03 apr 2025·8 min
State beheren tussen frontend en backend in AI-apps
Leer hoe UI-, sessie- en datastatus tussen frontend en backend bewegen in AI-apps, met praktische patronen voor synchronisatie, persistentie, caching en beveiliging.
Wat “state” betekent in een AI-applicatie
“State” is alles wat je app moet onthouden om van het ene moment op het andere correct te blijven functioneren.
Als een gebruiker in een chat-UI op Verzenden klikt, mag de app niet vergeten wat die gebruiker heeft getypt, wat de assistent al heeft geantwoord, of er nog een verzoek loopt, of welke instellingen (toon, model, tools) ingeschakeld zijn. Dat is allemaal state.
State, in gewone termen
Een handige manier om over state te denken is: de huidige waarheid van de app—waarden die bepalen wat de gebruiker ziet en wat het systeem daarna doet. Dat omvat voor de hand liggende dingen zoals formulierinvoer, maar ook “onzichtbare” feiten zoals:
- Welke conversatie de gebruiker voert
- Of het laatste antwoord nog streamed wordt of voltooid is
- De lijst met berichten en hun volgorde
- Tool-aanroepen en tool-resultaten (zoekresultaten, database-opzoekingen, bestands-extracts)
- Fouten, retries en rate-limit backoff
Waarom AI-apps meer bewegende delen hebben
Traditionele apps lezen vaak data, tonen die, en slaan updates op. AI-apps voegen extra stappen en tussenresultaten toe:
- Een enkele gebruikersactie kan meerdere backend-operaties triggeren (LLM-aanroep, tool-aanroep, nog een LLM-aanroep).
- Antwoorden kunnen incrementeel binnenkomen (gestreamde tokens), dus de UI moet gedeeltelijke state beheren.
- Context telt: het systeem moet mogelijk gespreksgeheugen, tool-uitvoer en modelinstellingen consistent houden over verzoeken heen.
Die extra beweging is waarom statebeheer vaak de verborgen complexiteit is in AI-toepassingen.
Wat deze gids behandelt
In de volgende secties verdelen we state in praktische categorieën (UI-state, sessie-state, gepersistente data en model/runtime-state) en laten zien waar elk daarvan hoort te leven (frontend vs. backend). We behandelen ook synchronisatie, caching, langlopende taken, streaming-updates en beveiliging—want state is alleen nuttig als het correct en beschermd is.
Kort voorbeeldscenario
Stel je een chat-app voor waarin een gebruiker vraagt: “Vat de facturen van afgelopen maand samen en markeer alles wat ongewoon is.” De backend zou kunnen (1) facturen ophalen, (2) een analysetool draaien, (3) een samenvatting naar de UI streamen en (4) het eindrapport opslaan.
Om dat naadloos te laten voelen, moet de app berichten, tool-resultaten, voortgang en de opgeslagen output bijhouden—zonder gesprekken door elkaar te halen of data tussen gebruikers te lekken.
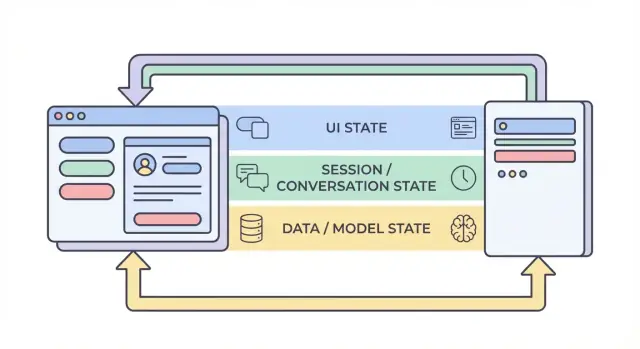
De vier lagen van state: UI, sessie, data en model
Als mensen “state” zeggen in een AI-app, vermengen ze vaak heel verschillende dingen. State in vier lagen splitsen—UI, sessie, data en model/runtime—maakt het makkelijker om te beslissen waar iets moet leven, wie het kan veranderen en hoe het opgeslagen moet worden.
1) UI-state (wat de gebruiker nu doet)
UI-state is de live, moment-voor-moment state in de browser of mobiele app: tekstvelden, toggles, geselecteerde items, welke tab open is en of een knop uitgeschakeld is.
AI-apps voegen een paar UI-specifieke details toe:
- Laadindicatoren en “denkende” statussen
- Gestreamde tokens (gedeeltelijke tekst die zichtbaar wordt terwijl deze gegenereerd wordt)
- Lokale conceptberichten (voordat ze verzonden zijn)
UI-state moet eenvoudig te resetten zijn en veilig te verliezen. Als de gebruiker de pagina ververst, kun je dit verliezen—en dat is meestal acceptabel.
2) Sessie / conversatie-state (gedeelde context voor een gebruikersflow)
Sessie-state koppelt een gebruiker aan een lopende interactie: gebruikersidentiteit, een conversation ID en een consistente weergave van de berichtgeschiedenis.
In AI-apps bevat dit vaak:
- Berichtgeschiedenis (of verwijzingen ernaar)
- Tool-traces (welke functies/tools werden aangeroepen en met welke resultaten)
- “Werkset”-keuzes zoals het huidige project/document, geselecteerd model of workspace
Deze laag overspant vaak frontend en backend: de frontend houdt lichte identificatoren, terwijl de backend de autoriteit is voor sessie-continuïteit en toegangcontrole.
3) Data-state (duurzame records in opslag)
Data-state is wat je bewust in een database opslaat: projecten, documenten, embeddings, voorkeuren, auditlogs, factureringsevenementen en opgeslagen conversatietranscripten.
In tegenstelling tot UI- en sessie-state moet data-state:
- Duurzaam zijn (overleeft restarts)
- Doorzoekbaar zijn (je kunt het zoeken/filteren)
- Controleerbaar zijn (je kunt later begrijpen wat er gebeurde)
4) Model / runtime-state (hoe de AI nu is geconfigureerd)
Model/runtime-state is de operationele setup die gebruikt wordt om een antwoord te produceren: system prompts, ingeschakelde tools, temperature/max tokens, veiligheidsinstellingen, rate limits en tijdelijke caches.
Een deel daarvan is configuratie (stabiele defaults); een deel is vluchtig (kortlevende caches of per-request token-budgetten). Het grootste deel hoort op de backend zodat het consistent beheerst kan worden en niet onnodig blootgesteld wordt.
Waarom scheiding bugs vermindert
Als deze lagen vervagen, krijg je klassieke fouten: de UI toont tekst die niet is opgeslagen, de backend gebruikt andere prompt-instellingen dan de frontend verwacht, of gespreksgeheugen lekt tussen gebruikers. Duidelijke grenzen creëren duidelijke bronnen van waarheid—en maken het duidelijk wat moet blijven, wat opnieuw berekend kan worden en wat beschermd moet worden.
Wat leeft op de frontend vs. de backend (en waarom)
Een betrouwbare manier om bugs in AI-apps te verminderen is: beslis voor elk stuk state waar het moet leven—in de browser (frontend), op de server (backend) of in beide. Deze keuze beïnvloedt betrouwbaarheid, beveiliging en hoe “verrassend” de app aanvoelt bij verversen, nieuwe tabbladen of netwerkverlies.
Frontend-state: snel, tijdelijk en gebruikersgestuurd
Frontend-state is het beste voor dingen die snel veranderen en niet hoeven te overleven bij verversen. Lokale opslag maakt de UI responsief en voorkomt onnodige API-aanroepen.
Veelvoorkomende frontend-only voorbeelden:
- Concepttekst die de gebruiker typt
- Lokale filters en sorteervolgorde in een tabel
- Modal open/dicht status, geselecteerde tab, hover-states
Als je deze state verliest bij verversen, is dat meestal acceptabel (en vaak verwacht).
Backend-state: gezaghebbend, gevoelig en gedeeld
Backend-state moet alles bevatten wat vertrouwd, controleerbaar of consequent gehandhaafd moet worden. Dit omvat state die andere apparaten/tabs moeten zien, of die correct moet blijven als de client is aangepast.
Veelvoorkomende backend-only voorbeelden:
- Permissies en rollen (wat de gebruiker mag doen)
- Facturering/abonnementstatus en gebruikslimieten
- Langlopende jobs (documentindexering, grote exports, fine-tune runs) en hun status
Een goede denkwijze: als foutieve state geld kan kosten, data kan lekken of toegang kan breken, hoort het op de backend.
Gedeelde state: gecoördineerd, maar met één bron van waarheid
Sommige state is van nature gedeeld:
- Conversatietitel
- Geselecteerde kennisbronnen voor een chat
- Gebruikersprofielvelden die op meerdere apparaten gebruikt worden
Zelfs wanneer gedeeld, kies een “bron van waarheid.” Gewoonlijk is de backend gezaghebbend en cachet de frontend een kopie voor snelheid.
Vuistregel (en een veelvoorkomend anti-patroon)
Houd state zo dicht mogelijk bij waar het nodig is, maar persist wat moet overleven bij verversen, apparaatwissel of onderbreking.
Vermijd het anti-patroon om gevoelige of gezaghebbende state alleen in de browser op te slaan (bijvoorbeeld een client-side isAdmin-vlag, plan-tier of job-completie status behandelen als waarheid). De UI mag deze waarden tonen, maar de backend moet ze verifiëren.
Een typische AI-request lifecycle: van klik tot voltooiing
Een AI-feature voelt als “één actie”, maar het is eigenlijk een keten van state-transities gedeeld tussen browser en server. Het begrijpen van de lifecycle helpt mismatches in de UI, ontbrekende context en dubbele kosten te vermijden.
1) Gebruikersactie → frontend bereidt intentie voor
Een gebruiker klikt op Verzenden. De UI werkt direct lokale state bij: het kan een “in afwachting”-bericht toevoegen, de verzendknop uitschakelen en de huidige input vastleggen (tekst, bijlagen, geselecteerde tools).
Op dit punt moet de frontend correlatie-identificatoren genereren of toevoegen:
- conversation_id: bij welke thread dit hoort
- message_id: de client-ID voor het nieuwe gebruikersbericht
- request_id: uniek per poging (handig voor retries)
Deze IDs laten beide zijden over hetzelfde event praten, zelfs wanneer antwoorden laat of dubbel binnenkomen.
2) API-aanroep → server valideert en persist
De frontend stuurt een API-verzoek met het gebruikersbericht plus de IDs. De server valideert permissies, rate limits en payload-shape, en slaat het gebruikersbericht op (of ten minste een onveranderlijk logrecord) keyed op conversation_id en message_id.
Deze persistence-stap voorkomt “fantoomgeschiedenis” wanneer de gebruiker de pagina ververst tijdens een lopend verzoek.
3) Server reconstrueert context
Om het model aan te roepen, bouwt de server context opnieuw op vanuit zijn bron van waarheid:
- Haal recente berichten op voor de conversation_id
- Haal gerelateerde records op (documenten, voorkeuren, tool-uitvoer)
- Pas conversatiepolicies toe (system prompts, geheugenregels, truncatie)
Het sleutelidee: vertrouw de client niet om de volledige geschiedenis te leveren. De client kan verouderd zijn.
4) Model/tool-executie → tussenliggende state
De server kan tools aanroepen (zoekopdracht, database-query) vóór of tijdens modelgeneratie. Elke tool-aanroep produceert tussenliggende state die moet worden gevolgd tegen de request_id zodat het geaudit en veilig herhaald kan worden.
5) Antwoord (streaming of niet) → UI-voltooiing
Bij streaming stuurt de server gedeeltelijke tokens/events. De UI werkt het in afwachting zijnde assistentbericht incrementeel bij, maar behandelt het nog als “in uitvoering” totdat een finale gebeurtenis voltooiing markeert.
6) Faalpunten om op te plannen
Retries, dubbele submits en out-of-order responses gebeuren. Gebruik request_id om te dedupliceren op de server, en message_id om in de UI te reconciliëren (negeer late chunks die niet bij de actieve aanvraag passen). Toon altijd een duidelijke “mislukt”-status met een veilige retry die geen dubbele berichten creëert.
Sessies en gespreksgeheugen: context behouden zonder chaos
Ship met rollback-veiligheid
Itereer op state-wijzigingen met vertrouwen dankzij snapshots en rollback in Koder.ai.
Een sessie is de “thread” die de acties van een gebruiker verbindt: welke workspace ze gebruiken, wat ze laatst zochten, welke concepten ze aan het bewerken waren en welke conversatie een AI-antwoord moet voortzetten. Goede sessie-state zorgt dat de app continuïteit voelt over pagina's heen—en idealiter over apparaten—zonder je backend te veranderen in een opslagplaats voor alles wat de gebruiker ooit zei.
Doelen voor sessie-state
Streef naar: (1) continuïteit (een gebruiker kan weggaan en terugkomen), (2) correctheid (de AI gebruikt de juiste context voor de juiste conversatie), en (3) isolatie (één sessie mag niet in een andere lekken). Als je meerdere apparaten ondersteunt, behandel sessies als user-scoped plus device-scoped: “zelfde account” betekent niet altijd “zelfde geopende werk”.
Cookies vs. tokens vs. server-sessies
Je kiest meestal één van deze manieren om de sessie te identificeren:
- Cookies: het eenvoudigst voor webapps omdat de browser ze automatisch meestuurt. Geweldig voor traditionele sessies, maar je moet beveiligingsflags instellen (
HttpOnly,Secure,SameSite) en CSRF goed afhandelen. - Tokens (bijv. JWT): goed voor API's en mobiele apps omdat de client ze expliciet kan meesturen. Ze schalen goed, maar intrekking en rotatie vereisen extra ontwerp (en je moet geen gevoelige state in het token proppen).
- Server-sessies: de server slaat sessiegegevens op (vaak in Redis) en de client houdt alleen een ondoorzichtige session ID. Het is het makkelijkst om in te trekken en bij te werken, maar je moet de session store draaien en schalen.
Gespreksgeheugenstrategieën
“Geheugen” is gewoon state die je kiest terug te sturen naar het model.
- Volledige geschiedenis: het meest accuraat, maar wordt duur en kan oude gevoelige inhoud naar boven halen.
- Samengevat geheugen: houd een lopende samenvatting plus een paar recente beurten; goedkoper en meestal “goed genoeg”.
- Windowed context: alleen de laatste N berichten; het eenvoudigst, maar kan belangrijke eerdere beslissingen missen.
Een praktische aanpak is samenvatting + window: voorspelbaar en helpt onverwacht gedrag van het model te vermijden.
Tool-aanroepen: herhaalbaar en auditbaar
Als de AI tools gebruikt (search, database-queries, bestandslezing), sla elke tool-aanroep op met: inputs, tijdstempels, tool-versie en de teruggegeven output (of een verwijzing daarnaar). Dit laat je uitleggen “waarom de AI dat zei”, runs opnieuw afspelen voor debugging en detecteren wanneer resultaten veranderden omdat een tool of dataset veranderde.
Privacy guardrails
Sla niet standaard langdurig geheugen op. Bewaar alleen wat je nodig hebt voor continuïteit (conversation IDs, samenvattingen en tool-logs), stel retentie-limieten in en vermijd het persisteren van ruwe gebruikerstekst tenzij er een duidelijk productdoel en gebruikersconsent is.
State veilig synchroniseren: bronnen van waarheid en conflictafhandeling
State wordt riskant wanneer hetzelfde “ding” op meer dan één plek bewerkt kan worden—je UI, een tweede tab of een achtergrondtaak die een conversatie bijwerkt. De oplossing gaat minder over slimme code en meer over duidelijke eigenaarschap.
Definieer bronnen van waarheid
Bepaal welk systeem gezaghebbend is voor elk stuk state. In de meeste AI-applicaties zou de backend het canonieke record moeten bezitten voor alles wat correct moet zijn: conversatie-instellingen, tool-permissies, berichtgeschiedenis, factureringslimieten en jobstatus. De frontend kan cachen en afleiden voor snelheid (geselecteerde tab, conceptprompttekst, “is typing”-indicatoren), maar moet ervan uitgaan dat de backend gelijk heeft bij mismatch.
Een praktische regel: als je het vervelend zou vinden om het te verliezen bij verversen, hoort het waarschijnlijk op de backend.
Optimistische UI-updates (met voorzichtigheid gebruiken)
Optimistische updates laten de app meteen voelen: schakel een instelling om, update de UI direct en bevestig daarna met de server. Dit werkt goed voor laag-risico, omkeerbare acties (bijv. een gesprek sterren).
Het veroorzaakt verwarring wanneer de server de wijziging kan afwijzen of transformeren (permissiechecks, quota-limieten, validatie of server-side defaults). In die gevallen, toon een “opslaan…”-status en werk de UI pas bij na bevestiging.
Conflicten afhandelen (twee tabs, één conversatie)
Conflicten ontstaan wanneer twee clients hetzelfde record bijwerken op basis van verschillende beginversies. Veelvoorkomend voorbeeld: Tab A en Tab B wijzigen beide de model-temperature.
Gebruik lichte versionering zodat de backend verouderde writes kan detecteren:
updated_attimestamps (simpel, menselijk-debugbaar)- ETags /
If-Matchheaders (HTTP-native) - Oplopende revisienummers (expliciete conflictdetectie)
Als de versie niet matcht, retourneer een conflict-respons (vaak HTTP 409) en stuur het nieuwste server-object terug.
Ontwerp API's om mismatches te verminderen
Laat na elk schrijven de API het opgeslagen object retourneren (inclusief servergegenereerde defaults, genormaliseerde velden en de nieuwe versie). Hierdoor kan de frontend zijn cache onmiddellijk vervangen—één update van de bron van waarheid in plaats van raden wat er veranderde.
Caching en performance: versnellen zonder verouderde state
Caching is één van de snelste manieren om een AI-app direct te laten aanvoelen, maar het creëert ook een tweede kopie van state. Als je het verkeerde ding cached—or op de verkeerde plek—lever je een snelle maar verwarrende UI.
Wat te cachen op de client
Client-side caches moeten focussen op ervaring, niet op autoriteit. Goede kandidaten zijn recente conversatievoorspellingen (titels, laatste berichtsnippet), UI-voorkeuren (thema, geselecteerd model, sidebar-state) en optimistische UI-state (berichten die “verzenden”).
Houd de client-cache klein en wegwerpbaar: als hij gewist wordt, moet de app nog steeds werken door opnieuw van de server te fetchen.
Wat te cachen op de server
Server-caches richten zich op dure of vaak herhaalde werkzaamheden:
- Tool-resultaten die veilig hergebruikt kunnen worden (bv. een weer-opvraag voor dezelfde stad binnen 5 minuten)
- Embedding-opzoekingen en vector search-resultaten voor herhaalde queries (vaak met korte TTLs)
- Rate-limit state en throttling-tellers (om je API en kosten te beschermen)
Hier kun je ook afgeleide state cachen zoals tokencounts, moderatiebeslissingen of document-parsing-resultaten—alles deterministisch en kostbaar.
Basisprincipes cache-invalidation (zonder ingewikkeld te doen)
Drie praktische regels:
- Gebruik duidelijke cache-sleutels die inputs encoderen (
user_id, model, tool-parameters, documentversie). - Stel TTL's in op basis van hoe snel de onderliggende data verandert. Korte TTL is beter dan slimme logica.
- Sla de cache over wanneer correctheid belangrijker is dan snelheid: nadat een gebruiker een document bijwerkt, permissies wijzigt of een refresh aanvraagt.
Als je niet kunt uitleggen wanneer een cache-entry fout wordt, cache het dan niet.
Cache geen geheimen of persoonlijke data in gedeelde caches
Vermijd het plaatsen van API-keys, auth-tokens, ruwe prompts met gevoelige tekst of gebruikerspecifieke content in gedeelde lagen zoals CDN-caches. Als je gebruikersdata moet cachen, isoleer per gebruiker en versleutel in rust—of bewaar het in je primaire database.
Meet impact: snelheid vs. verouderde UI
Caching moet bewezen zijn, niet aangenomen. Meet p95-latentie voor/na, cache-hit rate en gebruikerszichtbare fouten zoals “bericht bijgewerkt na renderen.” Een snelle respons die later de UI tegenspreekt is vaak slechter dan een iets tragere, consistente.
Persistentie en langlopende taken: jobs, queues en status-state
Voorkom retry-duplicaten
Laat Koder.ai request IDs en idempotency keys in je endpoints scaffolden.
Sommige AI-features zijn binnen een seconde klaar. Andere duren minuten: uploaden en parsen van een PDF, embeddings maken en indexeren van een knowledge base, of een multi-step tool-workflow draaien. Voor deze taken is “state” niet alleen wat op het scherm staat—het is wat restarts, retries en tijd overleeft.
Wat te persist (en waarom)
Persist alleen wat echte productwaarde ontsluit.
Conversatiegeschiedenis is voor de hand liggend: berichten, tijdstempels, gebruikersidentiteit en (vaak) welk model/tooling werd gebruikt. Dit maakt “later hervatten”, audit trails en betere support mogelijk.
Gebruiker- en workspace-instellingen horen in de database: voorkeursmodel, temperature-defaults, feature-toggles, system prompts en UI-voorkeuren die een gebruiker over apparaten heen moeten volgen.
Bestanden en artifacts (uploads, geëxtraheerde tekst, gegenereerde rapporten) worden meestal opgeslagen in object storage met database-records die ernaar verwijzen. De database houdt metadata (eigenaar, grootte, content-type, verwerkingsstatus), terwijl de blob-store de bytes bevat.
Achtergrondjobs voor lange taken
Als een verzoek niet betrouwbaar binnen een normale HTTP-timeout kan finishen, verplaats het werk naar een queue.
Een typisch patroon:
- Frontend roept een API aan zoals
POST /jobsmet inputs (file id, conversation id, parameters). - Backend zet een job in de wachtrij (extractie, indexering, batch tool-runs) en retourneert direct een
job_id. - Workers verwerken jobs asynchroon en schrijven resultaten terug naar duurzame opslag.
Dit houdt de UI responsief en maakt retries veiliger.
Status-state waarop de UI kan vertrouwen
Maak job-state expliciet en opvraagbaar: queued → running → succeeded/failed (optioneel canceled). Sla deze transities server-side op met tijdstempels en foutdetails.
Reflecteer status duidelijk in de frontend:
- Queued/running: toon een spinner en blokkeer duplicaatacties.
- Failed: toon een beknopte fout en een Retry-knop.
- Succeeded: laad het resulterende artifact of update de conversatie.
Bied GET /jobs/{id} (polling) of stream-updates (SSE/WebSocket) zodat de UI nooit hoeft te raden.
Idempotency-keys: retries zonder dubbele writes
Netwerk-timeouts gebeuren. Als de frontend POST /jobs opnieuw probeert, wil je niet twee identieke jobs (en dubbele kosten).
Vereis een Idempotency-Key per logische actie. De backend slaat de key op met het resulterende job_id/response en retourneert hetzelfde resultaat voor herhaalde verzoeken.
Cleanup- en expiratiebeleid
Langlopende AI-apps verzamelen snel data. Definieer retentieregels vroeg:
- Verwijder oude conversaties na N dagen (of laat gebruikers dit configureren).
- Verwijder afgeleide artifacts wanneer de bron verwijderd wordt.
- Reinig periodiek mislukte jobs en tussenliggende bestanden.
Behandel cleanup als onderdeel van statebeheer: het vermindert risico, kosten en verwarring.
Streamingresponses en real-time updates: gedeeltelijke state beheren
Streaming maakt state complexer omdat het “antwoord” niet langer één blob is. Je werkt met gedeeltelijke tokens (tekst die woord voor woord binnenkomt) en soms gedeeltelijke tool-werkzaamheden (een zoekopdracht begint en is later klaar). Dat betekent dat UI en backend moeten overeenkomen over wat tijdelijk is en wat definitief.
Backend: stream getypeerde events, niet alleen tekst
Een schoon patroon is het streamen van een reeks kleine events, elk met een type en payload. Bijvoorbeeld:
token: incrementele tekst (of een klein chunk)tool_start: een tool-aanroep is begonnen (bijv. “Zoeken…”, met een id)tool_result: tool-output is klaar (zelfde id)done: het assistentbericht is compleeterror: er is iets misgegaan (inclusief een gebruikers-veilige boodschap en een debug-id)
Deze event-stream is makkelijker te versionen en debuggen dan ruwe tekststreaming, omdat de frontend voortgang nauwkeurig kan renderen (en toolstatus kan tonen) zonder te raden.
Frontend: append-only updates, daarna een finale commit
Op de client behandel je streaming als append-only: maak een “concept” assistentbericht en blijf het uitbreiden naarmate token-events binnenkomen. Bij ontvangst van done voer je een commit uit: markeer het bericht als definitief, persist het (als je lokaal opslaat) en ontgrendel acties zoals kopiëren, beoordelen of regenereren.
Dit voorkomt dat de geschiedenis halverwege wordt herschreven en houdt je UI voorspelbaar.
Onderbrekingen afhandelen (annuleren, drops, timeouts)
Streaming vergroot de kans op half-afgewerkt werk:
- Gebruiker annuleert: stuur een cancel-signaal; stop met tokens renderen; houd het concept zichtbaar geannuleerd.
- Netwerk valt uit: stop de stream; toon “opnieuw verbinden…” en ga niet uit van voltooiing.
- Server timeouts/fouten: finaliseer het concept als mislukt en bied een retry aan die een nieuw verzoek start (stitch streams niet stilletjes aan elkaar).
Rehydratie: herladen en stabiele state reconstrueren
Als de pagina midden in een stream opnieuw geladen wordt, reconstrueer vanuit de laatste stabiele state: de laatst gecommitte berichten plus opgeslagen concept-metadata (message id, opgebouwde tekst tot nu toe, tool-statussen). Als je de stream niet kunt hervatten, toon het concept als onderbroken en laat de gebruiker opnieuw proberen in plaats van te doen alsof het voltooid is.
Beveiliging en privacy: state end-to-end beschermen
Deploy zonder extra setup
Ga van chat naar gehoste web- en backend-builds zonder een volledige pipeline te beheren.
State is niet alleen “data die je opslaat”—het zijn gebruikersprompts, uploads, voorkeuren, gegenereerde outputs en de metadata die alles verbindt. In AI-apps kan die state uitzonderlijk gevoelig zijn (persoonlijke info, proprietaire documenten, interne beslissingen), dus beveiliging moet in elke laag worden ingebouwd.
Houd geheimen op de server
Alles wat een client in staat zou stellen je app te imiteren moet backend-only blijven: API-keys, private connectors (Slack/Drive/DB credentials) en interne system prompts of routeringslogica. De frontend kan een actie aanvragen (“vat dit bestand samen”), maar de backend beslist hoe dit wordt uitgevoerd en met welke credentials.
Autoriseer elke write (en de meeste reads)
Behandel elke statemutatie als een bevoegde operatie. Wanneer de client een bericht wil aanmaken, een conversatie hernoemen of een bestand bijvoegt, moet de backend verifiëren:
- De gebruiker is geauthenticeerd.
- De gebruiker bezit de resource (conversatie, workspace, project).
- De gebruiker mag die actie uitvoeren (rol, planniveau, organisatiebeleid).
Dit voorkomt “ID-guessing” attacks waarbij iemand een conversation_id ruilt en toegang krijgt tot andermans geschiedenis.
Vertrouw nooit op de browser: valideer en saniteer
Ga ervan uit dat alle client-geleverde state onbetrouwbaar is. Valideer schema en beperkingen (types, lengtes, toegestane enums) en saniteer voor de bestemming (SQL/NoSQL, logs, HTML-rendering). Als je “state-updates” accepteert (bv. instellingen, tool-parameters), whitelist toegestane velden in plaats van willekeurige JSON te mergen.
Audit trails voor kritieke acties
Voor acties die duurzame state veranderen—delen, exporteren, verwijderen, connector-toegang—registreer wie wat en wanneer deed. Een lichte auditlog helpt bij incident response, klantenservice en compliance.
Data-minimalisatie en encryptie
Sla alleen op wat je nodig hebt om de feature te leveren. Als je niet eeuwig prompts nodig hebt, overweeg retentievensters of redactie. Versleutel gevoelige state in rust waar passend (tokens, connector-credentials, geüploade documenten) en gebruik TLS tijdens transport. Scheid operationele metadata van content zodat je toegang strikter kunt beperken.
Praktische referentie-architectuur en een bouw-checklist
Een nuttige default voor AI-apps is simpel: de backend is de bron van waarheid, en de frontend is een snelle, optimistische cache. De UI kan instant voelen, maar alles wat je zonde zou vinden te verliezen (berichten, jobstatus, tool-uitvoer, factureringsrelevante events) moet bevestigd en server-side opgeslagen worden.
Als je bouwt met een “vibe-coding” workflow—waar veel productoppervlak snel gegenereerd wordt—wordt het state-model nog belangrijker. Platforms zoals Koder.ai helpen teams volledige web-, backend- en mobiele apps uit chat te laten ontstaan, maar dezelfde regel blijft gelden: snel itereren is het veiligst wanneer bronnen van waarheid, IDs en statustransities van tevoren zijn ontworpen.
Referentie-architectuur (één die je kunt uitrollen)
Frontend (browser/mobile)
- UI-state: geopende panelen, conceptprompttekst, geselecteerd model, tijdelijke “typing”-indicatoren.
- Gecachte server-state: recente conversaties, laatst bekende jobstatus, gedeeltelijke stream-buffer.
- Een enkele request-pijplijn die altijd meezendt:
session_id,conversation_id, en een nieuwerequest_id.
Backend (API + workers)
- API-service: valideert input, maakt records aan, geeft streaming-responses.
- Duurzame opslag (SQL/NoSQL): conversaties, berichten, tool-aanroepen, jobstatus.
- Queue + workers: langlopende taken (RAG-indexering, bestandsparsing, beeldgeneratie).
- Cache (optioneel): hot reads (conversatiesamenvattingen, embeddings-metadata), altijd keyed met versies/tijdstempels.
Opmerking: een praktische manier om dit consistent te houden is je backend-stack vroeg te standaardiseren. Bijvoorbeeld, Koder.ai-gegeneerde backends gebruiken vaak Go met PostgreSQL (en React aan de frontend), wat het eenvoudig maakt om gezaghebbende state in SQL te centraliseren terwijl de client-cache wegwerpbaar blijft.
Ontwerp je state-model eerst
Voordat je schermen bouwt, definieer de velden waarop je in elke laag vertrouwt:
- IDs en eigendom:
user_id,org_id,conversation_id,message_id,request_id. - Timestamps en ordening:
created_at,updated_aten een explicietesequencevoor berichten. - Statusvelden:
queued | running | streaming | succeeded | failed | canceled(voor jobs en tool-aanroepen). - Versioning:
etagofversionvoor conflict-veilige updates.
Dit voorkomt de klassieke bug waarin de UI “er goed uitziet” maar retries, verversen of gelijktijdige bewerkingen niet kan reconciliëren.
Gebruik consistente API-vormen
Houd endpoints voorspelbaar over features heen:
GET /conversations(lijst)GET /conversations/{id}(haal op)POST /conversations(aanmaken)POST /conversations/{id}/messages(toevoegen)PATCH /jobs/{id}(status bijwerken)GET /streams/{request_id}ofPOST .../stream(stream)
Retourneer overal hetzelfde envelop-formaat (inclusief fouten) zodat de frontend state uniform kan bijwerken.
Voeg observability toe op plekken waar state kan breken
Log en geef een request_id terug voor elke AI-aanroep. Registreer tool-call inputs/outputs (met redactie), latency, retries en eindstatus. Maak het eenvoudig om te beantwoorden: “Wat zag het model, welke tools draaiden en welke state hebben we opgeslagen?”
Bouw-checklist (om veelvoorkomende state-bugs te vermijden)
- Backend is de bron van waarheid; frontend-cache is duidelijk gelabeld en wegwerpbaar.
- Elke write is idempotent (veilig te retryen) met
request_id(en/of een Idempotency-Key). - Status-transities zijn expliciet en gevalideerd (geen stille sprongen van
queuednaarsucceeded). - Streaming-updates mergen op IDs/sequence, niet op “laatste bericht wint”.
- Conflicten worden afgehandeld via
version/etagof server-side merge-regels. - PII en geheimen worden nooit opgeslagen in client-state; redacteer logs standaard.
- Één dashboard-weergave bestaat voor debugging: requests, tool-calls, jobstatus en fouten.
Als je snellere build-cycli (inclusief AI-ondersteunde generatie) adopteert, overweeg guardrails die deze checklist-items automatisch afdwingen—schema-validatie, idempotentie en evented streaming—zodat “snel bouwen” niet resulteert in state-drift. In de praktijk is dat waar een end-to-end platform zoals Koder.ai nuttig kan zijn: het versnelt levering en laat je toch state-handling-patronen consistent houden over web, backend en mobiel.