08 mei 2025·8 min
Hoe je een webapp bouwt voor leveranciersscores en beoordelingen
Leer hoe je een webapp plant, ontwerpt en bouwt voor leveranciersscorecards en beoordelingen — met datamodellen, workflows, permissies en rapportagetips.
Leer hoe je een webapp plant, ontwerpt en bouwt voor leveranciersscorecards en beoordelingen — met datamodellen, workflows, permissies en rapportagetips.
Voordat je schermen schetst of een database kiest, maak duidelijk waar de app voor is, wie erop vertrouwt en hoe “goed” eruitziet. Leveranciersscore-apps falen vaak wanneer ze proberen iedereen tegelijk tevreden te stellen — of wanneer ze basisvragen niet kunnen beantwoorden zoals “Welke leverancier beoordelen we eigenlijk?”
Begin met het benoemen van je primaire gebruikersgroepen en hun dagelijkse beslissingen:
Een handige truc: kies één “kerngebruiker” (vaak procurement) en ontwerp de eerste release rond hun workflow. Voeg daarna de volgende groep pas toe als je kunt uitleggen welke nieuwe mogelijkheid dat ontsluit.
Schrijf uitkomsten als meetbare veranderingen, niet als features. Veelvoorkomende uitkomsten zijn:
Deze uitkomsten sturen later je KPI-tracking en rapportageselecties.
“Leverancier” kan verschillende dingen betekenen afhankelijk van je organisatie en contracten. Beslis vroeg of een leverancier een:
Je keuze beïnvloedt alles: score-rollups, permissies en of één slechte faciliteit de gehele relatie mag schaden.
Er zijn drie veelvoorkomende patronen:
Maak de scoringsmethode begrijpelijk genoeg zodat een leverancier (en een interne auditor) hem kan volgen.
Kies een paar app-niveau succesmetrics om adoptie en waarde te valideren:
Met doelen, gebruikers en scope duidelijk, heb je een stabiele basis voor het scoringsmodel en workflowontwerp die volgen.
Een leveranciersscore-app leeft of sterft op de vraag of de score overeenkomt met de praktijk. Voordat je schermen bouwt, beschrijf de exacte KPI's, schalen en regels zodat procurement, operations en finance resultaten hetzelfde interpreteren.
Begin met een kernset die de meeste teams herkennen:
Houd definities meetbaar en koppel elke KPI aan een databron of een beoordelingsvraag.
Kies ofwel 1–5 (makkelijk voor mensen) of 0–100 (meer fijnmazig), en definieer wat elk niveau betekent. Bijvoorbeeld: “On-time delivery: 5 = ≥ 98%, 3 = 92–95%, 1 = < 85%.” Duidelijke drempels verminderen discussies en maken beoordelingen vergelijkbaar.
Wijs categoriegewichten toe (bijv. Levering 30%, Kwaliteit 30%, SLA 20%, Kosten 10%, Responsiviteit 10%) en documenteer wanneer gewichten veranderen (verschillende contracttypen kunnen andere prioriteiten hebben).
Beslis hoe je met ontbrekende data omgaat:
Wat je ook kiest, pas het consequent toe en maak het zichtbaar in drill-down weergaven zodat teams “ontbrekend” niet als “goed” lezen.
Ondersteun meer dan één scorecard per leverancier zodat teams prestaties kunnen vergelijken per contract, regio of periode. Dit voorkomt dat problemen die aan een specifieke site of project zijn gebonden, worden weggemiddeld.
Documenteer hoe disputen scores beïnvloeden: of een metric achteraf kan worden gecorrigeerd, of een geschil de score tijdelijk markeert en welke versie als “officieel” geldt. Zelfs een eenvoudige regel als “scores worden opnieuw berekend wanneer een correctie is goedgekeurd, met een notitie die de wijziging uitlegt” voorkomt verwarring later.
Een schoon datamodel houdt scoring eerlijk, reviews traceerbaar en rapporten geloofwaardig. Je wilt betrouwbare antwoorden kunnen geven op vragen als “Waarom kreeg deze leverancier deze maand een 72?” en “Wat is er veranderd sinds vorig kwartaal?” zonder rond te moeten draaien of spreadsheets te gebruiken.
Minimaal definieer je deze entiteiten:
Deze set ondersteunt zowel ‘harde’ gemeten prestaties als ‘zachte’ gebruikersfeedback, die meestal verschillende workflows nodig hebben.
Modelleer de relaties expliciet:
Een veelgebruikte aanpak is:
scorecard_period (bijv. 2025-10)vendor_period_score (overall)vendor_period_metric_score (per metric, inclusief teller/noemer indien van toepassing)Voeg consistente velden toe over de meeste tabellen:
created_at, updated_at, en voor goedkeuringen submitted_at, approved_atcreated_by_user_id, plus approved_by_user_id waar relevantsource_system en externe identificatoren zoals erp_vendor_id, crm_account_id, erp_invoice_idconfidence-score of data_quality_flag om onvolledige feeds of schattingen te markerenDeze velden voeden auditsporen, geschilafhandeling en betrouwbare inkoopanalytics.
Scores veranderen omdat data laat binnenkomt, formules evolueren of iemand een mapping corrigeert. In plaats van geschiedenis te overschrijven, bewaar je versies:
calculation_run_id) op elke scorerij.Qua retentie: bepaal hoe lang je ruwe transacties vs. afgeleide scores bewaart. Vaak bewaar je afgeleide scores langer (minder opslag, hoge rapportagewaarde) en houd je ruwe ERP-extracten korter volgens beleid.
Behandel externe IDs als volwaardige velden, geen notities:
unique(source_system, external_id)).Deze basis maakt integraties, KPI-tracking, reviewmoderatie en auditability veel eenvoudiger te implementeren en uit te leggen.
Een leveranciersscore-app is slechts zo goed als de inputs. Plan vanaf dag één meerdere ingestieroutes, zelfs als je met één begint. De meeste teams hebben uiteindelijk een mix nodig van handmatige invoer voor randgevallen, bulkuploads voor historische data en API-sync voor doorlopende updates.
Handmatige invoer is nuttig voor kleine leveranciers, incidentele gebeurtenissen of wanneer een team direct een review wil vastleggen.
CSV-upload helpt bij het bootstrappen van het systeem met historische prestaties, facturen, tickets of leveringsrecords. Maak uploads voorspelbaar: publiceer een template en versieer het zodat wijzigingen imports niet stilletjes breken.
API-sync koppelt typisch aan ERP/inkooptools (PO's, ontvangsten, facturen) en servicesystemen zoals helpdesks (tickets, SLA-overtredingen). Geef de voorkeur aan incrementele sync (sinds de laatste cursor) om te vermijden dat je telkens alles ophaalt.
Stel duidelijke validatieregels tijdens import:
Bewaar ongeldige rijen met foutmeldingen zodat admins kunnen herstellen en opnieuw uploaden zonder context te verliezen.
Imports zitten soms fout. Ondersteun re-runs (idempotent op source IDs), backfills (historische perioden) en recalculation logs die vastleggen wat is veranderd, wanneer en waarom. Dit is cruciaal voor vertrouwen wanneer de score van een leverancier verschuift.
De meeste teams redden zich met dagelijkse/weekelijkse imports voor finance- en leveringsmetrics, plus near-real-time events voor kritische incidenten.
Toon een adminvriendelijke importpagina (bijv. /admin/imports) met status, aantal rijen, waarschuwingen en exacte fouten—zodat issues zichtbaar en oplosbaar zijn zonder ontwikkelaarshulp.
Duidelijke rollen en een voorspelbaar goedkeuringspad voorkomen “scorecard-chaos”: conflicterende bewerkingen, onverwachte waardeveranderingen en onzekerheid over wat een leverancier kan zien. Definieer toegangsregels vroeg en handhaaf ze consequent in UI en API.
Een praktisch basissetje rollen:
Vermijd vage permissies als “kan leveranciers beheren.” Controleer in plaats daarvan specifieke mogelijkheden:
Overweeg “export” op te splitsen in “eigen leveranciers exporteren” vs. “alles exporteren”, vooral voor procurement analytics.
Leveranciersgebruikers zouden doorgaans alleen hun eigen data moeten zien: hun scores, gepubliceerde reviews en de status van openstaande items. Beperk standaard details over beoordelaars (bijv. toon afdeling of rol in plaats van volledige naam) om interpersoonlijke wrijving te verminderen. Als je leveranciers reacties toestaat, houd die threaded en duidelijk als leverancier-provided gelabeld.
Behandel reviews en scorewijzigingen als voorstellen totdat ze goedgekeurd zijn:
Tijdgebonden workflows helpen: bv. scorewijzigingen vereisen goedkeuring alleen tijdens maand-/kwartaalafsluiting.
Voor compliance en verantwoordelijkheid log je elk betekenisvol event: wie wat deed, wanneer, vanaf waar en wat is veranderd (voor/na-waarden). Auditregels moeten permissiewijzigingen, bewerkingsgeschiedenis, goedkeuringen, publicaties, exports en deleties dekken. Maak de audittrail doorzoekbaar, exporteerbaar voor audits en bescherm tegen manipulatie (append-only opslag of onveranderlijke logs).
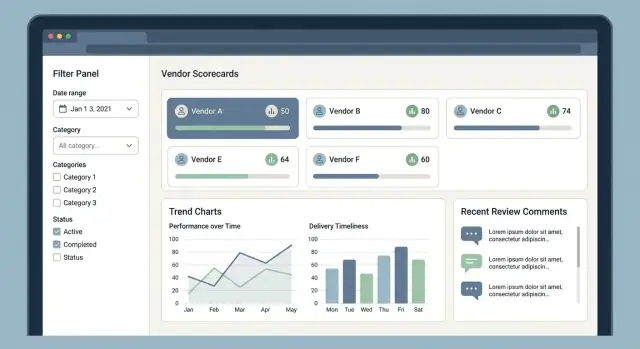
Een leveranciersscore-app slaagt of faalt op basis van of drukbezette gebruikers snel de juiste leverancier vinden, de score in één oogopslag begrijpen en betrouwbare feedback zonder wrijving kunnen achterlaten. Begin met een beperkte set “home base”-schermen en maak elk getal uitlegbaar.
Hier beginnen de meeste sessies. Houd de layout simpel: leveranciersnaam, categorie, regio, huidige scoreband, status en laatste activiteit.
Filteren en zoeken moet direct en voorspelbaar aanvoelen:
Sla veelgebruikte weergaven op (bv. “Kritische leveranciers in EMEA onder 70”) zodat procurementteams niet elke dag filters opnieuw hoeven te bouwen.
Het leveranciersprofiel moet samenvatten “wie ze zijn” en “hoe ze presteren” zonder gebruikers te dwingen te vroeg in tabs te klikken. Zet contactgegevens en contractmetadata naast een duidelijke scoresamenvatting.
Toon de totaalscore en de KPI-onderverdeling (kwaliteit, levering, kosten, compliance). Elke KPI heeft een zichtbare bron: de onderliggende reviews, issues of metrics die hem hebben geproduceerd.
Een goed patroon is:
Maak reviewinvoer mobielvriendelijk: grote touchtargets, korte velden en snelle commentaarmogelijkheden. Koppel reviews altijd aan een tijdsperiode en (indien relevant) een aankooporder, site of project zodat feedback actiegericht blijft.
Rapporten moeten antwoord geven op veelgestelde vragen: “Welke leveranciers gaan achteruit?” en “Wat is er deze maand veranderd?” Gebruik leesbare grafieken, duidelijke labels en toetsenbordnavigatie voor toegankelijkheid.
Reviews brengen context, bewijs en het “waarom” achter de cijfers. Om ze consistent (en verdedigbaar) te houden, behandel reviews eerst als gestructureerde records en daarna als vrij tekstveld.
Verschillende momenten vragen om verschillende reviewtemplates. Een eenvoudig begin:
Elk type kan gemeenschappelijke velden delen maar toestaan dat er type-specifieke vragen zijn, zodat teams incidenten niet in een kwartaalformulier hoeven te proppen.
Naast een verhalend commentaar, voeg gestructureerde inputs toe die filtering en rapportage aansturen:
Deze structuur verandert “feedback” in traceerbaar werk, niet alleen tekst in een veld.
Laat beoordelaars bewijs bijvoegen op dezelfde plek waar ze de review schrijven:
Sla metadata op (wie uploadde, wanneer, waar het betrekking op heeft) zodat audits geen speurtocht worden.
Zelfs interne tools hebben moderatie nodig. Voeg toe:
Vermijd stille edits—transparantie beschermt zowel beoordelaars als leveranciers.
Definieer notificatieregels vooraf:
Goed geregeld maken reviews een gesloten feedbackloop in plaats van een eenmalige klacht.
Je eerste architectuurbeslissing gaat minder over “de nieuwste tech” en meer over hoe snel je een betrouwbare leverancier-score- en reviewplatform kunt leveren zonder een onderhoudslast te creëren.
Als je snel wilt valideren, overweeg dan het prototypen van de workflow (vendors → scorecards → reviews → approvals → reports) op een platform dat een werkende app uit een duidelijke specificatie kan genereren. Bijvoorbeeld, Koder.ai is een vibe-coding platform waar je web-, backend- en mobiele apps kunt bouwen via een chatinterface en vervolgens de broncode kunt exporteren als je verder wilt. Het is een praktische manier om het scoringsmodel en rollen/permissies te valideren voordat je zwaar investeert in custom UI en integraties.
Voor de meeste teams is een modulaire monolith het gouden midden: één deployable app, georganiseerd in duidelijke modules (Vendors, Scorecards, Reviews, Reporting, Admin). Je krijgt eenvoudige ontwikkeling en debugging, plus minder complexe beveiliging en deployments.
Scheid services pas wanneer je een sterke reden hebt—bijv. zware rapportagebelastingen, meerdere productteams of strikte isolatievereisten. Een veelgebruikte evolutie is: monolith nu, split imports/reporting later als dat nodig is.
Een REST API is meestal het eenvoudigst te begrijpen en te integreren met inkooptools. Streef naar voorspelbare resources en enkele “task”-endpoints waar het systeem echt werk doet.
Voorbeelden:
/api/vendors (create/update vendors, status)/api/vendors/{id}/scores (huidige score, historische uitsplitsing)/api/vendors/{id}/reviews (lijst/maken reviews)/api/reviews/{id} (update, moderatie-acties)/api/exports (request exports; retourneert job id)Houd zware operaties (exports, bulk-herberekeningen) asynchroon zodat de UI responsief blijft.
Gebruik een jobqueue voor:
Dit helpt ook bij retries zonder handmatig brandje blussen.
Dashboards kunnen kostbaar zijn. Cache geaggregeerde metrics (per datumbereik, categorie, business unit) en invalideer bij betekenisvolle veranderingen, of vernieuw op schema. Zo blijft het dashboard snel terwijl drill-down data nauwkeurig blijft.
Schrijf API-docs (OpenAPI/Swagger is prima) en onderhoud een interne, adminvriendelijke gids in een blog-achtige stijl—bijv. “Hoe scoring werkt”, “Hoe om te gaan met betwiste reviews”, “Hoe exports draaien”—en link er vanuit je app naar /blog zodat het makkelijk te vinden en actueel te houden is.
Leveranciersscoredata kan contracten en reputaties beïnvloeden, dus je hebt voorspelbare, controleerbare en auditbare beveiligingsmaatregelen nodig die ook gemakkelijk te gebruiken zijn voor niet-technische mensen.
Begin met de juiste inlogopties:
Koppel authenticatie aan rolgebaseerde toegangscontrole (RBAC): procurement admins, reviewers, approvers en read-only stakeholders. Houd permissies fijnmazig (bv. “scores bekijken” vs “reviewtekst bekijken”). Bewaar een audittrail voor scorewijzigingen, goedkeuringen en bewerkingen.
Versleutel data in transit (TLS) en at rest (database + backups). Behandel secrets (DB-wachtwoorden, API-sleutels, SSO-certificaten) serieus:
Zelfs als de app “intern” is, kunnen publieke endpoints (wachtwoordreset, uitnodigingslinks, review-submissie) worden misbruikt. Voeg rate limiting en botbescherming (CAPTCHA of risicoscoring) toe waar zinvol, en lock API's met scopebare tokens.
Reviews bevatten vaak namen, e-mails of incidentdetails. Minimaliseer persoonlijke data standaard (gestructureerde velden boven vrije tekst), definieer retentieregels en bied tools om te redigeren of te verwijderen wanneer nodig.
Log genoeg om te debuggen (request IDs, latency, foutcodes), maar vermijd het vastleggen van vertrouwelijke reviewtekst of bijlagen. Gebruik monitoring en alerts voor mislukte imports, scoring job-fouten en ongewone toegangspatronen—zonder dat je logs een tweede database van gevoelige inhoud worden.
Een leveranciersscore-app is alleen nuttig zolang beslissingen eruit volgen. Rapportage moet drie vragen snel beantwoorden: Wie presteert goed, vergeleken met wat, en waarom?
Begin met een executive dashboard dat totale score, scoreveranderingen in de tijd en een categorie-uitsplitsing (kwaliteit, levering, compliance, kosten, service, etc.) samenvat. Trendlijnen zijn cruciaal: een leverancier met iets lagere score maar sterke verbetering kan beter zijn dan een hoge scorer die achteruitgaat.
Maak dashboards filterbaar op periode, business unit/site, leveranciercategorie en contract. Gebruik consistente defaults (bv. “laatste 90 dagen”) zodat twee kijkers vergelijkbare antwoorden krijgen.
Benchmarking is krachtig en gevoelig. Laat gebruikers leveranciers vergelijken binnen dezelfde categorie (bijv. “Verpakkingsleveranciers”) terwijl je permissies afdwingt:
Zo voorkom je onbedoelde openbaarmaking en ondersteun je toch selectiebeslissingen.
Dashboards moeten linken naar drill-down rapporten die scorebeweging verklaren:
Een goede drill-down eindigt met “wat is er gebeurd” bewijs: gerelateerde reviews, incidenten, tickets of verzendrecords.
Ondersteun CSV voor analyse en PDF voor delen. Exports moeten op schermfilters lijken, een timestamp bevatten en optioneel een alleen-intern-watermerk (en kijkeridentiteit) toevoegen om doorsluizen buiten de organisatie te ontmoedigen.
Vermijd “black box” scores. Elke leveranciersscore moet een duidelijke uitsplitsing hebben:
Wanneer gebruikers de berekening kunnen zien, verlopen disputen sneller en worden verbeterplannen eenvoudiger overeengekomen.
Testen van een leveranciersscore- en reviewplatform gaat niet alleen om bugs vangen—het beschermt vertrouwen. Procurementteams moeten erop vertrouwen dat een score klopt en leveranciers moeten zeker zijn dat reviews en goedkeuringen consistent worden behandeld.
Maak kleine, herbruikbare testdatasets met edgecases: ontbrekende KPI's, late inzendingen, tegenstrijdige waarden tussen imports en disputen (bijv. een leverancier betwist een leverings-SLA). Voeg gevallen toe waar een leverancier geen activiteit heeft of waar KPI's bestaan maar uitgesloten moeten worden vanwege ongeldige datums.
Je scoreberekeningen zijn het hart van het product, test ze als een financiële formule:
Unit tests moeten niet alleen eindscores controleren, maar ook tussenliggende componenten (per-KPI scores, normalisatie, boetes/bonussen) zodat fouten makkelijker te debuggen zijn.
Integratietests simuleren end-to-end flows: import van een leveranciersscorecard, toepassen van permissies en zekerstellen dat alleen de juiste rollen kunnen bekijken, reageren, goedkeuren of escaleren. Voeg tests toe voor audittrail-entries en geblokkeerde acties (bv. een leverancier die probeert een goedgekeurde review te bewerken).
Voer user acceptance tests uit met procurement en een pilotgroep van leveranciers. Meet verwarrende momenten en verbeter UI-tekst, validatie en help-hints.
Rond af met performance-tests voor piekperiodes (maand/kwartaalafsluiting), gericht op dashboardlaadtijden, bulk-exports en gelijktijdige herberekeningstaken.
Een leveranciersscore-app slaagt wanneer mensen hem daadwerkelijk gebruiken. Dat betekent meestal gefaseerd uitrollen, spreadsheets zorgvuldig vervangen en verwachtingen scheppen over wat verandert (en wanneer).
Begin met de kleinste versie die nog steeds bruikbare scorecards oplevert.
Fase 1: Alleen intern scorecards. Geef procurement en stakeholderteams een nette plek om KPI-waarden vast te leggen, leverancier-scorecards te genereren en interne aantekeningen te bewaren. Houd de workflow simpel en focus op consistentie.
Fase 2: Leveranciers toegang. Zodra interne scoring stabiel voelt, nodig leveranciers uit om eigen scorecards te bekijken, te reageren op feedback en context toe te voegen (bijv. “vertraging door havenstoring”). Hier worden permissies en auditspoor belangrijk.
Fase 3: Automatisering. Voeg integraties en geplande herberekening toe als je het scoringsmodel vertrouwt. Te vroeg automatiseren kan slechte data of onduidelijke definities versterken.
Als je tijd naar pilot wilt verkorten, is dit een plek waar Koder.ai kan helpen: je kunt de kernworkflow (rollen, review-goedkeuring, scorecards, exports) snel neerzetten, itereren met procurement in “planningmodus” en later de code exporteren om integraties en compliance te verankeren.
Als je spreadsheets vervangt, plan een transitieperiode in plaats van een big-bang cutover.
Bied importtemplates die bestaande kolommen weerspiegelen (leveranciersnaam, periode, KPI-waarden, beoordelaar, notities). Voeg importhelpers toe zoals validatiefouten (“onbekende leverancier”), previews en een dry-run modus.
Bepaal ook of je historische data volledig migreert of alleen recente perioden. Vaak is het importeren van de laatste 4–8 kwartalen genoeg voor trendrapportage zonder migration tot datagearcheologie te maken.
Houd training kort en rol-specifiek:
Behandel scoringdefinities als een product. KPI's veranderen, categorieën groeien en gewichten evolueren.
Stel een herberekeningsbeleid vooraf in: wat gebeurt er als een KPI-definitie verandert? Herbereken je historische scores of behoud je originele berekening voor auditbaarheid? Veel teams behouden historische resultaten en herberekenen alleen vanaf een ingangsdatum.
Naarmate je verder komt dan de pilot, bepaal wat inbegrepen is in elke tier (aantal leveranciers, reviewcycli, integraties, geavanceerde rapportage, vendor-portal toegang). Als je een commercieel plan maakt, werk pakketten uit en verwijs naar /pricing voor details.
Als je build vs buy vs accelerate evalueert, kun je ook “hoe snel kunnen we een betrouwbaar MVP leveren?” als input gebruiken voor packaging. Platforms zoals Koder.ai (met tiers van gratis tot enterprise) kunnen een praktische brug zijn: snel bouwen en itereren, deployen en hosten, en toch de optie behouden om de volledige broncode te exporteren en te bezitten zodra je leveranciersscoreprogramma rijper is.
Begin met het benoemen van één “kerngebruiker” en optimaliseer de eerste release voor hun workflow (vaak procurement). Schrijf op:
Voeg features voor finance/operations pas toe als je duidelijk kunt uitleggen welke nieuwe beslissing dat mogelijk maakt.
Kies vroeg één definitie en ontwerp je datamodel daaromheen:
Als je twijfelt, modelleer een leverancier als een parent met child “vendor units” (sites/servicelijnen) zodat je kunt roll-uppen of inzoomen later.
Gebruik gewogen KPI's wanneer je betrouwbare operationele data hebt en je wilt automatisering en transparantie. Gebruik rubrics wanneer prestatie grotendeels kwalitatief is of inconsistent tussen teams.
Een praktische standaard is hybride:
Welke je ook kiest, maak de methode uitlegbaar voor auditors en leveranciers.
Begin met een klein setje dat de meeste stakeholders herkennen en consistent kunnen meten:
Voor elke KPI: documenteer definitie, schaal en databron voordat je UI of rapporten bouwt.
Kies een schaal die mensen hardop kunnen beschrijven (veelal 1–5 of 0–100) en definieer thresholds in gewone taal.
Voorbeeld:
Vermijd ‘gevoelscijfers’. Duidelijke thresholds verminderen meningsverschillen en maken vergelijkingen eerlijk tussen teams en locaties.
Kies en documenteer één beleid per KPI (en pas het consistent toe):
Sla ook een data-quality indicator op (bv. ) zodat rapporten “slechte prestatie” onderscheiden van “onbekende prestatie.”
Behandel geschillen als een workflow met traceerbare uitkomsten:
Bewaar een versie-id (bijv. calculation_run_id) zodat je betrouwbaar kunt antwoorden op “wat is er veranderd sinds vorig kwartaal?”.
Een solide minimumschema bevat doorgaans:
Voeg velden toe die je nodig hebt voor traceerbaarheid: timestamps, actor-IDs, source system + external IDs, en een score-/versieverwijzing zodat elk getal uitlegbaar en reproduceerbaar is.
Plan meerdere ingestiepaden, ook als je met één begint:
Handhaaf bij import vereiste velden, numerieke bereiken en duplicaatdetectie. Bewaar ongeldige rijen met duidelijke foutmeldingen zodat admins kunnen corrigeren en opnieuw uploaden zonder context te verliezen.
Gebruik rolgebaseerde toegang en behandel wijzigingen als voorstellen:
Log elk betekenisvol event (bewerkingen, goedkeuringen, exports, permissiewijzigingen) met vóór/na-waarden. Dit beschermt vertrouwen en maakt audits overzichtelijk—vooral zodra leveranciers kunnen inzien of reageren.
data_quality_flag