾਂ ਤੁਹਾਡੀ ਐਪ ਦੇ اندر ਹੀ ਕਤਾਰ ਬਣ ਜਾਂਦੀ ਹੈ ਜਦੋਂ ਉਹ ਖਾਲੀ ਕਨੈਕਸ਼ਨ ਦੇ ਇੰਤਜ਼ਾਰ ਵਿੱਚ ਹੁੰਦੀ ਹੈ।
ਕਨੈਕਸ਼ਨ ਸੀਮਾਵਾਂ ਨੰਨ੍ਹੇ ਐਪਸ ਲਈ ਵੀ ਮਹੱਤਵਪੂਰਣ ਹਨ ਕਿਉਂਕਿ ਟਰੈਫਿਕ ਆਮ ਤੌਰ 'ਤੇ ਬਰਸਟ ਵਿੱਚ ਹੁੰਦੀ ਹੈ। ਇੱਕ ਮਾਰਕੇਟਿੰਗਈਮੇਲ, ਇੱਕ cron job, ਜਾਂ ਕੁਝ ਧੀਮੇ endpoints ਕਈ ਦਰਖ਼ਤੀਆਂ ਰਿਕਵੈਸਟਾਂ ਨੂੰ ਇਕੱਠਾ ਕਰ ਸਕਦੇ ਹਨ। ਜੇ ਹਰ ਰਿਕਵੈਸਟ ਨਵਾਂ ਕਨੈਕਸ਼ਨ ਖੋਲ੍ਹਦਾ ਹੈ, ਤਾਂ Postgres ਆਪਣੀ ਸਮਰੱਥਾ ਦਾ ਕਾਫ਼ੀ ਹਿੱਸਾ ਸਿਰਫ਼ ਕਨੈਕਸ਼ਨ ਪ੍ਰਬੰਧਨ 'ਤੇ ਖਰਚ ਕਰ ਸਕਦਾ ਹੈ ਬਜਾਏ ਕਿ ਕੁਐਰੀ ਚਲਾਉਣ ਦੇ। ਜੇ ਤੁਹਾਡੇ ਕੋਲ ਪਹਿਲਾਂ ਹੀ ਪੂਲ ਹੈ ਪਰ ਇਹ ਬਹੁਤ ਵੱਡਾ ਹੈ, ਤੁਸੀਂ ਬਹੁਤ ਸਾਰੇ ਐਕਟਿਵ ਬੈਕਐਂਡ ਨਾਲ Postgres ਨੂੰ ਓਵਰਲੋਡ ਕਰ ਸਕਦੇ ਹੋ ਅਤੇ ਕੋਨਟੈਕਸਟ ਸਵਿੱਚਿੰਗ ਅਤੇ ਮੈਮੋਰੀ ਦਬਾਅ ਤਰੱਕ ਹੋ ਸਕਦੇ ਹਨ।
ਸ਼ੁਰੂਆਤੀ ਲੱਛਣਾਂ ਲਈ ਧਿਆਨ ਦਿਓ:
ਪੂਲਿੰਗ ਕਨੈਕਸ਼ਨ ਚਰਨਨੂੰ ਘਟਾਉਂਦੀ ਹੈ ਅਤੇ Postgres ਨੂੰ ਬਰਸਟ ਹੈਂਡਲ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਦੀ ਹੈ। ਇਹ ਧੀਮੇ SQL ਨੂੰ ਠੀਕ ਨਹੀਂ ਕਰੇਗੀ। ਜੇ ਕੋਈ ਕੁਐਰੀ ਫੁੱਲ ਟੇਬਲ ਸਕੈਨ ਕਰ ਰਹੀ ਹੈ ਜਾਂ ਲੌਕਾਂ 'ਤੇ ਰੁਕੀ ਹੋਈ ਹੈ, ਤਾਂ ਪੂਲਿੰਗ ਅਕਸਰ ਸਿਰਫ਼ ਇਹ ਬਦਲਦੀ ਹੈ ਕਿ ਸਿਸਟਮ ਕਿਵੇਂ ਫੇਲ ਹੁੰਦਾ ਹੈ (ਜਿਆਦਾ ਜਲਦੀ ਕਤਾਰ, ਬਾਅਦ ਵਿੱਚ ਟਾਈਮਆਉਟ), ਨਾ ਕਿ ਉਹ ਤੇਜ਼ ਹੈ।
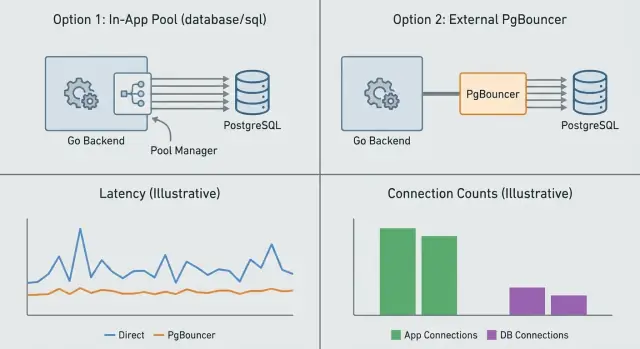
ਕਨੈਕਸ਼ਨ ਪੁਲਿੰਗ ਇਸ ਗੱਲ ਬਾਰੇ ਹੈ ਕਿ ਇੱਕ ਸਮੇਂ ਵਿੱਚ ਕਿੰਨੀਆਂ ਡੇਟਾਬੇਜ਼ ਕਨੈਕਸ਼ਨ ਖੁਲੀਆਂ ਰਹਿਣ ਅਤੇ ਉਹਨਾਂ ਨੂੰ ਕਿਵੇਂ ਦੁਬਾਰਾ ਵਰਤਿਆ ਜਾਵੇ। ਤੁਸੀਂ ਇਹ ਆਪਣੀ ਐਪ ਦੇ اندر ਕਰ ਸਕਦੇ ਹੋ (app-level pooling) ਜਾਂ Postgres ਦੇ ਸਾਹਮਣੇ ਇੱਕ ਵੱਖਰਾ ਸਰਵਿਸ ਰੱਖ ਕੇ (PgBouncer)। ਇਹ ਸਬੰਧਤ ਪਰ ਵੱਖ-ਵੱਖ ਸਮੱਸਿਆਵਾਂ ਹੱਲ ਕਰਦੇ ਹਨ।
App-level pooling (Go ਵਿੱਚ ਆਮ ਤੌਰ 'ਤੇ ਬਿਲਟ-ਇਨ database/sql ਪੂਲ) ਪ੍ਰਤੀ ਪ੍ਰੋਸੈਸ ਕਨੈਕਸ਼ਨ ਨੂੰ ਮੈਨੇਜ ਕਰਦਾ ਹੈ। ਇਹ ਫੈਸਲਾ ਕਰਦਾ ਹੈ ਕਿ ਕਦੋਂ ਨਵਾਂ ਕਨੈਕਸ਼ਨ ਖੋਲ੍ਹਣਾ ਹੈ, ਕਦੋਂ ਕਿਸੇ ਨੂੰ ਦੁਬਾਰਾ ਵਰਤਣਾ ਹੈ, ਅਤੇ ਕਦੋਂ ਆਈਡਲ ਨੂੰ ਬੰਦ ਕਰਨਾ ਹੈ। ਇਸ ਨਾਲ ਹਰ ਰਿਕਵੈਸਟ 'ਤੇ ਸੈਟਅੱਪ ਖਰਚੋਂ ਬਚਿਆ ਜਾਂਦਾ ਹੈ। ਜੋ ਇਹ ਨਹੀਂ ਕਰ ਸਕਦਾ ਉਹ ਹੈ ਕਈ ਐਪ ਇੰਸਟੈਂਸਾਂ ਦਰਮਿਆਨ ਤਾਲਮੇਲ ਕਰਨਾ। ਜੇ ਤੁਸੀਂ 10 ਰੀਪਲੀਕਾਜ਼ ਚਲਾ ਰਹੇ ਹੋ, ਤਾਂ ਤੁਸੀਂ ਅਸਲ ਵਿੱਚ 10 ਵੱਖ-ਵੱਖ ਪੂਲ ਰੱਖ ਰਹੇ ਹੋ।
PgBouncer ਤੁਹਾਡੀ ਐਪ ਅਤੇ Postgres ਵਿਚਕਾਰ ਬੈਠਦਾ ਹੈ ਅਤੇ ਬਹੁਤ ਸਾਰੇ ਕਲਾਇੰਟਾਂ ਵਾਸਤੇ ਪੂਲ ਕਰਦਾ ਹੈ। ਇਹ ਸਭ ਤੋਂ ਜ਼ਿਆਦਾ ਲਾਭਦਾਇਕ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਤੁਹਾਡੇ ਕੋਲ ਬਹੁਤ ਸਾਰੇ ਛੋਟੇ ਸਮੇਂ ਵਾਲੇ ਰਿਕਵੈਸਟ ਹਨ, ਕਈ ਐਪ ਇੰਸਟੈਂਸ ਹਨ, ਜਾਂ ਟਰੈਫਿਕ ਬਰਸਟੀ ਹੁੰਦਾ ਹੈ। ਇਹ Postgres ਵੱਲ ਸਰਵਰ-ਸਾਈਡ ਕਨੈਕਸ਼ਨਾਂ ਨੂੰ ਸੀਮਿਤ ਕਰ ਦਿੰਦਾ ਹੈ ਭਾਵੇਂ ਸੈਂਕੜੇ ਕਲਾਇੰਟ ਕਨੈਕਸ਼ਨ ਇੱਕੋ ਵਕਤ ਆ ਜਾਣ।
ਜ਼ਿੰਨੀ ਸਧਾਰਣ ਜ਼ਿੰਮੇਵਾਰੀ ਵੰਡ ਹੈ:
ਉਹ ਇਕੱਠੇ ਕੰਮ ਕਰ ਸਕਦੇ ਹਨ ਬੇਸ਼ੱਕ ਜੇ ਹਰ ਲੇਅਰ ਦੀ ਇੱਕ ਸਾਫ਼ ਜ਼ਿੰਮੇਵਾਰੀ ਹੋਵੇ: ਹਰ Go ਪ੍ਰੋਸੈਸ ਲਈ ਇਕ ਸਮਝਦਾਰ database/sql ਪੂਲ, ਅਤੇ PgBouncer ਨਾਲ ਗਲੋਬਲ ਕਨੈਕਸ਼ਨ ਬਜਟ ਪ੍ਰਬੰਧਤ ਕਰਨਾ।
ਅਕਸਰ ਗਲਤਫਹਮੀਆਂ ਇਹ ਧਾਰਣਾ ਹੁੰਦੀ ਹੈ ਕਿ "ਜਿਆਦਾ ਪੂਲਾਂ ਦਾ ਮਤਲਬ ਵੱਧ ਕੈਪੇਸਿਟੀ"। ਅਕਸਰ ਇਸ ਦਾ ਉਲਟ ਹੁੰਦਾ ਹੈ। ਜੇ ਹਰ ਸਰਵਿਸ, ਵਰਕਰ, ਅਤੇ ਰੀਪਲੀਕਾ ਆਪਣਾ ਵੱਡਾ ਪੂਲ ਰੱਖਦਾ ਹੈ, ਤਾਂ ਕੁੱਲ ਕਨੈਕਸ਼ਨ ਗਿਣਤੀ ਫਟਾਕੇ ਨਾਲ ਵਧ ਸਕਦੀ ਹੈ ਅਤੇ ਕਤਾਰ, ਕੋਨਟੈਕਸਟ ਸਵਿੱਚਿੰਗ, ਅਤੇ ਅਚਾਨਕ ਲੈਟੈਂਸੀ ਸਪਾਈਕ ਹੋ ਸਕਦੇ ਹਨ।
database/sql ਪੂਲ ਕੀ ਤਰ੍ਹਾਂ ਵਾਸਤਵ ਵਿੱਚ ਵਰਤਦਾ ਹੈGo ਵਿੱਚ, sql.DB ਇੱਕ ਕਨੈਕਸ਼ਨ ਪੂਲ ਮੈਨੇਜਰ ਹੈ, ਇੱਕ ਸਿੰਗਲ ਕਨੈਕਸ਼ਨ ਨਹੀਂ। ਜਦੋਂ ਤੁਸੀਂ db.Query ਜਾਂ db.Exec ਕਾਲ ਕਰਦੇ ਹੋ, database/sql ਇੱਕ ਆਈਡਲ ਕਨੈਕਸ਼ਨ ਰੀਯੂਜ਼ ਕਰਨ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰਦਾ ਹੈ। ਜੇ ਉਹ ਨਹੀਂ ਕਰ ਸਕਦਾ, ਤਾਂ ਇਹ ਨਵਾਂ ਖੋਲ੍ਹ ਸਕਦਾ ਹੈ (ਤੁਹਾਡੇ ਲਿਮਿਟ ਤੱਕ) ਜਾਂ ਰਿਕਵੈਸਟ ਨੂੰ ਰੋਕ ਸਕਦਾ ਹੈ।
ਇਹੀ ਉਡੀਕ ਅਕਸਰ "ਰਹਸਮੀ ਲੈਟੈਂਸੀ" ਦਾ ਕਾਰਨ ਬਣਦੀ ਹੈ। ਜਦੋਂ ਪੂਲ ਸੈਚਰੈਟਡ ਹੁੰਦਾ ਹੈ, ਤਾਂ ਰਿਕਵੈਸਟ ਤੁਹਾਡੇ ਐਪ ਦੇ اندر ਕਤਾਰ ਵਿੱਚ ਖੜੇ ਹੁੰਦੇ ਹਨ। ਬਾਹਰੋਂ ਇਹ ਇਸ ਤਰ੍ਹਾਂ ਲੱਗਦਾ ਹੈ ਕਿ Postgres ਧੀਮਾ ਹੋ ਗਿਆ, ਪਰ ਸੱਚਾਈ ਇਹ ਹੈ ਕਿ ਸਮਾਂ ਸਿਰਫ਼ ਇੱਕ ਖਾਲੀ ਕਨੈਕਸ਼ਨ ਦੇ ਇੰਤਜ਼ਾਰ ਵਿੱਚ ਲੰਘ ਰਿਹਾ ਹੈ।
ਜ਼ਿਆਦਾਤਰ ਟਿਊਨਿੰਗ ਚਾਰ ਸੈਟਿੰਗਾਂ 'ਤੇ ਆਉਂਦੀ ਹੈ:
MaxOpenConns: ਖੁਲੇ ਕਨੈਕਸ਼ਨਾਂ ਦਾ ਹਾਰਡ ਕੈਪ (idle + in use). ਜਦੋਂ ਤੁਸੀਂ ਇਸ ਨੂੰ ਹਿੱਟ ਕਰਦੇ ਹੋ, callers block ਹੋ ਜਾਂਦੇ ਹਨ।MaxIdleConns: ਕਿਨ੍ਹੇ ਕਨੈਕਸ਼ਨ ਰੀਡੀ ਰੱਖੇ ਜਾ ਸਕਦੇ ਹਨ। ਬਹੁਤ ਘੱਟ ਹੋਣ 'ਤੇ ਦੁਬਾਰਾ ਕਨੈਕਟ ਹੋਣ ਵਧਦਾ ਹੈ।ConnMaxLifetime: ਸਮੇਂ-ਸਮੇਂ 'ਤੇ ਕਨੈਕਸ਼ਨਾਂ ਨੂੰ ਰੀਸਾਇਕਲ ਕਰਨ ਲਈ। ਲੋਡ ਬੈਲੈਂਸਰ ਅਤੇ NAT ਟਾਈਮਆਉਟ ਲਈ ਮਦਦਗਾਰ, ਪਰ ਬਹੁਤ ਛੋਟਾ ਹੋਵੇ ਤਾਂ churn ਬਣਦਾ ਹੈ।ConnMaxIdleTime: ਉਹਨਾਂ ਕਨੈਕਸ਼ਨਾਂ ਨੂੰ ਬੰਦ ਕਰਦਾ ਹੈ ਜੋ ਲੰਮੇ ਸਮੇਂ ਲਈ ਬੇਕਾਮ ਹਨ।ਕਨੈਕਸ਼ਨ ਰੀਯੂਜ਼ ਆਮ ਤੌਰ 'ਤੇ ਲੈਟੈਂਸੀ ਅਤੇ ਡੇਟਾਬੇਜ਼ CPU ਨੂੰ ਘਟਾਉਂਦਾ ਹੈ ਕਿਉਂਕਿ ਤੁਸੀਂ ਬਾਰ-ਬਾਰ ਸੈਟਅੱਪ (TCP/TLS, auth, session init) ਨੋਹਰ ਨਹੀਂ ਕਰਦੇ। ਪਰ ਵੱਡਾ ਪੂਲ ਇਸਦਾ ਉਲਟ ਕਰ ਸਕਦਾ ਹੈ: ਇਹ Postgres ਲਈ ਵੱਧ concurrent queries ਅਨੁਮਤ ਕਰਦਾ ਹੈ ਜੋ ਉਹ ਚੰਗੀ ਤਰ੍ਹਾਂ ਸੰਭਾਲ ਨਹੀਂ ਸਕਦਾ, ਜਿਸ ਨਾਲ contention ਅਤੇ ਓਵਰਹੈੱਡ ਵਧਦਾ ਹੈ।
ਪਰੋਸੈਸ-ਵਾਰ ਸੋਚੋ, ਨਾ ਕਿ ਸਿਰਫ਼ ਪ੍ਰਤੀ-ਪ੍ਰੋਸੈਸ। ਜੇ ਹਰ Go ਇੰਸਟੈਂਸ 50 open connections ਅਨੁਮਤ ਕਰਦਾ ਹੈ ਅਤੇ ਤੁਸੀਂ 20 ਇੰਸਟੈਂਸ ਤੱਕ ਸਕੇਲ ਕਰਦੇ ਹੋ, ਤਾਂ ਤੁਸੀਂ ਅਸਲ ਵਿੱਚ 1,000 connections ਆਗਿਆ ਦਿੱਤੀ ਹੈ। ਉਸ ਗਿਣਤੀ ਨੂੰ ਤੁਸੀਂ ਆਪਣੇ Postgres ਸਰਵਰ ਦੀ ਯਥਾਰਥ ਸਮਰੱਥਾ ਨਾਲ ਤੁਲਨਾ ਕਰੋ।
ਇੱਕ ਪ੍ਰਾਇਕਟਿਕ ਸ਼ੁਰੂਆਤ ਇਹ ਹੈ ਕਿ MaxOpenConns ਨੂੰ ਪ੍ਰਤੀ ਇੰਸਟੈਂਸ ਉਮੀਦ ਕੀਤੀ concurrency ਨਾਲ ਬਾਂਧੋ, ਫਿਰ ਪੂਲ ਮੈਟ੍ਰਿਕਸ (in-use, idle, ਅਤੇ wait time) ਨਾਲ ਵੈਰੀਫਾਈ ਕਰੋ ਪਹਿਲਾਂ ਕਿ ਤੁਸੀਂ ਇਸਨੂੰ ਵਧਾਉਂਦੇ ਹੋ।
PgBouncer ਤੁਹਾਡੇ ਐਪ ਅਤੇ PostgreSQL ਵਿਚਕਾਰ ਇੱਕ ਛੋਟਾ ਪ੍ਰਾਕਸੀ ਹੈ। ਤੁਹਾਡੀ ਸੇਵਾ PgBouncer ਨਾਲ ਜੁੜਦੀ ਹੈ, ਅਤੇ PgBouncer ਕੋਲ Postgres ਲਈ ਇੱਕ ਸੀਮਿਤ ਸੰਖਿਆ ਵਿੱਚ ਅਸਲ ਸਰਵਰ ਕਨੈਕਸ਼ਨ ਹੁੰਦੇ ਹਨ। ਬਰਸਟ ਦੌਰਾਨ, PgBouncer ਕਲਾਇੰਟ ਕੰਮ ਨੂੰ ਕਤਾਰ ਵਿੱਚ ਰੱਖਦਾ ਹੈ ਨਾਂ ਕਿ ਤੁਰੰਤ ਹੋਰ Postgres ਬੈਕਐਂਡ ਬਣਾਉਂਦਾ ਹੈ। ਉਹ ਕਤਾਰ ਹੀ ਕਈ ਵਾਰੀ ਫ਼ਰਕ ਪੈਦਾ ਕਰਦੀ ਹੈ—ਇੱਕ ਨਿਯੰਤ੍ਰਿਤ ਧੀਮਾਪਨ ਅਤੇ ਇੱਕ ਡੇਟਾਬੇਜ਼ ਦੇ ਢਹਿਣੇ ਵਿਚਕਾਰ।
PgBouncer ਦੇ ਤਿੰਨ ਪੂਲਿੰਗ ਮੋਡ ਹਨ:
Session pooling ਸਭ ਤੋਂ ਵੱਧ direct Postgres ਨਾਲ ਮਿਲਦੀ ਜੁਲਦੀ ਵਰਤੋਂ ਹੈ। ਇਹ ਘੱਟ ਹੈਰਾਨੀਜਨਕ ਹੈ, ਪਰ ਬਰਸਟ ਲੋਡ ਦੌਰਾਨ ਇਹ ਸਰਵਰ ਕਨੈਕਸ਼ਨਾਂ ਦੀ ਬਚਤ ਘੱਟ ਕਰਦੀ ਹੈ।
ਆਮ Go HTTP APIs ਲਈ, transaction pooling ਅਕਸਰ ਇਕ ਮਜ਼ਬੂਤ ਡਿਫਾਲਟ ਹੁੰਦਾ ਹੈ। ਜਿਆਦातर ਰਿਕਵੈਸਟ ਇੱਕ ਛੋਟਾ ਕੁਐਰੀ ਜਾਂ ਛੋਟੀ ਟਰਾਂਜ਼ੈਕਸ਼ਨ ਕਰਦੇ ਹਨ ਅਤੇ ਫਿਰ ਖਤਮ ਹੋ ਜਾਂਦੇ ਹਨ। Transaction pooling ਬਹੁਤ ਸਾਰੇ ਕਲਾਇੰਟ ਕਨੈਕਸ਼ਨਾਂ ਨੂੰ ਘੱਟ Postgres ਕਨੈਕਸ਼ਨ ਬਜਟ ਨਾਲ ਸਾਂਝਾ ਕਰਨ ਦਿੰਦਾ ਹੈ।
ਟ੍ਰੇਡ-ਆਫ਼ session state ਹੈ। transaction ਮੋਡ ਵਿੱਚ, ਉਹ ਸਭ ਕੁਝ ਜੋ ਇੱਕ ਹੀ ਸਰਵਰ ਕਨੈਕਸ਼ਨ 'ਤੇ ਜੰਮ ਜਾਂਦਾ ਹੈ ਉਹ ਟੁੱਟ ਸਕਦਾ ਹੈ ਜਾਂ ਅਜੀਬ ਤਰੀਕੇ ਨਾਲ ਵਤੀਰਾ ਕਰ ਸਕਦਾ ਹੈ, ਜਿਸ ਵਿੱਚ ਸ਼ਾਮਲ ਹਨ:
SET, SET ROLE, search_path)ਜੇ ਤੁਹਾਡੀ ਐਪ ਐਸੇ ਸੈਸ਼ਨ ਰਾਜ ਤੇ ਨਿਰਭਰ ਕਰਦੀ ਹੈ, ਤਾਂ session pooling ਜ਼ਿਆਦਾ ਸੁਰੱਖਿਅਤ ਹੈ। Statement pooling ਸਭ ਤੋਂਸੀਮਿਤ ਹੈ ਅਤੇ ਵੈੱਬ ਐਪਸ ਲਈ ਰੈਅਰਲੀ ਮੈਚ ਕਰਦੀ ਹੈ।
ਇੱਕ ਉਪਯੋਗੀ ਨਿਯਮ: ਜੇ ਹਰ ਰਿਕਵੈਸਟ ਇੱਕ ਟਰਾਂਜ਼ੈਕਸ਼ਨ ਦੇ اندر ਆਪਣੀ ਲੋੜ ਸੈੱਟ ਕਰ ਸਕਦਾ ਹੈ, ਤਾਂ transaction pooling ਬਰਸਟੀ ਲੋਡ ਹੇਠਾਂ ਲੈਟੈਂਸੀ ਨੂੰ ਜ਼ਿਆਦਾ ਸਥਿਰ ਰੱਖਣ ਵਾਲੀ ਹੁੰਦੀ ਹੈ। ਜੇ ਤੁਹਾਨੂੰ ਲੰਬੇ ਸਮੇਂ ਦੇ session ਵਰਤੋਂ ਦੀ ਲੋੜ ਹੈ, ਤਾਂ session pooling ਵਰਤੋ ਅਤੇ ਐਪ ਵਿਚ ਕਠੋਰ ਸੀਮਾਵਾਂ 'ਤੇ ਧਿਆਨ ਦਿਓ।
ਜੇ ਤੁਸੀਂ database/sql ਨਾਲ Go ਸੇਵਾ ਚਲਾ ਰਹੇ ਹੋ, ਤਾਂ ਤੁਹਾਡੇ ਕੋਲ ਪਹਿਲਾਂ ਹੀ ਐਪ-ਸਾਈਡ ਪੂਲ ਹੈ। ਕਈ ਟੀਮਾਂ ਲਈ, ਇਹ ਹੀ ਕਾਫ਼ੀ ਹੁੰਦਾ ਹੈ: ਕੁਝ ਇੰਸਟੈਂਸ, ਸਥਿਰ ਟਰੈਫਿਕ, ਅਤੇ ਐਸੀਆਂ ਕੁਐਰੀਆਂ ਜੋ ਬਹੁਤ ਹੀ ਬਰਸਟੀ ਨਹੀਂ ਹਨ। ਇਸ ਸੈਟਅਪ ਵਿੱਚ, ਸਭ ਤੋਂ ਸਧਾਰਣ ਅਤੇ ਸਭ ਤੋਂ ਸੁਰੱਖਿਅਤ ਚੋਣ Go ਪੂਲ ਨੂੰ ਟਿਊਨ ਕਰਨਾ ਹੈ, ਡੇਟਾਬੇਜ਼ ਕਨੈਕਸ਼ਨ ਲਿਮਿਟ ਨੂੰ ਹਕੀਕਤ-ਨੁਮਾ ਰੱਖਣਾ, ਅਤੇ ਇੱਥੇ ਰੁਕ ਜਾਣਾ।
PgBouncer ਉਦੋਂ ਸਭ ਤੋਂ ਜ਼ਿਆਦਾ ਮਦਦਗਾਰ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਡੇਟਾਬੇਜ਼ 'ਤੇ ਬਹੁਤ ਸਾਰੇ ਕਲਾਇੰਟ ਕਨੈਕਸ਼ਨ ਇੱਕੋ ਵਕਤ ਹਮਲਾ ਕਰਦੇ ਹਨ। ਇਹ ਹਾਲਤ ਕਈ ਐਪ ਇੰਸਟੈਂਸਾਂ (ਜਾਂ serverless-ਨੁਮਾ ਸਕੇਲਿੰਗ), ਬਰਸਟੀ ਟਰੈਫਿਕ, ਅਤੇ ਬਹੁਤ ਛੋਟੀਆਂ ਕੁਐਰੀਆਂ ਨਾਲ ਦਿਸਦੀ ਹੈ।
PgBouncer ਨੁਕਸਾਨ ਵੀ ਕਰ ਸਕਦਾ ਹੈ ਜੇ ਇਹ ਗਲਤ ਮੋਡ ਵਿੱਚ ਵਰਤਿਆ ਜਾਵੇ। ਜੇ ਤੁਹਾਡਾ ਕੋਡ ਸੈਸ਼ਨ ਰਾਜ 'ਤੇ ਨਿਰਭਰ ਕਰਦਾ ਹੈ (ਅਸਥਾਈ ਟੇਬਲ, prepared statements ਜੋ ਰਿਕਵੈਸਟਾਂ ਦੇ ਵਿਚਕਾਰ ਦੁਬਾਰਾ ਵਰਤੇ ਜਾਂਦੇ ਹਨ, advisory locks, ਜਾਂ session-level settings), ਤਾਂ transaction pooling ਗੁੰਝਲਦਾਰ ਫੇਲ ਹੋ ਸਕਦਾ ਹੈ। ਜੇ ਤੁਹਾਨੂੰ ਵਾਕਈ session ਵਰਤੋਂ ਦੀ ਲੋੜ ਹੈ, ਤਾਂ session pooling ਵਰਤੋ ਜਾਂ PgBouncer ਛੱਡ ਦਿਉ ਅਤੇ ਐਪ ਪੂਲਾਂ ਨੂੰ ਧਿਆਨ ਨਾਲ ਸਾਈਜ਼ ਕਰੋ।
ਇਹ ਨਿਯਮ ਵਰਤੋਂ:
ਕਨੈਕਸ਼ਨ ਲਿਮਿਟ ਇਕ ਬਜਟ ਹੁੰਦਾ ਹੈ। ਜੇ ਤੁਸੀਂ ਇੱਕੋ ਵਾਰ ਸਾਰਾ ਬਜਟ ਖਰਚ ਕਰ ਦਿੰਦੇ ਹੋ, ਤਾਂ ਹਰ ਨਵਾਂ ਰਿਕਵੈਸਟ ਉਡੀਕ ਕਰਦਾ ਹੈ ਅਤੇ ਟੇਲ ਲੈਟੈਂਸੀ ਛਾਲ ਮਾਰਦੀ ਹੈ। ਲਕਸ਼ ਇਹ ਹੈ ਕਿ concurrency ਨੂੰ ਨਿਯੰਤਰਿਤ ਤਰੀਕੇ ਨਾਲ ਕੈਪ ਕੀਤਾ ਜਾਵੇ ਜਦਕਿ throughput ਸਥਿਰ ਰਹੇ।
ਅੱਜ ਦੇ ਪੀਕ ਅਤੇ ਟੇਲ ਲੈਟੈਂਸੀ ਨੂੰ ਮਾਪੋ। ਪੀਕ active connections (ਸਿਰਫ਼ ਐਵਰੇਜ ਨਹੀਂ), ਨਾਲ ਹੀ requests ਅਤੇ ਮੁੱਖ ਕੁਐਰੀਆਂ ਲਈ p50/p95/p99 ਨੋਟ ਕਰੋ। ਕਿਸੇ ਵੀ ਕਨੈਕਸ਼ਨ ਐਰਰ ਜਾਂ ਟਾਈਮਆਉਟ ਨੂੰ ਨੋਟ ਕਰੋ।
ਐਪ ਲਈ ਇੱਕ ਸੁਰੱਖਿਅਤ Postgres ਕਨੈਕਸ਼ਨ ਬਜਟ ਸੈੱਟ ਕਰੋ। max_connections ਤੋਂ ਸ਼ੁਰੂ ਕਰੋ ਅਤੇ admin access, migrations, background jobs, ਅਤੇ ਬਰਸਟ ਲਈ headroom ਘਟਾਓ। ਜੇ ਕਈ ਸੇਵਾਵਾਂ ਡੇਟਾਬੇਜ਼ ਸਾਂਝਾ ਕਰਦੀਆਂ ਹਨ, ਤਾਂ ਬਜਟ ਨੂੰ ਜਾਣੂ ਤਰੀਕੇ ਨਾਲ ਵੰਡੋ।
ਬਜਟ ਨੂੰ Go ਲਿਮਿਟਾਂ (ਪ੍ਰਤੀ ਇੰਸਟੈਂਸ) ਨਾਲ ਮੇਪ ਕਰੋ। ਐਪ ਬਜਟ ਨੂੰ ਇੰਸਟੈਂਸਾਂ ਦੀ ਗਿਣਤੀ ਨਾਲ ਵੰਡੋ ਅਤੇ MaxOpenConns ਨੂੰ ਉਸ ਪੇਮਾਨੇ ਤੇ ਸੈੱਟ ਕਰੋ (ਜਾਂ ਥੋੜ੍ਹਾ ਘੱਟ)। MaxIdleConns ਇਸ kadar ਰੱਖੋ ਕਿ constant reconnects نہ ہوں, ਤੇ lifetimes ਐਸੇ ਰੱਖੋ ਕਿ ਕਨੈਕਸ਼ਨਾਂ ਕਦੇ-ਕਦੇ ਰੀਸਾਇਕਲ ਹੋ ਜਾਣ ਪਰ churn ਨਾ ਬਣੇ।
ਸਿਰਫ਼ ਜ਼ਰੂਰਤ ਹੋਣ 'ਤੇ PgBouncer ਜੋੜੋ, ਅਤੇ ਇੱਕ ਮੋਡ ਚੁਣੋ। ਜੇਤੋਂ session state ਦੀ ਲੋੜ ਹੈ ਤਾਂ session pooling ਵਰਤੋ। ਜੇ ਤੁਹਾਡੀ ਐਪ ਕੰਪੈਟਿਬਲ ਹੈ ਅਤੇ ਤੁਸੀਂ ਸਰਵਰ ਕਨੈਕਸ਼ਨਾਂ ਵਿਚ ਵੱਡੀ ਘਟੋਤਰੀ ਚਾਹੁੰਦੇ ਹੋ ਤਾਂ transaction pooling ਵਰਤੋ।
ਧੀਰੇ-ਧੀਰੇ ਰੋਲ ਆਉਟ ਕਰੋ ਅਤੇ ਪਹਿਲਾਂ-ਬਾਅਦੋਂ ਤੁਲਨਾ ਕਰੋ। ਇੱਕ ਸਮੇਂ 'ਤੇ ਇੱਕ ਹੀ ਚੀਜ਼ ਬਦਲੋ, canary ਰੋਲਆਉਟ ਕਰੋ, ਫਿਰ tail latency, pool wait time, ਅਤੇ database CPU ਦੀ ਤੁਲਨਾ ਕਰੋ।
ਉਦਾਹਰਨ: ਜੇ Postgres ਤੁਹਾਡੀ ਸੇਵਾ ਨੂੰ ਸੁਰੱਖਿਅਤ ਰੂਪ ਵਿੱਚ 200 connections ਦੇ ਸਕਦਾ ਹੈ ਅਤੇ ਤੁਸੀਂ 10 Go ਇੰਸਟੈਂਸ ਚਲਾ ਰਹੇ ਹੋ, ਤਾਂ ਸ਼ੁਰੂ ਕਰੋ MaxOpenConns=15-18 ਪ੍ਰਤੀ ਇੰਸਟੈਂਸ ਨਾਲ। ਇਸ ਨਾਲ ਬਰਸਟ ਲਈ ਥੋੜ੍ਹਾ ਜਿਹਾ ਕਮਰਾ ਰਹਿੰਦਾ ਹੈ ਅਤੇ ਇਸ ਗੱਲ ਦੇ ਅਵਸਰ ਘੱਟ ਹੁੰਦੇ ਹਨ ਕਿ ਹਰ ਇਕ ਇੰਸਟੈਂਸ ਇੱਕੋ ਵਾਰ ਸੀਲਿੰਗ ਨੂੰ ਹਿੱਟ ਕਰੇ।
ਪੂਲਿੰਗ ਸਮੱਸਿਆਵਾਂ ਆਮ ਤੌਰ 'ਤੇ ਪਹਿਲਾਂ "too many connections" ਵਜੋਂ ਨਹੀਂ ਦਿਖਦੀਆਂ। ਜਿਆਦਾਤਰ ਵੇਲੇ ਤੁਸੀਂ ਉਡੀਕ ਸਮਾਂ ਵਿੱਚ ਹੌਲੇ-ਹੌਲੇ ਵਾਧੇ ਨੂੰ ਵੇਖਦੇ ਹੋ ਅਤੇ ਫਿਰ ਅਚਾਨਕ p95 ਅਤੇ p99 ਛਾਲ ਮਾਰਦੇ ਹਨ।
ਆਪਣੇ Go ਐਪ ਦੀ ਰਿਪੋਰਟ ਕੀਤੀ ਚੀਜ਼ਾਂ ਤੋਂ ਸ਼ੁਰੂ ਕਰੋ। database/sql ਨਾਲ open connections, in-use, idle, wait count, ਅਤੇ wait time ਮੋਨਿਟਰ ਕਰੋ। ਜੇ wait count ਵਧ ਰਿਹਾ ਹੈ ਜਦੋਂ ਕਿ ਟਰੈਫਿਕ ਇੱਕੋ ਜਿਹਾ ਹੈ, ਤਾਂ ਤੁਹਾਡਾ ਪੂਲ ਛੋਟਾ ਹੈ ਜਾਂ ਕਨੈਕਸ਼ਨ ਬਹੁਤ ਲੰਮੇ ਰੱਖੇ ਜਾ ਰਹੇ ਹਨ।
ਡੇਟਾਬੇਜ਼ ਪਾਸੇ, active connections vs max, CPU, ਅਤੇ lock activity ਟ੍ਰੈਕ ਕਰੋ। ਜੇ CPU ਘੱਟ ਹੈ ਪਰ ਲੈਟੈਂਸੀ ਉੱਚੀ ਹੈ, ਤਾਂ ਆਮ ਤੌਰ 'ਤੇ ਇਹ queueing ਜਾਂ locks ਹੁੰਦੇ ਹਨ, ਕੱਚੇ ਕੰਪਿਊਟੇ ਦੀ ਘਾਟ ਨਹੀਂ।
ਜੇ ਤੁਸੀਂ PgBouncer ਚਲਾ ਰਹੇ ਹੋ, ਤਾਂ ਤੀਜੀ ਨਜਰ ਸ਼ਾਮਲ ਕਰੋ: client connections, server connections to Postgres, ਅਤੇ queue depth। ਇੱਕ ਵਧਦੀ ਕਤਾਰ ਜਦ ਕਿ server connections ਸਥਿਰ ਹਨ ਇੱਕ ਸਪੱਸ਼ਟ ਸੰਕੇਤ ਹੈ ਕਿ ਬਜਟ ਸੈਚੁਰੇਟਡ ਹੈ।
ਚੰਗੇ ਅਲਾਰਮ ਸੰਕੇਤ:
ਪੂਲਿੰਗ مسئلے ਅਕਸਰ ਬਰਸਟ ਦੌਰਾਨ ਆਉਂਦੇ ਹਨ: ਰਿਕਵੈਸਟ ਕਨੈਕਸ਼ਨ ਦੀ ਉਡੀਕ ਕਰਦੇ ਹੋਏ ਪਹੁੰਚ ਜਾਂਦੀਆਂ ਹਨ, ਫਿਰ ਫਿਰ ਸਭ ਕੁਝ ਠੀਕ ਲੱਗਦਾ ਹੈ। ਜੜ ਇਹ ਹੇਠਾਂ ਦਿੱਤੀਆਂ ਸੈਟਿੰਗਾਂ ਵਿੱਚੋਂ ਕੋਈ ਇੱਕ ਹੁੰਦੀ ਹੈ ਜੋ ਇੱਕ ਇੰਸਟੈਂਸ ਤੇ ਵਾਜਿਬ ਲੱਗਦੀ ਹੈ ਪਰ ਕਈ ਨਕਲਾਂ ਦੇ ਚੱਲਣ 'ਤੇ ਖ਼ਤਰਨਾਕ ਬਣ ਜਾਂਦੀ ਹੈ।
ਆਮ ਕਾਰਨ:
MaxOpenConns ਨੂੰ ਪ੍ਰਤੀ ਇੰਸਟੈਂਸ ਬਿਨਾਂ ਗਲੋਬਲ ਬਜਟ ਦੇ ਸੈੱਟ ਕੀਤਾ ਗਿਆ। 100 connections ਪ੍ਰਤੀ ਇੰਸਟੈਂਸ across 20 instances 2,000 ਸੰਭਾਵਿਤ connections ਹੈ।ConnMaxLifetime / ConnMaxIdleTime ਬਹੁਤ ਘੱਟ ਸੈੱਟ ਹੋਣਾ। ਜਿਸ ਨਾਲ ਬਹੁਤ ਸਾਰੇ ਕਨੈਕਸ਼ਨਾਂ ਇੱਕ ਵਾਰੀ 'ਤੇ ਰੀਸਾਇਕਲ ਹੋ ਕੇ reconnect storms ਬਣ ਜਾਂਦੇ ਹਨ।ਸਪਾਈਕ ਘਟਾਉਣ ਲਈ ਇੱਕ ਸਧਾਰਣ ਢੰਗ ਇਹ ਹੈ ਕਿ ਪੂਲਿੰਗ ਨੂੰ ਇੱਕ ਸਾਂਝਾ ਸੀਮਾ ਮੰਨੋ, ਨਾ ਕਿ ਇੱਕ ਐਪ-ਲੋਕਲ ਡਿਫਾਲਟ: ਸਾਰੇ ਇੰਸਟੈਂਸਾਂ ਵਿੱਚ ਕੁੱਲ ਕਨੈਕਸ਼ਨਾਂ ਨੂੰ ਕੈਪ ਕਰੋ, ਇੱਕ ਮੋਡੇਸਟ idle ਪੂਲ ਰੱਖੋ, ਅਤੇ synchronized reconnects ਤੋਂ ਬਚਣ ਲਈ lifetimes ਐਨੇ ਲੰਮੇ ਰੱਖੋ ਜੋ reconnect storms ਨਾ ਬਣਾਉਣ।
ਜਦੋਂ ਟਰੈਫਿਕ ਵਧਦਾ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਆਮ ਤੌਰ 'ਤੇ ਤਿੰਨ ਨਤੀਜਿਆਂ ਵਿੱਚੋਂ ਇੱਕ ਦੇਖਦੇ ਹੋ: ਰਿਕਵੈਸਟ ਇੱਕ ਖਾਲੀ ਕਨੈਕਸ਼ਨ ਦੀ ਉਡੀਕ ਕਰਦੇ ਹੋਏ ਕਤਾਰ ਵਿੱਚ ਖੜੇ ਹੋ ਜਾਂਦੇ ਹਨ, ਰਿਕਵੈਸਟ ਟਾਈਮਆਉਟ ਹੋ ਜਾਂਦੇ ਹਨ, ਜਾਂ ਸਭ ਕੁਝ ਇੰਨਾ ਧੀਮਾ ਹੋ ਜਾਂਦਾ ਹੈ ਕਿ retries ਇਕੱਠੇ ਹੋ ਜਾਂਦੇ ਹਨ।
ਕਤਾਰ ਬਣਨਾ ਸਭ ਤੋਂ ਚਲਾਕੀ ਵਾਲੀ ਗੱਲ ਹੈ। ਤੁਹਾਡਾ ਹੈਂਡਲਰ ਅਜੇ ਵੀ ਚੱਲ ਰਿਹਾ ਹੁੰਦਾ ਹੈ, ਪਰ ਇਹ ਕਨੈਕਸ਼ਨ ਦੀ ਉਡੀਕ ਵਿੱਚ ਪਾਰਕ ਹੈ। ਉਹ ਉਡੀਕ ਜਵਾਬ ਸਮੇਂ ਦਾ ਹਿੱਸਾ ਬਣ ਜਾਂਦੀ ਹੈ, ਇਸ ਲਈ ਛੋਟਾ ਪੂਲ 50 ms ਵਾਲੀ ਕੁਐਰੀ ਨੂੰ ਲੋਡ ਹੇਠਾਂ ਕਈ ਸਕਿੰਟਾਂ ਵਾਲਾ ਏਂਡਪੌਇੰਟ ਬਣਾ ਸਕਦਾ ਹੈ।
ਇੱਕ ਮਦਦਗਾਰ ਮਾਨਸਿਕ ਮਾਡਲ: ਜੇ ਤੁਹਾਡੇ ਪੂਲ ਵਿੱਚ 30 ਵਰਤੋਂਯੋਗ ਕਨੈਕਸ਼ਨ ਹਨ ਅਤੇ ਅਚਾਨਕ 300 ਸਮਕਾਲੀ ਰਿਕਵੈਸਟ ਆ ਜਾਂਦੀਆਂ ਹਨ ਜੋ ਸਾਰੇ ਡੇਟਾਬੇਜ਼ ਦੀ ਲੋੜ ਰੱਖਦੀਆਂ ਹਨ, ਤਾਂ 270 ਉਨ੍ਹਾਂ ਵਿੱਚੋਂ ਉਡੀਕ ਕਰਨਗੇ। ਜੇ ਹਰ ਰਿਕਵੈਸਟ ਇੱਕ ਕਨੈਕਸ਼ਨ 100 ms ਲਈ ਰੱਖਦਾ ਹੈ, ਤਾਂ ਟੇਲ ਲੈਟੈਂਸੀ ਜਲਦੀ ਹੀ ਸਕਿੰਟਾਂ ਵਿੱਚ ਚੱਲ ਜਾ ਸਕਦੀ ਹੈ।
ਇੱਕ ਸਾਫ਼ ਟਾਈਮਆਉਟ ਬਜੱਟ ਸੈੱਟ ਕਰੋ ਅਤੇ ਇਸਤੇ ਅਟਲ ਰਹੋ। ਐਪ ਟਾਈਮਆਉਟ DB ਟਾਈਮਆਉਟ ਤੋਂ ਥੋੜ੍ਹਾ ਛੋਟਾ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ ਤਾਂ ਜੋ ਤੁਸੀਂ ਤੇਜ਼ੀ ਨਾਲ fail ਕਰੋ ਅਤੇ ਦਬਾਅ ਘਟ ਕਰੋ ਨਾਂ ਕਿ ਕੰਮ ਲੰਮੇ ਟਿਕੇ ਰਹਿਣ ਦਿਓ।
statement_timeout ਤਾਂ ਜੋ ਇੱਕ ਖਰਾਬ ਕੁਐਰੀ ਕਨੈਕਸ਼ਨਾਂ ਨੂੰ ਸਦਾ ਲਈ ਨ੍ਹਿੱਬੇ ਨਾ ਰੱਖੇਫਿਰ ਬੈਕਪ੍ਰੈਸ਼ਰ ਜੋੜੋ ਤਾਂ ਕਿ ਤੁਸੀਂ ਪੂਲ ਨੂੰ ਪਹਿਲਾਂ ਹੀ ਓਵਰਲੋਡ ਨਾ ਕਰੋ। ਇੱਕ ਜਾਂ ਦੋ ਪੇਛਾਣਯੋਗ ਮਕੈਨ਼ਜ਼ਮ ਚੁਣੋ, ਜਿਵੇਂ ਕਿ ਪ੍ਰਤੀ-ਏਂਡਪੌਇੰਟ concurrency ਸੀਮਿਤ ਕਰਨਾ, 429 ਵਰਗੇ ਸਪਸ਼ਟ errors ਨਾਲ load shedding, ਜਾਂ background jobs ਨੂੰ user traffic ਤੋਂ ਅਲੱਗ ਰੱਖਣਾ।
ਅੰਤ ਵਿੱਚ, ਸਭ ਤੋਂ ਪਹਿਲਾਂ ਧੀਮੀਆਂ ਕੁਐਰੀਆਂ ਠੀਕ ਕਰੋ। ਪੁਲਿੰਗ ਦਬਾਅ ਹੇਠਾਂ, ਧੀਮੀ ਕੁਐਰੀਆਂ ਕਨੈਕਸ਼ਨ ਨੂੰ ਲੰਮਾ ਰੱਖਦੀਆਂ ਹਨ, ਜਿਸ ਨਾਲ ਉਡੀਕ ਵਧਦੀ ਹੈ, ਟਾਈਮਆਉਟ ਵਧਦੇ ਹਨ, ਅਤੇ retries ਪੈਦਾ ਹੁੰਦੇ ਹਨ। ਉਹ feedback loop ਹੈ ਜਿਸ ਨਾਲ "ਥੋੜ੍ਹਾ ਧੀਮਾ" "ਸਭ ਕੁਝ ਧੀਮਾ" ਵਿੱਚ ਬਦਲ ਜਾਂਦਾ ਹੈ।
ਲੋਡ ਟੈਸਟਿੰਗ ਨੂੰ ਆਪਣੇ ਕਨੈਕਸ਼ਨ ਬਜਟ ਨੂੰ ਵੈਰਿਫਾਈ ਕਰਨ ਦੇ ਤਰੀਕੇ ਵਜੋਂ treat ਕਰੋ, ਕੇਵਲ throughput ਲਈ ਨਹੀਂ। ਮਕਸਦ ਇਹ ਪੱਕਾ ਕਰਨਾ ਹੈ ਕਿ ਪੂਲਿੰਗ ਜਦ ਦਬਾਅ ਹੇਠਾਂ ਹੋਵੇ ਤਾਂ ਉਹ ਸਟੇਜਿੰਗ ਵਾਲੀ ਤਰ੍ਹਾਂ ਹੀ ਵਰਤਿਆ ਜਾਵੇ।
ਅਸਲੀ ਟਰੈਫਿਕ ਨਾਲ ਟੈਸਟ ਕਰੋ: ਉਦਾਹਰਨ ਲਈ ਉਹੀ request mix, ਬਰਸਟ ਪੈਟਰਨ, ਅਤੇ ਉਹੀ ਨੰਬਰ ਐਪ ਇੰਸਟੈਂਸ ਜਿਹੜੇ ਤੁਸੀਂ production ਵਿੱਚ ਚਲਾਉਂਦੇ ਹੋ। "ਇੱਕ endpoint" ਬੈਂਚਮਾਰਕ ਅਕਸਰ ਪੂਲ ਸਮੱਸਿਆਵਾਂ ਨੂੰ ਛੁਪਾ ਦਿੰਦਾ ਹੈ ਜਦੋਂ ਤੱਕ ਲਾਂਚ ਦਿਨ।
ਵਾਰਮ-ਅੱਪ ਸ਼ਾਮਲ ਕਰੋ ਤਾਂ ਜੋ ਤੁਸੀਂ cold caches ਅਤੇ ramp-up ਪ੍ਰਭਾਵ ਮਾਪ ਨਾ ਕਰੋ। ਪੂਲਾਂ ਨੂੰ ਆਪਣੀ ਨਾਰਮਲ ਸਾਈਜ਼ ਤੱਕ ਪਹੁੰਚਣ ਦਿਓ, ਫਿਰ ਨੰਬਰ ਲੈਣਾ ਸ਼ੁਰੂ ਕਰੋ।
ਜੇ ਤੁਸੀਂ ਰਣਨੀਤੀਆਂ ਦੀ ਤੁਲਨਾ ਕਰ ਰਹੇ ਹੋ, workload ਇੱਕੋ ਜਿਹਾ ਰੱਖੋ ਅਤੇ ਚਲਾਓ:
database/sql, ਕੋਈ PgBouncer ਨਹੀਂ)ਹਰ ਦੌੜ ਤੋਂ ਬਾਅਦ, ਇੱਕ ਛੋਟਾ ਸਕੋਰਕਾਰਡ ਰਿਕਾਰਡ ਕਰੋ ਜੋ ਤੁਸੀਂ ਹਰ ਰਿਲੀਜ਼ ਤੋਂ ਬਾਅਦ ਦੁਬਾਰਾ ਵਰਤ ਸਕੋ:
ਸਮੇਂ ਨਾਲ, ਇਹ capacity planning ਨੂੰ ਅਟਕਲਾਂ ਨਾਲ ਨਹੀਂ ਸਗੋਂ ਦੁਹਰਾਏ ਜਾਣ ਯੋਗ ਬਣਾਉਂਦਾ ਹੈ।
ਪੂਲ ਸਾਈਜ਼ ਛੇਡਣ ਤੋਂ ਪਹਿਲਾਂ ਇੱਕ ਨੰਬਰ ਲਿਖੋ: ਤੁਹਾਡਾ connection budget। ਇਹ ਉਹ ਮੈਕਸਿਮਮ ਸੁਰੱਖਿਅਤ ਸੰਖਿਆ ਹੈ ਜੋ ਇਸ environment (dev, staging, prod) ਲਈ active Postgres connections ਦੀ ਹੋ ਸਕਦੀ ਹੈ, ਜਿਸ ਵਿੱਚ background jobs ਅਤੇ admin access ਵੀ ਸ਼ਾਮਲ ਹਨ। ਜੇ ਤੁਸੀਂ ਇਹ ਨੰਬਰ ਨਹੀਂ ਦੱਸ ਸਕਦੇ, ਤਾਂ ਤੁਸੀਂ ਅਟਕਲ ਲੈ ਰਹੇ ਹੋ।
ਇੱਕ ਤੁਰੰਤ ਚੈਕਲਿਸਟ:
MaxOpenConns) ਬਜਟ ਵਿੱਚ ਫਿੱਟ ਹੁੰਦਾ ਹੈ (ਜਾਂ PgBouncer cap)।max_connections ਅਤੇ ਕੋਈ reserved connections ਆਪਣੇ ਯੋਜਨਾ ਨਾਲ ਮਿਲਦੇ ਹਨ ਇਹ ਪੁਸ਼ਟੀ ਕਰੋ।ਰੋਲਆਉਟ ਯੋਜਨਾ ਜੋ ਰੋਲਬੈਕ ਨੂੰ ਆਸਾਨ ਰੱਖਦੀ ਹੈ:
ਜੇ ਤੁਸੀਂ Go + PostgreSQL ਐਪ Koder.ai (koder.ai) 'ਤੇ ਬਣਾ ਰਹੇ ਹੋ ਜਾਂ ਹੋਸਟ ਕਰ ਰਹੇ ਹੋ, ਤਾਂ Planning Mode ਤੁਹਾਨੂੰ ਚੇਂਜ ਅਤੇ ਮਾਪਣ ਯੋਜਨਾ ਬਣਾਉਣ ਵਿੱਚ ਮਦਦ ਕਰ ਸਕਦਾ ਹੈ, ਅਤੇ snapshots ਅਤੇ rollback ਤੇਜ਼ੀ ਨਾਲ revert ਕਰਨ 'ਤੇ ਆਸਾਨੀ ਦਿੰਦੇ ਹਨ ਜੇ tail latency ਖਰਾਬ ਹੋ ਜਾਵੇ।
ਅਗਲਾ ਕਦਮ: ਅਗਲੇ ਟਰੈਫਿਕ ਜੰਪ ਤੋਂ ਪਹਿਲਾਂ ਇਕ ਮਾਪ ਜੋੜੋ। "ਐਪ ਵਿੱਚ ਕਨੈਕਸ਼ਨ ਦੀ ਉਡੀਕ ਵਿੱਚ ਲਗਿਆ ਸਮਾਂ" ਆਮ ਤੌਰ 'ਤੇ ਸਭ ਤੋਂ ਲਾਭਦਾਇਕ ਹੁੰਦਾ ਹੈ, ਕਿਉਂਕਿ ਇਹ ਉਪਭੋਗਤਿਆਂ ਨੂੰ ਮਹਿਸੂਸ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ ਪੁਲਿੰਗ ਦਬਾਅ ਦਿਖਾਉਂਦਾ ਹੈ।
A pool keeps a small set of PostgreSQL connections open and reuses them across requests. This avoids paying the setup cost (TCP/TLS, auth, backend process setup) over and over, which helps keep tail latency steady during bursts.
When the pool is saturated, requests wait inside your app for a free connection, and that wait time shows up as slow responses. This often looks like “random slowness” because averages can stay fine while p95/p99 jump during traffic bursts.
No, it mostly changes how the system behaves under load by reducing reconnect churn and controlling concurrency. If a query is slow because of scans, locks, or poor indexing, pooling can’t make it fast; it can only limit how many slow queries run at once.
App pooling manages connections per process, so each app instance has its own pool and its own limits. PgBouncer sits in front of Postgres and enforces a global connection budget across many clients, which is especially useful when you have many replicas or spiky traffic.
If you run a small number of instances and your total open connections stay comfortably under the database limit, tuning Go’s database/sql pool is usually enough. Add PgBouncer when many instances, autoscaling, or bursty traffic could push total connections beyond what Postgres can handle smoothly.
A good default is to set a total connection budget for the service, then divide it by the number of app instances and set MaxOpenConns slightly below that per instance. Start small, watch wait time and p95/p99, and only increase if you’re sure the database has headroom.
Transaction pooling is often a strong default for typical HTTP APIs because it lets many client connections share fewer server connections and stays stable during bursts. Use session pooling if your code relies on session state persisting across statements, such as temp tables, session settings, or prepared statements reused across requests.
Prepared statements, temp tables, advisory locks, and session-level settings can behave differently because a client may not get the same server connection next time. If you need those features, either keep everything within a single transaction per request or switch to session pooling to avoid confusing failures.
Watch p95/p99 latency alongside app pool wait time, because wait time often rises before users complain. On Postgres, track active connections, CPU, and locks; on PgBouncer, track client connections, server connections, and queue depth to see if you’re saturating your connection budget.
First, stop unlimited waiting by setting request deadlines and a DB statement timeout so one slow query can’t hold connections forever. Then add backpressure by limiting concurrency for DB-heavy endpoints or shedding load, and reduce connection churn by avoiding overly short connection lifetimes that cause reconnect storms.