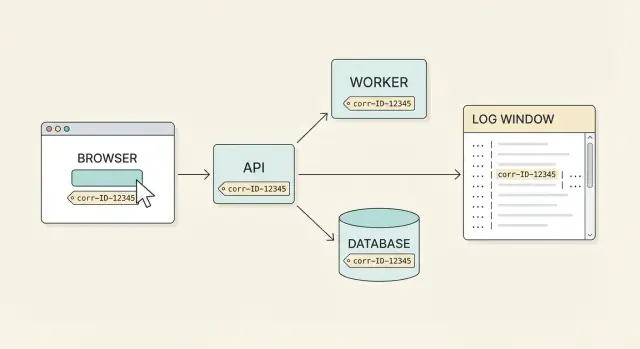
ਸਪੋਰਟ ਲਈ ਕੋਰਲੇਸ਼ਨ ਆਈਡੀਜ਼ ਮਹੱਤਵਪੂਰਨ ਕਿਉਂ ਹਨ
ਸਪੋਰਟ ਨੂੰ ਅਕਸਰ ਸਾਫ ਬੱਗ ਰਿਪੋਰਟ ਨਹੀਂ ਮਿਲਦੀ। ਯੂਜ਼ਰ ਕਹਿੰਦਾ ਹੈ, "ਮੈਂ Pay ਤੇ ਕਲਿੱਕ ਕੀਤਾ ਅਤੇ ਇਹ ਫੇਲ ਹੋ ਗਿਆ," ਪਰ ਉਹ ਇੱਕ ਕਲਿੱਕ ਬ੍ਰਾਉਜ਼ਰ, ਇੱਕ API gateway, payments ਸਰਵਿਸ, ਡੇਟਾਬੇਸ ਅਤੇ ਬੈਕਗ੍ਰਾਊਂਡ ਜੌਬ ਸਭ ਨੂੰ ਛੂਹ ਸਕਦਾ ਹੈ। ਹਰ ਹਿੱਸਾ ਵੱਖ-ਵੱਖ ਸਮਿਆਂ 'ਤੇ, ਵੱਖ-ਵੱਖ ਮਸ਼ੀਨਾਂ 'ਤੇ ਆਪਣੀ ਲੋੜੀ ਦੀ ਕਹਾਣੀ ਲੌਗ ਕਰਦਾ ਹੈ। ਇੱਕ ਸਾਂਝੇ ਲੇਬਲ ਬਿਨਾਂ, ਤੁਸੀਂ ਅੰਦਾਜ਼ਾ ਲਗਾਉਂਦੇ ਰਹਿ ਜਾਂਦੇ ਹੋ ਕਿ ਕਿਹੜੀਆਂ ਲੌਗ ਲਾਈਨਾਂ ਇਕੱਠੀਆਂ ਹਨ।
ਕੋਰਲੇਸ਼ਨ ID ਉਹ ਸਾਂਝਾ ਲੇਬਲ ਹੈ। ਇਹ ਇੱਕ ID ਹੁੰਦੀ ਹੈ ਜੋ ਇੱਕ ਯੂਜ਼ਰ ਕਾਰਵਾਈ (ਜਾਂ ਇੱਕ ਲਾਜ਼ਮਾਤੀ ਵਰਕਫਲੋ) ਨਾਲ ਜੁੜੀ ਹੁੰਦੀ ਹੈ ਅਤੇ ਹਰ ਰਿਕਵੇਸਟ, ਰੀਟ੍ਰਾਈ ਅਤੇ ਸਰਵਿਸ ਹੌਪ ਦੇ ਰਾਹੀਂ ਚਲਦੀ ਹੈ। ਅਸਲ end-to-end ਕਵਰੇਜ਼ ਨਾਲ ਤੁਸੀਂ ਯੂਜ਼ਰ ਦੀ ਸ਼ਿਕਾਇਤ ਤੋਂ ਸ਼ੁਰੂ ਕਰਕੇ ਪੂਰੀ ਟਾਈਮਲਾਈਨ ਖਿੱਚ ਸਕਦੇ ਹੋ।
ਲੋਕ ਅਕਸਰ ਕੁਝ ਮਿਲਦੇ-ਜੁਲਦੇ IDs ਨੂੰ ਗਲਤ ਸਮਝ ਲੈਂਦੇ ਹਨ। ਸਾਫ ਵੰਡ ਇਹ ਹੈ:
- Correlation ID: ਇੱਕ ਕਾਰਵਾਈ ਨਾਲ ਜੁੜੇ ਸਾਰੇ ਇਵੈਂਟਾਂ ਨੂੰ ਗਰੁੱਪ ਕਰਦਾ ਹੈ (ਉਦਾਹਰਣ: "Save settings").
- Request ID: ਇੱਕ HTTP request ਨੂੰ ਪਹਚਾਣਦਾ ਹੈ। ਰੀਟ੍ਰਾਈਜ਼ ਨਵੇਂ request IDs ਬਣਾਉਂਦੇ ਹਨ।
- Trace ID: distributed tracing ਟੂਲਾਂ ਵੱਲੋਂ ਵਰਤਿਆ ਜਾਂਦਾ ਹੈ; ਉਦਦੇਸ਼ ਮਿਲਦਾ ਜੁਲਦਾ ਹੈ ਅਤੇ ਅਕਸਰ tracing ਲਾਇਬ੍ਰੇਰੀਜ਼ ਦੁਆਰਾ ਜਨਰੇਟ ਹੁੰਦਾ ਹੈ।
- Session ID: ਇਕ ਯੂਜ਼ਰ ਸੈਸ਼ਨ ਨੂੰ ਕਵਰ ਕਰਦਾ ਹੈ; ਇੱਕੋ ਘਟਨਾ ਨੂੰ ਡੀਬੱਗ ਕਰਨ ਲਈ ਬਹੁਤ ਵਿਆਪਕ ਹੁੰਦਾ ਹੈ।
ਉਦਾਹਰਣ ਵਧੀਆ ਹੋਣ ਦੀ ਇੱਕ ਸਿੱਧੀ ਤਸਵੀਰ ਇਹ ਹੈ: ਯੂਜ਼ਰ ਇੱਕ ਸਮੱਸਿਆ ਰਿਪੋਰਟ ਕਰਦਾ ਹੈ, ਤੁਸੀਂ UI 'ਤੇ (ਜਾਂ support ਸਕ੍ਰੀਨ 'ਤੇ) ਦਿਖਾਈ ਦੇ ਰਹੀ correlation ID ਪੁੱਛਦੇ ਹੋ, ਅਤੇ ਟੀਮ ਦਾ ਕੋਈ ਵੀ ਮੈਂਬਰ ਕੁਝ ਮਿੰਟਾਂ ਵਿੱਚ ਪੂਰੀ ਕਹਾਣੀ ਲੱਭ ਸਕਦਾ ਹੈ। ਤੁਸੀਂ frontend request, API response, backend ਕਦਮ ਅਤੇ ਡੇਟਾਬੇਸ ਨਤੀਜੇ ਸਾਰੇ ਇਕੱਠੇ ਦੇਖਦੇ ਹੋ।
ਆਪਣੀਆਂ correlation ID conventions ਫੈਸਲੋ
ਕਿਸੇ ਵੀ ID ਨੂੰ ਜਨਰੇਟ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ ਕੁਝ ਨਿਯਮਾਂ 'ਤੇ ਸਹਿਮਤ ਹੋ ਜਾਓ। ਜੇ ਹਰ ਟੀਮ ਵੱਖਰਾ header ਨਾਮ ਜਾਂ log field ਚੁੰਨੇਗੀ ਤਾਂ support ਫਿਰ ਵੀ ਅਨੁਮਾਨ ਲਗਾਉਣ 'ਤੇ ਮਜਬੂਰ ਰਹੇਗੀ।
ਇੱਕ canonical ਨਾਮ ਲਓ ਅਤੇ ਹਰ ਜਗ੍ਹਾ ਇਸਦੀ ਵਰਤੋਂ ਕਰੋ। ਆਮ ਚੋਣ ਇੱਕ HTTP header ਹੈ ਜਿਵੇਂ X-Correlation-Id, ਨਾਲ ਹੀ ਇੱਕ structured log field ਜਿਵੇਂ correlation_id। ਇੱਕ ਵਰਣਨ ਅਤੇ casing ਚੁਣੋ, ਦਸਤਾਵੇਜ਼ ਬਣਾਓ, ਅਤੇ ਯਕੀਨੀ ਬਣਾਓ ਕਿ ਤੁਹਾਡਾ reverse proxy ਜਾਂ gateway header ਨੂੰ rename ਜਾਂ drop ਨਹੀਂ ਕਰੇगा।
ਇੱਕ ਐਸਾ ਫਾਰਮੈਟ ਚੁਣੋ ਜੋ ਬਣਾਉਣਾ ਆਸਾਨ ਹੋਵੇ ਅਤੇ tickets ਅਤੇ chats ਵਿੱਚ ਸਾਂਝਾ ਕਰਨ ਲਈ ਸੁਰੱਖਿਅਤ ਹੋਵੇ। UUIDs ਚੰਗੇ ਕੰਮ ਕਰਦੇ ਹਨ ਕਿਉਂਕਿ ਉਹ unique ਅਤੇ ਸਾਦੇ ਹੁੰਦੇ ਹਨ। ID ਕਾਫ਼ੀ ਛੋਟੀ ਰੱਖੋ ਤਾਂ ਜੋ ਕਾਪੀ ਕਰਨ ਵਿੱਚ ਆਸਾਨੀ ਹੋਵੇ, ਪਰ ਐਨੀ ਛੋਟੀ ਨਾ ਕਿ collision ਦਾ ਖਤਰਾ ਰਹੇ। ਲਗਾਤਾਰਤਾ ਚਤੁਰਾਈ ਤੋਂ ਵਧ ਕੇ ਮਹੱਤਵਪੂਰਨ ਹੈ।
ਇਹ ਵੀ ਫੈਸਲੋ ਕਿ ID ਕਿੱਥੇ-ਕਿੱਥੇ ਦਿਖਾਈ ਦੇਵੇ ਤਾਂ ਕਿ ਮਨੁੱਖ ਵਰਗੀਆਂ ਚੀਜ਼ਾਂ ਇਸਦਾ ਉਪਯੋਗ ਕਰ ਸਕਣ। ਅਮਲ ਵਿੱਚ ਇਹ ਮਤਲਬ ਹੈ ਕਿ ਇਹ requests, logs, ਅਤੇ error outputs ਵਿੱਚ ਮੌਜੂਦ ਹੋਵੇ ਅਤੇ ਜਿਸ ਟੂਲ ਨੂੰ ਟੀਮ ਵਰਤਦੀ ਹੈ ਉਸ ਵਿੱਚ searchable ਹੋਵੇ।
ਇੱਕ ID ਦੀ ਉਮਰ ਕਿੰਨੀ ਹੋਵੇ ਇਹ ਵੀ ਨਿਰਧਾਰਤ ਕਰੋ। ਇੱਕ ਚੰਗਾ ਡਿਫੌਲਟ ਇੱਕ ਯੂਜ਼ਰ ਕਾਰਵਾਈ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ, ਜਿਵੇਂ "clicked Pay" ਜਾਂ "saved profile." ਲੰਬੇ ਵਰਕਫਲੋਜ਼ ਲਈ ਜੋ ਸਰਵਿਸਾਂ ਅਤੇ queues ਦੇ ਰਾਹੀਂ ਜਾਂਦੇ ਹਨ, ਇੱਕੋ ID ਉਹਨਾਂ ਦੌਰਾਨ ਰੱਖੋ ਅਤੇ ਫਿਰ ਅਗਲੇ ਐਕਸ਼ਨ ਲਈ ਨਵੀਂ ਸ਼ੁਰੂ ਕਰੋ। "ਸਾਰੀ session ਲਈ ਇੱਕ ID" ਤੋਂ ਬਚੋ ਕਿਉਂਕਿ search 결과 ਜਲਦੀ noisy ਹੋ ਜਾਂਦੇ ਹਨ।
ਇੱਕ ਸਖ਼ਤ ਨਿਯਮ: ID ਵਿੱਚ ਕਦੇ ਵੀ ਨਿੱਜੀ ਡਾਟਾ ਨਾ ਪਾਓ। ਕੋਈ emails, phone numbers, user IDs ਜਾਂ order numbers ਨਹੀਂ। ਜੇ ਤੁਹਾਨੂੰ ਉਹ ਸੰਦਰਭ ਚਾਹੀਦਾ ਹੈ ਤਾਂ ਉਨ੍ਹਾਂ ਨੂੰ ਵੱਖਰੇ ਫੀਲਡਾਂ ਵਿੱਚ ਲੌਗ ਕਰੋ ਜਿਨ੍ਹਾਂ ਉੱਤੇ ਪ੍ਰਾਈਵੇਸੀ ਨਿਯੰਤਰਣ ਲਾਗੂ ਹੋਵੇ।
ਫਰੰਟਐਂਡ ਵਿੱਚ ID ਜਨਰੇਟ ਕਰੋ (ਵਿਆਵਹਾਰਿਕ ਤਰੀਕਾ)
ਸਰਲ ਥਾਂ ਜੋ correlation ID ਸ਼ੁਰੂ ਕਰਨ ਲਈ ਸਭ ਤੋਂ ਵਧੀਆ ਹੈ ਉਹ ਹੈ ਜਦ ਯੂਜ਼ਰ ਉਹ ਕਾਰਵਾਈ ਸ਼ੁਰੂ ਕਰਦਾ ਹੈ ਜਿਸਦੀ ਤੁਸੀਂ ਪਰਵਾਹ ਕਰਦੇ ਹੋ: "Save" ਤੇ ਕਲਿੱਕ, ਫਾਰਮ ਭੇਜਣਾ, ਜਾਂ ਕੋਈ ਅਜਿਹਾ ਫਲੋ ਜੋ ਕਈ ਰਿਕਵੇਸਟਾਂ ਨੂੰ ਯਾਤਰਾ ਕਰਾਉਂਦਾ ਹੈ। ਜੇ ਤੁਸੀਂ backend ਦੇ ਬਣਾਉਣ ਦੀ ਉਮੀਦ ਰੱਖਦੇ ਹੋ ਤਾਂ ਅਕਸਰ UI errors, ਰੀਟ੍ਰਾਈਜ਼ ਜਾਂ ਰੱਦ ਹੋਈਆਂ requestਾਂ ਦਾ ਪਹਿਲਾ ਹਿੱਸਾ ਖੋ ਜਾਂਦਾ ਹੈ।
ਇੱਕ random, unique ਫਾਰਮੈਟ ਵਰਤੋ। UUID v4 ਆਮ ਚੋਣ ਹੈ ਕਿਉਂਕਿ ਇਹ ਬਣਾਉਣ ਵਿੱਚ ਆਸਾਨ ਹੈ ਅਤੇ collision ਦੀ ਸੰਭਾਵਨਾ ਘੱਟ ਹੈ। ID ਨੂੰ opaque ਰੱਖੋ (ਕੋਈ usernames, emails ਜਾਂ timestamps ਨਾ ਲਿਖੋ) ਤਾਂ ਜੋ header ਅਤੇ logs ਵਿੱਚ ਨਿੱਜੀ ਡਾਟਾ leak ਨਾ ਹੋਏ।
ਇੱਕ ਵਰਕਫਲੋ ਲਈ ID ਬਣਾਓ ਅਤੇ ਰੱਖੋ
ਇੱਕ "ਵਰਕਫਲੋ" ਨੂੰ ਉਸ ਇੱਕ ਯੂਜ਼ਰ ਕਾਰਵਾਈ ਵਜੋਂ treat ਕਰੋ ਜੋ ਕਈ ਰਿਕਵੇਸਟਾਂ ਨੂੰ trigger ਕਰ ਸਕਦੀ ਹੈ: validate, upload, create record, ਫਿਰ lists refresh। ਜਦ ਵਰਕਫਲੋ ਸ਼ੁਰੂ ਹੁੰਦਾ ਹੈ ਤਾਂ ਇੱਕ ID ਬਣਾਓ ਅਤੇ ਜਦ ਤੱਕ ਵਰਕਫਲੋ ਖਤਮ ਨਹੀਂ ਹੁੰਦਾ (success, failure, ਜਾਂ user cancel) ਇਸਨੂੰ ਰੱਖੋ। ਇੱਕ ਸਧਾਰਣ ਪੈਟਰਨ ਇਹ ਹੈ ਕਿ ਇਸਨੂੰ component state ਜਾਂ ਇੱਕ ਹੌਲਕਾ request context object ਵਿੱਚ store ਕਰ ਲਓ।
ਜੇ ਯੂਜ਼ਰ ਇੱਕੋ ਕਰਵਾਈ ਦੋ ਵਾਰੀ ਸ਼ੁਰੂ ਕਰਦਾ ਹੈ ਤਾਂ ਦੂਜੇ ਯਤਨ ਲਈ ਨਵੀਂ correlation ID ਬਣਾਓ। ਇਸ ਨਾਲ support ਨੂੰ ਇਹ ਫਰਕ ਸਮਝ ਆਉਂਦਾ ਹੈ ਕਿ "ਇਕੋ ਕਲਿੱਕ ਰੀਟ੍ਰਾਈ" ਹੈ ਜਾਂ "ਦੋ ਵੱਖ-ਵੱਖ submissions"।
ਉਸ ਵਰਕਫਲੋ ਦੀ ਹਰ ਰਿਕਵੇਸਟ ਨਾਲ attach ਕਰੋ
ਉਸ ਵਰਕਫਲੋ ਦੁਆਰਾ ਕੀਤੀਆਂ ਹਰ API call ਵਿੱਚ ID ਜੋੜੋ, ਆਮ ਤੌਰ 'ਤੇ ਇੱਕ header ਜਿਵੇਂ X-Correlation-ID ਰਾਹੀਂ। ਜੇ ਤੁਹਾਡੇ ਕੋਲ ਇੱਕ shared API client (fetch wrapper, Axios instance ਆਦਿ) ਹੈ ਤਾਂ ਇਕ ਵਾਰੀ ID ਪਾਸ ਕਰੋ ਅਤੇ client ਸਾਰੇ calls ਵਿੱਚ ਇਹ header inject ਕਰ ਦੇਵੇ।
const correlationId = crypto.randomUUID();
await api.post('/orders', payload, {
headers: { 'X-Correlation-ID': correlationId }
});
await api.get('/orders/summary', {
headers: { 'X-Correlation-ID': correlationId }
});
ਜੇ ਤੁਸੀਂ UI ਵਿੱਚ ਕੁਝ background requests ਕਰ ਰਹੇ ਹੋ ਜੋ ਕਾਰਵਾਈ ਨਾਲ ਸਬੰਧਤ ਨਹੀਂ ਹਨ (polling, analytics, auto-refresh), ਉਹਨਾਂ ਲਈ ਵਰਕਫਲੋ ID ਰੀਉਜ਼ ਨਾ ਕਰੋ। ਕੋਰਲੇਸ਼ਨ IDs ਨੂੰ ਮਕਸਦ-ਕੇਂਦ੍ਰਿਤ ਰੱਖੋ ਤਾਂ ਜੋ ਇੱਕ ID ਇੱਕ ਸਪਸ਼ਟ ਕਹਾਣੀ ਦੱਸੇ।
ਆਪਣੇ APIs ਰਾਹੀਂ ID ਨੂੰ ਭਰੋਸੇਯੋਗ ਢੰਗ ਨਾਲ ਪਾਸ ਕਰੋ
ਜਦ ਤੁਸੀਂ ਬਰਾਊਜ਼ਰ ਵਿੱਚ correlation ID ਬਣਾਉਂਦੇ ਹੋ, ਅੱਗੇ ਦਾ ਕੰਮ ਸਧਾਰਣ ਹੈ: ਇਹ frontend ਤੋਂ ਹਰ request ਨਾਲ ਬਾਹਰ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ ਅਤੇ ਹਰ API ਬਾਰਡਰ 'ਤੇ ਬਿਨਾ ਬਦਲੇ ਪਹੁੰਚਣਾ ਚਾਹੀਦਾ ਹੈ। ਇਹੀ ਜ਼ਿਆਦਾਤਰ ਵਾਰ ਟੁੱਟਦਾ ਹੈ ਜਦ ਟੀਮਾਂ ਨਵੇਂ endpoints, ਨਵੇਂ clients ਜਾਂ ਨਵੀਂ middleware ਜੋੜਦੀਆਂ ਹਨ।
ਸੁਰੱਖਿਅਤ ਡਿਫੌਲਟ ਇੱਕ HTTP header ਹਰ call 'ਤੇ (ਉਦਾਹਰਣ X-Correlation-Id) ਰੱਖਣਾ ਹੈ। headers ਇੱਕ ਹੀ ਥਾਂ (fetch wrapper, Axios interceptor, mobile networking layer) ਵਿੱਚ ਜੋੜਨ ਲਈ ਆਸਾਨ ਹੁੰਦੇ ਹਨ ਅਤੇ payloads ਬਦਲਣ ਦੀ ਲੋੜ ਨਹੀਂ ਪੈਂਦੀ।
ਜੇ ਤੁਹਾਡੇ ਕੋਲ cross-origin requests ਹਨ ਤਾਂ ਯਕੀਨੀ ਬਣਾਓ ਕਿ ਤੁਹਾਡੀ API ਉਹ header allow ਕਰਦੀ ਹੈ। ਨਹੀਂ ਤਾਂ browser ਇਸਨੂੰ ਚੁੱਪ ਕਰਕੇ ਰੋਕ ਸਕਦਾ ਹੈ ਅਤੇ ਤੁਸੀਂ ਸੋਚੋਗੇ ਕਿ ਤੁਸੀਂ ਭੇਜ ਰਹੇ ਹੋ ਪਰ ਅਸਲ ਵਿੱਚ ਨਹੀਂ ਭੇਜ ਰਹੇ।
ਜੇ ਤੁਹਾਨੂੰ ID query string ਜਾਂ request body ਵਿੱਚ ਪਾਉਣੀ ਪੈਂਦੀ ਹੈ (ਕੁਝ ਤਫ਼ਰੀਤੀ ਟੂਲ ਜਾਂ file uploads ਇਹ ਮੰਗ ਸਕਦੇ ਹਨ), ਤਾਂ ਇਸਨੂੰ consistent ਰੱਖੋ ਅਤੇ ਦਰਜ ਕਰੋ। ਇਕ ਹੀ field ਨਾਮ ਚੁਣੋ ਅਤੇ ਹਰ ਥਾਂ ਇਸਦੀ ਵਰਤੋਂ ਕਰੋ। correlationId, requestId ਅਤੇ cid ਨੂੰ endpoint-ਵਾਰ ਮਿਕਸ ਨਾ ਕਰੋ।
ਰੀਟ੍ਰਾਈਜ਼ ਹੋਰ ਇੱਕ ਆਮ ਫੈਸਲਾ ਹੈ। ਜੇ ਰੀਟ੍ਰਾਈ ਉਹੀ ਯੂਜ਼ਰ ਕਾਰਵਾਈ ਹੀ ਹੈ ਤਾਂ ਉਹੀ correlation ID ਰੱਖਣੀ ਚਾਹੀਦੀ ਹੈ। ਉਦਾਹਰਣ: ਯੂਜ਼ਰ "Save" ਤੇ ਕਲਿੱਕ ਕਰਦਾ ਹੈ, ਨੈੱਟਵਰਕ ਡ੍ਰਾਪ ਹੋ ਜਾਂਦਾ ਹੈ, ਤੁਹਾਡਾ client POST retry ਕਰਦਾ ਹੈ। support ਨੂੰ ਇੱਕ ਜੁੜਿਆ ਹੋਇਆ ਟ੍ਰੇਲ ਦੇਖਣਾ ਚਾਹੀਦਾ ਹੈ, ਨਾ ਕਿ ਤਿੰਨ ਅਲੱਗ-ਅਲੱਗ। ਨਵਾਂ ਯੂਜ਼ਰ ਕਲਿੱਕ (ਜਾਂ ਨਵਾਂ ਬੈਕਗ੍ਰਾਊਂਡ ਜੌਬ) ਨਵੀਂ ID ਬਣਾਏ।
WebSockets ਲਈ, ID ਨੂੰ message envelope ਵਿੱਚ ਸ਼ਾਮਲ ਕਰੋ, ਸਿਰਫ initial handshake ਵਿੱਚ ਨਹੀਂ। ਇੱਕ connection ਕਈ ਯੂਜ਼ਰ ਕਾਰਵਾਈਆਂ ਲੈ ਜਾ ਸਕਦੀ ਹੈ।
ਇੱਕ ਤੇਜ਼ reliability ਚੈਕ ਲਈ, ਸਧਾਰਨ ਰਖੋ:
- ਇੱਕ shared client helper ਹਰ request 'ਤੇ header ਜੋੜਦਾ ਹੈ।
- ਰੀਟ੍ਰਾਈਜ਼ ਉਹੀ ID reuse ਕਰਦੇ ਹਨ ਜੇ ਉਹੀ ਕਾਰਵਾਈ ਹੈ।
- ਕਿਸੇ body/query fallback ਲਈ ਇੱਕ ਦਸਤਾਵੇਜ਼ਬੱਧ field ਨਾਮ ਹੈ।
- WebSocket messages ਵਿੱਚ explicit
correlationId ਫੀਲਡ ਹੋਵੇ।
API entry point ਵਿਵਹਾਰ ਸੈੱਟ ਕਰੋ
ਇੱਕ ਭਰੋਸੇਯੋਗ API entry ਨੀਤੀ ਸੈੱਟ ਕਰੋ
gateway ਲੌਜਿਕ ਬਣਾਓ ਜੋ X-Correlation-ID ਨੂੰ ਸਵੀਕਾਰ, ਵੈਲਿਡੇਟ ਅਤੇ ਆਪੋ-ਆਪ echo ਕਰੇ।
ਤੁਹਾਡਾ API edge (gateway, load balancer, ਜਾਂ ਪਹਿਲੀ web service) ਉਹ ਥਾਂ ਹੈ ਜਿੱਥੇ correlation IDs ਭਰੋਸੇਯੋਗ ਬਣ ਜਾਂਦੇ ਹਨ ਜਾਂ ਅਨੁਮਾਨ ਦਾ ਖੇਤਰ ਬਣ ਜਾਂਦੇ ਹਨ। ਇਸ entry point ਨੂੰ source of truth ਸਮਝੋ।
ਆਉਣ ਵਾਲੀ ID ਨੂੰ ਸਵੀਕਾਰ ਕਰੋ ਜੇ client ਭੇਜੇ, ਪਰ ਇਹ ਮੰਨ ਕੇ ਨਹੀਂ ਚਲੋ ਕਿ ਸਦਾ ਹੋਵੇਗੀ। ਜੇ ਇਹ ਮੌਜੂਦ ਨਹੀਂ ਹੈ ਤਾਂ ਤੁਰੰਤ ਨਵੀਂ ਬਣਾਓ ਅਤੇ ਬਾਕੀ ਰਿਕਵੈਸਟ ਲਈ ਇਸਦੀ ਵਰਤੋਂ ਕਰੋ। ਇਹ ਉਨ੍ਹਾਂ clients ਨੂੰ ਕੰਮ ਕਰਨ ਦੇ ਯੋਗ ਬਣਾਉਂਦਾ ਹੈ ਜੋ ਥੋੜੇ ਪੁਰਾਣੇ ਜਾਂ ਗਲਤ ਕਨਫਿਗਰਡ ਹੋ ਸਕਦੇ ਹਨ।
ਖ਼ਰਾਬ ਮੁੱਲਾਂ ਨੂੰ ਤੁਹਾਡੇ ਲੌਗਾਂ ਵਿੱਚ ਨਾਚੀਨ ਕਰਨ ਤੋਂ ਰੋਕਣ ਲਈ ਹਲਕੀ ਵੈਲਿਡੇਸ਼ਨ ਕਰੋ। ਪਰ ਇੱਟਨੀ ਕਠੋਰ ਨਾ ਕਰੋ ਕਿ ਉਹ ਅਸਲੀ ਟ੍ਰੈਫਿਕ ਨੂੰ reject ਕਰ ਦੇਵੇ। ਉਦਾਹਰਣ ਵਜੋਂ 16-64 ਅੱਖਰ ਅਤੇ letters, numbers, dash, underscore allow ਕਰੋ। ਜੇ value validation fail ਕਰਦੀ ਹੈ ਤਾਂ ਇੱਕ ਤਾਜ਼ਾ ID ਨਾਲ ਬਦਲ ਦਿਓ ਅਤੇ ਅੱਗੇ ਵਧੋ।
ਕਾਲਰ ਨੂੰ ID ਦਿਖਾਉਣਾ ਯਕੀਨੀ ਬਣਾਓ। ਹਮੇਸ਼ਾਂ ਇਸਨੂੰ response headers ਵਿੱਚ ਵਾਪਸ ਦਿਓ ਅਤੇ error bodies ਵਿੱਚ ਸ਼ਾਮਲ ਕਰੋ। ਇਸ ਤਰ੍ਹਾਂ ਯੂਜ਼ਰ UI ਤੋਂ ਕਾਪੀ ਕਰ ਸਕਦਾ ਹੈ, ਜਾਂ support agent ਇਸ ਨੂੰ ਪੁੱਛ ਕੇ ਬਿਲਕੁਲ ਠੀਕ ਲੌਗ ਟ੍ਰੇਲ ਲੱਭ ਸਕਦਾ ਹੈ।
ਇੱਕ ਵਿਵਹਾਰਿਕ edge policy ਇਸ ਤਰ੍ਹਾਂ ਦਿਖਦੀ ਹੈ:
- ਰਿਕਵੇਸਟ ਤੋਂ
X-Correlation-ID (ਜਾਂ ਤੁਹਾਡਾ ਚੁਣਿਆ header) ਪੜ੍ਹੋ।
- ਜੇ ਮਿਸਿੰਗ ਜਾਂ invalid ਹੋਵੇ, ਇੱਕ ਨਵੀਂ ID ਬਣਾਓ ਅਤੇ request context ਨਾਲ attach ਕਰੋ।
- ਹਰ response (errors ਸਮੇਤ) ਵਿੱਚ
X-Correlation-ID ਜੋੜੋ।
- JSON errors ਵਾਪਸ ਕਰਦੇ ਸਮੇਂ, payload ਵਿੱਚ ID echo ਕਰੋ।
Example error payload (ਜੋ support ਟਿਕਟਾਂ ਅਤੇ ਸਕ੍ਰੀਨਸ਼ਾਟ ਵਿੱਚ ਦਿਖਾਈ ਦਿੰਦਾ ਹੈ):
{
"error": {
"code": "PAYMENT_FAILED",
"message": "We could not confirm the payment.",
"correlation_id": "c3a8f2d1-9b24-4c61-8c4a-2a7c1b9c2f61"
}
}
backend ਸਰਵਿਸਿਜ਼ ਵਿੱਚ ID propagate ਕਰੋ
ਜਦ request ਤੁਹਾਡੇ backend 'ਤੇ ਪਹੁੰਚਦੀ ਹੈ, correlation ID ਨੂੰ request context ਦਾ ਹਿੱਸਾ ਸਮਝੋ, ਨਾ ਕਿ ਕਿਸੇ global variable ਵਿੱਚ ਸਟੋਰ ਕਰੋ। ਗਲੋਬਲ ਉਹ ਵੇਲੇ ਟੁੱਟ ਜਾਂਦੇ ਹਨ ਜਦ ਤੁਸੀਂ ਇੱਕੋ ਸਮੇਂ ਦੋ requests handle ਕਰਦੇ ਹੋ ਜਾਂ ਜਦ async ਕੰਮ response ਤੋਂ ਬਾਅਦ ਜਾਰੀ ਰਹਿੰਦਾ ਹੈ।
ਇੱਕ scale ਕਰਨ ਵਾਲਾ ਨਿਯਮ: ਹਰ ਫੰਕਸ਼ਨ ਜੋ ਲੌਗ ਕਰ ਸਕਦਾ ਹੈ ਜਾਂ ਹੋਰ ਸਰਵਿਸ ਨੂੰ ਕਾਲ ਕਰਦਾ ਹੈ, ਉਸਨੂੰ ਉਸ context ਨਾਲ ਮਿਲਣਾ ਚਾਹੀਦਾ ਹੈ ਜਿਸ ਵਿੱਚ ID ਹੈ। Go ਸਰਵਿਸਿਜ਼ ਵਿੱਚ ਇਹ ਅਕਸਰ context.Context ਪਾਸ ਕਰਕੇ ਕੀਤਾ ਜਾਂਦਾ ਹੈ।
ਜੇ Service A Service B ਨੂੰ ਕਾਲ ਕਰਦਾ ਹੈ ਤਾਂ ਉਹੀ ID outgoing request ਵਿੱਚ ਨਕਲ ਕਰੋ। ਮਧਯ-ਉਡਾਣ ਵਿੱਚ ਨਵਾਂ ID ਨਾ ਬਣਾਉ ਜਦ ਤੱਕ ਤੁਸੀਂ оригинਲ ਨੂੰ parent ਨਾ ਰੱਖੋ (ਉਦਾਹਰਣ parent_correlation_id)। ID ਬਦਲਣ ਨਾਲ support ਨੂੰ ਉਸ ਇੱਕ ਧਾਗੇ ਨੂੰ ਖੋ ਜਾਣ ਵਿੱਚ ਮੁਸ਼ਕਿਲ ਆਉਂਦੀ ਹੈ ਜੋ ਕਹਾਣੀ ਜੋੜਦਾ ਹੈ।
Propagation ਅਕਸਰ ਕੁਝ ਪੂਰਵਾਨੁਮਾਨੀ ਥਾਵਾਂ 'ਤੇ ਛੁੱਟ ਜਾਂਦੀ ਹੈ: ਰਿਕਵੇਸਟ ਦੌਰਾਨ kicked-off background jobs, client ਲਾਇਬ੍ਰੇਰੀਆਂ ਦੇ ਅੰਦਰ ਰੀਟ੍ਰਾਈਜ਼, ਬਾਅਦ ਵਿੱਚ trigger ਹੋਣ ਵਾਲੇ webhooks, ਅਤੇ fan-out calls। ਕੋਈ ਵੀ async message (queue/job) ID ਲੈ ਕੇ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ, ਅਤੇ ਕੋਈ ਵੀ retry ਲੌਜਿਕ ਇਸਨੂੰ preserve ਕਰੇ।
ਲੌਗਾਂ ਨੂੰ structured ਰੱਖੋ ਅਤੇ ਇੱਕ ਸਥਿਰ ਫੀਲਡ ਨਾਮ ਜਿਵੇਂ correlation_id ਵਰਤੋ। ਇੱਕ ਹੀ spelling ਰੱਖੋ ਅਤੇ ਹਰ ਜਗ੍ਹਾ ਇਸਨੂੰ follow ਕਰੋ। requestId, req_id, ਅਤੇ traceId ਮਿਲਾਉਣ ਤੋਂ ਬਚੋ ਜੇ ਤੱਕ ਤੁਹਾਡੇ ਕੋਲ ਇੱਕ ਸਪਸ਼ਟ mapping ਨਾ ਹੋਵੇ।
ਜੇ ਸੰਭਵ ਹੋਵੇ ਤਾਂ ID ਨੂੰ ਡੇਟਾਬੇਸ ਵਿਜ਼ਿਬਿਲਿਟੀ ਵਿੱਚ ਵੀ ਸ਼ਾਮਲ ਕਰੋ। ਇੱਕ ਵਿਆਵਹਾਰਿਕ ਤਰੀਕਾ ਇਹ ਹੈ ਕਿ ਇਸਨੂੰ query comments ਜਾਂ session metadata ਵਿੱਚ ਜੋੜੋ ਤਾਂ ਕਿ slow query logs ਵਿੱਚ ਵੀ ਇਹ ਦਿਖਾਈ ਦੇਵੇ। ਜਦ ਕੋਈ ਵਿਅਕਤੀ ਰਿਪੋਰਟ ਕਰਦਾ ਹੈ "Save button 10 ਸਕਿੰਟ ਲਈ hang ਹੋ ਗਿਆ," support correlation_id=abc123 ਲੱਭ ਕੇ API ਲੌਗ, downstream calls ਅਤੇ ਉਹ ਮੰਨ੍ਹਾ slow SQL statement ਵੇਖ ਸਕਦਾ ਹੈ।
ਉਹ ਲੌਗਾਂ ਵਿੱਚ ID ਸ਼ਾਮਲ ਕਰੋ ਜੋ ਮਨੁੱਖ ਵਰਤੇ
ਕੋਰਲੇਸ਼ਨ ID ਸਿਰਫ਼ ਉਤਨਾ ਫਾਇਦਾ ਕਰਦਾ ਹੈ ਜਿੰਨਾ ਕਿ ਲੋਕ ਇਸਨੂੰ ਲੱਭ ਸਕਣ ਤੇ follow ਕਰ ਸਕਣ। ਇਸਨੂੰ ਇੱਕ first-class log field ਬਣਾਓ (message string ਵਿੱਚ ਛੁਪਿਆ ਨਾ ਰੱਖੋ), ਅਤੇ ਹਰ ਸਰਵਿਸ ਵਿੱਚ ਲੌਗ entry ਦਾ structure consistent ਰੱਖੋ।
ਲੌਗ ਫੀਲਡ ਜੋ ID ਨੂੰ ਵਰਤਣਯੋਗ ਬਣਾਉਂਦੇ ਹਨ
correlation ID ਨੂੰ ਕੁਝ ਛੋਟੇ ਫੀਲਡਾਂ ਨਾਲ ਜੋੜੋ ਜੋ ਇਹ ਦੱਸਦੇ ਹਨ: ਕਦੋਂ, ਕਿੱਥੇ, ਕੀ ਅਤੇ ਕਿਸ ਲਈ (user-safe ਤਰੀਕੇ ਨਾਲ)। ਬਹੁਤ ਟੀਮਾਂ ਲਈ ਇਹ ਅਰਥ ਹੈ:
timestamp (timezone ਸਮੇਤ)service ਅਤੇ env (api, worker, prod, staging)route (ਜਾਂ operation name) ਅਤੇ methodstatus ਅਤੇ duration_ms- ਇੱਕ user-safe identifier (ਉਦਾਹਰਣ
account_id ਜਾਂ hashed user id, email ਨਹੀਂ)
ਇਸ ਨਾਲ support correlation ID ਦੁਆਰਾ search ਕਰਕੇ ਪੁਸ਼ਟੀ ਕਰ ਸਕਦਾ ਹੈ ਕਿ ਉਹ ਸਹੀ request ਦੇਖ ਰਿਹਾ ਹੈ ਅਤੇ ਕਿਹੜੀ ਸਰਵਿਸ ਨੇ ਇਸਨੂੰ ਸੰਭਾਲਿਆ।
start, success, ਅਤੇ failure 'ਤੇ ਕੀ ਲੌਗ ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ
ਹਰ request ਲਈ ਕਈ ਮਜ਼ਬੂਤ breadcrumbs ਰੱਖੋ, ਪੂਰਾ transcript ਨਹੀਂ।
- Start: correlation ID, route, safe user identifier, ਅਤੇ ਮੁੱਖ inputs (ਸੰਖੇਪ ਵਿੱਚ)।
- Success: correlation ID, status, duration, ਅਤੇ ਛੋਟਾ outcome (ਉਦਾਹਰਣ
rows=12).
- Failure: correlation ID, error type, safe context, ਅਤੇ ਕਿੱਥੇ ਹੋਇਆ (handler, dependency)।
ਜ਼ਿਆਦਾ noisy ਲੌਗਾਂ ਤੋਂ ਬਚਣ ਲਈ default ਤੇ debug-level ਵੇਰਵੇ ਨਾ ਰੱਖੋ; ਸਿਰਫ ਉਹ events promote ਕਰੋ ਜੋ ਕਿਸੇ ਨੂੰ ਇਹ ਸਵਾਲ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਦੇ ਹਨ, "ਇੱਥੇ ਕਿੱਥੇ fail ਹੋਇਆ?" ਜੇ ਕੋਈ ਲਾਈਨ ਸਮੱਸਿਆ ਲੱਭਣ ਜਾਂ ਪ੍ਰਭਾਵ ਮਾਪਣ ਵਿੱਚ ਮਦਦ ਨਹੀਂ ਕਰਦੀ ਤਾਂ ਉਹ info-level 'ਤੇ ਰਹਿਣੀ ਚਾਹੀਦੀ ਨਹੀਂ।
Redaction structure 만큼 ਮਹੱਤਵਪੂਰਨ ਹੈ। ਕੋਰਲੇਸ਼ਨ ID ਜਾਂ ਲੌਗਸ ਵਿੱਚ ਕਦੇ ਵੀ PII ਨਾ ਰੱਖੋ: ਕੋਈ emails, names, phone numbers, ਪੂਰੇ ਪਤੇ ਜਾਂ raw tokens ਨਹੀਂ। ਜੇ ਤੁਹਾਨੂੰ ਯੂਜ਼ਰ ਪਛਾਣਨੀ ਭਰਤੀ ਹੈ ਤਾਂ ਇੱਕ ਅੰਦਰੂਨੀ ID ਜਾਂ one-way hash ਲੌਗ ਕਰੋ।
ਉਦਾਹਰਣ: UI ਤੋਂ ਡੇਟਾਬੇਸ ਤੱਕ ਇੱਕ ਯੂਜ਼ਰ ਰਿਪੋਰਟ ਟਰੇਸ ਕਰਨਾ
ਸਪੋਰਟ-ਤਿਆਰ error ਸਕ੍ਰੀਨ ਭੇਜੋ
ਉਹ UI error ਬਣਾਓ ਜੋ ਤੇਜ਼ ਟਿਕਟ ਲਈ ਕਾਪੀ ਕਰਨ ਯੋਗ correlation ID ਦਿਖਾਉਂਦਾ ਹੈ।
ਇੱਕ ਯੂਜ਼ਰ support ਨੂੰ message ਕਰਦਾ ਹੈ: "Checkout failed when I clicked Pay." ਸਭ ਤੋਂ ਵਧੀਆ follow-up ਸਵਾਲ ਸਧਾਰਨ ਹੈ: "ਕੀ ਤੁਸੀਂ error ਸਕ੍ਰੀਨ 'ਤੇ ਦਿਖਾਈ ਦੇ ਰਹੀ correlation ID ਪੇਸਟ ਕਰ ਸਕਦੇ ਹੋ?" ਉਹ cid=9f3c2b1f6a7a4c2f ਨਾਲ ਵਾਪਸ ਆਉਂਦੇ ਹਨ।
ਹੁਣ support ਕੋਲ ਇੱਕ ਹਥਿਆਰ ਹੈ ਜੋ UI, API ਅਤੇ ਡੇਟਾਬੇਸ ਕੰਮ ਨੂੰ ਜੋੜਦਾ ਹੈ। ਲਕੜੀ ਇਹ ਹੈ ਕਿ ਉਸ ਕਾਰਵਾਈ ਲਈ ਹਰ ਲੌਗ ਲਾਈਨ ਉਹੀ ID ਰੱਖਦੀ ਹੋਵੇ।
Support 9f3c2b1f6a7a4c2f ਲਈ ਲੌਗ ਖੋਜਦਾ ਹੈ ਅਤੇ ਫਲੋ ਨੂੰ ਵੇਖਦਾ ਹੈ:
frontend INFO cid=9f3c2b1f6a7a4c2f event="checkout_submit" cart=3 items
api INFO cid=9f3c2b1f6a7a4c2f method=POST path=/api/checkout user=1842
api ERROR cid=9f3c2b1f6a7a4c2f msg="payment failed" provider=stripe status=502
ਉੱਥੋਂ, ਇੰਜੀਨੀਅਰ ਉਹੀ ID ਅਗਲੇ ਹੋਪ ਵਿੱਚ follow ਕਰਦਾ ਹੈ। ਮੁੱਖ ਗੱਲ ਇਹ ਹੈ ਕਿ backend ਸੇਵਾ ਕਾਲਾਂ (ਅਤੇ ਕੋਈ queue jobs) ਵੀ ਉਹੀ ID ਭੇਜਦੀਆਂ ਹਨ।
payments INFO cid=9f3c2b1f6a7a4c2f action="charge" amount=49.00 currency=USD
payments ERROR cid=9f3c2b1f6a7a4c2f err="timeout" upstream=stripe timeout_ms=3000
db INFO cid=9f3c2b1f6a7a4c2f query="insert into failed_payments" rows=1
ਹੁਣ ਸਮੱਸਿਆ ਸਪਸ਼ਟ ਹੈ: payments service 3 ਸੈਕੇਂਡ ਦੇ ਬਾਅਦ timeout ਹੋ ਗਿਆ ਅਤੇ ਇੱਕ failure record ਲਿਖਿਆ ਗਿਆ। ਇੰਜੀਨੀਅਰ ਹਾਲੀਆ deploys ਜਾਂਚ ਸਕਦਾ ਹੈ, timeout settings ਬਦਲੇ ਤਾਂ ਨਹੀਂ, ਅਤੇ ਵੇਖ ਸਕਦਾ ਹੈ ਕਿ ਕੀ ਰੀਟ੍ਰਾਈਜ਼ ਹੋ ਰਹੇ ਹਨ।
ਲੂਪ ਬੰਦ ਕਰਨ ਲਈ, ਚਾਰ ਚੀਜ਼ਾਂ ਚੈੱਕ ਕਰੋ:
- ਕਾਰਨ ਠੀਕ ਕਰੋ (ਉਦਾਹਰਣ: timeout adjust ਕਰੋ ਅਤੇ ਇੱਕ safe retry ਸ਼ਾਮਲ ਕਰੋ)।
- ਯਕੀਨੀ ਬਣਾਓ ਕਿ ਯੂਜ਼ਰ-ਮੁੱਖ error messages correlation ID ਸ਼ਾਮਲ ਕਰਦੀਆਂ ਹਨ।
- ਨਵੀਆਂ ਲਾਈਨਾਂ ਲਈ ਨਿਗਰਾਨੀ ਕਰੋ ਜਿਨ੍ਹਾਂ ਵਿੱਚ ਉਹੀ error ਪੈਟਰਨ ਹੋਵੇ ਪਰ ਵੱਖ-ਵੱਖ IDs।
- ਪੁਸ਼ਟੀ ਕਰੋ ਕਿ ID ਹਰ ਹੋਪ 'ਤੇ ਜਿਉਂਦਾ ਰਹਿੰਦਾ ਹੈ (workers ਅਤੇ queue messages ਸਮੇਤ)।
ਆਮ ਗਲਤੀਆਂ ਅਤੇ ਉਨ੍ਹਾਂ ਤੋਂ ਕਿਵੇਂ ਬਚਿਆ ਜਾਏ
ਕੋਰਲੇਸ਼ਨ IDs ਨੂੰ ਬੇਕਾਰ ਬਣਾਉਣ ਦਾ ਸਭ ਤੋਂ ਤੇਜ਼ ਤਰੀਕਾ ਚੇਨ ਟੁੱਟਣਾ ਹੈ। ਜ਼ਿਆਦਾਤਰ ਫੇਲਿਅਰ ਛੋਟੇ ਫੈਸਲਿਆਂ ਤੋਂ ਹੁੰਦੇ ਹਨ ਜੋ ਬਣਾਉਣ ਵੇਲੇ ਨਿਰਦੋਸ਼ ਲੱਗਦੇ ਹਨ ਪਰ support ਨੂੰ ਜਵਾਬ ਲੱਭਣ 'ਤੇ ਦੁੱਖ ਦੇਂਦੇ ਹਨ।
ਇੱਕ ਕ classiques ਗਲਤੀ ਹਰ hop ਤੇ ਨਵੀਂ ID ਜਨਰੇਟ ਕਰਨਾ ਹੈ। ਜੇ browser ID ਭੇਜੇ ਤਾਂ ਤੁਹਾਡਾ API gateway ਇਸਨੂੰ ਰੱਖੇ, ਇਸਨੂੰ ਬਦਲਣ ਦੀ ਜਰੂਰਤ ਨਹੀਂ। ਜੇ ਤੁਹਾਨੂੰ internal ID ਦੀ ਲੋੜ ਹੈ (queue message ਜਾਂ background job ਲਈ), ਤਾਂ original ਨੂੰ parent field ਵਜੋਂ ਰੱਖੋ ਤਾਂ ਕਿ ਕਹਾਣੀ ਜੁੜੀ ਰਹੇ।
ਹੋਰ ਆਮ ਖਾਮੀ partial logging ਹੈ। ਟੀਮਾਂ ਪਹਿਲੀ API ਵਿੱਚ ID ਜੋੜਦੀਆਂ ਹਨ ਪਰ workers, scheduled jobs ਜਾਂ database access layer ਭੁੱਲ ਜਾਂਦੀਆਂ ਹਨ। ਨਤੀਜਾ ਇੱਕ dead end ਹੁੰਦਾ ਹੈ: ਤੁਸੀਂ ਵੇਖ ਸਕਦੇ ਹੋ ਰਿਕਵੇਸਟ ਸਿਸਟਮ ਵਿੱਚ ਐਂਟਰੀ ਕਰਦਾ ਹੈ, ਪਰ ਅੱਗੇ ਕਿੱਥੇ ਗਿਆ ਇਹ ਨਹੀ ਮਿਲਦਾ।
"naming chaos" ਸਮੱਸਿਆ ਤੋਂ ਬਚੋ
ਭਾਵੇਂ ID ਹਰ ਜਗ੍ਹਾ ਮੌਜੂਦ ਹੋਵੇ, ਪਰ ਹਰ ਸਰਵਿਸ ਵੱਖਰਾ field ਨਾਮ ਜਾਂ ਫਾਰਮੈਟ ਵਰਤੇ ਤਾਂ search ਮੁਸ਼ਕਿਲ ਹੋ ਸਕਦਾ ਹੈ। ਇੱਕ ਨਾਮ ਚੁਣੋ ਅਤੇ frontend, APIs ਅਤੇ logs 'ਚ ਇਸ 'ਤੇ ਟਿਕੇ ਰਹੋ (ਉਦਾਹਰਣ correlation_id)। ਇੱਕ ਫਾਰਮੈਟ (ਅਕਸਰ UUID) ਚੁਣੋ ਅਤੇ copy-paste ਲਈ case-sensitive ਰੱਖੋ।
ਜਦ ਗਲਤੀਆਂ ਹੋ ਰਹੀ ਹੋਣ ਤਾਂ ID ਨਾ ਗੁਆਓ। ਜੇ API 500 ਜਾਂ validation error ਵਾਪਸ ਕਰਦੀ ਹੈ ਤਾਂ error response ਵਿੱਚ correlation ID ਸ਼ਾਮਲ ਕਰੋ (ਅਤੇ ਸੰਭਵ ਹੋਵੇ ਤਾਂ response header ਵਿੱਚ ਵੀ)। ਤਾਂ ਯੂਜ਼ਰ support chat ਵਿੱਚ ਇਸਨੂੰ ਪੇਸਟ ਕਰ ਸਕਦਾ ਹੈ ਅਤੇ ਟੀਮ turant पूरी path trace ਕਰ ਸਕਦੀ ਹੈ।
ਇੱਕ ਤੇਜ਼ ਟੈਸਟ: ਕੀ ਇੱਕ support ਵਿਅਕਤੀ ਇੱਕ ID ਨਾਲ ਸ਼ੁਰੂ ਕਰਕੇ ਹਰ ਲਾਗ ਲਾਈਨ follow ਕਰ ਸਕਦਾ ਹੈ, failures ਸਮੇਤ? ਜੇ ਨਹੀਂ, ਉਹ ਪਹਿਲਾ gap fix ਕਰੋ।
end-to-end coverage ਦੀ ਪੁਸ਼ਟੀ ਕਰਨ ਲਈ ਤੇਜ਼ ਚੈੱਕਲਿਸਟ
ਇੱਕ traceable ਐਪ ਤੇਜ਼ੀ ਨਾਲ ਤਾਇਨਾਤ ਕਰੋ
ਯੋਜਨਾ ਤੋਂ ਚੱਲ ਰਹੀ ਐਪ ਤੱਕ ਬਿਨਾਂ ਸਰਵਰ ਸੈੱਟਅਪ ਦੇ ਜਲਦੀ ਜਾਓ।
ਇਸਨੂੰ ਇੱਕ sanity check ਵਜੋਂ ਵਰਤੋ ਜਦ ਤੱਕ ਤੁਸੀਂ support ਨੂੰ "ਸਿਰਫ ਲੌਗ ਖੋਜੋ" ਕਹਿਣਾ ਨਹੀਂ ਸ਼ੁਰੂ ਕਰਦੇ। ਇਹ ਸਿਰਫ ਉਸ ਵੇਲੇ ਕੰਮ ਕਰਦਾ ਹੈ ਜਦ ਹਰ ਹੋਪ ਇਕੋ ਨਿਯਮਾਂ ਦੀ ਪਾਲਣਾ ਕਰੇ।
ਲਾਜ਼ਮੀ ਚੈੱਕ
- ਤੁਹਾਡੇ ਕੋਲ ਇੱਕ ID ਫਾਰਮੈਟ ਅਤੇ ਇੱਕ header ਨਾਮ ਹੈ, ਜੋ ਹਰ ਜਗ੍ਹਾ ਵਰਤਿਆ ਜਾਂਦਾ ਹੈ (frontend, gateway, APIs, workers)।
- frontend ਇੱਕ ਯੂਜ਼ਰ ਕਾਰਵਾਈ ਦੀ ਸ਼ੁਰੂਆਤ 'ਚ ID ਬਣਾਉਂਦਾ (ਜਾਂ ਰੀਯੂਜ਼ ਕਰਦਾ) ਅਤੇ ਕਾਰਵਾਈ ਖਤਮ ਹੋਣ ਤੱਕ ਇਸਨੂੰ ਸਥਿਰ ਰੱਖਦਾ ਹੈ।
- ਤੁਹਾਡਾ API entry point ਮਿਸਿੰਗ ਹੋਣ 'ਤੇ ID ਬਣਾਉਂਦਾ ਅਤੇ ਹਮੇਸ਼ਾਂ response headers ਵਿੱਚ ਵਾਪਸ ਕਰਦਾ ਹੈ।
- ਹਰ backend ਸੇਵਾ request-ਸੰਬੰਧੀ ਲੌਗਾਂ ਵਿੱਚ
correlation_id ਨੂੰ structured field ਵਜੋਂ ਸ਼ਾਮਲ ਕਰਦੀ ਹੈ।
- on-call ਇੱਕ ID ਨੂੰ log search ਵਿੱਚ ਪੇਸਟ ਕਰਕੇ minutes ਵਿੱਚ ਪੂਰਾ path ਦੇਖ ਸਕਦਾ ਹੈ: edge request, auth, service calls, database operation, ਅਤੇ retries।
ਜੇ ਕੋਈ ਚੈੱਕ fail ਹੋਏ ਤਾਂ ਇਸ ਤਰ੍ਹਾਂ ਠੀਕ ਕਰੋ
ਉਸ ਛੋਟੀ ਸੇਧ ਦੀ ਚੋਣ ਕਰੋ ਜੋ ਚੇਨ ਨੂੰ ਅਟੁੱਟ ਰੱਖਦਾ ਹੈ।
- ਜੇ IDs mid-flight ਬਦਲ ਰਹੇ ਹਨ ਤਾਂ internal services ਵਿੱਚ ਨਵੇਂ IDs ਜਨਰੇਟ ਕਰਨਾ ਰੋਕੋ। original
correlation_id ਰੱਖੋ ਅਤੇ ਜੇ ਹੋਰ ਵੇਰਵਾ ਚਾਹੀਦਾ ਹੋਵੇ ਤਾਂ ਇੱਕ ਵੱਖਰਾ span_id ਜੋੜੋ।
- ਜੇ logs ਵਿੱਚ ਫੀਲਡ ਗਾਇਬ ਹੈ ਤਾਂ logging middleware ਜੋੜੋ ਤਾਂ ਕਿ ਇੰਜੀਨੀਅਰ ਹਰ ਵਾਰੀ ਯਾਦ ਨਾ ਰੱਖਣ।
- ਜੇ support ID ਨਹੀਂ ਪ੍ਰਾਪਤ ਕਰ ਸਕਦੀ ਤਾਂ UI ਨੂੰ error ਸਕ੍ਰੀਨ 'ਤੇ ID surface ਕਰਨ ਅਤੇ gateway ਨੂੰ ਹਰ response 'ਚ echo ਕਰਨ ਦੀ ਯਕੀਨੀ ਬਣਾਓ।
ਇੱਕ ਤੇਜ਼ ਟੈਸਟ ਜੋ gaps ਫੜਦਾ ਹੈ: devtools ਖੋਲ੍ਹੋ, ਇੱਕ ਐਕਸ਼ਨ trigger ਕਰੋ, ਪਹਿਲੀ request ਤੋਂ correlation ID ਕਾਪੀ ਕਰੋ, ਫਿਰ ਪੁਸ਼ਟੀ ਕਰੋ ਕਿ ਉਹੀ value ਹਰ ਸਬੰਧਤ API request ਅਤੇ ਹਰ ਸੰਬੰਧਿਤ ਲੌਗ ਲਾਈਨ ਵਿੱਚ ਨਜ਼ਰ ਆਉਂਦੀ ਹੈ।
ਅਗਲੇ ਕਦਮ: ਇਸਨੂੰ ਆਪਣੇ build ਪ੍ਰਕਿਰਿਆ ਵਿੱਚ ਸ਼ਾਮਲ ਕਰੋ
ਕੋਰਲੇਸ਼ਨ IDs तभी ਮਦਦਗਾਰ ਹੁੰਦੀਆਂ ਹਨ ਜਦ ਹਰ ਕੋਈ ਹਰ ਵਾਰੀ ਉਹਨਾਂ ਨੂੰ ਇੱਕੋ ਤਰੀਕੇ ਨਾਲ ਵਰਤੇ। correlation ID ਵਿਅਹਾਰ ਨੂੰ shipping ਦਾ ਇੱਕ ਜ਼ਰੂਰੀ ਹਿੱਸਾ ਬਣਾਓ, ਨਾ ਕਿ ਇੱਕ ਛੋਟੀ logging ਸੁਧਾਰ।
ਕਿਸੇ ਵੀ ਨਵੇਂ endpoint ਜਾਂ UI action ਲਈ "definition of done" ਵਿੱਚ ਇੱਕ ਨੰਨਾ traceability step ਜੋੜੋ। ਇਸ ਵਿੱਚ ਕਵਰ ਕਰੋ ਕਿ ID ਕਿਵੇਂ ਬਣਾਈ ਜਾਂਦੀ (ਜਾਂ reuse ਕੀਤੀ ਜਾਂਦੀ), flow ਦੌਰਾਨ ਇਹ ਕਿੱਥੇ ਰਹਿੰਦੀ ਹੈ, ਕਿਹੜਾ header ਇਸਨੂੰ ਲੈ ਕੇ ਜਾਂਦਾ ਹੈ, ਅਤੇ ਜਦ header ਮਿਸਿੰਗ ਹੋਵੇ ਤਾਂ ਹਰ ਸਰਵਿਸ ਕੀ ਕਰਦੀ ਹੈ।
ਇੱਕ ਹਲਕਾ-ਫੁਲਕਾ ਚੈੱਕਲਿਸਟ ਆਮ ਤੌਰ 'ਤੇ ਕਾਫੀ ਹੁੰਦਾ ਹੈ:
- Frontend: ਹਰ ਯੂਜ਼ਰ ਕਾਰਵਾਈ ਲਈ ਇੱਕ ID generate ਜਾਂ reuse ਕਰੋ ਅਤੇ ਉਸ ਕਾਰਵਾਈ ਦੀ ਸਾਰੀਆਂ API calls ਨੂੰ attach ਕਰੋ।
- API entry point: header ਸਵੀਕਾਰ ਕਰੋ, validate ਜਾਂ generate ਕਰੋ, ਅਤੇ response ਵਿੱਚ echo ਕਰੋ।
- Backend: ID ਨੂੰ downstream services ਅਤੇ jobs ਵੱਲ ਪਾਸ ਕਰੋ, ਅਤੇ ਲੌਗਾਂ ਵਿੱਚ ਸ਼ਾਮਲ ਕਰੋ।
- Logging: apps ਅਤੇ services ਵਿੱਚ ਇੱਕ ਜੋੜੀ ਹੋਈ field ਨਾਮ ਰੱਖੋ (ਉਦਾਹਰਣ
correlation_id)।
- Reviews: ਉਹ PRs reject ਕਰੋ ਜੋ endpoints ਜੋੜਦੀਆਂ ਹਨ ਬਿਨਾਂ ਕਿਸੇ ਟੈਸਟ ਦੇ ਜੋ ਸਾਬਤ ਕਰੇ ਕਿ ID ਲੌਗਾਂ ਵਿੱਚ ਨਜ਼ਰ ਆਉਂਦੀ ਹੈ।
Support ਲਈ ਇੱਕ ਸਧਾਰਨ script ਵੀ ਬਣਾਓ ਤਾਂ ਕਿ ਡੀਬੱਗ ਤੇਜ਼ ਅਤੇ ਦੁਹਰਾਏ ਜਾ ਸਕਣ। ਇਹ ਨਿਰਧਾਰਤ ਕਰੋ ਕਿ ID ਯੂਜ਼ਰ ਕੋਲ ਕਿੱਥੇ ਦਿਖਾਈ ਦੇਵੇ (ਉਦਾਹਰਣ, error dialogs 'ਤੇ "Copy debug ID" ਬਟਨ), ਅਤੇ ਲਿਖੋ ਕਿ support ਕਿਸ ਨੂੰ ਪੁੱਛੇ ਅਤੇ ਕਿੱਥੇ ਖੋਜੇ।
ਪ੍ਰੋਡਕਸ਼ਨ 'ਤੇ ਇਸ ਤੇ ਨਿਰਭਰ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ, ਇੱਕ staged flow ਚਲਾਓ ਜੋ ਅਸਲੀ ਵਰਤੋਂ ਨਾਲ ਮਿਲਦਾ-ਜੁਲਦਾ ਹੋਵੇ: ਇੱਕ ਬਟਨ ਕਲਿੱਕ ਕਰੋ, ਇੱਕ validation error trigger ਕਰੋ, ਫਿਰ ਕਾਰਵਾਈ complete ਕਰੋ। ਪੁਸ਼ਟੀ ਕਰੋ ਕਿ ਤੁਸੀਂ browser request ਤੋਂ ਲੈ ਕੇ API logs, ਕਿਸੇ background worker, ਅਤੇ ਜੇ ਤੁਸੀਂ ਉਹਨਾਂ ਨੂੰ record ਕਰਦੇ ਹੋ ਤਾਂ database call logs ਤੱਕ ਇਕੋ ID follow ਕਰ ਸਕਦੇ ਹੋ।
ਜੇ ਤੁਸੀਂ Koder.ai 'ਤੇ ਐਪ ਬਣਾ ਰਹੇ ਹੋ, ਤਾਂ ਇਹ ਸਹਾਇਕ ਹੈ ਕਿ ਆਪਣੀ correlation ID header ਅਤੇ logging conventions Planning Mode ਵਿੱਚ ਦਰਜ ਕਰੋ ਤਾਂ ਕਿ generated React frontends ਅਤੇ Go services ਪਹਿਲੇ ਦਿਨ ਤੋਂ ਹੀ consistent ਬਣਕੇ ਆਉਣ।