Welk probleem probeerde NoSQL op te lossen?
NoSQL ontstond toen veel teams een mismatch ervoeren tussen wat hun applicaties nodig hadden en waar traditionele relationele databases (SQL-databases) voor geoptimaliseerd waren. SQL “faalde” niet per se — maar op webschaal begonnen teams andere doelen te prioriteren.
De twee drukpunten: schaal en verandering
Ten eerste, schaal. Populaire consumentenapps kregen verkeerspieken, constante schrijfactiviteit en enorme hoeveelheden door gebruikers gegenereerde data. Voor deze workloads werd “koop gewoon een grotere server” duur, traag om uit te rollen en uiteindelijk beperkt door de grootste machine die je praktisch kon draaien.
Ten tweede, verandering. Productfeatures evolueerden snel en de onderliggende data paste niet altijd netjes in een vaste set tabellen. Nieuwe attributen toevoegen aan gebruikersprofielen, meerdere eventtypes opslaan of semi-gestructureerde JSON van verschillende bronnen verwerken betekende vaak herhaalde schema-migraties en coördinatie tussen teams.
Waarom relationele databases het in sommige gevallen lastig hadden
Relationele databases zijn uitstekend in het afdwingen van structuur en het mogelijk maken van complexe queries over genormaliseerde tabellen. Maar bij sommige high-scale workloads maken juist die sterke punten het moeilijker om ze effectief te benutten:
- Veel gelijktijdige schrijfbewerkingen over veel tabellen kunnen tot contention leiden.
- Zware join-gebaseerde queries kunnen kostbaar worden naarmate data snel groeit.
- Horizontaal schalen over veel machines is mogelijk, maar het beheren terwijl je overal strikte consistentie behoudt kan ingewikkeld zijn.
Het resultaat: sommige teams zochten systemen die bepaalde garanties en mogelijkheden inruilden voor eenvoudiger schalen en snellere iteratie.
NoSQL: een familie van benaderingen, geen één ding
NoSQL is geen enkele database of ontwerp. Het is een overkoepelende term voor systemen die de nadruk leggen op een mix van:
- Horizontaal schalen (meer machines toevoegen)
- Flexibele datamodellen
- Toegangspatronen afgestemd op specifieke applicatiebehoeften
Een reset van verwachtingen
NoSQL was nooit bedoeld als universele vervanging voor SQL. Het is een set afwegingen: je wint mogelijk schaalbaarheid of schema-flexibiliteit, maar accepteert zwakkere consistentiegaranties, minder ad-hoc query-opties of meer verantwoordelijkheid in applicatieniveau datamodellering.
Waarom traditioneel schalen begon te haperen
Jarenlang was het standaardantwoord op een trage database simpel: koop een grotere server. Meer CPU, meer RAM, snellere schijven, en behoud hetzelfde schema en operationeel model. Deze “scale up”-aanpak werkte — totdat het onpraktisch werd.
Verticale schaalbereik liep tegen grenzen aan
High-end machines worden snel duur, en de prijs/performancerelatie wordt na een bepaald punt ongunstig. Upgrades vereisen vaak grote, weinig frequente budgetgoedkeuringen en onderhoudsvensters om data te verplaatsen en te cut-overen. Zelfs als je het je kunt veroorloven, heeft één server altijd een grens: één geheugensubsys, één opslagpad en één primaire node die de schrijflast absorbeert.
Groei veranderde het karakter van de workload
Naarmate producten groeiden, kregen databases constante lees-/schrijfdruk in plaats van sporadische pieken. Verkeer werd echt 24/7 en bepaalde features veroorzaakten onevenwichtige toegangs-patronen. Een klein aantal sterk geaccessede rijen of partities kon het meeste verkeer trekken, waardoor hot tables (of hot keys) ontstonden die alles vertraagden.
Operationele knelpunten werden gebruikelijk:
- Index-bloat door nieuwe features die meer secundaire indexes vroegen
- Contention door veel gelijktijdige schrijfbewerkingen op dezelfde tabellen
- Lock-waits die latentie onvoorspelbaar maakten onder belasting
- Replicatievertraging en tragere failovers naarmate datasets groeiden
Grotere servers losten wereldwijde beschikbaarheid niet op
Veel applicaties moesten beschikbaar zijn in meerdere regio's, niet alleen snel in één datacenter. Eén “hoofd”-database op één locatie vergroot latentie voor verre gebruikers en maakt uitval dramatischer. De vraag verschoven van “Hoe kopen we een grotere box?” naar “Hoe draaien we de database over veel machines en locaties?”
De behoefte aan flexibele datamodellen
Relationele databases schitteren wanneer de vorm van je data stabiel is. Veel moderne producten blijven echter niet stabiel. Een tabelschema is bewust strikt: elke rij volgt dezelfde set kolommen, types en constraints. Die voorspelbaarheid is waardevol — tot je snel wil itereren.
Rigide schema's en de werkelijke kosten van verandering
In de praktijk kunnen frequente schema-wijzigingen duur zijn. Een ogenschijnlijk kleine update kan migraties, backfills, indexupdates, gecoördineerde deploy-timing en compatibiliteitsplanning vereisen zodat oudere codepaden niet breken. Op grote tabellen kan zelfs het toevoegen van een kolom of het wijzigen van een type een tijdrovende operatie met reëel operationeel risico worden.
Die frictie zet teams ertoe aan veranderingen uit te stellen, workarounds op te stapelen of rommelige blobs in tekstvelden op te slaan — geen van allen ideaal voor snelle iteratie.
Semi-gestructureerde data past bij hoe producten evolueren
Veel applicatiegegevens zijn van nature semi-gestructureerd: genestelde objecten, optionele velden en attributen die in de loop van de tijd veranderen.
Bijvoorbeeld kan een “gebruikersprofiel” beginnen met naam en e-mail en later groeien met voorkeuren, gekoppelde accounts, verzendadressen, meldingsinstellingen en experimentflags. Niet elke gebruiker heeft elk veld en nieuwe velden verschijnen geleidelijk. Documentachtige modellen kunnen geneste en ongelijkvormige structuren direct opslaan zonder elke record in hetzelfde strikte sjabloon te dwingen.
Snellere iteratie, minder ongemakkelijke joins
Flexibiliteit vermindert ook de behoefte aan complexe joins voor bepaalde data-vormen. Wanneer één scherm een samengesteld object nodig heeft (een bestelling met items, verzendinfo en statusgeschiedenis), vereist relationeel ontwerp meerdere tabellen en joins — plus ORM-lagen die die complexiteit proberen te verbergen maar vaak wrijving toevoegen.
NoSQL-opties maakten het gemakkelijker om data te modelleren dichter bij hoe de applicatie het leest en schrijft, waardoor teams sneller konden uitrollen.
De web-schaalverschuiving die database-eisen veranderde
Webapplicaties werden niet alleen groter — ze veranderden van vorm. In plaats van een voorspelbaar aantal interne gebruikers tijdens kantooruren, begonnen producten miljoenen wereldwijde gebruikers 24/7 te bedienen, met plotselinge pieken door lanceringen, nieuws of sociale shares.
Altijd-aan verwachtingen verhoogden de lat: downtime werd een headline, geen ongemak. Tegelijk werden teams gevraagd features sneller te leveren — vaak voordat iemand wist wat het “definitieve” datamodel zou worden.
Gedistribueerd werd de standaard route naar groei
Om bij te blijven was het schalen van één database-server niet meer genoeg. Hoe meer verkeer je handelde, hoe meer je capaciteit wilde die je incrementeel kon toevoegen — een node toevoegen, load verdelen, falen isoleren.
Dit duwde architectuur naar fleet-achtige opstellingen in plaats van één “hoofd” box en veranderde wat teams van databases verwachtten: niet alleen correctheid, maar voorspelbare prestaties bij hoge gelijktijdigheid en gracieus gedrag wanneer delen van het systeem ongezond zijn.
Patronen die teams adopteerden voordat databases bij waren
Voordat “NoSQL” mainstream werd, bogen veel teams systemen al naar web-schaalrealiteiten:
- Caching-lagen (vaak in-memory) om herhaalde reads te verminderen
- Denormalisatie om dure joins te vermijden en round-trips te verminderen
- Precomputed views en materialized rollups voor feeds, timelines en dashboards
Deze technieken werkten, maar verplaatsten complexiteit naar applicatiecode: cache-invalidation, het consistent houden van gedupliceerde data en het bouwen van pipelines voor “ready-to-serve” records.
Hoe dit databases dwong te evolueren
Naarmate deze patronen standaard werden, moesten databases data over machines kunnen verdelen, gedeeltelijke fouten tolereren, hoge schrijfsnelheden aan en evoluerende data netjes representeren. NoSQL-databases ontstonden deels om gangbare web-schaalstrategieën eersteklas te maken in plaats van permanente workarounds.
Gedistribueerde afwegingen en het CAP-theorema
Ship met veranderende schema's
Modelleer flexibele, evoluerende records in een app die je kunt aanpassen als eisen veranderen.
Wanneer data op één machine leeft lijken de regels simpel: er is één bron van waarheid en elke read of write kan direct worden gecontroleerd. Spreid je data over servers (vaak regio's), dan verschijnt een nieuwe realiteit: berichten kunnen vertraagd raken, nodes kunnen falen en delen van het systeem kunnen tijdelijk stoppen met communiceren.
De kernafweging (in gewone taal)
Een gedistribueerde database moet beslissen wat te doen als hij niet veilig kan coördineren. Blijft hij verzoeken bedienen zodat de app “up” blijft, ook als resultaten iets verouderd zijn? Of weigert hij bepaalde bewerkingen totdat replica's overeenkomen, wat voor gebruikers als downtime kan lijken?
Dergelijke situaties komen voor bij routerfouten, overbelaste netwerken, rolling deploys, firewall-misconfiguraties en cross-region replicatievertragingen.
CAP in één beeld: C, A en P
Het CAP-theorema is een shorthand voor drie eigenschappen die je tegelijk zou willen:
- Consistency (C): elke read geeft de nieuwste write terug (of een fout). In de praktijk: “iedereen ziet nu hetzelfde antwoord.”
- Availability (A): elk verzoek krijgt een antwoord (niet per se met de nieuwste data).
- Partition Tolerance (P): het systeem blijft werken zelfs als het netwerk in geïsoleerde groepen splitst.
Het kernpunt is niet “kies twee voor altijd.” Het is: wanneer een netwerkpartitionering optreedt, moet je kiezen tussen consistentie en beschikbaarheid. In web-schaal systemen worden partitioneringen als onvermijdelijk beschouwd — zeker in multi-region setups.
Partities verbinden direct met echte uitvalscenario's
Stel dat je app in twee regio's draait voor veerkracht. Een kabelbreuk of routingprobleem voorkomt synchronisatie.
- Als je beschikbaarheid prioriteert, blijven beide regio's schrijfbewerkingen accepteren en kan data tijdelijk uit elkaar lopen.
- Als je consistentie prioriteert, kan één regio schrijfbewerkingen (of reads) weigeren totdat er overeenstemming is.
Verschillende NoSQL-systemen (en verschillende configuraties binnen hetzelfde systeem) maken verschillende compromissen, afhankelijk van wat belangrijker is: gebruikerservaring tijdens fouten, correctheidsgaranties, operationele eenvoud of herstelgedrag.
Schalen door uit te breiden: sharding en replicatie
Horizontaal schalen betekent capaciteit vergroten door meer machines (nodes) toe te voegen in plaats van één grotere server te kopen. Voor veel teams was dit een financiële en operationele verschuiving: commodity-nodes konden stapsgewijs worden toegevoegd, falen werd verwacht en groei vereiste geen riskante “big box” migraties.
Sharding (partitionering): het werk verdelen
Om veel nodes nuttig te maken leunden NoSQL-systemen op sharding (ook partitionering genoemd). In plaats van één database die elk verzoek afhandelt, wordt data opgesplitst in partitities en verspreid over nodes.
Een eenvoudig voorbeeld is partitioneren op een sleutel (zoals user_id):
- Node A slaat gebruikers 1–1.000.000 op
- Node B slaat gebruikers 1.000.001–2.000.000 op
Reads en writes spreiden zich, verminderen hotspots en laten de throughput groeien naarmate je nodes toevoegt. De partition key wordt een ontwerpprobleem: kies een sleutel die bij querypatronen past, anders kun je per ongeluk te veel verkeer naar één shard leiden.
Replicatie: beschikbaarheid en lees-schaal
Replicatie houdt in dat meerdere kopieën van dezelfde data op verschillende nodes bewaard worden. Dit verbetert:
- Beschikbaarheid: als één node faalt, kan een replica verzoeken bedienen.
- Leescapaciteit: reads kunnen vanaf meerdere replica's worden bediend.
Replicatie maakt het ook mogelijk data over racks of regio's te verspreiden om lokale uitval te overleven.
De verborgen kosten: rebalancing en operatiewerk
Sharding en replicatie brengen continue operationele taken met zich mee. Als data groeit of nodes veranderen, moet het systeem rebalancen — partitities verplaatsen terwijl het online blijft. Als dat slecht wordt afgehandeld kan rebalancing latency-pieken, ongelijke load of tijdelijke capaciteitsproblemen veroorzaken.
Dit is een kernafweging: goedkoper schalen door meer nodes, in ruil voor complexere distributie, monitoring en failover-hantering.
Consistentiemodellen: van strikt tot eventual
Zodra data verspreid is, moet een database definiëren wat “correct” betekent wanneer updates gelijktijdig gebeuren, netwerken vertragen of nodes niet kunnen communiceren.
Strikte (sterke) consistentie
Bij sterke consistentie geldt: zodra een write bevestigd is, moet elke lezer die meteen zien. Dit komt overeen met de “enkele bron van waarheid” ervaring die men vaak associëert met relationele databases.
De uitdaging is coördinatie: strikte garanties over nodes heen vereisen meerdere berichten, wachten op genoeg antwoorden en het omgaan met fouten tijdens de operatie. Hoe verder nodes uit elkaar staan (of hoe drukker het is), hoe meer latentie je kunt introduceren — soms bij elke write.
Eventuele consistentie
Eventuele consistentie versoepelt die garantie: na een write kunnen verschillende nodes korte tijd verschillende antwoorden geven, maar het systeem convergeert over tijd.
Voorbeelden:
- Een “like”-teller kan op de ene replica 101 likes tonen terwijl een andere nog 100 laat zien voor een paar seconden.
- Een nieuw bericht kan voor sommige gebruikers eerder in een feed verschijnen dan voor anderen, zeker over regio's heen.
Voor veel gebruikerservaringen is die tijdelijke mismatch acceptabel als het systeem snel en beschikbaar blijft.
Conflicten en hoe ze worden opgelost
Als twee replica's bijna tegelijk updates accepteren, heeft de database een samenvoegregel nodig.
Gangbare benaderingen zijn:
- Tijdstempels (last-write-wins): bewaar de update met het nieuwste tijdstempel. Eenvoudig, maar kan data verliezen bij klokdrift of als “nieuwste” niet semantisch juist is.
- Versievectoren (conceptueel): houd bij welke replica's welke updates hebben gezien, detecteer gelijktijdige writes en mergeer of toon conflicten.
Waar sterke consistentie nog steeds belangrijk is
Sterke consistentie is de moeite waard voor geldtransacties, voorraadlimieten, unieke gebruikersnamen, permissies en workflows waarbij “twee waarheden voor een moment” echte schade kan veroorzaken.
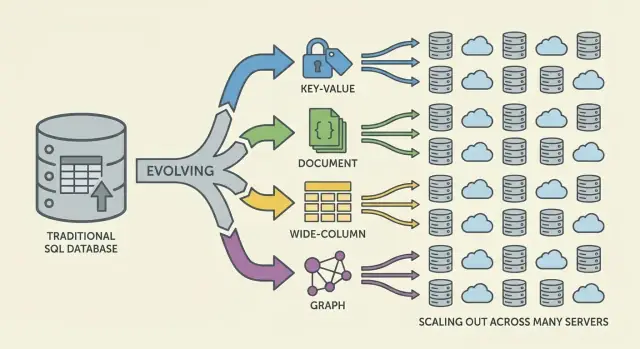
De belangrijkste NoSQL-families (en waarop ze optimaliseerden)
Probeer een hybride setup
Zet een hybride basis op met Postgres als system of record en iteratief uitbreiden.
NoSQL is een set modellen die verschillende afwegingen maken rond schaal, latentie en datastructuur. Begrijpen tot welke “familie” iets behoort helpt voorspellen wat snel zal zijn, wat pijnlijk is en waarom.
Key-value stores: snelheid door eenvoud
Key-value databases slaan een waarde op achter een unieke sleutel, als een gigantische gedistribueerde hashmap. Omdat het toegangspatroon typisch “get by key” / “set by key” is, kunnen ze extreem snel en horizontaal schaalbaar zijn.
Ze zijn ideaal als je de sleutel al kent (sessions, caching, feature flags), maar beperkt voor ad-hoc queries: filteren over meerdere velden is vaak niet het doel van het systeem.
Documentdatabases: flexibele records in JSON-achtige vorm
Documentdatabases slaan JSON-achtige documenten op (vaak in collecties). Elk document kan een iets andere structuur hebben, wat schema-flexibiliteit ondersteunt als producten evolueren.
Ze zijn geoptimaliseerd voor het lezen en schrijven van complete documenten en het zoeken op velden erin — zonder rigide tabellen. De afweging: relaties modelleren kan lastig worden en joins (als ondersteund) zijn vaak beperkter dan in relationele systemen.
Wide-column stores: hoge schrijfsnelheid op enorme schaal
Wide-column databases (geïnspireerd door Bigtable) organiseren data per rijkey met veel kolommen die per rij kunnen variëren. Ze excelleren bij enorme schrijfsnelheden en gedistribueerde opslag, wat ze geschikt maakt voor time-series, events en log-workloads.
Ze belonen doorgaans zorgvuldige ontwerpkeuzes rond toegangspatronen: je queryt efficiënt op primaire sleutel en clusteringregels, niet op willekeurige filters.
Grafdatabases: relaties eerst
Grafdatabases behandelen relaties als eersteklas data. In plaats van herhaaldelijk tabellen te joinen, traverseren ze edges tussen nodes, wat vragen als “hoe zijn deze dingen verbonden?” natuurlijk en snel maakt (frauderingsnetwerken, aanbevelingen, afhankelijkheden).
Snelle gids: wanneer welk model het beste past
- Key-value: snelste lookups per ID; caching, sessions, tellers
- Document: evoluerende productdata; profielen, catalogi, content
- Wide-column: zware ingest op schaal; telemetry, logs, time-series
- Graph: diepe relatiequeries; sociale grafen, routing, fraude-analyse
Veranderingen in datamodellering: minder joins, meer doelgericht ontwerp
Relationele databases moedigen normalisatie aan: data opsplitsen in veel tabellen en bij querytijd weer samenvoegen met joins. Veel NoSQL-systemen duwen je om te ontwerpen rond de belangrijkste toegangspatronen — soms ten koste van duplicatie — om latentie voorspelbaar te houden over nodes.
Waarom denormalisatie zo gebruikelijk is
In gedistribueerde databases kan een join data uit meerdere partitities of machines vereisen. Dat voegt netwerk-hops, coördinatie en onvoorspelbare latentie toe. Denormalisatie (gerelateerde data samen opslaan) vermindert round-trips en houdt een read vaak “lokaal”.
Een praktisch gevolg: je slaat mogelijk dezelfde klantnaam op in een orders-record, ook al bestaat die in customers, omdat “laatste 20 orders” een kernquery is.
Querybeperkingen: minder joins, meer modelleren in de app
Veel NoSQL-databases ondersteunen beperkte joins (of geen), dus neemt de applicatie meer verantwoordelijkheid:
- Haal een document/rij op via sleutel en render direct
- Lees twee datasets apart en merge in code
- Precomputeer read-modellen (tellingen, samenvattingen) om dure scans te vermijden
Daarom begint NoSQL-modellering vaak met: “Welke schermen moeten we laden?” en “Wat zijn de topqueries die snel moeten zijn?”
Secundaire indexes — en hun verborgen kosten
Secundaire indexes maken nieuwe queries mogelijk (“vind gebruikers op e-mail”), maar ze zijn niet gratis. In gedistribueerde systemen kan elke write meerdere indexstructuren updaten, wat leidt tot:
- Write-amplificatie: één logische write wordt meerdere fysieke writes
- Extra opslag: indexvermeldingen kunnen de datasize benaderen
- Operationele complexiteit: indexes kunnen achterlopen of zorgvuldig afgesteld moeten worden
Voorbeelden van modelkeuzes die prestaties verbeteren
- Embed in plaats van referentie: orderitems in een orderdocument opslaan om een order in één request te lezen
- Bucket time-series data: events per apparaat per dag bewaren om onbeperkte partitities te vermijden
- Materialiseer read-modellen: een “user_profile_summary” onderhouden om een profielpagina te serveren zonder posts, likes en follows te scannen
Voordelen en afwegingen die teams accepteerden
Compenseer je bouwtijd
Verdien credits door content te maken over Koder.ai of collega's door te verwijzen.
NoSQL werd niet gekozen omdat het in elk opzicht “beter” was. Teams kozen het omdat ze bereid waren bepaalde gemakken van relationele databases in te ruilen voor snelheid, schaal en flexibiliteit onder web-schaaldruk.
Wat teams wonnen
Schaal-out by design. Veel NoSQL-systemen maakten het praktisch om machines toe te voegen (horizontaal schalen) in plaats van continu één server te upgraden. Sharding en replicatie werden kernmogelijkheden, geen bijzaak.
Flexibele schema's. Document- en key-value-systemen laten applicaties evolueren zonder elk veld via een strikt tabeldefinitie te sturen, wat wrijving vermindert als eisen wekelijks veranderen.
Patronen voor hoge beschikbaarheid. Replicatie over nodes en regio's maakte het makkelijker om services draaiende te houden tijdens hardwarefouten of onderhoud.
Wat teams betaalden
Dataduplicatie en denormalisatie. Het vermijden van joins betekent vaak dat data gedupliceerd wordt. Dat verbetert leesprestaties maar vergroot opslag en introduceert complexiteit om updates overal door te voeren.
Consistentie-verrassingen. Eventuele consistentie is vaak acceptabel — tot het dat niet is. Gebruikers kunnen verouderde data of verwarrende randgevallen zien tenzij de applicatie ontworpen is om conflicten te verdragen of op te lossen.
Moeilijkere analytics (soms). Sommige NoSQL-stores excelleren bij operationele reads/writes maar maken ad-hoc querying, rapportage of complexe aggregaties lastiger dan SQL-first systemen.
Vroege NoSQL-acceptatie verschoof vaak inspanning van databasefeatures naar engineeringdiscipline: replicatie monitoren, partitities beheren, compaction draaien, backups/restores plannen en faalscenario's load-testen. Teams met sterke operationele volwassenheid profiteerden het meest.
Hoe je de afwegingen beoordeelt
Kies op basis van workload-realiteiten: verwachte latentie, piekdoorvoer, dominante querypatronen, tolerantie voor verouderde lezingen en herstelvereisten (RPO/RTO). De “juiste” NoSQL-keuze is meestal degene die past bij hoe je applicatie faalt, schaalt en bevraagd moet worden — niet de meest indrukwekkende featurelijst.
Hoe bepaal je of NoSQL vandaag geschikt is
Kiezen voor NoSQL moet niet beginnen met databasemerken of hype — begin met wat je applicatie moet doen, hoe het zal groeien en wat “correct” voor je gebruikers betekent.
Begin met eisen en toegangspatronen
Voordat je een datastore kiest, noteer:
- De top 5–10 queries/bewerkingen die je moet ondersteunen (reads, writes, search, aggregaties)
- Verwacht verkeer nu vs over 12–24 maanden
- Je tolerantie voor verouderde data (milliseconden, seconden, nooit)
- Je faalverwachtingen (wat gebeurt er als een node of regio uitvalt?)
Als je je toegangspatronen niet duidelijk kunt beschrijven, wordt elke keuze giswerk — vooral bij NoSQL, waar modellering vaak wordt gevormd door lees- en schrijfpatronen.
Een simpele beslissingschecklist (SQL vs NoSQL vs hybride)
Gebruik dit als snelle filter:
- Kies SQL als je standaard sterke consistentie nodig hebt, veel ad-hoc queries en veel relaties die van joins profiteren.
- Kies NoSQL als je eenvoudige horizontale schaal voor specifieke toegangspatronen nodig hebt, je data rond die patronen kunt modelleren en enige versoepelde consistentie kunt accepteren.
- Kies hybrid als verschillende delen van de app verschillende behoeften hebben (veelvoorkomend in echte producten).
Een praktische aanwijzing: als je “kernwaarheid” (bestellingen, betalingen, voorraad) te allen tijde correct moet zijn, bewaar die in SQL of een ander sterk consistent store. Voor high-volume content, sessies, caching, activity feeds of flexibele gebruikersdata past NoSQL vaak goed.
Overweeg polyglot persistence (bewust)
Veel teams slagen met meerdere stores: bijvoorbeeld SQL voor transacties, een documentdatabase voor profielen/content en een key-value store voor sessions. Het doel is niet complexiteit omwille van complexiteit — het is workloads matchen met tools die ze schoon afhandelen.
Dit is ook waar ontwikkelaarservaring telt. Als je architectuur aan het itereren bent (SQL vs NoSQL vs hybrid), kan het snel opzetten van een prototype — API, datamodel en UI — beslissingen minder risicovol maken. Platforms zoals Koder.ai helpen teams daarbij door full-stack apps vanuit chat te genereren, doorgaans met een React-frontend en een Go + PostgreSQL-backend, en daarna de broncode te exporteren. Zelfs als je later een NoSQL-store voor specifieke workloads introduceert, kan een sterk SQL “system of record” plus snelle prototyping, snapshots en rollback experimenten veiliger en sneller maken.
Valideer met tests, niet met meningen
Wat je ook kiest, bewijs het:
- Voer loadtests uit met realistische queries en datasets.
- Doe faaltests (kill nodes, simuleer netwerkproblemen, test restores).
- Maak een schema-evolutieplan: hoe voeg je velden toe, migreer je records en houd je oude/nieuwe versies compatibel tijdens uitrol.
Als je deze scenario's niet kunt testen, blijft je databasekeuze theoretisch — en zal productie uiteindelijk het testen voor je doen.