14 ਜੁਲਾ 2025·8 ਮਿੰਟ
ਮੇਮੋਰੀ ਪ੍ਰਬੰਧਨ ਰਣਨੀਤੀਆਂ: ਭਾਸ਼ਾਵਾਂ ਵਿੱਚ ਪ੍ਰਦਰਸ਼ਨ ਬਨਾਮ ਸੁਰੱਖਿਆ
ਜਾਣੋ ਕਿ ਗਾਰਬੇਜ਼ ਕਲੈਕਸ਼ਨ, ਮਲਕੀਅਤ ਅਤੇ ਰੈਫਰੰਸ ਕਾਊਂਟਿੰਗ ਤੇਜ਼ੀ, ਲੇਟੈਂਸੀ ਅਤੇ ਸੁਰੱਖਿਆ ਨੂੰ ਕਿਵੇਂ ਪ੍ਰਭਾਵਿਤ ਕਰਦੇ ਹਨ—ਅਤੇ ਕਿਵੇਂ ਉਹ ਭਾਸ਼ਾ ਚੁਣੋ ਜੋ ਤੁਹਾਡੇ ਟੀਚਿਆਂ ਨਾਲ ਮੇਲ ਖਾਂਦੀ ਹੋਵੇ।
ਜਾਣੋ ਕਿ ਗਾਰਬੇਜ਼ ਕਲੈਕਸ਼ਨ, ਮਲਕੀਅਤ ਅਤੇ ਰੈਫਰੰਸ ਕਾਊਂਟਿੰਗ ਤੇਜ਼ੀ, ਲੇਟੈਂਸੀ ਅਤੇ ਸੁਰੱਖਿਆ ਨੂੰ ਕਿਵੇਂ ਪ੍ਰਭਾਵਿਤ ਕਰਦੇ ਹਨ—ਅਤੇ ਕਿਵੇਂ ਉਹ ਭਾਸ਼ਾ ਚੁਣੋ ਜੋ ਤੁਹਾਡੇ ਟੀਚਿਆਂ ਨਾਲ ਮੇਲ ਖਾਂਦੀ ਹੋਵੇ।
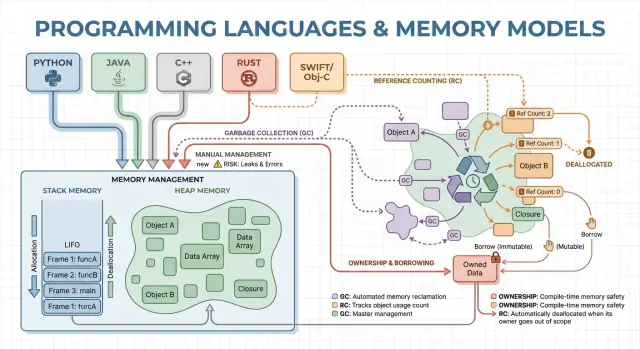
ਮੈਮੋਰੀ ਪ੍ਰਬੰਧਨ ਉਹ ਨਿਯਮ ਅਤੇ ਮਕੈਨਿਜ਼ਮ ਹਨ ਜੋ ਇੱਕ ਪ੍ਰੋਗਰਾਮ ਮੈਮੋਰੀ ਮੰਗਣ, ਵਰਤਣ ਅਤੇ ਵਾਪਸ ਕਰਨ ਲਈ ਵਰਤਦਾ ਹੈ। ਹਰ ਚੱਲ ਰਹੇ ਪ੍ਰੋਗਰਾਮ ਨੂੰ ਵੇਰੀਏਬਲਜ਼, ਯੂਜ਼ਰ ਡੇਟਾ, ਨੈੱਟਵਰਕ ਬਫਰ, ਇਮੇਜ਼ ਅਤੇ ਬੀਚਲੇ ਨਤੀਜੇ ਵਰਗੀਆਂ ਚੀਜ਼ਾਂ ਲਈ ਮੈਮੋਰੀ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ। ਕਿਉਂਕਿ ਮੈਮੋਰੀ ਸੀਮਿਤ ਹੈ ਅਤੇ ਓਐਸ ਅਤੇ ਹੋਰ ਐਪਲੀਕੇਸ਼ਨਾਂ ਨਾਲ ਸਾਂਝੀ ਹੁੰਦੀ ਹੈ, ਭਾਸ਼ਾਵਾਂ ਨੂੰ ਇਹ ਫੈਸਲਾ ਕਰਨਾ ਪੈਂਦਾ ਹੈ ਕਿ ਕੌਣ ਮੈਮੋਰੀ ਨੂੰ ਫ੍ਰੀ ਕਰੇਗਾ ਅਤੇ ਕਦੋਂ।
ਇਹ ਫੈਸਲੇ ਦੋ ਨਤੀਜਿਆਂ ਨੂੰ ਸ਼ੇਪ ਕਰਦੇ ਹਨ ਜਿਨ੍ਹਾਂ ਦੀ ਜ਼ਿਆਦਾ ਲੋਕ ਪਰਵਾ ਕਰਦੇ ਹਨ: ਇੱਕ ਪ੍ਰੋਗਰਾਮ ਕਿੰਨਾ ਤੇਜ਼ ਮਹਿਸੂਸ ਹੁੰਦਾ ਹੈ, ਅਤੇ ਇਹ ਦਬਾਅ ਹੇਠ ਕਿੰਨਾ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਵਰਤਦਾ ਹੈ।
ਪ੍ਰਦਰਸ਼ਨ ਇੱਕ ਇਕੱਲਾ ਨੰਬਰ ਨਹੀਂ ਹੁੰਦਾ। ਮੈਮੋਰੀ ਪ੍ਰਬੰਧਨ ਇਹਨਾਂ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰ ਸਕਦਾ ਹੈ:
ਜੋ ਭਾਸ਼ਾ ਤੇਜ਼ੀ ਨਾਲ allocate ਕਰਦੀ ਹੈ ਪਰ ਕਦੇ-ਕਦੇ ਸਾਫ਼-ਸਫਾਈ ਲਈ ਰੁਕਦੀ ਹੈ ਉਹ ਬੈਂਚਮਾਰਕ 'ਚ ਵਧੀਆ ਲੱਗ ਸਕਦੀ ਹੈ ਪਰ ਇੰਟਰੈਕਟਿਵ ਐਪਾਂ ਵਿੱਚ ਜਿੱਟਰੀ ਮਹਿਸੂਸ ਹੋ ਸਕਦੀ ਹੈ। ਦੂਜਾ ਮਾਡਲ ਜੋ ਰੁਕਾਵਟਾਂ ਤੋਂ ਬਚਦਾ ਹੈ ਉਹ ਲੀਕ ਅਤੇ ਲਾਈਫਟਾਈਮ ਦੀyaan ਗਲਤੀਆਂ ਰੋਕਣ ਲਈ ਹੋਰ ਧਿਆਨ ਦੀ ਲੋੜ ਰੱਖ ਸਕਦਾ ਹੈ।
ਸੁਰੱਖਿਆ ਉਹ ਹੈ ਜੋ ਮੈਮੋਰੀ-ਸਬੰਧੀ ਫੇਲ੍ਹਰਾਂ ਨੂੰ ਰੋਕਦਾ ਹੈ, ਜਿਵੇਂ:
ਕਈ ਪ੍ਰਮੁੱਖ ਸੁਰੱਖਿਆ ਮੁੱਦੇ ਮੈਮੋਰੀ ਗਲਤੀਆਂ ਜਿਵੇਂ use-after-free ਜਾਂ buffer overflows ਵੱਲੋਂ ਉਤਪੰਨ ਹੁੰਦੇ ਹਨ।
ਇਹ ਗਾਈਡ ਪ੍ਰਸਿੱਧ ਭਾਸ਼ਾਵਾਂ ਵਿੱਚ ਵਰਤੇ ਜਾਣ ਵਾਲੇ ਮੁੱਖ ਮੈਮੋਰੀ ਮਾਡਲਾਂ ਦੀ ਗੈਰ-ਤਕਨੀਕੀ ਸੈਰ ਹੈ, ਉਹ ਕੀOptimize ਕਰਦੇ ਹਨ, ਅਤੇ ਤੁਹਾਡੇ ਚੁਣਾਅ ਨਾਲ ਤੁਸੀਂ ਕਿੰਨੇ ਟਰੇਡਆਫ਼ ਸਵੀਕਾਰ ਰਹੇ ਹੋ।
ਮੈਮੋਰੀ ਉਹ ਜਗ੍ਹਾ ਹੈ ਜਿੱਥੇ ਤੁਹਾਡਾ ਪ੍ਰੋਗਰਾਮ ਰਨ ਹੋਣ ਦੌਰਾਨ ਡੇਟਾ ਰੱਖਦਾ ਹੈ। ਜ਼ਿਆਦातर ਭਾਸ਼ਾਵਾਂ ਇਹ ਨੂੰ ਦੋ ਮੁੱਖ ਖੇਤਰਾਂ 'ਚ ਵੰਡਦੀਆਂ ਹਨ: ਸਟੈਕ ਅਤੇ ਹੀਪ।
ਸਟੈਕ ਨੂੰ ਇੱਕ ਸੁਤੰਤਰਣ ਨੋਟ ਪੈਡ ਦੀ ਤਰ੍ਹਾਂ ਸੋਚੋ ਜੋ ਮੌਜੂਦਾ ਟਾਸਕ ਲਈ ਵਰਤਿਆ ਜਾਂਦਾ ਹੈ। ਜਦੋਂ ਇੱਕ ਫੰਕਸ਼ਨ ਸ਼ੁਰੂ ਹੁੰਦਾ ਹੈ, ਉਹ ਸਟੈਕ ਤੇ ਇੱਕ ਛੋਟੀ “ਫਰੇਮ” ਪ੍ਰਾਪਤ ਕਰਦਾ ਹੈ ਆਪਣੀਆਂ ਲੋਕਲ ਵੈਰੀਏਬਲ ਲਈ। ਜਦੋਂ ਫੰਕਸ਼ਨ ਖਤਮ ਹੁੰਦਾ ਹੈ, ਉਹ ਫਰੇਮ ਇਕੱਠੇ ਹਟ ਜਾਦਾ ਹੈ।
ਇਹ ਤੇਜ਼ ਅਤੇ ਪੂਰਵ-ਨਿਰਧਾਰਿਤ ਹੈ—ਪਰ ਇਹ ਸਿਰਫ਼ ਉਹਨਾਂ ਵੈਲਯੂਜ਼ ਲਈ ਕੰਮ ਕਰਦਾ ਹੈ ਜਿਨ੍ਹਾਂ ਦਾ ਆਕਾਰ ਪਤਾ ਹੈ ਅਤੇ ਜਿਨ੍ਹਾਂ ਦੀ ਲਾਈਫਟਾਈਮ ਫੰਕਸ਼ਨ ਕਾਲ ਦੇ ਨਾਲ ਖ਼ਤਮ ਹੁੰਦੀ ਹੈ।
ਹੀਪ ਇਕ ਸਟੋਰੇਜ ਰੂਮ ਵਾਂਗ ਹੈ ਜਿੱਥੇ ਤੁਸੀਂ ਆਇਟਮ ਜਿੰਨਾ ਸਮਾਂ ਚਾਹੁੰਦੇ ਰੱਖ ਸਕਦੇ ਹੋ। ਇਹ ਡਾਇਨਾਮਿਕ ਸਾਈਜ਼ ਵਾਲੀਆਂ ਲਿਸਟਾਂ, ਸਟਰਿੰਗਾਂ ਜਾਂ ਅਜਿਹੇ ਆਬਜੈਕਟਾਂ ਲਈ ਵਧੀਆ ਹੈ ਜੋ ਪ੍ਰੋਗਰਾਮ ਦੇ ਵੱਖ-ਵੱਖ ਹਿੱਸਿਆਂ ਵਿੱਚ ਸਾਂਝੇ ਹੋ ਸਕਦੇ ਹਨ।
ਕਿਉਂਕਿ ਹੀਪ ਆਬਜੈਕਟ ਇਕ ਫੰਕਸ਼ਨ ਤੋਂ ਬਾਹਰ ਜੀ ਸਕਦੇ ਹਨ, ਮੁੱਖ ਸਵਾਲ ਬਣ ਜਾਂਦਾ ਹੈ: ਕੌਣ ਉਹਨਾਂ ਨੂੰ ਫ੍ਰੀ ਕਰਨ ਦੀ ਜ਼ਿੰਮੇਵਾਰੀ ਲੈਂਦਾ ਹੈ, ਅਤੇ ਕਦੋਂ?
ਇੱਕ ਪੌਇੰਟਰ ਜਾਂ ਰੇਫਰੰਸ ਆਬਜੈਕਟ ਨੂੰ ਅਪਰੋਕਸੀਟਰ ਤਰੀਕੇ ਨਾਲ ਪਹੁੰਚ ਕਰਨ ਦਾ ਤਰੀਕਾ ਹੈ—ਜਿਵੇਂ ਸਟੋਰੇਜ ਰੂਮ ਵਿੱਚ ਬਕਸੇ ਲਈ ਸ਼ੈਲਫ਼ ਨੰਬਰ। ਜੇ ਬਕਸਾ ਸੁੱਟ ਦਿੱਤਾ ਗਿਆ ਪਰ ਤੁਹਾਡੇ ਕੋਲ ਸ਼ੈਲਫ਼ ਨੰਬਰ ਹਜੇ ਵੀ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਗਾਰਬੇਜ ਡੇਟਾ ਪੜ੍ਹ ਸਕਦੇ ਹੋ ਜਾਂ ਪ੍ਰੋਗਰਾਮ ਕ੍ਰੈਸ਼ ਹੋ ਸਕਦਾ ਹੈ (ਇਹ ਇੱਕ ਆਮ use-after-free ਬੱਗ ਹੈ)।
ਕਲਪਨਾ ਕਰੋ ਇੱਕ ਲੂਪ ਹੈ ਜੋ ਗਾਹਕ ਰਿਕਾਰਡ ਬਣਾਉਂਦਾ, ਇੱਕ ਸੁਨੇਹਾ ਫਾਰਮੈਟ ਕਰਦਾ ਅਤੇ ਉਸਨੂੰ ਫੈਂਕ ਦਿੰਦਾ:
ਕੁਝ ਭਾਸ਼ਾਵਾਂ ਇਹ ਵੇਰਵਿਆਂ ਨੂੰ ਛੁਪਾਉਂਦੀਆਂ ਹਨ (ਆਟੋਮੈਟਿਕ ਕਲੀਨਅਪ), ਜਦਕਿ ਹੋਰ ਇਹਨਾਂ ਨੂੰ ਖੁਲ੍ਹਾ ਛੱਡਦੀਆਂ ਹਨ (ਤੁਸੀਂ ਸਪਸ਼ਟ ਤੌਰ 'ਤੇ ਮੈਮੋਰੀ ਫ੍ਰੀ ਕਰਦੇ ਹੋ, ਜਾਂ ਤੁਹਾਨੂੰ ਕਿਸੇ ਨਿਯਮ ਦੇ ਅਨੁਸਾਰ ਮਲਕੀਅਤ ਫੋਲੋ ਕਰਨੀ ਪੈਂਦੀ ਹੈ)। ਅੱਗੇ ਦੇ ਹਿੱਸੇ ਇਸ ਗੱਲ ਨੂੰ ਖੋਜਦੇ ਹਨ ਕਿ ਉਹ ਚੋਣਾਂ ਤੇਜ਼ੀ, ਰੁਕਾਵਟਾਂ ਅਤੇ ਸੁਰੱਖਿਆ 'ਤੇ ਕਿਵੇਂ ਪ੍ਰਭਾਵ ਪਾਉਂਦੀਆਂ ਹਨ।
ਮੈਨੂਅਲ ਮੈਮੋਰੀ ਪ੍ਰਬੰਧਨ ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਪ੍ਰੋਗਰਾਮ (ਅਤੇ ਇਸ ਤਰ੍ਹਾਂ ਡੇਵਲਪਰ) ਸਪਸ਼ਟ ਤੌਰ 'ਤੇ ਮੈਮੋਰੀ ਮੰਗਦਾ ਹੈ ਅਤੇ ਬਾਅਦ ਵਿੱਚ ਉਸਨੂੰ ਰਿਲੀਜ਼ ਕਰਦਾ ਹੈ। ਅਮਲੀ ਤੌਰ 'ਤੇ ਇਹ C ਵਿੱਚ malloc/free ਜਾਂ C++ ਵਿੱਚ new/delete ਵਰਗਿਆਂ ਵਾਂਗ ਦਿੱਸਦਾ ਹੈ। ਇਹ ਸਿਸਟਮ ਪ੍ਰੋਗਰਾਮਿੰਗ ਵਿੱਚ ਅਜੇ ਵੀ ਆਮ ਹੈ ਜਿੱਥੇ ਤੁਹਾਨੂੰ ਇਹ ਜਾਣਣਾ ਹੋਵੇ ਕਿ ਕਦੋਂ ਮੈਮੋਰੀ ਪ੍ਰਾਪਤ ਅਤੇ ਵਾਪਸ ਕੀਤੀ ਜਾਂਦੀ ਹੈ।
ਤੁਸੀਂ ਆਮ ਤੌਰ 'ਤੇ ਮੈਮੋਰੀ allocate ਕਰਦੇ ਹੋ ਜਦੋਂ:
ਜਦੋਂ ਬੈਕਗ੍ਰਾਊਂਡ ਵਿੱਚ ਕੋਈ GC ਚੱਲਦਾ ਨਹੀਂ, ਤਾਂ ਅਚਾਨਕ ਪੌਜ਼ ਘੱਟ ਹੁੰਦੀਆਂ ਹਨ। ਐਲੋਕੇਸ਼ਨ ਅਤੇ ਡੀਅਲੋਕੇਸ਼ਨ ਬਹੁਤ ਨਿਰਧਾਰਿਤ ਬਣਾਏ ਜਾ ਸਕਦੇ ਹਨ, ਖ਼ਾਸ ਕਰਕੇ ਜਦੋਂ ਇਹ کسਟਮ allocators, ਪੂਲ ਜਾਂ fixed-size ਬਫਰਾਂ ਨਾਲ ਜੋੜੇ ਹੋਣ।
ਮੈਨੂਅਲ ਕੰਟਰੋਲ ਨਾਲ ਓਵਰਹੈਡ ਵੀ ਘੱਟ ਹੋ ਸਕਦਾ ਹੈ: ਕੋਈ tracing phase ਨਹੀਂ, ਕੋਈ write barriers ਨਹੀਂ, ਅਤੇ ਆਮ ਤੌਰ 'ਤੇ ਪਰ-ਆਬਜੈਕਟ metadata ਵੀ ਘੱਟ। ਜੇ ਕੋਡ ਸੰਭਾਲ ਕੇ ਲਿਖਿਆ ਗਿਆ ਹੋਵੇ, ਤਾਂ ਤੁਸੀਂ ਕਠੋਰ latency ਟੀਚੇ ਪਾ ਸਕਦੇ ਹੋ ਅਤੇ ਮੈਮੋਰੀ ਵਰਤੋਂ ਨੂੰ ਘੱਟ ਰੱਖ ਸਕਦੇ ਹੋ।
ਟਰੇਡਆਫ਼ ਇਹ ਹੈ ਕਿ ਰਨਟਾਈਮ ਉਸ ਸਮੇਂ ਗਲਤੀਆਂ ਨਹੀਂ ਰੋਕੇਗਾ:
ਇਹ ਬੱਗ ਕ੍ਰੈਸ਼, ਡੇਟਾ ਖਰਾਬੀ ਅਤੇ ਸੁਰੱਖਿਆ ਦੀਆਂ ਸਮੱਸਿਆਵਾਂ ਪੈਦਾ ਕਰ ਸਕਦੇ ਹਨ।
ਟੀਮਾਂ ਖ਼ਤਰੇ ਘਟਾਉਂਦੀਆਂ ਹਨ ਇਹਨਾਂ ਤਰੀਕਿਆਂ ਨਾਲ:
std::unique_ptr) ਦੇ ਨਾਲ ownership encode ਕਰਨਾਮੈਨੂਅਲ ਮੈਮੋਰੀ ਪ੍ਰਬੰਧਨ ਅਕਸਰ embedded ਸੋਫਟਵੇਅਰ, real-time ਸਿਸਟਮ, OS ਕੰਪੋਨੈਂਟ ਅਤੇ ਪ੍ਰਦਰਸ਼ਨ-ਮਹੱਤਵਪੂਰਨ ਲਾਇਬ੍ਰੇਰੀਜ਼ ਲਈ ਵਧੀਆ ਚੋਣ ਹੁੰਦੀ ਹੈ—ਜਿੱਥੇ ਕਠੋਰ ਕੰਟਰੋਲ ਅਤੇ ਨਿਰਧਾਰਿਤ ਲੇਟੈਂਸੀ ਡਿਵੈਲਪਰ ਦੀ ਸਹੂਲਤ ਨਾਲੋਂ ਵੱਧ ਮਹੱਤਵ ਰੱਖਦੇ ਹਨ।
ਗਾਰਬੇਜ਼ ਕਲੈਕਸ਼ਨ (GC) ਆਟੋਮੈਟਿਕ ਮੈਮੋਰੀ ਕਲੀਨਅਪ ਹੈ: ਤੁਹਾਨੂੰ ਖੁਦ free ਕਰਨ ਦੀ ਲੋੜ ਨਹੀਂ ਪੈਂਦੀ; ਰਨਟਾਈਮ ਆਬਜੈਕਟਾਂ ਨੂੰ ਟਰੈਕ ਕਰਦਾ ਹੈ ਅਤੇ ਉਹਨਾਂ ਨੂੰ ਰੀਕਲੇਮ ਕਰਦਾ ਹੈ ਜੋ ਹੁਣ ਪਹੁੰਚ ਯੋਗ ਨਹੀਂ ਰਹਿੰਦੇ। ਇਸਦਾ ਮਤਲਬ ਇਹ ਹੈ ਕਿ ਤੁਸੀਂ ਵ਼ਰਤਾਰਤੇ ਅਤੇ ਡੇਟਾ ਫਲੋ 'ਤੇ ਧਿਆਨ ਰੱਖ ਸਕਦੇ ਹੋ ਜਦਕਿ ਸਿਸਟਮ ਜ਼ਿਆਦਾਤਰ ਐਲੋਕੇਸ਼ਨ ਅਤੇ ਡੀਐਲੋਕੇਸ਼ਨ ਫੈਸਲਿਆਂ ਨੂੰ ਸੰਭਾਲਦਾ ਹੈ।
ਜ਼ਿਆਦਾਤਰ ਕਲੈਕਟਰ ਪਹਿਲਾਂ ਜਿਂਦੇ ਆਬਜੈਕਟਾਂ ਨੂੰ ਪਛਾਣਦੇ ਹਨ, ਫਿਰ ਬਾਕੀ ਨੂੰ ਰੀਕਲੇਮ ਕਰਦੇ ਹਨ।
Tracing GC ਰੂਟਸ (ਜਿਵੇਂ ਸਟੈਕ ਵੇਰੀਏਬਲ, ਗਲੋਬਲ ਰੈਫਰੰਸ, ਰਜਿਸਟਰ) ਤੋਂ ਸ਼ੁਰੂ ਕਰਦਾ ਹੈ, ਰੈਫਰੰਸਾਂ ਨੂੰ ਫਾਲੋ ਕਰਦਾ ਹੈ ਤਾਂ ਜੋ ਹਰ ਇੱਕ ਪਹੁੰਚਯੋਗ ਆਬਜੈਕਟ ਨੂੰ ਮਾਰਕ ਕਰ ਸਕੇ, ਅਤੇ ਫਿਰ ਹੀਪ ਨੂੰ ਸਕੈਨ ਕਰਕੇ ਨਾਨ-ਮਾਰਕਡ ਆਬਜੈਕਟਾਂ ਨੂੰ ਫ੍ਰੀ ਕਰਦਾ ਹੈ।
Generational GC ਇਸ ਨਜ਼ਰਿਏ 'ਤੇ ਅਧਾਰਿਤ ਹੈ ਕਿ ਜ਼ਿਆਦਾਤਰ ਆਬਜੈਕਟ ਛੋਟੇ ਸਮੇਂ ਵਿੱਚ ਮਰ ਜਾਂਦੇ ਹਨ। ਇਹ ਹੀਪ ਨੂੰ ਜਨਰੇਸ਼ਨਾਂ ਵਿੱਚ ਵੰਡਦਾ ਹੈ ਅਤੇ ਨੌਜ-ਏਰੀਆ ਨੂੰ ਜ਼ਿਆਦਾ ਫ਼ਰੀਕਵੈਂਸੀ ਨਾਲ ਕਲੈਕਟ ਕਰਦਾ ਹੈ, ਜੋ ਆਮ ਤੌਰ 'ਤੇ ਸਸਤਾ ਹੁੰਦਾ ਹੈ ਅਤੇ ਕੁੱਲ ਕੁਸ਼ਲਤਾ ਵਿੱਚ ਸੁਧਾਰ ਲਿਆਉਂਦਾ ਹੈ।
Concurrent GC ਕਲੈਕਸ਼ਨ ਦੇ ਹਿੱਸਿਆਂ ਨੂੰ ਐਪਲੀਕੇਸ਼ਨ ਥ੍ਰੈੱਡਸ ਦੇ ਨਾਲ ਚਲਾਉਂਦਾ ਹੈ, ਲੰਬੀਆਂ ਰੁਕਾਵਟਾਂ ਨੂੰ ਘਟਾਉਣ ਲਈ। ਇਹ ਮੈਮੋਰੀ ਦਿਖਾਈ ਦੇਣ ਵਾਲੀ ਸਥਿਤੀ ਨੂੰ ਕੰਸਿਸਟੈਂਟ ਰੱਖਣ ਲਈ ਹੋਰ ਬੁੱਕੀਪਿੰਗ ਕਰ ਸਕਦਾ ਹੈ।
GC ਆਮ ਤੌਰ 'ਤੇ ਮੈਨੂਅਲ ਕੰਟਰੋਲ ਦੀ ਬਦਲੀ ਵਿੱਚ ਰੰਟਾਈਮ ਕੰਮ ਲੈਂਦਾ ਹੈ। ਕੁਝ ਸਿਸਟਮ steady throughput ਨੂੰ ਤਰਜੀਹ ਦਿੰਦੇ ਹਨ ਪਰ stop-the-world ਰੁਕਾਵਟਾਂ ਹੋ ਸਕਦੀਆਂ ਹਨ। ਹੋਰ ਮੇਥਡ ਪਾਉਂਦੀਆਂ ਰੁਕਾਵਟਾਂ ਘਟਾਉਂਦੇ ਹਨ ਪਰ ਆਮ ਚੱਲਦਿਆਂ ਵਧੇਰਾ ਓਵਰਹੈਡ ਜੋੜ ਸਕਦੇ ਹਨ।
GC ਇੱਕ ਪੂਰੀ ਕਲਾਸ ਦੀ ਲਾਈਫਟਾਈਮ ਬੱਗਜ਼ (ਖਾਸ ਕਰਕੇ use-after-free) ਹਟਾ ਦਿੰਦਾ ਹੈ ਕਿਉਂਕਿ ਜਦ ਤੱਕ ਕੋਈ ਆਬਜੈਕਟ ਪਹੁੰਚਯੋਗ ਹੈ ਉਹ ਰੀਕਲੇਮ ਨਹੀਂ ਹੁੰਦਾ। ਇਸ ਨਾਲ ਗੁੰਝਲਦਾਰ ਵੱਡੇ ਕੋਡਬੇਸਾਂ ਵਿੱਚ ਓਨਰਸ਼ਿਪ ਟਰੈਕ ਕਰਨ ਦੀ ਲੋੜ ਘਟਦੀ ਹੈ ਅਤੇ iteration ਤੇਜ਼ ਹੁੰਦੀ ਹੈ।
GC ਰੰਟਾਈਮ JVM (Java, Kotlin), .NET (C#, F#), Go, ਅਤੇ ਬ੍ਰਾਊਜ਼ਰ ਅਤੇ Node.js ਵਿੱਚ JavaScript ਇੰਜਣਾਂ ਵਿੱਚ ਆਮ ਹਨ।
ਰੈਫਰੰਸ ਕਾਊਂਟਿੰਗ ਵਿੱਚ ਹਰ ਆਬਜੈਕਟ ਟਰੈਕ ਕਰਦਾ ਹੈ ਕਿ ਕਿੰਨੀ “ਮਲਕੀਨ” (ਰੇਫਰੰਸ) ਉਸ ਵੱਲ ਹਨ। ਜਦੋਂ ਕਾਊਂਟ ਜ਼ੀਰੋ ਹੋ ਜਾਂਦੀ ਹੈ, ਆਬਜੈਕਟ ਤੁਰੰਤ ਫ੍ਰੀ ਹੋ ਜਾਂਦਾ ਹੈ। ਇਹ ਤੁਰੰਤਤਾ ਸੰਵੇਦਨਸ਼ੀਲ ਹੁੰਦੀ ਹੈ: ਜਿਵੇਂ ਹੀ ਕੁਝ ਵੀ ਆਬਜੈਕਟ ਤੱਕ ਪਹੁੰਚ ਨਹੀਂ ਰਹਿੰਦੀ, ਉਸ ਦੀ ਮੈਮੋਰੀ ਰੀਕਲੇਮ ਹੋ ਜਾਂਦੀ ਹੈ।
ਜਦੋਂ ਤੁਸੀਂ ਕਿਸੇ ਆਬਜੈਕਟ ਨੂੰ ਕਾਪੀ ਕਰਦੇ ਹੋ ਜਾਂ ਕਿਸੇ ਵੇਰੀਏਬਲ ਵਿੱਚ ਸਟੋਰ ਕਰਦੇ ਹੋ, ਰਨਟਾਈਮ ਉਸਦੀ ਗਿਣਤੀ ਵਧਾ ਦਿੰਦਾ ਹੈ; ਜਦੋਂ ਰੀਫਰੰਸ ਨਾ ਰਹੇ ਤਾਂ ਘਟਾ ਦਿੰਦਾ ਹੈ। ਜਦੋਂ ਗਿਣਤੀ ਜ਼ੀਰੋ 'ਤੇ ਪਹੁੰਚਦੀ ਹੈ, ਸਾਫ਼-ਸਫਾਈ ਤੁਰੰਤ ਹੋ ਜਾਂਦੀ ਹੈ।
ਇਸ ਨਾਲ ਸਰੋਤ ਪ੍ਰਬੰਧਨ ਆਸਾਨ ਹੁੰਦਾ ਹੈ: ਆਬਜੈਕਟ ਆਮ ਤੌਰ 'ਤੇ ਉਸ ਸਮੇਂ ਹੀ ਰਿਲੀਜ਼ ਹੁੰਦੇ ਹਨ ਜਦ ਤੁਸੀਂ ਉਨ੍ਹਾਂ ਨੂੰ ਵਰਤਨਾ ਬੰਦ ਕਰਦੇ ਹੋ, ਜਿਸ ਨਾਲ ਪੀਕ ਮੈਮੋਰੀ ਵਰਤੋਂ ਘਟ ਸਕਦੀ ਹੈ ਅਤੇ ਦੇਰੀ ਨਾਲ ਰੀਕਲੇਮ ਨਹੀਂ ਹੁੰਦੀ।
ਰੈਫਰੰਸ ਕਾਊਂਟਿੰਗ ਅਕਸਰ ਸਥਿਰ, ਲਗਾਤਾਰ ਓਵਰਹੈਡ ਰੱਖਦੀ ਹੈ: increment/decrement ਚਾਲਾਂ ਤੇ ਅਤੇ ਫੰਕਸ਼ਨ ਕਾਲਾਂ 'ਤੇ ਹੁੰਦੇ ਹਨ। ਇਹ ਓਵਰਹੈਡ ਛੋਟਾ ਹੁੰਦਾ ਹੈ ਪਰ ਹਰ ਜਗ੍ਹਾ ਹੋਂਦਾ ਹੈ।
ਫਾਇਦਾ ਇਹ ਹੈ ਕਿ ਤੁਸੀਂ ਆਮ ਤੌਰ 'ਤੇ ਵੱਡੀਆਂ stop-the-world ਪੌਜ਼ ਨੀਂਹ ਪਾਉਂਦੇ। ਲੇਟੈਂਸੀ ਆਮ ਤੌਰ 'ਤੇ ਸਹੀ ਰਹਿੰਦੀ ਹੈ, ਹਾਲਾਂਕਿ ਜਦੋਂ ਵੱਡੇ ਆਬਜੈਕਟ ਗ੍ਰਾਫ ਇੱਕਠੇ ਤੌਰ 'ਤੇ ਆਪਣਾ ਆਖਰੀ ਮਲਕੀਨ ਗੁਆ ਦੇਂਦੇ ਹਨ ਤਦ ਡੀਅਲੋਕੇਸ਼ਨ ਦੇ ਕਸਰੇ ਹੋ ਸਕਦੇ ਹਨ।
ਰੈਫਰੰਸ ਕਾਊਂਟਿੰਗ ਉਹਨਾਂ ਆਬਜੈਕਟਾਂ ਨੂੰ ਜੋ ਸਾਈਕਲ ਵਿੱਚ ਹਨ ਰੀਕਲੇਮ ਨਹੀਂ ਕਰ ਸਕਦੀ। ਜੇ A B ਨੂੰ ਰੈਫਰ ਕਰਦਾ ਹੈ ਅਤੇ B A ਨੂੰ, ਦੋਹਾਂ ਦੀ ਗਿਣਤੀ ਨਜ਼ਰ ਵਿੱਚ ਉੱਚੀ ਰਹਿੰਦੀ ਹੈ ਭਾਵੇਂ ਕਿਹੜਾ ਹੋਰ ਕੁਝ ਵੀ ਉਹਨਾਂ ਤਕ ਪਹੁੰਚਯੋਗ ਨਾ ਹੋਵੇ—ਇਸ ਨਾਲ ਮੈਮੋਰੀ ਲੀਕ ਬਣਦੀ ਹੈ।
ਇਕੋਸਿਸਟਮ ਇਸਨੂੰ ਕੁਝ ਤਰੀਕਿਆਂ ਨਾਲ ਹੱਲ ਕਰਦੇ ਹਨ:
ਮਲਕੀਅਤ ਅਤੇ ਬੋਰੋਅਿੰਗ ਦਾ ਮਾਡਲ ਸਭ ਤੋਂ ਵਧੋਂ Rust ਨਾਲ ਜੋੜਿਆ ਜਾਂਦਾ ਹੈ। ਵਿਚਾਰ ਸਧਾਰਨ ਹੈ: ਕੰਪਾਇਲਰ ਅਜਿਹੇ ਨਿਯਮ ਲਗਾਂਦਾ ਹੈ ਜੋ dangling pointers, double-frees ਅਤੇ ਬਹੁਤ ਸਾਰੇ ਡੇਟਾ-ਰੇਸ ਨੂੰ ਬਣਨ ਤੋਂ ਰੋਕਦੇ ਹਨ—ਬਿਨਾਂ ਰਨਟਾਈਮ GC 'ਤੇ ਨਿਰਭਰ ਹੋਏ।
ਹਰ value ਦਾ ਇੱਕ-ਠੀਕ ਇੱਕ "owner" ਹੁੰਦਾ ਹੈ। ਜਦੋਂ owner ਸਕੋਪ ਤੋਂ ਬਾਹਰ ਜਾਂਦਾ ਹੈ, value ਤੁਰੰਤ ਅਤੇ ਨਿਰਧਾਰਿਤ ਤੌਰ 'ਤੇ ਸਾਫ ਹੋ ਜਾਂਦਾ ਹੈ। ਇਸ ਨਾਲ ਤੁਸੀਂ ਮੈਮੋਰੀ, ਫਾਈਲ ਹੈਂਡਲ, ਸਾਕੇਟ ਆਦਿ ਲਈ deterministic resource management ਪਾਉਂਦੇ ਹੋ—ਮੈਨੂਅਲ ਕਲੀਨਅਪ ਵਰਗਾ ਪਰ ਘੱਟ ਗਲਤੀਆਂ ਦੀ ਸੰਭਾਵਨਾ।
Ownership move ਵੀ ਹੋ ਸਕਦੀ ਹੈ: ਕਿਸੇ ਵੈਰੀਏਬਲ ਨੂੰ ਨਵੇਂ ਸਥਾਨ 'ਤੇ ਅਸਾਈਨ ਕਰਨ ਜਾਂ ਫੰਕਸ਼ਨ ਵਿੱਚ ਪਾਸ ਕਰਨ ਨਾਲ ਜ਼ਿੰਮੇਵਾਰੀ ਟ੍ਰਾਂਸਫਰ ਹੋ ਸਕਦੀ ਹੈ। ਮੂਵ ਤੋਂ ਬਾਅਦ ਪੁਰਾਣਾ ਬਾਈਂਡਿੰਗ ਵਰਤ ਨਹੀਂ ਕੀਤਾ ਜਾ ਸਕਦਾ, ਜਿਸ ਨਾਲ use-after-free ਕੁਦਰਤੀ ਤਰੀਕੇ ਨਾਲ ਰੋਕਿਆ ਜਾਂਦਾ ਹੈ।
ਬੋਰੋਅਿੰਗ ਤੁਹਾਨੂੰ ਕਿਸੇ value ਨੂੰ ਵਰਤਣ ਦਿੰਦਾ ਹੈ ਬਿਨਾਂ ਮਲਕੀਅਤ ਲੈਣ ਦੇ।
Shared borrow ਪੜ੍ਹਨ ਲਈ ਸਾਂਝੀ ਪਹੁੰਚ ਦਿੰਦਾ ਹੈ ਅਤੇ ਆਸਾਨੀ ਨਾਲ ਕਾਪੀ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ।
Mutable borrow ਅਪਡੇਟ ਕਰਨ ਦੀ اجازت ਦਿੰਦਾ ਹੈ, ਪਰ ਇਹ ਵਿਲੱਖਣ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ: ਜਦੋਂ ਇਹ ਮੌਜੂਦ ਹੁੰਦਾ ਹੈ, ਹੋਰ ਕੋਈ ਵੀ ਉਹੀ value ਨਾ ਪੜ੍ਹ ਸਕੇ ਨਾ ਲਿਖ ਸਕੇ। ਇਹ "ਇੱਕ ਲਿਖਾਉਣ ਵਾਲਾ ਜਾਂ ਬਹੁਤ ਸਾਹਿਤਕ ਪੜ੍ਹਨ ਵਾਲੇ" ਨਿਯਮ ਕੰਪਾਇਲ-ਟਾਈਮ ਤੇ ਚੈੱਕ ਹੁੰਦਾ ਹੈ।
ਕਿਉਂਕਿ ਲਾਈਫਟਾਈਮ ਟ੍ਰੈਕ ਕੀਤੀਆਂ ਜਾਂਦੀਆਂ ਹਨ, ਕੰਪਾਇਲਰ ਉਹ ਕੋਡ reject ਕਰ ਸਕਦਾ ਹੈ ਜੋ ਰਿਲੀਫਰੰਸ ਡਾਟਾ ਤੋਂ ਬਾਹਰ ਰਹਿ ਜਾਵੇਗਾ, ਬਹੁਤ ਸਾਰੇ dangling-reference ਬੱਗਾਂ ਨੂੰ ਦੂਰ ਕਰਦਾ ਹੈ। ਇਹ ਨਿਯਮ concurrency ਵਿੱਚ ਵੀ ਕਈ race conditions ਨੂੰ ਰੋਕਦੇ ਹਨ।
ਟਰੇਡਆਫ਼ ਸਿੱਖਣ ਦੀ ਓਢ ਅਤੇ ਕੁਝ ਡਿਜ਼ਾਈਨ ਸੀਮਾਵਾਂ ਹਨ। ਤੁਹਾਨੂੰ ਡੇਟਾ ਫਲੋ ਨੂੰ ਮੁੜ-ਸੰਰਚਿਤ ਕਰਨਾ ਪੈ ਸਕਦਾ ਹੈ, ownership ਹੱਦਾਂ ਨੂੰ ਸਾਫ਼ ਕਰਨਾ ਪੈ ਸਕਦਾ ਹੈ, ਜਾਂ ਸਾਂਝੇ mutable state ਲਈ ਵਿਸ਼ੇਸ਼ ਕਿਸਮਾਂ ਦੀ ਲੋੜ ਹੋ ਸਕਦੀ ਹੈ।
ਇਹ ਮਾਡਲ ਸਿਸਟਮ ਕੋਡ—ਸੇਵਾ, ਐਂਬੇਡਡ, ਨੈੱਟਵਰਕਿੰਗ, ਅਤੇ ਪ੍ਰਦਰਸ਼ਨ-ਸੰਵੇਦਨਸ਼ੀਲ ਕੰਪੋਨੈਂਟ—ਲਈ ਮਜ਼ਬੂਤ ਫਿਟ ਹੈ, ਜਿੱਥੇ ਤੁਸੀਂ GC ਪੌਜ਼ ਬਿਨਾਂ ਨਿਰਧਾਰਿਤ ਕਲੀਨਅਪ ਅਤੇ ਘੱਟ ਲੇਟੈਂਸੀ ਚਾਹੁੰਦੇ ਹੋ।
ਜਦੋਂ ਤੁਸੀਂ ਬਹੁਤ ਸਾਰੇ ਛੋਟੇ-ਅਵਧੀ ਆਬਜੈਕਟ ਬਣਾਉਂਦੇ ਹੋ—ਜਿਵੇਂ parser ਵਿੱਚ AST ਨੋਡ, ਗੇਮ ਫ੍ਰੇਮ ਵਿੱਚ ਐਂਟੀਟੀਜ਼, ਜਾਂ ਵੈਬ ਰਿਕਵੈਸਟ ਦੌਰਾਨ ਅਸਥਾਈ ਡੇਟਾ—ਤਦ ਹਰ ਇੱਕ ਆਬਜੈਕਟ ਲਈ ਅਲੱਗ-ਅਲੱਗ allocate/ਫ੍ਰੀ ਦਾ ਓਵਰਹੈਡ ਰਨਟਾਈਮ 'ਤੇ ਪ੍ਰਭਾਵ ਪਾ ਸਕਦਾ ਹੈ। ਅਰੀਨਾ (regions) ਅਤੇ ਪੂਲ ਅਜਿਹੇ ਪੈਟਰਨ ਹਨ ਜੋ fine-grained frees ਨੂੰ ਛੱਡ ਕੇ ਤੇਜ਼ ਬਲਕ ਮੈਨੇਜਮੈਂਟ ਦਿੰਦੇ ਹਨ।
ਅਰੀਨਾ ਇੱਕ ਮੈਮੋਰੀ "ਜ਼ੋਨ" ਹੈ ਜਿੱਥੇ ਤੁਸੀਂ ਸਮੇਂ ਦੇ ਦੌਰਾਨ ਬਹੁਤ ਸਾਰੇ ਆਬਜੈਕਟ allocate ਕਰਦੇ ਹੋ, ਫਿਰ ਉਹ ਸਾਰੇ ਇਕੱਠੇ release ਕਰ ਦਿੰਦੇ ਹੋ ਜਦੋਂ ਅਰੀਨਾ ਨੂੰ ਡ੍ਰਾਪ ਜਾਂ ਰੀਸੈੱਟ ਕੀਤਾ ਜਾਂਦਾ ਹੈ।
ਆਪਣੀਆਂ ਲਾਈਫਟਾਈਮ ਨੂੰ ਖ਼ਾਸ ਹੱਦ ਨਾਲ ਜੋੜ ਕੇ ਤੁਸੀਂ ਹਰ-ਆਬਜੈਕਟ ਲਾਈਫਟਾਈਮ ਨੂੰ ਟਰੈਕ ਕਰਨ ਦੀ ਜ਼ਰੂਰਤ ਹਟਾ ਦਿੰਦੇ ਹੋ—"ਇਸ ਰਿਕਵੈਸਟ ਲਈ ਸਭ ਕੁਝ" ਜਾਂ "ਇਸ ਫੰਕਸ਼ਨ ਦੀ ਕੰਪੈਲ ਕਰਨ ਦੌਰਾਨ ਸਭ ਕੁਝ"।
ਅਰੀਨਾ ਆਮ ਤੌਰ 'ਤੇ ਤੇਜ਼ ਹੁੰਦੇ ਹਨ ਕਿਉਂਕਿ ਉਹ:
ਇਸ ਨਾਲ throughput ਵਿਚ ਸੁਧਾਰ ਆ ਸਕਦਾ ਹੈ ਅਤੇ ਘੱਟ-ਵਾਰ ਫ੍ਰੀ ਤੋਂ ਹੋਣ ਵਾਲੇ ਲੇਟੈਂਸੀ ਸਪਾਈਕ ਘਟ ਸਕਦੇ ਹਨ।
ਅਰੀਨਾ ਅਤੇ ਪੂਲ ਆਮ ਤੌਰ 'ਤੇ ਮਿਲਦੇ ਹਨ:
ਮੁੱਖ ਨਿਯਮ ਸਧਾਰਨ ਹੈ: ਅਰੀਨਾ ਜੋ ਮੈਮੋਰੀ ਦੇ ਮਾਲਕ ਹਨ ਉਸ ਦੀ ਮਿਆਦ ਤੋਂ ਰਿਫਰੰਸ ਨਾ ਭੇਜੋ। ਜੇ ਕੋਈ ਚੀਜ਼ ਅਰੀਨਾ ਦੀ ਮਿਆਦ ਤੋਂ ਬਾਹਰ ਸਟੋਰ ਹੋ ਜਾਂਦੀ ਹੈ ਜਾਂ ਰਿਟਰਨ ਹੋ ਜਾਂਦੀ ਹੈ, ਤਾਂ use-after-free ਖਤਰਾ ਬਣ ਜਾਂਦਾ ਹੈ।
ਭਾਸ਼ਾਵਾਂ ਅਤੇ ਲਾਇਬ੍ਰੇਰੀਆਂ ਇਸਨੂੰ ਵੱਖ-ਵੱਖ ਤਰੀਕਿਆਂ ਨਾਲ ਸੰਭਾਲਦੀਆਂ ਹਨ: ਕੁਝ ਅਨੁਸ਼ਾਸਨ ਅਤੇ APIs 'ਤੇ ਨਿਰਭਰ ਕਰਦੀਆਂ ਹਨ, ਹੋਰ ਕਿਸੇ ਹੱਦ ਨੂੰ ਕਿਸਮਾਂ ਵਿੱਚ encode ਕਰਦੀਆਂ ਹਨ।
ਅਰੀਨਾ ਅਤੇ ਪੂਲ GC ਜਾਂ ownership ਦਾ ਵਿਕਲਪ ਨਹੀਂ ਹਨ—ਉਹ ਅਕਸਰ ਪੂਰਕ ਹੁੰਦੇ ਹਨ। GC ਭਾਵੇਂ ਵਾਲੀਆਂ ਭਾਸ਼ਾਵਾਂ ਹਾਟ ਪਾਥਾਂ ਲਈ ਆਬਜੈਕਟ ਪੂਲ ਵਰਤਦੀਆਂ ਹਨ; ownership-ਅਧਾਰਿਤ ਭਾਸ਼ਾਵਾਂ lifetime ਗਰੁੱਪ ਕਰਨ ਲਈ ਅਰੀਨਾ ਵਰਤ ਸਕਦੀਆਂ ਹਨ। ਧਿਆਨ ਨਾਲ ਵਰਤਣ 'ਤੇ ਇਹ "ਡਿਫਾਲਟ ਤੌਰ 'ਤੇ ਤੇਜ਼" ਐਲੋਕੇਸ਼ਨ ਦੇ ਸਕਦਾ ਹੈ ਬਿਨਾਂ ਇਸਦੇ ਕਿ ਮੈਮੋਰੀ ਕਦੋਂ ਰੀਲીઝ ਹੋਵੇ ਇਸ 'ਤੇ ਅਸਪਸ਼ਟਤਾ ਰਹੇ।
ਭਾਸ਼ਾ ਦਾ ਮੈਮੋਰੀ ਮਾਡਲ ਸਿਰਫ਼ ਪ੍ਰਦਰਸ਼ਨ ਅਤੇ ਸੁਰੱਖਿਆ ਦੀ ਕਹਾਣੀ ਦਾ ਇੱਕ ਹਿੱਸਾ ਹੈ। ਆਧੁਨਿਕ ਕੰਪਾਇਲਰ ਅਤੇ ਰਨਟਾਈਮ ਤੁਹਾਡੇ ਪ੍ਰੋਗਰਾਮ ਨੂੰ ਇਹੋ ਜਿਹਾ ਤਬਦੀਲ ਕਰਦੇ ਹਨ ਕਿ ਘੱਟ allocate ਹੋਵੇ, ਜਲਦੀ free ਹੋਵੇ, ਅਤੇ ਜ਼ਿਆਦਾ ਬੁੱਕੀਪਿੰਗ ਤੋਂ ਬਚਿਆ ਜਾਵੇ। ਇਸੀ ਲਈ "GC ਹਮੇਸ਼ਾ ਧੀਮਾ ਹੈ" ਜਾਂ "ਮੈਨੁਅਲ ਮੈਮੋਰੀ ਸਭ ਤੋਂ ਤੇਜ਼" ਜਿਹੇ ਨਿਯਮ ਅਮਲੀ ਜ਼ਿੰਦਗੀ 'ਚ ਟੋਟਕੇ ਹੋ ਸਕਦੇ ਹਨ।
ਕਈ allocations ਸਿਰਫ਼ ਫੰਕਸ਼ਨਾਂ ਦਰਮਿਆਨ ਡੇਟਾ ਪਾਸ ਕਰਨ ਲਈ ਹੁੰਦੀਆਂ ਹਨ। Escape analysis ਨਾਲ ਕੰਪਾਇਲਰ ਇਹ ਸਾਬਤ ਕਰ ਸਕਦਾ ਹੈ ਕਿ ਇਕ ਆਬਜੈਕਟ ਕਦੇ ਵੀ ਮੌਜੂਦਾ ਸਕੋਪ ਤੋਂ ਬਾਹਰ ਨਹੀਂ ਜਾਂਦਾ, ਅਤੇ ਇਸਨੂੰ ਹੀਪ ਦੀ ਥਾਂ ਸਟੈਕ 'ਤੇ ਰੱਖ ਸਕਦਾ ਹੈ।
ਇਸ ਨਾਲ ਇੱਕ ਹੀਪ allocation ਪੂਰੀ ਤਰ੍ਹਾਂ ਹੀ ਹਟ ਸਕਦੀ ਹੈ, ਨਾਲ-ਨਾਲ ਉਸ ਨਾਲ ਜੁੜੇ ਖ਼ਰਚ ਵੀ (GC ਟ੍ਰੈਕਿੰਗ, ਰੈਫਰੰਸ ਕਾਊਂਟ ਅਪਡੇਟ, alloc ਲਾਕ)। managed ਭਾਸ਼ਾਵਾਂ ਵਿੱਚ ਇਹ ਇੱਕ ਵੱਡਾ ਕਾਰਨ ਹੈ ਕਿ ਛੋਟੇ ਆਬਜੈਕਟ ਸੋਚਣ ਤੋਂ ਸਸਤੇ ਹੋ ਸਕਦੇ ਹਨ।
###Inlining ਅਤੇ allocation removal
ਜਦੋਂ ਕੰਪਾਇਲਰ ਇੱਕ ਫੰਕਸ਼ਨ ਨੂੰ inline ਕਰਦਾ ਹੈ (ਕਾਲ ਨੂੰ ਫੰਕਸ਼ਨ ਦੇ ਬਾਡੀ ਨਾਲ ਬਦਲਦਾ ਹੈ), ਤਾਂ ਉਹ ਅਕਸਰ abstraction ਦੀਆਂ ਪਰਤਾਂ ਨੂੰ ਦੇਖ ਸਕਦਾ ਹੈ। ਇਸ ਦਿੱਖ ਨਾਲ optimization ਹੋ ਸਕਦੀ ਹੈ ਜਿਵੇਂ:
ਚੰਗੀ ਤਰ੍ਹਾਂ ਡਿਜ਼ਾਇਨ ਕੀਤੀਆਂ APIs optimization ਤੋਂ ਬਾਅਦ "zero-cost" ਹੋ ਸਕਦੀਆਂ ਹਨ, ਭਾਵੇਂ ਸੋਰਸ ਕੋਡ ਵਿੱਚ ਉਹ allocation-heavy ਦਿੱਸ ਰਹੀਆਂ ਹੋਣ।
JIT (just-in-time) ਰਨਟਾਈਮ ਹਕੀਕਤੀ ਪ੍ਰੋਡਕਸ਼ਨ ਡੇਟਾ ਵਰਤ ਕੇ optimize ਕਰ ਸਕਦੀ ਹੈ: ਕਿਹੜੇ ਕੋਡ ਪਾਥ ਹੌਟ ਹਨ, ਆਮ ਆਬਜੈਕਟ ਆਕਾਰ, allocation ਪੈਟਰਨ। ਇਸ ਨਾਲ throughput ਉੱਤੇ ਅਕਸਰ ਸੁਧਾਰ ਆਉਂਦਾ ਹੈ, ਪਰ ਇਹ warm-up ਸਮਾਂ ਅਤੇ ਕਦੇ-ਕਦੇ recompilation ਜਾਂ GC ਲਈ ਰੁਕਾਵਟ ਜੋੜ ਸਕਦਾ ਹੈ।
Ahead-of-time ਕੰਪਾਇਲਰ ਅਗੇ ਤੋਂ ਹੋਰ ਅਨੁਮਾਨ ਕਰਦੇ ਹਨ ਪਰ ਉਹ predictable startup ਅਤੇ steady latency ਦਿੰਦੇ ਹਨ।
GC-ਅਧਾਰਿਤ ਰਨਟਾਈਮ տեղਾਂ ਜਿਹੋਜੇ heap sizing, pause-time targets, ਅਤੇ generation thresholds ਵਰਗੀਆਂ settings ਦਿੰਦੇ ਹਨ। ਇਨ੍ਹਾਂ ਨੂੰ ਤਦ ਹੀ ਅਡਜਸਟ ਕਰੋ ਜਦੋਂ ਤੁਹਾਡੇ ਕੋਲ ਮਾਪੇ ਹੋਏ ਸਬੂਤ ਹੋਣ (ਜਿਵੇਂ ਲੇਟੈਂਸੀ ਸਪਾਈਕ ਜਾਂ ਮੈਮੋਰੀ ਦਬਾਅ)।
ਉਹੇ ਐਲਗੋਰਿਥਮ ਦੀਆਂ ਦੋ ਇੰਪਲੀਮੈਂਟੇਸ਼ਨ hidden allocation ਗਿਣਤਾਂ, ਅਸਥਾਈ ਆਬਜੈਕਟਾਂ ਅਤੇ ਪੁਆਇੰਟਰ ਚੇਜ਼ਿੰਗ ਵਿੱਚ ਵੱਖ-ਵੱਖ ਹੋ ਸਕਦੀਆਂ ਹਨ। ਇਹ ਤਫਾਵਤ optimizers, allocator ਅਤੇ cache ਵਿਹਾਰ ਨਾਲ interaction ਕਰਦੀਆਂ ਹਨ—ਇਸ ਲਈ ਪ੍ਰਦਰਸ਼ਨ ਤੁਲਨਾ ਲਈ profiling ਜ਼ਰੂਰੀ ਹੈ, ਅਨੁਮਾਨ ਨਹੀਂ।
ਮੈਮੋਰੀ ਪ੍ਰਬੰਧਨ ਦੀ ਚੋਣ ਸਿਰਫ਼ ਇਹ ਬਦਲਦੀ ਨਹੀਂ ਕਿ ਤੁਸੀਂ ਕੋਡ ਕਿਵੇਂ ਲਿਖਦੇ ਹੋ—ਇਹ ਇਸ ਗੱਲ ਨੂੰ ਵੀ ਬਦਲ ਦਿੰਦੀ ਹੈ ਕਿ ਕੰਮ ਕਦੋਂ ਹੁੰਦਾ ਹੈ, ਤੁਹਾਨੂੰ ਕਿੰਨੀ ਮੈਮੋਰੀ ਰਿਜ਼ਰਵ ਕਰਨੀਆਂ ਪੈਂਦੀਆਂ ਹਨ, ਅਤੇ ਉਪਭੋਗਤਾਂ ਲਈ ਪ੍ਰਦਰਸ਼ਨ ਕਿੰਨਾ ਲਗਾਤਾਰ ਮਹਿਸੂਸ ਹੁੰਦਾ ਹੈ।
ਥਰੂਪੁੱਟ ‘‘ਇੱਕ ਇਕਾਈ ਸਮੇਂ ਵਿੱਚ ਕਿੰਨਾ ਕੰਮ" ਹੈ। ਰਾਤ ਦੀ ਬੈਚ ਨੌਕਰੀ ਜੋ 10 ਮਿਲੀਅਨ رਿਕਾਰਡ ਪ੍ਰੋਸੈਸ ਕਰਦੀ ਹੈ: ਜੇ GC ਜਾਂ ਰੈਫਰੰਸ ਕਾਊਂਟਿੰਗ ਇੱਕ ਛੋਟਾ ਓਵਰਹੈਡ ਜੋੜਦੀ ਹੈ ਪਰ ਡਿਵੈਲਪਰ ਉਤਪਾਦਕਤਾ ਤੇਜ਼ ਕਰਦਾ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਕੁੱਲ ਵਿੱਚ ਸਭ ਤੋਂ ਤੇਜ਼ੀ ਨਾਲ ਖਤਮ ਕਰ ਸਕਦੇ ਹੋ।
ਲੇਟੈਂਸੀ ਇੱਕ ਓਪਰੇਸ਼ਨ ਦਾ ਅੰਤ-ਟੁ-ਅੰਤ ਸਮਾਂ ਹੈ। ਵੈਬ ਰਿਕਵੈਸਟ ਲਈ, ਇੱਕ ਸਲੋ ਰਿਸਪੌਂਸ ਉਪਭੋਗਤਾ ਅਨੁਭਵ ਨੂੰ ਨੁਕਸਾਨ ਪਹੁੰਚਾਉਂਦਾ ਹੈ ਭਾਵੇਂ ਔਸਤ ਥਰੂਪੁੱਟ ਵਧੀਆ ਹੋਵੇ। ਉਹ ਰਨਟਾਈਮ ਜੋ ਕਦੇ-ਕਦੇ ਮੈਮੋਰੀ ਰਿਕਲੇਮ ਕਰਨ ਲਈ ਰੁਕਦੀ ਹੈ, ਬੈਚ ਪ੍ਰੋਸੈਸਿੰਗ ਲਈ ਠੀਕ ਹੋ ਸਕਦੀ ਹੈ ਪਰ ਇੰਟਰੈਕਟਿਵ ਐਪਾਂ ਲਈ ਇਸਦਾ ਅਸਰ ਨਜ਼ਰ ਆਉਂਦਾ ਹੈ।
ਵੱਡਾ ਮੈਮੋਰੀ ਫੁੱਟਪ੍ਰਿੰਟ ਕਲਾਉਡ ਖ਼ਰਚ ਵਧਾਉਂਦਾ ਅਤੇ ਪ੍ਰੋਗਰਾਮ ਨੂੰ ਧੀमा ਕਰ ਸਕਦਾ ਹੈ। ਜਦੋਂ ਤੁਹਾਡਾ ਵਰਕਿੰਗ ਸੈਟ CPU cache ਵਿੱਚ ਅੱਤਰ ਨਾਂ ਬੈਠਦਾ, CPU ਵਧੇਰੇ ਵਾਰੀ RAM ਤੋਂ ਡੇਟਾ ਲਈ ਇੰਤਜ਼ਾਰ ਕਰਦਾ ਹੈ। ਕੁਝ ਰਣਨੀਤੀਆਂ ਤੇਜ਼ੀ ਲਈ ਵਾਧੂ ਮੈਮੋਰੀ ਵਰਤਦੀਆਂ ਹਨ (ਜਿਵੇਂ freed objects ਨੂੰ ਪੂਲਾਂ ਵਿੱਚ ਰੱਖਣਾ), ਜਦਕਿ ਹੋਰ ਮੈਮੋਰੀ ਘਟਾਉਂਦੀਆਂ ਹਨ ਪਰ bookkeeping ਓਵਰਹੈਡ ਵਧਾ ਦਿੰਦੀਆਂ ਹਨ।
ਫ੍ਰੈਗਮੈਂਟੇਸ਼ਨ ਉਸ ਵੇਲੇ ਹੁੰਦੀ ਹੈ ਜਦੋਂ ਖਾਲੀ ਮੈਮੋਰੀ ਬਹੁਤ ਸਾਰੇ ਛੋਟੇ-ਛੋਟੇ ਹਿੱਸਿਆਂ ਵਿੱਚ ਟੁੱਟ ਜਾਂਦੀ ਹੈ—ਜਿਵੇਂ ਭਿੱਜਣ ਲਈ ਛੋਟੇ-ਛੋਟੇ ਸਥਾਨਾਂ ਵਾਲੀ ਗੱਡੀ ਪਾਰਕਿੰਗ ਲੌਟ। Allocators ਨੂੰ ਜਗ੍ਹਾ ਲੱਭਣ ਲਈ ਵਧੇਰੇ ਸਮਾਂ ਲੱਗ ਸਕਦਾ ਹੈ, ਅਤੇ ਮੈਮੋਰੀ ਵਧ ਸਕਦੀ ਹੈ ਭਾਵੇਂ ਥਿਆਰੀਕ ਤੌਰ 'ਤੇ ਕਾਫ਼ੀ ਖਾਲੀ ਹੋਵੇ।
ਕੈਸ਼ ਲੋਕੈਲਿਟੀ ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਸੰਬੰਧਤ ਡੇਟਾ ਨੇੜੇ ਇਕੱਠੇ ਹੋਵੇ। ਪੂਲ/ਅਰੀਨਾ ਐਲੋਕੇਸ਼ਨ ਅਕਸਰ ਲੋਕੈਲਿਟੀ ਸੁਧਾਰਦੇ ਹਨ, ਜਦਕਿ ਲੰਬੀ-ਆਵਧੀ ਹੀਪਾਂ ਵਿੱਚ ਵੱਖ-ਵੱਖ ਆਕਾਰ ਵਾਲੇ ਆਬਜੈਕਟ ਮਿਲ ਜਾਣ ਨਾਲ ਕੈਸ਼-ਅਣਕੂਲ ਲੇਆਉਟ ਬਣ ਸਕਦੇ ਹਨ।
ਜੇ ਤੁਹਾਨੂੰ ਲਗਾਤਾਰ ਰਿਸਪਾਂਸ ਟਾਈਮ ਚਾਹੀਦਾ ਹੈ—ਗੇਮਜ਼, ਆਡੀਓ ਐਪ, ਟ੍ਰੇਡਿੰਗ ਸਿਸਟਮ, ਐਂਬੇਡਡ ਜਾਂ ਰੀਅਲ-ਟਾਈਮ ਕੰਟਰੋਲ—"ਅਕਸਰ ਤੇਜ਼ ਪਰ ਕਦੇ-ਕਦੇ ਧੀਮਾ" ਨਾਲੋਂ "ਥੋੜ੍ਹਾ ਧੀਮਾ ਪਰ ਲਗਾਤਾਰ" ਵਧੀਆ ਹੋ ਸਕਦਾ ਹੈ। ਇੱਥੇ ਨਿਰਧਾਰਿਤ ਡੀਅਲੋਕੇਸ਼ਨ ਪੈਟਰਨ ਅਤੇ ਐਲੋਕੇਸ਼ਨ 'ਤੇ ਕਠੋਰ ਕੰਟਰੋਲ ਮਹੱਤਵਪੂਰਨ ਹੁੰਦੇ ਹਨ।
ਮੈਮੋਰੀ ਤਰੁੱਟੀਆਂ ਸਿਰਫ਼ "ਡਿਵੈਲਪਰ ਦੀਆਂ ਗਲਤੀਆਂ" ਨਹੀਂ ਹੁੰਦੀਆਂ। ਕਈ ਵਾਸਤਵਿਕ ਸਿਸਟਮਾਂ ਵਿੱਚ ਉਹ ਸੁਰੱਖਿਆ ਸਮੱਸਿਆਵਾਂ ਵਿੱਚ ਬਦਲ ਜਾਂਦੀਆਂ ਹਨ: ਅਚਾਨਕ ਕ੍ਰੈਸ਼ (denial of service), ਅਣਚਾਹੀ ਡੇਟਾ ਰਿਫ਼ਲੈਕਸ਼ਨ (ਫ੍ਰੀ ਹੋਈ ਜਾਂ ਅਣਇਨੀਸ਼ੀਅਲਾਈਜ਼ਡ ਮੈਮੋਰੀ ਪੜ੍ਹਨਾ), ਜਾਂ ਐਸੇ ਹਾਲਾਤ ਜਿੱਥੇ ਹਮਲਾਵਰ ਐਪਲੀਕੇਸ਼ਨ ਨੂੰ ਗਲਤ ਪਰਿਵਰਤਿਤ ਕਰਨ ਲਈ ਪ੍ਰੇਰਤ ਕਰ ਸਕਦੇ ਹਨ।
ਵੱਖ-ਵੱਖ ਮੈਮੋਰੀ-ਮੈਨੇਜਮੈਂਟ ਰਣਨੀਤੀਆਂ ਵੱਖ-ਵੱਖ ਤਰੀਕਿਆਂ ਨਾਲ ਫੇਲ ਹੁੰਦੀਆਂ ਹਨ:
Concurrency ਖ਼ਤਰੇ ਦੇ ਮਾਡਲ ਨੂੰ ਬਦਲ ਦਿੰਦੀ ਹੈ: ਇੱਕ ਥ੍ਰੈਡ ਵਿੱਚ "ਠੀਕ" ਮੰਨੀ ਜਾਣ ਵਾਲੀ ਮੈਮੋਰੀ ਦੂਜੇ ਥ੍ਰੈਡ ਵਿੱਚ free ਜਾਂ mutate ਹੋ ਸਕਦੀ ਹੈ। ਉਹ ਮਾਡਲ ਜੋ ਸ਼ੇਅਰਿੰਗ ਦੇ ਬਾਰੇ ਨਿਯਮ ਲਗਾਂਦੇ ਹਨ (ਜਾਂ explicit synchronization ਲੋੜੀਂਦੀ ਹੈ) race conditions ਨੂੰ ਘਟਾਉਂਦੇ ਹਨ ਜੋ corrupted state, data leaks ਅਤੇ intermittent crashes ਬਣਾ ਸਕਦੇ ਹਨ।
ਕੋਈ ਵੀ ਮੈਮੋਰੀ ਮਾਡਲ ਸਾਰੇ ਖਤਰਿਆਂ ਨੂੰ ਹਟਾ ਨਹੀਂ ਦਿੰਦਾ—ਲਾਜਿਕਲ ਬੱਗ (ਆਥ ਮਿਸਟੇਕਾਂ, insecure defaults, flawed validation) ਹਜੇ ਵੀ ਹੋ ਸਕਦੇ ਹਨ। ਮਜ਼ਬੂਤ ਟੀਮਾਂ ਕੁਝ ਹੋਰ ਪ੍ਰੋਟੈਕਸ਼ਨ ਜੋੜਦੀਆਂ ਹਨ: ਟੈਸਟਿੰਗ ਵਿੱਚ sanitizers, ਸੁਰੱਖਿਅਤ standard libraries, ਕਤਰਨੀ ਕੋਡ ਰਿਵਿਊ, fuzzing, ਅਤੇ unsafe/FFI ਕੋਡ ਦੇ ਆਲੇ-ਦੁਆਲੇ ਸਖ਼ਤ ਹੱਦਾਂ। ਮੈਮੋਰੀ ਸੇਫਟੀ ਹਮਲਾਵਰ 'ਤੇ ਇੱਕ ਵੱਡਾ ਘਟਾਓ ਹੈ ਪਰ ਗਾਰੰਟੀ ਨਹੀਂ।
ਮੈਮੋਰੀ ਮੁੱਦੇ ਜਿਸ ਤਰ੍ਹਾਂ ਜਿੰਨੀ ਜਲਦੀ ਤੁਸੀਂ ਉਨ੍ਹਾਂ ਨੂੰ ਲੱਭ ਲਓਗੇ, ਉਨ੍ਹਾਂ ਨੂੰ ਠੀਕ ਕਰਨਾ ਓ ਉਹਦੀ ਸ਼ੁਰੂਆਤ ਵਾਲੀ ਚੇਂਜ ਦੇ ਨਜ਼ਦੀਕ ਹੋਵੇਗਾ। ਕੁੰਜੀ ਹੈ ਪਹਿਲਾਂ ਮਾਪੋ, ਫਿਰ ਮਸਲੇ ਨੂੰ ਸਹੀ ਟੂਲ ਨਾਲ 좁 ਕਰੋ।
ਸ਼ੁਰੂ 'ਚ ਫਰਕ ਕਰੋ ਕਿ ਤੁਸੀਂ ਸਪੀਡ ਦਾ ਪਿੱਛਾ ਕਰ ਰਹੇ ਹੋ ਜਾਂ ਮੈਮੋਰੀ ਗ੍ਰੋਥ ਦਾ।
ਪ੍ਰਦਰਸ਼ਨ ਲਈ wall-clock ਸਮਾਂ, CPU ਸਮਾਂ, allocation rate (bytes/sec), ਅਤੇ GC ਜਾਂ allocator ਵਿੱਚ ਲੱਗੇ ਸਮੇਂ ਨੂੰ ਮਾਪੋ। ਮੈਮੋਰੀ ਲਈ peak RSS, steady-state RSS, ਅਤੇ ਆਬਜੈਕਟ ਗਿਣਤੀ ਸਮੇਂ-ਸਿਰ ਨੂੰ ਟਰੈਕ ਕਰੋ। ਇੱਕੋ ਵਰਕਲੋਡ ਨਾਲ ਦੌੜਾਓ; ਘੱਟ variation allocation churn ਨੂੰ ਢਕ ਸਕਦੀ ਹੈ।
ਆਮ ਨਿਸ਼ਾਨ: ਇੱਕ ਹੀ ਰਿਕਵੈਸਟ ਉਮੀਦ ਨਾਲੋਂ ਕਾਫੀ ਵੱਧ allocate ਕਰਦਾ ਹੈ, ਜਾਂ ਟ੍ਰੈਫਿਕ ਨਾਲ ਮੈਮੋਰੀ ਚੜ੍ਹਦੀ ਜਾਂਦੀ ਹੈ ਜਦਕਿ throughput ਸਥਿਰ ਰਹਿੰਦਾ ਹੈ। fixes ਆਮ ਤੌਰ 'ਤੇ ਬਫਰ ਦੁਬਾਰਾ ਵਰਤਣ, ਛੋਟੇ-ਅਵਧੀ object ਲਈ arena/pool allocation, ਅਤੇ object graphs ਸਧਾਰਨ ਕਰਨ ਨੂੰ ਸ਼ਾਮِل ਕਰਦੀਆਂ ਹਨ ਤਾਂ ਕਿ ਘੱਟ ਆਬਜੈਕਟ ਸਰਚਿਵ ਹੋ ਕੇ ਆਉਣ।
ਘੱਟੋ-ਘੱਟ ਇਨਪੁੱਟ ਨਾਲ reproducible case ਬਣਾਓ, ਸਭ ਤੋਂ ਸਖ਼ਤ runtime checks (sanitizers/GC verification) enable ਕਰੋ, ਫਿਰ capture ਕਰੋ:
ਪਹਿਲਾ ਫਿਕਸ ਇੱਕ ਪ੍ਰਯੋਗ ਵਾਂਗ ਸੋਚੋ; ਮਾਪਿਆਂ ਦੁਬਾਰਾ ਦੌੜਾਉਣਾ ਤਾਂ ਕਿ ਤਸਦੀਕ ਹੋ ਸਕੇ ਕਿ ਬਦਲਾਅ ਨੇ allocations ਘਟਾਈਆਂ ਜਾਂ ਮੈਮੋਰੀ ਨੂੰ ਸਥਿਰ ਕੀਤਾ—ਬਿਨਾ ਕਿਸੇ ਹੋਰ ਸਥਾਨ ਤੇ ਸਮੱਸਿਆ ਸਥਾਨਾਂਤਰਿਤ ਕੀਤੇ। ਵਧੇਰੇ ਟਰੇਡਆਫ਼ ਦੇ ਵਿਆਖਿਆ ਲਈ, ਦੇਖੋ /blog/performance-trade-offs-throughput-latency-memory-use.
ਭਾਸ਼ਾ ਚੁਣਣਾ ਸਿਰਫ਼ ਸਿੰਟੈਕਸ ਜਾਂ ਇਕੋਸਿਸਟਮ ਬਾਰੇ ਨਹੀਂ ਹੁੰਦਾ—ਉਸਦਾ ਮੈਮੋਰੀ ਮਾਡਲ ਦਿਨ-ਪ੍ਰਤੀਦਿਨ ਵਿਕਾਸ ਦੀ رفتار, ਓਪਰੇਸ਼ਨਲ ਖ਼ਤਰਾ, ਅਤੇ ਹਕੀਕਤੀ ਟ੍ਰੈਫਿਕ ਹੇਠ ਪ੍ਰਦਰਸ਼ਨ ਦੀ ਨਿਰਧਾਰਿਤਤਾ ਨੂੰ ਆਕਾਰ ਦਿੰਦਾ ਹੈ।
ਆਪਣੇ ਉਤਪਾਦ ਦੀਆਂ ਲੋੜਾਂ ਨੂੰ ਇੱਕ ਮੈਮੋਰੀ ਰਣਨੀਤੀ ਨਾਲ ਮੈਪ ਕਰੋ ਇਹਨਾਂ ਸਵਾਲਾਂ ਦੇ ਜਵਾਬ ਦਿੰਦਿਆਂ:
ਜੇ ਤੁਸੀਂ ਮਾਡਲ ਬਦਲ ਰਹੇ ਹੋ ਤਾਂ friction ਦੀ ਯੋਜਨਾ ਬਣਾਓ: ਮੌਜੂਦਾ ਲਾਇਬ੍ਰੇਰੀਜ਼ (FFI) ਵਿੱਚ ਕਾਲਿੰਗ, ਮਿਲੇ-जੁਲੇ ਮੈਮੋਰੀ ਸੰਸਥਾਵਾਂ, ਟੂਲਿੰਗ, ਅਤੇ hiring market। ਪ੍ਰੋਟੋਟਾਈਪ ਛਿਪੇ ਖ਼ਰਚ (pauses, memory growth, CPU overhead) ਨੂੰ ਪਹਿਲਾਂ ਹੀ ਖੋਜਣ ਵਿੱਚ ਮਦਦ ਕਰਦੇ ਹਨ।
ਇੱਕ ਅਮਲੀ ਪਹੁੰਚ ਇਹ ਹੈ ਕਿ ਤੁਸੀਂ ਉਹੀ ਫੀਚਰ ਅਲੱਗ-ਅਲੱਗ ਮਾਹੌਲਾਂ ਵਿੱਚ ਪ੍ਰੋਟੋਟਾਈਪ ਕਰੋ ਅਤੇ ਨੁਮਾਇੰਦਗੀ ਵਾਲੇ ਲੋਡ ਹੇਠ allocation rate, tail latency, ਅਤੇ peak memory ਦੀ ਤੁਲਨਾ ਕਰੋ। ਟੀਮਾਂ ਕਦੇ-ਕਦੇ ਇਹ “ਸੇਬ-ਤੁਲਨਾ-ਸੇਬ” ਮੁਲਾਂਕਣ ਕਰਦੀਆਂ ਹਨ। ਉਦਾਹਰਣ ਲਈ Koder.ai ਵਰਤ ਕੇ ਛੋਟੀ React ਫਰੰਟਐਂਡ + Go + PostgreSQL ਬੈਕਐਂਡ ਦਾ ਸਕੈਫੋਲਡ ਬਣਾਇਆ ਜਾ ਸਕਦਾ ਹੈ ਅਤੇ ਟ੍ਰੈਫਿਕ ਸ਼ੇਪਸ ਅਤੇ ਡੇਟਾ ਸਟਰੱਕਚਰਾਂ ਦੇ साथ iterate ਕਰਕੇ ਵੇਖਿਆ ਜਾ ਸਕਦਾ ਹੈ ਕਿ GC-ਅਧਾਰਿਤ ਸੇਵਾ ਹਕੀਕਤੀ ਟ੍ਰੈਫਿਕ ਹੇਠ ਕਿਵੇਂ ਵਰਤਦੀ ਹੈ (ਅਤੇ ਜਦੋਂ ਤੁਸੀਂ ਫਾਇਲ ਤਿਆਰ ਕਰਨ ਲਈ ਤਿਆਰ ਹੋ ਤਾਂ ਸੋర్స్ ਕੋਡ ਨਿਰਯਾਤ ਕਰੋ)।
ਉਪਰੋਕਤ 3–5 ਸੀਮਾਵਾਂ ਨੂੰ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ, ਇੱਕ ਪਤਲੈ ਪ੍ਰੋਟੋਟਾਈਪ ਬਣਾਓ, ਅਤੇ ਮਾਪੋ memory use, tail latency, ਅਤੇ failure modes।
| Model | Safety by default | Latency predictability | Developer speed | Typical pitfalls |
|---|---|---|---|---|
| Manual | Low–Medium | High | Medium | leaks, use-after-free |
| GC | High | Medium | High | pauses, heap growth |
| RC | Medium–High | High | Medium | cycles, overhead |
| Ownership | High | High | Medium | learning curve |
ਮੈਮੋਰੀ ਪ੍ਰਬੰਧਨ ਉਹ ਤਰੀਕਾ ਹੈ ਜਿਸ ਨਾਲ ਇੱਕ ਪ੍ਰੋਗਰਾਮ ਡੇਟਾ (ਜਿਵੇਂ ਆਬਜੈਕਟ, ਸਟਰਿੰਗ, ਬਫਰ) ਲਈ ਮੈਮੋਰੀ.allocate ਕਰਦਾ ਹੈ ਅਤੇ ਜਦੋਂ ਉਹ ਲੋੜੀਂਦਾ ਨਹੀਂ ਰਹਿੰਦਾ ਤਾਂ ਉਸਨੂੰ ਰਿਲੀਜ਼ ਕਰਦਾ ਹੈ।
ਇਸਦਾ ਪ੍ਰਭਾਵ ਇਹਨਾਂ 'ਤੇ ਪੈਂਦਾ ਹੈ:
ਸਟੈਕ ਤੇਜ਼, ਆਟੋਮੈਟਿਕ ਅਤੇ ਫੰਕਸ਼ਨ ਕਾਲਾਂ ਨਾਲ ਜੁੜਿਆ ਹੁੰਦਾ ਹੈ: ਜਦੋਂ ਫੰਕਸ਼ਨ ਖਤਮ ਹੁੰਦਾ ਹੈ, ਉਸਦੀ ਸਾਰੀ ਸਟੈਕ ਫਰੇਮ ਇਕੱਠੀ ਹਟ ਜਾਂਦੀ ਹੈ।
ਹੀਪ ਲਚਕੀਲਾ ਹੈ ਅਤੇ ਡਾਇਨਾਮਿਕ ਜਾਂ ਲੰਬੀ ਮਿਆਦ ਵਾਲੇ ਡੇਟਾ ਲਈ ਵਰਤਿਆ ਜਾਂਦਾ ਹੈ, ਪਰ ਇਹਨਾਂ ਲਈ ਇਹ ਦਿਸ਼ਾ-ਨਿਰਦੇਸ਼ ਚਾਹੀਦਾ ਹੈ ਕਿ ਕਦੋਂ ਅਤੇ ਕੌਣ ਮੈਮੋਰੀ ਛੁਡ਼ੇਗਾ।
ਇੱਕ ਆਮ ਨਿਯਮ: ਸਟੈਕ ਸੰਖਿਪਤ, ਨਿਰਧਾਰਿਤ ਆਕਾਰ ਵਾਲੇ ਲੋਕਲ ਲਈ ਵਧੀਆ ਹੈ; ਹੀਪ ਉਹਨਾਂ ਲਈ ਜਦੋਂ ਲਾਈਫਟਾਈਮ ਜਾਂ ਆਕਾਰ ਅਣਪ੍ਰੇਤ ਹੁੰਦੇ ਹਨ।
ਰੇਫਰੰਸ/ਪੌਇੰਟਰ ਇੱਕ ਆਬਜੈਕਟ ਨੂੰ ਅਪਰੋਕਸੀਤਰ ਤਰੀਕੇ ਨਾਲ ਐਕਸੈਸ ਕਰਨ ਦਾ ਰਸਤਾ ਹੈ। ਖਤਰਾ ਉਦੋਂ ਬਣਦਾ ਹੈ ਜਦੋਂ ਆਬਜੈਕਟ ਦੀ ਮੈਮੋਰੀ ਰਿਲੀਜ਼ ਹੋ ਚੁਕੀ ਹੁੰਦੀ ਹੈ ਪਰ ਕੋਡ ਦੇ ਕੋਲ ਉਸਦਾ ਰਿਫਰੰਸ ਫਿਰ ਵੀ ਮੌਜੂਦ ਹੈ।
ਇਸ ਨਾਲ ਹੋ ਸਕਦਾ ਹੈ:
ਤੁਸੀਂ ਖੁਦ ਮੈਮੋਰੀ allocate ਅਤੇ free ਕਰਦੇ ਹੋ (ਉਦਾਹਰਣ: malloc/free, new/delete)।
ਇਹ ਇਸ ਵੇਲੇ ਵਰਤਿਆ ਜਾਂਦਾ ਹੈ ਜਦੋਂ ਤੁਹਾਨੂੰ ਚਾਹੀਦਾ ਹੈ:
ਲਾਗਤ: ਜੇ ਮਲਕੀਅਤ ਅਤੇ ਲਾਈਫਟਾਈਮ ਨੂੰ ਧਿਆਨ ਨਾਲ ਨਹੀਂ ਸੰਭਾਲਿਆ ਗਿਆ ਤਾਂ ਬੱਗਜ਼ ਦਾ ਖ਼ਤਰਾ ਵਧ ਜਾਂਦਾ ਹੈ।
ਜੇ ਪੂਰੀ ਤਰ੍ਹਾਂ ਡਿਜ਼ਾਇਨ ਚੰਗੀ ਹੋਵੇ ਤਾਂ ਮੈਨੂਅਲ ਪ੍ਰਬੰਧਨ ਬਹੁਤ ਨਿਰਧਾਰਿਤ ਲੇਟੈਂਸੀ ਦੇ ਸਕਦਾ ਹੈ, ਕਿਉਂਕਿ ਪਿੱਛੇ ਕੋਈ GC ਚੱਕਰ نہ ਚੱਲਦਾ।
ਤੁਸੀਂ ਇਸਨੂੰ ਅਪਟਿਮਾਈਜ਼ ਕਰ ਸਕਦੇ ਹੋ:
ਪਰ ਆਸਾਨੀ ਨਾਲ ਮਹਿੰਗੇ ਪੈਟਰਨ ਵੀ ਬਣ ਸਕਦੇ ਹਨ (ਫ੍ਰੈਗਮੈਂਟੇਸ਼ਨ, allocator contention, ਛੋਟੀਆਂ ਬਾਰ-ਬਾਰ ਐਲੋਕੇਸ਼ਨ/ਫ੍ਰੀ)।
ਗਾਰਬੇਜ਼ ਕਲੈਕਸ਼ਨ (GC) ਆਪਣੇ-ਆਪ ਵਿੱਚ ਓਬਜੈਕਟਾਂ ਨੂੰ ਖੋਜ ਕੇ ਸਾਫ ਕਰਦਾ ਹੈ ਜੋ ਹੁਣ ਪਹੁੰਚ ਦੇ ਯੋਗ ਨਹੀਂ ਰਹਿੰਦੇ।
ਜ्यਾਦਾਤਰ ਟ੍ਰੇਸਿੰਗ GCs ਇਹ ਕਰਦੇ ਹਨ:
ਇਹ ਸੁਰੱਖਿਆ ਨੂੰ ਬਿਹਤਰ ਕਰਦਾ ਹੈ (ਬਹੁਤ ਸਾਰੇ use-after-free ਬੱਗ ਹਟਦੇ ਹਨ) ਪਰ-runtime ਕੰਮ ਵਧਦਾ ਹੈ ਅਤੇ ਕਲੈਕਸ਼ਨ ਡਿਜ਼ਾਇਨ ਦੇ ਆਧਾਰ 'ਤੇ ਰੁਕਾਵਟਾਂ ਆ ਸਕਦੀਆਂ ਹਨ।
ਰੈਫਰੰਸ ਕਾਊਂਟਿੰਗ ਵਿੱਚ ਹਰ ਆਬਜੈਕਟ ਇਹ ਗਿਣਦਾ ਹੈ ਕਿ ਕਿੰਨੇ "ਮਲਕੀਨ" (references) ਉਸ ਵੱਲ ਵੇਖ ਰਹੇ ਹਨ। ਜਦੋਂ ਕਾਊਂਟ ਜ਼ੀਰੋ ਹੋ ਜਾਂਦੀ ਹੈ, ਆਬਜੈਕਟ ਤੁਰੰਤ ਫ੍ਰੀ ਹੋ ਜਾਂਦਾ ਹੈ।
ਫائدੇ:
ਮੁਸੀਬਤ:
ਮਲਕੀਅਤ ਅਤੇ ਬੋਰੋਅਿੰਗ ਦਾ ਮਾਡਲ (ਜੋ ਖਾਸ ਕਰਕੇ Rust ਨਾਲ ਜੁੜਿਆ ਹੈ) ਕੰਪਾਇਲ-ਟਾਈਮ ਨਿਯਮ ਲਗਾਂਦਾ ਹੈ ਜੋ dangling pointers, double-frees ਅਤੇ ਬਹੁਤ ਸਾਰੇ ਡਾਟਾ-ਰੇਸ ਸਬਕਲਾਸਾਂ ਨੂੰ ਬਣਨ ਤੋਂ ਰੋਕਦਾ ਹੈ—ਬਿਨਾਂ ਰਨਟਾਈਮ GC 'ਤੇ ਨਿਰਭਰ ਹੋਏ।
मुख्य ਵਿਚਾਰ:
ਇਸ ਨਾਲ ਬਹੁਤ ਸਾਰੇ dangling-reference ਬੱਗ ਕੰਪਾਇਲ-ਟਾਈਮ 'ਤੇ ਰੋਕ ਦਿੱਤੇ ਜਾਂਦੇ ਹਨ, ਪਰ ਸਿਖਣ ਦੀ ਘੱਟੀ ਅਤੇ ਡੇਟਾ ਫਲੋ ਨੂੰ ਮੁੜ-ਸੰਰਚਿਤ ਕਰਨ ਦੀ ਲੋੜ ਹੋ ਸਕਦੀ ਹੈ।
ਅਰੀਨਾ/ਰੀਜਨ ਇੱਕ ਮੈਮੋਰੀ ਜ਼ੋਨ ਹੈ ਜਿੱਥੇ ਤੁਸੀਂ ਬਹੁਤ ਸਾਰੇ ਆਬਜੈਕਟ allocate ਕਰਦੇ ਹੋ, ਅਤੇ ਫਿਰ ਉਹਨਾਂ ਸਾਰੇ ਨੂੰ ਇਕੱਠੇ free ਕਰਦੇ ਹੋ ਜਾਂ ਅਰੀਨਾ ਨੂੰ ਰੀਸੈੱਟ ਕਰਦੇ ਹੋ।
ਇਹ ਤਰੀਕਾ ਤੇਜ਼ ਹੈ ਕਿਉਂਕਿ:
ਅਸਲ ਨਿਯਮ: ਅਰੀਨਾ ਦੀ ਮਿਆਦ ਤੋਂ ਬਾਹਰ ਰਿਫਰੰਸ ਨਾ ਭੇਜੋ—ਇਸਨੂੰ ਤੋੜਨ ਨਾਲ use-after-free ਦਾ ਖਤਰਾ ਬਣਦਾ ਹੈ।
ਸਭ ਤੋਂ ਪਹਿਲਾਂ ਹਕੀਕਤੀ ਮਾਪ-ਟੋਲ ਨਾਲ ਮਾਪੋ:
ਫਿਰ ਲਕੜੀ ਟੂਲ ਵਰਗੇ allocation/CPU profilers, leak detectors, sanitizers ਅਤੇ fuzzing ਨਾਲ ਗਹਿਰਾਈ ਵਿੱਚ ਜਾਓ।
ਬਹੁਤ ਸਿਸਟਮ weak references ਜਾਂ cycle detector ਵਰਗੇ ਤਰੀਕਿਆਂ ਨਾਲ ਇਸਨੂੰ ਨਿਬਾਟਦੇ ਹਨ।
ਰੰਟਾਈਮ ਸੈਟਿੰਗ (GC parameters ਆਦਿ) ਨੂੰ ਸਿਰਫ਼ ਮਾਪੇ ਹੋਏ ਸਬੂਤ ਮਿਲਣ 'ਤੇ ਹੀ ਅਡਜਸਟ ਕਰੋ।