Wat sharding is (en wat het niet is)
Sharding (ook wel horizontale partitionering) betekent dat wat naar je applicatie als één database lijkt, wordt opgesplitst over meerdere machines, genaamd shards. Elke shard bevat slechts een deel van de rijen, maar samen vormen ze de volledige dataset.
Één logisch tabel, veel fysieke plekken
Een handig mentaal model is het verschil tussen logische structuur en fysieke plaatsing.
- Logisch: je hebt nog steeds één “Users”-tabel (dezelfde kolommen, dezelfde betekenis).
- Fysiek: de rijen voor die tabel liggen op verschillende plekken—misschien zitten gebruikers met IDs 1–1.000.000 op shard A, en de volgende miljoen op shard B.
Voor de app wil je queries draaien alsof het één tabel is. Onder de motorkap moet het systeem echter beslissen met welke shard(s) het praten moet.
Niet replicatie, niet “koop een grotere machine”
Sharding verschilt van replicatie. Replicatie maakt kopieën van dezelfde data op meerdere nodes, vooral voor hoge beschikbaarheid en read-schaal. Sharding splitst de data zodat elke node andere records bevat.
Het is ook anders dan verticale schaalvergroting, waarbij je één database behoudt maar op een grotere machine zet (meer CPU/RAM/sneller disk). Verticale schaal kan eenvoudiger zijn, maar heeft praktische limieten en wordt snel duur.
Wat sharding niet magisch oplost
Sharding vergroot capaciteit, maar het maakt je database niet automatisch “makkelijk” of elke query sneller.
- Joins kunnen duurder worden als gerelateerde rijen op verschillende shards staan.
- Transacties over shards zijn lastiger; all-or-nothing updates vereisen vaak coördinatie.
- Operationele complexiteit neemt toe: routering, rebalancing, debuggen en foutafhandeling worden onderdeel van het systeem.
Begrijp sharding dus als een manier om opslag en throughput te schalen—niet als een gratis verbetering van elk aspect van databasegedrag.
Waarom teams sharden: de problemen die het probeert op te lossen
Sharding is zelden iemands eerste keuze. Teams grijpen er meestal naar als een succesvol systeem fysieke grenzen bereikt—of als operationele pijn te vaak voorkomt om te negeren. De motivatie is minder “we willen sharding” en meer “we moeten blijven groeien zonder dat één database een single point of failure en kostenbron wordt.”
De pijnpunten die teams naar sharding duwen
Een enkele database-node kan op verschillende manieren vol raken:
- Opslaglimieten: tabellen en indexen groeien totdat schijfruimte krap wordt, backups traag zijn en onderhoud riskant wordt.
- Write-throughputlimieten: CPU, WAL/redo of lock-contentie beperken hoeveel writes per seconde je kunt verwerken.
- Read-throughputlimieten: zelfs met caching en replicas kan een workload de primaire overbelasten (of replicas worden duur om te schalen).
- Noisy neighbors: één tenant, klant of workloadpatroon monopoliseert resources en degradeert de rest.
Als deze issues regelmatig optreden, is het probleem vaak niet één slechte query—maar dat één machine te veel verantwoordelijkheid draagt.
De doelen: schaal uit, isoleer en beheers kosten
Database sharding spreidt data en verkeer over meerdere nodes zodat capaciteit groeit door machines toe te voegen in plaats van één machine verticaal te upgraden. Goed uitgevoerd kan het ook workloads isoleren (zodat een piek van één tenant de latency van anderen niet kapotmaakt) en kosten beheersen door enorme premium-instances te vermijden.
Vroege waarschuwingssignalen dat je het plafond nadert
Terugkerende patronen zijn onder meer stijgende p95/p99-latency tijdens piek, langere replicatie-lag, backups/restores die je acceptabele venster overschrijden, en “kleine” schemawijzigingen die grote gebeurtenissen worden.
Waarom sharding meestal een laatste stap is
Voor je je eraan commit, proberen teams doorgaans eenvoudiger opties: indexeren en queryfixes, caching, read replicas, partitionering binnen één database, archiveren van oude data en hardware-upgrades. Sharding kan schaalproblemen oplossen, maar het voegt ook coördinatie, operationele complexiteit en nieuwe faalwijzen toe—dus de drempel moet hoog zijn.
Een geshard database is niet één ding—het is een klein systeem van samenwerkende delen. De reden dat sharding “moeilijk te doorgronden” kan voelen, is dat correctheid en performance afhangen van hoe deze onderdelen samenwerken, niet alleen van de database-engine.
Shards: onafhankelijke partitities (met eigen indexen)
Een shard is een subset van de data, meestal opgeslagen op een eigen server of cluster. Elke shard heeft doorgaans zijn eigen:
- opslag (datafiles)
- indexen (zodat queries binnen die shard snel kunnen zijn)
- lokale limieten (CPU, geheugen, schijf, connecties)
Voor een applicatie probeert een geshard setup vaak op te gaan als één logisch database. Maar onder de motorkap kan een query die op een single-node database “één index lookup” was, worden: “vind de juiste shard, en doe dan de lookup.”
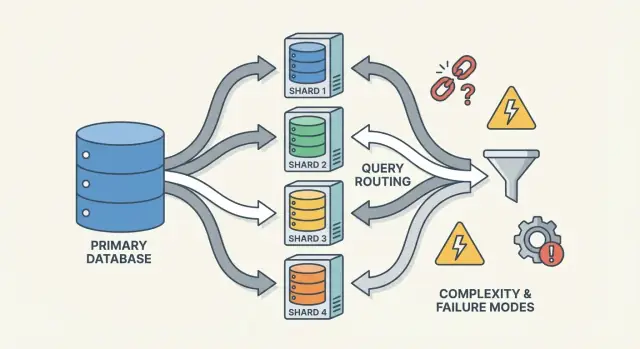
Routers/coördinatoren: hoe requests de juiste shard bereiken
Een router (soms coördinator, query router of proxy genoemd) is de verkeersagent. Hij beantwoordt de praktische vraag: gegeven dit verzoek, welke shard moet het afhandelen?
Twee gangbare patronen:
- Client-side routing: je applicatiebibliotheek kent de shard map en maakt direct verbinding met de juiste shard.
- Proxy routing: de app verbindt met een router-service, die het verzoek doorstuurt.
Routers verminderen complexiteit in de app, maar kunnen ook een bottleneck of nieuw faalpunt worden als ze niet zorgvuldig zijn ontworpen.
Sharding vertrouwt op metadata—een bron van waarheid die beschrijft:
- de shard map (welke shard bezit welke range/hash-buckets/IDs)
- ownership (vooral tijdens migraties, wanneer ownership tijdelijk overlapt)
- health en membership (welke nodes up zijn, primary/replica-rollen, draining status)
Deze informatie leeft vaak in een config-service (of een kleine “control plane” database). Als metadata verouderd of inconsistent is, kunnen routers verkeer naar de verkeerde plek sturen—evenals elke shard perfect gezond is.
Achtergrondjobs: balanceren, migraties en backups
Tot slot hangt sharding af van achtergrondprocessen die het systeem leefbaar houden:
- rebalancing van data wanneer één shard sneller groeit dan andere
- migraties bij het verplaatsen van ownership tussen shards
- backup/restore procedures die over veel shards werken (en aansluiten op je recovery-doelen)
Deze jobs zijn makkelijk te negeren in het begin, maar veroorzaken veel productiesurprises—omdat ze de vorm van het systeem veranderen terwijl het nog live verkeer verwerkt.
Een shard key kiezen: de eerste grote afweging
Een shard key is het veld (of combinatie van velden) dat je systeem gebruikt om te beslissen op welke shard een rij/document komt te staan. Die ene keuze bepaalt stilletjes performance, kosten en zelfs welke features later “makkelijk” aanvoelen—omdat het bepaalt of requests naar één shard gaan of naar velen moeten fan-outen.
Wat een shard key “goed” maakt
Een goede key heeft meestal:
- Hoge cardinaliteit: veel mogelijke waarden (bijv.
user_id in plaats van country).
- Gelijke verdeling: waarden spreiden reads en writes over shards in plaats van op één te concentreren.
- Stabiele toegangspatronen: het sluit aan op hoe je nu het meest bij de data komt én hoe je verwacht het volgend kwartaal te gebruiken.
Een veelvoorkomend voorbeeld is sharden op tenant_id in een multi-tenant app: de meeste reads en writes voor een tenant blijven op één shard, en tenants zijn voldoende talrijk om load te spreiden.
Wat een shard key “slecht” maakt (en waarom het pijn doet)
Sommige keys garanderen bijna problemen:
- Tijdsgebaseerde monotone keys (timestamps, auto-increment IDs): nieuwe data clustert op de “laatste” shard en creëert een write-hotspot.
- Velden met lage cardinaliteit (status, plan_tier, country): te weinig distinct values betekent dat een paar shards het meeste werk doen.
- Veranderlijke identifiers (email, mutable usernames): als de key wijzigt, wordt data verplaatsen tussen shards duur en riskant.
Zelfs als een low-cardinality key handig lijkt om op te filteren, verandert het routinematig queries vaak in scatter-gather queries, omdat overeenkomende rijen overal kunnen leven.
De echte afweging: querygemak vs distributiekwaliteit
De beste shard key voor load-balancing is niet altijd de beste voor productqueries.
- Kies een key die past bij je primaire toegangspatroon (bijv.
user_id), en sommige “globale” queries (bijv. admin-rapportage) worden langzamer of vereisen aparte pipelines.
- Kies een key die op rapportage aansluit (bijv.
region), en je riskeert hotspots en ongelijke capaciteit.
De meeste teams ontwerpen rond deze afweging: optimaliseer de shard key voor de meest frequente, latency-gevoelige operaties—en los de rest op met indexen, denormalisatie, replicas of speciale analytics-tabellen.
Veelvoorkomende shardingstrategieën (Range, Hash, Directory)
Er is geen “beste” manier om te sharden. De strategie die je kiest bepaalt hoe makkelijk routering is, hoe gelijkmatig data verdeeld wordt, en welke toegangspatronen problemen geven.
Range sharding
Bij range sharding bezit elke shard een aaneengesloten stuk van een key-ruimte—bijvoorbeeld:
- Shard A: customer_id 1–1.000.000
- Shard B: customer_id 1.000.001–2.000.000
Routering is eenvoudig: kijk naar de key, kies de shard.
Het nadeel is hotspots. Als nieuwe gebruikers altijd toenemende IDs krijgen, wordt de “laatste” shard de write-bottleneck. Range sharding is ook gevoelig voor ongelijke groei (een range wordt populair, een andere blijft rustig). Het voordeel: range-queries (“alle orders van 1–31 okt”) kunnen efficiënt zijn omdat de data fysiek gegroepeerd is.
Hash sharding
Hash sharding leidt de shard key door een hash-functie en gebruikt het resultaat om een shard te kiezen. Dit verspreidt data doorgaans gelijkmatiger en voorkomt het probleem dat alles naar de nieuwste shard gaat.
Trade-off: range-queries worden lastig. Een query zoals “customers met ID tussen X en Y” mapt niet langer naar een klein aantal shards; het kan veel aanraken.
Een praktisch detail dat teams onderschatten is consistent hashing. In plaats van rechtstreeks naar het aantal shards te mappen (waardoor alles herschudt als je shards toevoegt), gebruiken veel systemen een hashring met “virtual nodes” zodat het toevoegen van capaciteit slechts een deel van de keys verplaatst.
Directory (lookup) sharding
Directory sharding slaat een expliciete mapping op (een lookup-tabel/service) van key → shard-locatie. Dit is het meest flexibel: je kunt specifieke tenants op dedicated shards plaatsen, één klant verplaatsen zonder iedereen te verplaatsen, en ongelijkmatige shardgrootten ondersteunen.
Het nadeel is een extra afhankelijkheid. Als de directory traag, verouderd of onbeschikbaar is, leidt dat tot routingproblemen—evenals de shards gezond zijn.
Composiet keys en sub-sharding
Echte systemen mengen vaak benaderingen. Een composiete shard key (bijv. tenant_id + user_id) houdt tenants geïsoleerd en verspreidt tegelijk load binnen een tenant. Sub-sharding is vergelijkbaar: eerst routeer je op tenant, daarna hash je binnen die tenant’s shard-groep om te voorkomen dat één grote tenant één shard domineert.
Hoe queries werken: routering vs scatter-gather
Een geshard database heeft twee heel verschillende “querypaden.” Begrijpen op welk pad je zit verklaart de meeste performanceverrassingen—en waarom sharding onvoorspelbaar kan lijken.
Single-shard queries: het snelle pad
Het ideale resultaat is dat een query naar precies één shard wordt gerouteerd. Als het verzoek de shard key bevat (of iets waar de router naar kan mappen), kan het direct naar de juiste plek.
Daarom raken teams geobsedeerd door het zo shard-key-aware mogelijk maken van veelvoorkomende reads. Eén shard betekent minder netwerkhops, eenvoudiger uitvoering, minder locks en veel minder coördinatie. Latency is dan vooral het databasewerk zelf, niet het cluster dat discussieert over wie het moet doen.
Scatter-gather reads: fan-out en tail-latency
Als een query niet precies kan worden gerouteerd (bijv. filteren op een non-shard-key veld), kan het systeem het naar veel of alle shards broadcasten. Elke shard voert de query lokaal uit, waarna de router (of een coördinator) resultaten samenvoegt—sorteren, dedupliceren, limits toepassen en gedeeltelijke aggregaten combineren.
Dit fan-out vergroot tail-latency: zelfs als 9 shards snel reageren, kan één trage shard het hele verzoek gijzelen. Het vergroot ook de belasting: één gebruikersverzoek kan N shard-verzoeken worden.
Cross-shard joins en aggregaties
Joins over shards zijn duur omdat data die “binnen” de database bij elkaar zou komen, nu tussen shards moet reizen (of naar een coördinator). Zelfs simpele aggregaties (COUNT, SUM, GROUP BY) kunnen een tweefasig plan vereisen: bereken partial results op elke shard en voeg ze daarna samen.
Indexbeperkingen: lokaal vs globaal
De meeste systemen hebben standaard lokale indexen: elke shard indexeert alleen z’n eigen data. Die zijn goedkoop in onderhoud, maar helpen niet bij routering—dus queries scatteren nog steeds.
Globale indexen kunnen gerichte routering op non-shard-key velden mogelijk maken, maar ze voegen write-overhead, extra coördinatie en eigen schaal- en consistentieproblemen toe.
Writes en transacties over shards
Writes zijn het moment waarop sharding ophoudt als “gewoon schalen” en begint met het veranderen van hoe je features ontwerpt. Een write die één shard raakt kan snel en simpel zijn. Een write die meerdere shards raakt kan traag, foutgevoelig en verrassend moeilijk om correct te maken zijn.
Single-shard writes: het gelukkige pad
Als elk verzoek naar precies één shard kan worden gerouteerd (typisch via een shard key), kan de database zijn normale transactionele mechanismen gebruiken. Je krijgt atomiciteit en isolatie binnen die shard, en de meeste operationele issues lijken op bekende single-node problemen—alleen N keer herhaald.
Multi-shard writes: waar complexiteit omhoogschiet
Op het moment dat je data op twee shards in één “logische actie” moet updaten (bijv. geld overboeken, een order tussen klanten verplaatsen, een aggregate ergens anders bijwerken), zit je in distributed transaction-territory.
Gedistribueerde transacties zijn lastig omdat ze coördinatie vereisen tussen machines die traag, gepartitioneerd of herstart kunnen zijn. Two-phase-commit-achtige protocollen voegen extra roundtrips toe, kunnen blokkeren op timeouts en maken falen ambigu: heeft shard B de verandering al toegepast voordat de coördinator viel? Als de client opnieuw probeert, apply je de write dubbel? Als je niet herhaalt, verlies je de write?
Patronen om cross-shard writes te vermijden
Een paar veelgebruikte tactieken verminderen hoe vaak je multi-shard transacties nodig hebt:
- Datalocaliteit: co-locatieer gerelateerde records op dezelfde shard (bijv. alles voor een klant).
- Request routing: zorg dat een operatie door één shard wordt beheerd en behandel anderen als read-only inputs.
- Denormalisatie: dupliceer kleine stukjes data zodat updates niet moeten fan-outen.
Idempotentie en retry-veiligheid
In geshardde systemen zijn retries onvermijdelijk. Maak writes idempotent door stabiele operation IDs te gebruiken (bijv. een idempotency key) en door in de database "al toegepast" markers op te slaan. Zo wordt een retry na een timeout een no-op in plaats van een dubbele betaling, dubbele order of inconsistente teller.
Consistentie en replicatie: data correct houden
Sharding splitst je data over machines, maar haalt de noodzaak voor redundantie niet weg. Replicatie is wat een shard beschikbaar houdt als een node faalt—en het is ook waarom “wat is nu waar?” lastiger te beantwoorden is.
Replicatie binnen elke shard
De meeste systemen repliceren binnen elke shard: één primary (leader) accepteert writes en één of meer replicas kopiëren die veranderingen. Als de primary faalt, promoot het systeem een replica (failover). Replicas kunnen ook reads bedienen om load te verminderen.
De afweging is timing. Een read-replica kan enkele milliseconden—of seconden—achterlopen. Die kloof is normaal, maar belangrijk als gebruikers verwachten “ik heb net geüpdatet, dus ik zou het moeten zien”.
Consistentiemodellen in eenvoudige termen
- Sterke consistentie: na een succesvolle write zullen reads deze reflecteren (uit het oogpunt dat het systeem belooft). Dit betekent meestal lezen van de leader of wachten op replica-acknowledgements.
- Eventual consistency: het systeem convergeert, maar een read kan tijdelijk oudere data teruggeven.
In geshardde setups eindig je vaak met sterke consistentie binnen een shard en zwakkere garanties over shards heen, vooral bij multi-shard operaties.
"Single source of truth" als data verdeeld is
Bij sharding betekent “single source of truth” meestal: voor elk gegeven stuk data is er één gezaghebbende plek om te schrijven (meestal de leader van die shard). Globaal is er echter niet één machine die instantaan de laatste staat van alles kan bevestigen. Je hebt veel lokale waarheden die via replicatie synchroon moeten blijven.
Globale constraints: uniciteit, foreign keys, tellers
Constraints zijn lastig als de data die gecontroleerd moet worden op verschillende shards leeft:
- Uniciteit (bijv. username): het afdwingen van “geen duplicaten overal” kan een gecentraliseerde index, een dedicated "constraint shard" of een applicatieworkflow voor reservering vereisen.
- Foreign keys: als parent- en child-rijen op verschillende shards staan, kan de database referentiële integriteit niet gemakkelijk afdwingen zonder cross-shard coördinatie.
- Tellers (globale totalen, sequentiële IDs): naïeve aanpakken creëren een bottleneck. Gebruik per-shard ranges, batching of accepteer benaderende counts.
Deze keuzes zijn geen implementatiedetails—ze definiëren wat "correct" betekent voor je product.
Rebalancing en resharding zonder downtime
Rebalancing houdt een geshard database bruikbaar naarmate de realiteit verandert. Data groeit ongelijk, een aanvankelijk gebalanceerde shard key raakt scheef, je voegt nieuwe nodes toe voor capaciteit of je moet hardware uitfaseren. Elk van die zaken kan één shard tot bottleneck maken—zelfs als het oorspronkelijke ontwerp perfect leek.
Waarom het moeilijk is
In tegenstelling tot een single database bakeert sharding de locatie van data in routeringslogica. Als je data verplaatst, kopieer je niet alleen bytes—je verandert waar queries heen moeten. Rebalancing gaat dus evenveel over metadata en clients als over opslag.
Het online migratiepatroon (copy → overlap → cutover)
De meeste teams streven naar een online workflow die een grote "stop-the-world"-venster vermijdt:
- Copy: backfill de doelshard(s) vanaf de bronshard terwijl het systeem live is.
- Dual-write (soms dual-read): tijdens de transitie schrijf je nieuwe wijzigingen naar zowel oud als nieuw. Reads kunnen beide raadplegen (of je gebruikt een "new wins"-regel) tot je zeker bent.
- Cutover: update de shard map zodat routers/clients naar de nieuwe locatie sturen.
- Cleanup: stop dual-writes, verwijder de oude kopie en compacteer/reclaim space.
Shard maps en clientgedrag
Een shard map-wijziging breekt als clients routingbeslissingen cachen. Goede systemen behandelen routingmetadata als configuratie: versioneer het, refresh het regelmatig en wees expliciet over wat gebeurt als een client een verplaatste key raakt (redirect, retry of proxy).
Operationele risico's om voor te plannen
Rebalancing veroorzaakt vaak tijdelijke performance-dips (extra writes, cache-churn, achtergrond copy-load). Partiële verplaatsingen komen veel voor—sommige ranges migreren eerder dan andere—dus je hebt duidelijke observability en een rollbackplan nodig (bijv. de map terugdraaien en dual-writes draineren) voordat je de cutover start.
Hotspots en skew: wanneer "gelijke verdeling" faalt
Sharding veronderstelt dat werk zich verspreidt. De verrassing is dat een cluster op papier "gelijk" kan lijken (gelijke aantallen rijen per shard) maar in productie extreem ongelijk kan gedragen.
Hot partitions (hot keys)
Een hotspot ontstaat wanneer een klein deel van je keyspace de meeste requests krijgt—denk aan een celebrity-account, een populair product, een tenant die een zware batch job draait, of een tijdgebaseerde key waarbij "vandaag" alle writes trekt. Als die keys op één shard landen, wordt die shard de bottleneck, zelfs als alle andere shards idle zijn.
Skew: datagrootte vs verkeer
"Skew" is niet één ding:
- Data skew: één shard houdt meer bytes/rijen (opslagdruk, langzamere backups, tragere scans).
- Traffic skew: één shard verwerkt meer QPS of zwaardere queries (CPU-saturatie, wachtrijen, latency spikes).
Ze komen niet altijd overeen. Een shard met minder data kan het heetste zijn als het de meest gevraagde keys bezit.
Hoe je het snel detecteert
Je hebt geen geavanceerde tracing nodig om skew te vinden. Begin met per-shard dashboards:
- p95 latency per shard (één shard’s p95 die divergeert is een alarmbel)
- QPS (en write QPS) per shard
- Opgeslagen data / tabelgrootte per shard
Als de latency van één shard stijgt met zijn QPS terwijl anderen vlak blijven, heb je waarschijnlijk een hotspot.
Mitigaties
Oplossingen ruilen meestal eenvoud voor balans:
- Kies een shard key die verkeer verspreidt, niet alleen records.
- Voeg bucketing/salting toe voor hete keys (splits één logische key over meerdere fysieke buckets).
- Gebruik caching voor read-zware hot items.
- Pas rate limits of per-tenant quota's toe om de cluster te beschermen.
- Split hot shards (of verplaats hete ranges) als een shard niet afgekoeld kan worden.
Faaltwijzen en debuggen in een geshard systeem
Sharding voegt niet alleen meer servers toe—het voegt meer manieren toe waarop dingen fout kunnen gaan, en meer plekken om te onderzoeken als dat gebeurt. Veel incidenten zijn niet “de database is down”, maar “één shard is down” of “het systeem is het niet eens over waar data leeft.”
Veelvoorkomende faalwijzen
Enkele patronen die vaak terugkomen:
- Een shard is onbeschikbaar (crash, schijf vol, lange GC-pauses), wat tot partiële outages leidt: sommige klanten werken, anderen falen.
- Router routed verkeerd, vaak na een config change of een slechte deploy. Reads kunnen stilletjes lege resultaten teruggeven als ze naar de verkeerde shard gaan.
- Verouderde of inconsistente metadata (bv. shard map, directory-tabel). Tijdens moves of splits kunnen verschillende componenten dezelfde key anders routeren.
- Partiële netwerkproblemen: timeouts tussen routers en een subset van shards kunnen als “willekeurige” fouten lijken en retries veroorzaken die load versterken.
Hoe debuggen verandert
Bij een single-node database tail je één log en check je één set metrics. In een geshard systeem heb je observability nodig die een request over shards volgt.
Gebruik correlation IDs in elk request en propageren ze van de API-laag via routers naar elke shard. Koppel dat aan distributed tracing zodat een scatter-gather query laat zien welke shard traag of gefaald was. Metrics moeten per-shard zijn opgesplitst (latency, queue depth, error rate), anders valt een hete shard weg in fleet-gemiddelden.
Data-correctheid incidenten
Sharding-fouten tonen zich vaak als correctness-bugs:
- Duplicaten na retries of niet-idempotente writes.
- Missende rijen wanneer data is verplaatst maar routing nog naar de oude locatie wijst.
- Split-brain writes als twee metadata-views writes accepteren voor hetzelfde key-range.
Backup, restore en disaster recovery
"De database herstellen" wordt "veel delen herstellen in de juiste volgorde." Je moet mogelijk eerst metadata herstellen, dan elke shard, en verifiëren dat shard-grenzen en routingregels passen bij het herstelpunt. DR-plannen moeten oefening bevatten die bewijst dat je een consistente cluster kunt herbouwen—niet alleen individuele machines terugzetten.
Wanneer niet sharden: praktische alternatieven en een beslis-checklist
Sharding wordt vaak gezien als de "schaal-schakelaar", maar het is ook een permanente toename in systeemcomplexiteit. Als je je performance- en betrouwbaarheidseisen zonder data-splitting kunt halen, krijg je meestal een eenvoudiger architectuur, makkelijker debuggen en minder operationele randgevallen.
Praktische alternatieven die vaak veel ademruimte geven
Voor je naar sharding grijpt, probeer opties die één logisch database behouden:
- Beter indexeren + query tuning: repareer eerst de langzame paden—missende indexen, niet-afgebakende queries, dure joins en N+1-patronen.
- Caching: zet read-zware, stabiele responses achter een cache (app-level cache, CDN voor publieke content, of een in-memory cache voor hot keys).
- Read replicas: verplaats read-verkeer zonder het write-pad te veranderen (en accepteer replica-lag waar dat ok is).
- Gepartitioneerde tabellen op één node: veel databases ondersteunen partitionering die onderhoud en queries verbetert zonder cross-node routing.
Een praktische manier om risico te verkleinen is het prototypen van de plumbing (routingafbakening, idempotency, migratieworkflows en observability) voordat je je productiedatabase eraan wijdt.
Bijvoorbeeld, met Koder.ai kun je snel een kleine, realistische service spinnen uit chat—vaak een React admin UI plus een Go backend met PostgreSQL—en experimenteren met shard-key-aware APIs, idempotency keys en "cutover"-gedrag in een veilige sandbox. Omdat Koder.ai planning mode, snapshots/rollback en source code-export ondersteunt, kun je sharding-gerelateerde ontwerpkeuzes itereren (zoals routing en metadata-vorm) en de resulterende code en runbooks meenemen naar je hoofdstack als je er zeker van bent.