26 ਜੁਲਾ 2025·8 ਮਿੰਟ
ਕਾਰੋਬਾਰੀ ਪ੍ਰਕਿਰਿਆ ਐਕਸਪਸ਼ਨਾਂ ਨੂੰ ਟ੍ਰੈਕ ਕਰਨ ਲਈ ਵੈੱਬ ਐਪ ਕਿਵੇਂ ਬਣਾਈਏ
ਇਕ ਵੈੱਬ ਐਪ ਡਿਜ਼ਾਇਨ, ਬਣਾਉਣ ਅਤੇ ਲਾਂਚ ਕਰਨ ਦੇ ਕਦਮ ਸਿਖੋ ਜੋ ਕਾਰੋਬਾਰੀ ਪ੍ਰਕਿਰਿਆ ਐਕਸਪਸ਼ਨਾਂ ਨੂੰ ਲੌਗ, ਰੂਟ, ਅਤੇ ਹੱਲ ਕਰੇ—ਸਾਫ਼ ਵਰਕਫਲੋ ਅਤੇ ਰਿਪੋਰਟਿੰਗ ਨਾਲ।
ਬਿਜ਼ਨਸ ਪ੍ਰਕਿਰਿਆ ਐਕਸਪਸ਼ਨ ਕੀ ਹੁੰਦੇ ਹਨ (ਅਤੇ ਏਹਨਾਂ ਨੂੰ ਕਿਉਂ ਟ੍ਰੈਕ ਕਰਣਾ ਚਾਹੀਦਾ ਹੈ)
A business process exception ਉਹ ਹਰ ਚੀਜ਼ ਹੈ ਜੋ ਰੋਜ਼ਮਰਰਾ ਵਾਲੇ ਵਰਕਫਲੋ ਦੇ “ਖੁਸ਼ਹਾਲ ਰਸਤੇ” ਨੂੰ ਤੋੜ ਦਿੰਦੀ—ਇਕ ਐਸਾ ਘਟਨਾ ਜਿਸ ਨੂੰ ਮਨੁੱਖੀ ਧਿਆਨ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ ਕਿਉਂਕਿ ਮਿਆਰੀ ਨਿਯਮ ਇਸਨੂੰ ਕਵਰ ਨਹੀਂ ਕਰਦੇ ਜਾਂ ਕਿਉਂਕਿ ਕੁਝ ਗਲਤ ਹੋ ਗਿਆ।
ਐਕਸਪਸ਼ਨ ਨੂੰ ਦੈਨੰਦਿਨ ਕਾਰੋਬਾਰੀ ਕੰਮ ਦੇ "edge cases" ਦੇ ਸਮਾਨ ਸੋਚੋ।
ਰਿਲੇਟੇਬਲ ਉਦਾਹਰਣ
ਐਕਸਪਸ਼ਨ ਲਗਭਗ ਹਰ ਵਿਭਾਗ ਵਿੱਚ ਆਉਂਦੇ ਹਨ:
- Invoice mismatch: ਚਾਰਜ ਦਾ ਟੋਟਲ purchase order ਨਾਲ ਮਿਲਦਾ ਨਹੀਂ, ਮਾਤਰਾ ਵੱਖ ਹੈ, ਜਾਂ ਕਿਸੇ ਲਾਈਨ ਆਈਟਮ ਦੀ کمی ਹੈ।
- Missing approval: ਕੰਟ੍ਰੈਕਟ ਸਹੀ ਸਾਈਨ-ਆਫ਼ ਤੋਂ ਬਗੈਰ ਨਿਖਰ ਗਿਆ, ਜਾਂ ਖਰਚਾ лимिट ਤੋਂ ਵੱਧ ਬਿਨਾਂ ਮਨਜ਼ੂਰੀ ਭੇਜਿਆ ਗਿਆ।
- Late shipment: ਡਿਲਿਵਰੀ وعدੇ ਦਿਤੀ ਤਾਰੀਖ ਨੂੰ ਛੱਡ ਗਈ, ਅੱਡੀ-ਭੇਜੀ ਗਈ shipment ਆਈ, ਜਾਂ ਗਲਤ SKU ਭੇਜ ਦਿੱਤਾ ਗਿਆ।
ਇਹ ਗੱਲਾਂ "ਸ਼ਾਹਤ" ਨਹੀਂ—ਇਹ ਆਮ ਹਨ—ਅਤੇ ਜਦੋਂ ਤੁਹਾਡੇ ਕੋਲ ਇਹਨਾਂ ਨੂੰ ਕੈਪਚਰ ਅਤੇ ਹੱਲ ਕਰਨ ਦਾ ਸਪਸ਼ਟ ਤਰੀਕਾ ਨਹੀਂ ਹੁੰਦਾ ਤਾਂ ਦੇਰੀ, ਦੁਬਾਰਾ ਕੰਮ ਅਤੇ ਨਿਰਾਸ਼ਾ ਪੈਦਾ ਹੁੰਦੀ ਹੈ।
ਕਿਉਂ spreadsheets ਅਤੇ email threads ਫੇਲ ਹੋ ਜਾਂਦੇ ਹਨ
ਬਹੁਤ ਸਾਰੀਆਂ ਟੀਮਾਂ ਇੱਕ ਸਾਂਝਾ spreadsheet ਅਤੇ emails ਜਾਂ chat ਨਾਲ ਸ਼ੁਰੂ ਕਰਦੀਆਂ ਹਨ। ਇਹ ਕੰਮ ਕਰਦਾ ਹੈ—ਜਦ ਤਕ ਇਹ ਨਹੀਂ ਕਰਦਾ।
ਇੱਕ spreadsheet ਦੀ ਇੱਕ řੋ ਤੁਹਾਨੂੰ ਇਹ ਦੱਸ ਸਕਦੀ ਹੈ ਕਿ ਕੀ ਹੋਇਆ, ਪਰ ਅਕਸਰ ਹੋਰ ਸਾਰੀਆਂ ਜਾਣਕਾਰੀਆਂ ਗੁੰਮ ਹੋ ਜਾਂਦੀਆਂ ਹਨ:
- ਸੰਦਰਭ ਗੁੰਮ ਹੋਣਾ: ਮੁੱਖ ਵੇਰਵੇ inboxes (스크린ਸ਼ਾਟਸ, vendor ਦੇ ਜਵਾਬ, approvals) ਵਿੱਚ ਰਹਿ ਜਾਂਦੇ ਹਨ, record ਨਾਲ ਜੁੜੇ ਨਹੀਂ।
- ਕੋਈ ਸਾਫ਼ ਮਲਕੀਅਤ ਨਹੀਂ: ਲੋਕ ਮੰਨ ਲੈਂਦੇ ਹਨ ਕਿ ਕੋਈ ਹੋਰ ਇਸ ਨੂੰ ਸੰਭਾਲ ਰਿਹਾ ਹੈ, ਖਾਸ ਕਰਕੇ ਜਦੋਂ exceptions ਟੀਮਾਂ ਨੂੰ ਪਾਰ ਕਰਦੇ ਹਨ।
- ਕਮਜ਼ੋਰ ਇਤਿਹਾਸ: ਇਹ ਦੇਖਣਾ ਔਖਾ ਹੁੰਦਾ ਹੈ ਕਿ ਕਿਸਨੇ ਕੀ ਬਦਲਿਆ ਅਤੇ ਕਿਉਂ—ਜੋ ਬਾਅਦ ਵਿੱਚ ਸਵਾਲ ਉਠਣ 'ਤੇ ਮਹੱਤਵਪੂਰਕ ਹੁੰਦਾ ਹੈ।
ਸਮੇਂ ਨਾਲ, spreadsheet ਅੱਧੂਰੇ ਅਪਡੇਟਸ, ਡੁਪਲੀਕੇਟ ਐਂਟਰੀਜ਼ ਅਤੇ ਕਿਸੇ 'status' ਫੀਲਡ ਦਾ ਮਿਕਸ ਬਣ ਜਾਂਦਾ ਹੈ ਜਿਸ 'ਤੇ ਕਿਸੇ ਨੂੰ ਭਰੋਸਾ ਨਹੀਂ ਰਹਿੰਦਾ।
ਐਕਸਪਸ਼ਨ ਨੂੰ ਠੀਕ ਤਰੀਕੇ ਨਾਲ ਟ੍ਰੈਕ ਕਰਕੇ ਤੁਹਾਨੂੰ ਕੀ ਲਾਭ ਮਿਲਦੇ ਹਨ
ਇੱਕ ਸਧਾਰਨ exception tracking ਐਪ (ਤੁਹਾਡੇ ਪ੍ਰਕਿਰਿਆ ਲਈ ਇੱਕ incident/issue ਲੌਗ) ਤੁਰੰਤ operational value ਪੈਦਾ ਕਰਦੀ ਹੈ:
- ਝੱਟੀ ਰਿਜ਼ੋਲੂਸ਼ਨ: ਸਹੀ ਵਿਅਕਤੀ ਨੂੰ ਨੋਟੀਫਾਈ ਕੀਤਾ ਜਾਂਦਾ ਹੈ, ਸਹਾਇਕ ਜਾਣਕਾਰੀ exception ਨਾਲ ਰੁਕਦੀ ਹੈ ਅਤੇ ਸਥਿਤੀ ਦਿਸਦੀ ਹੈ।
- ਘੱਟ ਅਵਰਤਨਾਂ: ਪੈਟਰਨ ਉभर ਆਉਂਦੇ ਹਨ (ਉਹੀ vendor, ਉਹੀ ਕਦਮ, ਉਹੀ approval ਗੈਪ), ਤਾਂ ਤੁਸੀਂ ਰੂਟ ਕਾਰਨਾਂ ਨੂੰ ਠੀਕ ਕਰ ਸਕਦੇ ਹੋ।
- ਸਾਫ਼ ਜ਼ਿੰਮੇਵਾਰੀ: ਹਰ exception ਦਾ ਇੱਕ owner ਹੁੰਦਾ ਹੈ, due dates (SLA/ਟਾਰਗੇਟ) ਹੁੰਦੇ ਹਨ, ਅਤੇ ਇੱਕ ਦਸਤਾਵੇਜ਼ਬੱਧ ਨਤੀਜਾ ਹੁੰਦਾ ਹੈ।
ਉਮੀਦਾਂ ਸੈਟ ਕਰੋ: ਸਧਾਰਨ ਤੋਂ ਸ਼ੁਰੂ ਕਰੋ ਅਤੇ ਇਤਰਲ ਕਰੋ
ਤੁਹਾਨੂੰ ਪਹਿਲੇ ਦਿਨ 'ਤੇ ਪੂਰਨ workflow ਦੀ ਲੋੜ ਨਹੀੰ। ਪਹਿਲਾਂ ਆਧਾਰ capture ਕਰੋ—ਕੀ ਹੋਇਆ, ਕੌਣ ਇਸਦਾ ਮਾਲਕ ਹੈ, ਮੌਜੂਦਾ ਸਥਿਤੀ ਅਤੇ ਅਗਲਾ ਕਦਮ—ਫਿਰ ਆਪਣੇ ਫੀਲਡਸ, routing ਅਤੇ ਰਿਪੋਰਟਿੰਗ ਨੂੰ ਵਧਾਓ ਜਿਵੇਂ-ਜਿਵੇਂ ਤੁਸੀਂ ਦੇਖਦੇ ਹੋ ਕਿ ਕਿਹੜੇ exceptions ਦੁਹਰਾਏ ਜਾ ਰਹੇ ਹਨ ਅਤੇ ਕਿਹੜਾ ਡੇਟਾ ਫੈਸਲੇ ਚਲਾਉਂਦਾ ਹੈ।
ਯੂਜ਼ਰ, ਸਕੋਪ, ਅਤੇ ਸਫਲਤਾ ਮੈਟ੍ਰਿਕਸ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ
ਸਕ੍ਰੀਨਸ ਡ੍ਰਾਫਟ ਕਰਨ ਜਾਂ ਟੂਲ ਚੁਣਨ ਤੋਂ ਪਹਿਲਾਂ, ਇਹ ਸਪਸ਼ਟ ਕਰੋ ਕਿ ਕੌਣ ਐਪ ਲਈ ਹੈ, ਕੀ version 1 'ਚ ਕਵਰ ਕੀਤਾ ਜਾਵੇਗਾ, ਅਤੇ ਕਿਵੇਂ ਤੁਸੀਂ ਜਾਣੋਗੇ ਕਿ ਇਹ ਕੰਮ ਕਰ ਰਿਹਾ ਹੈ। ਇਹ ਇੱਕ “exception tracking app” ਨੂੰ ਇੱਕ γενੇਰਿਕ ticketing ਸਿਸਟਮ ਵਿੱਚ ਬਦਲਣ ਤੋਂ ਰੋਕਦਾ ਹੈ।
ਪ੍ਰਧਾਨ ਰੋਲ ਪਛਾਣੋ
ਜ਼ਿਆਦਾਤਰ exception workflows ਨੂੰ ਕੁਝ ਸਾਫ਼ ਅਭਿਆਰਥੀ ਚਾਹੀਦੇ ਹਨ:
- Requester: exception ਲੌਗ ਕਰਦਾ ਹੈ ਅਤੇ ਸੰਦਰਭ ਦਿੰਦਾ ਹੈ (ਕੀ ਹੋਇਆ, ਕਦੋਂ, ਪ੍ਰਭਾਵ)।
- Approver: ਫ਼ੈਸਲਾ ਕਰਦਾ ਹੈ ਕਿ exception ਮਨਜ਼ੂਰ ਹੈ ਜਾਂ ਨਹੀਂ ਅਤੇ ਕਿਸ ਸ਼ਰਤ ਅਧੀਨ।
- Resolver: ਮੁੱਦੇ ਨੂੰ ਠੀਕ ਕਰਦਾ ਹੈ, workaround ਲਗਾਉਂਦਾ ਹੈ ਜਾਂ ਡੇਟਾ ਅੱਪਡੇਟ ਕਰਦਾ ਹੈ।
- Process owner: ਅਧਾਰਭੂਤ ਪ੍ਰਕਿਰਿਆ ਲਈ ਜਿੰਮੇਵਾਰ ਅਤੇ ਰੋਕਥਾਮ ਕਾਰਵਾਈਆਂ ਲਈ ਜਵਾਬਦੇਹ।
- Auditor/viewer: ਨਿਗਰਾਨੀ ਅਤੇ ਅਨੁਕੂਲਤਾ ਚੈੱਕ ਲਈ read-only ਐਕਸੈਸ।
ਹਰ ਰੋਲ ਲਈ 2–3 ਮੁੱਖ permissions (create, approve, reassign, close, export) ਅਤੇ ਉਹਨਾਂ ਦੇ ਫੈਸਲਿਆਂ ਨੂੰ ਲਿਖੋ।
ਮਕਸਦ ਸਪਸ਼ਟ ਕਰੋ
ਮਕਸਦ ਪ੍ਰਾਇਕਟਿਕ ਅਤੇ ਨਿਰੀਖਣਯੋਗ ਰੱਖੋ। ਆਮ ਮਕਸਦਾਂ ਵਿੱਚ:
- Consistency ਨਾਲ exceptions capture ਕਰਨਾ (ਹਰ ਵਾਰੀ ਇੱਕੋ ਘੱਟੋ-ਘੱਟ ਡੇਟਾ)।
- ਸਾਫ਼ ਮਲਕੀਅਤ ਨਿਰਧਾਰਤ ਕਰਨਾ ਤਾਂ ਕਿ ਕੋਈ ਚੀਜ਼ ਪੜ੍ਹੀ ਨਾ ਰਹਿ ਜਾਵੇ।
- ਫੈਸਲੇ ਦਾ ਦਸਤਾਵੇਜ਼ (ਕਿਉਂ exception ਮਨਜ਼ੂਰ/ਅਣਮਨਜ਼ੂਰ ਕੀਤਾ ਗਿਆ, ਕਿਸਨੇ ਕੀਤਾ)।
- ਅਵਰਤਨਾਂ ਘਟਾਉਣਾ ਰੂਟ ਕਾਰਨ ਅਤੇ ਰੋਕਥਾਮ ਕਾਰਵਾਈਆਂ ਨੂੰ ਟ੍ਰੈਕ ਕਰਕੇ।
v1 ਲਈ ਕੀ ਸਮੇਤਣ ਵਿੱਚ ਹੈ ਫੈਸਲਾ ਕਰੋ
ਉੱਪਰਲੇ 1–2 ਉੱਚ-ਵਾਲੀਅਮ ਵਰਕਫਲੋਜ਼ ਚੁਣੋ ਜਿੱਥੇ exceptions ਵਾਰ-ਵਾਰ ਹੁੰਦੇ ਹਨ ਅਤੇ ਦੇਰੀ ਦੀ ਕੀਮਤ ਮਹਿਸੂਸਯੋਗ ਹੈ (ਉਦਾਹਰਨ: invoice mismatches, order holds, onboarding ਦਸਤਾਵੇਜ਼ਾਂ ਦੀ ਕਮੀ)। “ਸਭ ਪ੍ਰਕਿਰਿਆਵਾਂ” ਨਾਲ ਸ਼ੁਰੂ ਨਾ ਕਰੋ। ਨਿਰਧਾਰਿਤ ਸਕੋਪ ਤੁਹਾਨੂੰ categories, statuses ਅਤੇ approval rules ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਸਟੈਂਡਰਡ ਕਰਨ ਦਾ ਮੌਕਾ ਦਿੰਦਾ ਹੈ।
3–5 ਸਫਲਤਾ ਮੈਟ੍ਰਿਕਸ ਲਿਖੋ
ਉਹ ਮੈਟ੍ਰਿਕਸ ਨਿਰਧਾਰਤ ਕਰੋ ਜੋ ਤੁਸੀਂ ਪਹਿਲੇ ਦਿਨ ਤੋਂ ਮਾਪ ਸਕਦੇ ਹੋ:
- Time to resolution (median, ਅਤੇ % ਜੋ SLA ਵਿੱਚ ਹਨ)
- Reopen rate (closure ਦੀ ਗੁਣਵੱਤਾ)
- Exception volume by type (ਸਭ ਤੋਂ ਵੱਡੇ ਕਾਰਨ)
- Approval cycle time (request → decision)
- Repeat exceptions ਜੋ ਇੱਕੋ root cause ਨਾਲ ਜੁੜੇ ਹਨ
ਇਹ ਮੈਟ੍ਰਿਕਸ ਤੁਹਾਡੇ iteration ਲਈ ਬੇਸਲਾਈਨ ਬਣਦੇ ਹਨ ਅਤੇ ਭਵਿੱਖੀ automation ਦਾ ਜਾਇਜ਼ਾ ਦਿੰਦੇ ਹਨ।
ਐਕਸਪਸ਼ਨ ਲਾਈਫਸਾਈਕਲ ਅਤੇ ਸਥਿਤੀਆਂ ਮੈਪ ਕਰੋ
ਇੱਕ ਸਾਫ਼ ਲਾਈਫਸਾਈਕਲ ਸਭ ਨੂੰ ਇਸ ਗੱਲ 'ਤੇ ਇਕਝੁਟ ਰੱਖਦੀ ਹੈ ਕਿ exception ਕਿੱਥੇ ਹੈ, ਕੌਣ ਇਸਦਾ ਮਾਲਕ ਹੈ, ਅਤੇ ਅਗਲਾ ਕਦਮ ਕੀ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ। ਸਥਿਤੀਆਂ ਘੱਟ ਅਤੇ ਅਸਪਸ਼ਟ ਰੱਖੋ ਅਤੇ ਉਹ ਅਸਲ ਕਾਰਵਾਈਆਂ ਨਾਲ ਜੁੜੀਆਂ ਹੋਣ।
ਇੱਕ ਪ੍ਰਾਇਕਟਿਕ ਡਿਫਾਲਟ ਲਾਈਫਸਾਈਕਲ
Created → Triage → Review → Decision → Resolution → Closed
- Created: ਇੱਕ exception ਲੌਗ ਕੀਤਾ ਜਾਂਦਾ ਹੈ ਸਹੀ ਘੱਟੋ-ਘੱਟ ਵੇਰਵਿਆਂ ਨਾਲ।
- Triage: ਕੋਈ ਇਸਨੂੰ ਵੇਰਵਾ ਕਰਦਾ ਹੈ, ਮਲਕੀਅਤ ਨਿਰਧਾਰਤ ਕਰਦਾ ਹੈ, ਅਤੇ urgencey ਸੈਟ ਕਰਦਾ ਹੈ।
- Review: ਸਹੀ ਟੀਮ ਸਬੂਤ ਇਕੱਤਰ ਕਰਦੀ ਹੈ ਅਤੇ ਵਿਕਲਪਾਂ ਦਾ ਮੁਲਾਂਕਣ ਕਰਦੀ ਹੈ।
- Decision: exception ਮਨਜ਼ੂਰ/ਇਨਕਾਰ ਕੀਤਾ ਜਾਂਦਾ ਹੈ (ਜਾਂ ਬਦਲਾਅ ਮੰਗੇ ਜਾਂਦੇ ਹਨ) ਅਤੇ ਤਰਕ ਦਰਜ ਕੀਤਾ ਜਾਂਦਾ ਹੈ।
- Resolution: corrective action ਲਾਗੂ ਅਤੇ ਵੈਰੀਫਾਈ ਕੀਤਾ ਜਾਂਦਾ ਹੈ।
- Closed: ਰਿਕਾਰਡ ਰਿਪੋਰਟਿੰਗ ਅਤੇ ਆਡਿਟ ਲਈ ਫਾਈਨਲ ਕੀਤਾ ਜਾਂਦਾ ਹੈ।
ਦਾਖਲ/ਬਾਹਰ ਜਾਣ ਦੇ ਮਾਪਦੰਡ ਨਾਲ “हो ਗਿਆ” ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ
ਹਰ ਸਟੇਜ ਵਿੱਚ ਦਾਖਲ ਹੋਣ ਅਤੇ ਨਿਕਲਣ ਲਈ ਕੀ ਸੱਚ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ ਲਿਖੋ:
- Created (exit): ਲਾਜ਼ਮੀ ਫੀਲਡ ਪੂਰੇ; category ਚੁਣੀ; requester ਦਰਜ।
- Triage (exit): owner ਨਿਰਧਾਰਤ; ਪ੍ਰਭਾਵ + due date ਸੈਟ; duplicates ਚੈੱਕ ਕੀਤੇ।
- Review (exit): ਸਬੂਤ ਜੁੜੇ; stakeholders ਸਲਾਹ-ਮਸ਼ਵਰਾ ਕੀਤੇ; ਸਿਫਾਰਿਸ਼ ਦਰਜ।
- Decision (exit): ਫੈਸਲਾ ਦਰਜ; approver ਦਰਜ; ਸਥਿਤੀਆਂ (ਜੇ ਕੋਈ) ਰਿਕਾਰਡ ਕੀਤੀਆਂ।
- Resolution (exit): ਕਾਰਵਾਈਆਂ ਮੁਕੰਮਲ; ਨਤੀਜਾ ਵੈਰੀਫਾਈ; SLA ਪਾਲਿਆ ਗਿਆ ਜਾਂ breach ਦਾ ਕਾਰਨ ਲਿਖਿਆ।
- Closed (exit): ਆਖਰੀ ਨੋਟਸ ਸ਼ਾਮਿਲ; ਕੋਈ ਖੁਲੀ ਟਾਸਕ ਨਹੀਂ; ਆਡਿਟ ਟਰੇਲ ਪੂਰਾ।
ਰੋਕਥਾਮ ਨਿਯਮ ਜੋ ਰੁਕਾਵਟ ਰੋਕਦੇ ਹਨ
ਜਦੋਂ ਕੋਈ exception overdue ਹੋਵੇ (due date/SLA ਤੋਂ ਪਿੱਛੇ), blocked ਹੋਵੇ (ਬਾਹਰੀ ਨਿਰਭਰਤਾ ਬਹੁਤ ਲੰਬਾ ਰੁਕੀ ਹੋਈ), ਜਾਂ high impact ਹੋਵੇ (severity ਥ੍ਰੇਸ਼ਹੋਲਡ), ਤਾਂ automatic escalation ਸ਼ਾਮਿਲ ਕਰੋ। Escalation ਦਾ ਮਤਲਬ ਹੋ ਸਕਦਾ ਹੈ: ਮੈਨੇਜਰ ਨੂੰ ਨੋਟੀਫਾਈ ਕਰਨਾ, ਉੱਚ approval ਲੈਵਲ ਵੱਲ ਰੀ-ਰੂਟ ਕਰਨਾ, ਜਾਂ ਪ੍ਰਾਇਰਟੀ ਵਧਾਉਣਾ।
Reopen ਅਤੇ duplicate ਹੈਂਡਲਿੰਗ
- Reopen ਜਦੋਂ ਉਹੀ exception ਫਿਰ ਤੋਂ ਉਭਰਦਾ ਹੈ (ਉਦਾਹਰਨ: fix fail ਹੋ ਗਿਆ)। ਇੱਕ ਕਾਰਨ ਲਾਜ਼ਮੀ ਰੱਖੋ ਅਤੇ ਇਸਨੂੰ ਵਾਪਸ Triage ਜਾਂ Review ਵਿੱਚ ਭੇਜੋ।
- Duplicate ਜਦੋਂ ਦੋ ਰਿਕਾਰਡ ਇਕੋ ਢੰਗ ਦਾ ਮੁੱਦਾ ਦਰਸਾਉਂਦੇ ਹਨ। ਇੱਕ ਨੂੰ “primary” ਮਾਰਕ ਕਰੋ, duplicates ਨੂੰ link ਕਰੋ, ਅਤੇ duplicates ਨੂੰ “Merged” outcome ਨਾਲ ਬੰਦ ਕਰੋ ਤਾਂ ਰਿਪੋਰਟਿੰਗ ਸਹੀ ਰਹੇ।
ਡੇਟਾ ਮਾਡਲ ਅਤੇ ਲੋੜੀਂਦੇ ਫੀਲਡਜ਼ ਡਿਜ਼ਾਇਨ ਕਰੋ
ਇੱਕ ਚੰਗੀ exception tracking ਐਪ ਆਪਣੀ ਡੇਟਾ ਮਾਡਲ 'ਤੇ ਟਿਕਦੀ ਹੈ। ਜੇ structure ਬਹੁਤ ਢਿੱਲਾ ਰੱਖਦੇ ਹੋ ਤਾਂ ਰਿਪੋਰਟਿੰਗ ਅਣਭਰੋਸੇਯੋਗ ਬਣਦੀ ਹੈ; ਜੇ ਜ਼ਿਆਦਾ ਕਠੋਰ ਰੱਖਦੇ ਹੋ ਤਾਂ ਯੂਜ਼ਰ ਡੇਟਾ ਭਰਨ ਤੋਂ ਰੁਕ ਜਾਣਗੇ। ਘੱਟ ਲਾਜ਼ਮੀ ਫੀਲਡ ਅਤੇ ਵਧੇਰੇ ਠੀਕ-ਨਿਰਧਾਰਤ ოპਸ਼ਨਲ ਫੀਲਡ ਰੱਖੋ।
ਸ਼ੁਰੂਆਤੀ ਮੁੱਖ entities
ਕੁਝ ਕੋਰ ਰਿਕਾਰਡ ਤੋਂ ਸ਼ੁਰੂ ਕਰੋ ਜੋ ਵੱਧਤਰ ਸਹੀ ਸਥਿਤੀਆਂ ਕਵਰ ਕਰਦੇ ਹਨ:
- Exception: ਮੁੱਖ ਰਿਕਾਰਡ (ਕੀ ਹੋਇਆ, ਕਿੱਥੇ, ਅਤੇ ਕੀ ਹੱਲ ਦੀ ਲੋੜ)।
- Comment: ਵਿਚਾਰ-ਵਟਾਂਦਰਾ, ਸਪੱਸ਼ਟੀਕਰਨ ਅਤੇ ਪ੍ਰਗਤੀ ਅਪਡੇਟ।
- Attachment: ਸਕਰੀਨਸ਼ਾਟ, PDFs, emails, exports।
- Task: ਨਿਸ਼ਚਿਤ ਕਾਰਵਾਈਆਂ ਜੋ ਕਿਸੇ ਮੁਨਾਸ਼ਜ਼ ਵਿਅਕਤੀ ਨੂੰ ਦਿੱਤੀਆਂ ਜਾ ਸਕਦੀਆਂ ਹਨ।
- Decision: approvals/denials, policy exceptions, ਜਾਂ closure decisions।
- Category: ਇੱਕ ਨਿਯੰਤਰਿਤ ਸੂਚੀ ਜੋ ਰਿਪੋਰਟਿੰਗ ਨੂੰ ਸਾਫ਼ ਰੱਖਦੀ ਹੈ।
- User: reporters, assignees, approvers, ਅਤੇ viewers।
ਲਾਜ਼ਮੀ ਫੀਲਡ (ਇਸਨੂੰ ਛੋਟਾ ਰੱਖੋ)
ਹਰ Exception 'ਤੇ ਹੇਠ ਲਿਖਿਆ ਲਾਜ਼ਮੀ ਹੋਵੇ:
- Title ਅਤੇ description (ਸਧੀ ਭਾਸ਼ਾ ਵਿੱਚ, ਕੀ ਹੋਇਆ ਅਤੇ ਕਿਉਂ ਇਹ ਮਹੱਤਵਪੂਰਨ ਹੈ)
- Category
- Impact (ਉਦਾਹਰਨ ਲਈ: financial, customer, compliance, operational)
- Process area (ਉਦਾਹਰਨ: invoicing, fulfillment, returns)
- Due date (ਜਾਂ target resolution date)
ਢਾਂਚਾਬੱਧ ਕੀਮਤਾਂ ਜੋ ਤੁਸੀਂ ਸਟੈਂਡਰਡ ਕਰਨੀ ਚਾਹੀਦੀ ਹਨ
ਫਰੀ-ਟੈਕਸਟ ਦੀ ਥਾਂ ਨਿਯੰਤਰਿਤ ਕੀਮਤਾਂ ਵਰਤੋ:
- Status (Created, Triage, Review, Decision, Resolution, Closed)
- Priority (Low/Medium/High/Urgent)
- Root cause (Human error, system defect, missing data, vendor issue, unclear policy)
- Resolution type (Corrected data, refund issued, workaround, process updated, training, no action)
ਲਿੰਕਿੰਗ ਅਤੇ ਟਰੇਸਾਬਿਲਿਟੀ
exceptions ਨੂੰ ਵਾਸਤਵਿਕ ਕਾਰੋਬਾਰੀ objects ਨਾਲ ਜੋੜਨ ਲਈ ਫੀਲਡਸ ਦੀ ਯੋਜਨਾ ਬਣਾਓ:
- Affected record references (Order ID, invoice ID, customer ID)
- External system IDs (ERP ticket, CRM case)
- Related exceptions (duplicates, recurring patterns, parent/child)
ਏਹ ਲਿੰਕ ਦੁਹਰਾਏ ਮਸਲਿਆਂ ਨੂੰ ਪਛਾਣਨਾ ਆਸਾਨ ਬਣਾਉਂਦੇ ਹਨ ਅਤੇ ਬਾਅਦ ਵਿੱਚ ਅਚਿੰਤ ਰਿਪੋਰਟਿੰਗ ਲਈ ਮਦਦਗਾਰ ਹਨ।
ਯੂਜ਼ਰ ਅਨੁਭਵ ਅਤੇ ਮੁੱਖ ਸਕ੍ਰੀਨ ਡਿਜ਼ਾਇਨ ਕਰੋ
ਇੱਕ ਚੰਗੀ exception tracking ਐਪ ਇੱਕ ਸਾਂਝੇ inbox ਵਾਂਗ ਮਹਿਸੂਸ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ: ਹਰ ਕੋਈ ਜਲਦੀ ਦੇਖ ਸਕੇ ਕਿ ਕੀ ਧਿਆਨ ਦੀ ਲੋੜ ਹੈ, ਕੀ ਰੁਕਿਆ ਹੋਇਆ ਹੈ, ਅਤੇ ਕੀ overdue ਹੈ। ਪਹਿਲਾਂ ਉਹਨਾਂ ਸਕ੍ਰੀਨਾਂ ਨੂੰ ਡਿਜ਼ਾਇਨ ਕਰੋ ਜੋ ਦੈਨੀਕ ਕੰਮ ਦੇ 90% ਨੂੰ ਕਵਰ ਕਰਦੀਆਂ ਹਨ, ਫਿਰ advanced reporting ਅਤੇ integrations ਜੋੜੋ।
ਪਹਿਲਾਂ ਡਿਜ਼ਾਇਨ ਕਰਨ ਲਈ ਮੁੱਖ ਸਕ੍ਰੀਨ
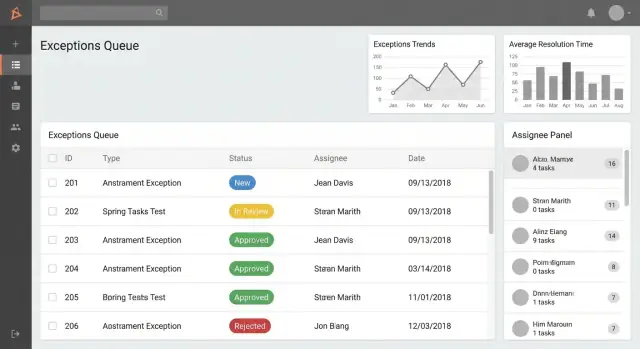
1) Exception list / queue (ਹੋਮ ਸਕ੍ਰੀਨ)
ਇਹ ਥਾਂ ਹੈ ਜਿੱਥੇ ਯੂਜ਼ਰ ਰਹਿੰਦੇ ਹਨ। ਇਸਨੂੰ ਤੇਜ਼, ਸਕੈਨਏਬਲ, ਅਤੇ ਕਾਰਵਾਈ-ਉਤਸ਼ਾਹਿਤ ਬਣਾਓ।
ਰੋਲ-ਆਧਾਰਿਤ queues ਬਣਾਓ ਜਿਵੇਂ:
- My exceptions (ਮੇਰੇ ਦੁਆਰਾ ਬਣਾਈ ਜਾਂ ਮੈਨੂੰ ਅਸਾਈਨ ਕੀਤੀਆਂ)
- Needs my approval (ਉਹ ਆਈਟਮ ਜੋ ਫੈਸਲੇ ਦੀ ਉਡੀਕ ਕਰ ਰਹੇ ਹਨ)
- Overdue (SLA ਜਾਂ target date ਤੋਂ ਪਿੱਛੇ)
ਈੱ search ਅਤੇ filters ਸ਼ਾਮਿਲ ਕਰੋ ਜੋ ਲੋਕਾਂ ਦੀ ਬੋਲਚਾਲ ਵਾਲੀ ਭਾਸ਼ਾ ਨਾਲ ਮਿਲਦੇ ਹਨ:
- Status, category, process area
- Date range (created, due, closed)
- Assignee / team
2) Create exception form
ਪਹਿਲਾ ਕਦਮ ਹਲਕਾ ਰੱਖੋ: ਕੁਝ ਲਾਜ਼ਮੀ ਫੀਲਡ, ਬਾਕੀ "More" ਹੇਠਾਂ ਵਿਕਲਪ। Drafts ਸੇਵ ਕਰੋ ਅਤੇ "unknown" ਮੁੱਲ (ਜਿਵੇਂ “assignee TBD”) ਦੀ ਆਗਿਆ ਦਿਓ ਤਾਂ ਕਿ ਵਰਕਅਰਾਊਂਡ ਨਾ ਬਣਨ।
3) Exception detail page
ਇਸ ਨਾਲ ਇਹ ਸਵਾਲ ਜਵਾਬ ਹੋ ਜਾਣੇ ਚਾਹੀਦੇ ਹਨ: “ਕੀ ਹੋਇਆ? ਅਗਲਾ ਕੀ ਹੈ? ਕੌਣ ਮਸੂਲ ਹੈ?” ਸ਼ਾਮਿਲ ਕਰੋ:
- Summary, status, owner/assignee, due date/SLA
- ਸਪਸ਼ਟ ਮੁੱਖ ਕਾਰਵਾਈਆਂ (Assign, Request approval, Close)
- ਮੁੱਖ ਮੈਟਾਡੇਟਾ ਲਈ ਇੱਕ ਸਾਈਡ ਪੈਨਲ
ਸਹਿਯੋਗ ਦੀਆਂ ਬੁਨਿਆਦੀਆਂ (ਬਿਨਾਂ chat ਬਣਾਉਣ)
ਸ਼ਾਮਿਲ ਕਰੋ:
- Comments ਨਾਲ @mentions ਤਾਂ ਜੋ ਸਹੀ ਲੋਕਾਂ ਨੂੰ ਖਿੱਚਿਆ ਜਾ ਸਕੇ
- Attachments ਸਬੂਤ ਲਈ (스크린ਸ਼ਾਟ, PDFs)
- ਇੱਕ activity timeline ਜੋ ਬਦਲਾਅ ਰਿਕਾਰਡ ਕਰਦਾ ਹੈ (status updates, reassignment, approvals) ਤਾਂ ਕਿ ਯੂਜ਼ਰਾਂ ਨੂੰ ਪੁੱਛਣਾ ਨਾ ਪਵੇ "ਕਿਸਨੇ ਇਹ ਬਦਲਿਆ?"
Admin ਸੈਟਿੰਗਸ (ਘੱਟੋ-ਘੱਟ ਪਰ ਜ਼ਰੂਰੀ)
Categories, process areas, SLA targets, ਅਤੇ notification ਨਿਯਮ ਪ੍ਰਬੰਧ ਕਰਨ ਲਈ ਇੱਕ ਛੋਟਾ admin ਖੇਤਰ ਦਿਓ—ਤਾਂ ਜੋ operations ਟੀਮ ਬਿਨਾਂ redeploy ਦੇ ਐਪ ਨੂੰ ਅਪਡੇਟ ਕਰ ਸਕੇ।
ਤਕਨੀਕੀ ਰੁੱਖ ਅਤੇ ਆਰਕੀਟੈਕਚਰ ਚੁਣੋ
Role-Based Queues ਬਣਾਓ
ਹਰ ਰੋਲ ਨੂੰ ਕੇਵਲ ਉਹੀ ਚੀਜ਼ ਦਿਖਾਉਣ ਲਈ queues ਅਤੇ permissions ਬਣਾਓ ਜੋ ਉਹਨਾਂ ਨੂੰ ਚਾਹੀਦੀ ਹੈ।
ਇੱਥੇ ਤੁਸੀਂ ਤੇਜ਼ੀ, ਲਚੀਲਾਪਣ, ਅਤੇ ਲੰਬੇ ਸਮੇਂ ਦੀ maintainability ਵਿੱਚ ਸੰਤੁਲਨ ਕਰਦੇ ਹੋ। "ਸਹੀ" ਜਵਾਬ ਪੂਰੀ ਤਰ੍ਹਾਂ ਇਸ ਗੱਲ 'ਤੇ ਨਿਰਭਰ ਕਰਦਾ ਹੈ ਕਿ ਤੁਹਾਡੀ exception ਲਾਈਫਸਾਈਕਲ ਕਿੰਨੀ ਜਟਿਲ ਹੈ, ਕਿੰਨੀ ਟੀਮਾਂ ਇਸ ਟੂਲ ਨੂੰ ਵਰਤਣਗੀਆਂ, ਅਤੇ ਤੁਹਾਡੇ ਆਡਿਟ ਦੀਆਂ ਲੋੜਾਂ ਕਿੰਨੀਆਂ ਕੱਠਿਨ ਹਨ।
ਤਿੰਨ ਪ੍ਰਾਇਕਟਿਕ build ਰੁਝਾਨ
1) Custom build (ਪੂਰਾ ਕੰਟਰੋਲ). UI, API, ਡੇਟਾਬੇਸ ਅਤੇ integrations ਖੁਦ ਬਣਾਓ। ਜਦੋਂ ਤੁਹਾਨੂੰ tailor-made workflows, routing, SLAs, audit trail ਅਤੇ ERP/ticketing integrations ਦੀ ਲੋੜ ਹੋਵੇ ਇਹ ਵਧੀਆ ਹੈ। ਟ੍ਰੇਡ-ਆਫ਼: ਉੱਚ ਪ੍ਰਾਰੰਭਿਕ ਲਾਗਤ ਅਤੇ ongoing engineering ਸਹਾਇਤਾ ਦੀ ਲੋੜ।
2) Low-code (ਸਭ ਤੋਂ ਤੇਜ਼ ਲਾਂਚ)। Internal app builders ਤੇਜ਼ੀ ਨਾਲ forms, tables ਅਤੇ ਬੇਸਿਕ approvals ਪੈਦਾ ਕਰ ਸਕਦੇ ਹਨ। ਪਾਈਲਟ ਜਾਂ ਇਕ ਵਿਭਾਗੀ ਰੋਲਆਊਟ ਲਈ ਇਹ ਉਤਮ ਹੈ। ਟ੍ਰੇਡ-ਆਫ਼: ਜਟਿਲ permissions, custom reporting, ਸਕੇਲ ਤੇ performance ਜਾਂ data portability 'ਤੇ ਸੀਮਾਵਾਂ ਆ ਸਕਦੀਆਂ ਹਨ।
3) Vibe-coding / agent-assisted build (ਤੁਰੰਤ ਇਤਰਲ ਨਾਲ ਅਸਲੀ ਕੋਡ). ਜੇ ਤੁਸੀਂ ਤੇਜ਼ੀ ਚਾਹੁੰਦੇ ਹੋ ਬਿਨਾਂ ਮੈਨਟੇਨੇਬਲ ਕੋਡ ਛੱਡੇ, ਤਾਂ ਇੱਕ ਪਲੇਟਫ਼ਾਰਮ ਜਿਵੇਂ Koder.ai ਤੁਹਾਨੂੰ chat-driven spec ਤੋਂ ਇੱਕ ਕੰਮ ਕਰ ਰਹੀ web app ਬਣਾਉਣ ਵਿੱਚ ਮਦਦ ਕਰ ਸਕਦਾ ਹੈ—ਫਿਰ ਜਦੋਂ ਲੋੜ ਹੋਵੇ source code export ਕਰੋ। ਟੀਮਾਂ ਆਮ ਤੌਰ 'ਤੇ initial React UI ਅਤੇ Go + PostgreSQL backend ਤਿਆਰ ਕਰਨ ਲਈ ਇਸਨੂੰ ਵਰਤਦੀਆਂ ਹਨ, planning mode ਵਿੱਚ iterate ਕਰਦੀਆਂ ਹਨ, ਅਤੇ snapshots/rollback 'ਤੇ ਰਿਹਾਇਸ਼ ਕਰਦੀਆਂ ਹਨ ਜਦੋਂ workflow ਸਥਿਰ ਹੋਵੇ।
ਇੱਕ ਸਧਾਰਨ, ਸਕੇਲ ਕਰਨ ਯੋਗ ਆਰਕੀਟੈਕਚਰ
ਚਿੰਨ੍ਹਿਤ ਕਰੋ ਕਿ concerns ਵੱਖ-ਵੱਖ ਰਹਿਣ:
- Web UI ਵਰਤੋਂਕਾਰਾਂ ਲਈ exceptions submit, review, ਅਤੇ resolve ਕਰਨ ਲਈ
- API ਜੋ validation, permissions, ਅਤੇ workflow rules ਲਗੂ ਕਰਦਾ ਹੈ
- Database ਜੋ exceptions, comments, attachments metadata, decisions, tasks ਅਤੇ audit events ਸਟੋਰ ਕਰਦਾ ਹੈ
- Background jobs notifications, escalations, SLA timers, ਅਤੇ scheduled reports ਲਈ
ਇਹ ਬਣਤਰ ਜਦ ਐਪ ਵਧਦੀ ਹੈ ਤਾਂ ਸਮਝਣਯੋਗ ਰਹਿੰਦੀ ਹੈ ਅਤੇ integrations ਜੋੜਨ ਵਿੱਚ ਸੌਖੀ ਰਹਿੰਦੀ ਹੈ।
ਹੋਸਟਿੰਗ ਅਤੇ environements
ਘੱਟੋ-ਘੱਟ dev → staging → prod ਦੀ ਯੋਜਨਾ ਬਣਾਓ। Staging ਨੂੰ prod ਦਾ ayn mirror ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ (ਖਾਸ ਕਰਕੇ auth ਅਤੇ email) ਤਾਂ ਜੋ ਤੁਸੀਂ routing, SLAs, ਅਤੇ ਰਿਪੋਰਟਿੰਗ ਨੂੰ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਟੈਸਟ ਕਰ ਸਕੋ।
ਜੇ ਤੁਹਾਨੂੰ ਸ਼ੁਰੂ ਵਿੱਚ ops overhead ਘਟਾਉਣੀ ਹੈ, ਤਾਂ ਉਹ ਪਲੇਟਫ਼ਾਰਮ ਚੁਣੋ ਜੋ deployment ਅਤੇ hosting ਦੇ ਨਾਲ ਆਉਂਦਾ ਹੈ (ਉਦਾਹਰਨ: Koder.ai, ਜੋ deployment/hosting, custom domains, ਅਤੇ global AWS regions ਸਹਾਇਤ ਕਰਦਾ ਹੈ)—ਫਿਰ ਜਦੋਂ workflow ਸਬੂਤ ਹੋ ਜਾਵੇ ਤਾਂ bespoke setup 'ਤੇ ਵਾਪਸ ਵੇਖੋ।
ਲਾਗਤ ਅਤੇ ਜਟਿਲਤਾ ਦੇ ਟ੍ਰੇਡ-ਆਫ਼
Low-code time-to-first-version ਘਟਾਉਂਦਾ ਹੈ, ਪਰ customization ਅਤੇ compliance ਜ਼ਰੂਰਤਾਂ ਬਾਅਦ ਵਿੱਚ ਲਾਗਤ ਵਧਾ ਸਕਦੀਆਂ ਹਨ (workarounds, add-ons, vendor constraints)। Custom builds ਪ੍ਰਾਥਮਿਕ ਤੌਰ ਤੇ ਮਹਿੰਗੇ ਹੁੰਦੇ ਹਨ, ਪਰ ਜੇ exception handling operations ਦਾ ਮੂਲ ਹੈ ਤਾਂ ਸਮੇਂ ਦੇ ਨਾਲ ਸਸਤੇ ਪੈ ਸਕਦੇ ਹਨ। ਇੱਕ ਮੱਧ ਰਾਹ—ਤੇਜ਼ੀ ਨਾਲ ship ਕਰਨਾ, workflow ਨੂੰ validate ਕਰਨਾ, ਅਤੇ ਸਾਫ਼ migration path (ਜਿਵੇਂ code export) ਰੱਖਣਾ—ਅਕਸਰ ਸਭ ਤੋਂ ਬਿਹਤਰ cost-to-control ਅਨੁਪਾਤ ਦਿੰਦਾ ਹੈ।
ਪ੍ਰਮਾਣਿਕਤਾ, ਰੋਲਜ਼, ਅਤੇ ਐਕਸੈਸ ਕੰਟਰੋਲ ਸੈੱਟ ਕਰੋ
Exception ਰਿਕਾਰਡ ਅਕਸਰ ਸੰਵੇਦਨਸ਼ੀਲ ਵੇਰਵਿਆਂ (customer ਨਾਮ, financial adjustments, policy breaches) ਨੂੰ ਸ਼ਾਮਿਲ ਕਰਦੇ ਹਨ। ਜੇ ਐਕਸੈਸ ਬਹੁਤ ਖੁਲਾ ਹੋਵੇ ਤਾਂ ਗੋਪਨੀਯਤਾ ਮੁੱਦੇ ਅਤੇ “shadow edits” ਦਾ ਖਤਰਾ ਹੁੰਦਾ ਹੈ ਜੋ ਸਿਸਟਮ 'ਤੇ ਭਰੋਸਾ ਘਟਾਉਂਦੇ ਹਨ।
ਸਾਈਨ-ਇਨ ਅਤੇ ਸੁਰੱਖਿਅਤ ਸੈਸ਼ਨ
ਆਪਣਾ password ਸਿਸਟਮ ਬਣਾਉਣ ਦੀ ਥਾਂ ਮੰਨਿਆ ਹੋਇਆ authentication ਵਰਤੋ। ਜੇ ਤੁਹਾਡੀ organization ਕੋਲ identity provider ਹੈ, ਤਾਂ SSO (SAML/OIDC) ਵਰਤੋ ਤਾਂ ਕਿ ਵਰਤੋਂਕਾਰ ਆਪਣੇ ਵਰਕ ਖਾਤੇ ਨਾਲ ਸਾਈਨ-ਇਨ ਕਰਨ ਅਤੇ ਤੁਸੀਂ ਮੌਜੂਦਾ controls ਜਿਵੇਂ MFA ਅਤੇ account offboarding ਵੇਲੇ ਵਾਰਸ ਰੱਖ ਸਕੋ।
SSO ਜਾਂ email login ਦੇ ਬਾਵਜੂਦ, session handling ਨੂੰ ਇੱਕ ਪਹਿਲੀ ਦਰਜੇ ਦੀ ਵਿਸ਼ੇਸ਼ਤਾ ਬਣਾਓ: short-lived sessions, secure cookies, CSRF protection browser apps ਲਈ, ਅਤੇ high-risk roles ਲਈ inactivity 'ਤੇ automatic logout। Authentication events (login, logout, failed attempts) ਨੂੰ ਲੌਗ ਕਰੋ ਤਾਂ ਕਿ ਤੁਸੀਂ ਅਸਧਾਰਨ ਐਕਟੀਵਿਟੀ ਦੀ ਜਾਂਚ ਕਰ ਸਕੋ।
ਰੋਲਜ਼ ਅਤੇ permissions (ਹਰ ਵਿਅਕਤੀ ਕੀ ਕਰ ਸਕਦਾ ਹੈ)
ਰੋਲਜ਼ ਨੂੰ ਸਾਫ਼ ਵਪਾਰੀ ਸ਼ਬਦਾਂ ਵਿੱਚ ਨਿਰਧਾਰਤ ਕਰੋ ਅਤੇ ਉਨ੍ਹਾਂ ਨੂੰ ਐਪ ਵਿੱਚ ਕਾਰਵਾਈਆਂ ਨਾਲ ਜੋੜੋ। ਆਮ ਸ਼ੁਰੂਆਤ:
- Reporter: exceptions ਬਣਾਉਣ, ਨੋਟਸ/attachments ਜੋੜਨ, ਆਪਣੀਆਂ ਆਈਟਮ ਵੇਖਣ ਦੀ ਆਗਿਆ
- Assignee/Resolver: ਫੀਲਡਸ ਅਪਡੇਟ ਕਰਨ, resolution ਸੁਝਾਅ ਦੇਣ, ਸਥਿਤੀ ਅਪਡੇਟ ਕਰਨ
- Approver/Manager: ਮਨਜ਼ੂਰ ਜਾਂ ਰੱਦ ਕਰਨ, ਹੋਰ ਜਾਣਕਾਰੀ ਮੰਗਣ, ਆਈਟਮ ਬੰਦ ਕਰਨ
- Admin: ਸਿਸਟਮ ਸੰਰਚਨਾ (ਰੋਜ਼ਾਨਾ ਪ੍ਰਕਿਰਿਆ ਨਹੀਂ)
ਜੋ ਡਿਲੀਟ ਕਰ ਸਕਦਾ ਹੈ ਉਸ ਬਾਰੇ ਸਪਸ਼ਟ ਹੋਵੋ। ਬਹੁਤ ਸਾਰੀਆਂ ਟੀਮਾਂ hard deletes ਬੰਦ ਰੱਖਦੀਆਂ ਹਨ ਅਤੇ ਸਿਰਫ admins ਨੂੰ archive ਕਰਨ ਦੀ ਆਗਿਆ ਦਿੰਦੀਆਂ ਹਨ, ਇਤਿਹਾਸ ਦੀ ਰੱਖਿਆ ਬਣਾਈ ਰੱਖਣ ਲਈ।
ਰਿਕਾਰਡ-ਸਤਰ ਐਕਸੈਸ (ਕੌਣ ਕਿਸੇ exception ਨੂੰ ਦੇਖ ਸਕਦਾ ਹੈ)
ਰੋਲ ਤੋਂ ਇਲਾਵਾ, department, team, location, ਜਾਂ process area ਦੇ ਆਧਾਰ 'ਤੇ visibility ਨੂੰ ਸੀਮਤ ਕਰਨ ਵਾਲੇ ਨਿਯਮ ਜੋੜੋ। ਆਮ ਰੁਝਾਨ:
- ਯੂਜ਼ਰ ਉਹ ਆਈਟਮ ਦੇਖ ਸਕਦੇ ਹਨ ਜੋ ਉਹਨਾਂ ਨੇ ਬਣਾਈਆਂ ਜਾਂ ਉਹਨਾਂ ਨੂੰ ਅਸਾਈਨ ਹੋਈਆਂ
- ਮੈਨੇਜਰ ਆਪਣੀ org unit ਦੇ ਸਾਰੇ ਆਈਟਮ ਵੇਖ ਸਕਦੇ ਹਨ
- Compliance/audit ਰੋਲ across units read-only ਵੇਖ ਸਕਦੇ ਹਨ
ਇਸ ਨਾਲ “ਖੁੱਲ੍ਹਾ ਬ੍ਰਾਊਜ਼ਿੰਗ” ਰੋਕਿਆ ਜਾਂਦਾ ਹੈ ਜਦਕਿ ਸਹਿਯੋਗ ਬਰਕਰਾਰ ਰਹਿੰਦਾ ਹੈ।
ਤੁਹਾਨੂੰ ਕਿਸ admin ਸਹੂਲਤਾਂ ਦੀ ਲੋੜ ਹੋਏਗੀ
Admins categories ਅਤੇ subcategories, SLA rules (due dates, escalation thresholds), notification templates, ਅਤੇ user role assignments ਸੇਟ ਕਰ ਸਕਣ। admin ਕਾਰਵਾਈਆਂ auditable ਹੋਣ ਅਤੇ high-impact ਬਦਲਾਅ (ਜਿਵੇਂ SLA edits) ਲਈ elevated confirmation ਲੋੜੀਏ—ਕਿਉਂਕਿ ਇਹ settings ਰਿਪੋਰਟਿੰਗ ਅਤੇ ਜਵਾਬਦੇਹੀ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰਦੀਆਂ ਹਨ।
ਵਰਕਫਲੋਜ਼, ਰੂਟਿੰਗ, ਅਤੇ ਨੋਟੀਫਿਕੇਸ਼ਨ ਬਣਾਓ
ਆਪਣਾ ਸੋਰਸ ਕੋਡ ਐਕਸਪੋਰਟ ਕਰੋ
ਜਦੋਂ ਤੁਹਾਨੂੰ ਗਹਿਰੇ ਕਸਟਮਾਈਜ਼ੇਸ਼ਨ ਜਾਂ ਨਵੇਂ ਹੋਸਟ ਦੀ ਲੋੜ ਹੋਵੇ, React, Go ਅਤੇ PostgreSQL ਕੋਡ ਐਕਸਪੋਰਟ ਕਰੋ।
Workflows ਇੱਕ ਸਧਾਰਨ “ਲੌਗ” ਨੂੰ ਇੱਕ exception tracking ਐਪ ਬਣਾਉਂਦੇ ਹਨ ਜਿਸਤੇ ਲੋਕ ਭਰੋਸਾ ਕਰ ਸਕਦੇ ਹਨ। ਲਕੜੀ ਇਹ ਹੈ ਕਿ ਹਰ exception ਦਾ ਇੱਕ ਸਪਸ਼ਟ ਮਾਲਕ, ਅਗਲਾ ਕਦਮ, ਅਤੇ ਸਮਾਂ-सीਮਾ ਹੋਵੇ।
Routing ਨਿਯਮ: ਕੌਣ ਕਿਸੇ ਚੀਜ਼ ਨੂੰ ਕਦੋਂ ਪਾਉਂਦਾ ਹੈ
ਛੋਟੇ ਅਤੇ ਆਸਾਨ ਸਮਝ ਆਉਣ ਵਾਲੇ routing ਨਿਯਮਾਂ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ। ਤੁਸੀਂ route ਕਰ ਸਕਦੇ ਹੋ:
- Category (ਜਿਵੇਂ data quality, policy deviation, system outage)
- Impact (financial amount, customer count, severity)
- Process area (AP/AR, onboarding, fulfillment)
- Thresholds (ਉਦਾਹਰਨ: “Amount > $10,000” ਜਾਂ “High severity”)
ਨਿਯਮ deterministic ਰੱਖੋ: ਜੇ ਕਈ ਨਿਯਮ ਮਿਲਦੇ ਹਨ ਤਾਂ ਇੱਕ precedence order ਨਿਰਧਾਰਤ ਕਰੋ। ਇੱਕ safe fallback ਵੀ ਰੱਖੋ (ਉਦਾਹਰਨ: “Exception Triage” ਕਿਊ) ਤਾਂ ਕਿ ਕੋਈ ਸਮਾਨ ਨਿਰਲੱਸ ਨਾ ਰਹਿ ਜਾਵੇ।
Approvals: ਸਰਲ, multi-step, ਅਤੇ overrides
ਕਈ exceptions ਨੂੰ ਮਨਜ਼ੂਰੀ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ ਪਹਿਲਾਂ ਕਿ ਉਹ ਮੰਨਿਆ ਜਾਵੇ, ਮਰੰਮਤ ਕੀਤੀ ਜਾਵੇ, ਜਾਂ ਬੰਦ ਕੀਤਾ ਜਾਵੇ।
ਦੋ ਆਮ ਪੈਟਰਨ ਲਈ ਡਿਜ਼ਾਇਨ ਕਰੋ:
- Single approver: ਇੱਕ ਵਿਅਕਤੀ ਮਨਜ਼ੂਰ/ਰੱਦ ਕਰਦਾ ਹੈ (ਸਭ ਤੋਂ ਤੇਜ਼)।
- Multi-step approval: ਇੱਕ ਕ੍ਰਮ ਜਿਵੇਂ Manager → Compliance → Finance.
ਇਹ ਸਪਸ਼ਟ ਕਰੋ ਕਿ ਕੌਣ override ਕਰ ਸਕਦਾ ਹੈ (ਅਤੇ ਕਿਸ ਸ਼ਰਤ 'ਤੇ)। ਜੇ overrides ਦੀ ਆਗਿਆ ਹੈ, ਤਾਂ ਇੱਕ ਕਾਰਨ ਲਾਜ਼ਮੀ ਰੱਖੋ ਅਤੇ audit trail ਵਿੱਚ ਦਰਜ ਕਰੋ (ਉਦਾਹਰਨ: “Approved by override due to SLA risk”)।
ਨੋਟੀਫਿਕੇਸ਼ਨ ਜੋ ਸ਼ੋਰ ਨਹੀਂ ਪੈਦਾ ਕਰਦੀਆਂ
ਉਹ ਘਟਨਾਵਾਂ ਲਈ email ਅਤੇ in-app ਨੋਟੀਫਿਕੇਸ਼ਨ ਜੋ ownership ਜਾਂ urgency ਬਦਲਦੇ ਹਨ:
- Assignment ਅਤੇ reassignment
- ਨਵੇਂ comments ਜਾਂ mentions
- Approval requested / approved / rejected
- Overdue items ਅਤੇ “due soon” reminders
ਯੂਜ਼ਰ optional notifications ਕੰਟਰੋਲ ਕਰ ਸਕਣ, ਪਰ critical ones (assignment, overdue) default 'ਤੇ ਓਨ ਰੱਖੋ।
Tasks/checklists ਨਾਲ resolution ਕੰਮ ਦਿਖਾਓ
Exceptions ਅਕਸਰ ਇਸ ਲਈ fail ਹੁੰਦੇ ਹਨ ਕਿ ਕੰਮ “ਇਗ਼ਰ-ਬਾਇ-ਸਾਈਡ” ਹੁੰਦਾ ਹੈ। exception ਨਾਲ ਜੁੜੇ ਹਲਕੇ tasks ਜਾਂ checklists ਸ਼ਾਮਿਲ ਕਰੋ: ਹਰ task ਦਾ owner, due date, ਅਤੇ status ਹੋਵੇ। ਇਸ ਨਾਲ ਪ੍ਰਗਤੀ ਟ੍ਰੈਕ ਕੀਤੀ ਜਾ ਸਕਦੀ ਹੈ, ਹੈਂਡਔਫ਼ ਸੁਧਰਦੇ ਹਨ, ਅਤੇ ਮੈਨੇਜਰਾਂ ਨੂੰ ਪਤਾ ਲੱਗਦਾ ਹੈ ਕਿ ਕੀ ਰੁਕਾਵਟ ਹੈ।
ਰਿਪੋਰਟਿੰਗ ਅਤੇ ਓਪਰੇਸ਼ਨਲ ਡੈਸ਼ਬੋਰਡ ਸ਼ਾਮਿਲ ਕਰੋ
ਰਿਪੋਰਟਿੰਗ ਉਹ ਥਾਂ ਹੈ ਜਿੱਥੇ exception tracking ਐਪ ਇੱਕ “ਲੌਗ” ਤੋਂ ਇਕ ਓਪਰੇਸ਼ਨਲ ਟੂਲ ਬਣ ਜਾਂਦੀ ਹੈ। ਮਕਸਦ ਨੇਤਾਓਂ ਨੂੰ ਪੈਟਰਨ ਜਲਦੀ ਨੋਟ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਨਾ ਅਤੇ ਟੀਮਾਂ ਨੂੰ ਦੱਸਣਾ ਕੀ ਅਗਲਾ ਕੰਮ ਹੈ—ਬਿਨਾਂ ਹਰ ਰਿਕਾਰਡ ਖੋਲ੍ਹੇ।
ਸ਼ੁਰੂਆਤੀ ਸਟੈਂਡਰਡ ਰਿਪੋਰਟਸ
ਛੋਟੇ ਸੈੱਟ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਜੋ ਆਮ ਸਵਾਲਾਂ ਦੇ ਅਕਸਰ ਉੱਤਰ ਦਿੰਦੇ ਹਨ:
- Volume over time (daily/weekly/monthly): exceptions ਵਧ ਰਹੇ ਹਨ, ਘਟ ਰਹੇ ਹਨ, ਜਾਂ ਮੌਸਮੀ ਹਨ?
- By category/cause: ਕਿਹੜੇ exception ਕਿਸੇ ਵਿਭਾਗ/ਕਾਰਨ ਨੇ ਸਭ ਤੋਂ ਜ਼ਿਆਦਾ ਪ੍ਰਭਾਵ ਪਾਇਆ?
- By team/owner: workload ਕਿੱਥੇ ਕੇਂਦ੍ਰਿਤ ਹੈ?
- By status: ਹਰ ਸਟੇਜ ਵਿੱਚ ਕਿੰਨਾ ਹੈ (Created, Triage, Review, Decision, Resolution, Closed)?
ਚਾਰਟ ਸਧਾਰਨ ਰੱਖੋ (trends ਲਈ line, breakdowns ਲਈ bar)। ਮੁੱਖ ਮੁੱਲ consistency ਹੈ—ਯੂਜ਼ਰਾਂ ਨੂੰ ਭਰੋਸਾ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ ਕਿ ਰਿਪੋਰਟ exception list ਨਾਲ ਮਿਲਦੀ ਹੈ।
Performance ਅਤੇ SLA ਟਰੈਕਿੰਗ
ਅਜਿਹੇ operational metrics ਸ਼ਾਮਿਲ ਕਰੋ ਜੋ ਸੇਵਾ ਦੀ ਸਿਹਤ ਦਰਸਾਉਂਦੇ ਹਨ:
- Average resolution time (ਤੇ магчым ਹੋਏ ਤਾਂ median)
- SLA breach rate (ਟਾਰਗੇਟ ਤੋਂ ਉਪਰ ਬਰੀਚ)
- Backlog size (open exceptions) ਅਤੇ aging (ਇਤਦਾ ਲੰਮਾ ਸਮਾਂ ਖੁੱਲ੍ਹੇ ਰਹੇ)
ਜੇ ਤੁਸੀਂ timestamps ਜਿਵੇਂ created_at, assigned_at, ਅਤੇ resolved_at ਸਟੋਰ ਕਰਦੇ ਹੋ, ਤਾਂ ਇਹ ਮੈਟ੍ਰਿਕਸ ਸਪੱਠ ਅਤੇ ਸਪਸ਼ਟ ਬਣ ਜਾਂਦੇ ਹਨ।
ਡ੍ਰਿੱਲ-ਡਾਊਨ, ਐਕਸਪੋਰਟ, ਅਤੇ ਸ਼ੈਡਿਊਲਡ ਸਮਰੀਜ਼
ਹਰ ਚਾਰਟ ਨੂੰ drill-down ਸਮਰਥਨ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ: ਕੋਈ bar ਜਾਂ segment 'ਤੇ ਕਲਿਕ ਕਰਨ ਨਾਲ ਯੂਜ਼ਰ ਨੂੰ filtered exception list ਤੇ ਲੈ ਜਾਓ (ਉਦਾਹਰਨ: “Category = Shipping, Status = Open”). ਇਹ dashboards actionable ਬਣਾਉਂਦਾ ਹੈ।
ਸ਼ੇਅਰਿੰਗ ਅਤੇ offline analysis ਲਈ ทั้ง list ਅਤੇ key reports ਤੋਂ CSV export ਦਿਓ। ਜੇ stakeholder ਨਿਯਮਤ ਨਜ਼ਰ ਰੱਖਣਾ ਚਾਹੁੰਦੇ ਹਨ, ਤਾਂ scheduled summaries (ਹਫਤਾਵਾਰ email ਜਾਂ in-app digest) ਜੋ trend changes, top categories, ਅਤੇ SLA breaches ਉਜागर ਕਰਦੀਆਂ ਹਨ, ਨਾਲ filtered views ਦੀ ਦਿਸ਼ਾ ਦਿਓ (ਉਦਾਹਰਨ: /exceptions?status=open&category=shipping)।
ਆਡੀਟੇਬਿਲਿਟੀ ਅਤੇ compliance ਬੁਨਿਆਦੀ ਗੱਲਾਂ ਸੁਨਿਸ਼ਚਿਤ ਕਰੋ
ਜੇ ਤੁਹਾਡੀ exception tracking ਐਪ approvals, payments, customer outcomes, ਜਾਂ regulatory reporting ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰਦੀ ਹੈ, ਤਾਂ ਤੁਹਾਨੂੰ ਬਾਅਦ ਵਿੱਚ "ਕਿਸਨੇ ਕੀ ਕੀਤਾ, ਕਦੋਂ, ਅਤੇ ਕਿਉਂ" ਦਾ ਜਵਾਬ ਦੇਣਾ ਪਵੇਗਾ। ਸ਼ੁਰੂ ਤੋਂ auditability ਬਣਾਉਣ ਨਾਲ ਦੁਖਦ ਘੜੀਆਂ ਤੋਂ ਬਚਾ ਜਾ ਸਕਦਾ ਹੈ ਅਤੇ ਟੀਮਾਂ ਨੂੰ ਇਹ ਭਰੋਸਾ ਮਿਲਦਾ ਹੈ ਕਿ ਰਿਕਾਰਡ ਤੇ ਭਰੋਸਾ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ।
ਇੱਕ activity log ਬਣਾਓ ਜਿਸ 'ਤੇ ਕੋਈ ਵਾਦ ਨਹੀਂ ਹੋ ਸਕਦਾ
ਹਰ exception ਰਿਕਾਰਡ ਲਈ ਇੱਕ ਪੂਰਾ activity log ਬਣਾਓ। actor (ਯੂਜ਼ਰ ਜਾਂ ਸਿਸਟਮ), timestamp (timezone ਸਮੇਤ), action type (created, field changed, status transitioned), ਅਤੇ before/after values ਲੌਗ ਕਰੋ।
ਲੌਗ append-only ਰੱਖੋ। edits(history) ਨੂੰ overwrite ਨਾ ਕਰੋ; ਬਦਲੇ ਵਿੱਚ ਨਵਾਂ event ਜੋੜੋ। ਜੇ ਤੁਸੀਂ ਸਹੀ ਕਰਨ ਦੀ ਲੋੜ ਮਹਿਸੂਸ ਕਰੋ, ਤਾਂ ਇੱਕ “correction” event ਦਰਜ ਕਰੋ ਜਿਸ ਵਿੱਚ ਵਿਆਖਿਆ ਹੋਵੇ।
ਫੈਸਲਿਆਂ ਨੂੰ ਕਾਰਨ ਅਤੇ ਸਬੂਤ ਨਾਲ ਸਟੋਰ ਕਰੋ
Approvals ਅਤੇ rejections status ਬਦਲਣ ਵਜੋਂ ਨਹੀਂ, ਬਲਕਿ first-class events ਹੋਣ ਚਾਹੀਦੇ ਹਨ। capture ਕਰੋ:
- Decision (approved/denied/returned)
- Reason code + free-text note (ਮੁੱਖ ਫੈਸਲਿਆਂ ਲਈ ਲਾਜ਼ਮੀ)
- Attachments (스크린ਸ਼ਾਟ, PDFs, emails) ਅਤੇ ਕੌਣ upload ਕੀਤਾ
ਇਸ ਨਾਲ ਰਿਵਿਊਜ਼ ਤੇਜ਼ ਹੋ ਜਾਂਦੇ ਹਨ ਅਤੇ ਜਦੋਂ ਕੋਈ ਪੁੱਛਦਾ ਹੈ ਕਿ ਕਿਉਂ exception ਮਨਜ਼ੂਰ ਕੀਤਾ ਗਿਆ, ਤਾਂ ਘੁੰਮ-ਫਿਰ ਕੇ ਗਲ-ਬਾਤ ਘਟਦੀ ਹੈ।
ਰਿਟੇਨਸ਼ਨ ਅਤੇ ਡਿਲੀਟ ਨੀਤੀਆਂ (ਇਹਨਾਂ ਨੂੰ ਜਾਣ-ਬੁਝ ਕੇ ਸੈੱਟ ਕਰੋ)
ਨਿਰਧਾਰਤ ਕਰੋ ਕਿ exceptions, attachments, ਅਤੇ logs ਕਿੰਨੇ ਸਮੇਂ ਰੱਖੇ ਜਾਣ:
- Records ਅਤੇ audit events ਨੂੰ ਇੱਕ ਨਿਰਧਾਰਿਤ ਦੌਰਾਨੀ ਰੱਖੋ (ਉਦਾਹਰਨ: 3–7 ਸਾਲ)
- ਡਿਲੀਟ ਕਰਨ ਦੀ ਆਗਿਆ ਘੱਟ admin ਗਰੁੱਪ ਤੱਕ ਸੀਮਿਤ ਕਰੋ, with mandatory justification
- “Soft delete” ਨੂੰ ਤਰਜੀਹ ਦਿਓ (ਨਾਰਮਲ views ਤੋਂ ਛੁਪਿਆ), ਜਦ ਕਿ audit trail ਬਰਕਰਾਰ ਰਹੇ
ਆਪਣੀ ਨੀਤੀ ਨੂੰ ਆਰਗਨਾਈਜ਼ੇਸ਼ਨ ਦੀ ਗਵਰਨੈਂਸ ਅਤੇ ਕਿਸੇ ਵੀ ਕਾਨੂੰਨੀ ਲੋੜ ਨਾਲ ਮਿਲਾਓ।
ਰੀਵਿਊਜ਼ ਅਤੇ ਆਡਿਟ ਲਈ ਡਿਜ਼ਾਇਨ ਕਰੋ
Auditors ਅਤੇ compliance reviewers ਨੂੰ ਤੇਜ਼ੀ ਅਤੇ ਸਪਸ਼ਟਤਾ ਚਾਹੀਦੀ ਹੈ। review ਕੰਮ ਲਈ filters ਸ਼ਾਮਿਲ ਕਰੋ: date range, owner/team, status, reason codes, SLA breach, ਅਤੇ approval outcomes।
Printable summaries ਅਤੇ exportable reports ਦਿਓ ਜੋ immutable history (events timeline, decision notes, ਅਤੇ attachments list) ਨੂੰ ਸ਼ਾਮਿਲ ਕਰਦੇ ਹੋਣ। ਇੱਕ ਚੰਗਾ ਨਿਯਮ: ਜੇ ਤੁਸੀਂ record ਅਤੇ ਇਸਦੇ log ਤੋਂ ਪੂਰੀ ਕਹਾਣੀ ਦੁਬਾਰਾ ਨਹੀਂ ਬਣਾਉ ਸਕਦੇ, ਤਾਂ ਸਿਸਟਮ audit-ready ਨਹੀਂ ਹੈ।
ਟੈਸਟ, ਪਾਇਲਟ, ਅਤੇ ਰੋਲਆਊਟ
ਇਕੱਠੇ ਡੀਪਲੋਇ ਅਤੇ ਹੋਸਟ ਕਰੋ
ਆਪਣਾ ਇੰਫਰਾਸਟਰਕਚਰ ਸੈਟਅਪ ਕੀਤੇ ਬਗੈਰ deployment, hosting ਅਤੇ custom domains ਨਾਲ ਲਾਂਚ ਕਰੋ।
ਟੈਸਟਿੰਗ ਅਤੇ ਰੋਲਆਊਟ ਉਹ ਸਟੇਜ ਹਨ ਜਿੱਥੇ exception tracking ਐਪ "ਚੰਗਾ ਵਿਚਾਰ" ਤੋਂ ਇਕ ਭਰੋਸੇਯੋਗ ਟੂਲ ਬਣਦੀ ਹੈ। ਉਹ ਕੁਝ ਫ਼ਲੋ ਜਿਸਨੂੰ ਹਰ ਰੋਜ਼ ਹੁੰਦਾ ਹੈ ਤੇ ਧਿਆਨ ਕੇਂਦਰਿਤ ਕਰੋ, ਫਿਰ ਹੌਲੀ-ਹੌਲੀ ਵਧਾਓ।
ਮੁੱਖ ਫਲੋਜ਼ end-to-end ਟੈਸਟ ਕਰੋ
ਇੱਕ ਸਧਾਰਨ test script (ਇੱਕ spreadsheet ਠੀਕ ਹੈ) ਬਣਾਓ ਜੋ ਪੂਰੀ ਲਾਈਫਸਾਈਕਲ ਨੂੰ ਚਲਾਏ:
- ਇੱਕ exception ਬਣਾਓ, ਫ਼ਾਈਲ ਲਗਾਓ, ਤੇ ਲਾਜ਼ਮੀ ਫੀਲਡਸ enforcement ਦੀ ਪੁਸ਼ਟੀ ਕਰੋ।
- ਇਸਨੂੰ ਸਹੀ ਵਿਅਕਤੀ/ਟੀਮ ਨੂੰ ਅਸਾਈਨ ਕਰੋ ਅਤੇ ਪੁਸ਼ਟੀ ਕਰੋ ਕਿ ਉਹ ਤੁਰੰਤ ਵੇਖ ਸਕਦੇ ਹਨ।
- Approve ਅਤੇ reject paths: ਯਕੀਨੀ ਬਣਾਓ ਕਿ ਹਰ ਫੈਸਲੇ ਵਿੱਚ ਕਾਰਨ ਅਤੇ timestamp ਦਰਜ ਹੁੰਦੇ ਹਨ।
- Exception ਨੂੰ ਬੰਦ ਕਰੋ ਅਤੇ ਪੁਸ਼ਟੀ ਕਰੋ ਕਿ ਉਹ read-only (ਜਾਂ ਸੀਮਿਤ-ਸੰਪਾਦ) ਹੋ ਗਿਆ।
- ਇਸਨੂੰ reopen ਕਰੋ ਅਤੇ ਯਕੀਨੀ ਬਣਾਓ ਕਿ history/audit trail ਸਾਫ਼ ਦਿਖਦੀ ਹੈ ਕਿ ਕੀ ਬਦਲਿਆ।
"ਅਸਲੀ ਜ਼ਿੰਦਗੀ" ਦੇ ਵੈਰੀਏਸ਼ਨ ਸ਼ਾਮਿਲ ਕਰੋ: priority ਬਦਲਨਾ, reassignments, ਅਤੇ overdue ਆਈਟਮ ਤਾਂ ਜੋ SLA ਅਤੇ resolution time ਗਣਨ ਦੀ ਜਾਂਚ ਹੋ ਸਕੇ।
ਗਲਤ ਡੇਟਾ ਰੋਕਣ ਲਈ validation ਅਤੇ error handling ਜੋੜੋ
ਜ਼ਿਆਦਾਤਰ ਰਿਪੋਰਟਿੰਗ ਸਮੱਸਿਆਵਾਂ inconsistent inputs ਤੋਂ ਆਉਂਦੀਆਂ ਹਨ। ਸ਼ੁਰੂ ਵਿੱਚ guardrails ਜੋੜੋ:
- ਲਾਜ਼ਮੀ ਫੀਲਡ (ਉਦਾਹਰਨ: process area, exception type, owner, due date)
- ਫ਼ਾਈਲ upload limits (size/type) ਨਾਲ ਸਪਸ਼ਟ ਸੁਨੇਹੇ
- Duplicate detection (ਉਦਾਹਰਨ: same customer/order/date) ਨਾਲ "link to existing" ਵਿਕਲਪ
- ਐਜ ਕੇਸਾਂ ਦੀ ਸੁਰੱਖਿਅਤ ਸੰਭਾਲ: missing assignee, invalid dates, deleted users
ਅਣਪਸੰਦ ਪਥਾਂ ਦਾ ਟੈਸਟ ਵੀ ਕਰੋ: network interruption, expired sessions, ਅਤੇ permissions errors।
ਪਹਿਲਾਂ ਇੱਕ ਟੀਮ ਨਾਲ ਪਾਇਲਟ ਚਲਾਓ
ਇੱਕ ਐਸੀ ਟੀਮ ਚੁਣੋ ਜਿਸਦਾ ਵਾਲੀਅਮ ਪ੍ਰਯਾਪਤ ਹੋਵੇ ਤਾਂ ਕਿ ਤੇਜ਼ੀ ਨਾਲ ਸਿੱਖਿਆ ਮਿਲੇ, ਪਰ ਛੋਟੀ ਹੋ ਜੇ ਤਾ ਪੂਰਕ ਬਦਲਾਅ ਤੇਜ਼ੀ ਨਾਲ ਕੀਤਾ ਜਾ ਸਕੇ। 2–4 ਹਫ਼ਤੇ ਲਈ ਪਾਇਲਟ ਕਰੋ, ਫਿਰ ਸਮੀਖਿਆ:
- ਕੀ ਫੀਲਡ ਉਹੀ ਜਾਣਕਾਰੀ capture ਕਰ ਰਹੇ ਹਨ ਜੋ ਲੋਕਾਂ ਨੂੰ ਹਕੀਕਤ ਵਿੱਚ ਚਾਹੀਦੀ ਹੈ?
- ਕੀ statuses ਵਰਕ ਦੇ ਢੰਗ ਨਾਲ ਮਿਲਦੇ ਹਨ?
- ਕੀ notifications ਲਾਭਦਾਇਕ ਹਨ ਜਾਂ ਸ਼ੋਰ?
ਹਰ ਹਫ਼ਤੇ ਬਦਲਾਅ ਕਰੋ, ਪਰ ਆਖਰੀ ਹਫ਼ਤੇ ਲਈ workflow freeze ਕਰੋ ਤਾਂ ਕਿ ਸਥਿਰਤਾ ਆ ਸਕੇ।
ਇੱਕ ਹਲਕਾ launch kit ਨਾਲ rollout ਕਰੋ
ਰੋਲਆਊਟ ਸਧਾਰਨ ਰੱਖੋ:
- ਇੱਕ ਇੱਕ-ਪੰਨਾ "ਐਪ ਨੂੰ ਅਸੀਂ ਕਿਵੇਂ ਵਰਤਦੇ ਹਾਂ" ਗਾਈਡ (statuses, ownership rules, SLAs)
- ਇੱਕ ਛੋਟੀ training ਸੈਸ਼ਨ (15–30 ਮਿੰਟ) ਅਤੇ ਰਿਕਾਰਡਿੰਗ
- ਇੱਕ launch checklist: access/roles, default routing, templates, ਅਤੇ support contact
ਲਾਂਚ ਦੇ ਬਾਅਦ ਪਹਿਲੇ ਹਫ਼ਤੇ ਦੈਨਿਕ ਤੌਰ 'ਤੇ adoption ਅਤੇ backlog health ਮੌਨੀਟਰ ਕਰੋ, ਫਿਰ ਹਫਤਾਵਾਰ।
ਸਮੇਂ ਦੇ ਨਾਲ ਰੱਖ-ਰਖਾਅ, ਸੁਧਾਰ, ਅਤੇ ਸਕੇਲ
ਐਪ ਸ਼ਿਪ ਕਰਨਾ ਸ਼ੁਰੂਆਤ ਹੈ: exception ਲੌਗ ਸੱਚਾ, ਤੇਜ਼, ਅਤੇ ਕਾਰੋਬਾਰ ਦੇ ਢੰਗ ਨਾਲ aligned ਰੱਖਣਾ ਅਸਲੀ ਕੰਮ ਹੈ।
ਵਰਤੋਂ ਅਤੇ ਬੌਟਲਨੇਕ ਮਾਨੀਟਰ ਕਰੋ
Exception ਫਲੋ ਨੂੰ ਇੱਕ operational pipeline ਵਾਂਗ ਸਮਝੋ। ਦੇਖੋ ਕਿ ਆਈਟਮ ਕਿੱਥੇ ਅਟਕਦੇ ਹਨ (status, team, owner ਨਾਲ), ਕਿਹੜੀਆਂ categories ਵੱਧ ਹਨ, ਅਤੇ SLAs ਹਕੀਕਤ ਵਿੱਚ ਕਿੰਨੀ ਵਾਜਬ ਹਨ।
ਇਕ ਸਧਾਰਨ ਮਹੀਨਾਵਾਰ ਚੈੱਕ ਕਾਫੀ ਹੁੰਦਾ ਹੈ:
- category ਅਨੁਸਾਰ median ਅਤੇ 90th percentile resolution time
- "Aging" counts (ਉਦਾਹਰਨ: open > 7/30/60 days)
- Reopen rates ਅਤੇ “sent back” loops
- ਸਭ ਤੋਂ ਵੱਢੇ ਖੇਤਰੀ ਫੀਲਡ ਜਿਹੜੇ ਖਾਲੀ ਛੱਡੇ ਜਾਂਦੇ ਹਨ (UX friction)
ਇਹ ਨਤੀਜੇ status definitions, required fields, ਅਤੇ routing rules ਨੂੰ ਸਧਾਰਨ ਤਰੀਕੇ ਨਾਲ ਬਦਲਣ ਲਈ ਵਰਤੋਂ—ਬਿਨਾਂ ਲੱਗਾਤਾਰ ਜਟਿਲਤਾ ਵਧਾਏ।
iteration backlog ਨੂੰ maintain ਕਰੋ
ਇੱਕ ਹਲਕੀ iteration backlog ਬਣਾਓ ਜੋ operators, approvers, ਅਤੇ compliance ਦੀਆਂ ਬੇਨਤੀਆਂ ਕੈਪਚਰ ਕਰੇ। ਆਮ ਆਈਟਮ:
- ਨਵੇਂ ਫੀਲਡ (ਸਿਰਫ ਜਦੋਂ ਰਿਪੋਰਟਿੰਗ ਜਾਂ ਫੈਸਲਾ-ਲੈਣ ਲਈ ਲੋੜ ਹੋਵੇ)
- Automations (auto-assign based on category, due-date defaults)
- Common exception types ਲਈ templates
- ਛੋਟੇ UI fixes ਜੋ misclassification ਘਟਾਉਂਦੇ ਹਨ
ਉਹਨਾਂ ਬਦਲਾਵਾਂ ਨੂੰ ਪ੍ਰਾਥਮਿਕਤਾ ਦਿਓ ਜੋ cycle time ਘਟਾਉਂਦੇ ਜਾਂ recurring exceptions ਰੋਕਦੇ ਹਨ।
Integrations: ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ, ਫਿਰ ਗਹਿਰਾਈ ਨਾਲ ਜੋੜੋ
Integrations ਮੂਲ ਸੱਰਵਿਸ ਨੂੰ ਵਧਾ ਸਕਦੀਆਂ ਹਨ, ਪਰ ਉਹ ਖਤਰਾ ਅਤੇ maintenance ਵੀ ਵਧਾਉਂਦੀਆਂ ਹਨ। read-only links ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ:
- External record IDs (ERP/CRM/ticketing) ਸਟੋਰ ਕਰੋ
- ਤ੍ਰਾਹ-ਲਿੰਕ ਤੋਂ source system (ਉਦਾਹਰਨ: order, customer, invoice) ਤੱਕ deep-link ਦਿਓ
ਜਦੋਂ ਸਿਸਟਮ ਸਥਿਰ ਹੋ ਜਾਵੇ, selective write-backs (status updates, comments) ਅਤੇ event-based syncing ਵੱਲ ਵਧੋ।
ਸਪਸ਼ਟ ਮਲਕੀਅਤ ਨਿਰਧਾਰਤ ਕਰੋ
ਉਹ ਹਿੱਸੇ ਜਿਨ੍ਹਾਂ ਨੂੰ ਅਕਸਰ ਬਦਲਿਆ ਜਾਂਦਾ ਹੈ ਲਈ ਮਾਲਿਕ ਨਿਰਧਾਰਤ ਕਰੋ:
- Category taxonomy (ਕਦੋਂ merge/retire ਕਰਨਾ)
- SLA ਪਰਿਭਾਸ਼ਾਵਾਂ ਅਤੇ escalation ਨਿਯਮ
- Workflow/routing rules ਅਤੇ notification ਨੀਤੀਆਂ
ਜਦੋਂ ਮਲਕੀਅਤ ਸਪਸ਼ਟ ਹੁੰਦੀ ਹੈ, ਤਾਂ ਐਪ ਵਫ਼ਾਦਾਰ ਰਹਿੰਦੀ ਹੈ ਜਦੋਂ ਵਾਲੀਅਮ ਵਧਦਾ ਹੈ ਅਤੇ ਟੀਮਾਂ reorganize ਹੁੰਦੀਆਂ ਹਨ।
build velocity ਤੇ ਕਾਇਮ ਰੱਖਣ ਲਈ ਇੱਕ ਟਿੱਪ
Exception tracking ਰੁਕਦਾ ਨਹੀਂ—ਇਹ ਟੀਮਾਂ ਸਿੱਖਣ ਤੇ ਬਦਲਦੇ ਹਨ। ਜੇ ਤੁਸੀਂ ਅਕਸਰ workflow ਬਦਲਣ ਦੀ ਉਮੀਦ ਕਰਦੇ ਹੋ, ਤਾਂ ਉਹ ਦApproach ਚੁਣੋ ਜੋ iteration ਨੂੰ ਸੁਰੱਖਿਅਤ ਬਨਾਏ (feature flags, staging, rollback) ਅਤੇ ਤੁਹਾਨੂੰ ਕੋਡ ਅਤੇ ਡੇਟਾ 'ਤੇ ਕੰਟਰੋਲ ਦਿੰਦਾ ਰਹੇ। ਪਲੇਟਫਾਰਮਾਂ ਜਿਵੇਂ Koder.ai ਅਕਸਰ ਇਥੇ ਵਰਤੇ ਜਾਂਦੇ ਹਨ ਤਾਂ ਕਿ initial version ਤੇਜ਼ੀ ਨਾਲ ship ਕੀਤਾ ਜਾਏ (Free/Pro tiers pilot ਲਈ ਕਾਫੀ), ਫਿਰ Business/Enterprise ਜ਼ਰੂਰਤਾਂ ਨਾਲ ਵਧੇ।