21 sep 2025·8 min
Meilisearch voor instant server-side zoeken in je apps
Leer hoe je Meilisearch toevoegt aan je backend voor snelle, fouttolerante zoekfuncties: setup, indexering, ranking, filters, beveiliging en basisprincipes van schaalbaarheid.
Leer hoe je Meilisearch toevoegt aan je backend voor snelle, fouttolerante zoekfuncties: setup, indexering, ranking, filters, beveiliging en basisprincipes van schaalbaarheid.
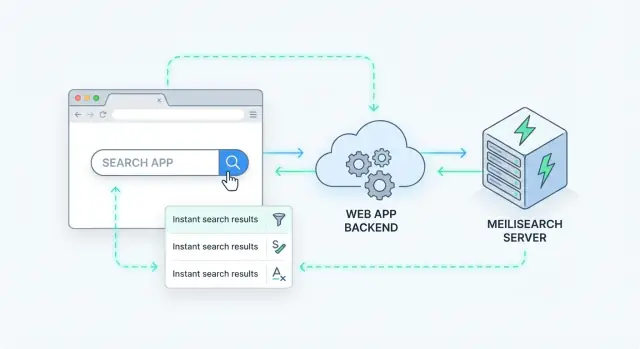
Server-side search betekent dat de query op jouw server (of een dedicated search-service) wordt verwerkt, niet in de browser. Je app stuurt een zoekverzoek, de server voert het uit tegen een index en retourneert gerangschikte resultaten.
Dit is belangrijk wanneer je dataset te groot is om naar de client te sturen, wanneer je consistente relevantie over platforms nodig hebt, of wanneer toegangscontrole niet onderhandelbaar is (bijvoorbeeld interne tools waarbij gebruikers alleen mogen zien wat ze mogen zien). Het is ook de standaardkeuze wanneer je analytics, logging en voorspelbare prestaties wilt.
Mensen denken niet aan zoekmachines—ze beoordelen de ervaring. Een goede “instant” zoekflow betekent meestal:
Als dit ontbreekt, compenseren gebruikers door andere queries te proberen, meer te scrollen, of de zoekfunctie helemaal te verlaten.
Dit artikel is een praktische walkthrough om die ervaring te bouwen met Meilisearch. We behandelen hoe je het veilig opzet, hoe je je geïndexeerde data structureert en synchroniseert, hoe je relevantie en rankingregels afstemt, hoe je filters/sortering/facets toevoegt, en hoe je aan security en scaling denkt zodat zoeken snel blijft naarmate je app groeit.
Meilisearch past goed bij:
Het doel: resultaten die direct, nauwkeurig en betrouwbaar aanvoelen—zonder van zoeken een groot engineeringproject te maken.
Meilisearch is een zoekengine die je naast je app draait. Je stuurt documenten (producten, artikelen, gebruikers of supporttickets) en Meilisearch bouwt een index die geoptimaliseerd is voor snel zoeken. Je backend (of frontend) query’t Meilisearch via een eenvoudige HTTP API en krijgt in milliseconden gerangschikte resultaten terug.
Meilisearch richt zich op de functies die mensen van moderne zoekervaringen verwachten:
Het is ontworpen om responsief en vergevingsgezind aan te voelen, zelfs wanneer een query kort, lichtelijk fout of dubbelzinnig is.
Meilisearch vervangt je primaire database niet. Je database blijft de bron van waarheid voor schrijfacties, transacties en constraints. Meilisearch slaat een kopie op van de velden die je kiest om doorzoekbaar, filterbaar of weer te geven te maken.
Een goed mentaal model is: database voor opslaan en bijwerken, Meilisearch om het snel te vinden.
Meilisearch kan extreem snel zijn, maar resultaten hangen af van een paar praktische factoren:
Voor kleine tot middelgrote datasets kun je het vaak op één machine draaien. Naarmate je index groeit, wil je bewuster kiezen wat je indexeert en hoe je updates bijhoudt—onderwerpen die we later behandelen.
Voordat je iets installeert, bepaal wat je daadwerkelijk wilt doorzoeken. Meilisearch voelt “instant” aan alleen als je indexes en documenten overeenkomen met hoe mensen je app doorzoeken.
Begin met het opsommen van je doorzoekbare entiteiten—meestal producten, artikelen, gebruikers, helpdocs, locaties, enz. In veel apps is de schoonste aanpak één index per entiteitstype (bijv. products, articles). Dat houdt rankingregels en filters voorspelbaar.
Als je UX over meerdere types in één zoekveld zoekt (“search everything”), kun je aparte indexes houden en resultaten in je backend samenvoegen, of later een dedicated “global” index maken. Forceer niet alles in één index tenzij velden en filters echt op elkaar aansluiten.
Elk document heeft een stabiele identifier (primaire sleutel) nodig. Kies iets dat:
id, sku, slug)Voor de documentvorm, geef de voorkeur aan platte velden wanneer mogelijk. Platte structuren zijn eenvoudiger om op te filteren en sorteren. Geneste velden zijn prima als ze een compacte, onveranderlijke bundel representeren (bijv. een author-object), maar vermijd diepe geneste structuren die je relationele schema spiegelen—zoekdocumenten moeten read-optimized zijn, niet database-gestyled.
Een praktische manier om documenten te ontwerpen is elk veld een rol te geven:
Dit voorkomt een veelgemaakte fout: een veld “just in case” indexeren en later afvragen waarom resultaten ruisen of filters traag zijn.
“Taals” kan verschillende dingen betekenen in je data:
lang: "en")Bepaal vroeg of je aparte indexes per taal gebruikt (eenvoudig en voorspelbaar) of een enkele index met taalvelden (minder indexes, meer logica). Het juiste antwoord hangt af van of gebruikers binnen één taal tegelijk zoeken en hoe je vertalingen opslaat.
Meilisearch draaien is eenvoudig, maar “veilig vanaf de start” vergt een paar bewuste keuzes: waar je het deployt, hoe je data persist wordt en hoe je de master key beheert.
Opslag: Meilisearch schrijft zijn index naar schijf. Zet de data-directory op betrouwbare, persistente opslag (niet op vluchtige containeropslag). Plan capaciteit voor groei: indexes kunnen snel groeien bij veel tekstvelden en veel attributen.
Geheugen: reserveer genoeg RAM om zoeken responsief te houden onder load. Als je swapping ziet, lijdt de performance.
Backups: backup de Meilisearch data-directory (of gebruik snapshots op storage-niveau). Test restore minstens één keer; een backup die je niet kunt terugzetten is alleen maar een bestand.
Monitoring: track CPU, RAM, schijfgebruik en disk I/O. Monitor ook proceshealth en logfouten. Alert in elk geval als de service stopt of schijfruimte laag is.
Draai Meilisearch altijd met een master key buiten lokale ontwikkeling. Bewaar deze in een secret manager of versleutelde environment store (niet in Git, niet in plain-text .env in je repo).
Voorbeeld (Docker):
docker run -d --name meilisearch \\
-p 7700:7700 \\
-v meili_data:/meili_data \\
-e MEILI_MASTER_KEY="$(openssl rand -hex 32)" \\
getmeili/meilisearch:latest
Overweeg ook netwerkregels: bind aan een privé-interface of beperk inkomend verkeer zodat alleen je backend Meilisearch kan bereiken.
curl -s http://localhost:7700/version
Meilisearch-indexering is asynchroon: je stuurt documenten, Meilisearch zet een taak in de wachtrij en pas nadat die taak slaagt, worden documenten doorzoekbaar. Behandel indexering als een jobsysteem, niet als een enkelvoudig request.
id).curl -X POST 'http://localhost:7700/indexes/products/documents?primaryKey=id' \\
-H 'Content-Type: application/json' \\
-H 'Authorization: Bearer YOUR_WRITE_KEY' \\
--data-binary @products.json
taskUid. Poll tot die succeeded (of failed).curl -X GET 'http://localhost:7700/tasks/123' \\
-H 'Authorization: Bearer YOUR_WRITE_KEY'
curl -X GET 'http://localhost:7700/indexes/products/stats' \\
-H 'Authorization: Bearer YOUR_WRITE_KEY'
Als counts niet kloppen, gok niet—controleer eerst task error details.
Batching draait om voorspelbare en herstelbare taken.
addDocuments gedraagt zich als een upsert: documenten met dezelfde primaire sleutel worden bijgewerkt, nieuwe worden ingevoegd. Gebruik dit voor normale updates.
Doe een volledige reindex wanneer:\n\n- je de vorm van documenten significant hebt veranderd,\n- je afgeleide velden opnieuw moet berekenen,\n- je sync is gedrift en je een schone reset wilt.
Voor verwijderingen roep expliciet deleteDocument(s) aan; anders blijven oude records achter.
Indexeren moet retryable zijn. De sleutel is stabiele documentids.
taskUid samen met je batch/job-id en retry op basis van taskstatus.Index vóór productiedata een kleine dataset (200–500 items) die je echte velden nabootst. Bijvoorbeeld: een products-set met id, name, description, category, brand, price, inStock, createdAt. Dit is genoeg om taskflow, counts en update/delete-gedrag te valideren—zonder te wachten op een enorme import.
“Relevantie” betekent gewoon: wat verschijnt eerst, en waarom. Meilisearch maakt dit aanpasbaar zonder dat je je eigen score-systeem hoeft te bouwen.
Twee instellingen bepalen wat Meilisearch met je content kan doen:
searchableAttributes: de velden waar Meilisearch in zoekt wanneer een gebruiker typt (bijv. title, summary, tags). Volgorde doet ertoe: eerdere velden worden als belangrijker gezien.displayedAttributes: de velden die in de response terugkomen. Dit is belangrijk voor privacy en payloadgrootte—als een veld niet displayed is, wordt het niet teruggestuurd.Een praktische baseline is een paar hoog-signaalvelden searchable maken (title, belangrijkste tekst) en displayed fields beperken tot wat de UI nodig heeft.
Meilisearch sorteert matchende documenten met ranking rules—een pijplijn van tie-breakers. Conceptueel geeft het de voorkeur aan:
Je hoeft de interne details niet uit je hoofd te leren om het effectief te tunen; je kiest vooral welke velden het meest tellen en wanneer je aangepaste sortering toepast.
Doel: “Titel-matches moeten winnen.” Zet title eerst:
{
"searchableAttributes": ["title", "subtitle", "description", "tags"]
}
Doel: “Nieuwere content eerst.” Voeg een sorteerregel toe en sorteer bij de query (of stel een custom ranking in):
{
"sortableAttributes": ["publishedAt"],
"rankingRules": ["sort", "typo", "words", "proximity", "attribute", "exactness"]
}
Vraag dan:
{ "q": "release notes", "sort": ["publishedAt:desc"] }
Doel: “Promoot populaire items.” Maak popularity sortable en sorteer erop wanneer dat passend is.
Kies 5–10 echte queries die gebruikers typen. Sla topresultaten op voor wijzigingen en vergelijk met na.
Voorbeeld:
"apple" → Apple Watch band, Pineapple slicer, Apple iPhone case"apple" → Apple iPhone case, Apple Watch band, Pineapple slicerAls de “na”-lijst beter aansluit bij intentie, houd dan de instellingen. Als het randgevallen schaadt, pas dan één ding tegelijk aan (attribuutvolgorde, dan sorteerregels) zodat je weet wat de verbetering veroorzaakte.
Een goede zoekbalk is niet alleen “typen en matches krijgen.” Mensen willen ook resultaten beperken (“alleen beschikbare items”) en ordenen (“goedkoopste eerst”). In Meilisearch doe je dit met filters, sortering en facets.
Een filter is een regel die je toepast op de resultaten. Een facet is wat je in de UI laat zien om gebruikers te helpen die regels te bouwen (vaak als checkboxes of aantallen).
Niet-technische voorbeelden:
Een gebruiker zoekt bijvoorbeeld “running” en filtert dan naar category = Shoes en status = in_stock. Facets kunnen aantallen tonen zoals “Shoes (128)” en “Jackets (42)” zodat gebruikers weten wat beschikbaar is.
Meilisearch heeft expliciet jouw toestemming nodig voor velden die je gebruikt bij filteren en sorteren.
category, status, brand, price, created_at (als je op tijd filtert), tenant_id (als je klanten isoleert).price, rating, created_at, popularity.Houd de lijst compact. Alles filterable/sortable maken kan indexgrootte vergroten en updates vertragen.
Zelfs als je 50.000 matches hebt, ziet de gebruiker alleen de eerste pagina. Gebruik kleine pagina’s (vaak 20–50 resultaten), stel een verstandig limit in en pagineer met offset (of gebruik nieuwere paginatiefuncties als je die verkiest). Beperk ook maximale paginadiepte in je app om dure “pagina 400”-requests te voorkomen.
Een nette manier om server-side search toe te voegen is Meilisearch te behandelen als een gespecialiseerd dataservice achter je API. Je app ontvangt een zoekverzoek, roept Meilisearch aan en retourneert een uitgeklede response naar de client.
De meeste teams gebruiken een flow zoals:
GET /api/search?q=wireless+headphones&limit=20).Dit patroon houdt Meilisearch vervangbaar en voorkomt dat frontend afhankelijk wordt van index-internals.
Als je een nieuwe app bouwt (of een intern tool herbouwt) en dit patroon snel wilt implementeren, kan een vibe-coding platform zoals Koder.ai helpen om de volledige flow te scaffolden—React UI, een Go-backend en PostgreSQL—en Meilisearch achter één /api/search-endpoint te integreren zodat de client simpel blijft en permissies server-side blijven.
Meilisearch ondersteunt client-side queries, maar backend-query’s zijn meestal veiliger omdat:
Client-side query’en kunnen nog werken voor publieke data met beperkte keys, maar als je enige gebruiker-specifieke zichtbaarheidregels hebt, route zoekverkeer via je server.
Zoekverkeer heeft vaak herhalingen (“iphone case”, “return policy”). Voeg caching toe op je API-laag:
Behandel search als een publiek endpoint:
limit en maximale querylengte in.Meilisearch staat vaak “achter” je app omdat het gevoelige zakelijke data snel kan teruggeven. Behandel het als een database: sluit het af en geef alleen vrij wat elke caller mag zien.
Meilisearch heeft een master key die alles kan: indexes maken/verwijderen, settings updaten en documenten lezen/schrijven. Bewaar die alleen server-side.
Genereer voor applicaties API-keys met beperkte acties en beperkte indexes. Een veelgebruikt patroon:
Least privilege zorgt dat een gelekte key geen data kan verwijderen of lezen uit niet-toegestane indexes.
Als je meerdere klanten (tenants) bedient, heb je twee hoofdopties:
1) Eén index per tenant.
Eenvoudig te redeneren en vermindert risico op cross-tenant toegang. Nadelen: meer indexes om te beheren en instellingen moeten consistent toegepast worden.
2) Gedeelde index + tenant-filter.
Sla een tenantId-veld op elk document en eis een filter zoals tenantId = "t_123" voor alle zoekopdrachten. Dit kan goed schalen, maar alleen als je er zeker van bent dat elk verzoek altijd die filter toepast (idealiter via een scoped key zodat callers die niet kunnen verwijderen).
Zelfs als zoekresultaten correct zijn, kunnen velden die je niet wilt tonen toch lekken (e-mails, interne notities, kostprijzen). Configureer wat teruggegeven mag worden:
Doe een korte “worst-case” test: zoek op een veelvoorkomend woord en controleer dat geen privévelden verschijnen.
Als je twijfelt of een key client-side moet zijn, neem dan aan “nee” en hou zoeken server-side.
Meilisearch is snel als je twee workloads uit elkaar houdt: indexering (writes) en search queries (reads). De meeste onduidelijke traagheid komt doordat één van deze resources (CPU, RAM, schijf) gedeeld wordt.
Indexeringsload kan spikes geven bij grote imports, frequente updates of veel zoekbare velden. Indexering is background, maar verbruikt nog steeds CPU en schijfbandbreedte. Als je taskqueue groeit, kunnen zoekopdrachten langzamer aanvoelen.
Query-load groeit met traffic, maar ook met features: meer filters, meer facets, grotere resultsets en sterkere fouttolerantie verhogen de kosten per request.
Disk I/O is vaak de stille boosdoener. Langzame schijven (of noisy neighbors op gedeelde volumes) kunnen “instant” in “eventueel” veranderen. NVMe/SSD is typisch baseline voor productie.
Begin met eenvoudige sizing: geef Meilisearch genoeg RAM om indexes hot te houden en genoeg CPU voor piek-QPS. Scheid daarna verantwoordelijkheden:
Houd een klein aantal signalen in de gaten:
Backups moeten routine zijn. Gebruik Meilisearch’s snapshot-functie op schema, bewaar snapshots extern en test restores periodiek. Voor upgrades: lees release notes, test in non-prod en plan reindexertijd als een versiewijziging indexeringsgedrag beïnvloedt.
Als je al environment-snapshots en rollback in je platform gebruikt (bijv. via Koder.ai’s snapshots/rollback), stem je zoek-rollout af op dezelfde discipline: snapshot vóór wijzigingen, verifieer healthchecks en houd een snelle terugkeer naar een bekende goede staat.
Zelfs met een nette integratie vallen zoekproblemen vaak in een paar herhaalbare categorieën. Het goede nieuws: Meilisearch geeft genoeg zichtbaarheid (tasks, logs, deterministische instellingen) om snel te debuggen—als je systematisch te werk gaat.
filterableAttributes, of documenten slaan het op in een onverwachte vorm (string vs array vs genest object).sortableAttributes/rankingRules-aanpassing duwt ongewenste items omhoog.Begin met controleren of Meilisearch je laatste wijziging succesvol heeft toegepast.
filter, dan sort, dan facets.Als je een resultaat niet kunt verklaren, schakel tijdelijk je configuratie terug: verwijder synoniemen, beperk ranking-aanpassingen en test met een kleine dataset. Complexe relevantieproblemen zijn veel makkelijker te zien op 50 documenten dan op 5 miljoen.
your_index_v2 parallel, pas instellingen toe en replay een steekproef van productievraagstukken.filterableAttributes en sortableAttributes overeenkomen met je UI-eisen.Gerelateerde gidsen: /blog (zoekbetrouwbaarheid, indexeringspatronen en productie-rollouttips).
Server-side search betekent dat de query op jouw backend (of een dedicated search-service) draait, niet in de browser. Het is de juiste keuze wanneer:
Gebruikers merken vier dingen meteen op:
Als er één ontbreekt, typen mensen opnieuw, scrollen teveel of haken ze af.
Behandel Meilisearch als een zoekindex, niet als jouw bron van waarheid. Je database regelt schrijfacties, transacties en constraints; Meilisearch slaat een kopie van geselecteerde velden op, geoptimaliseerd om snel op te halen.
Een nuttig mentaal model is:
Een veelgebruikte standaard is één index per entiteitstype (bijv. products, articles). Dit houdt:
Als je “alles doorzoeken” nodig hebt, kun je meerdere indexes query’en en resultaten in je backend samenvoegen, of later een speciale globale index toevoegen.
Kies een primaire sleutel die:
id, sku, slug)Stabiele IDs maken indexering idempotent: als je een upload opnieuw probeert, maak je geen duplicaten omdat updates veilige upserts worden.
Classificeer elk veld op doel zodat je niet te veel indexeert:
Door deze rollen expliciet te houden vermijd je ruis in resultaten en te trage of opgeblazen indexes.
Indexering is asynchroon: documentuploads maken een taak, en documenten worden pas doorzoekbaar nadat die taak geslaagd is.
Een betrouwbare flow is:
succeeded of failedAls resultaten verouderd lijken, controleer dan eerst de taakstatus voordat je verder zoekt.
Gebruik meerdere kleinere batches in plaats van één enorme upload. Praktische uitgangspunten:
Kleinere batches zijn makkelijker opnieuw te proberen, makkelijker te debuggen (slechte records vinden) en minder gevoelig voor time-outs.
Twee hoog-impacthevels zijn:
searchableAttributes: welke velden worden doorzocht en in welke volgordepublishedAt, price of popularityEen praktische aanpak: neem 5–10 echte gebruikersqueries, noteer topresultaten “voor”, wijzig één instelling en vergelijk “na”.
De meeste filter/sort-problemen komen door ontbrekende configuratie:
filterableAttributes staan om erop te filterensortableAttributes staan om er op te sorterenControleer ook de vorm en types van velden in documenten (string vs array vs genest object). Als een filter faalt, inspecteer dan de laatste settings/taskstatus en bevestig dat de geïndexeerde documenten de verwachte veldwaarden bevatten.