27 ਅਗ 2025·8 ਮਿੰਟ
Go ਵਰਕਰ ਪੂਲ ਬੈਕਗ੍ਰਾਊਂਡ ਜੌਬ ਲਈ: ਰੀਟ੍ਰਾਈ, ਰੱਦ ਅਤੇ ਸ਼ਟਡਾਊਨ
ਛੋਟੀ ਟੀਮਾਂ ਲਈ Go ਵਰਕਰ ਪੂਲ — ਬੈਕਗ੍ਰਾਊਂਡ ਜੌਬਾਂ ਨੂੰ ਰੀਟ੍ਰਾਈ, context ਰੱਦ ਅਤੇ ਸਾਫ਼ ਸ਼ਟਡਾਊਨ ਨਾਲ ਸੰਭਾਲਣ ਦੇ ਸਧਾਰਨ ਪੈਟਰਨ, ਭਾਰੀ ਇੰਫ੍ਰਾਸਟਰੱਕਚਰ ਸ਼ੁਰੂ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ।
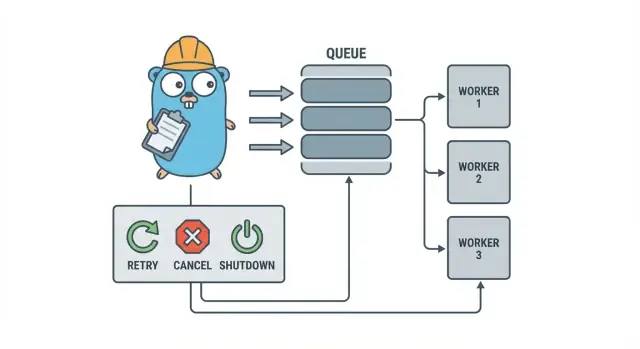
ਬੈਕਗ੍ਰਾਊਂਡ ਜੌਬ ਤੇਜ਼ੀ ਨਾਲ ਗੜਬੜ ਕਿਉਂ ਹੋ ਜਾਂਦੇ ਹਨ
ਇੱਕ ਛੋਟੀ Go ਸਰਵਿਸ ਵਿੱਚ, ਬੈਕਗ੍ਰਾਊਂਡ ਕੰਮ ਆਮ ਤੌਰ 'ਤੇ ਸਧਾਰਨ ਲਕਸ਼ ਨਾਲ ਸ਼ੁਰੂ ਹੁੰਦਾ ਹੈ: HTTP ਜਵਾਬ ਤੇਜ਼ੀ ਨਾਲ ਵਾਪਸ ਭੇਜੋ, ਫਿਰ ਢੀਰੇ ਕੰਮ ਬਾਅਦ ਵਿੱਚ ਕਰੋ। ਉਹ ਇਮੇਲ ਭੇਜਣਾ, ਇਮੇਜ ਰੀਸਾਈਜ਼ ਕਰਨਾ, ਕਿਸੇ ਹੋਰ API ਨਾਲ ਸਿੰਕ ਕਰਨਾ, ਸਰਚ ਇੰਡੈਕਸ ਦੁਬਾਰਾ ਬਣਾਉਣਾ ਜਾਂ ਰਾਤਰੀ ਰਿਪੋਰਟ ਚਲਾਉਣਾ ਹੋ ਸਕਦਾ ਹੈ।
ਮੁੱਦਾ ਇਹ ਹੈ ਕਿ ਇਹ ਜੌਬ ਵੀ ਅਸਲ ਉਤਪਾਦਨ ਕੰਮ ਹਨ, ਪਰ ਬਿਨਾਂ ਉਹਨਾਂ ਰਖਾਵਾਂ ਦੇ ਜੋ ਤੁਸੀਂ ਰਿਕਵੇਸਟ ਹੈਂਡਲਿੰਗ ਵਿੱਚ ਆਮ ਤੌਰ 'ਤੇ ਮਿਲਦੇ ਹੋ। HTTP ਹੈਂਡਲਰ ਤੋਂ ਸ਼ੁਰੂ ਕੀਤੀ ਗਈ ਇੱਕ goroutine ਠੀਕ ਲੱਗਦੀ ਹੈ ਜਦ ਤੱਕ ਡਿਪਲੋਇਮੈਂਟ ਮਿਡ-ਟਾਸਕ ਹੋ ਕੇ ਰੁਕ ਨਹੀਂ ਜਾਂਦਾ, ਕਿਸੇ upstream API ਦਾ ਸਲੋ ਹੋ ਜਾਣਾ ਨਹੀਂ ਹੁੰਦਾ, ਜਾਂ ਉਹੀ ਰਿਕਵੇਸਟ ਦੁਬਾਰਾ ਚਲ ਕੇ ਇੱਕੋ ਜੌਬ ਦੋ ਵਾਰੀ ਟਰਿੱਗਰ ਨਹੀਂ ਕਰ ਦਿੰਦੀ।
ਪਹਿਲੇ ਦਰਜੇ ਦੇ ਦਰਦ-ਬਿੰਦੂ ਅੰਦਾਜ਼ੇ-ਲਾਇਕ ਹਨ:
- ਫਸੇ ਹੋਏ ਜੌਬ: ਇੱਕ ਕਾਲ ਟੰਗ ਹੋ ਜਾਂਦੀ ਹੈ ਅਤੇ ਵਰਕਰ ਪ੍ਰਗਤੀ ਨਹੀਂ ਕਰਦੇ।
- ਨਕਲਿਆ ਹੋਇਆ ਕੰਮ: HTTP ਲੇਅਰ ਤੇ ਰੀਟ੍ਰਾਈ ਇੱਕੋ ਜੌਬ ਨੂੰ ਦੁਬਾਰਾ ਚਲਾਉਂਦੇ ਹਨ।
- ਕੋਈ ਸ਼ਟਡਾਊਨ ਯੋਜਨਾ ਨਹੀਂ: ਪ੍ਰੋਸੈਸ ਬੰਦ ਹੋ ਜਾਂਦਾ ਹੈ ਅਤੇ ਕੰਮ ਗੁਮ ਜਾਂ ਅਧ-ਪੂਰਨ ਰਹਿ ਜਾਂਦਾ ਹੈ।
- ਚੁੱਪਚਾਪ ਫੇਲਿਅਰ: ਐਰਰ ਇੱਕ ਵਾਰੀ ਲੌਗ ਹੁੰਦੇ ਹਨ (ਜਾਂ ਬਿਲਕੁਲ ਨਹੀਂ) ਅਤੇ ਗਾਇਬ ਹੋ ਜਾਂਦੇ ਹਨ।
- ਰੀਟ੍ਰਾਈ ਤੂਫਾਨ: ਫੇਲ੍ਹ ਹੋ ਰਹੇ ਜੌਬ ਤੁਰੰਤ ਰੀਟ੍ਰਾਈ ਹੋਕੇ Dependencies 'ਤੇ ਬੋਝ ਪਾ ਦਿੰਦੇ ਹਨ।
ਇਥੇ ਇੱਕ ਛੋਟਾ, ਸਪੱਸ਼ਟ ਪੈਟਰਨ ਜਿਵੇਂ Go ਵਰਕਰ ਪੂਲ ਮਦਦਗਾਰ ਹੁੰਦਾ ਹੈ। ਇਹ concurrency ਨੂੰ ਇੱਕ ਚੋਇਸ ਬਣਾਉਂਦਾ (N ਵਰਕਰ), “ਇਸਨੂੰ ਬਾਅਦ ਕਰੋ” ਨੂੰ ਇੱਕ ਸਪੱਸ਼ਟ ਜੌਬ ਕਿਸਮ ਬਣਾਉਂਦਾ, ਅਤੇ ਤੁਹਾਨੂੰ ਰੀਟ੍ਰਾਈ, ਟਾਈਮਆਉਟ ਅਤੇ ਰੱਦ ਕਰਨ ਲਈ ਇੱਕ ਥਾਂ ਦਿੰਦਾ ਹੈ।
ਉਦਾਹਰਨ: ਇੱਕ SaaS ਐਪ ਨੂੰ ਇਨਵਾਇਸ ਭੇਜਣੇ ਹੀ ਹੁੰਦੇ ਹਨ। ਤੁਸੀਂ 500 ਇਕੱਠੇ ਭੇਜਣ ਨਹੀਂ ਚਾਹੁੰਦੇ ਬਾਅਦ ਵਿੱਚ, ਅਤੇ ਨਾ ਹੀ ਤੁਸੀਂ ਇੱਕੋ ਇਨਵਾਇਸ ਨੂੰ ਦੁਬਾਰਾ ਭੇਜਣਾ ਚਾਹੁੰਦੇ ਕਿਉਂਕਿ ਇੱਕ ਰਿਕਵੇਸਟ ਰੀਟ੍ਰਾਈ ਹੋ ਗਿਆ। ਵਰਕਰ ਪੂਲ ਤੁਹਾਨੂੰ throughput ਸੀਮਤ ਕਰਨ ਦਿੰਦਾ ਅਤੇ “ਇਨਵਾਇਸ #123 ਭੇਜੋ” ਨੂੰ ਟ੍ਰੈਕ ਕੀਤੇ ਜਾਣ ਵਾਲੇ ਕੰਮ ਵਜੋਂ ਸਲਾਹਿਆ ਜਾ ਸਕਦਾ ਹੈ।
ਇਕ ਇਨ-ਪ੍ਰੋਸੈਸ ਪੂਲ ਉਹ ਸਮਾਨ ਨਹੀਂ ਜਦੋਂ ਤੁਹਾਨੂੰ durable, cross-process ਗਾਰੰਟੀਜ਼ ਦੀ ਲੋੜ ਹੋਵੇ। ਜੇ ਜੌਬ ਕਰੈਸ਼ ਤੋਂ ਬਚਣੇ ਚਾਹੀਦੇ ਹਨ, ਭਵਿੱਖ ਲਈ ਸ਼ਡਿਊਲ ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ, ਜਾਂ ਕਈ ਸਰਵਿਸز ਦੁਆਰਾ ਪ੍ਰੋਸੈਸ ਕਰਨੇ ਹੋਣ, ਤਾਂ ਤੁਹਾਨੂੰ ਅਕਸਰ ਇੱਕ ਅਸਲ 큐 ਅਤੇ ਜਾਬ ਸਟੇਟ ਲਈ ਨਿਰੰਤਰ ਸਟੋਰੇਜ ਦੀ ਲੋੜ ਪਏਗੀ।
ਵਰਕਰ ਪੂਲ ਮਾਡਲ ਆਮ ਭਾਸ਼ਾ ਵਿੱਚ
ਇੱਕ Go ਵਰਕਰ ਪੂਲ ਜ਼ਿਆਦਾ ਦਿਲਚਸਪ ਨਹੀਂ ਹੁੰਦਾ: ਕੰਮ ਨੂੰ ਇੱਕ ਕਿਊ ਵਿੱਚ ਰੱਖੋ, ਇੱਕ ਨਿਧਾਰਤ ਗਿਣਤੀ ਦੇ ਵਰਕਰ ਉਸਨੂੰ ਖਿੱਚਦੇ ਹਨ, ਅਤੇ ਯਕੀਨੀ ਬਣਾਓ ਕਿ ਇਹ ਸਾਰਾ ਪ੍ਰਕਿਰਿਆ ਸੂਚੱਜੇ ਤਰੀਕੇ ਨਾਲ ਰੁਕ ਸਕਦੀ ਹੈ।
ਮੁਢਲੀ ਸ਼ਬਦਾਵਲੀ:
- Job: ਇੱਕ ਇਕਾਈ ਕੰਮ, ਜਿਵੇਂ “ਇਸ ਇਮੇਜ ਨੂੰ ਰੀਸਾਈਜ਼ ਕਰੋ” ਜਾਂ “ਇਹ ਇਨਵਾਇਸ ਈਮੇਲ ਭੇਜੋ”।
- Queue: ਜਿੱਥੇ ਜੌਬ ਉਡੀਕ ਕਰਦੇ ਹਨ।
- Worker: ਇੱਕ goroutine ਜੋ ਲਗਾਤਾਰ ਜੌਬ ਲੈਂਦਾ ਅਤੇ ਚਲਾਉਂਦਾ ਹੈ।
- Dispatcher: ਉਹ ਹਿੱਸਾ ਜੋ ਜੌਬ ਲੈਂਦਾ ਅਤੇ ਕਿਊ ਵਿੱਚ ਪਾਉਂਦਾ ਹੈ।
ਬਹੁਤ ਸਾਰੇ in-process ਡਿਜ਼ਾਈਨਾਂ ਵਿੱਚ, Go channel ਕਿਊ ਹੁੰਦਾ ਹੈ। ਇੱਕ buffered channel ਇੱਕ ਸੀਮਿਤ ਗਿਣਤੀ ਦੇ ਜੌਬ ਰੱਖ ਸਕਦਾ ਹੈ ਜਦ ਤੱਕ ਪ੍ਰੋਡੀੂਸਰ ਬਲੌਕ ਨਾ ਹੋ ਜਾਣ। ਉਹ ਬਲੌਕ ਬੈਕਪ੍ਰੈਸ਼ਰ ਹੈ, ਅਤੇ ਅਕਸਰ ਇਹ ਤੁਹਾਡੇ ਸੇਵਾ ਨੂੰ ਅਨੰਤ ਕੰਮ ਸਵੀਕਾਰ ਕਰਨ ਤੋਂ ਅਤੇ ਟ੍ਰੈਫਿਕ spike ਤੇ ਮੈਮੋਰੀ ਖ਼ਤਮ ਹੋਣ ਤੋਂ ਬਚਾਉਂਦਾ ਹੈ।
ਬਫ਼ਰ ਦਾ ਆਕਾਰ ਸਿਸਟਮ ਦੀ ਸੰਵੇਦਨਸ਼ੀਲਤਾ ਬਦਲ ਦਿੰਦਾ ਹੈ। ਛੋਟਾ ਬਫ਼ਰ ਦਬਾਅ ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਦਿਖਾਵਦਾ ਹੈ (ਕਾਲਰ ਜਲਦੀ ਰੁਕਦੇ ਹਨ)। ਵੱਡਾ ਬਫ਼ਰ ਛੋਟੇ ਬਰਸਟਾਂ ਨੂੰ ਸਮਤਲ ਕਰਦਾ ਹੈ ਪਰ ਓਵਰਲੋਡ ਨੂੰ ਬਾਅਦ ਵਿੱਚ ਛੁਪਾ ਸਕਦਾ ਹੈ। ਲਾਈਕ ਕੋਈ ਸੁਪਰ ਸੰਖਿਆ ਨਹੀਂ, ਸਿਰਫ਼ ਉਹ ਨੰਬਰ ਜੋ ਤੁਸੀਂ ਬਰਦਾਸ਼ਤ ਕਰ ਸਕਦੇ ਹੋ।
ਤੁਸੀਂ ਇਹ ਵੀ ਚੁਣਦੇ ਹੋ ਕਿ ਪੂਲ ਸਾਈਜ਼ ਫਿਕਸਡ ਹੋਵੇ ਜਾਂ ਬਦਲ ਸਕੇ। ਫਿਕਸਡ ਪੂਲ ਸੋਚਣ ਵਿੱਚ ਆਸਾਨ ਹੁੰਦੇ ਹਨ ਅਤੇ ਸਰੋਤ ਵਰਤੋਂ ਨਿਯਤ ਰੱਖਦੇ ਹਨ। ਆਟੋ-ਸਕੇਲਿੰਗ ਵਰਕਰ ਅਨਅਨੁਸ਼ਾਸ਼ਤ ਲੋਡ ਵਿੱਚ ਮਦਦਗਾਰ ਹੋ ਸਕਦੇ ਹਨ, ਪਰ ਇਹ ਫੈਸਲੇ ਲਿਆਉਂਦੇ ਹਨ ਜਿਨ੍ਹਾਂ ਨੂੰ ਤੁਸੀਂ ਰੱਖ-ਰਖਾਅ ਕਰਨਾ ਪਏਗਾ (ਕਦੋਂ ਸਕੇਲ ਕਰਨਾ, ਕਿੰਨਾ, ਅਤੇ ਕਦੋਂ ਵਾਪਸ ਘਟਾਉਣਾ)।
ਆਖਿਰਕਾਰ, ਇੱਕ in-process ਪੂਲ ਵਿੱਚ “ack” ਆਮ ਤੌਰ 'ਤੇ ਸਿਰਫ਼ ਇਹ ਮਤਲਬ ਰੱਖਦਾ ਹੈ ਕਿ “ਵਰਕਰ ਨੇ ਜੌਬ ਖਤਮ ਕੀਤਾ ਅਤੇ ਕੋਈ ਐਰਰ ਵਾਪਸ ਨਹੀਂ ਕੀਤਾ।” ਕੋਈ ਬਾਹਰੀ ਬ੍ਰੋਕਰ ڊੈਲਿਵਰੀ ਦੀ ਪੁਸ਼ਟੀ ਨਹੀਂ ਕਰ ਰਿਹਾ, ਇਸ ਲਈ ਤੁਹਾਡਾ ਕੋਡ ਪਰਿਭਾਸ਼ਿਤ ਕਰਦਾ ਹੈ ਕਿ “ਡਨ” ਦਾ ਕੀ ਮਤਲਬ ਹੈ ਅਤੇ ਜਦੋਂ ਜੌਬ ਫੇਲ ਹੋਵੇ ਜਾਂ ਰੱਦ ਹੋਵੇ ਤਾਂ ਕੀ ਹੁੰਦਾ ਹੈ।
ਡਿਜ਼ਾਈਨ ਲੱਖੇ: ਰੀਟ੍ਰਾਈ, ਰੱਦ, ਅਤੇ ਸਾਫ਼ ਸ਼ਟਡਾਊਨ
ਵਰਕਰ ਪੂਲ ਮਕੈਨੀਕਲ ਤੌਰ 'ਤੇ ਸਧਾਰਨ ਹੈ: ਨਿਧਾਰਤ ਗਿਣਤੀ ਦੇ ਵਰਕਰ ਚਲਾਓ, ਉਹਨਾਂ ਨੂੰ ਜੌਬ ਫੀਡ ਕਰੋ, ਅਤੇ ਉਹਨਾਂ ਨੂੰ ਪ੍ਰੋਸੈਸ ਕਰਵਾਓ। ਮੁੱਲ ਨਿਯੰਤਰਣ ਹੈ: ਪੂਰਵਾਨੁਮਾਨਯੋਗ concurrency, ਸਪੱਸ਼ਟ ਫੇਲਿਅਰ ਹੈਂਡਲਿੰਗ, ਅਤੇ ਇੱਕ ਸ਼ਟਡਾਊਨ ਰਸਤਾ ਜੋ ਅਧੂਰੇ ਕੰਮ ਨੂੰ ਪਿਛੇ ਨਹੀਂ ਛੱਡਦਾ।
ਛੋਟੀਆਂ ਟੀਮਾਂ ਨੂੰ ਸਾਂਭਣ ਲਈ ਤਿੰਨੇ ਲੱਖੇ:
- ਕੰਕਰੈਂਸੀ ਸੀਮਤ ਕਰੋ ਤਾਂ ਜੋ ਇੱਕ spike database ਜਾਂ ਬਾਹਰੀ API ਨੂੰ ਨੁਕਸਾਨ ਨਾ ਪੁੰਚਾਏ।
- ਕੰਮ ਗੁਮ ਨਾ ਹੋਵੇ (ਜਾਂ ਘੱਟੋ-ਘੱਟ ਇਹ ਪਤਾ ਹੋਵੇ ਕਿ ਕੀ ਡ੍ਰੌਪ ਹੋਇਆ ਅਤੇ ਕਿਉਂ)।
- ਡਿਬੱਗ ਕਰਨਯੋਗ ਰਹੋ: ਹਰ ਜੌਬ ਨੂੰ ਲੋਗ ਅਤੇ ਕੁਝ ਕਾਊਂਟਰਾਂ ਰਾਹੀਂ ਟ੍ਰੇਸ ਕੀਤਾ ਜਾ ਸਕੇ।
ਜ਼ਿਆਦਾਤਰ ਫੇਲਿਅਰ ਸਧਾਰਨ ਹੁੰਦੇ ਹਨ, ਪਰ ਤੁਹਾਨੂੰ ਉਹਨਾਂ ਨੂੰ ਵੱਖ-ਵੱਖ ਵਰਤਣਾ ਚਾਹੀਦਾ ਹੈ:
- ਅਸਤਾਈ ਐਰਰ (ਨੈਟਵਰਕ ਹਿੱਕਅਪ, ਰੇਟ ਲਿਮਿਟ) ਜੋ ਰੀਟ੍ਰਾਈ ਯੋਗ ਹਨ।
- ਕਾਇਮੀ ਐਰਰ (ਖਰਾਬ ਇਨਪੁੱਟ, ਮਿਸਿੰਗ ਰਿਕਾਰਡ) ਜੋ ਰੀਟ੍ਰਾਈ ਨਹੀਂ ਹੋਣੇ ਚਾਹੀਦੇ।
- ਟਾਈਮਆਉਟ (ਕੋਈ dependency ਹੈਂਗ) ਜਿਸਨੂੰ ਕੱਟ ਕੇ ਵਰਕਰਾਂ ਨੂੰ ਬਚਾਇਆ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ।
ਰੱਦ ਕਰਨਾ ਐਰਰ ਤੋਂ ਵੱਖਰਾ ਹੈ। ਇਹ ਇੱਕ ਫੈਸਲਾ ਹੈ: ਯੂਜ਼ਰ ਨੇ ਰੱਦ ਕੀਤਾ, ਡਿਪਲੋਇਮੈਂਟ ਨੇ ਤੁਹਾਡਾ ਪ੍ਰੋਸੈਸ ਬਦਲਿਆ, ਜਾਂ ਤੁਹਾਡੀ ਸਰਵਿਸ ਸ਼ਟਡਾਊਨ ਹੋ ਰਹੀ ਹੈ। Go ਵਿੱਚ, context cancellation ਨੂੰ ਇੱਕ ਪਹਿਲ-ਕਲਾਸ ਸਿਗਨਲ ਸਮਝੋ, ਅਤੇ ਯਕੀਨੀ ਬਣਾਓ ਕਿ ਹਰ ਜੌਬ ਮਹਿੰਗਾ ਕੰਮ ਸ਼ੁਰੂ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ ਅਤੇ ਕਈ ਸੁਰੱਖਿਅਤ ਬਿੰਦੂਆਂ 'ਤੇ ਇਸਨੂੰ ਚੈੱਕ ਕਰੇ।
ਸਾਫ਼ ਸ਼ਟਡਾਊਨ ਹੀ ਉਹ ਜ਼ਗ੍ਹਾ ਹੈ ਜਿੱਥੇ ਬਹੁਤ ਸਾਰੇ ਪੂਲ ਗਲਤ ਹੋ ਜਾਂਦੇ ਹਨ। ਪਹਿਲਾਂ ਤੈਅ ਕਰੋ ਕਿ ਤੁਹਾਡੇ ਜੌਬ ਲਈ “ਸੁਰੱਖਿਅਤ” ਦਾ ਕੀ ਮਤਲਬ ਹੈ: ਕੀ ਤੁਸੀਂ ਇਨ-ਫਲਾਈਟ ਕੰਮ ਖਤਮ ਕਰੋਗੇ, ਜਾਂ ਤੁਸੀਂ ਤੇਜ਼ੀ ਨਾਲ ਬੰਦ ਹੋ ਕੇ ਬਾਅਦ ਵਿੱਚ ਦੁਬਾਰਾ ਚਲਾਉਣਾ ਚਾਹੁੰਦੇ ਹੋ? ਇੱਕ ਵਰਤੋਂਯੋਗ ਫਲੋ ਇਹ ਹੈ:
- ਨਵੀਆਂ ਜੌਬਾਂ ਲੈਣਾ ਰੋਕੋ।
- ਵਰਕਰਾਂ ਨੂੰ ਦੱਸੋ ਕਿ ਉਹ ਆਪਣਾ ਮੌਜੂਦਾ ਜੌਬ ਖਤਮ ਕਰਨ ਤੋਂ ਬਾਅਦ ਰੁਕ ਜਾਣ (ਜਾਂ ਤੁਰੰਤ ਰੁਕੋ)।
- ਇੱਕ ਡੈਡਲਾਈਨ ਤੱਕ ਉਡੀਕ ਕਰੋ, ਫਿਰ ਜ਼ਬਰਦਸਤੀ ਬੰਦ ਕਰੋ।
ਜੇ ਤੁਸੀਂ ਇਹ ਨਿਯਮ ਪਹਿਲਾਂ ਹੀ ਤੈਅ ਕਰ ਲੈਂਦੇ ਹੋ, ਤਾਂ ਰੀਟ੍ਰਾਈ, ਰੱਦ ਅਤੇ ਸ਼ਟਡਾਊਨ ਛੋਟੇ ਅਤੇ ਪੂਰਵਾਨੁਮਾਨਯੋਗ ਰਹਿਣਗੇ ਬਜਾਏ ਕਿ ਇੱਕ ਘਰੇਲੂ ਫਰੇਮਵਰਕ ਬਣ ਜਾਣ।
ਕਦਮ-ਦਰ-ਕਦਮ: ਇਕ ਬੁਨਿਆਦੀ ਵਰਕਰ ਪੂਲ ਬਣਾਓ
ਵਰਕਰ ਪੂਲ ਸਿਰਫ਼ goroutine ਗਰੁੱਪ ਹੈ ਜੋ ਚੈਨਲ ਤੋਂ ਜੌਬ ਖਿੱਚ ਕੇ ਕੰਮ ਕਰਦੇ ਹਨ। ਮਹੱਤਵਪੂਰਨ ਹਿੱਸਾ ਇਹ ਹੈ ਕਿ ਮੂਲ ਗੱਲਾਂ ਪੂਰਵਾਨੁਮਾਨਯੋਗ ਹੋਣ: ਜੌਬ ਕਿਵੇਂ ਦਿਖਦਾ ਹੈ, ਵਰਕਰ ਕਿਵੇਂ ਰੁਕਦੇ ਹਨ, ਅਤੇ ਤੁਸੀਂ ਕਿਵੇਂ ਜਾਣਦੇ ਹੋ ਕਿ ਸਾਰੀ ਕਮਾਈ ਮੁਕੰਮਲ ਹੋ ਗਈ।
ਸੰਭਾਲਣ ਲਈ ਇੱਕ ਸਧਾਰਨ Job ਕਿਸਮ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ। ਇਸਨੂੰ ਲੌਗ ਲਈ ID, payload (ਕੀ ਪ੍ਰੋਸੈਸ ਕਰਨਾ ਹੈ), ਇੱਕ ਅਟੈਂਪਟ ਕਾਉੰਟਰ (بعد ਵਿੱਚ ਰੀਟ੍ਰਾਈ ਲਈ), timestamps, ਅਤੇ ਪ੍ਰਤੀ-ਜੌਬ context ਡੇਟਾ ਲਈ ਇੱਕ ਥਾਂ ਦਿਓ।
package jobs
import (
"context"
"sync"
"time"
)
type Job struct {
ID string
Payload any
Attempt int
Enqueued time.Time
Started time.Time
Ctx context.Context
Meta map[string]string
}
type Pool struct {
ctx context.Context
cancel context.CancelFunc
jobs chan Job
wg sync.WaitGroup
}
func New(size, queue int) *Pool {
ctx, cancel := context.WithCancel(context.Background())
p := \u00026Pool{ctx: ctx, cancel: cancel, jobs: make(chan Job, queue)}
for i := 0; i \u0003c size; i++ {
go p.worker(i)
}
return p
}
func (p *Pool) worker(_ int) {
for {
select {
case \u0003c-p.ctx.Done():
return
case job, ok := \u0003c-p.jobs:
if !ok {
return
}
p.wg.Add(1)
job.Started = time.Now()
_ = job // call your handler here
p.wg.Done()
}
}
}
// Submit blocks when the queue is full (backpressure).
func (p *Pool) Submit(job Job) error {
if job.Enqueued.IsZero() {
job.Enqueued = time.Now()
}
select {
case \u0003c-p.ctx.Done():
return context.Canceled
case p.jobs \u0003c- job:
return nil
}
}
func (p *Pool) Stop() { p.cancel() }
func (p *Pool) Wait() { p.wg.Wait() }
ਕੁਝ عملي ਚੋਣ ਜੋ ਤੁਸੀਂ ਤੁਰੰਤ ਕਰੋਗੇ:
- ਕਿਊ ਆਕਾਰ ਚੁਣੋ ਉਸ ਅਨੁਸਾਰ ਕਿ ਤੁਸੀਂ ਕਿੰਨੀ ਉਡੀਕ ਬਰਦਾਸ਼ਤ ਕਰ ਸਕਦੇ ਹੋ।
- ਨਿਰਣਾ ਕਰੋ ਕਿ ਬੈਕਪ੍ਰੈਸ਼ਰ ਕਾਲਰਾਂ ਲਈ ਕੀ ਮਤਲਬ ਰੱਖਦਾ ਹੈ: ਬਲੌਕ, ਐਰਰ ਵਾਪਸ ਕਰਨਾ, ਜਾਂ ਡਰੌਪ ਕਰਨਾ।
Stop()ਅਤੇWait()ਨੂੰ ਅਲੱਗ ਰੱਖੋ ਤਾਂ ਜੋ ਤੁਸੀਂ ਪਹਿਲਾਂ intake ਰੋਕ ਸਕੋ ਅਤੇ ਫਿਰ ਇਨ-ਫਲਾਈਟ ਕੰਮ ਖਤਮ ਹੋਣ ਦੀ ਉਡੀਕ ਕਰੋ।
ਬਿਨਾਂ ਫਰੇਮਵਰਕ ਬਣਾਉਣ ਦੇ ਰੀਟ੍ਰਾਈ ਜੋੜਨਾ
ਰੀਟ੍ਰਾਈ ਲਾਭਦਾਇਕ ਹਨ, ਪਰ ਉਹੀ ਜਗ੍ਹਾ ਹੈ ਜਿੱਥੇ ਵਰਕਰ ਪੂਲ ਗੁੰਝਲਦਾਰ ਹੋ ਜਾਂਦੇ ਹਨ। ਲਕਸ਼ ਨੂੰ ਸੰਗੀਨ ਨਾ ਬਣਾਓ: ਕੇਵਲ ਉਹਨਾਂ ਗਲਤੀਆਂ ਨੂੰ ਰੀਟ੍ਰਾਈ ਕਰੋ ਜਿਨ੍ਹਾਂ ਨੂੰ ਮੁੜ ਕੋਸ਼ਿਸ਼ ਕਰਨ ਨਾਲ ਅਸਲ ਚਾਂਸ ਹੋਵੇ, ਅਤੇ ਜਦੋਂ ਇਹ ਨਹੀਂ ਹੈ ਤੁਰੰਤ ਰੋਕ ਦਿਓ।
ਸ਼ੁਰੂਆਤ ਰੀਟ੍ਰਾਈਏਬਲ ਨਿਸ਼ਾਨਿਆਂ ਤੋਂ ਕਰੋ। ਅਸਤਾਈ ਸਮੱਸਿਆਵਾਂ (ਨੈੱਟਵਰਕ, ਟਾਈਮਆਉਟ, “ਫਿਰ ਕੋਸ਼ਿਸ਼ ਕਰੋ” ਜਵਾਬ) ਆਮ ਤੌਰ 'ਤੇ ਰੀਟ੍ਰਾਈ ਲਾਇਕ ਹੁੰਦੀਆਂ ਹਨ। ਕਾਇਮੀ ਸਮੱਸਿਆਵਾਂ (ਖਰਾਬ ਇਨਪੁੱਟ, ਮਿਸਿੰਗ ਰਿਕਾਰਡ, ਪੇਰਮਿਸ਼ਨ ਡਿਨਾਇਡ) ਨਹੀਂ।
ਇੱਕ ਛੋਟੀ ਰੀਟ੍ਰਾਈ ਪਾਲਿਸੀ ਆਮਤੌਰ 'ਤੇ ਕਾਫੀ ਹੁੰਦੀ ਹੈ:
- ਐਰਰ ਨੂੰ retryable vs non-retryable ਚਿਹਰ੍ਹੇ ਤੌਰ 'ਤੇ ਨਿਸ਼ਾਨ ਲਗਾਓ (ਉਦਾਹਰਣ ਲਈ,
Retryable(err)ਹੈਲਪਰ ਨਾਲ ਲਪੇਟੋ)। - ਇੱਕ ਮੈਕਸ ਅਟੈਂਪਟ ਕਾਉਂਟ ਰੱਖੋ (ਅਕਸਰ 3 ਤੋਂ 5)। ਇਸ ਤੋਂ ਬਾਅਦ ਆਮ ਤੌਰ 'ਤੇ ਵਕਤ ਘੁੰਮਾਉਣਾ ਹੀ ਹੈ।
- exponential backoff ਨਾਲ jitter ਵਰਤੋ ਤਾਂ ਜੋ ਜੌਬ sync ਵਿੱਚ ਰੀਟ੍ਰਾਈ ਨਾ ਕਰਨ।
- ਡੀਲੇ ਨੂੰ ਕੈਪ ਕਰੋ (ਉਦਾਹਰਨ ਲਈ, ਕਦੇ ਵੀ 30 ਸਕਿੰਟ ਤੋਂ ਵੱਧ ਸੁੱਤੋ ਨਾ)।
- ਰੀਟ੍ਰਾਈਜ਼ ਨੂੰ ਲੌਗ ਕਰੋ ਜਿਸ ਵਿੱਚ ਅਟੈਂਪਟ ਨੰਬਰ, ਅਗਲਾ ਡੀਲੇ, ਅਤੇ ਜੌਬ ID ਹੋਵੇ।
ਬੈਕਓਫ਼ ਜ਼ਿਆਦਾ ਮੁਸ਼ਕਲ ਹੋਣੀ ਲੋੜੀਂਦੀ ਨਹੀਂ। ਆਮ ਫਾਰਮ delay = min(base * 2^(attempt-1), max) ਹੈ, ਫਿਰ jitter ਜੋੜੋ (+/- 20% ਰੈਂਡਮ)। jitter ਜਰੂਰੀ ਹੈ ਕਿਉਂਕਿ ਨਹੀਂ ਤਾਂ ਕਈ ਵਰਕਰ ਇਕੱਠੇ ਫੇਲ ਹੋ ਕੇ ਇਕੱਠੇ ਰੀਟ੍ਰਾਈ ਕਰਾਂਗੇ।
ਡੀਲੇ ਕਿੱਥੇ ਰੱਖੀ ਜਾਵੇ? ਛੋਟੇ ਸਿਸਟਮਾਂ ਲਈ, ਵਰਕਰ ਦੇ ਅੰਦਰ ਸੌਣਾ ਠੀਕ ਹੈ, ਪਰ ਇਹ ਇੱਕ ਵਰਕਰ ਸਲੋਟ ਨੂੰ ਬੈਠਾ ਦਿੰਦਾ ਹੈ। ਜੇ ਰੀਟ੍ਰਾਈ ਕਿਰੇ ਮਾਮਲੇ ਵਿੱਚ ਅਕਸਰ ਹਨ ਜਾਂ ਡੀਲੇ ਲੰਮੇ ਹਨ, ਤਾਂ ਜੌਬ ਨੂੰ "run after" ਟਾਈਮਸਟੈਂਪ ਨਾਲ ਦੁਬਾਰਾ ਕਿਊ ਵਿੱਚ ਪਾਉਣ ਬਾਰੇ ਸੋਚੋ ਤਾਂ ਜੋ ਵਰਕਰ ਹੋਰ ਕੰਮ 'ਤੇ ਰੁਝੇ ਰਹਿਣ।
ਅਖੀਰਲੇ ਫੇਲ ਹੁੰਦੇ ਸਮੇਂ, ਸਪਸ਼ਟ ਹੋਵੋ। ਫੇਲ ਹੋਇਆ ਜੌਬ (ਅਤੇ ਆਖਰੀ ਐਰਰ) ਸੰਭਾਲ ਕੇ ਰੱਖੋ ਤਾਂ ਕਿ ਰਿਵਿਊ ਕੀਤੀ ਜਾ ਸਕੇ, ਦੁਬਾਰਾ ਚਲਾਉਣ ਲਈ ਕਾਫੀ ਸੰਦਰਭ ਲੌਗ ਕਰੋ, ਜਾਂ ਇਸਨੂੰ ਇੱਕ dead list ਵਿੱਚ ਪਾਓ ਜੋ ਤੁਸੀਂ ਨਿਯਮਤ ਤੌਰ 'ਤੇ ਚੈੱਕ ਕਰੋ। ਚੁੱਪਚਾਪ ਡਰੌਪਿੰਗ ਤੋਂ ਬਚੋ। ਇੱਕ ਪੂਲ ਜੋ ਫੇਲਿਅਰ ਨੂੰ ਲੁਕਾਉਂਦਾ ਹੈ ਉਹ ਬਿਨਾਂ ਰੀਟ੍ਰਾਈ ਵਰਗੋਂ ਵੀ ਖਰਾਬ ਹੈ।
ਰੱਦ ਅਤੇ ਟਾਈਮਆਉਟ ਜੋ ਅਸਲ ਵਿੱਚ ਕੰਮ ਰੋਕਦੇ ਹਨ
ਜੌਬ ਹੈਂਡਲਰਾਂ ਵਿੱਚ idempotency ਜੋੜੋ
Koder.ai ਤੋਂ ਮੰਗੋ ਕਿ ਉਹ ਤੁਹਾਡੇ ਜੌਬ ਹੈਂਡਲਰਾਂ ਵਿੱਚ idempotency ਕੀਜ਼ ਅਤੇ ਸੁਰੱਖਿਅਤ ਰੀਟ੍ਰਾਈ ਜੋੜ ਦੇਵੇ।
ਵਰਕਰ ਪੂਲ ਸਿਰਫ਼ ਉਸ ਵੇਲੇ ਹੀ ਸੁਰੱਖਿਅਤ ਮਹਿਸੂਸ ਹੁੰਦੇ ਹਨ ਜਦੋਂ ਤੁਸੀਂ ਉਹਨਾਂ ਨੂੰ ਰੋਕ ਸਕਦੇ ਹੋ। ਸਭ ਤੋਂ ਸਧਾਰਣ ਨੀਅਮ ਇਹ ਹੈ: ਹਰ ਲੇਅਰ ਜੋ ਬਲੌਕ ਕਰ ਸਕਦੀ ਹੈ, ਉਹਨੂੰ context.Context ਦਿਓ। ਇਸਦਾ ਮਤਲਬ ਹੈ submission, execution, ਅਤੇ cleanup — ਸਭ ਤੇ context ਲਪੇਟੋ।
ਇੱਕ عملي ਸੈਟਅਪ ਦੋ ਟਾਈਮ ਸੀਮ੍ਹਾਂ ਵਰਤਦਾ ਹੈ:
- ਇੱਕ ਪ੍ਰਤੀ-ਜੌਬ ਟਾਈਮਆਉਟ ਤਾਂ ਜੋ ਇੱਕ ਟਾਸਕ ਇੱਕ ਵਰਕਰ ਨੂੰ ਸਦਾ ਲਈ ਘੇਰ ਨਾ ਲਏ।
- ਇੱਕ ਸ਼ਟਡਾਊਨ ਟਾਈਮਆਉਟ ਤਾਂ ਜੋ ਪ੍ਰੋਸੈਸ ਬਾਹਰ ਨਿਕਲ ਸਕੇ ਜੇ ਕੁਝ ਜੌਬ ਸਹਿਯੋਗ ਨਹੀਂ ਕਰਦੇ।
End-to-end context ਵਰਤੋ
ਹਰ ਜੌਬ ਨੂੰ ਕੰਮ ਵਾਲੇ context ਤੋਂ ਉਤਪੰਨ context ਦਿਓ। ਫਿਰ ਹਰ ਧੀਮੀ ਕਾਲ (DB, HTTP, ਕਿਊ, ਫਾਇਲ I/O) ਨੂੰ ਉਹ context ਵਰਤਣਾ ਚਾਹੀਦਾ ਹੈ ਤਾਂ ਜੋ ਉਹ ਅੱਗੇ ਵਾਪਸ ਆ ਸਕੇ।
func worker(ctx context.Context, jobs \u0003c-chan Job) {
for {
select {
case \u0003c-ctx.Done():
return
case job, ok := \u0003c-jobs:
if !ok { return }
jobCtx, cancel := context.WithTimeout(ctx, job.Timeout)
_ = job.Run(jobCtx) // Run must respect jobCtx
cancel()
}
}
}
ਜੇ Run ਤੁਹਾਡੇ DB ਜਾਂ API ਨੂੰ ਕਾਲ ਕਰਦਾ ਹੈ, ਤਾਂ ਉਹਨਾਂ ਕਾਲਜ਼ ਵਿੱਚ context ਨੂੰ ਵਾਇਰ ਕਰੋ (ਉਦਾਹਰਨ ਲਈ, QueryContext, NewRequestWithContext, ਜਾਂ client ਮੈਥਡ ਜੋ context ਲੈਂਦੇ ਹਨ)। ਜੇ ਤੁਸੀਂ ਕਿਸੇ ਇੱਕ ਥਾਂ ਨੂੰ ਨਜ਼ਰਅੰਦਾਜ਼ ਕਰਦੇ ਹੋ, ਤਾਂ ਰੱਦ “best effort” ਬਣ ਜਾਂਦਾ ਹੈ ਅਤੇ ਆਮ ਤੌਰ 'ਤੇ ਉਹ ਸਮਾਂ ਵਿੱਚ ਫੇਲ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਤੁਹਾਨੂੰ ਸਬ ਤੋਂ ਵੱਧ ਲੋੜ ਹੁੰਦੀ ਹੈ।
ਅੱਧੇ-ਕੰਮ ਅਤੇ "ਸੇਫ਼ ਟੂ ਰੀਟ੍ਰਾਈ" ਕਦਮ
ਰੱਦ ਮਿਡ-ਜੌਬ ਹੋ ਸਕਦੀ ਹੈ, ਇਸ ਲਈ ਅਧੂਰਾ ਕੰਮ ਆਮ ਸਮਝੋ। ਦੁਬਾਰਾ ਚਲਾਉਣ ਲਈ idempotent ਕਦਮ ਕਰੋ ਤਾਂ ਕਿ ਦੁਬਾਰਿਆਂ ਵਿੱਚ ਡੁਪਲਿਕੇਟ ਨਾ ਬਣਨ। ਆਮ ਤਰੀਕੇ ਹਨ: ਇੰਸਰਟ ਲਈ ਯੂਨੀਕ ਕੀਜ਼ ਦਾ ਉਪਯੋਗ (ਜਾਂ upsert), ਪ੍ਰਗਤੀ ਮਾਰਕਰ ਲਿਖਣਾ (started/done), ਨਤੀਜੇ ਸਟੋਰ ਕਰਨਾ ਪਹਿਲਾਂ, ਅਤੇ ਕਦਮਾਂ ਦਰਮਿਆਨ ctx.Err() ਚੈੱਕ ਕਰਨਾ।
ਸ਼ਟਡਾਊਨ ਨੂੰ ਇੱਕ ਡੈਡਲਾਈਨ ਵਾਂਗ ਸਲੂਕ ਕਰੋ: ਨਵੀਆਂ ਜੌਬਾਂ ਲੈਣਾ ਰੋਕੋ, ਵਰਕਰ contexts ਰੱਦ ਕਰੋ, ਅਤੇ ਸਿਰਫ਼ ਸ਼ਟਡਾਊਨ ਟਾਈਮਆਉਟ ਤੱਕ ਇਨ-ਫਲਾਈਟ ਜੌਬਾਂ ਨੂੰ ਬੰਦ ਹੋਣ ਦੀ ਉਡੀਕ ਕਰੋ।
ਸਾਫ਼ ਸ਼ਟਡਾਊਨ: ਜਦੋਂ ਪ੍ਰੋਸੈਸ ਨੂੰ ਬੰਦ ਕਰਨਾ ਪਵੇ
ਸਾਫ਼ ਸ਼ਟਡਾਊਨ ਦਾ ਇਕ ਮਕਸਦ ਹੈ: ਨਵਾਂ ਕੰਮ ਲੈਣਾ ਰੋਕੋ, ਇਨ-ਫਲਾਈਟ ਕੰਮ ਨੂੰ ਰੁਕਣ ਲਈ ਕਹੋ, ਅਤੇ ਸਿਸਟਮ ਨੂੰ ਅਜਿਹੇ ਹਾਲਤ ਵਿੱਚ ਬੰਦ ਕਰੋ ਜੋ ਅਨਿਯਮਿਤ ਨਾ ਹੋਵੇ।
ਸਭ ਤੋਂ ਪਹਿਲਾਂ ਸਿਗਨਲਾਂ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ। ਜ਼ਿਆਦਾਤਰ ਡੀਪਲੋਏਮੈਂਟ ਵਿੱਚ ਤੁਹਾਨੂੰ SIGINT ਲੋਕਲ ਵਿੱਚ ਅਤੇ SIGTERM ਤੁਹਾਡੇ ਪ੍ਰੋਸੈਸ ਮੈਨੇਜਰ ਜਾਂ ਕੰਟੇਨਰ ਰਨਟਾਈਮ ਤੋਂ ਮਿਲੇਗਾ। ਇੱਕ shutdown context ਬਣਾਓ ਜੋ ਸਿਗਨਲ ਆਉਂਦੇ ਹੀ cancel ਹੋ ਜਾਏ, ਅਤੇ ਇਸਨੂੰ ਆਪਣੇ ਪੂਲ ਅਤੇ ਜੌਬ ਹੈਂਡਲਰਾਂ ਵਿੱਚ ਪਾਸ ਕਰੋ।
ਫਿਰ, ਨਵੀਆਂ ਜੌਬਾਂ ਲੈਣਾ ਰੋਕੋ। ਕਿਸੇ ਚੈਨਲ 'ਤੇ ਸਬਮਿਸ਼ਨ ਕਰਨ ਵਾਲੇ ਕੰਲਰਾਂ ਨੂੰ ਦੱਸੋ ਤਾਂ ਜੋ ਉਹ ਅੰਤਹਿ-ਨਹੀਂ ਬਲੌਕ ਹੋਣ। ਸਬਮਿਸ਼ਨ ਨੂੰ ਇੱਕ ਆਪਣੇ ਫੰਕਸ਼ਨ ਦੇ ਪਿੱਛੇ ਰੱਖੋ ਜੋ shutdown flag ਜਾਂ shutdown context ਨੂੰ ਦੇਖ ਕੇ ਹੀ ਭੇਜੇ।
ਫਿਰ ਕਿਊ ਵਿੱਚ ਰਹਿ ਗਏ ਕੰਮ ਮਾਮਲਾ ਫੈਸਲਾ ਕਰੋ:
- Drain: ਪਹਿਲਾਂ ਹੀ queued ਹਨ ਉਹਨਾਂ ਨੂੰ ਖਤਮ ਕਰੋ, ਪਰ ਨਵੀਆਂ ਸਵੀਕਾਰ ਨਾ ਕਰੋ।
- Drop: ਜੋ ਨਹੀਂ ਸ਼ੁਰੂ ਹੋਏ ਉਹਨਾਂ ਨੂੰ ਰੱਦ ਕਰੋ।
ਡਰੇਨ ਪੇਮੈਂਟ ਅਤੇ ਇਮੇਲ ਵਰਗੇ ਸੁਰੱਖਿਅਤ ਕੰਮਾਂ ਲਈ ਸੁਰੱਖਿਅਤ ਹੈ। ਡਰੌਪ cache ਰੀਕੰਪਿਊਟ ਜਿਹੇ "ਨੀਸ ਟੂ ਹੈਵ" ਕੰਮਾਂ ਲਈ ਠੀਕ ਹੈ।
ਇੱਕ عملي shutdown ਕ੍ਰਮ:
- SIGINT/SIGTERM ਫੜੋ ਅਤੇ shared context cancel ਕਰੋ।
- ਸਬਮਿਸ਼ਨ ਰੋਕੋ (ਸਬਮਿਟ ਪਾਤ ਨੂੰ ਬੰਦ ਕਰੋ, ਜਰੂਰੀ ਨਹੀਂ ਕਿ ਕੰਮ ਚੈਨਲ ਖੋਲ੍ਹਿਆ ਹੋਵੇ)।
- ਵਰਕਰਾਂ ਨੂੰ context ਅਨੁਸਾਰ ਖਤਮ ਹੋਣ ਦਿਓ ਜਾਂ abort ਕਰੋ।
- WaitGroup ਨਾਲ ਵਰਕਰਾਂ ਲਈ ਉਡੀਕ ਕਰੋ।
- ਇੱਕ ਡੈਡਲਾਈਨ ਲਗਾਓ, ਫਿਰ ਸਿਸਟਮ ਬੰਦ ਕਰੋ।
ਡੈਡਲਾਈਨ ਅਹੰਕਾਰਿਕ ਹੈ। ਉਦਾਹਰਨ ਲਈ, ਇਨ-ਫਲਾਈਟ ਜੌਬਾਂ ਨੂੰ ਬੰਦ ਹੋਣ ਲਈ 10 ਸਕਿੰਟ ਦਿਓ। ਉਸ ਤੋਂ ਬਾਅਦ ਜੋ ਚੱਲ ਰਹੇ ਹਨ ਉਹਨੂੰ ਲੌਗ ਕਰੋ ਅਤੇ ਬਾਹਰ ਨਿਕਲੋ। ਇਸ ਨਾਲ ਡਿਪਲੋਏਮੈਂਟ ਪੂਰਵਾਨੁਮਾਨਯੋਗ ਬਣਦਾ ਹੈ ਅਤੇ ਟੰਗੇ ਪ੍ਰੋਸੈਸ ਤੋਂ ਬਚਾਅ ਹੁੰਦਾ ਹੈ।
ਵਰਕਰ ਪੂਲ ਲਈ ਲਾਗਿੰਗ ਅਤੇ ਸਧਾਰਨ ਮੈਟ੍ਰਿਕਸ
ਅਗਲੇ ਬਿਲਡ ਲਈ ਕ੍ਰੈਡਿਟ ਜਿੱਤੋ
ਛੋਟੀ ਲਿਖਤ ਪਬਲਿਸ਼ ਕਰੋ ਅਤੇ Koder.ai ਉੱਤੇ ਅਗਲੇ ਬਿਲਡ ਲਈ ਕ੍ਰੈਡਿਟ ਹਾਸਲ ਕਰੋ।
ਜਦੋਂ ਵਰਕਰ ਪੂਲ ਟੁੱਟਦਾ ਹੈ, ਉਹ ਅਕਸਰ ਉੱਚ-ਸ਼ੋਰ ਦੇ ਨਾਲ ਨਹੀਂ ਟੁੱਟਦਾ। ਜੌਬ ਹੌਲੀ ਹੋ ਜਾਂਦੇ ਹਨ, ਰੀਟ੍ਰਾਈ ਜਮ੍ਹ ਹੋ ਜਾਂਦੇ ਹਨ, ਅਤੇ ਕੋਈ ਸ਼ਕਾਏਗਾ ਕਿ "ਕੁਝ ਨਹੀਂ ਹੋ ਰਿਹਾ"। ਲਾਗਿੰਗ ਅਤੇ ਕੁਝ ਮੂਲ ਕਾਊਂਟਰ ਇਸਨੂੰ ਇੱਕ ਸਪੱਸ਼ਟ ਕਹਾਣੀ ਵਿੱਚ ਬਦਲ ਦਿੰਦੇ ਹਨ।
ਹਰ ਜੌਬ ਨੂੰ ਇੱਕ ਸਥਿਰ ID ਦਿਓ (ਜਾਂ submit ਸਮੇਂ ਜਨਰੇਟ ਕਰੋ) ਅਤੇ ਹਰ ਲਾਗ ਰੇਖਾ ਵਿੱਚ ਸ਼ਾਮِل ਕਰੋ। ਲਾਗਾਂ ਕੋਨਸਿਸਟੈਂਟ ਰੱਖੋ: ਇੱਕ ਲਾਈਨ ਜਦੋਂ ਜੌਬ ਸ਼ੁਰੂ ਹੋਵੇ, ਇੱਕ ਜਦੋਂ ਉਹ ਖਤਮ ਹੋਵੇ, ਅਤੇ ਇਕ ਜਦੋਂ ਉਹ ਫੇਲ ਹੋਵੇ। ਜੇ ਤੁਸੀਂ ਰੀਟ੍ਰਾਈ ਕਰਦੇ ਹੋ, ਤਾਂ ਅਟੈਂਪਟ ਨੰਬਰ ਅਤੇ ਅਗਲਾ ਡੀਲੇ ਲਾਗ ਕਰੋ।
ਸਧਾਰਨ ਲਾਗ ਸ਼ੇਪ:
- start: job_id, worker_id, attempt, kind
- finish: job_id, worker_id, attempt, duration_ms
- fail/retry: job_id, worker_id, attempt, err, next_delay_ms
ਮੈਟ੍ਰਿਕਸ ਘੱਟ ਰੱਖੋ ਪਰ ਫਾਇਦੇਮੰਦ ਰਹਿਣ: ਕਿਊ ਲੰਬਾਈ, ਇਨ-ਫਲਾਈਟ ਜੌਬ, ਕੁੱਲ ਸਫਲਤਾ ਅਤੇ ਫੇਲਿਅਰ, ਅਤੇ ਜੌਬ ਲੈਟੈਂਸੀ (ਘੱਟੋ-ਘੱਟ ਆਸਤਨ ਅਤੇ ਬਹੁਤ ਵੱਧ) ਟ੍ਰੈਕ ਕਰੋ। ਜੇ ਕਿਊ ਲੰਬਾਈ ਵਧਦੀ ਰਹਿੰਦੀ ਹੈ ਅਤੇ ਇਨ-ਫਲਾਈਟ pegged ਹੈ ਵਰਕਰ ਗਿਣਤੀ ਤੇ, ਤਾਂ ਤੁਸੀਂ ਸੈਚੁਰੇਟ ਹੋ। ਜੇ submitterਾਂ jobs ਚੈਨਲ ਵਿੱਚ ਭੇਜਣ ਵਿੱਚ ਬਲੌਕ ਹੋ ਰਹੇ ਹਨ, ਤਾਂ ਬੈਕਪ੍ਰੈਸ਼ਰ ਕਾਲਰ ਤੱਕ ਪਹੁੰਚ ਰਿਹਾ ਹੈ। ਇਹ ਹਰ ਵਾਰ ਖਰਾਬ ਨਹੀਂ, ਪਰ ਇਹ ਜਾਣ-ਪਛਾਣ ਵਾਲਾ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ।
ਜਦੋਂ "ਜੌਬ ਫਸੇ ਹੋਏ ਹਨ", ਤਾਂ ਦੇਖੋ ਕਿ ਪ੍ਰੋਸੈਸ ਅਜੇ ਵੀ ਜੌਬ ਪ੍ਰਾਪਤ ਕਰ ਰਿਹਾ ਹੈ ਜਾਂ ਨਹੀਂ, ਕਿਊ ਲੰਬਾਈ ਵੱਧ ਰਹੀ ਹੈ ਜਾਂ ਨਹੀਂ, ਵਰਕਰ ਜੀਵੰਤ ਹਨ ਜਾਂ ਨਹੀਂ, ਅਤੇ ਸਭ ਤੋਂ ਲੰਬੇ ਸਮੇਂ ਤੋਂ ਕੌਣ-ਕੌਣ ਜੌਬ ਚੱਲ ਰਹੇ ਹਨ। ਲੰਬੇ ਰਨਟਾਈਮ ਆਮ ਤੌਰ 'ਤੇ ਮਿਸਿੰਗ ਟਾਈਮਆਉਟ, ਹੌਲੀ Dependencies, ਜਾਂ ਇਕ ਐਸੀ ਰੀਟ੍ਰਾਈ ਲੂਪ ਵੱਲ ਇਸ਼ਾਰਾ ਕਰਦੇ ਹਨ ਜੋ ਕਦੇ ਰੁਕਦੀ ਨਹੀਂ।
ਇੱਕ ਹਕੀਕਤੀ ਉਦਾਹਰਨ: ਇੱਕ ਛੋਟਾ SaaS ਬੈਕਗ੍ਰਾਊਂਡ ਕਿਊ
ਮੰਨੋ ਇੱਕ ਛੋਟਾ SaaS ਹੈ ਜਿੱਥੇ ਇੱਕ ਆਰਡਰ PAID ਹੋ ਜਾਂਦਾ ਹੈ। ਭੁਗਤਾਨ ਹੋਣ ਤੋਂ ਬਾਅਦ ਤੁਹਾਨੂੰ ਇਨਵਾਇਸ PDF ਭੇਜਣੀ, ਗਾਹਕ ਨੂੰ ਈਮੇਲ ਕਰਨੀਆਂ, ਅਤੇ ਆਪਣੀ ਅੰਦਰੂਨੀ ਟੀਮ ਨੂੰ ਸੂਚਿਤ ਕਰਨਾ ਹੈ। ਤੁਸੀਂ ਨਹੀਂ ਚਾਹੁੰਦੇ ਕਿ ਇਹ ਕੰਮ ਵੈੱਬ ਰਿਕਵੇਸਟ ਨੂੰ ਰੋਕੇ। ਇਹ ਵਰਕਰ ਪੂਲ ਲਈ ਇੱਕ ਵਧੀਆ ਫਿਟ ਹੈ ਕਿਉਂਕਿ ਕੰਮ ਅਸਲੀ ਹੈ, ਪਰ ਸਿਸਟਮ ਅਜੇ ਵੀ ਛੋਟਾ ਹੈ।
ਜੌਬ ਪੇਲੋਡ ਨਿਊਨਤਮ ਹੋ ਸਕਦਾ ਹੈ: ਸਿਰਫ਼ ਇੰਨਾ ਕਿ ਤੁਸੀਂ ਬਾਕੀ DB ਤੋਂ ਲੋਡ ਕਰ ਸਕੋ। API ਹੈਂਡਲਰ order update ਦੇ ਨਾਲ ਹੀ jobs(status='queued', type='send_invoice', payload, attempts=0) ਵਰਗੀ ਇਕ ਸਤਿੱਥੀ ਲਿਖਦਾ ਹੈ, ਫਿਰ ਬੈਕਗ੍ਰਾਊਂਡ ਲੂਪ queued ਜੌਬਾਂ ਨੂੰ ਪੋਲ ਕਰਦਾ ਅਤੇ ਉਹਨਾਂ ਨੂੰ ਵਰਕਰ ਚੈਨਲ ਵਿੱਚ ਪਾਊਂਦਾ।
type SendInvoiceJob struct {
OrderID string
CustomerID string
Email string
}
ਜਦੋਂ ਇੱਕ ਵਰਕਰ ਇਹ ਉਠਾਂਦਾ ਹੈ, ਤਾਂ ਖੁਸ਼ੀ ਦਾ ਰਸਤਾ ਸਿੱਧਾ ਹੈ: order ਲੋਡ ਕਰੋ, ਇਨਵਾਇਸ ਬਣਾਓ, ਈਮੇਲ ਪ੍ਰੋਵਾਈਡਰ ਨੂੰ ਕਾਲ ਕਰੋ, ਫਿਰ ਜੌਬ ਨੂੰ done ਦੇ ਨਿਸ਼ਾਨ ਨਾਲ ਮਾਰਕ ਕਰੋ।
ਰੀਟ੍ਰਾਈਜ਼ ਹੀ ਅਸਲ ਮਸਲਾ ਬਣਦੇ ਹਨ। ਜੇ ਤੁਹਾਡਾ ਈਮੇਲ ਪ੍ਰੋਵਾਈਡਰ ਅਸਥਾਈ outage ਵਿੱਚ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਨਹੀਂ ਚਾਹੁੰਦੇ ਕਿ 1,000 ਜੌਬ ਸਦੀਵੀ ਤੌਰ 'ਤੇ ਫੇਲ ਹੋਣ ਜਾਂ ਹਰ ਸਕਿੰਟ provider ਨੂੰ ਹਮਲਾ ਕਰਨ। ਇੱਕ عملي ਤਰੀਕਾ ਇਹ ਹੈ:
- ਨੈਟਵਰਕ ਐਰਰ ਅਤੇ 5xx ਜਵਾਬਾਂ ਨੂੰ retryable ਸਮਝੋ।
- exponential backoff ਵਰਤੋ ਇੱਕ ਮੈਕਸ ਡੀਲੇ ਨਾਲ (ਉਦਾਹਰਨ ਲਈ, 5s, 15s, 45s, 2m)।
- ਅਟੈਂਪਟਾਂ ਨੂੰ ਕੈਪ ਕਰੋ (ਉਦਾਹਰਨ ਲਈ, 10) ਅਤੇ ਫਿਰ ਜੌਬ ਨੂੰ failed ਮਾਰਕ ਕਰੋ।
- ਆਖਰੀ ਐਰਰ ਰਿਕਾਰਡ ਕਰੋ ਤਾਂ ਕਿ ਸਪੋਰਟ ਵੇਖ ਸਕੇ ਕਿ ਕੀ ਹੋਇਆ।
ਆਉਟੇਜ ਦੌਰਾਨ, ਜੌਬ queued ਤੋਂ in_progress ਹੋਕੇ ਫਿਰ queued ਵਿੱਚ ਥੋੜ੍ਹੀ ਭਵਿੱਖੀ ਰਨ ਟਾਈਮ ਨਾਲ ਵਾਪਸ ਆ ਜਾਂਦੇ ਹਨ। ਜਦੋਂ ਪ੍ਰੋਵਾਈਡਰ ਮੁੜ ਚੱਲਣ ਲੱਗਦਾ ਹੈ ਤਾਂ ਵਰਕਰ ਸਾਹਝੇ ਤੌਰ 'ਤੇ ਬੈਕਲੌਗ ਨੂੰ ਡਰੇਨ ਕਰ ਲੈਂਦੇ ਹਨ।
ਹੁਣ ਇੱਕ ਡਿਪਲੋਇਮੈਂਟ ਦੀ ਤਸਵੀਰ ਕਰੋ। ਤੁਸੀਂ SIGTERM ਭੇਜਦੇ ਹੋ। ਪ੍ਰੋਸੈਸ ਨੂੰ ਨਵਾਂ ਕੰਮ ਲੈਣਾ ਰੋਕਣਾ ਚਾਹੀਦਾ ਹੈ ਪਰ ਜੋ ਪਹਿਲਾਂ ਚੱਲ ਰਹੇ ਹਨ ਉਹਨਾਂ ਨੂੰ ਖਤਮ ਕਰਨ ਦੇ ਯੋਗ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ। ਪੋਲਿੰਗ ਰੋਕੋ, ਵਰਕਰ ਚੈਨਲ ਨੂੰ ਫੀਡ ਕਰਨਾ ਰੋਕੋ, ਅਤੇ ਵਰਕਰਾਂ ਲਈ ਇੱਕ ਡੈਡਲਾਈਨ ਨਾਲ ਉਡੀਕ ਕਰੋ। ਜੋ ਜੌਬ ਖਤਮ ਹੋ ਜਾਂਦੇ ਹਨ ਉਹ done ਮਾਰਕ ਹੋ ਜਾਣ। ਜੌਬ ਜੋ ਡੈਡਲਾਈਨ ਤੇ ਹਨ ਉਹਨਾਂ ਨੂੰ queued ਵਾਪਸ ਮਾਰਕ ਕੀਤਾ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ (ਜਾਂ progress 'ਤੇ ਇੱਕ ਵਾਚਡੌਗ ਛੱਡੋ) ਤਾਂ ਜੋ ਨਵੇਂ ਵਰਜਨ ਵਰਕਰ ਦੁਆਰਾ ਪਿਕ ਅਪ ਕੀਤੇ ਜਾ ਸਕਣ।
ਆਮ ਗਲਤੀਆਂ ਅਤੇ ਜਾਲ
ਬੈਕਗ੍ਰਾਊਂਡ ਪ੍ਰੋਸੈਸਿੰਗ ਵਿੱਚ ਜ਼ਿਆਦਾਤਰ ਬੱਗ ਜੌਬ ਲਾਜਿਕ ਵਿੱਚ ਨਹੀਂ ਹੁੰਦੇ। ਉਹ ਸਹਿ-ਸੰਯੋਜਨ ਗਲਤੀਆਂ ਤੋਂ ਹੁੰਦੇ ਹਨ ਜੋ ਸਿਰਫ਼ ਲੋਡ ਦੌਰਾਨ ਜਾਂ ਸ਼ਟਡਾਊਨ ਦੌਰਾਨ ਹੀ ਦਰਸਾਉਂਦੀਆਂ ਹਨ।
ਇੱਕ ਕਲਾਸਿਕ ਫੈਲਤੂ ਗਲਤੀ ਚੈਨਲ ਨੂੰ ਇੱਕ ਤੋਂ ਵੱਧ ਜਗ੍ਹਾ ਤੋਂ close ਕਰਨਾ ਹੈ। ਨਤੀਜਾ ਇੱਕ panic ਹੁੰਦੀ ਹੈ ਜੋ ਦੁਬਾਰਾ ਬਣਾਉਣਾ ਮੁਸ਼ਕਿਲ ਹੈ। ਹਰ ਚੈਨਲ ਦਾ ਇੱਕ ਮਾਲਕ ਚੁਣੋ (ਆਮ ਤੌਰ 'ਤੇ producer), ਅਤੇ ਓਹੁ ਹੀ ਜਗ੍ਹਾ ਹੋਵੇ ਜੋ close(jobs) ਕਾਲ ਕਰੇ।
ਰੀਟ੍ਰਾਈਜ਼ ਇੱਕ ਹੋਰ ਖੇਤਰ ਹਨ ਜਿੱਥੇ ਚੰਗੇ ਇਰਾਦੇ ਖ਼ਰਾਬੀ ਦਾ ਕਾਰਨ ਬਣ ਜਾਂਦੇ ਹਨ। ਜੇ ਤੁਸੀਂ ਸਭ ਕੁਝ ਰੀਟ੍ਰਾਈ ਕਰੋਗੇ ਤਾਂ ਤੁਸੀਂ ਕਾਇਮੀ ਫੇਲਿਅਰ ਵੀ ਦੁਬਾਰਾ ਕਰਨਗੇ। ਇਹ ਸਮਾਂ ਬਰਬਾਦ ਕਰਦਾ, ਲੋਡ ਵਧਾਂਦਾ, ਅਤੇ ਇੱਕ ਛੋਟਾ ਮੁੱਦਾ ਘਟਨਾ ਵਿੱਚ ਬਦਲ ਸਕਦਾ ਹੈ। ਐਰਰਾਂ ਨੂੰ ਵਰਗ-ਵਾਰ ਕਰਕੇ ਰੀਟ੍ਰਾਈਜ਼ ਨੂੰ ਸੀਮਤ ਰੱਖੋ।
ਡੁਪਲਿਕੇਟਸ ਹੋਣਗੇ ਭੀ — ਭਲਕੇ ਤੁਸੀਂ ਧਿਆਨ ਨਾਲ ਡਿਜ਼ਾਈਨ ਕਰੋ। ਵਰਕਰ ਮਿਡ-ਜੌਬ ਕਰੈਸ਼ ਹੋ ਸਕਦਾ ਹੈ, ਇੱਕ ਟਾਈਮਆਉਟ ਕੰਮ ਖਤਮ ਹੋਣ ਤੋਂ ਬਾਅਦ ਫਾਇਰ ਹੋ ਸਕਦਾ ਹੈ, ਜਾਂ ਤੁਸੀਂ deployment ਦੌਰਾਨ ਦੁਬਾਰਾ ਕਿਊ ਕਰ ਸਕਦੇ ਹੋ। ਜੇ ਜੌਬ idempotent ਨਹੀਂ ਹੈ ਤਾਂ ਡੁਪਲਿਕੇਟ ਸੱਚਮੁੱਚ ਨੁਕਸਾਨ ਪਹੁੰਚਾ ਸਕਦੇ ਹਨ: ਦੋ ਇਨਵਾਇਸ, ਦੋ ਵੈਲਕਮ ਈਮੇਲ, ਦੋ ਰੀਫੰਡ।
ਸਭ ਤੋਂ ਆਮ ਗਲਤੀਆਂ:
- ਇੱਕੋ ਚੈਨਲ ਨੂੰ ਕਈ goroutine ਤੋਂ close ਕਰਨਾ।
- ਕਾਇਮੀ ਫੇਲਿਅਰ ਨੂੰ ਰੀਟ੍ਰਾਈ ਕਰਨਾ ਬਜਾਏ ਉਨ੍ਹਾਂ ਨੂੰ surfaced ਕਰਨਾ।
- ਕੋਈ idempotency key ਨਾ ਹੋਣਾ, ਜਿਸ ਨਾਲ duplicates ਦੁਪਹੂੰਚ ਹੁੰਦੇ ਹਨ।
- ਅਨਬਾਊਂਡਡ ਇਨ-ਮੈਮੋਰੀ ਕਿਊਜ਼ ਜੋ ਮੈਮੋਰੀ ਵਧਣ ਤਕ ਵਧਦੇ ਰਹਿੰਦੇ ਹਨ।
context.Contextਨੂੰ ਨਜ਼ਰਅੰਦਾਜ਼ ਕਰਨਾ, ਇਸ ਕਾਰਨ shutdown ਸ਼ੁਰੂ ਹੋਣ ਮਗਰੋਂ ਕੰਮ ਜਾਰੀ ਰਹਿ ਜਾਣਾ।
ਅਨਬਾਊਂਡਡ ਕਿਊਜ਼ ਖ਼ਾਸ ਤੌਰ 'ਤੇ ਚਾਲਾਕ ਹਨ। ਕੰਮ ਦਾ ਇੱਕ spike RAM ਵਿੱਚ ਚੁਪਕੇ-ਚੁਪਕੇ ਜ਼ਮੀ ਹੋ ਸਕਦਾ ਹੈ। ਇੱਕ ਸੀਮਤ ਚੈਨਲ buffer ਪਸੰਦ ਕਰੋ ਅਤੇ ਫੈਸਲਾ ਕਰੋ ਕਿ ਭਰ ਜਾਣ 'ਤੇ ਕੀ ਹੋਵੇ: ਬਲੌਕ, ਡਰੌਪ, ਜਾਂ ਐਰਰ ਵਾਪਸ ਕਰੋ।
ਸ਼ਿਪਿੰਗ ਤੋਂ ਪਹਿਲਾਂ ਛੇਤੀ ਚੈੱਕਲਿਸਟ
ਆਪਣਾ ਬੈਕਗ੍ਰਾਊਂਡ ਵਰਕਰ ਡਿਪਲੌਏ ਕਰੋ
ਜਦੋਂ ਤੁਸੀਂ ਚਲਾਉਣ ਲਈ ਤਿਆਰ ਹੋਵੋਗੇ ਤਾਂ ਹੋਸਟਿੰਗ ਸਹਾਇਤਾ ਨਾਲ ਆਪਣੀ Go ਐਪ ਡਿਪਲੌਏ ਕਰੋ।
ਪ੍ਰੋਡਕਸ਼ਨ ਵਿੱਚ ਵਰਕਰ ਪੂਲ ਸ਼ਿਪ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ, ਤੁਸੀਂ ਜੌਬ ਲਾਈਫਸਾਈਕਲ ਉੱਲੇਖ ਸਾਫ਼ ਤਰੀਕੇ ਨਾਲ ਬਿਆਨ ਕਰ ਸਕਣਾ ਚਾਹੀਦਾ ਹੈ। ਜੇ ਕੋਈ ਪੁੱਛੇ "ਇਹ ਜੌਬ ਹੁਣ ਕਿੱਥੇ ਹੈ?", ਤਾਂ ਜਵਾਬ ਅਨੁਮਾਨ ਤੇ ਨਹੀਂ ਹੋਣਾ ਚਾਹੀਦਾ।
ਇੱਕ عملي ਪ੍ਰੀ-ਫਲਾਈਟ ਚੈੱਕਲਿਸਟ:
- ਤੁਸੀਂ ਹਰ ਸਟੇਟ ਅਤੇ ਟ੍ਰਾਂਜ਼ੀਸ਼ਨ ਦਾ ਨਾਮ ਲੈ ਸਕੋ: queued, picked up, running, finished, failed (ਅਤੇ ਕੀ ਕਾਰਨ ਬਣਦਾ ਹੈ) ।
- concurrency ਇੱਕ ਸਧਾਰਨ ਨਾਬ (ਜਿਵੇਂ
workerCount) ਹੈ, ਅਤੇ ਇਸਨੂੰ ਬਦਲਣ ਨਾਲ ਕੋਡ ਨਹੀਂ ਦੁਬਾਰਾ ਲਿਖਣਾ ਪੈਂਦਾ। - ਰੀਟ੍ਰਾਈਜ਼ ਸੀਮਤ ਹਨ: max attempts ਸਪਸ਼ਟ, ਬੈਕਓਫ਼ ਵਧਦਾ, ਅਤੇ ਕਾਇਮੀ ਫੇਲਿਅਰ ਕਿਸੇ ਇਰਾਦੇਸ਼ੀਲ ਥਾਂ ਤੇ ਚਲਾ ਜਾਂਦਾ ਹੈ।
- ਸ਼ਟਡਾਊਨ ਵਰਤਾਵ ਪ੍ਰਮਾਣਿਤ ਹੋਇਆ: ਤੁਸੀਂ intake ਰੋਕਦੇ ਹੋ, ਇਨ-ਫਲਾਈਟ ਜੌਬਾਂ ਨੂੰ ਖਤਮ ਹੋਣ ਦਿੰਦੇ ਹੋ, ਅਤੇ ਇੱਕ ਸਖਤ timeout ਹੈ।
- ਲੋਗ ਬੁਨਿਆਦੀ ਸਵਾਲਾਂ ਦਾ ਜਵਾਬ ਦਿੰਦੇ ਹਨ: job ID, attempt ਨੰਬਰ, ਮਿਆਦ, ਅਤੇ ਐਰਰ ਦਾ ਕਾਰਨ।
ਰਿਲੀਜ਼ ਤੋਂ ਪਹਿਲਾਂ ਇੱਕ ਹਕੀਕਤੀ ਡ੍ਰਿੱਲ ਕਰੋ: 100 "send receipt email" ਜੌਬ enqueue ਕਰੋ, 20 ਨੂੰ ਜ਼ਬਰਦਸਤ ਤੌਰ 'ਤੇ fail ਕਰਵਾਓ, ਫਿਰ ਸੇਵਾ ਨੂੰ ਦੌਰਾਨ restart ਕਰੋ। ਤੁਸੀਂ ਰੀਟ੍ਰਾਈਜ਼ ਆਸ-ਚਾਹੀਦੇ ਤਰੀਕੇ ਨਾਲ ਵਿਵਹਾਰ ਕਰਦੇ ਦੇਖਣੇ ਚਾਹੀਦੇ ਹੋ, ਕੋਈ duplicate side effects ਨਹੀਂ ਹੋਣੇ, ਅਤੇ ਜ਼ਬਾਨੀ ਤੌਰ 'ਤੇ cancellation ਵਾਕਈ shutdown ਡੈਡਲਾਈਨ 'ਤੇ ਕੰਮ ਰੋਕੇ।
ਜੇ ਕੋਈ ਚੀਜ਼ ਢਿੱਲੀ ਹੋਵੇ, ਤਾਂ ਹੁਣ ਹੀ ਠੀਕ ਕਰੋ। ਛੋਟੀ-ਛੋਟੀ ਸਹੀਗਈਆਂ ਬਾਅਦ ਵਿੱਚ ਦਿਨ ਬਚਾਉਂਦੀਆਂ ਹਨ।
ਅਗਲੇ ਕਦਮ: ਕਦੋਂ ਵੱਧ ਭਾਰੀ ਇੰਫ੍ਰਾਸਟਰੱਕਚਰ ਜੋੜਨਾ (ਅਤੇ ਕਦੋਂ ਨਹੀਂ)
ਇੱਕ ਸਧਾਰਨ in-process ਪੂਲ ਅਕਸਰ ਉਤਨਾ ਹੀ ਕਾਫੀ ਹੁੰਦਾ ਹੈ ਜਦ ਉਤਪਾਦ ਨੌਜਵਾਨ ਹੋ। ਜੇ ਤੁਹਾਡੇ ਜੌਬ "ਨੀਸ-ਟੂ-ਹੈਵ" ਹਨ (ਈਮੇਲ ਭੇਜਣਾ, cache ਰਿਫ੍ਰੈਸ਼, ਰਿਪੋਰਟ ਬਣਾਉਣਾ) ਅਤੇ ਤੁਸੀਂ ਇਹ ਮੁੜ ਚਲਾ ਸਕਦੇ ਹੋ, ਤਾਂ ਵਰਕਰ ਪੂਲ ਸਿਸਟਮ ਨੂੰ ਸਮਝਣ ਯੋਗ ਰੱਖਦਾ ਹੈ।
ਸੰਕੇਤ ਕਿ ਤੁਸੀਂ in-process ਪੂਲ ਨੂੰ ਪਾਰ ਕਰ ਚੁੱਕੇ ਹੋ
ਇਹ ਦਬਾਅ ਨੁਮਾਇੰਦਿਆਂ ਨੂੰ ਦੇਖੋ:
- ਤੁਸੀਂ ਕਈ ਐਪ ਇੰਸਟੈਂਸ ਚਲਾ ਰਹੇ ਹੋ ਅਤੇ ਚਾਹੁੰਦੇ ਹੋ ਕਿ ਉਨ੍ਹਾਂ ਵਿੱਚੋਂ ਸਿਰਫ਼ ਇੱਕ ਕੋਈ ਜੌਬ ਚੁਣੇ।
- ਤੁਹਾਨੂੰ durability ਚਾਹੀਦੀ ਹੈ (ਜੌਬਾਂ ਨੂੰ ਕਰੈਸ਼ ਅਤੇ ਡਿਪਲੋਏਮੈਂਟ ਤੋਂ ਬਚਣਾ)।
- ਤੁਹਾਨੂੰ audit trail ਚਾਹੀਦਾ ਹੈ: ਕਿਸ ਨੇ ਕੀ ਕੰਮ ਕਦੋਂ ਕਿਉਂ ਕੀਤਾ, ਅਤੇ ਨਤੀਜਾ।
- ਤੁਹਾਨੂੰ ਸਰਵਿਸز ਦੇ ਅੰਦਰ ਹੀ ਨਹੀਂ, ਸਗੋਂ ਸਰਵਿਸਜ਼-ਪਾਰ ਬੈਕਪ੍ਰੈਸ਼ਰ ਕੰਟਰੋਲ ਦੀ ਲੋੜ ਹੈ।
- ਤੁਹਾਨੂੰ ਸਖਤ ਸ਼ਡਿਊਲਿੰਗ ਜਾਂ ਲੰਬੇ ਡੀਲੇ (ਘੰਟਿਆਂ ਜਾਂ ਦਿਨਾਂ) ਚਾਹੀਦੇ ਹਨ ਉਤੇ ਭਰੋਸੇਯੋਗ ਵੈਕ-ਅਪ।
ਜੇ ਇਹਨਾਂ ਵਿੱਚੋਂ ਕੋਈ ਨਹੀਂ, ਤਾਂ ਭਾਰੀ ਟੂਲਜ਼ ਹੁੰਦੇ-ਹੁੰਦੇ ਵੀ ਉਹਨਾਂ ਦੀਆਂ ਜ਼ਰੂਰਤਾਂ ਮੁਕਾਬਲੇ ਜ਼ਿਆਦਾ ਮੁਸ਼ਕਲੀਆਂ ਜੋੜ ਸਕਦੇ ਹਨ।
ਧੀਰੇ-ਧੀਰੇ ਮਾਈਗਰੇਟ ਕਰੋ ਬਿਨਾਂ ਰੀਰਾਈਟ ਦੇ
ਸਭ ਤੋਂ ਚੰਗੀ ਹੇਜ ਇੱਕ ਸਥਿਰ ਜੌਬ ਇੰਟਰਫੇਸ ਹੈ: ਇੱਕ ਛੋਟਾ payload type, ਇੱਕ ID, ਅਤੇ ਇੱਕ ਹੈਂਡਲਰ ਜੋ ਸਪਸ਼ਟ ਨਤੀਜਾ ਵਾਪਸ ਕਰਦਾ ਹੈ। ਫਿਰ ਤੁਸੀਂ ਬਾਅਦ ਵਿੱਚ queue ਬੈਕਐਂਡ ਬਦਲ ਸਕਦੇ ਹੋ (ਇਨ-ਮੇਮੋਰੀ ਚੈਨਲ ਤੋਂ ਡੇਟਾਬੇਸ ਟੇਬਲ, ਅਤੇ ਫਿਰ ਇੱਕ ਸਮਰਪਿਤ ਕਿਊ) ਬਿਨਾਂ ਬਿਜਨੈਸ ਕੋਡ ਬਦਲਣ ਦੇ।
ਇੱਕ عملي ਮੱਧੀ ਕਦਮ ਇੱਕ ਛੋਟੀ Go ਸਰਵਿਸ ਹੈ ਜੋ PostgreSQL ਤੋਂ ਜੌਬ ਪੜ੍ਹਦੀ ਹੈ, ਉਨ੍ਹਾਂ ਨੂੰ ਲਾਕ ਕਰਦੀ ਹੈ, ਅਤੇ ਸਟੇਟ ਅਪਡੇਟ ਕਰਦੀ ਹੈ। ਤੁਹਾਨੂੰ durability ਅਤੇ ਬੁਨਿਆਦੀ auditability ਮਿਲਦੀ ਹੈ, ਨਾਲ ਹੀ ਉਹੀ ਵਰਕਰ ਲਾਜਿਕ ਰੱਖਦੇ ਹੋ।
ਜੇ ਤੁਸੀਂ ਤੇਜ਼ੀ ਨਾਲ ਪ੍ਰੋਟੋਟਾਈਪ ਕਰਨਾ ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ Koder.ai (koder.ai) ਇੱਕ chat prompt ਤੋਂ Go + PostgreSQL starter ਜਨਰੇਟ ਕਰ ਸਕਦਾ ਹੈ, ਜਿਸ ਵਿੱਚ ਬੈਕਗ੍ਰਾਊਂਡ ਜੌਬਜ਼ ਟੇਬਲ ਅਤੇ ਵਰਕਰ ਲੂਪ ਸ਼ਾਮਿਲ ਹੋ ਸਕਦਾ ਹੈ, ਅਤੇ ਇਸਦੀ snapshots ਅਤੇ rollback ਤੁਹਾਡੀ ਮਦਦ ਕਰ ਸਕਦੇ ਹਨ ਜਦੋਂ ਤੁਸੀਂ ਰੀਟ੍ਰਾਈਜ਼ ਅਤੇ ਸ਼ਟਡਾਊਨ ਵਿਹਾਰ ਨੂੰ ਟੀਊਨ ਕਰੋ।