21 sep 2025·8 min
Eric Brewer’s CAP-denken: waarom gedistribueerde systemen afwegen
Leer Eric Brewer’s CAP-theorema als praktisch denkkader: hoe consistentie, beschikbaarheid en partitietolerantie beslissingen in gedistribueerde systemen vormen.
Leer Eric Brewer’s CAP-theorema als praktisch denkkader: hoe consistentie, beschikbaarheid en partitietolerantie beslissingen in gedistribueerde systemen vormen.
Als je dezelfde data op meer dan één machine opslaat, win je snelheid en fouttolerantie—maar je krijgt ook een nieuw probleem: oneensheid. Twee servers kunnen verschillende updates ontvangen, berichten kunnen te laat of helemaal niet aankomen, en gebruikers kunnen verschillende antwoorden zien afhankelijk van welke replica ze raken. CAP werd populair omdat het ontwikkelaars een heldere manier geeft om die rommelige realiteit te bespreken zonder te vervallen in vaagheden.
Eric Brewer, computerwetenschapper en medeoprichter van Inktomi, introduceerde het kernidee in 2000 als een praktische uitspraak over gerepliceerde systemen onder falen. Het verspreidde zich snel omdat het overeenkwam met wat teams al in productie meemaakten: gedistribueerde systemen falen niet alleen door uit te vallen; ze falen door te splitsen.
CAP is het meest nuttig wanneer dingen misgaan—vooral wanneer het netwerk zich niet gedraagt. Op een gezonde dag kunnen veel systemen er zowel consistent als beschikbaar genoeg uitzien. De stresstest is wanneer machines niet betrouwbaar met elkaar kunnen communiceren en je moet beslissen wat te doen met reads en writes terwijl het systeem verdeeld is.
Die framing is waarom CAP een standaard mental model werd: het discussieert niet over best practices; het dwingt een concrete vraag af—wat offeren we op tijdens een split?
Aan het einde van dit artikel zou je in staat moeten zijn om:
CAP blijft relevant omdat het vage "gedistribueerd is moeilijk"-praat omzet in een beslissing die je kunt nemen—en verdedigen.
Een gedistribueerd systeem is, in gewone bewoordingen, veel computers die proberen als één te werken. Je kunt meerdere servers in verschillende racks, regio’s of cloudzones hebben, maar voor de gebruiker is het “de app” of “de database.”
Om dat gedeelde systeem op echte schaal te laten werken, repliceren we meestal: we bewaren meerdere kopieën van dezelfde data op verschillende machines.
Replicatie is populair om drie praktische redenen:
Tot nu toe klinkt replicatie als een eenvoudige winst. De catch is dat replicatie een nieuwe taak creëert: alle kopieën in overeenstemming houden.
Als elke replica altijd instant met elke andere replica kon praten, konden ze updates coördineren en op dezelfde staat blijven. Maar echte netwerken zijn niet perfect. Berichten kunnen vertraagd, weggegooid of omgeleid worden rond fouten.
Wanneer communicatie gezond is, kunnen replicas meestal updates uitwisselen en naar dezelfde staat convergeren. Maar als communicatie faalt (zelfs tijdelijk), kun je eindigen met twee geldig-uitziende versies van “de waarheid.”
Stel dat een gebruiker zijn afleveradres verandert. Replica A krijgt de update, replica B niet. Nu moet het systeem een ogenschijnlijk simpele vraag beantwoorden: wat is het huidige adres?
Dit is het verschil tussen:
CAP-denken begint precies hier: zodra replicatie bestaat, is onenigheid onder communicatie-uitval geen randgeval—het is het centrale ontwerpprobleem.
CAP is een denkkader voor wat gebruikers daadwerkelijk voelen wanneer een systeem verspreid is over meerdere machines (vaak op meerdere locaties). Het beschrijft geen “goede” of “slechte” systemen—alleen de spanning die je moet beheren.
Consistentie gaat over overeenstemming. Als je iets bijwerkt, zal de volgende read (van waar dan ook) die update laten zien?
Voor een gebruiker is het het verschil tussen “ik heb het net veranderd en iedereen ziet dezelfde nieuwe waarde” versus “sommige mensen zien de oude waarde nog een tijdje.”
Beschikbaarheid betekent dat het systeem reageert op verzoeken—reads en writes—met een succesvol resultaat. Niet “de snelst mogelijke,” maar “het weigert je niet te bedienen.”
Tijdens problemen (een server down, een netwerkglitch) blijft een beschikbaar systeem verzoeken accepteren, ook al antwoordt het mogelijk met verouderde data.
Een partitie is wanneer het netwerk splitst: machines draaien wel, maar berichten tussen sommige van hen kunnen niet doorkomen (of komen te laat voor praktisch gebruik). In gedistribueerde systemen kun je dit niet als onmogelijk beschouwen—je moet gedrag definiëren voor wanneer het gebeurt.
Stel je twee winkels voor die hetzelfde product verkopen en een gedeelde "1 voorraad" hebben. Een klant koopt het laatste artikel in Winkel A, dus Winkel A schrijft voorraad = 0. Tegelijkertijd voorkomt een netwerkpartitie dat Winkel B hiervan hoort.
Als Winkel B beschikbaar blijft, kan het een artikel verkopen dat het niet meer heeft (de verkoop accepteren terwijl het gesplitst is). Als Winkel B consistentie afdwingt, kan het de verkoop weigeren totdat het de nieuwste voorraad kan bevestigen (dienst weigeren tijdens de split).
Een “partitie” is niet alleen “het internet is down.” Het is elke situatie waarin delen van je systeem niet betrouwbaar met elkaar kunnen praten—ook al draaien die delen zelf nog prima.
In een gerepliceerd systeem wisselen nodes constant berichten uit: writes, acknowledgements, heartbeats, leader elections, read-verzoeken. Een partitie is wat er gebeurt wanneer die berichten niet meer aankomen (of te laat aankomen), waardoor onenigheid over de realiteit ontstaat: “Is de write gebeurd?” “Wie is de leader?” “Is node B alive?”
Communicatie kan op rommelige, gedeeltelijke manieren falen:
Het belangrijke punt: partities zijn vaak degradatie, geen schone aan/uit-uitval. Vanuit de applicatie gezien kan “traag genoeg” niet te onderscheiden zijn van “down.”
Naarmate je meer machines, netwerken, regio’s en bewegende delen toevoegt, ontstaan er simpelweg meer kansen voor communicatie om tijdelijk te breken. Zelfs als individuele componenten betrouwbaar zijn, ervaart het geheel falen omdat het meer afhankelijkheden en meer cross-node coördinatie heeft.
Je hoeft geen exacte faalkans aan te nemen om de realiteit te accepteren: als je systeem lang genoeg draait en genoeg infrastructuur overspant, zullen partities gebeuren.
Partitietolerantie betekent dat je systeem is ontworpen om door te werken tijdens een split—zelfs wanneer nodes het niet eens kunnen worden of niet kunnen bevestigen wat de andere kant heeft gezien. Dat dwingt een keuze af: blijf je verzoeken bedienen (met risico op inconsistentie) of stop/weiger je sommige verzoeken (bewaar consistentie).
Zodra je replicatie hebt, is een partitie gewoon een communicatiebreuk: twee delen van je systeem kunnen voor een tijdje niet betrouwbaar met elkaar praten. Replicas draaien nog steeds, gebruikers blijven klikken, en je service ontvangt nog steeds verzoeken—maar de replicas kunnen het niet eens worden over de laatste waarheid.
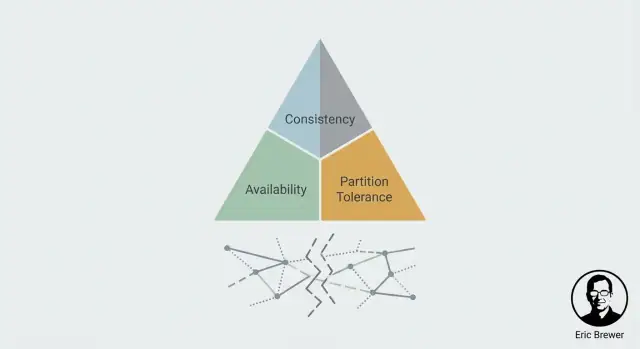
Dat is de CAP-spanning in één zin: tijdens een partitie moet je kiezen of je Consistentie (C) of Beschikbaarheid (A) prioriteert. Je krijgt niet beide tegelijk.
Je zegt: “Ik wil liever correct zijn dan responsief.” Wanneer het systeem niet kan bevestigen dat een verzoek alle replicas in sync houdt, moet het falen of wachten.
Praktisch effect: sommige gebruikers zien fouten, timeouts of “probeer het later opnieuw”—vooral bij operaties die data wijzigen. Dit is gebruikelijk wanneer je liever een betaling weigert dan twee keer in rekening te brengen, of een stoelreservering blokkeert dan overselling toe te staan.
Je zegt: “Ik wil liever reageren dan blokkeren.” Elke kant van de partition blijft verzoeken accepteren, zelfs als coördinatie niet mogelijk is.
Praktisch effect: gebruikers krijgen succesvolle responsen, maar de data die ze lezen kan verouderd zijn en gelijktijdige updates kunnen conflicteren. Je vertrouwt dan op latere reconciliatie (merge-rules, last-write-wins, handmatige review, enz.).
Het is niet altijd een enkele globale instelling. Veel producten mengen strategieën:
Het essentiële moment is per operatie beslissen wat erger is: een gebruiker nu blokkeren, of later conflicterende waarheden herstellen.
De slogan “kies twee” is gedenkwaardig, maar misleidt vaak mensen in de veronderstelling dat CAP een menu van drie features is waarvan je er permanent maar twee kunt behouden. CAP gaat over wat er gebeurt wanneer het netwerk niet meewerkt: tijdens een partitie (of alles wat daarop lijkt) moet een gedistribueerd systeem kiezen tussen het teruggeven van consistente antwoorden en het altijd beschikbaar blijven voor elk verzoek.
In echte gedistribueerde systemen kun je partities niet uitzetten. Als je systeem machines, racks, zones of regio’s overspant, kunnen berichten vertraagd, weggegooid, opnieuw gerangschikt of raar gerouteerd worden. Dat is vanuit de software gezien een partitie: nodes kunnen niet goed genoeg overeenkomen.
Zelfs als het fysieke netwerk in orde lijkt, creëren fouten elders hetzelfde effect—overbelaste nodes, GC-pauzes, noisy neighbors, DNS-hiccups, onbetrouwbare load balancers. Het resultaat is hetzelfde: sommige delen van het systeem kunnen niet goed genoeg met andere delen praten om te coördineren.
Applicaties ervaren geen partitie als een nette, binaire gebeurtenis. Ze ervaren latencypieken en timeouts. Als een verzoek na 200 ms time-out gaat, maakt het niet uit of het pakket na 201 ms arriveerde of nooit arriveerde: de app moet beslissen wat te doen. Vanuit de app is trage communicatie vaak niet te onderscheiden van kapotte communicatie.
Veel echte systemen zijn voornamelijk consistent of voornamelijk beschikbaar, afhankelijk van configuratie en operationele omstandigheden. Timeouts, retry-beleid, quorumgroottes en “read your writes”-opties kunnen het gedrag verschuiven.
Onder normale condities kan een database sterk consistent lijken; onder stress of cross-region problemen kan hij beginnen verzoeken te weigeren (consistency favoriseren) of verouderde data teruggeven (availability favoriseren).
CAP gaat minder over producten labelen en meer over begrijpen welke afweging je maakt wanneer onenigheid ontstaat—vooral wanneer die onenigheid veroorzaakt wordt door gewone traagheid.
CAP-discussies maken consistentie vaak binair: ofwel “perfect” ofwel “alles kan.” Echte systemen bieden een menu met garanties, elk met een andere gebruikerservaring wanneer replicas het oneens zijn of een netwerklink faalt.
Sterke consistentie (vaak “linearizable” gedrag) betekent dat zodra een write bevestigd is, iedere latere read—ongeacht welke replica—die write teruggeeft.
Wat het kost: tijdens een partitie of wanneer een minderheid van replicas onbereikbaar is, kan het systeem reads/writes vertragen of weigeren om tegenstrijdige staten te voorkomen. Gebruikers merken dit als timeouts, “probeer het later” of tijdelijk read-only gedrag.
Eventuele consistentie belooft dat als er geen nieuwe updates plaatsvinden, alle replicas uiteindelijk convergeren. Het belooft niet dat twee gebruikers die nu tegelijk lezen hetzelfde zien.
Wat gebruikers kunnen merken: een recent geüpdatete profielfoto die “terugtikt”, tellers die achterlopen, of een net-verzonden bericht dat op een ander apparaat pas later zichtbaar is.
Je kunt vaak een betere ervaring kopen zonder volstrekte sterke consistentie te eisen:
Deze garanties sluiten goed aan bij hoe mensen denken (“laat mijn eigen wijzigingen niet verdwijnen”) en zijn vaak makkelijker te handhaven tijdens gedeeltelijke fouten.
Begin met gebruikersbeloften, niet met jargon:
Consistentie is een productkeuze: beschrijf wat “fout” voor de gebruiker betekent en kies de zwakste garantie die die fout voorkomt.
Beschikbaarheid in CAP is geen opschepmetric (“vijf negens”)—het is een belofte aan gebruikers over wat er gebeurt wanneer het systeem niet zeker kan zijn.
Als replicas het niet eens kunnen worden, kies je vaak tussen:
Gebruikers ervaren dit als “de app werkt” versus “de app is correct.” Geen van beide is universeel beter; de juiste keuze hangt af van wat “fout” in jouw product betekent. Een licht verouderde sociale feed is vervelend; een verouderd rekeningoverzicht kan schadelijk zijn.
Twee veelvoorkomende gedragingen bij onzekerheid:
Dit is geen puur technische keuze; het is een beleidskeuze. Het product moet definiëren wat acceptabel is om te tonen en wat nooit geraden mag worden.
Beschikbaarheid is zelden alles-of-niets. Tijdens een split kun je gedeeltelijke beschikbaarheid zien: sommige regio’s, netwerken of gebruikergroepen slagen terwijl anderen falen. Dit kan een bewuste ontwerpkeuze zijn (serveren waar de lokale replica gezond is) of een accidenteel gevolg (routingimbalance, ongelijke quorum-toegang).
Een praktische middenweg is degradatiemodus: blijf veilige acties toestaan en beperk risicovolle acties. Bijvoorbeeld: laat browsen en zoeken toe, maar schakel tijdelijk “geld overmaken”, “wachtwoord wijzigen” of andere operaties uit waarbij correctheid en uniciteit cruciaal zijn.
CAP voelt abstract totdat je het koppelt aan wat je gebruikers ervaren tijdens een netwerk-split: geef je de voorkeur aan dat het systeem blijft reageren, of dat het stopt om conflicterende data te vermijden?
Stel twee datacenters accepteren bestellingen terwijl ze niet met elkaar kunnen praten.
Als je de checkout beschikbaar houdt, kan elk datacenter het “laatste artikel” verkopen en oversell ontstaan. Dat is acceptabel voor laag-risico goederen (je levert later of biedt excuses), maar pijnlijk bij gelimiteerde drops.
Kies je consistency-first, dan blokkeer je mogelijk nieuwe bestellingen wanneer je voorraad niet globaal bevestigd kan worden. Gebruikers zien “probeer het later”, maar je voorkomt dat je iets verkoopt dat je niet kunt leveren.
Geld is het klassieke domein waar fouten duur zijn. Als twee replicas onterecht gelijktijdig opnames toestaan tijdens een split, kan een rekening negatief raken.
Systemen geven vaak de voorkeur aan consistentie voor kritische writes: acties weigeren of vertragen als de laatste balans niet bevestigd kan worden. Je ruilt wat beschikbaarheid (tijdelijke betaalstoringen) in voor correctheid, auditbaarheid en vertrouwen.
In chat en sociale feeds tolereren gebruikers meestal kleine inconsistenties: een bericht arriveert een paar seconden later, een like-telling is even off, of een view-metric werkt later bij.
Hier kan ontwerpen voor beschikbaarheid een goede productkeuze zijn, zolang je duidelijk bent over welke elementen “eventueel correct” zijn en je updates goed kunt samenvoegen.
De “juiste” CAP-keuze hangt af van de kosten van fout gaan: restituties, juridische exposure, gebruikersvertrouwen of operationele chaos. Bepaal waar je tijdelijke staleness kunt tolereren en waar je gesloten moet blijven.
Als je hebt besloten wat je tijdens een netwerk-split gaat doen, heb je mechanismen nodig om die beslissing daadwerkelijk te maken. Deze patronen verschijnen in databases, berichtensystemen en API’s—zelfs als het product nooit “CAP” noemt.
Een quorum is gewoon “de meerderheid van de replicas is het eens.” Als je 5 kopieën van data hebt, is de meerderheid 3.
Door te eisen dat reads en/of writes een meerderheid contacteren, verklein je de kans op verouderde of conflicterende antwoorden. Bijvoorbeeld: als een write bevestiging van 3 replicas nodig heeft, is het lastiger voor twee geïsoleerde groepen om verschillende “waarheden” te accepteren.
De afweging is snelheid en bereik: als je geen meerderheid kunt bereiken (door een partitie of uitval), kan het systeem de operatie weigeren—je kiest consistentie boven beschikbaarheid.
Veel “beschikbaarheid”-problemen zijn geen harde fouten maar trage responses. Een korte timeout kan het systeem vlot laten aanvoelen, maar verhoogt ook de kans dat je langzame successen als fouten behandelt.
Retries kunnen herstel brengen bij tijdelijke blips, maar agressieve retries kunnen een al worstelende service overbelasten. Backoff (iets langer wachten tussen retries) en jitter (randomness) helpen voorkomen dat retries in een verkeerspiek veranderen.
De sleutel is deze instellingen af te stemmen op je belofte: “altijd reageren” betekent meestal meer retries en fallbacks; “nooit liegen” betekent strakkere limieten en duidelijke fouten.
Als je tijdens partities beschikbaar blijft, kunnen replicas verschillende updates accepteren en moet je later reconciliëren. Gebruikelijke benaderingen:
Retries kunnen duplicaten creëren: twee keer een kaart in rekening brengen of twee keer dezelfde bestelling plaatsen. Idempotentie voorkomt dat.
Een veelgebruikt patroon is een idempotency key (request ID) meegeven met elk verzoek. De server slaat het eerste resultaat op en geeft hetzelfde resultaat terug voor herhaalde verzoeken—zodat retries beschikbaarheid verbeteren zonder data te corrumperen.
De meeste teams “kiezen” een CAP-stance op een whiteboard—en ontdekken dan in productie dat het systeem zich anders gedraagt onder stress. Valideren betekent doelbewust de condities creëren waarin CAP-afwegingen zichtbaar worden en controleren of je systeem zich gedraagt zoals ontworpen.
Je hebt geen echte kabelbreuk nodig om iets te leren. Gebruik gecontroleerde foutinjectie in staging (en zorgvuldig in productie) om partities te simuleren:
Het doel is concrete vragen te beantwoorden: Worden writes afgewezen of geaccepteerd? Serveren reads verouderde data? Herstelt het systeem automatisch en hoe lang duurt reconciliatie?
Als je deze gedragingen vroeg wilt valideren (voordat je weken in integratie steekt), helpt het om snel een realistisch prototype op te zetten. Teams die Koder.ai gebruiken, starten bijvoorbeeld vaak met een kleine service (meestal een Go-backend met PostgreSQL en een React UI) en itereren dan op gedrag zoals retries, idempotency keys en degradatiemodusflows in een sandboxomgeving.
Traditionele uptime-checks vangen geen “beschikbaar maar fout” gedrag. Houd bij:
Operators hebben vooraf vastgestelde acties nodig wanneer een partitie gebeurt: wanneer writes bevriezen, wanneer te failoveren, wanneer features te degraderen en hoe je veilig opnieuw samenvoegen valideert.
Plan ook de gebruikersgedragingen. Als je consistentie kiest, kan de boodschap zijn: “We kunnen je update nu niet bevestigen—probeer het later.” Als je beschikbaarheid kiest, wees expliciet: “Je update kan een paar minuten duren voordat die overal zichtbaar is.” Duidelijke taal vermindert supportbelasting en behoudt vertrouwen.
Wanneer je een systeembeslissing neemt, is CAP het meest nuttig als een snelle “wat breekt er tijdens een split?”-audit—niet als een theoretisch debat. Gebruik deze checklist voordat je een databasefeature, cachingstrategie of replicatiemodus kiest.
Stel deze vragen op volgorde:
Als een netwerkpartitie gebeurt, beslis je welke van deze je eerst beschermt.
Vermijd een enkele globale instelling zoals “we zijn een AP-systeem.” Beslis per:
Voorbeeld: tijdens een split kun je writes naar payments blokkeren (consistency) maar reads voor product_catalog beschikbaar houden met gecachte data.
Schrijf op wat je kunt tolereren, met voorbeelden:
Als je inconsistentie niet in eenvoudige voorbeelden kunt beschrijven, wordt het lastig te testen en incidenten uit te leggen.
Vervolgonderwerpen die goed bij deze checklist passen: consensus, consistency models en SLOs/error budgets.
CAP is een denkkader voor gerepliceerde systemen bij communicatieproblemen. Het is het meest nuttig wanneer het netwerk traag, foutgevoelig of gesplitst is, omdat dat is wanneer replicas niet betrouwbaar kunnen overeenkomen en je wordt gedwongen te kiezen tussen:
Het helpt om “gedistribueerd is moeilijk” om te zetten in een concrete product- en engineeringbeslissing.
Een echte CAP-situatie vereist beide:
Als je systeem één enkele node is, of je replicaat niet toestaat, zijn CAP-afwegingen niet het centrale vraagstuk.
Een partitie is elke situatie waarin delen van je systeem niet betrouwbaar of binnen de benodigde tijd kunnen communiceren—zelfs als elke machine nog draait.
In de praktijk ziet een "partitie" er vaak uit als:
Vanaf het applicatiepunt van zicht kan “te langzaam” hetzelfde zijn als “down”.
Consistentie (C) betekent dat reads de meest recente erkende write teruggeven, ongeacht welke replica je raakt. Voor gebruikers voelt dat als: “Ik heb het aangepast en iedereen ziet het.”
Beschikbaarheid (A) betekent dat elk verzoek een succesvol antwoord krijgt (niet per se de nieuwste data). Voor gebruikers voelt dat als: “de app blijft werken”, mogelijk met verouderde resultaten.
Tijdens een partitie kun je meestal niet beide garanties voor alle bewerkingen tegelijk garanderen.
Omdat partities onvermijdelijk zijn in gedistribueerde systemen die over machines, racks, zones of regio’s verspreid zijn. Als je repliceert, moet je gedrag definiëren voor wanneer nodes niet kunnen samenwerken.
"Partitietolereren" betekent meestal: wanneer communicatie faalt, heeft het systeem een duidelijke manier om door te gaan—ofwel door sommige acties te weigeren/pauzeren (ten koste van beschikbaarheid) of door best-effort resultaten te retourneren (ten koste van consistentie).
Als je consistentie verkiest, doe je meestal:
Dit is gebruikelijk bij geldtransacties, voorraadreserveringen en machtigingen—domeinen waar fout gaan erger is dan kort onbeschikbaar zijn.
Als je beschikbaarheid verkiest, doe je meestal:
Gebruikers zien minder harde fouten, maar kunnen verouderde data, gedupliceerde effecten zonder idempotentie of conflicterende updates tegenkomen die moeten worden opgeschoond.
Je kunt verschillend kiezen per endpoint/data type. Veelvoorkomende gemengde strategieën:
Dit voorkomt een enkele globale label "we zijn AP/CP" die zelden bij echte productbehoeften past.
Handige opties zijn onder meer:
Valideer door omstandigheden te creëren waarin onenigheid zichtbaar wordt:
Kies de zwakste garantie die voorkomt dat gebruikers zichtbare, onacceptabele fouten zien.
Bereid ook runbooks en gebruikerscommunicatie voor die passen bij je gekozen gedrag (fail closed vs fail open).