31 ਅਗ 2025·7 ਮਿੰਟ
expand/contract ਪੈਟਰਨ ਨਾਲ ਬਿਨਾਂ ਡਾਊਨਟਾਈਮ ਵਾਲੇ ਸਕੀਮਾ-ਬਦਲਾਅ
expand/contract ਪੈਟਰਨ ਸਿੱਖੋ: ਨਵੀਂ ਕਾਲਮਾਂ ਨਿਰਾਪਦ ਤਰੀਕੇ ਨਾਲ ਜੋੜੋ, ਬੈਚਾਂ ਵਿੱਚ backfill ਕਰੋ, ਪੈਚ-ਅਨੁਕੂਲ ਕੋਡ ਡਿਪਲੌਇ ਕਰੋ, ਫਿਰ ਪੁਰਾਣੇ ਰਸਤੇ ਹਟਾਓ।
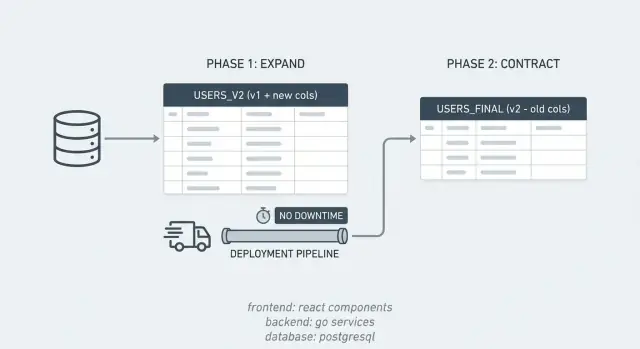
expand/contract ਪੈਟਰਨ ਸਿੱਖੋ: ਨਵੀਂ ਕਾਲਮਾਂ ਨਿਰਾਪਦ ਤਰੀਕੇ ਨਾਲ ਜੋੜੋ, ਬੈਚਾਂ ਵਿੱਚ backfill ਕਰੋ, ਪੈਚ-ਅਨੁਕੂਲ ਕੋਡ ਡਿਪਲੌਇ ਕਰੋ, ਫਿਰ ਪੁਰਾਣੇ ਰਸਤੇ ਹਟਾਓ।
ਡਾਟਾਬੇਸ-ਬਦਲਾਅ ਤੋਂ ਹੋਣ ਵਾਲਾ ਡਾਊਨਟਾਈਮ ਹਮੇਸ਼ਾਂ ਸਾਫ਼ ਤੇ ਜ਼ਾਹਿਰ ਨਹੀਂ ਹੁੰਦਾ। ਯੂਜ਼ਰਾਂ ਲਈ ਇਹ ਇੱਕ ਐਸੀ ਪੇਜ ਹੋ ਸਕਦੀ ਹੈ ਜੋ ਲੰਮੇ ਸਮੇਂ ਤੱਕ ਲੋਡ ਹੋ ਰਹੀ ਹੋਵੇ, ਇੱਕ ਚੈਕਆਊਟ ਫੇਲ ਹੋ ਜਾਵੇ, ਜਾਂ ਐਪ ਅਚਾਨਕ "ਕੁਝ ਗਲਤ ਹੋ ਗਿਆ" ਦਿਖਾਏ। ਟੀਮਾਂ ਲਈ ਇਹ alerts, ਵੱਧ ਰਹੀ error rates, ਅਤੇ ਫੇਲ੍ਹ ਹੋਈਆਂ ਰਾਈਟਸ ਦਾ ਬੈਕਲੌਗ ਵਗੈਰਾ ਵਜੋਂ ਨज़र ਆਉਂਦਾ ਹੈ।
ਸਕੀਮਾ-ਬਦਲਾਅ ਖਤਰਨਾਕ ਹੁੰਦੇ ਹਨ ਕਿਉਂਕਿ ਡਾਟਾਬੇਸ ਤੁਹਾਡੇ ਐਪ ਦੇ ਹਰ ਚੱਲ ਰਹੇ ਵਰਜ਼ਨ ਵੱਲੋਂ ਸਾਂਝਾ ਕੀਤਾ ਜਾਂਦਾ ਹੈ। ਰਿਲੀਜ਼ ਦੌਰਾਨ ਅਕਸਰ ਪੁਰਾਣੀ ਅਤੇ ਨਵੀਂ ਕੋਡ ਇਕੱਠੇ ਹੀ ਚੱਲ ਰਹੀ ਹੁੰਦੀ ਹੈ (rolling deploys, ਬਹੁਤ ਸਾਰੇ ਇੰਸਟੈਂਸ, background jobs)। ਇੱਕ ਮਾਈਗ੍ਰੇਸ਼ਨ ਜੋ ਦਿਖਣ ਵਿੱਚ ਸਹੀ ਲੱਗਦੀ ਹੈ, ਫਿਰ ਵੀ ਕਿਸੇ ਇਕ ਵਰਜ਼ਨ ਨੂੰ ਤੋੜ ਸਕਦੀ ਹੈ।
ਆਮ ਫੇਲ ਹੋਣ ਦੇ ਤਰੀਕੇ ਸ਼ਾਮਲ ਹਨ:
ਭਾਵੇਂ ਕੋਡ ਠੀਕ ਹੋਵੇ, ਰਿਲੀਜ਼ timing ਅਤੇ ਵਰਜ਼ਨਾਂ ਦਰਮਿਆਨ compatibility ਦੀ ਸਮੱਸਿਆ ਕਾਰਨ ਰੁਕ ਜਾਂਦੇ ਹਨ।
ਬਿਨਾਂ-ਡਾਊਨਟਾਈਮ ਸਕੀਮਾ-ਬਦਲਾਅ ਦਾ ਮੁੱਖ ਨਿਯਮ ਇਹ ਹੈ: ਹਰ ਵਿਚਕਾਰਲਾ ਸਟੇਟ ਪੁਰਾਣੀ ਅਤੇ ਨਵੀਂ ਕੋਡ ਲਈ ਸੁਰੱਖਿਅਤ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ। ਤੁਸੀਂ ਡਾਟਾਬੇਸ ਨੂੰ ਇਸ ਤਰ੍ਹਾਂ ਬਦਲਦੇ ਹੋ ਕਿ ਮੌਜੂਦਾ reads ਅਤੇ writes ਨਾ ਟੁੱਟਣ, ਐਸਾ ਕੋਡ ਸ਼ਿਪ ਕਰੋ ਜੋ ਦੋਹਾਂ ਸ਼ੇਪਾਂ ਨੂੰ ਸੰਭਾਲ ਸਕੇ, ਅਤੇ ਸਿਰਫ਼ ਉਸ وقت ਪੁਰਾਣੇ ਰਸਤੇ ਹਟਾਓ ਜਦੋਂ ਕਿਸੇ ਨੂੰ ਉਨ੍ਹਾਂ ਦੀ ਲੋੜ ਨਾ ਰਹੇ।
ਜਦੋਂ ਤੁਹਾਡੇ ਕੋਲ ਅਸਲ ਟਰੈਫਿਕ, ਕਾਫੀ ਸਖ਼ਤ SLAs, ਜਾਂ ਬਹੁਤ ਸਾਰੇ app instances ਅਤੇ workers ਹੁੰਦੇ ਹਨ ਤਾਂ ਇਹ ਵਾਧੂ ਕਦਮ ਕਰਨਾ ਲਾਭਦਾਇਕ ਹੁੰਦਾ ਹੈ। ਇਕ ਛੋਟੀ ਅੰਦਰੂਨੀ ਟੂਲ ਲਈ ਜਿਸਦਾ ਡਾਟਾਬੇਸ ਸ਼ਾਂਤ ਹੈ, ਇੱਕ ਨਿਯਤ maintenance window ਸਧਾਰਨ ਹੋ ਸਕਦਾ ਹੈ।
ਜ਼ਿਆਦਾਤਰ ਡਾਟਾਬੇਸ-ਕਾਮ ਤੋਂ ਹੋਣ ਵਾਲੀਆਂ ਘਟਨਾਵਾਂ ਇਸ ਕਰਕੇ ਹੁੰਦੀਆਂ ਹਨ ਕਿ ਐਪ ਸੋਚਦੀ ਹੈ ਕਿ ਡਾਟਾਬੇਸ ਤੁਰੰਤ ਬਦਲ ਜਾਵੇਗਾ, ਪਰ ਡਾਟਾਬੇਸ ਬਦਲਾਉਣ ਵਿੱਚ ਸਮਾਂ ਲਗਦਾ ਹੈ। expand/contract ਪੈਟਰਨ ਇਸ ਨੂੰ ਛੋਟੇ, ਸੁਰੱਖਿਅਤ ਕਦਮਾਂ ਵਿੱਚ ਵੰਡ ਕੇ ਇਸ ਤੋਂ ਬਚਦਾ ਹੈ।
ਇਕ ਛੋਟੇ ਸਮੇਂ ਲਈ ਤੁਹਾਡੀ ਸਿਸਟਮ ਦੋ "dialects" ਇਕੱਠੇ ਸਮਰਥਨ ਕਰਦੀ ਹੈ। ਤੁਸੀਂ ਪਹਿਲਾਂ ਨਵੀਂ ਸਟ੍ਰਕਚਰ ਲਿਆਉਂਦੇ ਹੋ, ਪੁਰਾਣੀ ਨੂੰ ਚਲਦਾ ਰੱਖਦੇ ਹੋ, ਡਾਟਾ gradually ਲਿਜਾ ਰਹੇ ਹੋ, ਫਿਰ ਸਾਫ਼ ਕਰਦੇ ਹੋ।
ਪੈਟਰਨ ਸਰਲ ਹੈ:
ਇਹ rolling deploys ਨਾਲ ਚੰਗਾ ਕੰਮ ਕਰਦਾ ਹੈ। ਜਦੋਂ ਤੁਸੀਂ 10 ਸਰਵਰ ਇੱਕ-ਇੱਕ ਕਰਕੇ ਅਪਡੇਟ ਕਰਦੇ ਹੋ, ਤਾਂ ਤੁਸੀਂ ਥੋੜ੍ਹੇ ਸਮੇਂ ਲਈ ਪੁਰਾਣੇ ਅਤੇ ਨਵੇਂ ਵਰਜ਼ਨ ਇਕੱਠੇ ਚਲਾ ਰਹੇ ਹੋਂਗੇ। expand/contract ਦੌਰਾਨ ਦੋਹਾਂ ਨੂੰ ਇੱਕੋ ਹੀ ਡਾਟਾਬੇਸ ਨਾਲ ਦਰਮਿਆਨੀ ਸਟੇਟ ਵਿੱਚ ਸੁਰੱਖਿਅਤ ਰੱਖਦਾ ਹੈ।
ਇਹ rollbacks ਨੂੰ ਵੀ ਘੱਟ ਡਰਾਉਣਾ ਬਣਾਉਂਦਾ ਹੈ। ਜੇ ਨਵਾਂ ਰਿਲੀਜ਼ ਬੱਗ ਨਾਲ ਆਵੇ, ਤਾਂ ਤੁਸੀਂ ਐਪ ਨੂੰ rollback ਕਰ ਸਕਦੇ ਹੋ ਬਿਨਾਂ ਡਾਟਾਬੇਸ rollback ਕੀਤੇ, ਕਿਉਂਕਿ expand ਵਿੰਡੋ ਦੌਰਾਨ ਪੁਰਾਣੀਆਂ ਸਟ੍ਰਕਚਰਾਂ ਮੌਜੂਦ ਰਹਿੰਦੀਆਂ ਹਨ।
ਉਦਾਹਰਣ: ਤੁਸੀਂ PostgreSQL ਵਿੱਚ ਇੱਕ full_name ਕਾਲਮ ਨੂੰ first_name ਅਤੇ last_name ਵਿੱਚ ਵੰਡਣਾ ਚਾਹੁੰਦੇ ਹੋ। ਪਹਿਲਾਂ ਨਵੀਂ ਕਾਲਮਾਂ ਜੋੜੋ (expand), ਐਸਾ ਕੋਡ ਸ਼ਿਪ ਕਰੋ ਜੋ ਦੋਹਾਂ ਸਟਾਈਲਾਂ ਨੂੰ ਲਿਖ ਅਤੇ ਪੜ੍ਹ ਸਕੇ, ਪੁਰਾਣੇ ਰਿਕਾਰਡਾਂ ਨੂੰ backfill ਕਰੋ, ਫਿਰ full_name ਨੂੰ drop ਕਰੋ ਜਦੋਂ ਤੁਸੀਂ ਨिश्चਿੰਤ ਹੋ ਜਾਓ ਕਿ ਕੋਈ ਵੀ ਉਹਦੀ ਵਰਤੋਂ ਨਹੀਂ ਕਰ ਰਿਹਾ।
Expand ਫੇਜ਼ ਇਸ ਬਾਰੇ ਹੁੰਦਾ ਹੈ ਕਿ ਨਵੀਆੰ ਚੀਜ਼ਾਂ ਜੋੜੀਆਂ ਜਾਣ, ਨਾ ਕਿ ਪੁਰਾਣੀਆਂ ਹਟਾਈਆਂ ਜਾਣ।
ਆਮ ਪਹਿਲਾ ਕਦਮ ਨਵੀਂ ਕਾਲਮ ਜੋੜਨਾ ਹੁੰਦਾ ਹੈ। PostgreSQL ਵਿੱਚ ਆਮ ਤੌਰ 'ਤੇ ਇਹ safest ਹੁੰਦਾ ਹੈ ਕਿ ਕਾਲਮ nullable ਹੋਵੇ ਅਤੇ ਕੋਈ default ਨਾ ਰੱਖਿਆ ਜਾਵੇ। NOT NULL ਨਾਲ default ਜੋੜਨਾ ਟੇਬਲ rewrite ਜਾਂ ਭਾਰੀ locks ਕਰ ਸਕਦਾ ਹੈ, ਇਸ ਲਈ ਇੱਕ ਸੁਰੱਖਿਅਤ ਕ੍ਰਮ ਹੈ: nullable ਜੋੜੋ, tolerant ਕੋਡ ਡਿਪਲੌਇ ਕਰੋ, backfill ਕਰੋ, ਫਿਰ ਬਾਅਦ ਵਿੱਚ NOT NULL ਲਗਾਓ।
ਇੰਡੈਕਸਾਂ ਨੂੰ ਵੀ ਧਿਆਨ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ। ਆਮ ਇੰਡੈਕਸ ਬਣਾਉਣਾ ਲਿਖਤਾਂ ਨੂੰ ਉਮੀਦ ਤੋਂ ਵੱਧ ਸਮੇਂ ਲਈ بلاک ਕਰ ਸਕਦਾ ਹੈ। ਜਦੋਂ ਸਕੇ, concurrent index creation ਵਰਤੋਂ ਤਾਂ ਕਿ reads ਅਤੇ writes ਚਲਦੇ ਰਹਿਣ। ਇਹ ਲੰਬਾ ਲੈਂਦਾ ਹੈ, ਪਰ release-ਰੋਕਣ ਵਾਲੇ lock ਤੋਂ ਬਚਾਉਂਦਾ ਹੈ।
Expand ਦਾ ਮਤਲਬ ਨਵੀਆਂ ਟੇਬਲਾਂ ਜੋੜਨਾ ਵੀ ਹੋ ਸਕਦਾ ਹੈ। ਜੇ ਤੁਸੀਂ ਇੱਕ single column ਤੋਂ many-to-many ਰਿਸ਼ਤਾ ਵੱਲ ਜਾ ਰਹੇ ਹੋ ਤਾਂ join table ਜੋੜੋ ਅਤੇ ਪੁਰਾਣਾ ਕਾਲਮ ਜਗ੍ਹਾ ਤੇ ਰੱਖੋ। ਪੁਰਾਣਾ ਰਸਤਾ ਚਲਦਾ ਰਹੇਗਾ ਅਤੇ ਨਵਾਂ ਰਚਨਾ ਡਾਟਾ ਇਕੱਠਾ ਕਰਨਾ ਸ਼ੁਰੂ ਕਰੇਗੀ।
ਅਮਲ ਵਿੱਚ, expand ਅਕਸਰ ਸ਼ਾਮਲ ਹੁੰਦਾ ਹੈ:
Expand ਤੋਂ ਬਾਅਦ, ਪੁਰਾਣੇ ਅਤੇ ਨਵੇਂ ਐਪ ਵਰਜ਼ਨ ਇਕੱਠੇ ਚੱਲ ਸਕਣੇ ਚਾਹੀਦੇ ਹਨ ਬਿਨਾਂ ਅਚਾਨਕ ਸਮੱਸਿਆਵਾਂ ਦੇ।
ਜਿਆਦਾਤਰ ਰਿਲੀਜ਼ ਦੀਆਂ ਸਮੱਸਿਆਵਾਂ ਮੱਧ ਵਿੱਚ ਹੁੰਦੀਆਂ ਹਨ: ਕੁਝ ਸਰਵਰ ਨਵਾਂ ਕੋਡ ਚਲਾ ਰਹੇ ਹੁੰਦੇ ਹਨ, ਹੋਰ ਪੁਰਾਣਾ, ਤੇ ਡਾਟਾਬੇਸ ਪਹਿਲਾਂ ਹੀ ਬਦਲ ਰਿਹਾ ਹੁੰਦਾ ਹੈ। ਤੁਹਾਡਾ ਲਕਸ਼ ਸਿੱਧਾ ਹੈ: ਰੋਲਆਊਟ ਵਿੱਚ ਕੋਈ ਵੀ ਵਰਜ਼ਨ ਦੋਹਾਂ—ਪੁਰਾਣੇ ਅਤੇ expanded—ਸਕੀਮਾ ਨਾਲ ਕੰਮ ਕਰ ਸਕੇ।
ਆਮ ਤਰੀਕਾ dual-write ਹੈ। ਜੇ ਤੁਸੀਂ ਨਵੀਂ ਕਾਲਮ ਜੋੜਦੇ ਹੋ, ਨਵੀਂ ਐਪ ਦੋਨਾਂ ਕਾਲਮਾਂ ਵਿੱਚ ਲਿਖਦੀ ਹੈ। ਪੁਰਾਣੇ ਐਪ ਵਰਜ਼ਨ ਸਿਰਫ ਪੁਰਾਣੇ ਵਿੱਚ ਹੀ ਲਿਖਦੇ ਰਹਿੰਦੇ ਹਨ, ਜੋ ਠੀਕ ਹੈ ਕਿਉਂਕਿ ਉਹ ਕਾਲਮ ਮੌਜੂਦ ਹੈ। ਪਹਿਲਾਂ ਨਵੀਂ ਕਾਲਮ optional ਰੱਖੋ, ਅਤੇ ਸਖ਼ਤ constraints ਨੂੰ ਦੇਰ ਨਾਲ ਲਗਾਓ ਜਦੋਂ ਤੱਕ ਸਾਰੇ writers ਅਪਗਰੇਡ ਨਾ ਹੋ ਜਾਣ।
ਪੜ੍ਹਾਈ ਆਮ ਤੌਰ 'ਤੇ ਲਿਖਾਈ ਦੀ ਤੁਲਨਾ ਵਿੱਚ ਹੌਲੇ ਸਵਿੱਚ ਹੁੰਦੀ ਹੈ। ਇਕ ਸਮੇਂ ਲਈ ਪੁਰਾਣੀ ਕਾਲਮ 'ਤੇ ਪੜ੍ਹਾਈ ਰਹੇ (ਜੋ ਪੂਰੀ ਤਰ੍ਹਾਂ ਭਰੀ ਹੋਈ ਹੋਵੇ)। backfill ਅਤੇ ਵੈਰੀਫਿਕੇਸ਼ਨ ਤੋਂ ਬਾਅਦ, ਪੜ੍ਹਾਈ ਨੂੰ ਨਵੀਂ ਕਾਲਮ ਨੂੰ ਪ੍ਰਾਥਮਿਕਤਾ ਦਿਓ ਪਰ fallback ਰੱਖੋ ਜੇ ਨਵੀਂ ਮੁਕੰਮਲ ਨਹੀਂ।
ਆਪਣੇ API ਆਊਟਪੁੱਟ ਨੂੰ ਵੀ ਸਥਿਰ ਰੱਖੋ ਜਦੋਂ ਡਾਟਾਬੇਸ ਅਧੀਨ ਬਦਲ ਰਿਹਾ ਹੋਵੇ। ਭਾਵੇਂ ਤੁਸੀਂ ਅੰਦਰੂਨੀ ਤੌਰ 'ਤੇ ਨਵਾਂ ਫੀਲਡ ਜੋੜੋ, ਪਰ ਰਿਸਪਾਂਸ ਸ਼ੇਪਾਂ ਨੂੰ ਬਦਲਣ ਤੋਂ ਬਚੋ ਜਦ ਤੱਕ ਸਾਰੇ consumers ਤਿਆਰ ਨਾ ਹੋਣ (web, mobile, integrations)।
Rollback-friendly rollout ਇੱਕ ਆਮ ਰੂਪ ਵਿੱਚ ਅਜਿਹਾ ਹੁੰਦਾ ਹੈ:
ਮੁੱਖ ਵਿਚਾਰ ਇਹ ਹੈ ਕਿ ਪਹਿਲਾ irreversible ਕਦਮ ਪੁਰਾਣੇ ਸਟ੍ਰਕਚਰ ਨੂੰ drop ਕਰਨਾ ਹੈ, ਇਸ ਲਈ ਤੁਸੀਂ ਇਹ ਅੰਤ ਤੱਕ ਮੁਲਤਵੀ ਰੱਖਦੇ ਹੋ।
Backfilling ਉਹ ਥਾਂ ਹੈ ਜਿੱਥੇ ਬਹੁਤ ਸਾਰੇ "ਬਿਨਾਂ-ਡਾਊਨਟਾਈਮ" ਸਕੀਮਾ-ਬਦਲਾਅ ਗਲਤ ਹੋ ਜਾਂਦੇ ਹਨ। ਤੁਸੀਂ ਮੌਜੂਦਾ rows ਲਈ ਨਵੀਂ ਕਾਲਮ ਭਰਨਾ ਚਾਹੁੰਦੇ ਹੋ ਬਿਨਾਂ ਲੰਬੇ locks, ਸਲੋ ਕੁਇਰੀਆਂ, ਜਾਂ ਅਚਾਨਕ ਲੋਡ spikes ਦੇ।
Batching ਮਹੱਤਵਪੂਰਨ ਹੈ। ਐਸੇ batches ਲਛੋ ਜੋ ਛੇਤੀ ਖਤਮ ਹੋਣ (ਸੈਕਿੰਡਾਂ, ਮਿੰਟਾਂ ਨਹੀਂ)। ਜੇ ਹਰ batch ਛੋਟਾ ਹੈ ਤਾਂ ਤੁਸੀਂ ਜੌਬ ਨੂੰ ਰੋਕ ਸਕਦੇ ਹੋ, ਮੁੜ ਚਲਾ ਸਕਦੇ ਹੋ, ਅਤੇ ਬਿਨਾਂ ਰਿਲੀਜ਼ ਰੋਕਣ tune ਕਰ ਸਕਦੇ ਹੋ।
ਪ੍ਰਗਤੀ ਟਰੈਕ ਕਰਨ ਲਈ stable cursor ਵਰਤੋਂ। PostgreSQL ਵਿੱਚ ਇਹ ਆਮ ਤੌਰ 'ਤੇ primary key ਹੁੰਦੀ ਹੈ। rows ਨੂੰ order ਵਿੱਚ process ਕਰੋ ਅਤੇ ਆਖਰੀ id ਜੋ ਤੁਸੀਂ ਮੁਕੰਮਲ ਕੀਤਾ ਉਹ ਸਟੋਰ ਕਰੋ, ਜਾਂ id ranges ਵਿੱਚ ਕੰਮ ਕਰੋ। ਇਸ ਨਾਲ ਜੌਬ ਦੁਬਾਰਾ ਸ਼ੁਰੂ ਹੋਣ 'ਤੇ ਮਹਿੰਗੀਆਂ full-table scans ਤੋਂ ਬਚਿਆ ਜਾ ਸਕਦਾ ਹੈ।
ਇੱਥੇ ਇੱਕ ਸਧਾਰਣ ਪੈਟਰਨ ਹੈ:
UPDATE my_table
SET new_col = ...
WHERE new_col IS NULL
AND id > $last_id
ORDER BY id
LIMIT 1000;
ਅਪਡੇਟ ਨੂੰ conditional ਬਣਾਓ (ਉਦਾਹਰਨ ਵਜੋਂ, WHERE new_col IS NULL) ਤਾਂ ਕਿ ਜੌਬ idempotent ਹੋਵੇ। ਰੀਰਨਾਂ ਸਿਰਫ ਉਹੀ rows ਛੁਹਣ ਜੋ ਅਜੇ ਵੀ ਕੰਮ ਦੀ ਲੋੜ ਹਨ, ਜਿਸ ਨਾਲ ਫਜੂਲ ਲਿਖਤ ਘੱਟ ਹੁੰਦੀ ਹੈ।
ਨਵਾਂ ਡਾਟਾ backfill ਦੌਰਾਨ ਆ ਰਿਹਾ ਹੋਵੇ ਇਹ ਮੰਨ ਕੇ ਚਲੋ। ਆਮ ਕ੍ਰਮ ਇਹ ਹੈ:
ਇੱਕ ਵਧੀਆ backfill ਨਿਵੜਿਆ ਹੋਇਆ ਹੁੰਦਾ ਹੈ: ਸਥਿਰ, ਮਾਪਯੋਗ, ਅਤੇ ਢੰਗ ਨਾਲ ਰੋਕਣ ਯੋਗ ਜੇ DB ਗਰਮ ਹੋਵੇ।
ਸਭ ਤੋਂ ਖਤਰਨਾਕ ਮੋਹੜਾ ਨਵੀਂ ਕਾਲਮ ਜੋੜਣਾ ਨਹੀਂ, ਸਗੋਂ ਇਹ ਫੈਸਲਾ ਕਰਨਾ ਹੈ ਕਿ ਹੁਣ ਤੁਸੀਂ ਉਸ 'ਤੇ ਨਿਰਭਰ ਹੋ ਸਕਦੇ ਹੋ।
Contract ਵੱਲ ਜਾਣ ਤੋਂ ਪਹਿਲਾਂ ਦੋ ਗੱਲਾਂ ਸਾਬਤ ਕਰੋ: ਨਵਾਂ ਡਾਟਾ ਮੁਕੰਮਲ ਹੈ, ਅਤੇ ਪ੍ਰੋਡਕਸ਼ਨ ਨੇ ਉਸ ਨੂੰ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਪੜ੍ਹਿਆ ਹੈ।
ਸ਼ੁਰੂਆਤ ਕਰੋ completeness checks ਨਾਲ ਜੋ ਤੇਜ਼ ਅਤੇ ਦੁਹਰਾਏ ਜਾ ਸਕਣ:
ਜੇ ਤੁਸੀਂ dual-writing ਕਰ ਰਹੇ ਹੋ ਤਾਂ silent bugs ਪਕੜਨ ਲਈ ਇਕ consistency check ਜੋੜੋ। ਉਦਾਹਰਨ ਵਜੋਂ, ਘੰਟਾਵਾਰ ਇੱਕ query ਚਲਾਓ ਜੋ ਉਹ rows ਲੱਭੇ ਜਿਨ੍ਹਾਂ old_value <> new_value ਹਨ ਅਤੇ alert ਕਰੋ ਜੇ ਇਹ ਜ਼ੀਰੋ ਨਾ ਹੋਵੇ। ਇਹ ਆਮ ਤੌਰ 'ਤੇ ਤੁਰੰਤ ਖ਼ਬਰ ਪਾਉਣ ਦਾ ਤਰੀਕਾ ਹੈ ਕਿ ਕੋਈ writer ਸਿਰਫ ਪੁਰਾਣੇ ਕਾਲਮ ਨੂੰ ਅਪਡੇਟ ਕਰ ਰਿਹਾ ਹੈ।
ਜਿਨ੍ਹਾਂ ਕੋਡ ਪਾਥਾਂ ਨੇ ਨਵੀਂ ਕਾਲਮ ਪੜ੍ਹਨੀ ਸ਼ੁਰੂ ਕੀਤੀ ਹੈ ਉਹਨਾਂ ਦੇ error rates ਅਤੇ query time ਵੇਖੋ, ਖ਼ਾਸ ਕਰਕੇ deploy ਦੇ ਬਾਅਦ।
ਦੋ ਰਸਤੇ ਕਿੰਨੇ ਸਮੇਂ ਰੱਖਣੇ? ਘੱਟੋ-ਘੱਟ ਇੱਕ ਪੂਰਾ release cycle ਅਤੇ ਇੱਕ backfill rerun ਬਚਾਉਣ ਲਈ ਕਾਫੀ। ਕਈ ਟੀਮਾਂ 1-2 ਹਫ਼ਤੇ ਜਾਂ ਤੱਕ ਰੱਖਦੀਆਂ ਹਨ, ਜਾਂ ਜਦ ਤੱਕ ਉਹ ਯਕੀਨ ਨਾ ਕਰ ਲੈਣ ਕਿ ਕੋਈ ਪੁਰਾਣਾ app ਵਰਜ਼ਨ ਦੌੜ ਰਿਹਾ ਨਹੀਂ।
Contract ਉਹ ਥਾਂ ਹੈ ਜਿੱਥੇ ਟੀਮਾਂ ਨਰਭੇਗੀ ਮਹਿਸੂਸ ਕਰਦੀਆਂ ਹਨ ਕਿਉਂਕਿ ਇਹ point-of-no-return ਵਾਂਗ ਲੱਗਦਾ ਹੈ। ਜੇ expand ਠੀਕ ਕੀਤਾ ਗਿਆ ਹੋਇਆ ਤਾਂ contract ਜ਼ਿਆਦातर ਸਾਫ਼-ਸਫ਼ਾਈ ਹੁੰਦੀ ਹੈ, ਅਤੇ ਤੁਸੀਂ ਇਸਨੂੰ ਵੀ ਛੋਟੇ, ਘੱਟ-ਜੋਖਮ ਵਾਲੇ ਕਦਮਾਂ ਵਿੱਚ ਕਰ ਸਕਦੇ ਹੋ।
ਮੋਮੈਂਟ ਚੁਣੋ ਧਿਆਨ ਨਾਲ। backfill ਖਤਮ ਹੋਣ ਤੁਰੰਤ ਬਾਅਦ ਕੁਝ ਵੀ drop ਨਾ ਕਰੋ। ਘੱਟੋ-ਘੱਟ ਇੱਕ ਪੂਰਾ release cycle ਰੁਕੋ ਤਾਂ ਕਿ delayed jobs ਅਤੇ edge cases ਆ ਸਕਣ।
ਇੱਕ ਸੁਰੱਖਿਅਤ contract ਕ੍ਰਮ ਆਮ ਤੌਰ 'ਤੇ ਇਹ ਹੁੰਦਾ ਹੈ:
ਜੇ ਸੰਭਵ ਹੋਵੇ ਤਾਂ contract ਨੂੰ ਦੋ releases ਵਿੱਚ ਵੰਡੋ: ਇੱਕ ਜੋ ਕੋਡ reference ਹਟਾਏ (ਨਾਲ extra logging), ਅਤੇ ਦੂਜਾ ਜਿਸ ਵਿੱਚ ਡਾਟਾਬੇਸ objects ਹਟਾਏ ਜਾਣ। ਇਹ ਵੰਡ rollback ਅਤੇ troubleshooting ਨੂੰ ਬਹੁਤ ਆਸਾਨ ਬਣਾਉਂਦੀ ਹੈ।
PostgreSQL ਵਿਸ਼ੇਸ਼ ਤੌਰ 'ਤੇ ਇੱਥੇ ਮਹੱਤਵਪੂਰਨ ਹੈ। ਕਾਲਮ ਡ੍ਰੌਪ ਕਰਨਾ ਆਮ ਤੌਰ 'ਤੇ metadata change ਹੁੰਦੀ ਹੈ, ਪਰ ਇਹ ਵੀ ACCESS EXCLUSIVE lock ਲਈ ਸਕਦੀ ਹੈ ਥੋੜ੍ਹੇ ਸਮੇਂ ਲਈ। ਇੱਕ ਸ਼ਾਂਤ ਵਿੰਡੋ ਦੀ ਯੋਜਨਾ ਬਣਾਓ ਅਤੇ ਮਾਈਗ੍ਰੇਸ਼ਨ ਨੂੰ ਤੇਜ਼ ਰੱਖੋ। ਜੇ ਤੁਸੀਂ extra indexes ਬਣਾਏ ਸਨ ਤਾਂ ਉਹਨਾਂ ਨੂੰ DROP INDEX CONCURRENTLY ਨਾਲ ਹਟਾਉਣਾ ਪਸੰਦ ਕਰੋ ਤਾਂ ਕਿ writes ਨੂੰ block ਨਾ ਕਰੇ (ਇਹ transaction block ਵਿੱਚ ਨਹੀਂ ਚੱਲ ਸਕਦਾ, ਇਸ ਲਈ ਤੁਹਾਡੀ migration tooling ਨੂੰ ਇਸਨੂੰ support ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ)।
Zero-downtime migrations ਫੇਲ ਹੁੰਦੇ ਹਨ ਜਦੋਂ ਡਾਟਾਬੇਸ ਅਤੇ ਐਪ ਇਸ ਗੱਲ 'ਤੇ ਸਹਿਮਤ ਨਹੀਂ ਰਹਿ ਜਾਂਦੇ ਕਿ ਕੀ ਮਨਜ਼ੂਰ ਹੈ। ਇਹ ਪੈਟਰਨ तभी ਕੰਮ ਕਰਦਾ ਹੈ ਜਦੋਂ ਹਰ ਵਿਚਕਾਰਲਾ ਸਟੇਟ ਦੋਹਾਂ—ਪੁਰਾਣੀ ਅਤੇ ਨਵੀਂ—ਕੋਡ ਲਈ ਸੁਰੱਖਿਅਤ ਹੋਵੇ।
ਇਹ ਗਲਤੀਆਂ ਅਕਸਰ ਨਜ਼ਰ ਆਉਂਦੀਆਂ ਹਨ:
ਇੱਕ ਹਕੀਕਤੀ ਸੈਨਾਰਿਓ: ਤੁਸੀਂ API ਤੋਂ full_name ਲਿੱਕ ਰਿਹਾ/ਲਿਖ ਰਿਹਾ ਹੋ, ਪਰ ਇੱਕ background job ਜੋ users ਬਣਾਉਂਦਾ ਹੈ ਉਹ ਹਾਲੇ ਵੀ ਸਿਰਫ first_name ਅਤੇ last_name ਸੈੱਟ ਕਰਦਾ ਹੈ। ਇਹ ਰਾਤ ਨੂੰ ਚੱਲਦਾ ਹੈ, rows insert ਕਰਦਾ ਹੈ ਜਿਸ ਵਿੱਚ full_name = NULL ਹੁੰਦਾ ਹੈ, ਅਤੇ ਬਾਅਦ ਵਿੱਚ ਕੋਡ assume ਕਰਦਾ ਹੈ ਕਿ full_name ਹਮੇਸ਼ਾਂ ਮੌਜੂਦ ਹੈ।
ਹਰ ਕਦਮ ਨੂੰ ਇੱਕ release ਵਾਂਗ ਕਰਵਾਓ ਜੋ ਦਿਨਾਂ ਲਈ ਚਲ ਸਕਦਾ ਹੈ:
ਇੱਕ ਦੁਹਰਾਏ ਜਾਣ ਵਾਲੀ ਚੈੱਕਲਿਸਟ ਤੁਹਾਨੂੰ ਐਸਾ ਕੋਡ ship ਕਰਨ ਤੋਂ ਰੋਕਦੀ ਹੈ ਜੋ ਕੇਵਲ ਇਕ ਡਾਟਾਬੇਸ ਸਟੇਟ 'ਤੇ ਕੰਮ ਕਰਦਾ ਹੋਵੇ।
ਡਿਪਲੌਇ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ, ਪੱਕਾ ਕਰੋ ਕਿ ਡਾਟਾਬੇਸ ਵਿੱਚ ਪਹਿਲਾਂ ਹੀ expanded pieces ਮੌਜੂਦ ਹਨ (ਨਵੀਆਂ ਕਾਲਮ/ਟੇਬਲ, low-lock ਤਰੀਕੇ ਨਾਲ ਬਣਾਈਆਂ ਇੰਡੈਕਸ)। ਫਿਰ ਯਕੀਨ ਕਰੋ ਕਿ ਐਪ tolerant ਹੈ: ਇਹ old shape, expanded shape, ਅਤੇ half-backfilled ਸਟੇਟ ਦੋਹਾਂ ਨਾਲ ਕੰਮ ਕਰ ਸਕਦੀ ਹੈ।
ਚੈੱਕਲਿਸਟ ਛੋਟੀ ਰੱਖੋ:
ਇੱਕ ਮਾਈਗ੍ਰੇਸ਼ਨ ਤਦ ਹੀ ਮੁਕੰਮਲ ਮੰਨੀ ਜਾਂਦੀ ਹੈ ਜਦੋਂ reads ਨਵੀਂ ਡਾਟਾ ਵਰਤ ਰਹੇ ਹਨ, writes ਪੁਰਾਣੀ ਡਾਟਾ ਨੂ ਰੱਖਣਾ ਬੰਦ ਕਰ ਚੁੱਕੇ ਹਨ, ਅਤੇ ਤੁਸੀਂ backfill ਦੀ ਘੱਟੋ-ਘੱਟ ਇੱਕ ਸਧਾਰਣ ਜਾਂਚ (ਗਿਣਤੀ ਜਾਂ sample) ਨਾਲ verification ਕਰ ਲਿਆ ਹੈ।
ਮੰਨੋ ਤੁਹਾਡੇ ਕੋਲ ਇੱਕ PostgreSQL table customers ਹੈ ਜਿਸ ਵਿੱਚ phone ਕਾਲਮ ਨੇ ਬੇਰੂਲੇ ਫਾਰਮੈਟ ਰੱਖੇ ਹੋਏ ਹਨ (ਵੱਖ-ਵੱਖ ਫਾਰਮੈਟ, ਕਈ ਵਾਰੀ ਖਾਲੀ)। ਤੁਸੀਂ ਇਸਨੂੰ phone_e164 ਨਾਲ ਬਦਲਣਾ ਚਾਹੁੰਦੇ ਹੋ, ਪਰ ਰਿਲੀਜ਼ ਨੂੰ ਰੋਕਣਾ ਜਾਂ ਐਪ ਡਾਊਨ ਕਰਨਾ ਨੀ ਚਾਹੁੰਦੇ।
ਇੱਕ ਸਾਫ਼ expand/contract ਕ੍ਰਮ ਇਸ ਤਰ੍ਹਾਂ ਲੱਗਦਾ ਹੈ:
phone_e164 ਨੂੰ nullable ਦੇ ਤੌਰ 'ਤੇ ਜੋੜੋ, ਕੋਈ default ਨਾ ਰੱਖੋ, ਅਤੇ ਹੁਣੇ ਸਖ਼ਤ constraints ਨਾ ਲਗਾਓ।phone ਅਤੇ phone_e164 ਵਿੱਚ ਲਿਖਿਆ ਜਾਵੇ, ਪਰ reads phone 'ਤੇ ਹੀ ਰੱਖੋ ਤਾਂ ਕਿ ਯੂਜ਼ਰਾਂ ਲਈ ਕੁਝ ਬਦਲੇ ਨਾ।phone_e164 ਨੂੰ ਪੜ੍ਹੇ, ਅਤੇ ਜੇ ਉਹ NULL ਹੋਵੇ ਤਾਂ phone ਨੂੰ fallback ਵਜੋਂ ਵਰਤਵੇ।phone_e164 ਵਰਤ ਰਿਹਾ ਹੈ, fallback ਹਟਾ ਦਿਓ, phone drop ਕਰੋ, ਫਿਰ ਜੇ ਲੋੜ ਹੋਵੇ ਤਾਂ ਸਖ਼ਤ constraints ਲਗਾਓ।Rollback ਸਧਾਰਨ ਰਹਿੰਦਾ ਹੈ ਜਦੋਂ ਹਰ ਕਦਮ backward compatible ਹੋਵੇ। ਜੇ read switch ਸਮੱਸਿਆ ਪੈਦਾ ਕਰੇ ਤਾਂ ਐਪ rollback ਕਰੋ ਅਤੇ ਡਾਟਾਬੇਸ ਦੋਨਾ ਕਾਲਮਾਂ ਨੂੰ ਰੱਖਦਾ ਹੈ। ਜੇ backfill load spike ਪੈਦਾ ਕਰੇ ਤਾਂ ਜੌਬ ਨੂੰ ਰੋਕੋ, batch size ਘਟਾਓ, ਅਤੇ ਬਾਅਦ ਵਿੱਚ ਜਾਰੀ ਰੱਖੋ।
ਟੀਮ ਨੂੰ aligned ਰੱਖਣ ਲਈ ਯੋਜਨਾ ਇਕੱਠੇ document ਕਰੋ: ਸਹੀ SQL, ਕਿਹੜਾ release reads flip ਕਰਦਾ ਹੈ, completion measure (ਜਿਵੇਂ percent non-NULL phone_e164), ਅਤੇ ہر ਕਦਮ ਦਾ owner.
Expand/contract ਸਭ ਤੋਂ ਚੰਗਾ ਕੰਮ ਕਰਦਾ ਹੈ ਜਦੋਂ ਇਹ routine ਜਿਹਾ ਮਹਿਸੂਸ ਹੋਵੇ। ਆਪਣੀ ਟੀਮ ਲਈ ਇੱਕ ਛੋਟਾ runbook ਲਿਖੋ ਜੋ ਹਰ ਸਕीਮਾ-ਬਦਲਾਅ ਲਈ ਦੁਹਰਾਇਆ ਜਾ ਸਕੇ—ਇੱਕ ਪੰਨਾ ਹੋਵੇ ਅਤੇ ਨਵਾ ਨੌਜਵਾਨ ਟੀਮ ਮੈਂਬਰ ਵੀ ਉਸਨੂੰ ਫੋਲੋ ਕਰ ਸਕੇ।
ਇੱਕ ਵਿਹਾਰਕ ਟੈਮਪਲੇਟ ਇਹਨਾਂ ਨੂੰ ਕਵਰ ਕਰੇ:
ਹੁਣ ਤੋਂ ownership ਪਹਿਲਾਂ ਨਿਧਾਰਤ ਕਰੋ। "ਹਰ ਕੋਈ ਸੋਚਦਾ ਸੀ ਕਿ ਕਿਸੇ ਹੋਰ ਨੇ contract ਕਰ ਲੈਣਾ"—ਇਹੀ ਕਾਰਨ ਹੁੰਦਾ ਹੈ ਕਿ ਪੁਰਾਣੇ ਕਾਲਮ ਅਤੇ feature flags ਮਹੀਨਿਆਂ ਤੱਕ ਰਹਿ ਜਾਂਦੇ ਹਨ।
ਚਾਹੇ backfill online ਹੀ ਚੱਲੇ, ਇਸਨੂੰ ਘੱਟ ਟਰੈਫਿਕ ਵੇਲੇ ਸ਼ਡਿਊਲ ਕਰੋ। ਛੋਟੇ batches ਰੱਖਣਾ, DB ਲੋਡ ਦੇਖਣਾ, ਅਤੇ latency ਵਧਣ 'ਤੇ ਤੁਰੰਤ ਰੋਕਣਾ ਆਸਾਨ ਹੁੰਦਾ ਹੈ।
ਜੇ ਤੁਸੀਂ Koder.ai (koder.ai) ਨਾਲ build ਅਤੇ deploy ਕਰ ਰਹੇ ਹੋ, ਤਾਂ Planning Mode migrations ਲਈ ਫੇਜ਼ ਅਤੇ checkpoints ਨਕਸ਼ਾ ਬਣਾਉਣ ਦਾ ਇੱਕ ਉਪਯੋਗੀ ਤਰੀਕਾ ਹੈ। ਐਸੇ ਹੀ compatibility ਨਿਯਮ ਲਾਗੂ ਹੁੰਦੇ ਹਨ, ਪਰ ਕਦਮਾਂ ਨੂੰ ਲਿਖਿਤ ਰੱਖਣ ਨਾਲ ਉਹ ਨਿਰਾਸ਼ਾਜਨਕ boring ਕਦਮ ਛੱਡਣਾ ਮੁਸ਼ਕਲ ਹੋ ਜਾਂਦਾ ਹੈ ਜੋ ਆਉਟੇਜ ਰੋਕਦੇ ਹਨ।
ਕਿਉਂਕਿ ਤੁਹਾਡਾ ਡਾਟਾਬੇਸ ਤੁਹਾਡੇ ਐਪ ਦੇ ਹਰੇਕ ਰਣ ਹੋ ਰਹੇ ਵਰਜ਼ਨ ਵੱਲੋਂ ਸਾਂਝਾ ਕੀਤਾ ਜਾਂਦਾ ਹੈ। rolling deploys ਅਤੇ background jobs ਦੌਰਾਨ ਪੁਰਾਣੀ ਅਤੇ ਨਵੀਂ ਕੋਡ ਇਕੱਠੇ ਚੱਲ ਸਕਦੀ ਹਨ, ਅਤੇ ਜੇ ਮਾਈਗ੍ਰੇਸ਼ਨ ਨਾਮ ਬਦਲਦੀ ਹੈ, ਕਾਲਮ ਡਰੌਪ ਕਰਦੀ ਹੈ ਜਾਂ ਨਵੇਂ constraints ਜੋੜਦੀ ਹੈ ਤਾਂ ਉਹ ਕਿਸੇ ਵੀ ਵਰਜ਼ਨ ਨੂੰ ਟੁੱਟ ਸਕਦੀ ਹੈ ਜੋ ਉਸ ਖਾਸ ਸਕੀਮਾ ਸਟੇਟ ਲਈ ਨਹੀ ਬਣਾਇਆ ਗਿਆ।
ਇਸਦਾ ਮਤਲਬ ਹੈ ਕਿ ਤੁਸੀਂ ਐਸਾ ਮਾਈਗ੍ਰੇਸ਼ਨ ਡਿਜ਼ਾਇਨ ਕਰੋ ਕਿ ਹਰ ਵਿਚਕਾਰਲਾ ਡਾਟਾਬੇਸ ਸਟੇਟ ਪੁਰਾਣੀ ਅਤੇ ਨਵੀਂ ਕੋਡ ਦੋਹਾਂ ਲਈ ਕੰਮ ਕਰੇ। ਪਹਿਲਾਂ ਨਵੀਂ ਸਟ੍ਰਕਚਰ ਜੋੜੋ, ਕੁਝ ਸਮਾਂ ਦੋ ਰਸਤੇ ਇਕੱਠੇ ਚਲਾਓ, ਫਿਰ ਹੌਲੀ-ਹੌਲੀ ਪੁਰਾਣੀਆਂ ਚੀਜ਼ਾਂ ਹਟਾਓ ਜਦੋਂ ਕੋਈ ਉਨ੍ਹਾਂ 'ਤੇ ਨਿਰਭਰ ਨਾ ਰਹੇ।
Expand ਨਵੀਆਂ ਕਾਲਮਾਂ, ਟੇਬਲਾਂ ਜਾਂ ਇੰਡੈਕਸਾਂ ਨੂੰ ਜੋੜਦਾ ਹੈ ਬਿਨਾਂ ਉਹ ਚੀਜ਼یں ਹਟਾਏ ਜਿਨ੍ਹਾਂ ਦੀ ਮੌਜੂਦਾ ਐਪ ਨੂੰ ਲੋੜ ਹੈ। Contract ਉਹ ਸਾਫ਼-ਸਫ਼ਾਈ ਫੇਜ਼ ਹੈ ਜਿੱਥੇ ਤੁਸੀਂ ਪੁਰਾਣੇ ਕਾਲਮ, ਪੁਰਾਣੇ ਰੀਡ/ਰਾਈਟ ਕੋਡ ਅਤੇ ਅਣਚਾਹੀ ਸਿੰਕ ਲੌਜਿਕ ਹਟਾਉਂਦੇ ਹੋ, ਪਰ ընդੇ ਕੇਵਲ ਉਸ ਸਮੇਂ ਜਦੋਂ ਨਵਾਂ ਰਸਤਾ ਭਰੋਸੇਯੋਗ ਹੋ ਚੁੱਕੇ।
ਸਭ ਤੋਂ ਸੁਰੱਖਿਅਤ ਸ਼ੁਰੂਆਤ ਇੱਕ nullable ਕਾਲਮ ਬਣਾਉਣਾ ਹੈ ਜਿਸਦਾ ਕੋਈ ਡਿਫਾਲਟ ਨਾ ਹੋਵੇ, ਕਿਉਂਕਿ ਇਸ ਨਾਲ ਭਾਰੀ ਲਾਕਜ ਜਾਂ ਟੇਬਲ ਰੀਰਾਈਟ ਤੋਂ ਬਚਾਵ ਹੁੰਦਾ ਹੈ। ਫਿਰ ਕੋਡ ਐਸਾ ਡਿਪਲੌਇ ਕਰੋ ਜੋ ਕਾਲਮ ਦੇ ਮੌਜੂਦ ਨਾ ਹੋਣ ਜਾਂ NULL ਹੋਣ ਨੂੰ ਸੰਭਾਲ ਸਕੇ, ਹੌਲੀ-ਹੌਲੀ backfill ਕਰੋ ਅਤੇ ਫਿਰ ਬਾਅਦ ਵਿੱਚ NOT NULL ਵਰਗੇ constraints ਲਗਾਓ।
ਜਦੋਂ ਤਰਾਂ ਨਵਾਂ ਐਪ ਵਰਜ਼ਨ ਟਰਾਂਜ਼ਿਸ਼ਨ ਵਿੱਚ ਹੋਵੇ ਤਾਂ ਨਵੀਂ ਐਪ ਦੋਨਾਂ—ਪੁਰਾਣੇ ਅਤੇ ਨਵੇਂ—ਫੀਲਡਾਂ ਵਿੱਚ ਲਿਖਦੀ ਹੈ। ਇਸ ਨਾਲ ਡਾਟਾ consistent ਰਹਿੰਦਾ ਹੈ ਜਦੋਂ ਤੱਕ ਕੁਝ ਇੰਸਟੈਂਸ ਜਾਂ jobs ਸਿਰਫ਼ ਪੁਰਾਣੇ ਫੀਲਡ ਨੂੰ ਜਾਣਦੇ ਹਨ।
ਛੋਟੇ batches ਵਿੱਚ backfill ਕਰੋ ਜੋ ਛੇਤੀ ਖਤਮ ਹੋਣ (ਸੈਕਿੰਡਾਂ, ਮਿੰਟ ਨਹੀਂ)। ਹਰ batch idempotent ਬਣਾਓ ਤਾਂ ਕਿ ਰੀਰਨ ਸਿਰਫ਼ ਉਹੀ ਰੋਜ਼ ਅੱਪਡੇਟ ਕਰੇ ਜੋ ਅਜੇ ਵੀ ਜ਼ਰੂਰਤ ਵਾਲੇ ਹਨ। query time, lock waits ਅਤੇ replication lag 'ਤੇ ਨਜ਼ਰ ਰੱਖੋ ਅਤੇ DB ਗਰਮ ਹੋਣ 'ਤੇ ਜੌਬ ਰੋਕਣ ਜਾਂ batch size ਘਟਾਉਣ ਲਈ ਤਿਆਰ ਰਹੋ।
ਪਹਿਲਾਂ completeness ਜਾਂਚੋ — ਨਵੀਂ ਕਾਲਮ ਵਿੱਚ ਅਣਉਮੀਦਤ NULL ਤਾਂ ਨਹੀਂ। ਕਿੰਨੀ rows eligible ਸਨ ਬਨਾਮ ਕਿੰਨੀਆਂ ਭਰੀਆਂ ਗਈਆਂ, UUID/IDs ਦੇ ਛੋਟੇ ਨਮੂਨੇ ਨਾਲ cross-check ਕਰੋ, ਅਤੇ edge cases ਟੈਸਟ ਕਰੋ। ਜੇ ਤੁਸੀਂ dual-write ਕਰ ਰਹੇ ਹੋ ਤਾਂ ਇੱਕ consistency ਚੈਕ ਰੱਖੋ ਜਿਸ ਨਾਲ rows ਜਿਨ੍ਹਾਂ ਵਿੱਚ old_value <> new_value ਹੋਵੇ ਉਹ ਦਿਖਾਏ ਜਾਣ।
ਸਰਲ ਰੀਕਾਂਡ: NOT NULL ਜਲਦੀ ਨਾ ਜੋੜੋ; ਵੱਡੇ ਟੇਬਲ ਨੂੰ ਇੱਕ ਟਰੇਂਜ਼ੈਕਸ਼ਨ ਵਿੱਚ backfill ਨਾ ਕਰੋ; defaults ਹਮੇਸ਼ਾਂ free ਨਹੀਂ ਹੁੰਦੇ—ਕੁਝ Postgres ਵਰਜਨਾਂ ਵਿੱਚ ਉਹ ਟੇਬਲ ਰੀਰਾਈਟ ਕਰ ਦੇਂਦੇ ਹਨ; ਅਤੇ reads ਨਵੀਂ ਕਾਲਮ 'ਤੇ switch ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ ਯਕੀਨੀ ਕਰੋ ਕਿ writes ਨੂ ਭਰ ਰਿਹਾ ਹੈ।
ਜਦੋਂ ਤੁਸੀਂ ਪੁਰਾਣੀ ਫੀਲਡ ਨੂੰ ਲਿਖਣਾ ਬੰਦ ਕਰ ਦਿੰਦੇ ਹੋ, ਪੜ੍ਹਨ ਵਾਲੇ ਕੋਡ ਤੋਂ fallback ਹਟਾ ਦਿੰਦੇ ਹੋ, dead code/feature flags ਹਟਾ ਦਿੰਦੇ ਹੋ ਅਤੇ ਅੰਤ ਵਿੱਚ temporary triggers/compatibility views ਨੂੰ ਹਟਾ ਕੇ ਪੁਰਾਣੀ ਕਾਲਮ ਡ੍ਰੌਪ ਕਰ ਸਕਦੇ ਹੋ।Drop column ਇੱਕ ਛੋਟਾ ACCESS EXCLUSIVE lock ਲੈ ਸਕਦਾ ਹੈ—ਇਸ ਲਈ ਰੂਟ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ ਇੱਕ release cycle ਰੁਕੋ।
ਜੇ ਤੁਸੀਂ maintenance window ਮਨਜ਼ੂਰ ਕਰ ਸਕਦੇ ਹੋ ਅਤੇ ਟਰੈਫਿਕ ਘੱਟ ਹੈ ਤਾਂ ਇੱਕ ਸਧਾਰਨ ਇੱਕ-ਵਾਰ migration ਠੀਕ ਰਹੇਗੀ। ਪਰ ਜੇ ਤੁਹਾਡੇ ਕੋਲ ਰੀਅਲ ਯੂਜ਼ਰ, ਬਹੁਤ ਸਾਰੇ app instances, workers ਜਾਂ SLAs ਹਨ ਤਾਂ expand/contract ਜ਼ਿਆਦਾ ਮਦੀਰੀ ਹੁੰਦਾ ਹੈ ਕਿਉਂਕਿ ਇਹ ਰੋਲਆਊਟ ਅਤੇ ਰੋਲਬੈਕ ਨੂੰ ਸੁਰੱਖਿਅਤ ਬਣਾਉਂਦਾ ਹੈ; Koder.ai Planning Mode ਵਿੱਚ ਚਰਣਾਂ ਅਤੇ ਚੈੱਕਲਿਸਟ ਲਿਖ ਕੇ ਤੁਸੀਂ ਉਹਨੂੰ ਰੁਟੀਨ ਬਣਾਉ ਸਕਦੇ ਹੋ।