16 ਜਨ 2026·8 ਮਿੰਟ
ਦਸਤਾਵੇਜ਼-ਕੇਂਦਰਤ ਵਰਕਫਲੋਜ਼: ਡੇਟਾ ਮਾਡਲ ਅਤੇ UI ਪੈਟਰਨ
ਦਸਤਾਵੇਜ਼-ਕੇਂਦਰਤ ਵਰਕਫਲੋਜ਼ ਨੂੰ ਵਰਜ਼ਨ, ਪ੍ਰੀਵਿਊਜ਼, ਮੈਟਾਡੇਟਾ ਅਤੇ ਸਪਸ਼ਟ ਸਟੇਟਸ ਨਾਲ ਵਿਵਹਾਰਕ ਡੇਟਾ ਮਾਡਲ ਅਤੇ UI ਪੈਟਰਨਾਂ ਦੇ ਨਾਲ ਸਮਝਾਇਆ ਗਿਆ।
ਦਸਤਾਵੇਜ਼-ਕੇਂਦਰਤ ਵਰਕਫਲੋਜ਼ ਨੂੰ ਵਰਜ਼ਨ, ਪ੍ਰੀਵਿਊਜ਼, ਮੈਟਾਡੇਟਾ ਅਤੇ ਸਪਸ਼ਟ ਸਟੇਟਸ ਨਾਲ ਵਿਵਹਾਰਕ ਡੇਟਾ ਮਾਡਲ ਅਤੇ UI ਪੈਟਰਨਾਂ ਦੇ ਨਾਲ ਸਮਝਾਇਆ ਗਿਆ।
ਐਪ document-centric ਹੁੰਦੀ ਹੈ ਜਦੋਂ ਦਸਤਾਵੇਜ਼ ਹੀ ਉਹ ਪ੍ਰੋਡਕਟ ਹੁੰਦਾ ਹੈ ਜੋ ਉਪਭੋਗਤਾ ਬਣਾਉਂਦੇ, ਸਮੀਖਿਆ ਕਰਦੇ ਅਤੇ ਉਸ 'ਤੇ ਨਿਰਭਰ ਕਰਦੇ ਹਨ। ਤਜ਼ਰਬਾ ਫਾਈਲਾਂ (PDF, ਇਮੇਜ, ਸਕੈਨ, ਰਸੀਦਾਂ) ਦੇ ਆਲੇ-ਦੁਆਲੇ ਬਣਾਇਆ ਜਾਂਦਾ ਹੈ, ਨਾ ਕਿ ਕਿਸੇ ਫਾਰਮ ਦੇ ਆਲੇ-ਦੁਆਲੇ ਜਿੱਥੇ ਫਾਈਲ ਸਿਰਫ਼ ਇੱਕ ਅਟੈਚਮੈਂਟ ਹੈ।
Document-centric ਵਰਕਫਲੋ ਵਿਚ ਲੋਕ ਦਸਤਾਵੇਜ਼ ਦੇ ਅੰਦਰ ਅਸਲੀ ਕੰਮ ਕਰਦੇ ਹਨ: ਉਹ ਇਸਨੂੰ ਖੋਲ੍ਹਦੇ ਹਨ, ਵੇਖਦੇ ਹਨ ਕਿ ਕੀ ਬਦਲਿਆ, ਸੰਦਰਭ ਜੋੜਦੇ ਹਨ, ਅਤੇ ਅਗਲਾ ਕਦਮ ਨਿਰਧਾਰਤ ਕਰਦੇ ਹਨ। ਜੇ ਦਸਤਾਵੇਜ਼ 'ਤੇ ਭਰੋਸਾ ਨਹੀਂ ਕੀਤਾ ਜਾ ਸਕਦਾ, ਤਾਂ ਐਪ ਬੇਕਾਰ ਹੋ ਜਾਂਦਾ ਹੈ।
ਜ਼ਿਆਦਾਤਰ document-centric ਐਪਾਂ ਨੂੰ ਸ਼ੁਰੂਆਤ ਵਿੱਚ ਕੁਝ ਮੁੱਖ ਸਕ੍ਰੀਨਾਂ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ:
ਸਮੱਸਿਆਆਂ ਜ਼ਰੂਰ ਜਲਦੀ ਆਉਂਦੀਆਂ ਹਨ। ਯੂਜ਼ਰ ਇੱਕੋ ਰਸੀਦ ਦੋ ਵਾਰੀ ਅਪਲੋਡ ਕਰ ਦਿੰਦੇ ਹਨ। ਕੋਈ PDF ਸੋਧ ਕੇ ਵਾਪਸ ਅਪਲੋਡ ਕਰ ਦਿੰਦਾ ਹੈ ਬਿਨਾਂ ਵਜਹ ਦੱਸੇ। ਇੱਕ ਸਕੈਨ 'ਤੇ ਕੋਈ ਮਿਤੀ, ਵਿਕਰੇਤਾ ਜਾਂ ਮਾਲਕ ਨਹੀਂ ਹੁੰਦਾ। ਹਫ਼ਤਿਆਂ ਬਾਅਦ, ਕਿਸੇ ਨੂੰ ਪਤਾ ਨਹੀਂ ਹੁੰਦਾ ਕਿ ਕਿਹੜਾ ਵਰਜ਼ਨ ਮਨਜ਼ੂਰ ਕੀਤਾ ਗਿਆ ਸੀ ਜਾਂ ਫੈਸਲਾ ਕਿਸ ਆਧਾਰ ਤੇ ਲਿਆ ਗਿਆ।
ਅੱਛਾ document-centric ਐਪ ਤੇਜ਼ ਅਤੇ ਭਰੋਸੇਯੋਗ ਮਹਿਸੂਸ ਹੁੰਦਾ ਹੈ। ਯੂਜ਼ਰਾਂ ਨੂੰ ਸੈਕਿੰਡਾਂ ਵਿੱਚ ਇਹ ਸਵਾਲ ਜਵਾਬ ਕਰਨ ਯੋਗ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ:
ਇਹ ਸਪਸ਼ਟਤਾ ਪਰਿਭਾਸ਼ਾਵਾਂ ਤੋਂ ਆਉਂਦੀ ਹੈ। ਸਕ੍ਰੀਨਾਂ ਬਣਾਉਣ ਤੋਂ ਪਹਿਲਾਂ, ਨਿਰਧਾਰਤ ਕਰੋ ਕਿ ਤੁਹਾਡੇ ਐਪ ਵਿੱਚ “version,” “preview,” “metadata,” ਅਤੇ “status” ਦਾ ਕੀ ਮਤਲਬ ਹੈ। ਜੇ ਇਹ ਸ਼ਬਦ ਧੁੰਦਲੇ ਹਨ, ਤਾਂ ਤੁਸੀਂ ਡੁਪਲੀਕੇਟ, ਗੁੰਝਲਦਾਰ ਇਤਿਹਾਸ ਅਤੇ ਅਜਿਹੇ ਰਿਵਿਊ ਫਲੋ ਮਿਲਾਉਂਗੇ ਜੋ ਅਸਲੀ ਕੰਮ ਨਾਲ ਮੇਲ ਨਹੀਂ ਖਾਂਦੇ।
UI ਆਮ ਤੌਰ 'ਤੇ ਸਧਾਰਣ ਲੱਗਦਾ ਹੈ (ਇੱਕ ਲਿਸਟ, ਇੱਕ ਵਿਊਅਰ, ਕੁਝ ਬਟਨ), ਪਰ ਡੇਟਾ ਮਾਡਲ ਭਾਰ ਸਹਨ ਕਰਦਾ ਹੈ। ਜੇ ਮੁੱਖ ਆਬਜੈਕਟ ਸਹੀ ਹੋਣ, ਤਾਂ ਆਡਿਟ ਇਤਿਹਾਸ, ਤੇਜ਼ ਪ੍ਰੀਵਿਊ ਅਤੇ ਭਰੋਸੇਯੋਗ ਮਨਜ਼ੂਰੀਆਂ ਕਾਫੀ ਆਸਾਨ ਹੋ ਜਾਦੀਆਂ ਹਨ।
Document record ਨੂੰ file content ਤੋਂ ਵੱਖਰਾ ਰੱਖਣਾ ਸ਼ੁਰੂ ਕਰੋ। ਰਿਕਾਰਡ ਉਹ ਹੈ ਜਿਸ ਬਾਰੇ ਉਪਭੋਗਤਾ ਗੱਲ ਕਰਦੇ ਹਨ (ACME ਤੋਂ ਇਨਵੌਇਸ, ਟੈਕਸੀ ਰਸੀਦ). ਕੰਟੈਂਟ ਉਹ ਬਾਈਟਸ ਹਨ (PDF, JPG) ਜੋ ਬਦਲੇ ਜਾ ਸਕਦੇ ਹਨ, ਦੁਬਾਰਾ ਪ੍ਰੋਸੈਸ ਹੋ ਸਕਦੇ ਹਨ ਜਾਂ ਸਥਾਨਾਂਤਰਿਤ ਹੋ ਸਕਦੇ ਹਨ ਬਿਨਾਂ ਐਪ ਅੰਦਰ ਦਸਤਾਵੇਜ਼ ਦੇ ਅਰਥ ਨੂੰ ਬਦਲੇ।
ਇੱਕ ਵਰਤੋਂਯੋਗ ਆਬਜੈਕਟ ਸੈੱਟ ਜੋ ਮਾਡਲ ਕਰੋ:
ਨਿਰਧਾਰਤ ਕਰੋ ਕਿ ਕਿਸੇ ਚੀਜ਼ ਨੂੰ ਐਸਾ ID ਮਿਲਦਾ ਹੈ ਜੋ ਕਦੇ ਨਹੀਂ ਬਦਲੇਗਾ। ਇੱਕ ਉਪਯੋਗੀ ਨਿਯਮ ਇਹ ਹੈ: Document ID ਸਦਾ ਲਈ ਰਹਿੰਦਾ ਹੈ, ਜਦਕਿ Files ਅਤੇ Previews ਨੂੰ ਦੁਬਾਰਾ ਬਣਾਇਆ ਜਾ ਸਕਦਾ ਹੈ। Versions ਨੂੰ ਵੀ stable IDs ਦੀ ਲੋੜ ਹੈ, ਕਿਉਂਕਿ ਲੋਕ “ਕੱਲ੍ਹ ਇਹ ਇਉਂ ਸੀ” ਦਾ ਹਵਾਲਾ ਦੇਂਦੇ ਹਨ ਅਤੇ ਤੁਹਾਨੂੰ ਆਡਿਟ ਟ੍ਰੇਲ ਦੇਣੀ ਹੋਵੇਗੀ।
ਰਿਸ਼ਤੇ ਸਪਸ਼ਟ ਮਾਡਲ ਕਰੋ। ਇੱਕ Document ਦੇ ਕੋਲ ਬਹੁਤ ਸਾਰੀਆਂ Versions ਹੋ ਸਕਦੀਆਂ ਹਨ। ਹਰ Version ਕੋਲ ਵੱਖ-ਵੱਖ Previews (ਵੱਖ-ਵੱਖ ਆਕਾਰ ਜਾਂ ਫਾਰਮੈਟ) ਹੋ ਸਕਦੇ ਹਨ। ਇਸ ਨਾਲ ਲਿਸਟ ਸਕ੍ਰੀਨਾਂ ਤੇਜ਼ ਰਹਿਣਗੀਆਂ ਕਿਉਂਕਿ ਉਹ ਲਾਈਟਵੇਟ preview ਡੇਟਾ ਲੋਡ ਕਰ ਸਕਦੀਆਂ ਹਨ, ਜਦਕਿ ਡੀਟੇਲ ਸਕ੍ਰੀਨ ਜ਼ਰੂਰਤ ਪੈਣ 'ਤੇ ਪੂਰੀ ਫਾਈਲ ਲੋਡ ਕਰ ਸਕਦੀਆਂ ਹਨ।
ਉਦਾਹਰਨ: ਇੱਕ ਯੂਜ਼ਰ ਇੱਕ ਕ੍ਰਂਪਲਡ ਰਸੀਦ ਫੋਟੋ ਅਪਲੋਡ ਕਰਦਾ ਹੈ। ਤੁਸੀਂ ਇਕ Document ਬਣਾਉਂਦੇ ਹੋ, ਮੂਲ File ਸਟੋਰ ਕਰਦੇ ਹੋ, ਇੱਕ thumbnail Preview ਜਨਰੇਟ ਕਰਦੇ ਹੋ, ਅਤੇ Version 1 ਬਣਾਉਂਦੇ ਹੋ। ਬਾਅਦ ਵਿੱਚ ਯੂਜ਼ਰ ਇੱਕ ਸਾਫ਼ ਸਕੈਨ ਅਪਲੋਡ ਕਰਦਾ ਹੈ। ਉਹ Version 2 ਬਣ ਜਾਂਦੀ ਹੈ, ਟਿੱਪਣੀਆਂ, ਮਨਜ਼ੂਰੀਆਂ ਜਾਂ ਡਾਕੂਮੈਂਟ ਨਾਲ ਜੁੜੇ ਖੋਜ ਨੂੰ ਤੋੜੇ ਬਿਨਾਂ।
ਲੋਕ ਉਮੀਦ ਕਰਦੇ ਹਨ ਕਿ ਦਸਤਾਵੇਜ਼ ਸਮੇਂ ਦੇ ਨਾਲ ਬਦਲੇਗਾ ਬਿਨਾਂ "ਕਿਸੇ ਹੋਰ ਆਈਟਮ" ਵਿੱਚ ਤਬਦੀਲ ਹੋਏ। ਸਭ ਤੋਂ ਸਧਾਰਣ ਤਰੀਕ ਇਹ ਹੈ ਕਿ ਪਛਾਣ (Document) ਨੂੰ ਸਮਗ੍ਰੀ (Version ਅਤੇ Files) ਤੋਂ ਵੱਖਰਾ ਰੱਖਿਆ ਜਾਵੇ।
ਇੱਕ ਸਥਿਰ document_id ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਜੋ ਕਦੇ ਨਹੀਂ ਬਦਲੇ। ਚਾਹੇ ਯੂਜ਼ਰ ਇੱਕੋ PDF ਨੂੰ ਦੁਬਾਰਾ ਅਪਲੋਡ ਕਰੇ, ਧੁੰਦਲਾ ਫੋਟੋ ਬਦਲੇ ਜਾਂ ਸਹੀ ਕੀਤਾ ਸਕੈਨ ਅਪਲੋਡ ਕਰੇ, ਇਹ ਫਿਰ ਵੀ ਇੱਕੋ Document ਰਿਕਾਰਡ ਰਹਿਣਾ ਚਾਹੀਦਾ ਹੈ। ਟਿੱਪਣੀਆਂ, ਅਸਾਈਨਮੈਂਟ ਅਤੇ ਆਡਿਟ ਲਾਗ ਇੱਕ ਸਥਿਰ ID ਨਾਲ ਸਾਫ਼ ਢੰਗ ਨਾਲ ਜੁੜੇ ਰਹਿੰਦੇ ਹਨ।
ਹਰ ਮਹੱਤਵਪੂਰਨ ਬਦਲਾਅ ਨੂੰ ਇੱਕ ਨਵਾਂ version ਰਿਕਾਰਡ ਮਾਨੋ। ਹਰ ਵਰਜ਼ਨ ਨੂੰ ਦਰਜ ਕਰੋ ਕਿ ਕਿਸ ਨੇ ਇਸਨੂੰ ਬਣਾਇਆ ਅਤੇ ਕਦੋਂ, ਨਾਲ ਹੀ ਸਟੋਰੇਜ ਪੌਇੰਟਰ (file key, checksum, size, page count) ਅਤੇ ਨਿਕਲੇ ਹੋਏ ਆਰਟਿਫੈਕਟ (OCR ਟੈਕਸਟ, preview images) ਜੋ ਇਸ ਨਿਰਧਾਰਤ ਫਾਈਲ ਨਾਲ ਸੰਬੰਧਤ ਹਨ। ਸਥਾਨ 'ਤੇ ਸੋਧ ਕਰਨ ਤੋਂ ਬਚੋ। ਪਹਿਲਾਂ ਇਹ ਸਧਾਰਨ ਲੱਗਦਾ ਹੈ, ਪਰ ਇਸ ਨਾਲ ਟ੍ਰੇਸਬਿਲਟੀ ਟੁਟਦੀ ਹੈ ਅਤੇ ਬੱਗਸ ਨੂੰ ਠੀਕ ਕਰਨਾ ਮੁਸ਼ਕਲ ਹੋ ਜਾਂਦਾ ਹੈ।
ਫਾਸਟ ਰੀਡ ਲਈ, ਡਾਕੂਮੈਂਟ 'ਤੇ current_version_id ਰੱਖੋ। ਜ਼ਿਆਦਾਤਰ ਸਕ੍ਰੀਨਾਂ ਨੂੰ ਸਿਰਫ਼ "ਨਵੀਨਤਮ" ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ, ਤਾਂ ਹਰ ਵਾਰੀ ਵਰਜ਼ਨਾਂ ਨੂੰ ਸੌਰਟ ਕਰਨ ਦੀ ਲੋੜ ਨਹੀਂ ਰਹਿੰਦੀ। ਜਦੋਂ ਤੁਹਾਨੂੰ ਇਤਿਹਾਸ ਦੀ ਲੋੜ ਹੋਵੇ, ਤਾਂ ਵਰਜ਼ਨਾਂ ਨੂੰ ਅਲੱਗ ਲੋਡ ਕਰੋ ਅਤੇ ਇੱਕ ਸਾਫ ਟਾਈਮਲਾਈਨ ਦਿਖਾਓ।
Rollback ਸਿਰਫ਼ ਇੱਕ pointer ਬਦਲਣਾ ਹੈ। ਕੁਝ ਹਟਾਉਣ ਦੀ ਥਾਂ, current_version_id ਨੂੰ ਪੁਰਾਣੇ ਵਰਜ਼ਨ 'ਤੇ ਵਾਪਸ ਸੈੱਟ ਕਰੋ। ਇਹ ਤੇਜ਼, ਸੁਰੱਖਿਅਤ ਹੈ ਅਤੇ ਆਡਿਟ ਟ੍ਰੇਲ ਅਟੁੱਟ ਰੱਖਦੀ ਹੈ।
ਇਤਿਹਾਸ ਨੂੰ ਸਮਝਣਯੋਗ ਰੱਖਣ ਲਈ, ਦਰਜ ਕਰੋ ਕਿ ਹਰ ਵਰਜ਼ਨ ਕਿਉਂ ਬਣਿਆ। ਇੱਕ ਛੋਟਾ, ਸਥਿਰ reason ਫੀਲਡ (ਤੇ ਵਿਕਲਪਿਕ ਨੋਟ) ਟਾਈਮਲਾਈਨ ਨੂੰ ਰਹੱਸਮਈ ਅਪਡੇਟਾਂ ਨਾਲ ਭਰ ਜਾਣ ਤੋਂ ਬਚਾਉਂਦਾ ਹੈ। ਆਮ ਕਾਰਨਾਂ ਵਿੱਚ re-upload replacement, scan cleanup, OCR correction, redaction, ਅਤੇ approval edit ਸ਼ਾਮਲ ਹਨ।
ਉਦਾਹਰਨ: ਫ਼ਾਇਨੈਂਸ ਟੀਮ ਇੱਕ ਰਸੀਦ ਫੋਟੋ ਅਪਲੋਡ ਕਰਦੀ ਹੈ, ਉਸ ਦੇ ਬਾਅਦ ਸਾਫ਼ ਸਕੈਨ ਨਾਲ ਬਦਲਦੀ ਹੈ, ਫਿਰ OCR ਠੀਕ ਕਰਦੀ ਹੈ ਤਾਂ ਕਿ ਕੁੱਲ ਪੜ੍ਹਨਾ ਜਾ ਸਕੇ। ਹਰ ਕਦਮ ਇੱਕ ਨਵਾਂ ਵਰਜ਼ਨ ਹੈ, ਪਰ ਡਾਕੂਮੈਂਟ ਇਕ ਹੀ ਆਈਟਮ ਰਿਹਾ। ਜੇ OCR ਠੀਕ ਨਹੀਂ ਸੀ, ਤਾਂ rollback ਇੱਕ ਕਲਿੱਕ 'ਚ ਹੈ ਕਿਉਂਕਿ ਤੁਸੀਂ ਸਿਰਫ਼ current_version_id ਬਦਲ ਰਹੇ ਹੋ।
Document-centric ਵਰਕਫਲੋ ਵਿੱਚ ਪ੍ਰੀਵਿਊ ਆਮ ਤੌਰ 'ਤੇ ਸਭ ਤੋਂ ਮੁੱਖ ਚੀਜ਼ ਹੁੰਦਾ ਹੈ ਜਿਸ ਨਾਲ ਯੂਜ਼ਰ ਇੰਟਰੈਕਟ ਕਰਦੇ ਹਨ। ਜੇ ਪ੍ਰੀਵਿਊ ਧੀਮਾ ਜਾਂ ਖਰਾਬ ਹੋਵੇ, ਤਾਂ ਸਾਰਾ ਐਪ ਖ਼ਰਾਬ ਮਹਿਸੂਸ ਹੁੰਦਾ ਹੈ।
ਪ੍ਰੀਵਿਊ ਜਨਰੇਸ਼ਨ ਨੂੰ ਇੱਕ ਅਲੱਗ ਨੌਕਰੀ ਵਜੋਂ ਸਮਝੋ, ਨਾ ਕਿ ਅਪਲੋਡ ਸਕ੍ਰੀਨ ਜਿਸਦੀ ਉਡੀਕ ਹੋਵੇ। ਪਹਿਲਾਂ ਮੂਲ ਫਾਈਲ ਸੇਵ ਕਰੋ, ਯੂਜ਼ਰ ਨੂੰ ਕੰਟਰੋਲ ਵਾਪਸ ਦਿਓ, ਫਿਰ ਬੈਕਗ੍ਰਾਊਂਡ ਵਿੱਚ ਪ੍ਰੀਵਿਊ ਜਨਰੇਟ ਕਰੋ। ਇਸ ਨਾਲ UI ਜਵਾਬੀ ਰਹਿੰਦਾ ਹੈ ਅਤੇ ਰੀਟ੍ਰਾਈ ਸੁਰੱਖਿਅਤ ਹੁੰਦੇ ਹਨ।
ਕਈ ਪ੍ਰੀਵਿਊ ਆਕਾਰ ਸਟੋਰ ਕਰੋ। ਇੱਕ ਆਕਾਰ ਹਰ ਸਕ੍ਰੀਨ ਲਈ ਕਦੇ ਠੀਕ ਨਹੀਂ ਹੁੰਦਾ: ਲਿਸਟਾਂ ਲਈ ਛੋਟਾ thumbnail, ਸਪਲਿਟ ਵਿਊ ਲਈ ਮੱਧਮ ਆਕਾਰ, ਅਤੇ ਵਿਸਥਾਰ ਰਿਵਿਊ ਲਈ ਪੂਰਾ-ਪੰਨਾ ਚਿੱਤਰ (PDF ਲਈ ਪੰਨਾ-ਦਰ-ਪੰਨਾ)।
ਪ੍ਰੀਵਿਊ ਸਥਿਤੀ ਨੂੰ ਸਪਸ਼ਟ ਤੌਰ 'ਤੇ ਟ੍ਰੈਕ ਕਰੋ ਤਾਂ UI ਹਮੇਸ਼ਾ ਜਾਣੇ ਕਿ ਕੀ ਦਿਖਾਉਣਾ ਹੈ: pending, ready, failed, ਅਤੇ needs_retry। UI ਵਿੱਚ ਲੇਬਲ ਯੂਜ਼ਰ-ਫ੍ਰੈਂਡਲੀ ਰੱਖੋ, ਪਰ ਡੇਟਾ ਵਿੱਚ ਸਟੇਟ ਸਪਸ਼ਟ ਰੱਖੋ।
ਰੇਂਡਰਿੰਗ ਤੇਜ਼ ਰੱਖਣ ਲਈ, preview ਰਿਕਾਰਡ ਦੇ ਨਾਲ ਹੀ ਨਿਕਲੇ ਹੋਏ ਮੁੱਲਾਂ ਨੂੰ cache ਕਰੋ ਨਾ ਕਿ ਹਰ ਵੇਖਣ 'ਤੇ ਮੁੜ-ਗਣਨਾ ਕਰੋ। ਆਮ ਫੀਲਡਾਂ ਵਿੱਚ page count, preview width ਅਤੇ height, rotation (0/90/180/270), ਅਤੇ ਇਕ ਵਿਕਲਪਿਕ “ਥੰਬਨੇਲ ਲਈ ਸਭ ਤੋਂ ਵਧੀਆ ਪੰਨਾ” ਸ਼ਾਮਲ ਹਨ।
ਧੀਮੀਆਂ ਅਤੇ ਗੰਝਲਦਾਰ ਫਾਈਲਾਂ ਲਈ ਡਿਜ਼ਾਇਨ ਕਰੋ। 200-ਪੰਨੇ ਵਾਲਾ ਸਕੈਨ PDF ਜਾਂ ਝੁਠਲਾਏ ਰਸੀਦ ਫੋਟੋ ਪ੍ਰੋਸੈਸ ਕਰਨ ਵਿੱਚ ਵਕਤ ਲੈ ਸਕਦੇ ਹਨ। ਪ੍ਰੋਗ੍ਰੈਸੀਵ ਲੋਡਿੰਗ ਵਰਤੋ: ਜਿੰਨਾ ਵੀ ਪੰਨੇ ਤਿਆਰ ਹਨ ਉਹ ਪਹਿਲਾਂ ਦਿਖਾਓ, ਫਿਰ ਬਾਕੀ ਭਰੋ।
ਉਦਾਹਰਨ: ਯੂਜ਼ਰ 30 ਰਸੀਦ ਫੋਟੋਅਾਂ ਅਪਲੋਡ ਕਰਦਾ ਹੈ। ਲਿਸਟ ਵਿਉ ਵਿੱਚ ਥੰਬਨੇਲ "pending" ਵਜੋਂ ਦਿਖਾਈ ਦਿੰਦਾ ਹੈ, ਫਿਰ ਜਿਵੇਂ-ਜਿਵੇਂ ਪ੍ਰੀवਿਊ ਤਿਆਰ ਹੁੰਦਾ ਹੈ ਕਾਰਡ "ready" ਹੋ ਜਾਂਦਾ ਹੈ। ਜੇ ਕੁਝ corrupted image ਕਾਰਨ fail ਹੋ ਜਾਂਦੇ ਹਨ, ਉਹ ਸਪੱਸ਼ਟ retry ਕਾਰਵਾਈ ਨਾਲ ਦਿਖਦੇ ਹਨ ਬਲਕਿ ਪੂਰੇ ਬੈਚ ਨੂੰ ਰੋਕਣ ਦੀ ਥਾਂ।
ਮੈਟਾਡੇਟਾ ਫਾਈਲਾਂ ਦਾ ਇੱਕ ਢੇਰ ਕੁਝ ਇਸ ਤਰ੍ਹਾਂ ਬਣਾ ਦਿੰਦਾ ਹੈ ਕਿ ਤੁਸੀਂ ਉਹਨਾਂ ਨੂੰ ਖੋਜ, ਛਾਂਟ, ਸਮੀਖਿਆ ਅਤੇ ਮਨਜ਼ੂਰ ਕਰ ਸਕੋ। ਇਹ ਲੋਕਾਂ ਨੂੰ ਸਵਾਲਾਂ ਦੇ ਜਵਾਬ ਤੇਜ਼ੀ ਨਾਲ ਦੇਣ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ: ਇਹ ਕੀ ਹੈ? ਇਹ ਕਿਸ ਤੋਂ ਹੈ? ਕੀ ਇਹ ਵੈਧ ਹੈ? ਅਗਲਾ ਕੀ ਹੋਣਾ ਚਾਹੀਦਾ?
ਮੈਟਾਡੇਟਾ ਨੂੰ ਸਾਫ਼ ਰੱਖਣ ਦਾ ਇੱਕ ਆਮ ਤਰੀਕਾ ਇਹ ਹੈ ਕਿ ਤੁਸੀਂ ਇਸ ਨੂੰ ਆਉਣ ਵਾਲੇ ਸੋਰਸ ਅਨੁਸਾਰ ਵੱਖ-ਵੱਖ ਰੱਖੋ:
ਇਹ ਬਕੱਟਾਂ ਬਾਅਦ ਵਿੱਚ ਹੋਣ ਵਾਲੀਆਂ ਰਾਜ਼-ਬਾਦ-ਬਚਾਉਂਦੀਆਂ ਖ਼ਿਲਾਫ ਰੋਕਦੀਆਂ ਹਨ। ਜੇ ਇੱਕ total amount ਗਲਤ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਦੇਖ ਸਕਦੇ ਹੋ ਕਿ ਇਹ OCR ਤੋਂ ਆਇਆ ਸੀ ਜਾਂ ਮਨੁੱਖੀ ਸੋਧ ਹੈ।
ਰਸੀਦਾਂ ਅਤੇ ਇਨਵੌਇਸਾਂ ਲਈ, ਕੁਝ ਮੁੱਖ ਫੀਲਡ ਇੱਕਸਾਰ ਵਰਤੋਂ ਵਿੱਚ ਲਾਭਦਾਇਕ ਹਨ (ਉਹੀ ਨਾਮ, ਉਹੀ ਫਾਰਮੈਟ). ਆਮ anchor ਫੀਲਡ ਹਨ vendor, date, total, currency, ਅਤੇ document_number. ਸ਼ੁਰੂ ਵਿੱਚ ਉਹਨਾਂ ਨੂੰ ਵਿਕਲਪਿਕ ਰੱਖੋ। ਲੋਕ ਅਧੂਰੇ ਸਕੈਨ ਅਤੇ ਧੁੰਦਲੇ ਫੋਟੋਅਾਂ ਅਪਲੋਡ ਕਰਦੇ ਹਨ, ਅਤੇ ਇੱਕ ਫੀਲਡ ਦੀ ਗੈਰਹਾਜ਼ਰੀ ਕਾਰਨ ਪੂਰਾ ਫਲੋ ਰੋਕਣਾ ਰੁਕਾਵਟ ਬਣਦਾ ਹੈ।
ਅਣਜਾਣ ਮੁੱਲਾਂ ਨੂੰ ਪਹਿਲੀ ਕ਼ਦਰ ਵਜੋਂ ਮੰਨੋ। null/unknown ਵਰਗੀਆਂ ਸਪਸ਼ਟ ਸਥਿਤੀਆਂ ਅਤੇ ਜਦੋ ਲੋੜ ਹੋਵੇ ਇੱਕ ਕਾਰਨ ਦਿਓ (missing page, unreadable, not applicable). ਇਸ ਨਾਲ ਦਸਤਾਵੇਜ਼ ਅੱਗੇ ਵਧ ਸਕਦਾ ਹੈ ਪਰ ਸਮੀਖਿਆਕਾਰ ਨੂੰ ਦਿਸੇਗਾ ਕਿ ਕਿਹੜੀ ਚੀਜ਼ ਧਿਆਨ ਮਾਂਗਦੀ ਹੈ।
ਨਿਕਲੇ ਹੋਏ ਫੀਲਡਾਂ ਲਈ provenance ਅਤੇ confidence ਵੀ ਸਟੋਰ ਕਰੋ। ਸਰੋਤ ਹੋ ਸਕਦਾ ਹੈ user, OCR, import, ਜਾਂ API. confidence 0-1 ਸਕੋਰ ਹੋ ਸਕਦਾ ਹੈ ਜਾਂ high/medium/low ਵਰਗਾ ਛੋਟਾ ਸੈੱਟ। ਜੇ OCR ਨੇ "$18.70" ਘੱਟ confidence ਨਾਲ ਪੜ੍ਹਿਆ ਹੈ ਕਿਉਂਕਿ ਆਖਰੀ ਅੱਖਰ ਧੁੰਧਲਾ ਹੈ, ਤਾਂ UI ਇਸ ਨੂੰ ਹਾਈਲਾਈਟ ਕਰਕੇ ਤੇਜ਼ ਪੁਸ਼ਟੀ ਮੰਗ ਸਕਦਾ ਹੈ।
ਮਲਟੀ-ਪੇਜ ਦਸਤਾਵੇਜ਼ਾਂ ਲਈ ਇੱਕ ਹੋਰ ਫੈਸਲਾ ਲੈਣਾ ਪੈਂਦਾ ਹੈ: ਕੀ ਚੀਜ਼ ਪੂਰੇ ਦਸਤਾਵੇਜ਼ ਨਾਲ ਸੰਬੰਧਤ ਹੈ ਜਾਂ ਇਕ ਪੰਨੇ ਨਾਲ। ਟੋਟਲ ਅਤੇ vendor ਆਮ ਤੌਰ 'ਤੇ ਦਸਤਾਵੇਜ਼-ਸਤਰ 'ਤੇ ਹੁੰਦੇ ਹਨ। ਪੰਨਾ-ਸਤਰੀ ਨੋਟਸ, redactions, rotation, ਅਤੇ ਪ੍ਰਤੀ-ਪੰਨਾ ਵਰਗੀਕਰਨ ਪੰਨਾ-ਸਤਰੀ ਹੋ ਸਕਦੇ ਹਨ।
Status ਇੱਕ ਸਵਾਲ ਦਾ ਜਵਾਬ ਦਿੰਦਾ ਹੈ: “ਇਹ ਦਸਤਾਵੇਜ਼ ਪ੍ਰਕਿਰਿਆ ਵਿੱਚ ਕਿੱਥੇ ਹੈ?” ਇਸਨੂੰ ਛੋਟਾ ਅਤੇ ਨਿਰਸ ਰੱਖੋ। ਜੇ ਤੁਸੀਂ ਹਰ ਵਾਰੀ ਕੋਈ ਨਵਾਂ status ਜੋੜਾਂਗੇ ਜਦੋਂ ਕਿਸੇ ਨੇ ਪੁੱਛਿਆ, ਤਾਂ ਫਿਲਟਰ ਉਹਨਾਂ 'ਤੇ ਭਰੋਸਾ ਨਾ ਕਰਨਗੇ।
ਅਸਲੀ ਫੈਸਲਿਆਂ ਨਾਲ ਮੇਲ ਖਾਣ ਵਾਲੀਆਂ ਕੁਝ ਪ੍ਰਯੋਗਸ਼ੀਲ ਬਿਜ਼ਨਸ ਸਥਿਤੀਆਂ:
“Processing” ਨੂੰ ਬਿਜ਼ਨਸ status ਵਿੱਚ ਰੱਖਣ ਤੋਂ ਬਚੋ। OCR ਚੱਲ ਰਿਹਾ ਹੈ ਅਤੇ preview ਜਨਰੇਟ ਹੋ ਰਹੀ ਹੈ ਇਸ ਤੋਂ ਇਨਸਾਨੀ ਕਾਰਵਾਈ ਨੂੰ ਨਹੀਂ ਦਰਸਾਉਂਦਾ। ਇਹਨਾਂ ਨੂੰ ਵੱਖਰੇ processing ਸਟੇਟਸ ਵਜੋਂ ਸਟੋਰ ਕਰੋ।
ਅਸਾਈਨਮੈਂਟ ਨੂੰ status ਤੋਂ ਵੱਖਰਾ ਰੱਖੋ (assignee_id, team_id, due_date)। ਇੱਕ ਦਸਤਾਵੇਜ਼ Approved ਹੋ ਸਕਦਾ ਹੈ ਪਰ ਫਾਲੋ-ਅਪ ਲਈ ਹਾਲੇ ਅਸਾਈਨ ਕੀਤਾ ਹੋਵੇ, ਜਾਂ Needs review ਹੋ ਸਕਦਾ ਹੈ ਪਰ ਕੋਈ ਮਾਲਕ ਨਾਹ ਹੋਵੇ।
status ਇਤਿਹਾਸ ਰਿਕਾਰਡ ਕਰੋ, ਸਿਰਫ਼ ਵਰਤਮਾਨ ਮੁੱਲ ਨਹੀਂ। (from_status, to_status, changed_at, changed_by, reason) ਵਰਗਾ ਇੱਕ ਸਧਾਰਨ ਲਾਗ ਫਾਇਦਾ ਦਿੰਦਾ ਹੈ ਜਦੋਂ ਕੋਈ ਪੁੱਛੇ, “ਇਸ ਰਸੀਦ ਨੂੰ ਕਿਸਨੇ ਰੱਦ ਕੀਤਾ ਅਤੇ ਕਿਉਂ?”
ਅੰਤ ਵਿੱਚ, ਨਿਰਧਾਰਤ ਕਰੋ ਕਿ ਹਰ status ਵਿੱਚ ਕਿਹੜੀਆਂ ਕਾਰਵਾਈਆਂ ਦੀ ਆਗਿਆ ਹੈ। ਨਿਯਮ ਸਧਾਰਣ ਰੱਖੋ: Imported ਤੋਂ Needs review ਹੋ ਸਕਦਾ ਹੈ; Approved ਪੜ੍ਹਨ-ਕੇਵਲ (read-only) ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ ਜਦ ਤੱਕ ਨਵਾਂ ਵਰਜ਼ਨ ਨਹੀਂ ਬਣਦਾ; Rejected ਨੂੰ ਖੋਲ੍ਹਿਆ ਜਾ ਸਕਦਾ ਹੈ ਪਰ ਪਹਿਲਾ ਕਾਰਨ ਸੰਭਾਲ ਕੇ ਰੱਖਣਾ ਲਾਜ਼ਮੀ ਹੋਵੇ।
ਜ਼ਿਆਦਾਤਰ ਸਮਾਂ ਇੱਕ ਲਿਸਟ ਸਕੈਨ ਕਰਨ, ਇੱਕ ਆਈਟਮ ਖੋਲ੍ਹਣ, ਕੁਝ ਫੀਲਡ ਠੀਕ ਕਰਨ ਅਤੇ ਅਗੇ ਵੱਧਣ ਵਿੱਚ ਲੱਗਦਾ ਹੈ। ਅੱਛੀ UI ਇਹਨਾਂ ਕਦਮਾਂ ਨੂੰ ਤੇਜ਼ ਅਤੇ ਭਰੋਸੇਯੋਗ ਬਣਾਉਂਦੀ ਹੈ।
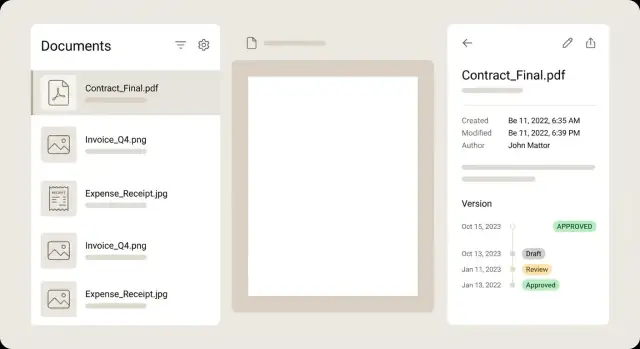
ਡਾਕੂਮੈਂਟ ਲਿਸਟ ਲਈ, ਹਰ ਰੋ ਨੂੰ ਇਕ ਸਮਰੀ ਵਾਂਗ ਦੇਖੋ ਤਾਂ ਯੂਜ਼ਰ ਹਰ ਫਾਈਲ ਨਾਂ ਖੋਲ੍ਹ ਕੇ ਫੈਸਲਾ ਕਰ ਸਕਣ। ਇੱਕ ਮਜ਼ਬੂਤ ਰੋ ਵਿੱਚ ਛੋਟਾ thumbnail, ਸਪਸ਼ਟ ਸਿਰਲੇਖ, ਕੁਝ ਮੁੱਖ ਫੀਲਡ (merchant, date, total), ਇੱਕ status ਬੈਜ, ਅਤੇ ਜਦੋਂ ਧਿਆਨ ਮੰਗਦਾ ਹੋਵੇ ਤਾ ਇੱਕ ਸੁੱਚੇ ਚੇਤਾਵਨੀ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ।
ਡੀਟੇਲ ਵਿਉ ਨੂੰ ਸ਼ਾਂਤ ਅਤੇ ਸਕੈਨ ਕਰਨਯੋਗ ਰੱਖੋ। ਆਮ ਲੇਆਉਟ: ਖੱਬੇ ਪਾਸੇ ਪ੍ਰੀਵਿਊ ਅਤੇ ਸੱਜੇ ਪਾਸੇ ਮੈਟਾ ਡੇਟਾ, ਹਰ ਫੀਲਡ ਦੇ ਨਾਲ ਸੋਧ ਕਾਬੀਲ ਕંટ੍ਰੋਲ। ਯੂਜ਼ਰ ਨੂੰ ਜੋਮ, ਘੁੰਮਾਉ, ਅਤੇ ਪੰਨਿਆਂ ਨੂੰ ਬਿਨਾਂ ਫਾਰਮ 'ਚ ਆਪਣੀ ਜਗ੍ਹਾ ਗਵਾ ਦਿੱਤੇ ਬਦਲਣ ਯੋਗ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ। ਜੇ ਇੱਕ ਫੀਲਡ OCR ਤੋਂ ਨਿਕਲੇ ਹੋਏ ਹੋਵੇ ਤਾਂ ਛੋਟਾ confidence ਚਿੰਨ੍ਹ ਦਿਖਾਓ, ਅਤੇ ਜੇ ਸੰਭਵ ਹੋਵੇ ਤਾਂ ਜਦੋਂ ਫੀਲਡ ਫੋਕਸ ਹੋਵੇ ਪ੍ਰੀਵਿਊ 'ਤੇ ਉਸ ਸੋਰਸ ਖੇਤਰ ਨੂੰ ਹਾਈਲਾਈਟ ਕਰੋ।
ਵਰਜ਼ਨ ਟਾਈਮਲਾਈਨ ਵਧੀਆ ਹੁੰਦੀ ਹੈ ਬਜਾਏ ਡ੍ਰੌਪਡਾਊਨ ਦੇ। ਦਿਖਾਓ ਕਿ ਕਿਸਨੇ ਕਿਉਂ ਅਤੇ ਕਦੋਂ ਬਦਲਿਆ, ਅਤੇ ਯੂਜ਼ਰ ਨੂੰ ਕਿਸੇ ਵੀ ਪੁਰਾਣੇ ਵਰਜ਼ਨ ਨੂੰ ਪੜ੍ਹਨ-ਕੇਵਲ ਮੋਡ ਵਿੱਚ ਖੋਲ੍ਹਣ ਦਿਓ। ਜੇ ਤੁਸੀਂ ਤੁਲਨਾ ਪੇਸ਼ ਕਰੋ ਤਾਂ metadata ਵਿੱਚ ਫਰਕਾਂ 'ਤੇ ਧਿਆਨ ਕੇਂਦ੍ਰਿਤ ਕਰੋ (amount ਬਦਲਿਆ, vendor ਠੀਕ ਕੀਤਾ) ਨਾਂ ਕਿ ਪੀਕਸਲ-ਦੇ-ਪੀਕਸਲ PDF ਤੁਲਨਾ ਨੂੰ ਲਾਜ਼ਮੀ ਬਣਾਓ।
ਰਿਵਿਊ ਮੋਡ ਨੂੰ ਗਤੀ ਲਈ Optimize ਕਰੋ। ਇੱਕ ਕੀਬੋਰਡ-ਪਹਿਲਾ triage ਫਲੋ ਆਮ ਤੌਰ 'ਤੇ ਕਾਫੀ ਹੈ: ਤੇਜ਼ approve/reject ਕਾਰਵਾਈਆਂ, ਆਮ ਫੀਲਡਾਂ ਲਈ ਤੇਜ਼ ਸੋਧਾਂ, ਅਤੇ ਰੱਦ ਕਰਨ ਲਈ ਛੋਟਾ comments ਬਾਕਸ।
ਖਾਲੀ ਸਥਿਤੀਆਂ ਮਹਤਵਪੂਰਨ ਹਨ ਕਿਉਂਕਿ ਦਸਤਾਵੇਜ਼ ਅਕਸਰ ਮੱਧ-ਪ੍ਰਕਿਰਿਆ ਵਿੱਚ ਹੁੰਦੇ ਹਨ। ਇੱਕ ਖਾਲੀ ਬਾਕਸ ਦੀ ਥਾਂ, ਦਸੋ ਕਿ ਕੀ ਹੋ ਰਿਹਾ ਹੈ: “Preview ਜਨਰੇਟ ਹੋ ਰਿਹਾ ਹੈ,” “OCR ਚੱਲ ਰਹੀ ਹੈ,” ਜਾਂ “ਇਸ ਫਾਈਲ ਟਾਈਪ ਲਈ ਕੋਈ ਪ੍ਰੀਵਿਊ ਉਪਲਬਧ ਨਹੀਂ ਹੈ।”
ਇੱਕ ਸਧਾਰਣ ਵਰਕਫਲੋ "ਅਪਲੋਡ, ਚੈੱਕ, ਮਨਜ਼ੂਰ" ਵਰਗਾ ਮਹਿਸੂਸ ਹੁੰਦਾ ਹੈ। ਅੰਦਰਲੇ ਤੌਰ ਤੇ, ਇਹ ਉਸ ਸਮੇਂ ਸਹੀ ਕੰਮ ਕਰਦਾ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਫਾਈਲ (ਵਰਜ਼ਨ ਅਤੇ ਪ੍ਰੀਵਿਊਜ਼) ਨੂੰ ਵਿਧਾਨਿਕ ਤੌਰ ਤੇ ਵਿਛੋੜ ਕੇ ਰੱਖਦੇ ਹੋ ਅਤੇ ਬਿਜ਼ਨਸ ਅਰਥ (ਮੈਟਾ ਡੇਟਾ ਅਤੇ ਸਟੇਟਸ) ਨੂੰ ਅਲੱਗ ਰੱਖਦੇ ਹੋ।
ਯੂਜ਼ਰ ਇੱਕ PDF, ਫੋਟੋ, ਜਾਂ ਰਸੀਦ ਸਕੈਨ ਅਪਲੋਡ ਕਰਦਾ ਹੈ ਅਤੇ ਤੁਰੰਤ ਉਸ ਨੂੰ ਇਕ ਇਨਬਾਕਸ ਲਿਸਟ ਵਿੱਚ ਵੇਖਦਾ ਹੈ। ਪ੍ਰੋਸੈਸਿੰਗ ਤੋਂ ਉਡੀਕ ਨਾ ਕਰੋ। ਇੱਕ ਫਾਈਲ ਨਾਮ, ਅਪਲੋਡ ਸਮਾਂ, ਅਤੇ "Processing" ਵਰਗਾ ਸਪਸ਼ਟ ਬੈਜ ਦਿਖਾਓ। ਜੇ ਤੁਸੀਂ ਪਹਿਲਾਂ ਹੀ ਸਰੋਤ ਜਾਣਦੇ ਹੋ (ਈਮੇਲ ਇੰਪੋਰਟ, ਮੋਬਾਈਲ ਕੈਮਰਾ, drag-and-drop), ਤਾਂ ਉਹ ਵੀ ਦਿਖਾਓ।
ਅਪਲੋਡ 'ਤੇ, ਇੱਕ Document ਰਿਕਾਰਡ (ਲੰਬੇ ਸਮੇਂ ਵਾਲੀ ਚੀਜ਼) ਅਤੇ ਇੱਕ Version ਰਿਕਾਰਡ (ਇਸ ਖਾਸ ਫਾਈਲ) ਬਣਾਉ। current_version_id ਨੂੰ ਨਵੇਂ ਵਰਜ਼ਨ 'ਤੇ ਸੈੱਟ ਕਰੋ। preview_state = pending ਅਤੇ extraction_state = pending ਸੈੱਟ ਕਰੋ ਤਾਂ ਕਿ UI ਸਚ ਬਿਆਨ ਕਰ ਸਕੇ ਕਿ ਕੀ ਤਿਆਰ ਹੈ।
ਡੀਟੇਲ ਵਿਉ ਤੁਰੰਤ ਖੁਲਣਾ ਚਾਹੀਦਾ ਹੈ, ਪਰ ਇੱਕ placeholder viewer ਅਤੇ "Preparing preview" ਸੁਨੇਹਾ ਦਿਖਾਓ ਨਾ ਕਿ ਟੁੱਟੀ ਫਰੇਮ।
ਇੱਕ ਬੈਕਗ੍ਰਾਊਂਡ ਨੌਕਰੀ thumbnails ਅਤੇ viewable preview (PDF ਲਈ ਪੰਨਾ-ਚਿੱਤਰ, ਫੋਟੋ ਲਈ ਰੀਸਾਈਜ਼ ਕੀਤੀਆਂ ਇਮੇਜ) ਬਣਾਉਂਦੀ ਹੈ। ਦੂਜੀ ਨੌਕਰੀ ਮੈਟਾਡੇਟਾ ਨਿਕਾਲਦੀ ਹੈ (vendor, date, total, currency, document type). ਜਦੋਂ ਹਰ ਨੌਕਰੀ ਖਤਮ ਹੋਵੇ, ਤਾਂ ਸਿਰਫ਼ ਉਸਦੀ ਸਥਿਤੀ ਅਤੇ ਟਾਈਮਸਟੈਮਪ ਅਪਡੇਟ ਕਰੋ ਤਾਂ ਕਿ ਅਸਫਲਤਾਵਾਂ ਨੂੰ ਦੁਬਾਰਾ ਕੋਸ਼ਿਸ਼ ਬਿਨਾਂ ਹੋਰ ਖਤਮ ਕੀਤੇ ਜਾ ਸਕੇ।
UI ਨੂੰ ਸੰਕੁਚਿਤ ਰੱਖੋ: preview state, data state ਦਿਖਾਓ, ਅਤੇ ਓਹਨਾਂ ਫੀਲਡਾਂ ਨੂੰ ਹਾਈਲਾਈਟ ਕਰੋ ਜਿਨ੍ਹਾਂ ਦੀ confidence ਘੱਟ ਹੈ।
ਜਦੋਂ ਪ੍ਰੀਵਿਊ ਤਿਆਰ ਹੋ ਜਾਵੇ, ਤਾਂ ਸਮੀਖਿਆਕਾਰ ਫੀਲਡ ਠੀਕ ਕਰਦੇ ਹਨ, ਨੋਟਸ ਜੋੜਦੇ ਹਨ, ਅਤੇ ਦਸਤਾਵੇਜ਼ ਨੂੰ ਬਿਜ਼ਨਸ ਸਟੇਟਸ ਵਿੱਚ ਲਿਜਾਂਦੇ ਹਨ ਜਿਵੇਂ Imported -> Needs review -> Approved (ਜਾਂ Rejected)। ਕਿਸਨੇ ਕਦੋਂ ਕੀ ਬਦਲਿਆ ਇਸ ਦਾ ਲਾਗ ਰੱਖੋ।
ਜੇ ਇਕ ਸਮੀਖਿਆਕਾਰ ਸੋਧੀ ਫਾਈਲ ਅਪਲੋਡ ਕਰਦਾ ਹੈ, ਤਾਂ ਉਹ ਨਵਾਂ Version ਬਣ ਜਾਂਦਾ ਹੈ ਅਤੇ ਦਸਤਾਵੇਜ਼ ਆਟੋਮੈਟਿਕ ਤੌਰ 'ਤੇ Needs review 'ਤੇ ਵਾਪਸ ਆ ਜਾਂਦਾ ਹੈ।
ਐਕਸਪੋਰਟ, ਇਕਾਊਂਟਿੰਗ ਸਿੰਕ, ਜਾਂ ਅੰਦਰੂਨੀ ਰਿਪੋਰਟ current_version_id ਅਤੇ ਮਨਜ਼ੂਰ ਮੈਟਾਡੇਟਾ snapshot ਤੋਂ ਪੜ੍ਹਣੇ ਚਾਹੀਦੇ ਹਨ, ਨਾ ਕਿ "ਆਖਰੀ ਨਿਕਾਸ" ਤੋਂ। ਇਸ ਨਾਲ ਇੱਕ ਅੱਧ-ਪ੍ਰੋਸੈਸਡ ਰੀ-ਅਪਲੋਡ ਨੰਬਰਾਂ ਨੂੰ ਬਦਲਦਾ ਨਹੀਂ।
Document-centric ਵਰਕਫਲੋ ਨਿਰਾਸ਼ਾ ਵਾਲੀਆਂ ਕਾਰਨਾਂ ਕਰਕੇ ਫੇਲ ਹੁੰਦੇ ਹਨ: ਸ਼ੁਰੂਆਤੀ ਛੋਟੇ ਕਾਰਟਾ-ਪੁੱਟ ਕੇ ਰੋਜ਼ਾਨਾ ਮੁਸ਼ਕਲ ਬਣ ਜਾਂਦੇ ਹਨ ਜਦੋਂ ਲੋਕ duplicate ਅਪਲੋਡ ਕਰਦੇ, ਗਲਤੀਆਂ ਠੀਕ ਕਰਦੇ, ਜਾਂ ਪੁੱਛਦੇ, "ਇਸਨੂੰ ਕਿਸਨੇ ਅਤੇ ਕਦੋਂ ਬਦਲਿਆ?"。
ਫਾਈਲ ਨਾਮ ਨੂੰ ਦਸਤਾਵੇਜ਼ ਦੀ ਪਛਾਣ ਮੰਨਣਾ ਇੱਕ ਕਲਾਸਿਕ ਗਲਤੀ ਹੈ। ਨਾਮ ਬਦਲਦੇ ਹਨ, ਯੂਜ਼ਰ ਦੁਬਾਰਾ ਅਪਲੋਡ ਕਰਦੇ ਹਨ, ਅਤੇ ਕੈਮਰੇ duplicates ਬਣਾਉਂਦੇ ਹਨ ਜਿਵੇਂ IMG_0001। ਹਰ ਦਸਤਾਵੇਜ਼ ਨੂੰ ਇੱਕ ਸਥਿਰ ID ਦਿਓ, ਅਤੇ ਫਾਈਲ ਨਾਮ ਨੂੰ ਇੱਕ ਲੇਬਲ ਵਜੋਂ ਹੀ ਰੱਖੋ।
ਮੂਲ ਫਾਈਲ ਨੂੰ ਓਵਰਰਾਈਟ ਕਰਨਾ ਵੀ ਮੁਸ਼ਕਲ ਪੈਦਾ ਕਰਦਾ ਹੈ। ਇਹ ਪਹਿਲਾਂ ਸਧਾਰਨ ਲੱਗਦਾ ਹੈ, ਪਰ ਤੁਸੀਂ ਆਪਣੀ ਆਡਿਟ ਟ੍ਰੇਲ ਗੁਆ ਦੇਂਦੇ ਹੋ ਅਤੇ ਬੈਂਕ-ਹਿਸਾਬ ਸਵਾਲਾਂ (ਕਿਹੜਾ ਮਨਜ਼ੂਰ ਕੀਤਾ ਗਿਆ, ਕਿਹੜੀ ਸੋਧ ਕੀਤੀ ਗਈ, ਕੀ ਭੇਜਿਆ ਗਿਆ) ਦਾ ਜਵਾਬ ਨਹੀਂ ਦੇ ਸਕਦੇ। ਬਾਈਨਰੀ ਫਾਈਲ ਨੂੰ ਅਮੂਟ ਰੱਖੋ ਅਤੇ ਨਵਾਂ ਵਰਜ਼ਨ ਜੋੜੋ।
ਸਟੇਟਸ ਦੀ ਗੁੰਝਲਦਾਰੀ ਨਾਜ਼ੁਕ ਬੱਗ ਪੈਦਾ ਕਰ ਸਕਦੀ ਹੈ। "OCR ਚੱਲ ਰਿਹਾ ਹੈ" ਅਤੇ "Needs review" ਇੱਕੋ ਗੱਲ ਨਹੀਂ ਹਨ। ਪ੍ਰੋਸੈਸਿੰਗ ਸਟੇਟਸ ਦੱਸਦੀ ਹੈ ਕਿ ਸਿਸਟਮ ਕੀ ਕਰ ਰਿਹਾ ਹੈ; ਬਿਜ਼ਨਸ ਸਟੇਟਸ ਦੱਸਦੀ ਹੈ ਕਿ ਮਨੁੱਖ ਨੂੰ ਅਗਲਾ ਕੀ ਕਰਨਾ ਹੈ। ਜਦੋਂ ਇਹ ਮਿਲ ਜਾਂਦੇ ਹਨ, ਦਸਤਾਵੇਜ਼ ਗਲਤ ਬਕੇਟ ਵਿੱਚ ਫਸ ਜਾਂਦੇ ਹਨ।
UI ਫ਼ੈਸਲੇ friction ਪੈਦਾ ਕਰ ਸਕਦੇ ਹਨ। ਜੇ ਤੁਸੀਂ ਸਕ੍ਰੀਨ ਨੂੰ ਪ੍ਰੀਵਿਊ ਜਨਰੇਸ਼ਨ ਹੋਣ ਤੱਕ ਬਲਾਕ ਕਰ ਦਿੰਦੇ ਹੋ, ਤਾਂ ਭਾਵੇਂ ਅਪਲੋਡ ਸਫਲ ਹੋ ਗਿਆ ਹੋਵੇ, ਲੋਕ ਐਪ ਨੂੰ ਧੀਮਾ ਮਹਿਸੂਸ ਕਰਨਗੇ। ਦਸਤਾਵੇਜ਼ ਨੂੰ ਤੁਰੰਤ ਦਿਖਾਓ ਇੱਕ placeholder ਨਾਲ, ਫਿਰ thumbnails ਵੇਖਣ ਯੋਗ ਹੋਣ 'ਤੇ ਉਹਨਾਂ ਨੂੰ ਬਦਲੋ।
ਅੰਤ ਵਿੱਚ, ਜਦੋਂ ਤੁਸੀਂ provenance ਬਿਨਾਂ ਮੁੱਲ ਸਟੋਰ ਕਰਦੇ ਹੋ ਤਾਂ ਮੈਟਾਡੇਟਾ ਭਰੋਸੇਯੋਗ ਨਹੀਂ ਰਹਿੰਦਾ। ਜੇ total OCR ਤੋਂ ਆਇਆ ਸੀ, ਤਾਂ ਦਿਖਾਓ। timestamps ਸੰਭਾਲੋ।
ਇੱਕ ਤੇਜ਼ ਗੁੱਟ-ਚੈੱਕ ਸੂਚੀ:
ਉਦਾਹਰਨ: ਇੱਕ ਰਸੀਦ ਐਪ ਵਿੱਚ, ਯੂਜ਼ਰ ਇੱਕ ਸਾਫ਼ ਫੋਟੋ ਦੁਬਾਰਾ ਅਪਲੋਡ ਕਰਦਾ ਹੈ। ਜੇ ਤੁਸੀਂ ਇਹਨੂੰ ਵਰਜ਼ਨ ਕਰਦੇ ਹੋ, ਤਾਂ ਪੁਰਾਣੀ ਇਮੇਜ ਰੱਖੋ, OCR ਨੂੰ ਮੁੜ ਚਲਾਓ, ਅਤੇ Needs review ਤੱਕ ਰੱਖੋ ਜਦ ਤੱਕ ਮਨੁੱਖ ਰਕਮ ਦੀ ਪੁਸ਼ਟੀ ਨਾ ਕਰ ਦੇਵੇ।
Document-centric ਵਰਕਫਲੋ "ਹੋ ਗਿਆ" ਤਦੋਂ ਮਹਿਸੂਸ ਹੁੰਦੀ ਹੈ ਜਦੋਂ ਲੋਕ ਜੋ ਉਹ ਵੇਖਦے ਹਨ ਉਸ 'ਤੇ ਭਰੋਸਾ ਕਰ ਸਕਣ ਅਤੇ ਗੜਬੜ ਹੋਣ 'ਤੇ ਵਾਪਸੀ ਕੀਤੀ ਜਾ ਸਕੇ। ਲਾਂਚ ਤੋਂ ਪਹਿਲਾਂ ਗੰਦੇ, ਅਸਲ ਦਸਤਾਵੇਜ਼ (ਧੁੰਦਲੇ ਰਸੀਦਾਂ, ਘੁੰਮਾਏ ਹੋਏ PDFs, ਦੁਹਰਾਏ ਅਪਲੋਡ) ਨਾਲ ਟੈਸਟ ਕਰੋ।
ਪੰਜ ਚੈੱਕ ਜੋ ਜਿਆਦਾਤਰ ਹੈਰਾਨੀ ਫੜ ਲੈਂਦੇ ਹਨ:
ਇੱਕ ਤੇਜ਼ ਹਕੀਕਤ ਟੈਸਟ: ਕਿਸੇ ਨੂੰ ਤਿੰਨ ਮਿਲਦੇ-ਜੁਲਦੇ ਰਸੀਦਾਂ ਦੀ ਸਮੀਖਿਆ ਕਰਨ ਲਈ ਕਹੋ ਅਤੇ ਇਕ ਨੂੰ ਜਾਨਬੂਝ ਕੇ ਗਲਤ ਸੋਧ ਦਿਓ। ਜੇ ਉਹ ਮੌਜੂਦਾ ਵਰਜ਼ਨ ਨੂੰ ਪਛਾਣ ਸਕਦੇ, status ਸਮਝ ਸਕਦੇ, ਅਤੇ ਇੱਕ ਮਿੰਟ ਤੋਂ ਘੱਟ ਵਿੱਚ ਗਲਤੀ ਠੀਕ ਕਰ ਸਕਦੇ ਹਨ, ਤਾਂ ਤੁਸੀਂ ਨਜ਼ਦੀਕ ਹੋ।
ਮਾਸਿਕ ਰਸੀਦ ਰੀਇੰਬਰਸਮੈਂਟ document-centric ਕੰਮ ਦਾ ਸਾਫ਼ ਉਦਾਹਰਨ ਹੈ। ਇੱਕ ਕਰਮਚਾਰੀ ਰਸੀਦ ਅਪਲੋਡ ਕਰਦਾ ਹੈ, ਫਿਰ ਦੋ ਸਮੀਖਿਆਕਾਰ — ਪਹਿਲਾਂ ਇੱਕ ਮੈਨੇਜਰ, ਫਿਰ ਫਾਇਨੈਂਸ — ਉਹਨਾਂ ਨੂੰ ਚੈੱਕ ਕਰਦੇ ਹਨ। ਰਸੀद ਹੀ ਪ੍ਰੋਡਕਟ ਹੈ, ਇਸ ਲਈ ਤੁਹਾਡਾ ਐਪ ਵਰਜ਼ਨਿੰਗ, ਪ੍ਰੀਵਿਊਜ਼, ਮੈਟਾਡੇਟਾ, ਅਤੇ ਸਪਸ਼ਟ ਸਟੇਟਸ 'ਤੇ ਨਿਰਭਰ ਕਰਦਾ ਹੈ।
Jamie ਇੱਕ ਟੈਕਸੀ ਰਸੀਦ ਦੀ ਫੋਟੋ ਅਪਲੋਡ ਕਰਦਾ ਹੈ। ਤੁਹਾਡੀ ਪ੍ਰਣਾਲੀ Document #1842 ਬਣਾਉਂਦੀ ਹੈ ਜਿਸ ਨਾਲ Version v1 (ਮੂਲ ਫਾਈਲ), ਇੱਕ thumbnail ਅਤੇ preview, ਅਤੇ metadata ਜਿਵੇਂ merchant, date, currency, total, ਅਤੇ OCR confidence ਸਕੋਰ ਜੁੜਦੇ ਹਨ। ਦਸਤਾਵੇਜ਼ Imported 'ਚ ਸ਼ੁਰੂ ਹੁੰਦਾ ਹੈ, ਫਿਰ preview ਅਤੇ extraction ਤਿਆਰ ਹੋਣ 'ਤੇ Needs review 'ਤੇ ਚੱਲ ਜਾਂਦਾ ਹੈ।
ਬਾਅਦ ਵਿੱਚ, Jamie ਗਲਤੀ ਨਾਲ ਉਹੀ ਰਸੀਦ ਦੁਬਾਰਾ ਅਪਲੋਡ ਕਰ ਦਿੰਦਾ ਹੈ। ਇੱਕ duplicate ਚੈਕ (ਫਾਈਲ hash + ਮਿਲਦੇ-जੁਲਦੇ merchant/date/total) ਇਕ ਸਧਾਰਨ ਚੋਣ ਉਤਪੰਨ ਕਰ ਸਕਦਾ ਹੈ: “ਇਹ #1842 ਦਾ duplicate ਲੱਗਦਾ ਹੈ। ਫਿਰ ਵੀ ਜੋੜਿਆ ਜਾਵੇ ਜਾਂ discard ਕੀਤਾ ਜਾਵੇ।” ਜੇ ਉਹ ਜੋੜ ਦਿੰਦੇ ਹਨ, ਤਾਂ ਉਸਨੂੰ ਇੱਕ ਹੋਰ File ਵਜੋਂ ਉਸੇ Document ਨਾਲ ਜੋੜੋ ਤਾਂ ਕਿ ਇਕੋ ਰਿਵਿਊ ਥ੍ਰੈਡ ਅਤੇ ਇਕੋ ਸਟੇਟਸ ਰਹਿਣ।
ਸਮੀਖਿਆ ਦੌਰਾਨ, ਮੈਨੇਜਰ ਪ੍ਰੀਵਿਊ, ਮੁੱਖ ਫੀਲਡ ਅਤੇ ਚੇਤਾਵਨੀਆਂ ਵੇਖਦਾ ਹੈ। OCR ਨੇ total $18.00 ਪੜ੍ਹਿਆ ਪਰ ਚਿੱਤਰ 'ਤੇ ਸaf ਸਪਸ਼ਟ $13.00 ਦਿਖਾਈ ਦਿੰਦਾ ਹੈ। Jamie total ਸਹੀ ਕਰਦਾ ਹੈ। ਇਤਿਾਹਾਸ ਨੂੰ overwrite ਨਾ ਕਰੋ। Version v2 ਬਣਾਓ, v1 ਅਛੂਤਾ ਰੱਖੋ, ਅਤੇ "Total corrected by Jamie" ਲਾਗ ਕਰੋ।
ਜੇ ਤੁਸੀਂ ਇਸ ਤਰ੍ਹਾਂ ਦਾ ਵਰਕਫਲੋ ਤੇਜ਼ੀ ਨਾਲ ਬਣਾਉਣਾ ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ Koder.ai (koder.ai) ਤੁਹਾਨੂੰ ਚੈਟ-ਅਧਾਰਤ ਪਲੈਨ ਤੋਂ ਪਹਿਲੀ ਵਰਕਿੰਗ ਵਰਜਨ ਜਨਰੇਟ ਕਰਵਾਉਣ ਵਿੱਚ ਮਦਦ ਕਰ ਸਕਦਾ ਹੈ, ਪਰ ਇੱਕੋ ਨਿਯਮ ਲਾਗੂ ਹੁੰਦਾ ਹੈ: ਪਹਿਲਾਂ ਆਬਜੈਕਟ ਅਤੇ ਸਟੇਟ ਡਿਫ਼ਾਈਨ ਕਰੋ, ਫਿਰ ਸਕ੍ਰੀਨਾਂ ਬਣਨ ਦਿਓ।
ਪ੍ਰਯੋਗਸ਼ੀਲ ਅਗਲੇ ਕਦਮ:
ਇਕ document-centric ਐਪ ਦਸਤਾਵੇਜ਼ ਨੂੰ ਮੁੱਖ ਚੀਜ਼ ਵਜੋਂ ਦੇਖਦੀ ਹੈ ਜਿਸ 'ਤੇ ਉਪਭੋਗਤਾ ਕੰਮ ਕਰਦੇ ਹਨ — ਨਾ ਕਿ ਉਹ ਸਿਰਫ਼ ਜੁੜੀ ਹੋਈ ਫਾਈਲ ਹੋਵੇ। ਲੋਕਾਂ ਨੂੰ ਦਸਤਾਵੇਜ਼ ਖੋਲ੍ਹ ਕੇ ਇਸ ਤੇ ਭਰੋਸਾ ਕਰਨ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ, ਸਮਝਣਾ ਹੁੰਦਾ ਹੈ ਕਿ ਕੀ ਬਦਲਾ, ਅਤੇ ਅਗਲਾ ਕਦਮ ਉਸੀ ਦਸਤਾਵੇਜ਼ ਦੇ ਆਧਾਰ ਤੇ ਲੈਣਾ ਹੁੰਦਾ ਹੈ।
ਇਨਬਾਕਸ/ਲਿਸਟ, ਇੱਕ ਡਾਕੂਮੈਂਟ ਡੀਟੇਲ ਵਿਊ ਜਿੱਥੇ ਤੇਜ਼ ਪ੍ਰੀਵਿਊ ਹੋਵੇ, ਇੱਕ ਸਧਾਰਨ ਰਿਵਿਊ ਏਕਸ਼ਨ ਖੇਤਰ (approve/reject/request changes), ਅਤੇ ਐਕਸਪੋਰਟ ਜਾਂ ਸ਼ੇਅਰ ਕਰਨ ਦਾ ਤਰੀਕਾ — ਇਹ ਸਾਰੇ ਸ਼ੁਰੂਆਤੀ ਸਕ੍ਰੀਨ ਹਨ। ਇਹ ਚਾਰ ਸਕ੍ਰੀਨਾਂ ਲੱਭੋ, ਖੋਲ੍ਹੋ, ਫੈਸਲਾ ਕਰੋ ਅਤੇ ਹਵਾਲਾ ਦੇਣ ਦੇ ਆਮ ਲੂਪ ਨੂੰ ਕਵਰ ਕਰਦੀਆਂ ਹਨ।
ਇੱਕ ਸਥਿਰ Document ਰਿਕਾਰਡ ਰੱਖੋ ਜੋ ਕਦੇ ਨਾ ਬਦਲੇ, ਅਤੇ ਅਸਲ ਬਾਈਟਾਂ ਨੂੰ ਅਲੱਗ File ਆਬਜੈਕਟਾਂ ਵਜੋਂ ਸਟੋਰ ਕਰੋ। ਫਿਰ Version ਜੋੜੋ ਜੋ ਕਿਸੇ ਨਿਰਧਾਰਤ ਫਾਈਲ ਨਾਲ ਡਾਕੂਮੈਂਟ ਨੂੰ ਜੋੜਦਾ ਹੈ। ਇਹ ਵੱਖ-ਵੱਖੀ ਕਰਨ ਨਾਲ ਫਾਈਲ ਦੁਬਾਰਾ ਅੱਪਲੋਡ ਹੋਣ 'ਤੇ ਵੀ ਟਿੱਪਣੀਆਂ, ਅਸਾਈਨਮੈਂਟ ਅਤੇ ਇਤਿਹਾਸ ਠੀਕ ਰਹਿੰਦੇ ਹਨ।
ਹਰ ਅਹੰਕਾਰਪੂਰਨ ਬਦਲਾਅ ਲਈ ਨਵਾਂ ਵਰਜ਼ਨ ਬਣਾਓ, ਸਥਾਨਕ (in-place) ਸੋਧ ਨਾ ਕਰੋ। ਦਸਤਾਵੇਜ਼ ਤੇ ਤੇਜ਼ ਪੜ੍ਹਨ ਲਈ current_version_id ਰੱਖੋ, ਅਤੇ ਆਡਿਟ ਅਤੇ ਰੋਲਬੈਕ ਲਈ ਪੁਰਾਣੇ ਵਰਜ਼ਨਾਂ ਦੀ ਟਾਈਮਲਾਈਨ ਸੰਭਾਲੋ।
ਅਸਲ ਫਾਈਲ ਸੇਵ ਕਰਨ ਤੋਂ ਬਾਅਦ ਪ੍ਰੀਵਿਊਜ਼ ਨੂੰ ਅਸਿੰਕ੍ਰੋਨਸ ਤਰੀਕੇ ਨਾਲ ਜਨਰੇਟ ਕਰੋ ਤਾਂ ਕਿ ਅਪਲੋਡ ਤਤਕਾਲ ਮਹਿਸੂਸ ਹੋਵੇ। pending/ready/failed ਵਰਗੇ ਪ੍ਰੀਵਿਊ ਰਾਜਾਂ ਨੂੰ ਟਰੈਕ ਕਰੋ ਤਾਂ UI ਸਪੱਸ਼ਟ ਹੋ ਸਕੇ, ਅਤੇ ਵੱਖ-ਵੱਖ ਆਕਾਰ ਸਟੋਰ ਕਰੋ ਤਾਂ ਕਿ ਲਿਸਟ ਅਤੇ ਡੀਟੇਲ ਦੋਹਾਂ ਤੇਜ਼ ਰਹਿਣ।
ਮੈਟਾ ਡੇਟਾ ਨੂੰ ਤਿੰਨ ਬਕੱਟਾਂ ਵਿੱਚ ਰੱਖੋ: ਸਿਸਟਮ (ਫਾਈਲ ਨਾਮ, ਆਕਾਰ), ਨਿਕਾਲਿਆ ਗਿਆ (OCR ਫੀਲਡ ਅਤੇ confidence) ਅਤੇ ਯੂਜ਼ਰ-ਦਰਜ ਸੋਧਾਂ। provenance ਰੱਖੋ ਤਾਂ ਪਤਾ ਲੱਗੇ ਕਿ ਕਿਸ ਨੇ ਜਾਂ ਕਿਸ ਤਰੀਕੇ ਨਾਲ ਕੋਈ ਮੁੱਲ ਦਿੱਤਾ ਸੀ — ਮਨੁੱਖ ਜਾਂ OCR।
ਸਧਾਰਨ ਬਿਜ਼ਨਸ ਸਟੇਟਸ ਰੱਖੋ ਜੋ ਇਨਸਾਨ ਨੂੰ ਪੁੱਛਦਾ ਹੈ ਕਿ ਅਗਲਾ ਕਦਮ ਕੀ ਹੈ: Imported, Needs review, Approved, Rejected, Archived. ਪ੍ਰੋਸੈਸਿੰਗ (OCR/preview) ਨੂੰ ਵੱਖਰਾ ਰੱਖੋ ਤਾਂ ਕਿ ਦਸਤਾਵੇਜ਼ ਗਲਤ ਸਟੇਟ ਵਿੱਚ ਨਾ ਟਿਕੇ ਰਹਿਣ।
ਅਪਲੋਡ 'ਤੇ immutable ਫਾਈਲ checksums ਸਟੋਰ ਕਰੋ ਅਤੇ ਉਹਨਾਂ ਨੂੰ ਤੁਲਨਾ ਕਰੋ; ਜਦੋਂ ਸੰਭਾਵਿਤ duplicate ਮਿਲੇ ਤਾਂ ਉਪਭੋਗਤਾ ਨੂੰ ਵੱਕਰੀ ਚੋਣ ਦਿਓ: ਮੌਜੂਦਾ ਡਾਕੂਮੈਂਟ ਨਾਲ ਜੋੜੋ ਜਾਂ discard ਕਰੋ। ਇਸ ਤਰ੍ਹਾਂ ਰਿਵਿਊ ਇਤਿਹਾਸ ਤੱਕ ਇਕੱਠਾ ਰਹਿੰਦਾ ਹੈ।
ਸਥਿਰ ਸਟੇਟਸ ਇਤਿਹਾਸ ਲਿਖੋ (from_status, to_status, changed_at, changed_by, reason) ਅਤੇ ਵਰਜ਼ਨ ਟਾਈਮਲਾਈਨ ਰੱਖੋ। rollback ਇੱਕ pointer ਬਦਲਣਾ ਹੋਵੇ, delete ਨਾ ਕਰੋ, ਤਾ ਕਿ ਆਡਿਟ ਟ੍ਰੇਲ ਸੇਫ਼ ਰਹੇ।
ਸਭ ਤੋਂ ਪਹਿਲਾਂ ਵਰਤੋਂਕਾਰ/ਸcreeਨ ਦੀਆਂ ਪਰਿਭਾਸ਼ਾਵਾਂ ਨੂੰ ਸਪਸ਼ਟ ਕਰੋ: Document/Version/File, preview ਅਤੇ extraction ਰਾਜ, ਅਤੇ ਸਟੇਟ ਨਿਯਮ — ਇਸ ਤਰ੍ਹਾਂ ਕੋਈ generated ਸੈਂਪਲ ਮਾਡਲ ਬਾਅਦ ਵਿੱਚ ਗੰਦੂ ਨਹੀਂ ਬਣੇਗਾ।