18 aug 2025·8 min
Soft deletes vs hard deletes: afwegingen die ertoe doen in echte apps
Soft deletes vs hard deletes: leer de echte afwegingen voor analytics, support, GDPR-achtige verwijdering en query-complexiteit, plus veilige restore-patronen.
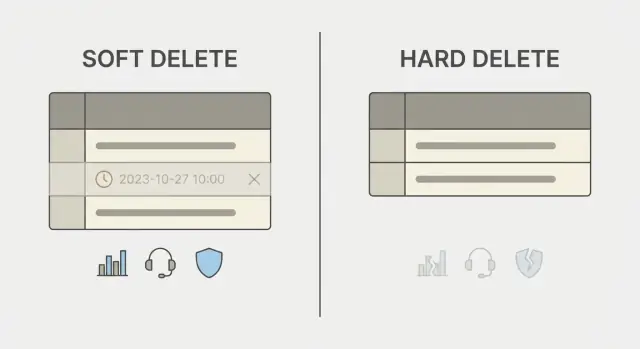
Wat soft deletes en hard deletes echt betekenen
Een verwijderknop kan twee heel verschillende dingen betekenen in een database.
Een hard delete verwijdert de rij. Daarna is het record weg, tenzij je backups, logs of replicaties hebt die het nog bevatten. Het is eenvoudig te begrijpen, maar definitief.
Een soft delete houdt de rij, maar markeert deze als verwijderd, meestal met een veld zoals deleted_at of is_deleted. De app behandelt gemarkeerde rijen dan als onzichtbaar. Je bewaart gerelateerde data, behoudt historie en kunt soms het record herstellen.
Deze keuze speelt vaker in dagelijkse werkzaamheden dan mensen verwachten. Het beïnvloedt hoe je vragen beantwoordt zoals: “Waarom daalde de omzet vorige maand?”, “Kun je mijn verwijderde project terughalen?”, of “We hebben een GDPR-verzoek — verwijderen we echt persoonsgegevens?” Het bepaalt ook wat “verwijderd” betekent in de UI. Gebruikers gaan er vaak vanuit dat ze het ongedaan kunnen maken, totdat dat niet meer kan.
Een praktische vuistregel:
- Gebruik soft delete wanneer gebruikers een undo verwachten, wanneer support fouten moet kunnen herstellen of wanneer je een audittrail nodig hebt.
- Gebruik hard delete wanneer het bewaren van data juridisch of veiligheidsrisico vormt, of duidelijke opslagkosten zonder echte waarde oplevert.
- Gebruik beide wanneer je een prullenbakperiode wilt: eerst soft delete, daarna permanent purge.
Voorbeeld: een klant verwijdert een workspace en beseft later dat er facturen voor de boekhouding in stonden. Met soft delete kan support het herstellen (als je app gebouwd is om restores veilig af te handelen). Met hard delete sta je waarschijnlijk voor de keuze van backups, vertragingen of “het is niet mogelijk.”
Geen van beide benaderingen is per se “de beste.” De minst pijnlijke optie hangt af van wat je moet beschermen: gebruikersvertrouwen, rapportage-accuratesse of privacy-compliance.
Analytics-afwegingen: nauwkeurigheid vs historie behouden
Verwijderingkeuzes verschijnen snel in analytics. De dag dat je actieve gebruikers, conversie of omzet gaat bijhouden, wordt “verwijderd” geen eenvoudige staat meer maar een rapportagebeslissing.
Als je hard delete gebruikt, lijken veel metrics schoon omdat verwijderde records uit queries verdwijnen. Maar je verliest context: eerdere abonnementen, vorige teamgroottes of hoe een funnel er vorige maand uitzag. Een verwijderde klant kan historische grafieken laten verschuiven wanneer je rapporten opnieuw draait, en dat is beangstigend voor finance en growth reviews.
Als je soft delete gebruikt, bewaart je de historie, maar kun je per ongeluk cijfers opblazen. Een eenvoudige “COUNT users” kan mensen mee-tellen die zijn vertrokken. Een churn-grafiek kan dubbel tellen als je deleted_at in het ene rapport als churn beschouwt en in een ander negeert. Zelfs omzet kan rommelig worden als facturen blijven bestaan maar het account als verwijderd gemarkeerd is.
Wat vaak werkt is een consistente rapportage-aanpak kiezen en je daaraan houden:
- Filter verwijderde records uit “huidige staat”-metrics (actieve gebruikers, huidige MRR).
- Gebruik snapshot-tabellen voor tijdgebonden dashboards zodat historie niet verandert wanneer entities later verwijderd worden.
- Scheid feiten van entiteiten: houd ongewijzigde event-rijen (betalingen, logins) ook als je de gebruikersrij verbergt.
- Behandel “verwijderd” als een lifecycle-state met een eigen datum en rapporteer het expliciet (created, activated, deleted).
- Definieer retentie-windows: wanneer soft-verwijderde data echt wordt verwijderd.
Het belangrijkste is documentatie zodat analisten niet hoeven te raden. Schrijf op wat “actief” betekent, of soft-verwijderde gebruikers worden meegenomen, en hoe omzet wordt toegeschreven als een account later wordt verwijderd.
Concreet voorbeeld: een workspace is per ongeluk verwijderd en vervolgens hersteld. Als je dashboard workspaces telt zonder te filteren, zie je een plotselinge daling en herstel die in de echte gebruiksstatistieken niet heeft plaatsgevonden. Met snapshots blijft de historische grafiek stabiel terwijl productweergaven verwijderde workspaces kunnen verbergen.
Support en audit trail: wat je later kunt herstellen
De meeste supporttickets rondom verwijdering klinken hetzelfde: “Ik heb het per ongeluk verwijderd,” of “Waar is mijn record gebleven?” Je delete-strategie bepaalt of support binnen minuten kan antwoorden, of dat het enige eerlijke antwoord is: “Het is weg.”
Met soft deletes kun je meestal verifiëren wat er gebeurde en het ongedaan maken. Met hard deletes moet support vaak op backups vertrouwen (als je die hebt), en dat kan traag, incompleet of onmogelijk zijn voor één enkel item. Daarom is de keuze niet alleen een databasespec; het bepaalt hoe “behulpzaam” je product kan zijn nadat iets misging.
Een eenvoudige audit trail (wat op te slaan)
Als je echte support verwacht, voeg dan een paar velden toe die deletie-events uitleggen:
deleted_at(timestamp)deleted_by(user id of systeem)delete_reason(optioneel, korte tekst)deleted_from_ipofdeleted_from_device(optioneel)restored_atenrestored_by(als je herstel ondersteunt)
Zelfs zonder een volledige activity log laten deze details support zien: wie het verwijderde, wanneer het gebeurde en of het een ongeluk of een geautomatiseerde cleanup was.
Wat hard deletes betekenen voor support
Hard deletes kunnen prima zijn voor tijdelijke data, maar voor gebruikersgerichte records veranderen ze wat support kan doen.
Support kan geen enkel record herstellen tenzij je elders een recycle bin bouwde. Ze hebben mogelijk een volledige backup-restore nodig, wat andere data kan beïnvloeden. Ze kunnen ook niet eenvoudig aantonen wat er gebeurde, wat leidt tot lange heen-en-weercommunicatie.
Restore-functionaliteit verandert ook de werkbelasting. Als gebruikers zelf binnen een venster kunnen herstellen, nemen tickets af. Als herstellen handmatig door support moet gebeuren, kunnen er meer tickets komen, maar ze worden snel en herhaalbaar in plaats van unieke onderzoeken.
GDPR-achtige verwijdering: soft delete is geen volledige verwijdering
Het “recht om vergeten te worden” betekent meestal dat je moet stoppen met het verwerken van iemands data en het verwijderen van plekken waar het nog bruikbaar is. Het betekent niet altijd dat je elke historische aggregate meteen moet wissen, maar het betekent wel dat je geen identificeerbare data “voor het geval dat” moet bewaren als je geen wettelijke reden meer hebt.
Hier wordt soft delete vs hard delete meer dan een productkeuze. Een soft delete (bijvoorbeeld deleted_at zetten) verbergt het record vaak alleen voor de app. De data staat nog in de database, is nog door admins opvraagbaar en zit vaak nog in exportbestanden, zoekindexen en analytics-tabellen. Voor veel GDPR-verzoeken is dat geen uitwissing.
Je hebt nog steeds een purge nodig wanneer:
- Een gebruiker om verwijdering vraagt en je geen geldige retentieregel hebt (bijv. boekhoudregels).
- Je bijzondere categorieën data opsloeg en je beleid zegt dat die verwijderd moeten worden.
- Het record verschijnt in gebruikersgerichte exports of kan door support worden hersteld.
- Een derde partij (e-mail, analytics, supporttools) het nog bewaart.
Backups en logs zijn wat teams vergeten. Je kunt misschien geen enkele rij uit een versleutelde backup wissen, maar je kunt regels instellen: backups verlopen snel en herstelde backups moeten verwijder-events opnieuw toepassen voordat het systeem live gaat. Logs moeten idealiter geen ruwe persoonsgegevens opslaan en duidelijke retentiegrenzen hebben.
Een eenvoudige, praktische policy is een twee-stappen verwijdering:
- Soft delete onmiddellijk (zodat het product zich correct gedraagt, accounts worden uitgeschakeld en “restore deleted records” werkt voor fouten).
- Start een retentie-timer (bijvoorbeeld 7 tot 30 dagen) en plan een purge-job die hard-delete of persoonsgegevens anonimiseert.
- Leg vast wat er gebeurde in een audittrail met niet-identificerende markers (timestampts, reden-codes) zodat support acties kan uitleggen zonder de data te bewaren.
Als je platform source- of data-export ondersteunt, behandel geëxporteerde bestanden ook als datastores: bepaal waar ze liggen, wie er toegang toe heeft en wanneer ze worden verwijderd.
Query-complexiteit en productgedrag: de verborgen kosten
Audit verwijderingen duidelijk
Voeg deleted_at, deleted_by en reden-velden toe vanuit één duidelijke specificatie.
Soft deletes klinken simpel: voeg een deleted_at (of is_deleted) vlag toe en verberg de rij. De verborgen kost is dat nu elke plek waar je data leest aan die vlag moet denken. Missen teams die filter één keer, dan ontstaan rare bugs: totalen bevatten verwijderde items, search toont “ghost” resultaten of een gebruiker ziet iets waarvan hij dacht dat het weg was.
UI- en UX-randgevallen duiken snel op. Stel dat een team een project genaamd “Roadmap” verwijdert en later probeert een nieuwe “Roadmap” aan te maken. Als je database een unieke regel op naam heeft, faalt de create omdat de verwijderde rij nog bestaat. Search kan gebruikers ook verwarren: als je verwijderde items in lijsten verbergt maar niet in globale search, denken gebruikers dat je app kapot is.
Soft delete-filters worden vaak vergeten in:
- Admin dashboards en supporttools
- Background jobs (e-mails, reminders, cleanups)
- Analytics-queries en exports
- Permission checks (“bestaat dit record?”)
- Autocomplete en zoekfunctionaliteit
Performance is meestal in het begin prima, maar de extra voorwaarde voegt werk toe. Als de meeste rijen actief zijn, is filteren op deleted_at IS NULL goedkoop. Als veel rijen verwijderd zijn, moet de database meer rijen overslaan tenzij je de juiste index toevoegt. In gewone taal: het is alsof je zoekt naar huidige documenten in een lade met ook veel oude documenten.
Een aparte “Archive”-sectie kan verwarring verminderen. Laat de standaardweergave alleen actieve records tonen en plaats verwijderde items op één plek met duidelijke labels en een tijdvenster. In snel gebouwde tools (bijvoorbeeld interne apps gemaakt op Koder.ai) voorkomt deze productkeuze vaak meer supporttickets dan elk slim query-trucje.
Veelvoorkomende datamodellen voor soft delete
Soft delete is niet één feature. Het is een datamodelkeuze en het model dat je kiest bepaalt alle volgende dingen: queryregels, restore-gedrag en wat “verwijderd” voor jouw product betekent.
Model 1: deleted_at plus deleted_by
Het meest voorkomende patroon is een nullable timestamp. Wanneer een record wordt verwijderd, zet je deleted_at (en vaak deleted_by naar de user id). “Actieve” records zijn die waar deleted_at null is.
Dit werkt goed als je een schone restore nodig hebt: herstellen is gewoon deleted_at en deleted_by leegmaken. Het geeft support ook een eenvoudige auditindicator.
Model 2: expliciete status-staten
In plaats van een timestamp gebruiken sommige teams een status veld met duidelijke staten zoals active, archived en deleted. Dit is handig wanneer “archived” een echte productstaat is (verborgen voor de meeste schermen maar toch meetelt in billing, bijvoorbeeld).
De kosten zijn regels. Je moet definiëren wat elke staat overal betekent: search, notificaties, exports en analytics.
Model 3: gesplitste opslag voor waardevolle records
Voor gevoelige of waardevolle objecten kun je verwijderde rijen naar een aparte tabel verplaatsen, of een event in een append-only log opnemen.
- Timestamp soft delete:
deleted_at,deleted_by - State machine:
statusmet benoemde staten - Aparte deleted-tabel: de "active" tabel blijft klein
- Event log: bewaar "wie deed wat" zonder volledige rijen voor altijd te bewaren
Dit gebruik je vaak wanneer restores strikt gecontroleerd moeten worden, of wanneer je een audittrail wilt zonder verwijderde data door alledaagse queries te mengen.
Child-records hebben ook een intentionele regel nodig. Als een workspace wordt verwijderd, wat gebeurt er met projecten, bestanden en lidmaatschappen?
- Cascade: markeer kinderen ook als verwijderd
- Restrict: blokkeer verwijderen totdat kinderen zijn afgehandeld
- Archive: zet kinderen op
archived(niet verwijderd) - Detach: verwijder relaties maar behoud het kind
Kies één regel per relatie, noteer het en houd het consistent. De meeste "restore ging mis" bugs komen doordat parent- en child-records verschillende betekenissen van deleted gebruiken.
Hoe je een veilige restore-functie implementeert (stap voor stap)
Een restore-knop klinkt simpel, maar kan stilletjes permissies breken, oude data op de verkeerde plek terugbrengen of gebruikers verwarren als “hersteld” niet betekent wat ze verwachten. Begin met het uitschrijven van de exacte belofte die je product doet.
Een praktische restore-flow
Gebruik een kleine, strikte volgorde zodat restore voorspelbaar en auditbaar is.
- Definieer wat “restore” betekent. Houdt het record dezelfde ID? Keert het terug naar dezelfde parent (workspace, project) en behoudt het dezelfde relaties? Bepaal wat er gebeurt met lidmaatschappen, rollen en zichtbaarheid.
- Laat de gebruiker bevestigen en leg een reden vast. Laat zien wat er hersteld wordt (naam, eigenaar, laatst aangepast) en eis een duidelijke bevestiging. Voor support-teams is een korte reden-veld (“per ongeluk verwijderd”, “ticket gesloten”) vaak genoeg.
- Controleer op conflicten voordat je iets verandert. Veelvoorkomende problemen: de oude naam is opnieuw gebruikt, de gebruiker heeft geen toestemming meer, of gerelateerde records zijn hard-verwijderd. Kies een regel: blokkeer herstel met een duidelijke melding, of herstel naar een veilige "needs review" staat.
- Log de restore-actie. Registreer wie herstelde, wanneer, waarvandaan (UI, API) en wat er veranderde. Dit helpt bij audits en support en is essentieel als iemand vraagt: “Waarom is dit teruggekomen?”
- Voeg zo nodig een tijdslimiet toe. Veel apps staan restores toe voor 30 of 90 dagen, daarna is een ander herstelproces nodig of wordt het als permanent beschouwd.
Als je apps snel bouwt in een chatgestuurde tool zoals Koder.ai, neem deze controles als onderdeel van de gegenereerde workflow zodat elk scherm en endpoint dezelfde regels volgt.
Veelgemaakte fouten en valkuilen om te vermijden
Implementeer GDPR-achtige purges
Stel retentie-timers en purge-jobs in zodat verborgen data niet blijft hangen.
De grootste pijn met soft deletes is niet de delete zelf, maar alle plekken die vergeten dat een record "weg" is. Veel teams kiezen soft delete uit veiligheid en tonen per ongeluk verwijderde items in zoekresultaten, badges of totalen. Gebruikers merken het snel als een dashboard “12 projecten” zegt maar er maar 11 verschijnen.
Op de tweede plaats staat toegangcontrole. Als een gebruiker, team of workspace soft-verwijderd is, mogen ze niet kunnen inloggen, de API aanroepen of notificaties ontvangen. Dit slipte vaak door omdat de login-check op e-mail zoekt, de rij vindt en de deleted-vlag nooit controleert.
Veelvoorkomende valkuilen die later supporttickets veroorzaken:
- Het missen van de deleted-filter in één leespad (admin views, exports, search, background jobs).
- Herstellen van records die botsen met unieke velden (email, username, slug, factuurnummer).
- Een parent verwijderen maar kinderen “actief” laten (of kinderen verwijderen terwijl de parent nog leeft).
- Verwijderde rijen meetellen in analytics, quota's of billing-berekeningen.
- Verwijderen naar derde partijen sturen omdat integraties en sync-jobs “deleted” niet begrijpen.
Uniciteit-botsingen zijn vooral vervelend tijdens restore. Als iemand een nieuw account aanmaakt met dezelfde e-mail terwijl het oude soft-verwijderd is, faalt een restore of overschrijft het mogelijk de verkeerde identiteit. Bepaal je regel van tevoren: blokkeer hergebruik tot purge, sta hergebruik toe maar verbied restore, of herstel onder een nieuw identifier.
Een veelvoorkomend scenario: een supportagent herstelt een soft-verwijderde workspace. De workspace komt terug, maar zijn leden blijven verwijderd en een integratie begint oude records naar een partnertool te syncen. Vanuit de gebruiker gezien werkte de restore “half” en veroorzaakte een nieuwe puinhoop.
Maak voor je release deze gedragingen expliciet:
- Wat “verwijderd” betekent voor login, API-toegang en notificaties
- Hoe restore omgaat met unieke velden en eigendom
- Hoe gerelateerde records de parent volgen (all-or-nothing voorkomt verrassingen)
- Hoe exports en integraties omgaan met verwijderde data (exclude, markeren of tombstones sturen)
Realistisch voorbeeld: een workspace per ongeluk verwijderd
Een B2B SaaS-team heeft een "Delete workspace" knop. Op een vrijdag voert een admin een cleanup uit en verwijdert 40 workspaces die inactief leken. Op maandag klagen drie klanten dat hun projecten weg zijn en vragen om direct herstel.
Het team dacht dat de beslissing simpel zou zijn. Dat was het niet.
Eerste probleem: support kan niet herstellen wat echt verwijderd is. Als de workspace-rij hard-verwijderd is en cascade projecten, bestanden en lidmaatschappen verwijdert, is de enige optie backups. Dat betekent tijd, risico en een ongemakkelijk antwoord naar de klant.
Tweede probleem: analytics lijkt kapot. Het dashboard telt “actieve workspaces” door alleen rijen te queryen waar deleted_at IS NULL. De per ongeluk verwijdering veroorzaakt een plotselinge daling in de grafieken. Nog erger: een weekrapport vergelijkt met vorige week en markeert een valse churn-piek. De data is niet verloren, maar werd op de verkeerde plekken uitgesloten.
Derde probleem: er komt een privacyverzoek binnen voor een van de getroffen gebruikers. Die vraagt om zijn persoonsgegevens te verwijderen. Een pure soft delete voldoet hier niet. Het team moet persoonlijke velden (naam, e-mail, IP-logs) purgen terwijl ze niet-persoonlijke aggregaten zoals factuurtotalen en factuurnummers mogelijk behouden.
Vierde probleem: iedereen vraagt: “Wie klikte op delete?” Als er geen spoor is, kan support niet uitleggen wat er gebeurde.
Een veiliger patroon is verwijdering als event met duidelijke metadata:
- Markeer de workspace als verwijderd (en verberg hem in het product)
- Registreer
deleted_by,deleted_aten een reden of ticket-id - Log wat er beïnvloed wordt (projectaantal, seats, opslag)
- Sta herstel toe binnen een tijdvenster en purge daarna geselecteerde persoonsvelden wanneer dat nodig is
Dit is het soort workflow dat teams vaak snel bouwen in platforms zoals Koder.ai, en later beseffen dat het verwijderbeleid net zoveel ontwerp nodig heeft als de functies eromheen.
Snelle checklist om de juiste delete-strategie te kiezen
Voorkom ghost records
Bouw lijst-, zoek- en exportweergaven die consequent verwijderde data filteren.
Kiezen tussen soft deletes en hard deletes gaat minder over voorkeur en meer over wat je app moet garanderen nadat een record "weg" is. Stel deze vragen voordat je één query schrijft.
- Heb je ooit echte uitwissing nodig? Als je privacy- of juridische verzoeken moet honoreren, plan dan echte verwijdering (inclusief backups en exports). Een soft delete-vlag alleen voldoet niet aan “volledige verwijdering”.
- Heb je een restore-knop nodig, en hoe lang? Als "undo" belangrijk is, bepaal het restore-window (7 dagen, 30 dagen, voor altijd) en wat er daarna gebeurt.
- Heeft rapportage de oude data na verwijdering nodig? Sommige teams willen grafieken die tonen wat gebruikers nu zien; anderen hebben historische aantallen voor finance of growth. Je delete-keuze verandert wat “actieve gebruikers” en “totale omzet” betekenen.
- Kan support uitleggen wat er gebeurde zonder detectivewerk? Als je tickets verwacht zoals “mijn project verdween”, heb je een duidelijk spoor nodig: wie verwijderde het, wanneer en vanaf waar, plus genoeg data om te onderzoeken.
- Kan je team gedrag overal consistent houden? Soft deletes creëren vaak verborgen regels: elke query moet verwijderde records filteren, elke join moet zich gedragen en elk scherm moet dezelfde definitie van “verwijderd” volgen.
Een eenvoudige manier om de beslissing te controleren is één realistisch incident doorlopen. Bijvoorbeeld: iemand verwijdert op vrijdagavond per ongeluk een workspace. Maandagochtend moet support het deletie-event zien, veilig herstellen en vermijden dat gerelateerde data wordt teruggebracht die verwijderd had moeten blijven. Als je een app bouwt op een platform zoals Koder.ai, definieer deze regels vroeg zodat je gegenereerde backend en UI één beleid volgen in plaats van speciale gevallen door de code te strooien.
Volgende stappen: kies een beleid en bouw het veilig
Kies je aanpak door een eenvoudig beleid op te schrijven en te delen met je team en support. Als het niet op papier staat, zakt het beleid weg en ervaren gebruikers inconsistentie.
Begin met een duidelijk set regels:
- Wat wordt soft-verwijderd (en hoe lang is het herstelbaar)
- Wat wordt meteen hard-verwijderd (en waarom)
- Wanneer wordt soft-verwijderde data gepurged (bijvoorbeeld na X dagen)
- Wie kan herstellen en welke bewijs of goedkeuring is vereist
- Hoe privacygedreven verwijderingsverzoeken end-to-end worden afgehandeld
Bouw daarna twee duidelijke paden die nooit door elkaar lopen: een “admin restore”-pad voor fouten en een “privacy purge”-pad voor echte verwijdering. Het restore-pad moet omkeerbaar en gelogd zijn. Het purge-pad moet definitief zijn en alle gerelateerde identificeerbare data verwijderen of anonimiseren, inclusief backups of exports indien je beleid dat vereist.
Voeg guardrails toe zodat verwijderde data niet teruglekt in het product. De makkelijkste manier is om “verwijderd” als een volwaardige staat in je tests te behandelen. Voeg review-checkpoints toe voor elke nieuwe query, lijstpagina, zoekfunctie, export en analytics-job. Een goede regel: als een scherm gebruikersgerichte data toont, moet er een expliciete beslissing zijn over verwijderde records (verbergen, tonen met label of admin-only).
Als je vroeg in een product zit, prototypeer beide flows voordat je het schema vastzet. In Koder.ai kun je het verwijderingsbeleid in de planningsmodus schetsen, de basale CRUD genereren en snel restore- en purge-scenario's uitproberen, en dan het datamodel aanpassen voordat je het commit.