Wat deze post behandelt (en waarom het nog steeds telt)
Joe Armstrong hielp niet alleen Erlang creëren — hij werd ook de meest heldere, overtuigende uitlegger ervan. Via talks, papers en een pragmatische invalshoek populariseerde hij een eenvoudige gedachte: als je software wilt die blijft draaien, ontwerp je voor falen in plaats van te doen alsof je het kunt vermijden.
Deze post is een rondleiding door de Erlang-mentaliteit en waarom die nog steeds belangrijk is bij het bouwen van betrouwbare realtime-platforms — denk aan chatsystemen, oproeproutering, live-notificaties, multiplayer-coördinatie en infrastructuur die snel en consistent moet reageren, ook als delen ervan vreemd doen.
“Realtime” in eenvoudige bewoordingen
Realtime betekent niet altijd “microseconden” of “harde deadlines.” In veel producten betekent het:
- snelle reacties die gebruikers merken (geen mysterieuze pauzes)
- voorspelbaar gedrag onder load (het kan vertragen, maar mag niet ontsporen)
- doorgaan tijdens gedeeltelijke storingen (een kapot onderdeel mag niet alles neerhalen)
Erlang werd gebouwd voor telecomsystemen waar deze verwachtingen niet ter discussie stonden — en die druk vormde de invloedrijkste ideeën.
De drie pijlers waarop we ons richten
In plaats van in syntax te duiken, richten we ons op de concepten die Erlang beroemd maakten en die steeds weer terugkomen in moderne systeemontwerpen:
- Concurrency als standaard: bouw software uit veel kleine, geïsoleerde workers in plaats van een paar gigantische.
- Fouttolerantie als ontwerpsdoel: ga ervan uit dat bugs, timeouts en crashes zullen gebeuren — en plan wat er daarna gebeurt.
- “Let it crash”: verdedig niet elke regel code tot het uiterste; faal snel en herstel schoon met structuur (geen heldendaden).
Onderweg koppelen we deze ideeën aan het actor model en berichtuitwisseling, leggen we supervisiebomen en OTP op toegankelijke wijze uit en laten we zien waarom de BEAM VM de hele aanpak praktisch maakt.
Ook als je Erlang niet gebruikt (en nooit zult gebruiken), blijft de kern: Armstrongs raamwerk geeft je een krachtig checklist voor het bouwen van systemen die responsief en beschikbaar blijven als de realiteit rommelig wordt.
Joe Armstrongs motivatie: systemen bouwen die blijven draaien
Telecomswitches en oproeprouteringsplatforms kunnen niet "uitvallen voor onderhoud" zoals veel websites wel kunnen. Ze moeten rond de klok oproepen, billing-events en signalering blijven verwerken — vaak met strikte eisen aan beschikbaarheid en voorspelbare reactietijden.
Erlang begon binnen Ericsson eind jaren 80 als een poging om die realiteit met software (niet alleen gespecialiseerde hardware) aan te pakken. Joe Armstrong en zijn collega’s zochten geen elegantie omwille van elegantie; ze probeerden systemen te bouwen die operators konden vertrouwen onder constante load, gedeeltelijke storingen en rommelige real-world condities.
Wat “betrouwbaar” in de praktijk betekende
Een belangrijke denkomslag is dat betrouwbaarheid niet hetzelfde is als “nooit falen.” In grote, langlopende systemen zal iets falen: een proces krijgt onverwachte input, een node reboot, een netwerklink flikkert, of een dependency stokt.
Dus wordt het doel:
- gebruikers blijven bedienen, zelfs als delen zich verkeerd gedragen
- fouten snel detecteren
- automatisch herstellen, met minimale menselijke tussenkomst
- fouten isoleren zodat één bug niet alles neerhaalt
Dit is de mentaliteit die later ideeën als supervisiebomen en “let it crash” redelijk maakt: je ontwerpt voor falen als normale gebeurtenis, niet als uitzonderlijke catastrofe.
Minder mythe, meer probleemoplossing
Het is verleidelijk om het verhaal te vertellen als de doorbraak van één visionair. De nuttigere blik is eenvoudiger: telecom-eisen dwongen andere afwegingen af. Erlang gaf prioriteit aan concurrentie, isolatie en herstel omdat dat praktische instrumenten waren om services draaiende te houden terwijl de wereld om hen heen veranderde.
Die probleemgerichte benadering is ook waarom Erlang-lessen vandaag de dag nog goed vertalen — overal waar uptime en snel herstel belangrijker zijn dan perfecte preventie.
Concurrency als standaard: veel kleine workers
Een kernidee in Erlang is dat “veel dingen tegelijk doen” geen speciale feature is die je later toevoegt — het is de normale manier om een systeem te structureren.
Lightweight processes, eenvoudig uitgelegd
In Erlang wordt werk opgesplitst in talloze kleine “processen.” Zie ze als kleine workers, elk verantwoordelijk voor één taak: een telefoongesprek afhandelen, een chatsessie bijhouden, een apparaat monitoren, een betaling herhalen of een queue in de gaten houden.
Ze zijn lichtgewicht, wat betekent dat je er enorme aantallen kunt hebben zonder gigantische hardware. In plaats van één zware worker die alles probeert te jongleren, krijg je een menigte gefocuste workers die snel kunnen starten, snel stoppen en snel vervangen kunnen worden.
Waarom “één groot programma” anders faalt
Veel systemen zijn ontworpen als één groot programma met veel nauw verbonden delen. Als zo’n systeem een ernstige bug, een geheugenprobleem of een blokkerende operatie tegenkomt, kan de fout zich uitbreiden — alsof het omschakelen van één stroomschakelaar het hele gebouw in het donker zet.
Erlang drijft het tegenovergestelde: verantwoordelijkheden isoleren. Als één kleine worker zich misdraagt, kun je die worker stoppen en vervangen zonder niet-gerelateerd werk neer te halen.
Berichtuitwisseling als “briefjes sturen”
Hoe coördineren deze workers? Ze spreken niet in elkaars interne state. Ze sturen berichten — meer zoals briefjes dan het delen van een rommend whiteboard.
Een worker kan zeggen: “Hier is een nieuw verzoek,” “Deze gebruiker is offline,” of “Probeer het over 5 seconden opnieuw.” De ontvangende worker leest het briefje en beslist wat te doen.
Het belangrijke voordeel is begrenzing: omdat workers geïsoleerd zijn en via berichten communiceren, is het riskanter dat fouten zich door het hele systeem verspreiden.
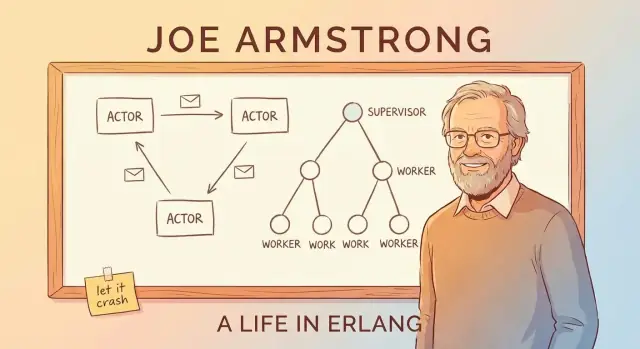
Berichtuitwisseling en het actor-model (zonder jargon)
Een eenvoudige manier om Erlangs actor-model te begrijpen is het systeem voor te stellen als veel kleine, onafhankelijke workers.
Actors: kleine workers die alleen via berichten praten
Een actor is een zelfvoorzienende eenheid met zijn eigen private state en een mailbox. Hij doet drie basale dingen:
- ontvangt berichten (één per keer) uit zijn mailbox
- bijgewerkt zijn interne state
- stuurt berichten naar andere actors
Dat is het. Geen gedeelde variabelen, geen “in het geheugen van een andere worker rommelen.” Als de ene actor iets van een andere nodig heeft, vraagt hij dat via een bericht.
Waarom het vermijden van gedeelde state hele categorieën bugs wegneemt
Wanneer meerdere threads dezelfde data delen, kun je race conditions krijgen: twee dingen veranderen dezelfde waarde vrijwel tegelijk en de uitkomst hangt van timing. Daar worden bugs intermittend en moeilijk reproduceerbaar.
Met message passing bezit elke actor zijn data. Andere actors kunnen het niet direct muteren. Dat elimineert niet alle bugs, maar vermindert aanzienlijk problemen veroorzaakt door gelijktijdige toegang tot hetzelfde stuk state.
Back-pressure, uitgelegd als een koffieshop-rij
Berichten komen niet “gratis.” Als een actor berichten sneller ontvangt dan hij kan verwerken, groeit zijn mailbox (queue). Dat is back-pressure: het systeem vertelt je indirect “dit deel is overbelast.”
In de praktijk monitor je mailboxgroottes en bouw je limieten: load afschrijven, batchen, bemonsteren of werk naar meer actors pushen in plaats van queues eindeloos te laten groeien.
Een concreet voorbeeld: chat-notificaties
Stel je een chat-app voor. Elke gebruiker kan een actor hebben die verantwoordelijk is voor het bezorgen van notificaties. Als een gebruiker offline gaat, blijven berichten binnenkomen — dus groeit de mailbox. Een goed ontworpen systeem kan de queue beperken, niet-kritische notificaties droppen of overschakelen naar een digest-modus in plaats van één trage gebruiker de hele service te laten degraderen.
“Let It Crash” uitgelegd: faal snel, herstel sneller
“Let it crash” is geen kreet voor slordige engineering. Het is een betrouwbaarheidsstrategie: wanneer een component in een slechte of onverwachte staat terechtkomt, moet die snel en luid stoppen in plaats van mank te blijven lopen.
Wat het echt betekent
In plaats van code te schrijven die binnen één proces elke mogelijke edge-case probeert af te handelen, moedigt Erlang aan om elke worker klein en gefocust te houden. Als die worker iets tegenkomt dat hij echt niet aankan (corrupte state, geschonden aannames, onverwachte input), sluit hij af. Een ander deel van het systeem is verantwoordelijk om hem weer op te starten.
Dit verschuift de hoofdvraag van “Hoe voorkomen we falen?” naar “Hoe herstellen we netjes als falen gebeurt?”
De afweging: minder defensieve checks, duidelijkere logica
Overal defensief programmeren kan eenvoudige flows veranderen in een doolhof van conditionals, retries en gedeeltelijke states. “Let it crash” ruilt wat van die in-process complexiteit in voor:
- simpelere, beter leesbare codepaden
- snellere detectie van verbrijzelde aannames
- consistent herstel (omdat het gecentraliseerd is)
Het grote idee is dat herstel voorspelbaar en herhaalbaar moet zijn, niet geïmproviseerd in elke functie.
Wanneer het past — en wanneer niet
Het past het best wanneer fouten herstelbaar en geïsoleerd zijn: een tijdelijke netwerkfout, een slecht verzoek, een vastgelopen worker of een third-party timeout.
Het is geen goede match wanneer een crash onherstelbare schade veroorzaakt, zoals:
- dataverlies zonder duurzame bron van waarheid
- safety-kritische operaties waar “probeer opnieuw” onacceptabel is
Snelle restarts en bekende-goede state
Crashen helpt alleen als terugkomen snel en veilig is. In de praktijk betekent dat workers herstarten in een bekende-goede staat — vaak door configuratie opnieuw in te laden, in-memory caches van duurzame opslag opnieuw op te bouwen en werk te hervatten zonder te doen alsof de gebroken staat nooit bestond.
Supervisiebomen: doelbewust ontwerpen voor falen
Erlangs “let it crash” idee werkt alleen omdat crashes niet aan het toeval worden overgelaten. Het sleutelpatroon is de supervisieboom: een hiërarchie waarbij supervisors optreden als managers en workers het echte werk doen (een oproep afhandelen, een sessie bijhouden, een queue consumeren, enz.). Als een worker zich misdraagt, merkt de manager het en start hem opnieuw.
Managers die workers herstarten
Een supervisor probeert een kapotte worker niet ter plaatse te “fixen.” In plaats daarvan past hij een eenvoudig, consistent regel toe: als de worker sterft, start een verse. Dat maakt het herstelpad voorspelbaar en vermindert de noodzaak voor ad-hoc error handling verspreid door de code.
Net zo belangrijk, supervisors kunnen ook beslissen wanneer niet te herstarten — als iets te vaak crasht, kan dat wijzen op een dieperliggend probleem, en herhaaldelijk herstarten kan het erger maken.
Herstartstrategieën (hoog niveau)
Supervisie is geen one-size-fits-all. Veelvoorkomende strategieën zijn:
- One-for-one: alleen de falende worker wordt herstart. Past bij onafhankelijke taken waar één falen anderen niet zou moeten raken.
- Group restarts: als één worker faalt, wordt een gerelateerde set samen herstart. Past bij sterk gekoppelde componenten die synchroon moeten blijven.
Dependencies: het deel waar je over na moet denken
Goed supervisieontwerp begint met een afhankelijkheidskaart: welke componenten vertrouwen op welke anderen en wat betekent een “verse start” voor hen.
Als een session handler afhankelijk is van een cacheproces, kan het herstarten van alleen de handler hem achterlaten met een slechte state. Die samen onder de juiste supervisor groeperen (of ze samen herstarten) verandert rommelige faalmodi in consistente, herhaalbare herstelpatronen.
OTP: herbruikbare bouwblokken voor betrouwbare services
Als Erlang de taal is, is OTP (Open Telecom Platform) het onderdelenpakket dat “let it crash” omzet in iets dat je jaren in productie kunt draaien.
OTP is geen enkele bibliotheek — het is een set conventies en kant-en-klare componenten (genoemd behaviours) die de saaie maar kritieke onderdelen van het bouwen van services oplossen:
gen_server voor een langlopende worker die state bewaart en requests één voor één afhandeltsupervisor voor automatisch herstarten van gefaalde workers volgens duidelijke regelsapplication voor definiëren hoe een volledige service start, stopt en in een release past
Dit zijn geen “magie.” Het zijn sjablonen met goed gedefinieerde callbacks, zodat je code in een bekend patroon past in plaats van elke keer een nieuw patroon te bedenken.
Waarom standaardpatronen beter zijn dan custom frameworks
Teams bouwen vaak ad-hoc background workers, huisgemaakte monitoring hooks en eenmalige restart-logica. Het werkt — totdat het niet meer werkt. OTP vermindert dat risico door iedereen naar dezelfde vocabulary en lifecycle te duwen. Als een nieuwe engineer aansluit, hoeft die niet eerst je custom framework te leren; die kan vertrouwen op gedeelde patronen die breed worden begrepen in het Erlang-ecosysteem.
Hoe OTP architectuur dagelijks stuurt
OTP stuurt je om te denken in termen van processrollen en verantwoordelijkheden: wat is een worker, wat is een coördinator, wat start wat opnieuw en wat mag nooit automatisch herstarten.
Het moedigt ook goede hygiëne aan: duidelijke naamgeving, expliciete opstartvolgorde, voorspelbare shutdown en ingebouwde monitoring-signalen. Het resultaat is software die ontworpen is om continu te draaien — services die van fouten herstellen, evolueren in de tijd en hun werk doen zonder voortdurend menselijk toezicht.
BEAM VM: de runtime die het model praktisch maakt
Erlangs grote ideeën — kleine processen, message passing en “let it crash” — zouden veel moeilijker in productie te gebruiken zijn zonder de BEAM virtual machine (VM). BEAM is de runtime die deze patronen natuurlijk laat aanvoelen, niet fragiel.
Scheduling: eerlijkheid boven “één grote thread”
BEAM is gebouwd om enorme aantallen lichtgewicht processen te draaien. In plaats van te vertrouwen op een handvol OS-threads en hopen dat de applicatie zich gedraagt, plant BEAM Erlang-processen zelf in.
Het praktische voordeel is responsiviteit onder load: werk wordt in kleine stukjes gesneden en eerlijk geroteerd, zodat geen enkele drukke worker lang het systeem domineert. Dat past perfect bij een service opgebouwd uit veel onafhankelijke taken — elk doet een stukje werk en geeft dan op.
Isolatie en “per-proces” geheugenopruiming
Elke Erlang-proces heeft zijn eigen heap en zijn eigen garbage collection. Dat is een sleutel-detail: geheugen opschonen in één proces vereist niet het pauzeren van het hele programma.
Net zo belangrijk, processen zijn geïsoleerd. Als één crasht, corrumpeert het niet het geheugen van anderen en blijft de VM leven. Deze isolatie is de basis die supervisiebomen realistisch maakt: falen wordt ingeperkt en vervolgens afgehandeld door het gefaalde deel opnieuw te starten in plaats van alles neer te halen.
Distributie: meerdere nodes, één systeem
BEAM ondersteunt ook distributie op eenvoudige wijze: je kunt meerdere Erlang-nodes (losse VM-instanties) draaien en ze berichten laten uitwisselen. Als je “processen praten via messaging” begrijpt, is distributie een uitbreiding van hetzelfde idee — sommige processen wonen gewoon op een andere node.
BEAM draait niet om ruwe snelheidsbeloften. Het draait om het standaard maken van concurrency, foutbegrenzing en herstel, zodat het betrouwbaarheidsverhaal praktisch is in plaats van theoretisch.
Updates zonder het systeem te stoppen (hot code, zorgvuldig)
Een van Erlangs meest besproken trucs is hot code swapping: delen van een draaiend systeem bijwerken met minimale downtime (waar runtime en tooling het ondersteunen). De praktische belofte is niet “nooit meer herstarten,” maar “push fixes zonder een kleine bug in een langdurige outage te veranderen.”
Wat “hot code” echt betekent
In Erlang/OTP kan de runtime twee versies van een module tegelijk geladen houden. Bestaande processen kunnen hun werk afronden met de oude versie terwijl nieuwe calls de nieuwe versie gebruiken. Dat geeft je ruimte om een bug te patchen, een feature te roll-outen of gedrag aan te passen zonder iedereen van het systeem af te kicken.
Goed gedaan ondersteunt dit direct betrouwbaarheiddoelen: minder volledige restarts, kortere onderhoudsvensters en sneller herstel wanneer iets in productie glipt.
De beperkingen die niemand mag negeren
Niet elke wijziging is veilig om live te wisselen. Enkele voorbeelden die extra zorg vereisen (of een restart):
- wijzigingen in de staatvorm (een proces verwacht data in één formaat, maar nieuwe code verwacht een ander)
- protocol- of berichtformatwijzigingen die over services heen consistent moeten zijn
- schema-migraties die tijd kosten of coördinatie vereisen
Erlang biedt mechanismen voor gecontroleerde transities, maar je moet nog steeds het upgradepad ontwerpen.
De mentaliteit: upgrades en rollbacks zijn normaal
Hot upgrades werken het best wanneer upgrades en rollbacks routine-operaties zijn, niet zeldzame noodgevallen. Dat betekent versiebeheer, compatibiliteit en een duidelijk “undo”-pad vanaf het begin plannen. In de praktijk combineren teams live-upgrade technieken met gefaseerde rollouts, health checks en supervisie-gebaseerd herstel.
Zelfs als je Erlang nooit gebruikt, draagt de les over: ontwerp systemen zodat veilig veranderen een eersteklas vereiste is, niet een bijzaak.
Realtime-platforms gaan minder over perfecte timing en meer over responsief blijven terwijl dingen constant fout gaan: netwerken wiebelen, dependencies vertragen en gebruikerstraffic piekt. Erlangs ontwerp — gekoesterd door Joe Armstrong — past bij die realiteit omdat het falen veronderstelt en concurrency normaal behandelt, niet uitzonderlijk.
Veelvoorkomende realtime use-cases
Je ziet Erlang-stijl denken overal waar veel onafhankelijke activiteiten tegelijk plaatsvinden:
- Messaging en chat: miljoenen kleine gesprekken, elk met eigen state en retries.
- Realtime communicatie: voice/video-signaling, presence-updates en sessiecoördinatie.
- IoT-coördinatie: fleets apparaten die inchecken, wegvallen en onvoorspelbaar weer terugkomen.
- Payments workflows: multi-stap processen waar sommige stappen traag, onbeschikbaar zijn of compenserende acties nodig hebben.
Wat “soft real-time” meestal betekent
De meeste producten hebben geen harde garanties nodig zoals “elke actie binnen 10 ms.” Ze hebben soft real-time: consistent lage latentie voor typische verzoeken, snel herstel als delen falen en hoge beschikbaarheid zodat gebruikers incidenten zelden merken.
Falen is normaal: ontwerp eromheen
Echte systemen krijgen te maken met zaken zoals:
- Verbroken verbindingen (mobiele netwerken, Wi‑Fi handoffs)
- Timeouts wanneer een downstream service traag is
- Gedeeltelijke uitval waar één regio of dependency degradeert
Erlangs model moedigt je aan elke activiteit te isoleren (een gebruikerssessie, apparaat, betalingspoging) zodat een fout zich niet verspreidt. In plaats van één gigantische “probeer alles te handelen” component, kun je in kleinere eenheden redeneren: elke worker doet één taak, praat via berichten en als hij faalt wordt hij netjes herstart.
Die verschuiving — van “voorkom elk falen” naar “begrens en herstel snel” — is vaak wat realtime-platforms stabiel maakt onder druk.
Veelvoorkomende misverstanden en reële grenzen
Erlangs reputatie kan klinken als een belofte: systemen die nooit uitvallen omdat ze gewoon herstarten. De realiteit is praktischer — en nuttiger. “Let it crash” is een tool om betrouwbare services te bouwen, geen vrijbrief om moeilijke problemen te negeren.
Herstarts zijn geen pleister
Een veelgemaakte fout is supervisie gebruiken om diepe bugs te verbergen. Als een proces direct na het starten crasht, kan een supervisor blijven herstarten tot je een crash loop hebt — CPU verbranden, logs vollopen en mogelijk een grotere storing veroorzaken dan de oorspronkelijke bug.
Goede systemen voegen backoff, restart-intensiteitslimieten en duidelijke “geef op en escaleer” gedrag toe. Herstarts moeten gezond gedrag herstellen, niet een gebroken invariant verbergen.
State is het lastige deel
Een proces herstarten is vaak makkelijk; de juiste state herstellen is dat niet. Als state alleen in geheugen leeft, moet je beslissen wat “correct” betekent na een crash:
- moet je herbouwen vanuit duurzame opslag?
- kun je events veilig her-afspelen (idempotentie)?
- wat gebeurt er met lopend werk of gedeeltelijk toegepaste updates?
Fouttolerantie vervangt geen zorgvuldig datadesign. Het dwingt je er expliciet over na te denken.
Je hebt nog steeds observability nodig
Crashes helpen alleen als je ze vroeg ziet en begrijpt. Dat betekent investeren in logging, metrics en tracing — niet alleen “hij is herstart, dus het is goed.” Je wilt toenemende restart-rates, groeiende queues en trage dependencies zien voordat gebruikers het merken.
Operationele limieten bestaan
Zelfs met BEAMs sterke kanten kunnen systemen op gewone manieren falen:
- Geheugengroei door leaks, caches of grote heaps
- Mailbox-achterstand wanneer producers sneller zijn dan consumers (latentiepieken en timeouts)
- Dependency-falen (databases, third-party APIs, DNS) waar herstarten van je code de root-cause niet oplost
Erlangs model helpt je falen in te perken en ervan te herstellen — maar het kan ze niet wegnemen.
Hoe je de lessen vandaag toepast (ook zonder Erlang)
Erlangs grootste gift is niet syntax — het zijn gewoonten voor het bouwen van services die blijven draaien als onderdelen onvermijdelijk falen. Je kunt die gewoonten in bijna elke stack toepassen.
Zet ideeën om in concrete acties
Begin met falengrenzen expliciet te maken. Breek je systeem in componenten die onafhankelijk kunnen falen en zorg dat elk een duidelijk contract heeft (inputs, outputs en wat “fout” betekent).
Automatiseer daarna herstel in plaats van te proberen elke fout te voorkomen:
- Isoleer componenten: draai risicovol werk in aparte processen/containers/threads zodat één crash niet alles vergiftigt.
- Definieer grenzen: timeouts, retries met backoff, circuit breakers en bulkheads om kettingstoringen te stoppen.
- Maak herstel routine: health checks, auto-restarts en veilige defaults zodat het systeem snel naar een bekende-goede staat terugkeert.
Een praktische manier om deze gewoonten echt te laten leven is ze in tooling en lifecycle te verankeren, niet alleen in code. Bijvoorbeeld: wanneer teams Koder.ai gebruiken om web-, backend- of mobiele apps via chat te vibe-coderen, moedigt de workflow Planning Mode aan, repeatable deployments en veilige iteratie met snapshots en rollback — concepten die aansluiten bij dezelfde operationele mentaliteit die Erlang populair maakte: ga ervan uit dat verandering en falen zullen gebeuren en maak herstel saai.
Beginpunten buiten Erlang
Je kunt “supervisie”-patronen benaderen met tools die je misschien al gebruikt:
- Supervisors: systemd, Kubernetes Deployments of een process manager (restart-on-failure, readiness probes).
- Procesisolatie: aparte worker-services voor CPU-intensief of onbetrouwbaar werk.
- Berichtuitwisseling: queues/streams (RabbitMQ, SQS, Kafka) om producers en consumers te decouplen en pieken af te vlakken.
Een korte beslis-checklist
Voordat je patronen kopieert, bepaal wat je echt nodig hebt:
- Verwachte faalmodi: overload, gedeeltelijke uitval, trage dependencies, slechte input, geheugenlekkages.
- Latentie-eisen: heb je realtime-respons nodig of is eventual processing OK?
- Hersteldoel: snelle restart, graceful degradering of handmatige interventie?
- Teamvaardigheden en tooling: wie is on-call, wie regelt observability en incident response?
Als je praktische vervolgstappen wilt, zie meer gidsen in /blog, of bekijk implementatiedetails in /docs (en plannen in /pricing als je tooling evalueert).