27 aug 2025·7 min
Go workerpools voor achtergrondtaken: retries, annulering en shutdown
Go workerpools helpen kleine teams achtergrondtaken te draaien met retries, annulering en nette shutdowns met eenvoudige patronen voordat je zware infrastructuur toevoegt.
Waarom achtergrondtaken snel rommelig worden
In een kleine Go-service begint achtergrondwerk meestal met een eenvoudig doel: geef snel het HTTP-antwoord terug en doe de trage dingen later. Dat kan e-mails verzenden, afbeeldingen schalen, synchroniseren met een externe API, zoekindexen opnieuw opbouwen of nachtelijke rapporten draaien zijn.
Het probleem is dat die taken echte productiewerkzaamheden zijn, maar zonder de vangrails die je bij request handling vanzelf hebt. Een goroutine die je vanuit een HTTP-handler start voelt goed totdat er een deploy plaatsvindt halverwege de taak, een upstream API vertraagt of hetzelfde verzoek opnieuw wordt geprobeerd en de taak twee keer triggert.
De eerste pijnpunten zijn voorspelbaar:
- Vastlopende taken: één call hangt en werkers maken geen voortgang meer.
- Dubbel werk: retries op HTTP-niveau draaien dezelfde taak opnieuw.
- Geen shutdown-plan: het proces stopt en werk gaat verloren of blijft half-af.
- Stille fouten: fouten worden één keer (of helemaal niet) gelogd en verdwijnen.
- Retry-stormen: falende jobs retryen direct en overbelasten afhankelijkheden.
Hier helpt een klein, expliciet patroon zoals een Go worker pool. Het maakt concurrency tot een keuze (N werkers), verandert “doe dit later” in een duidelijk jobtype en geeft je één plek om retries, timeouts en annulering af te handelen.
Voorbeeld: een SaaS-app moet facturen versturen. Je wilt geen 500 gelijktijdige verstuur-acties na een batch-import, en je wilt niet dezelfde factuur opnieuw versturen omdat een request werd herhaald. Een worker pool laat je doorvoer beperken en behandelt “verstuur factuur #123” als een getraceerde eenheid werk.
Een worker pool is niet het juiste gereedschap wanneer je duurzame, cross-process garanties nodig hebt. Als jobs crashes moeten overleven, op de toekomst gepland moeten worden of door meerdere services verwerkt moeten worden, heb je waarschijnlijk een echte queue plus persistente opslag voor jobstate nodig.
Het worker-poolmodel in eenvoudige taal
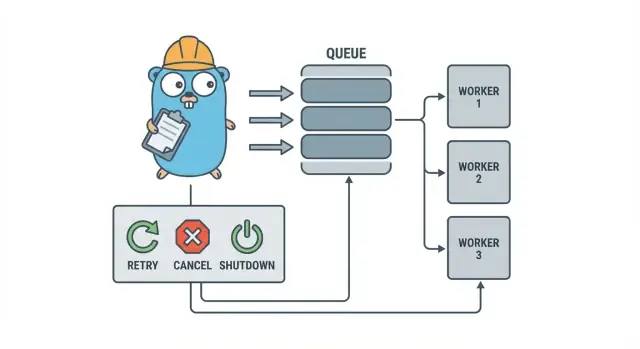
Een Go worker pool is opzettelijk saai: stop werk in een wachtrij, laat een vast aantal werkers het ophalen en zorg dat het geheel netjes kan stoppen.
De basistermen:
- Job: één eenheid werk, zoals “schaal deze afbeelding” of “verstuur deze factuur-e-mail”.
- Queue: waar jobs wachten.
- Worker: een goroutine die herhaaldelijk een job pakt en uitvoert.
- Dispatcher: het deel dat jobs accepteert en in de queue stopt.
In veel in-process ontwerpen is een Go channel de queue. Een gebufferd channel kan een beperkt aantal jobs vasthouden voordat producers blokkeren. Dat blokkeren is backpressure en vaak wat voorkomt dat je service onbeperkt werk accepteert en zonder geheugen komt te zitten bij verkeerpieken.
De buffer-grootte verandert het gevoel van het systeem. Een kleine buffer maakt druk snel zichtbaar (callers moeten eerder wachten). Een grotere buffer vlakt korte pieken af maar kan overload verbergen tot later. Er is geen perfect getal, alleen een getal dat past bij hoeveel wachten je kunt tolereren.
Je kiest ook of de poolgrootte vast is of kan variëren. Vaste pools zijn makkelijker te doorgronden en houden resourcegebruik voorspelbaar. Auto-scaling werkers kunnen helpen bij ongelijkmatige load, maar voegen beslissingen toe die je moet onderhouden (wanneer schalen, hoeveel en wanneer terugschalen).
Tot slot betekent “ack” in een in-process pool meestal gewoon “de worker heeft de job afgerond zonder fout.” Er is geen externe broker die aflevering bevestigt, dus jouw code definieert wat “klaar” betekent en wat er gebeurt als een job faalt of wordt geannuleerd.
Ontwerpdoelen: retries, annulering en nette shutdown
Mechanisch is een worker pool simpel: draai een vast aantal werkers, voed ze met jobs en verwerk ze. De waarde is controle: voorspelbare concurrency, duidelijk falingsgedrag en een shutdown-pad dat geen half-af werk achterlaat.
Drie doelen houden kleine teams sane:
- Beperk concurrency zodat één piek de database of een externe API niet kapotmaakt.
- Voorkom verlies van werk (of weet in ieder geval precies wat er is weggegooid en waarom).
- Blijf debugbaar: elke job moet traceerbaar zijn via logs en een paar counters.
De meeste fouten zijn saai, maar je wilt ze wel verschillend behandelen:
- Tijdelijke fouten (netwerkhaperingen, rate limits) die herhaald mogen worden.
- Permanente fouten (foute input, ontbrekend record) die niet herhaald moeten worden.
- Timeouts (een afhankelijkheid hangt) die afgesneden moeten worden zodat werkers niet dichtslibben.
Annulering is niet hetzelfde als "fout". Het is een beslissing: een gebruiker annuleerde, een deploy verving je proces, of je service gaat sluiten. In Go behandel je annulering als een eersteklas signaal met context-cancelatie en zorg je dat elke job dit controleert voordat hij zware taken start en op een paar veilige punten tijdens uitvoering.
Nette shutdown is waar veel pools mislukken. Bepaal vroeg wat “veilig” betekent voor je jobs: maak je lopend werk af of stop je snel en run je later opnieuw? Een praktisch flow is:
- Stop met het accepteren van nieuwe jobs.
- Zeg tegen werkers dat ze stoppen na hun huidige job (of onmiddellijk stoppen).
- Wacht tot een deadline, en forceer dan exit.
Als je deze regels vroeg definieert, blijven retries, annulering en shutdown klein en voorspelbaar in plaats van een eigen framework te worden.
Stap voor stap: bouw een basis worker pool
Een worker pool is gewoon een groep goroutines die jobs uit een channel halen en werk doen. Het belangrijke deel is om de basis voorspelbaar te maken: hoe een job eruitziet, hoe werkers stoppen en hoe je weet wanneer al het werk klaar is.
Begin met een simpel Job-type. Geef het een ID (voor logs), een payload (wat te verwerken), een pogingenteller (later handig voor retries), timestamps en een plek om per-job contextgegevens op te slaan.
package jobs
import (
"context"
"sync"
"time"
)
type Job struct {
ID string
Payload any
Attempt int
Enqueued time.Time
Started time.Time
Ctx context.Context
Meta map[string]string
}
type Pool struct {
ctx context.Context
cancel context.CancelFunc
jobs chan Job
wg sync.WaitGroup
}
func New(size, queue int) *Pool {
ctx, cancel := context.WithCancel(context.Background())
p := \u00026Pool{ctx: ctx, cancel: cancel, jobs: make(chan Job, queue)}
for i := 0; i \u0003c size; i++ {
go p.worker(i)
}
return p
}
func (p *Pool) worker(_ int) {
for {
select {
case \u0003c-p.ctx.Done():
return
case job, ok := \u0003c-p.jobs:
if !ok {
return
}
p.wg.Add(1)
job.Started = time.Now()
_ = job // call your handler here
p.wg.Done()
}
}
}
// Submit blocks when the queue is full (backpressure).
func (p *Pool) Submit(job Job) error {
if job.Enqueued.IsZero() {
job.Enqueued = time.Now()
}
select {
case \u0003c-p.ctx.Done():
return context.Canceled
case p.jobs \u0003c- job:
return nil
}
}
func (p *Pool) Stop() { p.cancel() }
func (p *Pool) Wait() { p.wg.Wait() }
Een paar praktische keuzes die je meteen maakt:
- Kies een queue-grootte op basis van hoeveel wachten je kunt tolereren.
- Bepaal wat backpressure betekent voor aanroepen: blokkeren, een fout teruggeven of weggooien.
- Houd
Stop()enWait()gescheiden zodat je eerst intake stopt en daarna wacht op lopend werk.
Retries toevoegen zonder er een framework van te maken
Retries zijn nuttig, maar ook de plek waar worker pools rommelig worden. Houd het doel smal: retry alleen wanneer een nieuwe poging een reële kans heeft om te slagen, en stop snel wanneer dat niet zo is.
Begin met vaststellen wat retryable is. Tijdelijke problemen (netwerkhaperingen, timeouts, “probeer later opnieuw” antwoorden) zijn meestal het proberen waard. Permanente problemen (foute input, ontbrekende records, toestemming geweigerd) niet.
Een klein retrybeleid is vaak genoeg:
- Markeer fouten als retryable of niet-retryable (bijvoorbeeld via een
Retryable(err)helper). - Stel een maximaal aantal pogingen in (vaak 3 tot 5). Daarna ben je meestal tijd aan het verbranden.
- Gebruik exponentiële backoff met jitter zodat jobs niet synchroon retrien.
- Begrens de vertraging (bijv. nooit meer dan 30 seconden slapen).
- Log retries met pogingsnummer, volgende vertraging en job ID.
Backoff hoeft niet gecompliceerd te zijn. Een veelgebruikte vorm is: delay = min(base * 2^(attempt-1), max), en voeg jitter toe (randomiseer met +/- 20%). Jitter is belangrijk omdat anders veel werkers samen falen en samen retrien.
Waar moet de vertraging leven? Voor kleine systemen is in de worker slapen prima, maar dat bezet een worker-slot. Als retries zeldzaam zijn, is dat acceptabel. Als retries vaak voorkomen of vertragingen lang zijn, overweeg het job opnieuw in de wachtrij te plaatsen met een “run after”-timestamp zodat werkers met ander werk bezig blijven.
Bij de definitieve mislukking wees expliciet. Sla de gefaalde job (en laatste fout) op voor review, log genoeg context om het opnieuw uit te voeren, of zet het in een dead-list die je regelmatig controleert. Vermijd stille drops. Een pool die fouten verbergt is slechter dan geen retries hebben.
Annulering en timeouts die echt werk stoppen
Plan je retrybeleid
Breng eerst je retry-regels en backoff in kaart, en laat Koder.ai het in je job runner bouwen.
Worker pools voelen alleen veilig als je ze kunt stoppen. De simpelste regel is: geef overal waar iets kan blokkeren een context.Context door. Dat betekent submissie, uitvoering en cleanup.
Een praktisch opzet gebruikt twee tijdslimieten:
- Een per-job timeout zodat één taak een worker niet voor altijd bezet houdt.
- Een shutdown timeout zodat het proces kan afsluiten zelfs als sommige jobs niet meewerken.
Gebruik context end-to-end
Geef elke job zijn eigen context afgeleid van de worker-context. Dan moeten alle trage calls (database, HTTP, queues, file I/O) die context gebruiken zodat ze vroegtijdig kunnen terugkeren.
func worker(ctx context.Context, jobs \u0003c-chan Job) {
for {
select {
case \u0003c-ctx.Done():
return
case job, ok := \u0003c-jobs:
if !ok { return }
jobCtx, cancel := context.WithTimeout(ctx, job.Timeout)
_ = job.Run(jobCtx) // Run must respect jobCtx
cancel()
}
}
}
Als Run je DB of een API aanroept, koppel de context dan aan die calls (bijv. QueryContext, NewRequestWithContext of clientmethodes die context accepteren). Als je het op één plek negeert, wordt annulering “best effort” en faalt het meestal wanneer je het het meest nodig hebt.
Gedeeltelijk werk en "veilig opnieuw proberen" stappen
Annulering kan halverwege een job gebeuren, dus ga uit van gedeeltelijk werk. Streef naar idempotente stappen zodat herhalingen geen duplicaten creëren. Gebruik unieke sleutels voor inserts (of upserts), schrijf voortgangsmarkers (gestart/klaar), sla tussentijdse resultaten op voordat je verdergaat en controleer ctx.Err() tussen stappen.
Behandel shutdown als een deadline: stop met het accepteren van nieuwe jobs, annuleer worker-contexts en wacht slechts tot de shutdown-timeout op lopende jobs om te stoppen.
Nette shutdown: wat te doen wanneer het proces moet stoppen
Een nette shutdown heeft één doel: stop met nieuw werk, vertel lopend werk te stoppen en sluit af zonder het systeem in een vreemde staat achter te laten.
Begin met signals. In de meeste deployments zie je lokaal SIGINT en vanaf je process manager of container runtime SIGTERM. Gebruik een shutdown-context die wordt gecanceld wanneer een signaal arriveert en geef die door aan je pool en jobhandlers.
Stop vervolgens met het accepteren van nieuwe jobs. Laat callers niet eeuwig blokkeren die proberen te submitten naar een channel dat niemand meer leest. Houd submissies achter een enkele functie die een gesloten vlag controleert of selecteert op de shutdown-context voordat hij verstuurt.
Bepaal dan wat er met in de wachtrij staand werk gebeurt:
- Drainen: maak alles af wat al in de wachtrij staat, maar weiger nieuwe submissies.
- Weggooien: gooi alles weg dat nog niet gestart is.
Drainen is veiliger voor dingen als betalingen en e-mails. Weggooien is prima voor "nice to have" taken zoals het opnieuw berekenen van een cache.
Een praktische shutdown-volgorde:
- Vang SIGINT/SIGTERM en cancel een gedeelde context.
- Stop submissies (sluit het submitpad, niet per se het work-channel).
- Laat werkers afmaken of afbreken op basis van context.
- Wacht op werkers met een WaitGroup.
- Leg een deadline op en exit daarna.
Die deadline is belangrijk. Geef bijvoorbeeld lopende jobs 10 seconden om te stoppen. Log daarna wat nog draait en sluit af. Dat houdt deploys voorspelbaar en voorkomt vastlopende processen.
Logging en simpele metrics voor worker pools
Genereer een worker pool starter
Beschrijf je taken en ontvang een Go + PostgreSQL scaffold om snel te starten.
Wanneer een worker pool uitvalt, faalt het zelden luid. Jobs vertragen, retries stapelen zich op en iemand meldt dat "er niets gebeurt". Logging en een paar basis-counters maken daar een helder verhaal van.
Geef elke job een stabiele ID (of genereer er één bij submissie) en neem die op in elke logregel. Houd logs consistent: één regel wanneer een job start, één wanneer hij eindigt en één wanneer hij faalt. Als je retryt, log dan pogingsnummer en volgende vertraging.
Een simpel logpatroon:
- start: job_id, worker_id, attempt, kind
- finish: job_id, worker_id, attempt, duration_ms
- fail/retry: job_id, worker_id, attempt, err, next_delay_ms
Metrics kunnen minimaal blijven en toch waardevol zijn. Volg queue-lengte, lopende jobs, totaal succes en fouten, en job-latentie (minimaal gemiddelde en max). Als queue-lengte blijft stijgen en in-flight op het aantal werkers blijft hangen, ben je verzadigd. Als submitters blokkeren bij het versturen naar het jobs-channel, bereikt backpressure de caller. Dat is niet altijd slecht, maar het moet wel een bewuste keuze zijn.
Wanneer "jobs vastlopen", controleer dan of het proces nog jobs ontvangt, of de queue-lengte groeit, of werkers alive zijn en welke jobs het langst draaien. Lange runtimes duiden meestal op ontbrekende timeouts, trage afhankelijkheden of een retry-loop die nooit stopt.
Een realistisch voorbeeld: een kleine SaaS achtergrondqueue
Stel je een kleine SaaS voor waar een order op PAID verandert. Direct na betaling moet je een factuur-PDF sturen, de klant e-mailen en je interne team informeren. Je wilt dat werk niet het webrequest blokkeert. Dit is een goede match voor een worker pool omdat het werk echt is, maar het systeem nog klein.
De jobpayload kan minimaal zijn: net genoeg om de rest uit je database te halen. De API-handler schrijft een rij zoals jobs(status='queued', type='send_invoice', payload, attempts=0) in dezelfde transactie als de order-update, daarna polt een achtergrondloop naar queued jobs en duwt ze in het worker-channel.
type SendInvoiceJob struct {
OrderID string
CustomerID string
Email string
}
Wanneer een worker hem oppakt, is het happy path eenvoudig: laad de order, genereer de factuur, roep de e-mailprovider aan en markeer dan de job als gedaan.
Retries zijn waar dit serieus wordt. Als je e-mailprovider een tijdelijke outage heeft, wil je niet dat 1.000 jobs voorgoed falen of de provider elke seconde bestormen. Een praktische aanpak is:
- Behandel netwerkfouten en 5xx-responses als retryable.
- Gebruik exponentiële backoff met een max delay (bijv. 5s, 15s, 45s, 2m).
- Beperk pogingen (bijv. 10) en markeer dan de job als failed.
- Leg de laatste fout vast zodat support kan zien wat er gebeurde.
Tijdens de outage verplaatsen jobs zich van queued naar in_progress en weer terug naar queued met een toekomstige uitvoertijd. Zodra de provider herstelt, draineren werkers vanzelf de achterstand.
Denk nu aan een deploy. Je stuurt SIGTERM. Het proces moet stoppen met nieuw werk maar afmaken wat al in behandeling is. Stop met pollingen, stop met het vullen van het worker-channel en wacht met een deadline op de werkers. Jobs die klaarkomen worden gemarkeerd als done. Jobs die nog lopen wanneer de deadline bereikt is, moeten teruggezet worden naar queued (of in progress blijven met een watchdog) zodat ze opgepikt kunnen worden nadat de nieuwe versie start.
Veelgemaakte fouten en valkuilen
De meeste bugs in achtergrondverwerking zitten niet in de joblogica. Ze komen door coördinatiefouten die alleen onder load of tijdens shutdown zichtbaar worden.
Een klassieke valkuil is het sluiten van een channel vanaf meer dan één plek. Het resultaat is een panic die moeilijk reproduceerbaar is. Kies één eigenaar voor elk channel (meestal de producer) en laat die de enige plek zijn die close(jobs) aanroept.
Retries zijn ook een gebied waar goede bedoelingen outages veroorzaken. Als je alles herhaalt, herhaal je ook permanente fouten. Dat verliest tijd, vergroot load en kan een klein probleem tot een incident maken. Classificeer fouten en cap retries met een helder beleid.
Duplicaten zullen gebeuren, zelfs met een zorgvuldig ontwerp. Werkers kunnen crashen halverwege een job, een timeout kan afgaan nadat werk al klaar is of je kunt opnieuw in de wachtrij plaatsen tijdens deployment. Als de job niet idempotent is, worden duplicaten schadelijk: twee facturen, twee welkomstmails, twee refunds.
Meest voorkomende fouten:
- Hetzelfde channel sluiten vanuit meerdere goroutines.
- Permanente fouten opnieuw proberen in plaats van ze te tonen.
- Geen idempotency-key, waardoor duplicaten dubbele bijwerkingen veroorzaken.
- Onbegrensde in-memory queues die blijven groeien tot geheugenpieken.
context.Contextnegeren, zodat werk doorgaat nadat shutdown is gestart.
Onbegrensde queues zijn extra sluw. Een piek kan stilletjes in RAM ophopen. Geef de voorkeur aan een begrensd channelbuffer en bepaal wat er gebeurt als het vol raakt: blokkeer, gooi weg of geef een fout terug.
Snel checklist voordat je naar productie gaat
Bezit de gegenereerde broncode
Krijg volledige Go-, React- en databasecode die je kunt bezitten en uitbreiden.
Voordat je een worker pool naar productie brengt, moet je het job-leven duidelijk kunnen beschrijven. Als iemand vraagt "waar is deze job nu?", mag het antwoord geen gok zijn.
Een praktische pre-flight checklist:
- Je kunt elke staat en transitie benoemen: queued, picked up, running, finished, failed (en wat het van de ene naar de andere brengt).
- Concurrency is één knop (zoals
workerCount) en veranderen ervan vereist geen codeherschrijving. - Retries zijn begrensd: max attempts zijn duidelijk, backoff groeit en permanente fouten gaan ergens bewust heen.
- Shutdown-gedrag is bewezen: je stopt intake, laat lopende jobs afmaken en hebt nog steeds een harde timeout.
- Logs beantwoorden de basics: job ID, pogingsnummer, duur en foutreden.
Doe één realistische drill voor release: zet 100 "send receipt email" jobs in de wachtrij, forceer 20 om te falen en herstart de service halverwege. Je moet zien dat retries zich gedragen zoals verwacht, geen dubbele bijwerkingen voorkomen en annulering daadwerkelijk werk stopt wanneer de deadline bereikt is.
Als iets onduidelijk is, verscherp het nu. Kleine fixes hier besparen dagen later.
Volgende stappen: wanneer zwaardere infrastructuur toevoegen (en wanneer niet)
Een simpele in-process pool is vaak genoeg zolang een product jong is. Als je jobs "nice to have" zijn (e-mails, cache verversen, rapporten genereren) en je ze opnieuw kunt draaien, houdt een worker pool het systeem makkelijk te begrijpen.
Signalen dat je een in-process pool ontgroeid bent
Houd deze drukpunten in de gaten:
- Je draait meerdere app-instanties en wilt dat slechts één ervan een job pakt.
- Je hebt duurzaamheid nodig (jobs moeten crashes en deploys overleven).
- Je hebt een audit trail nodig: wie wat in de wachtrij zette, wanneer het draaide en het exacte resultaat.
- Je hebt backpressure-controle nodig over services heen, niet alleen binnen één proces.
- Je hebt strikte scheduling of lange vertragingen (uren of dagen) met betrouwbare wake-up nodig.
Als geen van deze waar is, voegen zwaardere tools vaak meer bewegende delen toe dan waarde.
Geleidelijk migreren zonder rewrite
De beste hedge is een stabiele jobinterface: een kleine payloadtype, een ID en een handler die een duidelijk resultaat teruggeeft. Dan kun je de queue-backend later vervangen (van een in-memory channel naar een databasetabel en pas daarna naar een dedicated queue) zonder je businesscode te veranderen.
Een praktische tussenstap is een kleine Go-service die jobs uit PostgreSQL leest, ze claimt met een lock en status bijwerkt. Je krijgt duurzaamheid en basis-auditbaarheid terwijl je dezelfde workerlogica behoudt.
Als je snel wilt prototypen, kan Koder.ai (koder.ai) een Go + PostgreSQL starter genereren vanuit een chatprompt, inclusief een background jobs-tabel en een workerloop; zijn snapshots en rollback kunnen helpen terwijl je retries en shutdowngedrag afstelt.