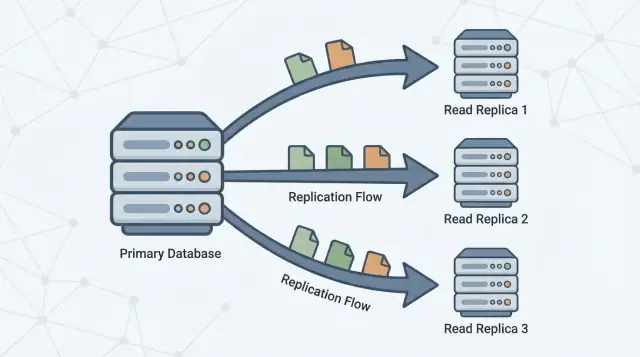
Wat een read replica is (en wat niet)
Een read replica is een kopie van je hoofd-database (vaak de primary genoemd) die up-to-date blijft doordat hij continu wijzigingen van die primary ontvangt. Je applicatie kan alleen-lezen queries (zoals SELECT) naar de replica sturen, terwijl de primary alle writes (zoals INSERT, UPDATE, en DELETE) blijft afhandelen.
De basisbelofte
De belofte is eenvoudig: meer lees-capaciteit zonder extra druk op de primary.
Als je app veel “haal”-verkeer heeft—homepages, productpagina's, gebruikersprofielen, dashboards—kan het verplaatsen van een deel van die reads naar één of meer replicas de primary vrijmaken om zich op write-werk en kritieke reads te concentreren. In veel setups kan dit met minimale aanpassingen aan de applicatie: je houdt één database als bron van waarheid en voegt replicas toe als extra plekken om queries naartoe te sturen.
Wat een read replica niet is
Read replicas zijn nuttig, maar geen magische prestatieknop. Ze doen niet:
- Write-capaciteit vergroten. Alle writes landen nog steeds op de primary.
- Trage queries oplossen. Als een query inefficiënt is (ontbrekende indexen, grootschalige scans, slechte join-patronen) zal die waarschijnlijk ook traag zijn op replicas—alleen ergens anders.
- Goede schema- en datadesign vervangen. Replicas lossen geen hot spots, te grote rijen, of een overvolle “alles”-tabel op.
- De noodzaak voor monitoring wegnemen. Replicas voegen bewegende delen toe: lag, verbindingslimieten en failover-gedrag.
Verwachtingen voor de rest van de gids
Zie replicas als een tool voor read-scaling met compromissen. De rest van dit artikel legt uit wanneer ze echt helpen, op welke manieren ze vaak misgaan, en hoe concepten als replicatie-lag en eventual consistency beïnvloeden wat gebruikers zien wanneer je vanaf een kopie leest in plaats van de primary.
Waarom read replicas bestaan
Een enkele primary-database server voelt vaak eerst “groot genoeg”. Hij verwerkt writes (inserts, updates, deletes) en beantwoordt ook elke read-aanvraag (SELECT queries) vanuit je app, dashboards en interne tools.
Naarmate het gebruik groeit, nemen reads meestal sneller toe dan writes: iedere paginavertoning kan meerdere queries triggeren, zoekschermen kunnen veel lookup-verzoeken genereren, en analytics-achtige queries kunnen veel rijen scannen. Zelfs bij matig write-volume kan de primary een bottleneck worden omdat hij twee taken tegelijk moet uitvoeren: wijzigingen veilig en snel accepteren én een groeiende berg read-verkeer met lage latency bedienen.
Reads scheiden van writes
Read replicas bestaan om die werklast te splitsen. De primary blijft zich richten op het verwerken van writes en het behouden van de “bron van waarheid”, terwijl één of meer replicas alleen-lezen queries behandelen. Als je applicatie bepaalde queries naar replicas kan routeren, verminder je CPU-, geheugen- en I/O-druk op de primary. Dat verbetert meestal de algehele reactietijd en laat meer ruimte voor write-bursts.
Replicatie in één zin
Replicatie is het mechanisme dat replicas up-to-date houdt door wijzigingen van de primary naar andere servers te kopiëren. De primary registreert wijzigingen, en replicas passen die wijzigingen toe zodat ze queries kunnen beantwoorden met vrijwel dezelfde data.
Dit patroon komt veel voor in verschillende databasesystemen en managed services (bijvoorbeeld PostgreSQL, MySQL en cloudvarianten). De exacte implementatie verschilt, maar het doel is hetzelfde: meer lees-capaciteit toevoegen zonder de primary eeuwig verticaal te moeten schalen.
Hoe replicatie werkt (eenvoudig mentaal model)
Zie de primary database als de “bron van waarheid”. Hij accepteert elke write—bestellingen aanmaken, profielen updaten, betalingen registreren—en kent die wijzigingen een vaste volgorde toe.
Eén of meer read replicas volgen vervolgens de primary, kopiëren die wijzigingen en kunnen zo read-queries beantwoorden (zoals “toon mijn bestelgeschiedenis”) zonder extra belasting op de primary.
De basisstroom
- Primary accepteert writes en legt ze vast in een duurzaam log (de exacte naam verschilt per database).
- Replicas streamen of halen die log-entries op van de primary.
- Replicas spelen dezelfde wijzigingen opnieuw af in dezelfde volgorde en lopen geleidelijk bij.
Reads kunnen vanaf replicas bediend worden, maar writes gaan nog steeds naar de primary.
Synchrone vs asynchrone replicatie (hoog niveau)
Replicatie kan in twee brede modi gebeuren:
- Synchronous: de primary wacht tot een replica (of een quorum) bevestigt dat de wijziging is ontvangen voordat de write als "committed" wordt beschouwd. Dit vermindert stale reads, maar kan write-latentie verhogen en maakt writes gevoeliger voor replica-/netwerkproblemen.
- Asynchronous: de primary commit de write onmiddellijk en replicas lopen later bij. Dit houdt writes snel en veerkrachtig, maar replicas kunnen tijdelijk achterlopen.
Replicatie-lag en “eventual consistency”
Die vertraging—replicas die achterlopen op de primary—noemen we replicatie-lag. Het is niet per definitie een fout; het is vaak de normale afweging die je accepteert om reads te schalen.
Voor eindgebruikers verschijnt lag als eventual consistency: nadat je iets verandert, wordt het systeem overal consistent, maar niet altijd direct.
Voorbeeld: je werkt je e-mailadres bij en vernieuwt je profielpagina. Als die pagina vanaf een replica wordt geserveerd die een paar seconden achterloopt, zie je tijdelijk het oude e-mailadres—totdat de replica de update toepast en "ingehaald" is.
Wanneer read replicas echt helpen
Read replicas helpen wanneer je primary-database gezond is voor writes maar overweldigd raakt door het bedienen van read-verkeer. Ze zijn het meest effectief wanneer je een substantieel deel van SELECT-load kunt offloaden zonder je schrijfbewerkingen te veranderen.
Signalen dat je read-bound bent (niet write-bound)
Let op patronen zoals:
- Hoge CPU op de primary tijdens pieken, terwijl write-throughput niet uitzonderlijk hoog is
- Een zeer hoge ratio
SELECT queries vergeleken met INSERT/UPDATE/DELETE
- Read-queries die langzamer worden tijdens pieken terwijl writes stabiel blijven
- Connection pool saturatie veroorzaakt door read-zware endpoints (productpagina's, feeds, zoekresultaten)
Hoe te bevestigen dat reads het probleem zijn (metrics om te checken)
Voordat je replicas toevoegt, valideer met concrete signalen:
- CPU vs I/O: Staat de primary-CPU vast wanneer read-latentie stijgt? Of is disk read I/O de bottleneck?
- Query mix: Percentage tijd besteed aan
SELECT statements (uit slow query log/APM).
- p95/p99 read-latentie: Track read-endpoints en database query-latentie apart.
- Buffer/cache hit rate: Een lage hit rate kan betekenen dat reads schijftoegang forceren.
- Top queries by total time: Eén dure query kan de "read load" domineren.
Sla goedkopere fixes niet over
Vaak is de beste eerste stap tuning: voeg de juiste index toe, herschrijf één query, verminder N+1 calls, of cache hot reads. Deze wijzigingen kunnen sneller en goedkoper zijn dan het beheren van replicas.
Korte checklist: replicas vs tuning
Kies replicas als:
- Het grootste deel van de load read-verkeer is en reads al redelijk geoptimaliseerd zijn
- Je occasionele verouderde reads voor de offloaded queries kunt verdragen
- Je snel extra capaciteit nodig hebt zonder risicovolle schema/query-wijzigingen
Kies eerst tuning als:
- Een paar queries het grootste deel van de leestijd domineren
- Ontbrekende indexen of inefficiënte joins duidelijk zijn
- Reads traag zijn zelfs bij laag verkeer (een teken van query-ontwerp problemen)
Best-fit gebruiksscenario's
Read replicas zijn het meest waardevol wanneer je primary druk is met writes (checkouts, aanmeldingen, updates), maar een groot deel van het verkeer read-intensief is. In een primary–replica architectuur verbetert het naar de juiste queries naar replicas sturen de databaseprestaties zonder features in de applicatie te veranderen.
1) Dashboards en analytics die transacties niet mogen vertragen
Dashboards draaien vaak lange queries: groeperen, filteren over grote datumbereiken of joins over meerdere tabellen. Die queries kunnen concurreren met transactioneel werk voor CPU, geheugen en cache.
Een read replica is een goede plek voor:
- Interne rapportageworkloads
- Admin-dashboards
- "Dagelijkse/wekelijkse metrics" views
Je houdt de primary gefocust op snelle, voorspelbare transacties terwijl analytics-reads onafhankelijk schalen.
2) Zoek- en browsepagina's met veel leesverkeer
Catalog-browsing, gebruikersprofielen en content-feeds kunnen veel gelijkaardige read-queries produceren. Als die read-schaal de bottleneck is, kunnen replicas het verkeer absorberen en latentiepieken verminderen.
Dit werkt vooral goed wanneer reads veel cache-misses veroorzaken (veel unieke queries) of wanneer je niet uitsluitend op een applicatiecache kunt vertrouwen.
3) Achtergrondjobs die veel data scannen
Exports, backfills, het opnieuw berekenen van samenvattingen en "vind alle records die aan X voldoen"-jobs kunnen de primary belasten. Deze scans op een replica draaien is vaak veiliger.
Zorg er wel voor dat de job eventual consistency tolereert: door replicatie-lag ziet de job mogelijk de nieuwste updates niet.
4) Multi-region reads voor lagere latency (met stalenheid-aantekeningen)
Als je gebruikers wereldwijd bedient, kan het plaatsen van read replicas dichter bij hen round-trip time verkorten. De afweging is dat je meer blootstaat aan stale reads tijdens lag of netwerkproblemen, dus dit is het beste voor pagina's waar "bijna up-to-date" acceptabel is (browse, aanbevelingen, openbare content).
Waar replicas kunnen tegenwerken
Begin met Go en Postgres
Genereer een Go + PostgreSQL backend en bepaal vroege read- en write-paden.
Read replicas zijn geweldig als "close enough" volstaat. Ze werken tegen als je product stilzwijgend verwacht dat elke read de laatste write reflecteert.
Het klassieke symptoom: “Ik heb het net aangepast, waarom is het niet veranderd?”
Een gebruiker bewerkt zijn profiel, verstuurt een formulier of wijzigt accountinstellingen—en de volgende paginalaad wordt vanaf een replica geserveerd die een paar seconden achterloopt. De update is gelukt, maar de gebruiker ziet oude data en probeert het opnieuw, submit dubbel, of verliest vertrouwen.
Dit is vooral pijnlijk in flows waar directe bevestiging verwacht wordt: e-mail wijzigen, voorkeuren wisselen, een document uploaden of een comment posten en vervolgens teruggeplaatst worden.
Schermen die “actueel moeten zijn” (neem hier geen risico)
Sommige reads kunnen zelfs kortstondig geen stale waarden verdragen:
- Winkelwagens en checkout-totals
- Wallet-saldi, loyaliteitspunten, voorraadcounts
- "Is mijn betaling doorgegaan?" status-schermen
Als een replica achterloopt, kun je het verkeerde winkelwagenbedrag tonen, voorraad oversellen of een verouderd saldo tonen. Zelfs als het systeem zichzelf later corrigeert, lijdt de gebruikerservaring (en het support-volume).
Interne dashboards sturen vaak echte beslissingen: fraudereview, klantenservice, orderafhandeling, moderatie en incident response. Als een admin-tool van replicas leest, loop je het risico op handelen op onvolledige data—bijv. terugbetalen van een order die al terugbetaald is, of het missen van de laatste statuswijziging.
Praktische oplossing: routeer "read-your-writes" naar de primary
Een gebruikelijk patroon is conditionele routing:
- Nadat een gebruiker schrijft, stuur hun opvolgende bevestigingsreads voor een korte periode (seconden tot minuten) naar de primary.
- Houd achtergrond-, anonieme of niet-kritieke reads op replicas.
Dit behoudt de voordelen van replicas zonder van consistentie een gokspel te maken.
Replicatie-lag en verouderde reads begrijpen
Replicatie-lag is de vertraging tussen het moment dat een write op de primary wordt gecommit en wanneer diezelfde verandering zichtbaar wordt op een read replica. Als je applicatie leest van een replica tijdens die vertraging, kan die verouderde resultaten teruggeven—data die even geleden waar was, maar niet meer.
Waarom lag optreedt
Lag is normaal en groeit meestal onder stress. Veelvoorkomende oorzaken zijn:
- Load spikes op de primary: veel writes betekent meer wijzigingen om te verzenden en toe te passen.
- Replica ondergedimensioneerd of druk: de replica kan wijzigingen niet zo snel toepassen als ze binnenkomen (CPU, schijf I/O).
- Netwerklatentie of jitter: vertragingen in het verplaatsen van de replicatiestroom.
- Grote transacties / bulk-updates: één grote wijziging kan tijd kosten om te serialiseren, over te zetten en opnieuw af te spelen.
Hoe verouderde reads zich in de product-ervaring laten zien
Lag beïnvloedt niet alleen "versheid"—het beïnvloedt de correctheid vanuit gebruikersperspectief:
- Een gebruiker werkt zijn profiel bij en ziet bij verversen de oude waarde.
- "Ongelezen berichten" of notificatiebadges lopen achter omdat tellingen van licht verouderde rijen worden berekend.
- Admin/reporting schermen missen de meest recente orders, refunds of statuswijzigingen.
Praktische manieren om ermee om te gaan
Begin met beslissen wat jouw feature kan verdragen:
- Voeg een tolerantievenster toe: "Data kan tot 30 seconden oud zijn" is acceptabel voor veel dashboards.
- Route read-after-write naar de primary: na een gebruikerwijziging lees dat entiteit voor een korte periode van de primary.
- UI-communicatie: zet verwachtingen (“Bijwerken…”, “Kan enkele seconden duren voordat dit zichtbaar is”).
- Retry-logica: als een kritisch read-resultaat een net-geschreven record mist, probeer dan tegen de primary of probeer opnieuw na korte vertraging.
Wat te monitoren en te alarmen
Track replica lag (tijd/bytes achter), replica apply-rate, replicatiefouten en replica CPU/schijf I/O. Alarm wanneer lag je afgesproken tolerantie overschrijdt (bijv. 5s, 30s, 2m) en wanneer lag blijft stijgen over tijd (een teken dat de replica niet kan bijlopen zonder interventie).
Read-scaling vs write-scaling (belangrijke afwegingen)
Ontwerp voor lag van tevoren
Modelleer eventual consistency-gedrag nu zodat gebruikers later geen “Ik heb het net aangepast”-problemen krijgen.
Read replicas zijn een instrument voor read-scaling: meer plekken om SELECT queries te bedienen. Ze zijn geen instrument voor write-scaling: het verhogen van hoeveel INSERT/UPDATE/DELETE operaties je systeem kan accepteren.
Reads schalen: waar replicas goed in zijn
Als je replicas toevoegt, verhoog je lees-capaciteit. Als je applicatie gebottlenecked is op read-zware endpoints (productpagina's, feeds, lookups), kun je die queries over meerdere machines verspreiden.
Dit verbetert vaak:
- Query-latentie onder load (minder contentie op de primary)
- Throughput voor reads (meer CPU/geheugen/I/O beschikbaar voor
SELECTs)
- Isolatie voor zware reads, zoals rapportage-workloads, zodat ze transactioneel verkeer niet afremmen
Writes schalen: wat replicas niet doen
Een veelvoorkomend misverstand is dat "meer replicas = meer write-throughput". In een typisch primary-replica model gaan alle writes nog steeds naar de primary. Sterker nog: meer replicas kunnen iets meer werk voor de primary betekenen, omdat die replicatiegegevens naar elke replica moet genereren en verzenden.
Als je probleem write-throughput is, helpen replicas niet veel. Je kijkt dan meestal naar andere aanpakken (query/index tuning, batching, partitioning/sharding of het veranderen van het datamodel).
Verbindingslimieten en pooling: de verborgen bottleneck
Zelfs als replicas je meer read-CPU geven, kun je eerst tegen connection limits aanlopen. Elke database-node heeft een maximum aantal gelijktijdige verbindingen, en replicas toevoegen kan het aantal plekken waar je app verbinding mee kan maken vergroten—zonder de totale vraag te verminderen.
Praktische regel: gebruik connection pooling (of een pooler) en hou per-service verbindingsaantallen bewust. Anders worden replicas simpelweg "meer databases om te overbelasten."
Kostenafwegingen: capaciteit is niet gratis
Replicas voegen echte kosten toe:
- Meer nodes (compute-kosten)
- Meer opslag (elke replica slaat doorgaans een volledige kopie)
- Meer operationele inspanning (monitoring van lag, backup/restore strategie, schema-wijzigingen, incident response)
De afweging is simpel: replicas kunnen je lees-headroom en isolatie kopen, maar voegen complexiteit toe en verhogen niet het write-plafond.
High availability en failover: wat replicas kunnen doen
Read replicas kunnen de lees-beschikbaarheid verbeteren: als je primary overbelast of tijdelijk onbereikbaar is, kun je mogelijk nog steeds sommige alleen-lezen pagina's vanaf replicas serveren. Dat kan klantgerichte pagina's responsief houden (voor content die iets mag verouderen) en het blast radius van een primary-incident beperken.
Wat replicas niet bieden is een volledige HA-oplossing op zichzelf. Een replica is meestal niet klaar om automatisch writes te accepteren, en een "leesbare kopie bestaat" is anders dan "het systeem kan veilig en snel weer writes accepteren."
Failover betekent doorgaans: detecteer primary-fout → kies een replica → promoot deze tot nieuwe primary → routeer writes (en meestal reads) naar de gepromote node.
Sommige managed databases automatiseren dit grotendeels, maar de kern blijft hetzelfde: je verandert wie writes mag accepteren.
Belangrijke risico's om op te plannen
- Verouderde replica-data: de replica kan achterlopen. Als je die promoot, kun je de meest recente writes verliezen die nooit gerepliceerd werden.
- Split-brain voorkomen: je moet voorkomen dat twee nodes tegelijk writes accepteren. Daarom zijn promoties meestal geborgd door een enkele autoriteit (een managed control plane, een quorum-systeem of strikte operationele procedures).
- Routing en caches: je app heeft een betrouwbare manier nodig om targets te wisselen—connection strings, DNS, proxies of een database-router. Zorg dat write-verkeer niet per ongeluk naar de oude primary blijft gaan.
Test het als een feature
Behandel failover als iets wat je oefent. Voer game-day tests uit in staging (en zorgvuldig in productie tijdens lage-risico vensters): simuleer primair verlies, meet tijd-tot-herstel, verifieer routing en bevestig dat je app read-only periodes en herverbindingen netjes afhandelt.
Praktische routeringspatronen (read/write splitting)
Read replicas helpen alleen als je verkeer er daadwerkelijk naartoe gaat. "Read/write splitting" is de set regels die writes naar de primary stuurt en geschikte reads naar replicas—zonder correctheid te breken.
Patroon 1: Split in de applicatie
De eenvoudigste aanpak is expliciete routing in je data access layer:
- Alle writes (
INSERT/UPDATE/DELETE, schema-wijzigingen) gaan naar de primary.
- Alleen geselecteerde reads mogen een replica gebruiken.
Dit is makkelijk te begrijpen en terug te draaien. Hier kun je ook bedrijfsregels coderen zoals "na checkout altijd orderstatus van de primary lezen voor een korte tijd."
Patroon 2: Split via een proxy of driver
Sommige teams geven de voorkeur aan een databaseproxy of slimme driver die 'primary vs replica' endpoints begrijpt en routeert op basis van query-type of connection-instellingen. Dit vermindert applicatiecodeveranderingen, maar wees voorzichtig: proxy's kunnen niet betrouwbaar weten welke reads productmatig "veilig" zijn.
Kiezen welke queries veilig naar replicas kunnen
Goed kandidaten zijn:
- Analytics, rapportageworkloads, dashboards
- Zoek-/browsepagina's waar iets verouderde data acceptabel is
- Achtergrondjobs die retries doen en de nieuwste waarde niet nodig hebben
Vermijd reads die direct volgen op een gebruikers-write (bijv. "profiel bijwerken → profiel opnieuw laden") tenzij je een consistentiestrategie hebt.
Transacties en sessie-consistentie
Binnen een transactie: houd alle reads op de primary.
Buiten transacties: overweeg "read-your-writes" sessions: na een write pin die gebruiker/sessie tijdelijk op de primary (TTL), of routeer specifieke opvolgende queries naar de primary.
Begin klein en meet
Voeg één replica toe, routeer een beperkte set endpoints/queries en vergelijk voor/na:
- Primary CPU en read IOPS
- Replica-utilisatie
- Foutpercentages en latentiepercentielen
- Incidenten gerelateerd aan verouderde reads
Breid routing alleen uit wanneer de impact duidelijk en veilig is.
Monitoring en operationele basis
Plan Replica Ready Architectuur
Gebruik Koder.ai om een primary-replica plan te schetsen voordat je een regel backend-code schrijft.
Read replicas zijn geen "set-and-forget". Het zijn extra database-servers met hun eigen prestatielimieten, faalwijzen en operationele taken. Een beetje monitoringdiscipline is meestal het verschil tussen "replicas hielpen" en "replicas zorgden voor verwarring."
Wat te bewaken (de paar metrics die er echt toe doen)
Focus op indicatoren die gebruikersklachten verklaren:
- Replica lag: hoe ver een replica achter de primary is (seconden, bytes of WAL/LSN positie afhankelijk van de database). Dit is je vroege waarschuwing voor verouderde reads.
- Replicatiefouten: verbroken verbindingen, auth-fouten, schijf-vol of replicatie-slot issues. Behandel deze als incidenten, niet als "ruis".
- Query-latentie (p50/p95) op replicas vs primary: replicas kunnen traag zijn terwijl de primary oké is (verschillende cache-state, andere hardware, lange rapporten).
- Cache hit rate: een replica die constant cache-misses heeft kan hogere latentie tonen na restarts of traffic-shifts.
Capacity planning: hoeveel replicas heb je nodig?
Begin met één replica als doel is reads offloaden. Voeg er meer toe wanneer je een duidelijk knelpunt hebt:
- Read throughput: één replica kan piek-QPS of zware analytische queries niet bijhouden.
- Isolatie: wijd een replica aan reporting zodat dashboards geen resources van gebruikersverkeer stelen.
- Geografie: een replica per regio kan read-latentie verminderen, maar verhoogt operationele overhead.
Praktische regel: schaal replicas pas nadat je hebt bevestigd dat reads de bottleneck zijn (niet indexen, trage queries of app-caching).
Veelvoorkomende operationele taken
- Backups: bepaal waar backups draaien. Backups van een replica nemen kan de primary ontzien, maar verifieer consistentie-eisen en dat de replica gezond is.
- Schema-wijzigingen: test migraties met replicatie in gedachten (langlopende DDL kan lag verhogen). Coördineer uitrol zodat app- en schema-wijzigingen compatibel blijven tijdens propagatie.
- Onderhoudsvensters: patching of herstarten van replicas vermindert tijdelijk lees-capaciteit. Plan rotatie zodat je niet onder je vereiste read-headroom zakt.
Troubleshooting checklist: "replicas zijn traag"
- Check replica lag: als die hoog is, herhalen gebruikers mogelijk of zien ze verouderde data.
- Vergelijk slow query logs op replica vs primary: rapportagequeries komen hier vaak naar voren.
- Verifieer CPU, geheugen, schijf I/O en netwerk op de replica-host.
- Zoek naar lock-contentie of langlopende transacties op de primary die replicatie vertragen.
- Controleer of je read routing niet één replica overbelast (oneven load balancing).
- Valideer dat indexen op replicas bestaan (ze zouden de primary moeten spiegelen) en dat statistieken up-to-date zijn.
Alternatieven en een eenvoudig beslissingskader
Read replicas zijn één tool om reads te schalen, maar zelden de eerste hendel. Voordat je operationele complexiteit toevoegt, controleer of een eenvoudiger oplossing hetzelfde resultaat oplevert.
Alternatieven om eerst te proberen
Caching kan hele categorieën reads uit je database halen. Voor "read-mostly" pagina's (productdetails, openbare profielen, configuratie) kan een applicatiecache of CDN de load drastisch verlagen—zonder replicatie-lag.
Indexen en query-optimalisatie presteren vaak beter dan replicas voor de veel voorkomende gevallen: een paar dure queries die CPU verbranden. De juiste index toevoegen, SELECT-kolommen beperken, N+1 queries vermijden en slechte joins repareren kan van "we hebben replicas nodig" naar "we hadden gewoon een beter plan nodig" veranderen.
Materialized views / pre-aggregatie helpen wanneer de workload inherent zwaar is (analytics, dashboards). In plaats van complexe queries telkens opnieuw te draaien, sla je berekende resultaten op en ververs je periodiek.
Wanneer sharden/partitioneren overwegen
Als je writes de bottleneck zijn (hot rows, lock-contentie, write IOPS-limieten), helpen replicas weinig. Dan is partitioneren van tabellen op tijd/tenant of sharding op klant-ID een manier om write-load te verspreiden en contentie te verminderen. Het is een grotere architecturale stap, maar het adresseert de daadwerkelijke beperking.
Een simpel beslissingskader
Stel vier vragen:
- Wat is het doel? Read-latentie verlagen, rapportage workloads offloaden, of beschikbaarheid verbeteren?
- Hoe vers moeten reads zijn? Als je geen verouderde reads kunt tolereren, kunnen replicas zichtbare problemen geven.
- Wat is je budget? Replicas voegen infrastructuurkosten en operationele monitoring toe.
- Hoeveel complexiteit kun je dragen? Read/write splitting, omgaan met eventual consistency en failover-testen zijn niet-triviaal.
Als je een product prototype of snel een service opzet, helpt het om deze beperkingen vroeg in de architectuur te verwerken. Teams die op Koder.ai bouwen (een vibe-coding platform dat React-apps met Go + PostgreSQL backends genereert vanuit een chatinterface) beginnen vaak met één primary voor eenvoud en stappen over naar replicas zodra dashboards, feeds of interne rapportage gaan concurreren met transactioneel verkeer. Een planning-first workflow maakt het makkelijker om van tevoren te bepalen welke endpoints eventual consistency kunnen verdragen en welke altijd "read-your-writes" van de primary moeten komen.
Als je hulp wilt bij het kiezen van een pad, zie pricing voor opties, of blader door gerelateerde gidsen in blog.