Waarom real-time apps traag aanvoelen ook al is de code snel
Snelheid heeft twee kanten: throughput en latency. Throughput is hoeveel werk je per seconde afhandelt (verzoeken, berichten, frames). Latency is hoe lang één eenheid werk nodig heeft van begin tot eind.
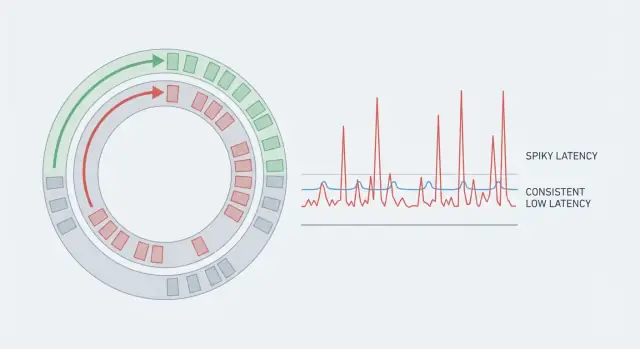
Een systeem kan een hoge throughput hebben en toch traag aanvoelen als sommige verzoeken veel langer duren dan andere. Daarom misleiden gemiddelden. Als 99 acties 5 ms duren en één actie 80 ms, ziet het gemiddelde er prima uit, maar de gebruiker die die 80 ms treft ervaart stotteren. In real-time systemen zijn die zeldzame pieken vaak het hele verhaal omdat ze het ritme breken.
Voorspelbare latency betekent dat je niet alleen streeft naar een lage gemiddelde waarde. Je streeft naar consistentie, zodat de meeste operaties binnen een smalle bandbreedte klaar zijn. Daarom kijken teams naar de staart (p95, p99). Daar verstoppen de pauzes zich.
Een spike van 50 ms kan uitmaken in gebieden zoals spraak en video (audio‑glitches), multiplayergames (rubber‑banding), real‑time trading (gemiste prijzen), industriële monitoring (late alarms) en live dashboards (cijfers springen, alerts voelen onbetrouwbaar).
Een eenvoudig voorbeeld: een chatapp bezorgt meestal berichten snel. Maar als een achtergrondpauze één bericht 60 ms vertraagt, knipperen typing-indicatoren en voelt het gesprek traag, ook al ziet de server er “snel” uit op gemiddeldes.
Als je real-time echt real wilt laten voelen, heb je minder verrassingen nodig, niet alleen snellere code.
Latency-basics: waar gaat de tijd echt naartoe
De meeste real-time systemen zijn niet traag omdat de CPU worstelt. Ze voelen traag omdat werk het grootste deel van zijn leven wacht: wachten om te worden gescheduled, wachten in een queue, wachten op het netwerk of wachten op opslag.
End-to-end latency is de volledige tijd van “iets gebeurde” tot “de gebruiker ziet het resultaat.” Zelfs als je handler 2 ms draait, kan het verzoek nog steeds 80 ms duren als het op vijf verschillende plekken pauzeert.
Een handige manier om het pad op te delen is:
- Netwerktijd (client naar edge, service naar service, retries)
- Schedulingtijd (je thread wacht om te draaien)
- Queuetijd (werk zit achter ander werk)
- Opslagtijd (disk, database locks, cache misses)
- Serialisatietijd (coderen en decoderen van data)
Die wachttijden stapelen zich op. Een paar milliseconden hier en daar maken van een “snel” codepad een trage ervaring.
Tail-latency is waar gebruikers beginnen te klagen. Gemiddelde latency kan er goed uitzien, maar p95 of p99 betekent de traagste 5% of 1% van de verzoeken. Outliers komen meestal door zeldzame pauzes: een GC‑cycle, een lawaaierige buur op de host, korte lock‑contentie, een cache‑refill of een burst die een wachtrij creëert.
Concreet voorbeeld: een prijsupdate arriveert over het netwerk in 5 ms, wacht 10 ms op een drukke worker, staat 15 ms achter andere events en stuit dan op een database‑stall van 30 ms. Je code draaide nog steeds in 2 ms, maar de gebruiker wachtte 62 ms. Het doel is elke stap voorspelbaar te maken, niet alleen de berekening snel.
De gebruikelijke bronnen van jitter buiten codesnelheid
Een snel algoritme kan nog steeds traag aanvoelen als de tijd per verzoek heen en weer slingert. Gebruikers merken pieken, geen gemiddelden. Die variatie is jitter, en die komt vaak van dingen die je code niet volledig controleert.
CPU-caches en geheugengedrag zijn verborgen kosten. Als hete data niet in de cache past, stopt de CPU terwijl hij op RAM wacht. Objectrijke structuren, verspreid geheugen en “nog één lookup” kunnen in herhaalde cache‑misses veranderen.
Geheugenallocatie voegt zijn eigen willekeur toe. Veel kortstondige objecten verhogen de druk op de heap, wat later als pauzes (garbage collection) of allocator‑contentie naar voren komt. Zelfs zonder GC kunnen frequente allocaties geheugen fragmenteren en locality schaden.
Thread‑scheduling is een andere veelvoorkomende bron. Wanneer een thread wordt gedescheduled, betaal je context switch‑overhead en verlies je cache‑warmte. Op een drukke machine kan je “real-time” thread achter niet-gerelateerd werk wachten.
Lock‑contentie is waar voorspelbare systemen vaak uit elkaar vallen. Een lock die “meestal vrij” is kan in een convoy veranderen: threads worden wakker, vechten om de lock en zetten elkaar weer in slaap. Het werk wordt nog steeds gedaan, maar tail‑latency rekt uit.
I/O‑wachten kunnen alles overschaduwen. Een enkele syscall, een volle netwerkbuffer, een TLS‑handshake, een disk‑flush of een trage DNS‑lookup kan een scherpe piek maken die geen micro‑optimalisatie oplost.
Als je jitter jagt, begin dan met het zoeken naar cache‑misses (vaak veroorzaakt door pointer‑rijke structuren en willekeurige toegang), frequente allocaties, context switches door te veel threads of lawaaierige buren, lock‑contentie en alle blokkerende I/O (netwerk, schijf, logging, synchrone calls).
Voorbeeld: een price‑ticker service kan updates in microseconden berekenen, maar één gesynchroniseerde logger‑call of een betwiste metrics‑lock kan af en toe tientallen milliseconden toevoegen.
Martin Thompson en wat het Disruptor‑patroon is
Martin Thompson is bekend in low‑latency engineering vanwege zijn focus op hoe systemen zich gedragen onder druk: niet alleen gemiddelde snelheid, maar voorspelbare snelheid. Samen met het LMAX‑team populariseerde hij het Disruptor‑patroon, een referentieaanpak om events door een systeem te verplaatsen met kleine en consistente vertragingen.
De Disruptor‑aanpak is een reactie op wat veel “snelle” apps onvoorspelbaar maakt: contentie en coördinatie. Typische queues vertrouwen vaak op locks of zware atomics, wekken threads op en neer en creëren wachttijden wanneer producers en consumers vechten om gedeelde structuren.
In plaats van een queue gebruikt Disruptor een ringbuffer: een vast‑grootte circulair array dat events in slots bewaart. Producers claimen de volgende slot, schrijven data en publiceren dan een sequentienummer. Consumers lezen op volgorde door dat sequentie te volgen. Omdat de buffer vooraf is gealloceerd, vermijd je frequente allocaties en verminder je druk op de garbage collector.
Een kernidee is het single‑writer‑principe: houd één component verantwoordelijk voor een bepaald stuk gedeelde staat (bijvoorbeeld de cursor die door de ring loopt). Minder schrijvers betekent minder momenten van “wie is er aan de beurt?”.
Backpressure is expliciet. Wanneer consumers achterlopen, bereiken producers uiteindelijk een slot dat nog in gebruik is. Op dat punt moet het systeem wachten, droppen of vertragen, maar het doet dat op een gecontroleerde, zichtbare manier in plaats van het probleem te verbergen in een steeds langer wordende queue.
Kernontwerpideeën die latency consistent houden
Wat Disruptor‑achtige ontwerpen snel maakt is geen slimme micro‑optimalisatie. Het is het wegnemen van onvoorspelbare pauzes die ontstaan wanneer een systeem tegen zijn eigen bewegende delen vecht: allocaties, cache‑misses, lock‑contentie en traag werk in het hot path.
Een nuttig mentaal model is een assemblagelijn. Events bewegen door een vaste route met duidelijke overdrachten. Dat vermindert gedeelde staat en maakt elke stap eenvoudiger om simpel en meetbaar te houden.
Houd geheugen en data voorspelbaar
Snelle systemen vermijden verrassende allocaties. Als je buffers vooraf alloceert en message‑objecten hergebruikt, verminder je "soms"‑pieken veroorzaakt door garbage collection, heap‑groei en allocator‑locks.
Het helpt ook om berichten klein en stabiel te houden. Als de data die je per event aanraakt in de CPU‑cache past, besteed je minder tijd aan wachten op geheugen.
In de praktijk zijn de gewoonten die meestal het meest tellen: hergebruik objecten in plaats van per event nieuwe te maken, houd event‑data compact, geef de voorkeur aan een enkele schrijver voor gedeelde staat en batched zorgvuldig zodat je coördinatiekosten minder vaak betaalt.
Maak trage paden zichtbaar
Real‑time apps hebben vaak extra’s zoals logging, metrics, retries of database‑writes nodig. De Disruptor‑mentaliteit is om die te isoleren van de kernlus zodat ze die niet kunnen blokkeren.
In een live price‑feed kan het hot path bijvoorbeeld alleen een tick valideren en de volgende price snapshot publiceren. Alles wat kan stagneren (disk, netwerkcalls, zware serialisatie) gaat naar een aparte consumer of zij‑kanaal, zodat het voorspelbare pad voorspelbaar blijft.
Architectuurkeuzes voor voorspelbare latency
Voorspelbare latency is grotendeels een architectuurprobleem. Je kunt snelle code hebben en toch spikes krijgen als te veel threads over dezelfde data vechten, of als berichten onnodig over het netwerk stuiteren.
Begin met beslissen hoeveel schrijvers en lezers dezelfde queue of buffer aanraken. Een enkele producer is makkelijker soepel te houden omdat het coördinatie vermijdt. Multi‑producer setups kunnen throughput verhogen, maar voegen vaak contentie toe en maken worst‑case timing minder voorspelbaar. Als je meerdere producers nodig hebt, verminder gedeelde writes door events te sharden op sleutel (bijv. userId of instrumentId) zodat elke shard zijn eigen hot path heeft.
Aan de consumer‑kant geeft een enkele consumer de meest stabiele timing als ordering belangrijk is, omdat staat lokaal bij één thread blijft. Worker pools helpen als taken echt onafhankelijk zijn, maar ze voegen scheduling‑vertragingen toe en kunnen werk herordenen tenzij je voorzichtig bent.
Batching is een andere afweging. Kleine batches snijden overhead (minder wakeups, minder cache‑misses), maar batchen kan ook wachten toevoegen als je events vasthoudt om een batch te vullen. Als je batched in een real‑time systeem, begrens de wachttijd (bijv. “tot 16 events of 200 microseconden, welke het eerst komt”).
Servicegrenzen doen er ook toe. In‑process messaging is meestal het beste als je strakke latency nodig hebt. Netwerkhops kunnen de moeite waard zijn voor schaal, maar elke hop voegt queues, retries en variabele vertraging toe. Als je een hop nodig hebt, houd het protocol eenvoudig en vermijd fan‑out in het hot path.
Een praktische regelsuite: houd waar mogelijk één single‑writer pad per shard, schaal door te sharden in plaats van één hot queue te delen, batch alleen met een strikte tijdslimiet, voeg worker pools alleen toe voor parallel en onafhankelijk werk, en behandel elke netwerkhop als een potentiële jitterbron totdat je het hebt gemeten.
Stap‑voor‑stap: ontwerp van een low‑jitter pipeline
Begin met een geschreven latency‑budget voordat je code aanraakt. Kies een target (wat “goed” voelt) en een p99 (wat je moet blijven ondergrenzen). Verdeel dat nummer over stadia zoals input, validatie, matching, persistence en outbound updates. Als een stage geen budget heeft, heeft het geen limiet.
Teken daarna de volledige dataflow en markeer elke overdracht: threadgrenzen, queues, netwerkhops en opslagcalls. Elke overdracht is een plek waar jitter zich verbergt. Als je ze ziet, kun je ze verminderen.
Een workflow die ontwerpen eerlijk houdt:
- Schrijf een budget per stage (target en p99), plus een kleine buffer voor onbekenden.
- Map de pipeline en label queues, locks, allocaties en blokkerende calls.
- Kies een concurrency‑model dat je kunt beredeneren (single writer, partitioned workers per key, of een dedicated I/O‑thread).
- Definieer berichtvorm vroeg: stabiele schema's, compacte payloads en minimale kopieën.
- Bepaal backpressureregels vooraf: drop, delay, degrade of shed load. Maak het zichtbaar en meetbaar.
Beslis daarna wat asynchroon kan zonder de gebruikerservaring te breken. Een eenvoudige regel: alles wat verandert wat de gebruiker “nu” ziet blijft op het kritieke pad. Alles wat dat niet doet verhuist naar buiten.
Analytics, audit logs en secundaire indexering zijn vaak veilig om van het hot path af te duwen. Validatie, ordering en stappen die nodig zijn om de volgende staat te produceren kunnen dat meestal niet.
Runtime‑ en OS‑keuzes die de tail beïnvloeden
Snel code kan nog steeds traag aanvoelen als de runtime of OS je werk op het verkeerde moment pauzeert. Het doel is niet alleen hoge throughput. Het is minder verrassingen in de traagste 1% van verzoeken.
Garbage‑collected runtimes (JVM, Go, .NET) zijn productief, maar kunnen pauzes introduceren als geheugen moet worden opgeruimd. Moderne collectors zijn veel beter, maar tail‑latency kan nog steeds springen als je veel kortstondige objecten aanmaakt onder load. Niet‑GC‑talen (Rust, C, C++) vermijden GC‑pauzes, maar verplaatsen de kosten naar manuele ownership en allocatiediscipline. Hoe dan ook, geheugengedrag is net zo belangrijk als CPU‑snelheid.
De praktische gewoonte is simpel: vind waar allocaties gebeuren en maak ze saai. Hergebruik objecten, pre‑size buffers en voorkom dat hot‑path data tijdelijke strings of maps worden.
Threading‑keuzes tonen zich ook als jitter. Elke extra queue, async hop of threadpool‑handoff voegt wachten toe en vergroot variantie. Geef de voorkeur aan een klein aantal langlevende threads, houd producer‑consumer grenzen duidelijk en vermijd blokkerende calls op het hot path.
Een paar OS‑ en containerinstellingen bepalen vaak of je staart schoon of piekerig is. CPU‑throttling door strakke limieten, lawaaierige buren op gedeelde hosts en slecht geplaatste logging of metrics kunnen plotselinge vertragingen veroorzaken. Als je één ding verandert, begin dan met het meten van allocatiesnelheid en context switches tijdens latency‑spikes.
Data, opslag en servicegrenzen zonder verrassende pauzes
Veel latency‑spikes zijn geen “trage code.” Het zijn onvoorziene wachtmomenten: een database‑lock, een retry‑storm, een cross‑service call die vastloopt of een cache miss die in een volledige roundtrip verandert.
Houd het kritieke pad kort. Elke extra hop voegt scheduling, serialisatie, netwerkqueues en meer plekken om te blokkeren toe. Als je een request uit één proces en één datastore kunt beantwoorden, doe dat eerst. Split alleen in meer services als elke call optioneel of strikt begrensd is.
Beperkte wachttijd is het verschil tussen snelle gemiddelden en voorspelbare latency. Zet harde timeouts op remote calls en faal snel als een dependency ongezond is. Circuit breakers gaan niet alleen over serverbesparing. Ze begrenzen hoe lang gebruikers vast kunnen zitten.
Wanneer datatoegang blokkeert, scheid de paden. Reads willen vaak geïndexeerde, gededenormaliseerde en cache‑vriendelijke vormen. Writes willen vaak duurzaamheid en ordering. Scheiding kan contentie wegnemen en lock‑tijd verminderen. Als je consistentiebehoeften het toelaten, gedragen append‑only records (een eventlog) zich vaak voorspelbaarder dan in‑place updates die hot‑row locking of achtergrondonderhoud triggeren.
Een eenvoudige regel voor real‑time apps: persistency hoort niet op het kritieke pad te liggen tenzij je het echt nodig hebt voor correctheid. Vaak is de betere vorm: update in geheugen, reageer, en persist asynchroon met een replay‑mechanisme (zoals een outbox of write‑ahead log).
In veel ringbuffer‑pipelines resulteert dit in: publiceer naar een in‑memory buffer, update staat, reageer, en laat een aparte consumer writes naar PostgreSQL batchen.
Een realistisch voorbeeld: real‑time updates met voorspelbare latency
Stel je een live collaboration app (of een kleine multiplayer game) voor die updates elke 16 ms pusht (ongeveer 60 keer per seconde). Het doel is niet “snel gemiddeld.” Het is “meestal onder 16 ms,” zelfs als de verbinding van één gebruiker slecht is.
Een eenvoudige Disruptor‑achtige flow ziet er zo uit: gebruikersinput wordt een klein event, het wordt gepubliceerd in een vooraf gealloceerde ringbuffer, daarna verwerkt door een vaste set handlers in volgorde (validate -> apply -> prepare outbound messages) en uiteindelijk uitgezonden naar clients.
Batching kan aan de randen helpen. Bijvoorbeeld: batch outbound writes per client één keer per tick zodat je de netwerklaag minder vaak aanroept. Maar batch niet in het hot path op een manier die “net even iets langer” wacht op meer events. Wachten is hoe je de tick mist.
Als iets traag wordt, behandel het als een containment‑probleem. Als één handler vertraagt, isoleer die dan achter zijn eigen buffer en publiceer een lightweight work item in plaats van de hoofdloop te blokkeren. Als één client traag is, laat die broadcaster er niet door ophopen; geef elke client een kleine sendqueue en drop of coalesce oude updates zodat je de laatste staat behoudt. Als bufferdiepte groeit, pas backpressure toe aan de rand (stop extra inputs voor die tick, of degradeer features).
Je weet dat het werkt als de cijfers saai blijven: backlogdiepte zweeft rond nul, gedropte/coalesced events zijn zeldzaam en verklaarbaar, en p99 blijft onder je tick‑budget tijdens realistische load.
Veelgemaakte fouten die latency‑spikes creëren
De meeste latency‑spikes zijn zelf toegebracht. De code kan snel zijn, maar het systeem pauzeert nog steeds wanneer het op andere threads, het OS of alles buiten de CPU‑cache wacht.
Een paar fouten die vaak terugkomen:
- Overal gedeelde locks gebruiken omdat het simpel voelt. Eén betwiste lock kan veel verzoeken stilzetten.
- Trage I/O in het hot path mengen, zoals synchrone logging, database‑writes of remote calls.
- Onbegrensde queues aanhouden. Ze verbergen overload totdat je seconden achterstand hebt.
- Gemiddelden bekijken in plaats van p95 en p99.
- Vroegtijdig over‑tunen. Threads pinnen helpt niet als vertragingen door GC, contentie of wachten op een socket komen.
Een snelle manier om spikes te verminderen is wachten zichtbaar en begrensd te maken. Plaats traag werk op een apart pad, begrens queues en bepaal wat er gebeurt als ze vol zijn (drop, shed load of degrade features).
Snelle checklist voor voorspelbare latency
Behandel voorspelbare latency als een producteigenschap, niet als een toevalstreffer. Voordat je code gaat tunen, zorg dat het systeem duidelijke doelen en vangrails heeft.
- Stel een expliciet p99‑doel (en p99.9 als dat telt), schrijf dan een latency‑budget per stage.
- Houd het hot path vrij van blokkerende I/O. Als I/O moet gebeuren, verplaats het naar een zijpad en bepaal wat je doet als het traag is.
- Gebruik begrensde queues en definieer overload‑gedrag (drop, shed load, coalesce of backpressure).
- Meet continu: backlogdiepte, per‑stage tijd en tail‑latency.
- Minimaliseer allocatie in de hot loop en maak het makkelijk zichtbaar in profielen.
Een eenvoudige test: simuleer een burst (10x normale traffic voor 30 seconden). Als p99 explodeert, vraag dan waar het wachten gebeurt: groeiende queues, een trage consumer, een GC‑pause of een gedeelde resource.
Volgende stappen: hoe pas je dit toe in je eigen app
Behandel het Disruptor‑patroon als een werkwijze, niet alleen als een bibliotheekkeuze. Bewijs voorspelbare latency met een dunne slice voordat je features toevoegt.
Kies één gebruikersactie die instant moet aanvoelen (bijv. “nieuwe prijs arriveert, UI werkt bij”). Schrijf het end‑to‑end budget op en meet p50, p95 en p99 vanaf dag één.
Een volgorde die vaak werkt:
- Bouw een dunne pipeline met één input, één kerndraad en één output. Valideer p99 onder load vroeg.
- Maak verantwoordelijkheden expliciet (wie bezit staat, wie publiceert, wie consumeert) en houd gedeelde staat klein.
- Voeg concurrency en buffering in kleine stappen toe en houd wijzigingen omkeerbaar.
- Deploy dicht bij gebruikers als het budget strak is en meet opnieuw onder realistische load (zelfde payloadgroottes, dezelfde burstpatronen).
Als je op Koder.ai (koder.ai) prototypeert, kan het helpen eerst de eventflow in Planning Mode te tekenen zodat queues, locks en servicegrenzen niet per ongeluk verschijnen. Snapshots en rollback maken het ook makkelijker om herhaalde latency‑experimenten uit te voeren en veranderingen terug te draaien die throughput verbeteren maar p99 verslechteren.
Houd metingen eerlijk. Gebruik een vaste testscript, warm het systeem op en registreer zowel throughput als latency. Wanneer p99 stijgt onder load, begin dan niet meteen met "de code optimaliseren." Zoek naar pauzes door GC, lawaaierige buren, logging‑bursts, thread‑scheduling of verborgen blokkerende calls.