16 jan 2026·7 min
Documentgerichte werkstromen: datamodel en UI‑patronen
Documentgerichte workflows uitgelegd met praktische datamodellen en UI‑patronen voor versies, previews, metadata en duidelijke statussen.
Documentgerichte workflows uitgelegd met praktische datamodellen en UI‑patronen voor versies, previews, metadata en duidelijke statussen.
document_id die nooit verandert. Zelfs als de gebruiker hetzelfde PDF opnieuw uploadt, een wazige foto vervangt of een gecorrigeerde scan uploadt, moet het nog steeds hetzelfde documentrecord zijn. Opmerkingen, toewijzingen en auditlogs koppelen zo netjes aan één duurzaam ID.\n\nBehandel elke betekenisvolle wijziging als een nieuwe version‑rij. Elke versie moet vastleggen wie deze maakte en wanneer, plus opslag‑pointers (file key, checksum, size, page count) en afgeleide artifacts (OCR‑tekst, preview‑afbeeldingen) die aan dat exacte bestand gekoppeld zijn. Vermijd “in‑place bewerken.” Dat lijkt aanvankelijk eenvoudiger, maar het breekt traceerbaarheid en maakt bugs moeilijk terug te draaien.\n\nVoor snelle leesacties, houd een current_version_id op het document. De meeste schermen hebben alleen “de nieuwste” nodig, zodat je niet bij elke laadactie versies hoeft te sorteren. Als je geschiedenis nodig hebt, laad versies apart en toon een duidelijke tijdlijn.\n\nRollbacks zijn gewoon een pointerwijziging. In plaats van iets te verwijderen, zet je current_version_id terug naar een oudere versie. Het is snel, veilig en houdt het auditspoor intact.\n\nOm geschiedenis begrijpelijk te houden, leg vast waarom elke versie bestaat. Een klein, consistent reason‑veld (plus een optionele notitie) voorkomt een tijdlijn vol mysterieuze updates. Veelvoorkomende redenen: re‑upload replacement, scan cleanup, OCR correction, redaction en approval edit.\n\nVoorbeeld: een finance‑team uploadt een foto van een bon, vervangt die door een scherpere scan en corrigeert daarna OCR zodat het totaal leesbaar is. Elke stap is een nieuwe versie, maar het document blijft één item in de inbox. Als de OCR‑correctie verkeerd was, is rollback één klik omdat je alleen current_version_id wijzigt.\n\n## Previews en thumbnails die snel en betrouwbaar blijven\n\nIn documentgerichte workflows is de preview vaak het belangrijkste waarmee gebruikers interactie hebben. Als previews traag of onbetrouwbaar zijn, voelt de hele app kapot aan.\n\nBehandel het genereren van previews als een aparte taak, niet iets waar het upload‑scherm op wacht. Sla eerst het originele bestand op, geef de controle terug aan de gebruiker en genereer daarna previews op de achtergrond. Dit houdt de UI responsief en maakt retries veilig.\n\nSla meerdere previewgroottes op. Eén grootte past nooit op elk scherm: een kleine thumbnail voor lijsten, een middelgrote afbeelding voor split‑views en full‑page afbeeldingen voor gedetailleerde beoordeling (pagina‑voor‑pagina voor PDF's).\n\nHoud de previewstatus expliciet bij zodat de UI altijd weet wat te tonen: pending, ready, failed en needs_retry. Houd de labels gebruikersvriendelijk in de UI, maar zorg dat de datahelderheid behouden blijft.\n\nOm rendering snel te houden, cache afgeleide waarden naast het preview‑record in plaats van ze bij elke weergave opnieuw te berekenen. Veelvoorkomende velden zijn page count, preview width en height, rotation (0/90/180/270) en een optionele “best page for thumbnail.”\n\nOntwerp voor trage en rommelige bestanden. Een 200‑pagina gescande PDF of een gekreukt bonnetje kan even duren om te verwerken. Gebruik progressief laden: laat de eerste beschikbare pagina zien zodra die klaar is en vul daarna de rest aan.\n\nVoorbeeld: een gebruiker uploadt 30 foto’s van bonnetjes. De lijstweergave toont miniaturen als “pending” en elke kaart schakelt naar “ready” zodra de preview klaar is. Als enkele mislukken door een corrupt beeld, blijven ze zichtbaar met een duidelijke retry‑actie in plaats van te verdwijnen of de hele batch te blokkeren.\n\n## Metadata: wat te bewaren en hoe het bruikbaar te houden\n\nMetadata verandert een stapel bestanden in iets waar je op kunt zoeken, sorteren, beoordelen en goedkeuren. Het helpt mensen simpele vragen snel te beantwoorden: wat is dit document? Van wie is het? Is het geldig? Wat moet er daarna gebeuren?\n\nEen praktische manier om metadata schoon te houden is ze te scheiden op herkomst:\n\n- Systeemmetadata: bestandsnaam, grootte, MIME‑type, page count, uploadtijd, checksum\n- Gedeclareerde metadata: OCR‑tekst, gedetecteerde velden (vendor, date, total), barcode/QR‑waarden\n- Door gebruiker ingevoerde metadata: correcties, tags, notities, categorisatie, opmerkingen van goedkeurders\n\nDeze bakken voorkomen later ruzie. Als een totaalbedrag fout is, kun je zien of het uit OCR of een handmatige wijziging kwam.\n\nVoor bonnetjes en facturen betaalt een kleine set velden zich terug als je ze consequent gebruikt (zelfde naamgeving,zelfde formaten). Veelgebruikte anker‑velden zijn vendor, date, total, currency en document_number. Houd ze aanvankelijk optioneel. Mensen uploaden gedeeltelijke scans en wazige foto’s en het blokkeren van voortgang omdat één veld ontbreekt vertraagt de hele workflow.\n\nBehandel onbekende waarden als volwaardige gevallen. Gebruik expliciete staten zoals null/unknown, plus een reden wanneer dat helpt (missende pagina, onleesbaar, niet van toepassing). Dat laat het document doorgaan terwijl je beoordelaars toont wat aandacht nodig heeft.\n\nBewaar ook herkomst en confidence voor geëxtraheerde velden. Bron kan user, OCR, import of API zijn. Confidence kan een 0–1 score zijn of een kleine set zoals high/medium/low. Als OCR “$18.70” leest met lage confidence omdat het laatste cijfer vervaagd is, kan de UI het markeren en om snelle bevestiging vragen.\n\nMeerpagina‑documenten vragen één extra beslissing: wat hoort bij het hele document versus bij een enkele pagina. Totalen en vendor behoren meestal tot het document. Pagina‑niveau notities, redactions, rotatie en per‑pagina klassificatie horen vaak op paginaniveau.\n\n## Statussen die aansluiten bij echt werk\n\nStatus beantwoordt één vraag: “Waar staat dit document in het proces?” Houd het klein en saai. Als je bij elke vraag een nieuwe status toevoegt, krijg je filters waar niemand op vertrouwt.\n\nEen praktische set zakelijke statussen die map naar echte beslissingen:\n\n- Imported: het bestand bestaat, maar er is nog niets gecontroleerd\n- Needs review: een mens moet sleutelvelden of leesbaarheid bevestigen\n- Approved: klaar voor downstream gebruik (betalen, archiveren, publiceren of exporteren)\n- Rejected: niet bruikbaar, met een reden\n- Archived: bewaard voor het dossier, uit actief werk\n\nHoud “processing” buiten zakelijke statussen. OCR uitvoeren en previews genereren beschrijven wat het systeem doet, niet wat een persoon moet doen. Sla die op als afzonderlijke verwerkingsstatussen.\n\nSchei ook toewijzing (assignee_id, team_id, due_date) van status. Een document kan Approved zijn maar nog steeds toegewezen voor follow‑up, of Needs review met nog niemand als eigenaar.\n\nLeg statusgeschiedenis vast, niet alleen de huidige waarde. Een eenvoudige log zoals (from_status, to_status, changed_at, changed_by, reason) betaalt zich terug als iemand vraagt: “Wie heeft dit bonnetje afgekeurd en waarom?”\n\nBepaal ten slotte welke acties in elke status toegestaan zijn. Houd regels simpel: Imported kan naar Needs review; Approved is alleen‑lezen tenzij er een nieuwe versie wordt aangemaakt; Rejected kan worden heropend maar moet de vorige reden bewaren.\n\n## UI‑patronen voor lijsten, detailweergaven en reviewflows\n\nDe meeste tijd gaat zitten in het scannen van een lijst, een item openen, een paar velden corrigeren en door naar de volgende. Goede UI maakt die stappen snel en voorspelbaar.\n\nVoor de documentenlijst behandel elke rij als een samenvatting zodat gebruikers kunnen beslissen zonder elk bestand te openen. Een sterke rij toont een kleine thumbnail, een duidelijke titel, een paar sleutelvelden (merchant, date, total), een statusbadge en een subtiele waarschuwing wanneer iets aandacht nodig heeft.\n\nHoud de detailweergave rustig en makkelijk scanbaar. Een veelvoorkomende layout is preview links en metadata rechts, met bewerkcontrols naast elk veld. Gebruikers moeten kunnen zoomen, roteren en pagina's omdraaien zonder hun plek in het formulier te verliezen. Als een veld uit OCR komt, toon dan een klein confidence‑hintje en idealiter markeer je het brongebied in de preview wanneer het veld geselecteerd is.\n\nVersies werken het beste als een tijdlijn, niet als een dropdown. Toon wie wat en wanneer heeft veranderd en laat gebruikers elke vorige versie in alleen‑lezen openen. Als je vergelijking aanbiedt, focus dan op metadata‑verschillen (bedrag gewijzigd, vendor gecorrigeerd) in plaats van een pixel‑voor‑pixel PDF‑vergelijking te forceren.\n\nReviewmodus moet optimaliseren voor snelheid. Een keyboard‑gerichte triageflow is vaak genoeg: snelle approve/reject‑acties, snelle fixes voor veelvoorkomende velden en een korte reactieruimte voor afwijzingen.\n\nLege staten zijn belangrijk omdat documenten vaak halverwege verwerking zitten. In plaats van een leeg vak, leg uit wat er gebeurt: “Preview wordt gegenereerd”, “OCR draait” of “Voor dit bestandstype is nog geen preview beschikbaar.”\n\n## Stap‑voor‑stap: een eenvoudige workflow van upload tot goedkeuring\n\nEen eenvoudige workflow voelt als “upload, controle, goedkeuren.” Onder de motorkap werkt het het beste als je het bestand zelf (versies en previews) scheidt van de zakelijke betekenis (metadata en status).\n\n### 1) Upload belandt in een inbox\n\nDe gebruiker uploadt een PDF, foto of bon‑scan en ziet het onmiddellijk in een inboxlijst. Wacht niet op verwerking. Toon een bestandsnaam, uploadtijd en een duidelijke badge zoals “Processing.” Als je de bron al kent (e‑mailimport, mobiele camera, drag‑and‑drop), toon die ook.\n\n### 2) Maak Document + Version, preview start als pending\n\nBij upload maak je een Document‑record (het langlevende ding) en een Version‑record (dit specifieke bestand). Zet current_version_id naar de nieuwe versie. Sla preview_state = pending en extraction_state = pending op zodat de UI eerlijk kan aangeven wat klaar is.\n\nDe detailweergave moet meteen openen, maar een plaatsvervangende viewer en een duidelijke melding “Preview voorbereiden” tonen in plaats van een gebroken frame.\n\n### 3) Achtergrondverwerking genereert previews en extraheert metadata\n\nEen achtergrondtaak maakt thumbnails en een bekijkbare preview (pagina‑afbeeldingen voor PDF's, resized afbeeldingen voor foto's). Een andere taak extraheert metadata (vendor, date, total, currency, document type). Wanneer elke taak klaar is, update je alleen die status en timestamps zodat je fouten kunt retryen zonder alles aan te raken.\n\nHoud de UI compact: toon preview‑status, data‑status en markeer velden met lage confidence.\n\n### 4) Reviewer corrigeert velden, verandert status, voegt notities toe\n\nWanneer de preview klaar is, corrigeren reviewers velden, voegen notities toe en verplaatsen het document door zakelijke statussen zoals Imported -> Needs review -> Approved (of Rejected). Log wie wat en wanneer heeft veranderd.\n\nAls een reviewer een gecorrigeerd bestand uploadt, wordt dat een nieuwe Version en keert het document automatisch terug naar Needs review.\n\n### 5) Downstream gebruik leest huidige versie plus goedgekeurde metadata\n\nExports, accounting sync of interne rapporten moeten lezen vanuit current_version_id en de goedgekeurde metadata‑snapshot, niet vanuit “laatste extractie.” Dat voorkomt dat een halfverwerkte herupload getallen verandert.\n\n## Veelvoorkomende fouten en valkuilen om te vermijden\n\nDocumentgerichte workflows mislukken om saaie redenen: vroege shortcuts worden dagelijkse pijn zodra mensen duplicaten uploaden, fouten corrigeren of vragen: “Wie heeft dit en wanneer gewijzigd?”\n\nHet bestandsnaam als documentidentiteit behandelen is een klassieke fout. Namen veranderen, gebruikers uploaden opnieuw en camera's produceren duplicaten zoals IMG_0001. Geef elk document een stabiel ID en behandel de bestandsnaam als label.\n\nHet originele bestand overschrijven wanneer iemand een vervanging uploadt veroorzaakt ook problemen. Het voelt eenvoudiger, maar je verliest je auditspoor en kunt later geen basisvragen meer beantwoorden (wat was goedgekeurd, wat was bewerkt, wat werd verzonden). Houd het binaire bestand onveranderlijk en voeg een nieuw versie‑record toe.\n\nStatusverwarring creëert subtiele bugs. “OCR draait” is niet hetzelfde als “Needs review.” Verwerkingsstatussen beschrijven wat het systeem doet; zakelijke status beschrijft wat een persoon vervolgens moet doen. Als die vermengd raken, belanden documenten in de verkeerde bak.\n\nUI‑keuzes kunnen ook frictie creëren. Als je het scherm blokkeert totdat previews zijn gegenereerd, ervaren mensen de app als traag, ook al is de upload geslaagd. Toon het document meteen met een duidelijke placeholder en wissel daarna miniaturen in wanneer ze klaar zijn.\n\nTot slot wordt metadata onbetrouwbaar als je waarden opslaat zonder herkomst. Als het totaal uit OCR komt, geef dat aan. Bewaar tijdstempels.\n\nEen korte checklist:\n\n- Stabiel document ID gescheiden van bestandsnaam\n- Nieuwe versie per vervanging, geen overschrijvingen\n- Zakelijke status gescheiden van verwerkingsstatus\n- Niet‑blokkerend laden van previews en thumbnails\n- Metadata inclusief bron en tijdstempels\n\nVoorbeeld: in een bonnetjesapp uploadt een gebruiker een scherpere foto. Als je het versieert, bewaar je de oude afbeelding, markeer je OCR als opnieuw verwerkend en houd je Needs review aan totdat een persoon het bedrag bevestigt.\n\n## Snelle checklist voordat je live gaat\n\nDocumentgerichte workflows voelen “klaar” aan wanneer mensen kunnen vertrouwen wat ze zien en kunnen herstellen wanneer er iets misgaat. Test vóór lancering met rommelige, echte documenten (wazige bonnetjes, geroteerde PDF's, herhaalde uploads).\n\nVijf checks die de meeste verrassingen vangen:\n\n- Huidige versie is onmiskenbaar. Markeer de actieve versie, toon wie het laatst gewijzigd heeft en wanneer, en voeg een korte reden toe zoals “bijgesneden” of “opnieuw geüpload.”\n- Previews falen netjes. Als een preview nog wordt gegenereerd, toon een nuttige placeholder (bestandsnaam, uploadtijd, pagina‑aantal indien bekend) en een duidelijke pendingsstatus. Als generatie faalt, toon een fout en een retry‑optie.\n- Statussen komen overeen met acties. Elke status heeft een duidelijke betekenis en een klein set toegestane acties. Als Approved bestaat, maak het alleen‑lezen.\n- Metadata‑bewerkingen wissen extractie niet. Laat gebruikers OCR corrigeren zonder de originele geëxtraheerde waarde te verliezen. Bewaar beide en toon welke gebruikt wordt.\n- Herstel is ingebouwd. Maak veelvoorkomende fixes eenvoudig: rol terug naar een eerdere versie, run extractie opnieuw, genereer previews opnieuw.\n\nEen snelle realiteitstest: vraag iemand drie vergelijkbare bonnetjes te beoordelen en laat ze opzettelijk één fout maken. Als ze de huidige versie kunnen vinden, de status begrijpen en de fout binnen een minuut kunnen herstellen, zit je goed.\n\n## Voorbeeldscenario en praktische vervolgstappen\n\nMaandelijkse onkostenvergoedingen zijn een duidelijk voorbeeld van documentgericht werk. Een werknemer uploadt bonnetjes, daarna controleren twee reviewers: een manager en finance. Het bonnetje is het product, dus jouw app leeft of sterft op versionering, previews, metadata en duidelijke status.\n\nJamie uploadt een foto van een taxi‑bon. Je systeem maakt Document #1842 met Version v1 (het originele bestand), een thumbnail en preview en metadata zoals merchant, date, currency, total en een OCR‑confidencescore. Het document start in Imported en gaat naar Needs review zodra preview en extractie klaar zijn.\n\nLater uploadt Jamie per ongeluk hetzelfde bonnetje opnieuw. Een duplicaatcheck (file hash plus vergelijkbare merchant/date/total) kan een eenvoudige keuze tonen: “Lijkt een duplicaat van #1842. Toch koppelen of negeren?” Als ze koppelen, sla je het op als een extra File gekoppeld aan hetzelfde Document zodat je één reviewthread en één status behoudt.\n\nTijdens de review ziet de manager de preview, sleutelvelden en waarschuwingen. OCR gokte het totaal op $18.00, maar de afbeelding toont duidelijk $13.00. Jamie corrigeert het totaal. Wis de geschiedenis niet: maak Version v2 met bijgewerkte velden, houd v1 ongewijzigd en log “Total corrected by Jamie.”\n\nAls je dit soort workflow snel wilt bouwen, kan Koder.ai (koder.ai) je helpen de eerste versie van de app te genereren vanuit een chatplan, maar dezelfde regel geldt: definieer eerst de objecten en statussen, en laat de schermen volgen.\n\nPraktische vervolgstappen:\n\n- Schets het datamodel: Document, Version, File, ExtractedField, Review, StatusHistory\n- Ontwerp twee schermen: inboxlijst (status + waarschuwingen) en detailweergave (preview + velden + versies)\n- Test met vijf echte bonnetjes en iterereer op statussen, duplicaatregels en reviewsnelheid\nEen documentgerichte app behandelt het document als het hoofdproduct waar gebruikers aan werken, niet als bijlage. Mensen moeten het kunnen openen, erop kunnen vertrouwen, begrijpen wat er is veranderd en op basis daarvan besluiten wat er daarna gebeurt.
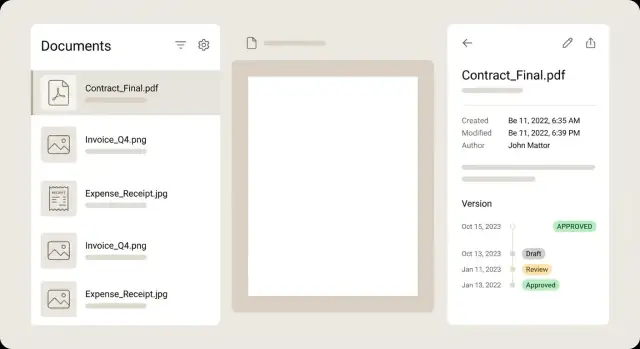
Begin met een inbox/lijst, een documentdetailweergave met een snelle preview, een eenvoudige review‑actiehoek (goedkeuren/afwijzen/wijzigingen vragen) en een manier om te exporteren of te delen. Deze vier schermen dekken de gebruikelijke cyclus: vinden, openen, beslissen en overdragen.
Modelleer een stabiel Document‑record dat nooit verandert en bewaar de feitelijke bestandsbytes als aparte File‑objecten. Voeg vervolgens Version toe als snapshot die een document aan een specifiek bestand (en de afgeleide resultaten) koppelt. Deze scheiding houdt reacties, toewijzingen en geschiedenis intact, ook als het bestand vervangen wordt.
Elke betekenisvolle wijziging is een nieuwe versie; overschrijven in plaats van een versie aanmaken veroorzaakt onduidelijke historie. Houd een current_version_id op het document voor snelle toegang tot de nieuwste versie en bewaar een tijdlijn met oudere versies voor audit en rollback.
Genereer previews asynchroon nadat het originele bestand is opgeslagen, zodat uploads direct aanvoelen en retries veilig zijn. Houd een preview‑status bij zoals pending/ready/failed zodat de UI eerlijk kan aangeven wat klaar is, en sla meerdere groottes op zodat de lijstweergaven licht blijven en de detailweergave scherp.
Bewaar metadata in drie categorieën: systeem (bestandsnaam, grootte, type), extractie (OCR‑velden en confidence) en door gebruiker ingevoerde correcties. Houd de herkomst bij zodat je kunt zien of een waarde uit OCR of van een persoon komt en voorkom dat werk vastloopt omdat een verplicht veld ontbreekt.
Gebruik een kleine set zakelijke statussen die aangeven wat een persoon moet doen, zoals Imported, Needs review, Approved, Rejected en Archived. Houd verwerkingsstatus (preview/OCR draaiende) apart zodat documenten niet vastlopen in een status die menselijk werk met machinewerk verwart.
Sla onveranderlijke bestandschecksums op en vergelijk deze bij upload, en voer een tweede controle uit op sleutelvelden zoals vendor/date/total wanneer die beschikbaar zijn. Als je een mogelijk duplicaat vindt, bied een duidelijke keuze: koppel aan het bestaande document of negeer. Zo verspreid je review‑geschiedenis niet over kopieën.
Houd een statusgeschiedenislog bij met wie wat heeft gewijzigd, wanneer en waarom, en bewaar versies leesbaar via een tijdlijn. Rollback moet een pointerwijziging naar een oudere versie zijn, geen delete, zodat je snel kunt herstellen zonder het auditspoor te verliezen.
Definieer eerst de objecten en statussen en laat de UI vervolgens volgen. Gebruik Koder.ai (koder.ai) alleen als je expliciet maakt hoe Document/Version/File, preview‑ en extractiestatussen en statusregels werken, zodat de gegenereerde schermen aansluiten op echte workflow‑behoeften.