23 okt 2025·6 min
Server-side vs client-side filtering: een beslischecklist
Checklist voor server-side vs client-side filtering: kies op basis van datagrootte, latency, permissies en caching, zonder UI-lekken of vertraging.
Checklist voor server-side vs client-side filtering: kies op basis van datagrootte, latency, permissies en caching, zonder UI-lekken of vertraging.
Filteren in een UI is meer dan één zoekvak. Meestal omvat het een paar gerelateerde acties die allemaal veranderen wat de gebruiker ziet: tekstzoekopdrachten (naam, e-mail, order-ID), facetten (status, eigenaar, datumbereik, tags) en sortering (nieuwste, hoogste waarde, laatste activiteit).
De kernvraag is niet welke techniek “beter” is. Het is waar de volledige dataset leeft en wie er toegang toe mag hebben. Als de browser records ontvangt die de gebruiker niet zou mogen zien, kan een UI gevoelige data blootleggen, zelfs als je die visueel verbergt.
De meeste discussies over server-side vs client-side filtering zijn in werkelijkheid reacties op twee fouten die gebruikers meteen opvallen:
Er is een derde probleem dat eindeloos bugreports oplevert: inconsistente resultaten. Als sommige filters op de client draaien en andere op de server, zien gebruikers aantallen, pagina's en totalen die niet kloppen. Dat schaadt snel het vertrouwen, vooral bij genummerde lijsten.
Een praktisch uitgangspunt is simpel: als de gebruiker geen toegang tot de volledige dataset mag hebben, filter dan op de server. Als ze wél toegang hebben en de dataset klein genoeg is om snel te laden, kan client-filtering prima zijn.
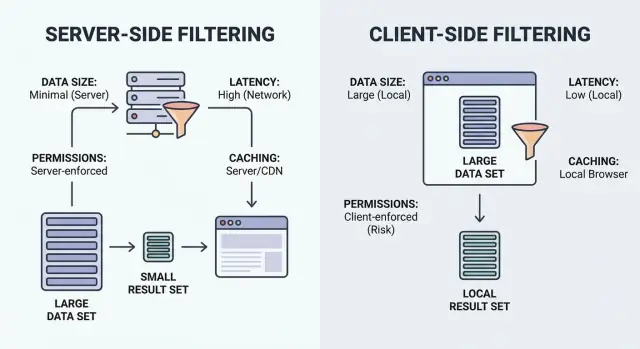
Filteren is gewoon "laat me de items zien die matchen." De belangrijkste vraag is waar het matchen gebeurt: in de browser van de gebruiker (client) of op je backend (server).
Client-side filtering draait in de browser. De app downloadt een set records (vaak JSON) en past daarna lokaal filters toe. Het kan na het laden direct aanvoelen, maar het werkt alleen wanneer de dataset klein genoeg is om te verzenden en veilig genoeg is om prijs te geven.
Server-side filtering draait op je backend. De browser stuurt filterinput (zoals status=open, owner=me, createdAfter=Jan 1), en de server retourneert alleen de overeenkomende resultaten. In de praktijk is dit meestal een API-endpoint dat filters accepteert, een databasequery bouwt en een gepagineerde lijst plus totalen terugstuurt.
Een eenvoudig mentaal model:
Hybride setups komen veel voor. Een goed patroon is om “grote” filters op de server af te dwingen (permissies, eigendom, datumbereik, zoeken) en vervolgens kleine UI-only schakelaars lokaal te gebruiken (verberg gearchiveerde items, snelle tag-chips, kolomzichtbaarheid) zonder extra verzoek.
Sortering, paginatie en zoeken horen meestal bij dezelfde beslissing. Ze beïnvloeden payloadgrootte, gebruikerservaring en welke data je blootlegt.
Begin met de meest praktische vraag: hoeveel data zou je naar de browser sturen als je client-side filtert? Als het eerlijke antwoord is “meer dan een paar schermen aan gegevens”, betaal je daarvoor in downloadtijd, geheugengebruik en trage interacties.
Je hebt geen perfecte schattingen nodig. Krijg gewoon de orde van grootte: hoeveel rijen kan de gebruiker zien en wat is de gemiddelde grootte van een rij? Een lijst van 500 items met een paar korte velden is heel anders dan 50.000 items waarbij elke rij lange notities, rijke tekst of genestelde objecten bevat.
Brede records zijn de stille payload-killer. Een tabel kan klein lijken in rijaantal maar zwaar zijn als elke rij veel velden, grote strings of joined data bevat (contact + bedrijf + laatste activiteit + volledig adres + tags). Zelfs als je maar drie kolommen toont, sturen teams vaak “alles, voor het geval” en blaast de payload op.
Denk ook aan groei. Een dataset die vandaag prima is, kan na een paar maanden problematisch zijn. Als data snel groeit, behandel client-side filtering als een tijdelijke shortcut, niet als de standaard.
Vuistregels:
Dat laatste punt is belangrijker dan alleen performance. “Kunnen we de hele dataset naar de browser sturen?” is ook een beveiligingsvraag. Als het antwoord geen volmondig ja is, stuur het niet.
Filterkeuzes falen vaak op gevoel, niet op juistheid. Gebruikers meten geen milliseconden. Ze merken pauzes, flikkering en resultaten die rondhopsen terwijl ze typen.
Tijd kan op verschillende plekken verdwijnen:
Definieer wat “snel genoeg” betekent voor dit scherm. Een lijstweergave moet responsief typen en soepel scrollen ondersteunen, terwijl een rapportagepagina een korte wachttijd kan verdragen zolang het eerste resultaat snel verschijnt.
Beoordeel niet alleen op kantoor-Wi-Fi. Op trage verbindingen kan client-side filtering na de eerste laadbeurt fijn aanvoelen, maar die eerste laadbeurt kan juist langzaam zijn. Server-side filtering houdt payloads klein, maar kan stroef aanvoelen als je bij elke toetsaanslag een verzoek stuurt.
Ontwerp rond menselijke input. Debounce verzoeken tijdens typen. Voor grote resultsets: gebruik progressief laden zodat de pagina snel iets toont en soepel blijft terwijl de gebruiker scrolt.
Permissies zouden je filteraanpak meer moeten bepalen dan snelheid. Als de browser ooit data ontvangt die een gebruiker niet mag zien, heb je al een probleem, zelfs als je die achter een uitgeschakelde knop of een ingeklapte kolom verbergt.
Begin met het benoemen wat gevoelig is op dit scherm. Sommige velden zijn duidelijk (e-mails, telefoonnummers, adressen). Andere zijn makkelijk te missen: interne notities, kosten of marge, speciale prijsregels, risicoscores, moderatieflags.
De grote valkuil is “we filteren in de client, maar tonen alleen toegestane rijen.” Dat betekent nog steeds dat de volledige dataset is gedownload. Iedereen kan de netwerkresponse inspecteren, devtools openen of de payload opslaan. Kolommen verbergen in de UI is geen toegangscontrole.
Server-side filtering is de veiligere default wanneer autorisatie per gebruiker verschilt, vooral wanneer verschillende gebruikers verschillende rijen of velden kunnen zien.
Snelle check:
Als op een van deze vragen ja is: houd filtering en veldselectie op de server. Stuur alleen wat de gebruiker mag zien en pas dezelfde regels toe op zoeken, sorteren, paginatie en export.
Voorbeeld: in een CRM-contactlijst mogen vertegenwoordigers alleen hun eigen accounts zien terwijl managers alles kunnen zien. Als de browser alle contacten downloadt en lokaal filtert, kan een vertegenwoordiger nog steeds verborgen accounts terughalen uit de response. Server-side filtering voorkomt dat door die rijen simpelweg nooit te verzenden.
Caching kan een scherm direct laten aanvoelen. Het kan ook de verkeerde waarheid tonen. De sleutel is beslissen wat je mag hergebruiken, hoe lang, en welke gebeurtenissen het moeten wissen.
Begin met het kiezen van de cache-eenheid. Een hele lijst cachen is simpel maar meestal verspilling en gaat snel stale. Pagina's cachen werkt goed voor infinite scroll. Queryresultaten cachen (filter + sort + search) is accuraat, maar kan snel groeien als gebruikers veel combinaties proberen.
Actualiteit is in sommige domeinen belangrijker dan in andere. Als data snel verandert (voorraadniveaus, saldi, bezorgstatus), kan zelfs een cache van 30 seconden gebruikers verwarren. Als data langzaam verandert (gearchiveerde records, referentiedata), is langer cachen vaak prima.
Plan invalidatie voordat je code schrijft. Naast verstrijken van tijd, beslis wat een refresh moet forceren: aanmaken/bewerken/verwijderen, permissiewijzigingen, bulkimports of merges, statusovergangen, undo/rollback-acties en achtergrondjobs die velden updaten waarop gebruikers filteren.
Bepaal ook waar caching plaatsvindt. Browsergeheugen maakt terug/vooruit-navigatie snel, maar kan data lekken tussen accounts als je het niet per gebruiker en org keyed. Backendcaching is veiliger voor permissies en consistentie, maar het moet de volledige filter-handtekening en de identiteit van de aanvrager bevatten zodat resultaten niet door elkaar raken.
Zie het doel als niet-onderhandelbaar: het scherm moet snel aanvoelen zonder data te lekken.
De meeste teams worden door dezelfde patronen geraakt: een UI die er mooi uitziet in een demo, maar met echte data, echte permissies en echte netwerksnelheden de scheuren blootgeeft.
De ernstigste fout is filtering als presentatie behandelen. Als de browser records ontvangt die niet zichtbaar hadden mogen zijn, ben je al verloren.
Twee veelvoorkomende oorzaken:
Voorbeeld: stagiaires mogen alleen leads uit hun regio zien. Als de API alle regio's retourneert en de dropdown dit in React filtert, kunnen stagiaires de volledige lijst extraheren.
Vertraging komt vaak voort uit aannames:
Een subtiel maar pijnlijk probleem is mismatchende regels. Als de server “begint met” anders behandelt dan de UI, zien gebruikers aantallen die niet kloppen of verdwijnen items na verversen.
Doe een laatste controle met twee denkwijzen: een nieuwsgierige gebruiker en een slechte netwerkdag.
Een simpele test: maak een beperkt record en controleer dat het nooit verschijnt in de payload, totalen of cache, zelfs niet wanneer je breed filtert of filters verwijdert.
Stel je een CRM voor met 200.000 contacten. Vertegenwoordigers mogen alleen hun eigen accounts zien, managers zien hun team en admins zien alles. Het scherm heeft zoeken, filters (status, eigenaar, laatste activiteit) en sortering.
Client-side filtering faalt snel hier. De payload wordt zwaar, de eerste laadbeurt wordt traag en het risico op een datalek is groot. Zelfs als de UI rijen verbergt, heeft de browser de data al ontvangen. Je legt ook druk op het apparaat: grote arrays, zware sorteringen, herhaalde filterruns, veel geheugen en crashes op oudere telefoons.
Een veiligere aanpak is server-side filtering met paginatie. De client stuurt filterkeuzes en zoektekst en de server retourneert alleen rijen die de gebruiker mag zien, al gefilterd en gesorteerd.
Een praktisch patroon:
Een kleine uitzondering waar client-side filtering prima is: kleine, statische data. Een dropdown voor “Contact status” met 8 waarden kan één keer worden geladen en lokaal gefilterd zonder veel risico of kosten.
Teams worden meestal niet geraakt door één verkeerde keuze; ze worden geraakt door het maken van verschillende keuzes op elk scherm en vervolgens proberen lekken en trage pagina's te repareren onder tijdsdruk.
Schrijf per scherm een korte beslisnotitie met filters: datagrootte, wat het kost om te verzenden, wat “snel genoeg” voelt, welke velden gevoelig zijn en hoe resultaten moeten worden gecachet (of niet). Houd server en UI in lijn zodat je niet met "twee waarheden" voor filtering eindigt.
Als je snel schermen bouwt in Koder.ai (koder.ai), is het de moeite waard van tevoren te beslissen welke filters op de backend moeten worden afgedwongen (permissies en rijniveau-toegang) en welke kleine, UI-only toggles in de React-laag kunnen blijven. Die ene keuze voorkomt meestal de duurste herschrijvingen later.
Standaard server-side gebruiken wanneer gebruikers verschillende permissies hebben, de dataset groot is, of je consistente paginatie en totalen wilt. Client-side alleen gebruiken wanneer de volledige dataset klein is, veilig om te tonen, en snel te downloaden.
Alles wat de browser ontvangt kan worden bekeken. Zelfs als de UI rijen of kolommen verbergt, kan een gebruiker netwerkresponses, gecachte payloads of in-memory objecten inspecteren.
Meestal gebeurt het wanneer je te veel data verzendt en vervolgens grote arrays op elke toetsaanslag filtert/sorteert, of wanneer je bij elke toetsaanslag een serververzoek stuurt zonder debouncing. Houd payloads klein en vermijd zware bewerkingen bij elke invoerwijziging.
Houd één bron van waarheid voor de "echte" filters: permissies, zoeken, sortering en paginatie moeten samen op de server worden afgedwongen. Beperk client-side logica tot kleine UI-only schakelaars die de onderliggende dataset niet veranderen.
Client-side caching kan verouderde of verkeerde data tonen en kan data lekken tussen accounts als het niet goed wordt keyed. Server-side caching is veiliger voor permissies, maar moet de volledige filterhandtekening en de identiteit van de aanvrager bevatten zodat resultaten niet door elkaar raken.
Stel twee vragen: hoeveel rijen kan een gebruiker realistisch hebben, en hoe groot is elke rij in bytes. Als je het niet comfortabel zou laden op een typische mobiele verbinding of op een ouder apparaat, verplaats filtering naar de server en gebruik paginatie.
Server-side. Als rollen, teams, regio's of eigenaarschapsregels bepalen wat iemand kan zien, moet de server rij- en veldtoegang afdwingen. De client mag alleen de rijen en velden ontvangen die de gebruiker mag zien.
Definieer het filter- en sorteerkontract eerst: geaccepteerde filtervelden, standaard sortering, paginatieregels en hoe zoeken matcht (hoofdletters, accenten, gedeeltelijke matches). Implementeer daarna dezelfde logica consistent op de backend en test dat totalen en pagina's overeenkomen.
Debounce bij typen zodat je niet bij elke toetsaanslag een verzoek doet, en houd oude resultaten zichtbaar totdat nieuwe binnenkomen om flikkering te verminderen. Gebruik paginatie of progressief laden zodat de gebruiker snel iets ziet zonder te blokkeren op een enorme response.
Pas permissies eerst toe, dan filters en sortering, en geef alleen één pagina plus een total count terug. Vermijd het sturen van "extra velden voor het geval dat" en zorg dat cache-keys user/org/role bevatten zodat een vertegenwoordiger nooit data van een manager ontvangt.